
[Database] Database 고가용성
회사에서 데이터베이스 시스템의 고가용성을 확보하기 위해 데이터베이스를 다중화하는 업무를 진행했다. 회사에서 사용하는 DBMS는 PostgreSQL이라, PostgreSQL에 다중화를 적용해야 했는데, 그에 앞서 데이터베이스 다중화에 대해 개념을 잡고 가야 할 필요가 있어 학습한 내용을 정리하고자 한다.
개요
데이터베이스 시스템의 가용성을 높이기 위해서는 데이터베이스 시스템이 갖는 특성을 바탕으로 해당 시스템의 다중화를 위해 어떠한 아키텍처를 도입할 수 있는지 고려해야 한다.
- 가용성(Availability): 서버, 네트워크, 프로그램 등의 정보 시스템을 정상적으로 사용할 수 있는 정도
- 고가용성(High Availability): 서버, 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질
- 다중화(Redundancy): 시스템 구성 요소를 여러 개 준비하여 시스템의 지속성을 높이는 것
시스템 구조

일반적으로 데이터베이스 시스템은 위의 그림과 같이, 서버와 스토리지로 구성된다.
- 스토리지: 실제 데이터가 저장되는 물리적인 공간
- 서버: 스토리지에 저장된 데이터를 서빙하는 컴포넌트
시스템 가용성
가용성 개념에 근거해, 데이터베이스 시스템의 가용성은 데이터베이스 시스템을 정상적으로 사용할 수 있는 정도로 판단할 수 있다. 데이터베이스 시스템의 구성 요소를 고려하면, 시스템 가용성 저해 요소는 서버와 스토리지 모두가 될 수 있다.
- DB 서버가 죽는다면?
- DB 스토리지가 망가진다면?
- DB 서버도 죽고, 스토리지도 제대로 동작하지 않는다면?
따라서 데이터베이스 시스템의 가용성을 높이기 위해서는 데이터베이스 시스템을 정상적으로 사용하지 못할 상황에 대비해, 해당 시스템 구성 요소를 다중화해야 한다.
- DB 서버의 확장: DB 서버 컴포넌트를 여러 대 두어, 서버 하나가 제대로 동작하지 않더라도 다른 서버가 스토리지의 데이터를 서빙할 수 있도록 해야 한다
- DB 스토리지의 확장: DB 스토리지를 여러 대 두어, 스토리지 하나가 제대로 동작하지 않더라도 데이터베이스 시스템을 이용할 수 있도록 해야 한다
특히, 데이터베이스 시스템은 여타 시스템과 달리 영속 계층으로서의 성격을 갖는다. 따라서 데이터베이스 시스템을 다중화할 때는 서버 뿐만 아니라 스토리지의 다중화까지 고려해야 하며, 이 경우 다중화된 시스템 간 데이터 정합성과 안정성까지 보장할 수 있어야 한다는 점에서 어려움이 있다.
데이터베이스 다중화 아키텍처
일반적으로 데이터베이스 시스템 다중화 문제를 풀기 위한 아키텍처는 크게 클러스터링과 리플리케이션으로 구분할 수 있다. 아키텍처 별로 어떤 구성 요소를 확장하고자 했는지, 그 과정에서 무엇을 중점적으로 고려했는지가 달라진다.
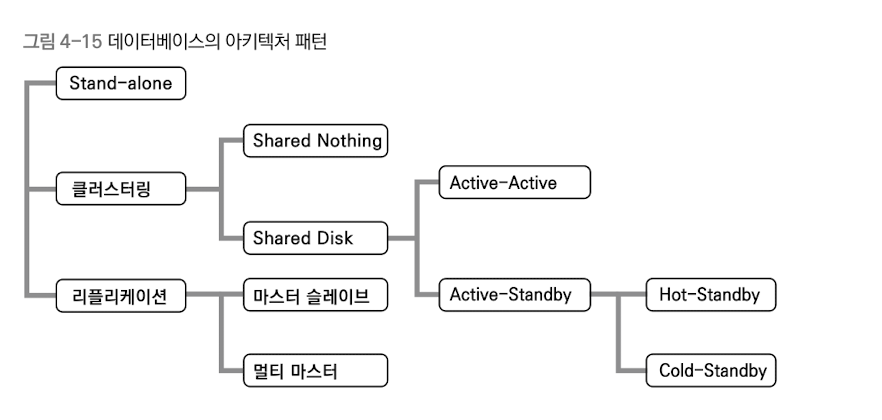
아키텍처 그림 상에서 마스터-슬레이브로 표현된 유형은, 최근의 추세에 따라 Primary-Standby/Secondary로 표현하는 것이 좋다.
- 클러스터링(Clustering): DB 서버를 다중화하여, 여러 대의 DB 서버를 마치 한 대의 서버처럼 동작시킨다. 한 대의 서버가 제대로 동작하지 않더라도 데이터베이스 시스템을 이용할 수 있도록 한다.
- DB 서버의 수평적 확장에 중점을 둠
- DB 서버의 Failover 처리, 서버 간 Load Balancing을 주로 고려함
- 스토리지가 다중화되지 않아 데이터가 유실될 수도 있다는 문제점이 여전히 존재함
- 리플리케이션(Replication): DB 서버와 저장소를 포함한 시스템 전체를 다중화한다. 하나의 시스템이 제대로 동작하지 않더라도 다른 데이터베이스 시스템을 이용할 수 있도록 한다
- DB 스토리지 내 데이터 복제에 중점을 둠
- DB 시스템 간 데이터 동기화, 데이터 일관성 및 신뢰성을 주로 고려함
- DB 서버와 저장소 세트를 여러 개로 다중화하여, 데이터 손실의 문제를 해결하고자 함
Disclaimer
위와 같은 개념을 바탕으로, 데이터베이스 시스템 다중화를 위해 DB 클러스터링과 DB 리플리케이션에 대해 알아 보았다. 그러나 학습 과정에서 각 아키텍처 내부적으로 각각의 유형을 심화해서 살펴 보았을 때, 각각의 유형을 서로 다른 유형과 배타적으로 구분 짓기 어려운 경우가 있었다.
- Shared Nothing 방식의 DB 클러스터링은 Shared Disk 방식의 DB 클러스터링이 갖는 성능 측면에서의 단점을 극복하기 위해 고안된 방식이다. 하지만, DB 서버가 늘어날 때 DB 저장소도 같이 늘어난다는 점에서 리플리케이션과 헷갈렸다.
- 고가용성 확보를 넘어, 수평적인 확장을 위한 아키텍처라고 보아야 한다.
- 오히려 샤딩과 더 가깝다.
- Primary 시스템에서 Write 쿼리를 처리하고, Standby 시스템에서 Read Only 쿼리를 처리하는 방식의 리플리케이션에서는 DB 클러스터링에서 주로 고려한 로드 밸런싱 효과도 얻을 수 있다.
특히, 개념적 측면에서 뿐만이 아니라, 실제 DBMS 별로 적용할 수 있는 다중화 솔루션(그것이 DBMS 차원에서 제공되는 내장 솔루션이든, 3rd party에서 제공되는 것이든 간에)을 살펴 보면, 각 솔루션은 각 아키텍처 유형별 특징을 고루 지니고 있는 것들도 많았다.
따라서, 개인적인 의견이긴 하나, DB 다중화 아키텍처는 개념적인 차원에서 두 가지가 어떻게 구분되는지 정도는 유념하되, 각 아키텍처 별 세부 유형이나 DBMS 별로 적용될 수 있는 실제 솔루션이 어디에 어떻게 속하는지를 구분하기 위해 노력하지는 않아도 될 것이라 보인다.
같은 맥락에서, 추후 기술될 각 개념별 특징들 역시 절대적으로 받아들이기 보다는 다른 개념들과 비교했을 때 어떤 특징을 갖는지 상대적으로 이해할 필요가 있다. 그리고 데이터베이스 시스템에 실제 다중화를 적용하고자 할 때는, 이 개념들은 배경 지식 정도로만 두고, 각 솔루션의 특징 자체에 집중해 어떤 솔루션들을 도입해 아키텍처를 설계할지 고민하는 것에 집중해야 할 것이다.
DB 클러스터링
DB 서버를 다중화한다. 여러 대의 DB 서버를 하나의 클러스터로 운용하는 다중화 방식이다.
- Shared Disk: 스토리지를 공유하는 클러스터링 방식
- Shared Nothing: 스토리지를 공유하지 않는 클러스터링 방식
Shared Disk
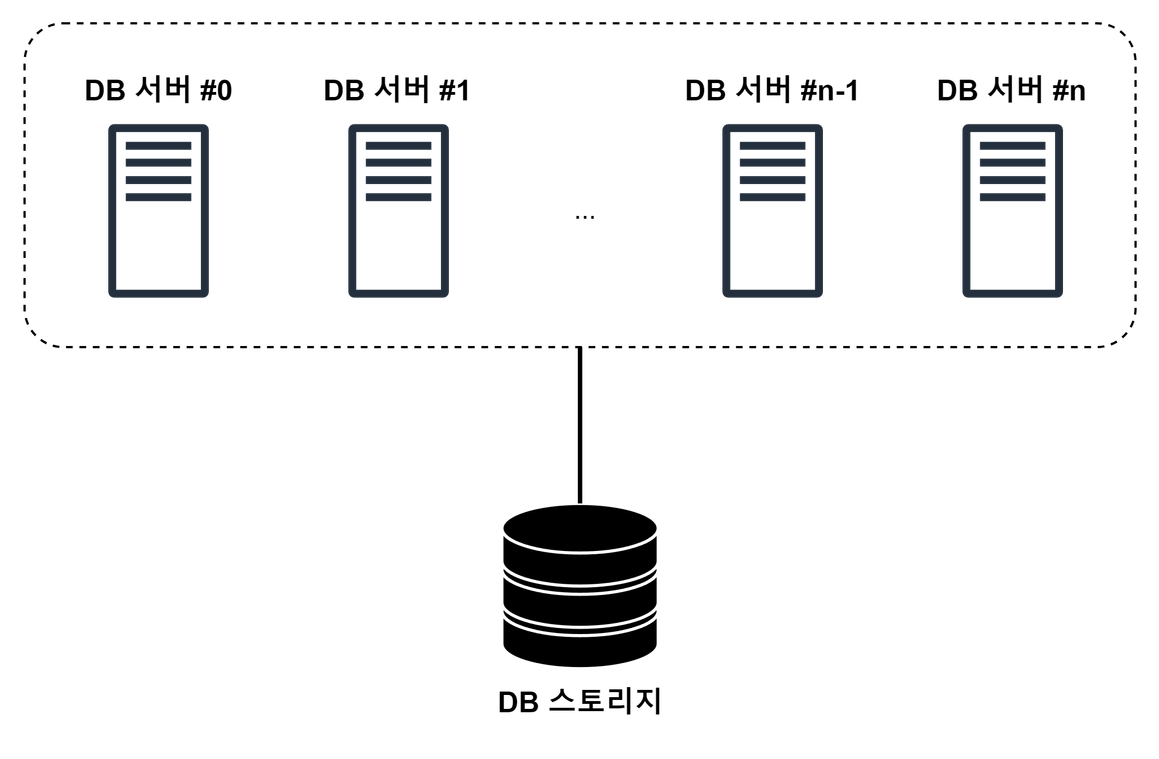
In a shared disk architecture, multiple nodes in a cluster share access to the same storage (disk) subsystem. Each node in the cluster has its own processor and memory, but they all have concurrent access to a common pool of storage.
- 주로 SAN(Storage Area Network)이나 Shared File System을 이용해 클러스터 내의 모든 DB 서버 인스턴스가 동일한 스토리지에 접근할 수 있도록 구현됨
- 데이터가 저장되는 스토리지가 한 군데이기 때문에, 데이터 동기화 및 정합성을 고려하지 않아도 됨
Active-Active
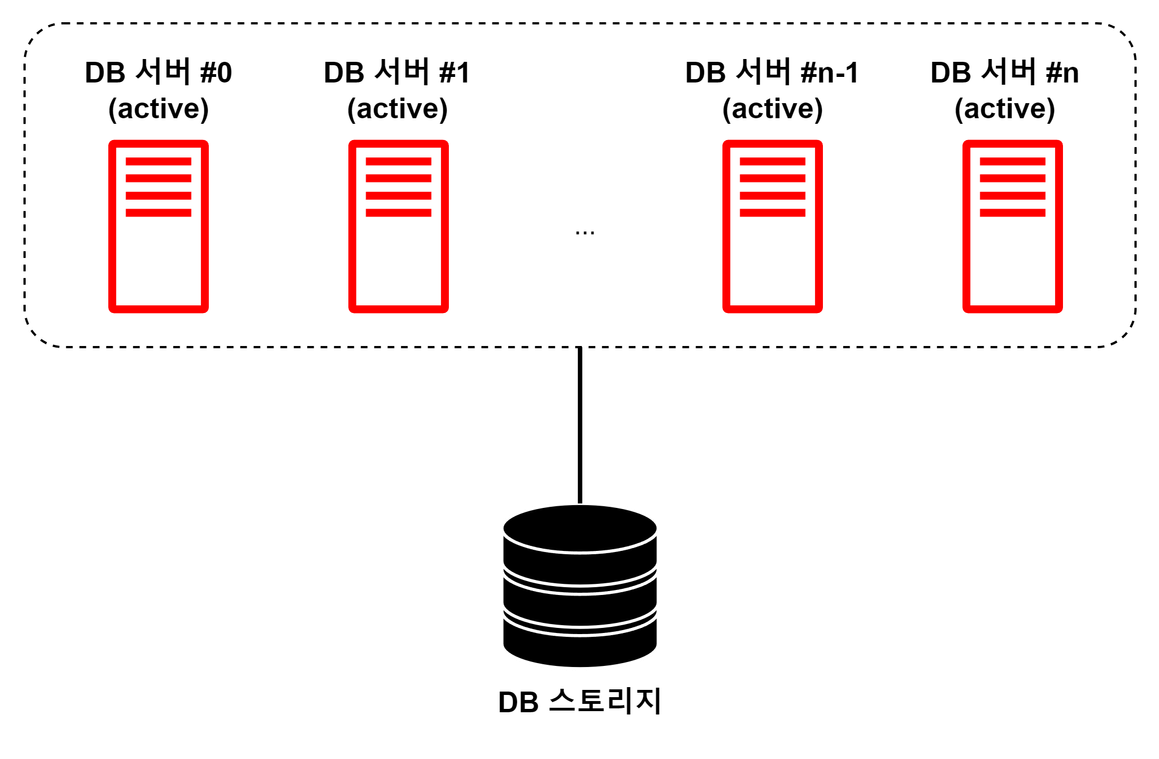
클러스터 내 DB 서버 모두를 동작 중(Active)인 상태로 구성한다. 서버 각각이 모두 클라이언트의 요청을 처리할 수 있다.
- 장점
- DB 서버 하나가 동작하지 않더라도 다른 서버가 바로 역할을 수행할 수 있어 서비스 중단 시간이 짧음
- 여러 서버 인스턴스가 동작 중이기 때문에, 로드 밸런싱 가능
- 모든 서버가 동작 중인 상태이기 때문에, 자원 이용률을 높일 수 있음
- 단점
- 서버를 여러 대 동시에 운영하고 있어야 하기 때문에, 관리 포인트 및 비용이 증가함
- 모든 동작 중인 서버가 스토리지 하나를 공유하게 되므로, 오히려 병목 현상이 발생할 수 있음
- 예
- Oracle RAC
Active-Standby
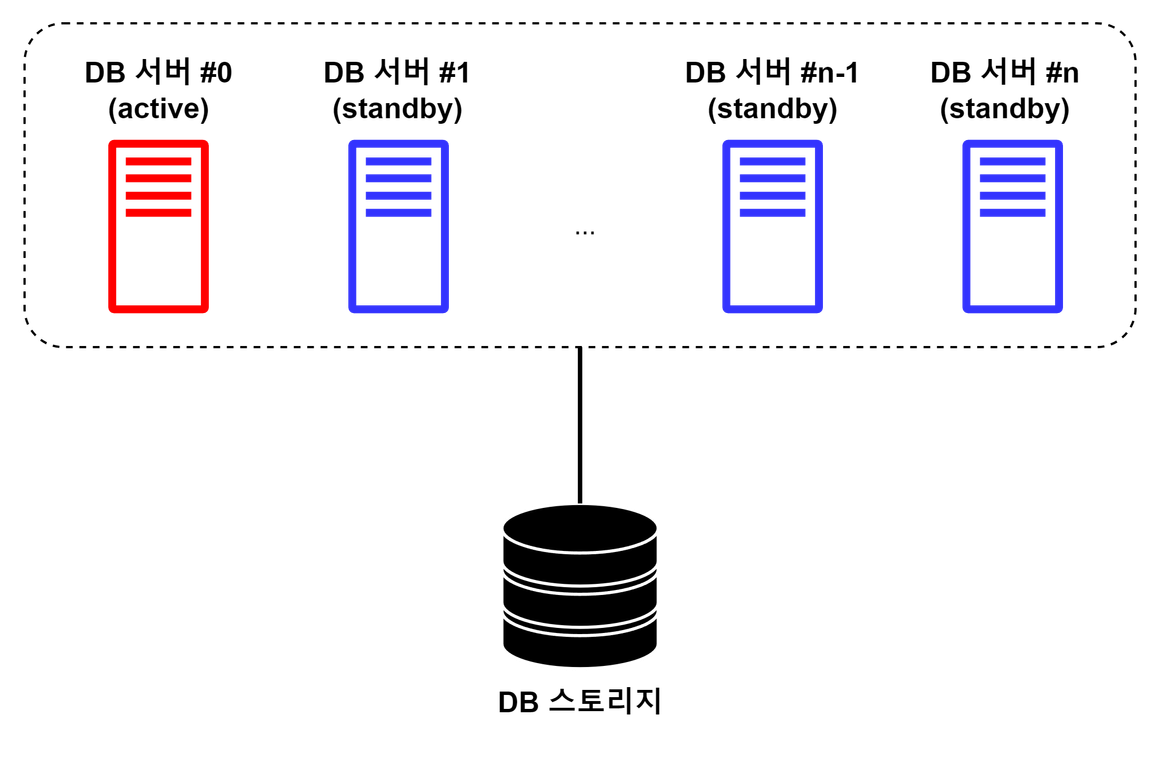
클러스터 내 DB 서버 중 한 대를 동작 중(Active)인 상태로, 나머지를 대기 중인 예비 상태(Standby)로 구성한다. 운영 중이던 Active 서버가 정지되었을 경우, Standby 서버를 Active 상태로 전환한다. Active 상태의 서버만 클라이언트의 요청을 처리할 수 있다.
- Active 서버의 Failover 처리 필요
- 주로 클러스터 내의 Standby 서버가 Active 서버에 heartbeat를 보내고, 이에 대한 응답이 돌아오지 않으면 Standby 서버를 Active 서버로 전환하는 방식 사용
- Standby 서버의 작동에 따른 세부 분류
- Cold Standby: 평소에는 동작하지 않다가, Active 서버가 정상 작동하지 않는 시점부터 동작함
- Hot Standby: 평소에도 동작함. 즉, Active 서버가 정상 작동하고 있는 시점이더라도 동작함
- Cold Standby에 비해 Failover 시 전환 시간이 짧음
- 어차피 동작하는 것은 Active 상태의 DB 한 대라는 점을 고려하면, 유지 비용이 높을 수 있음
- 장점
- Active-Active 방식에 비해 관리 포인트 및 비용이 적음
- Active-Active 방식에서 발생할 수 있는 저장소에 대한 병목 현상이 덜 발생함
- 단점
- Active-Active 방식에 비해 서비스 중단 시간이 긺
- Standby 서버가 Active 상태로 전환되는 동안, 어쩔 수 없이 시스템 다운이 발생함
- Standby 서버의 자원을 활용할 수 없음
- Active-Active 방식에 비해 서비스 중단 시간이 긺
Shared Nothing
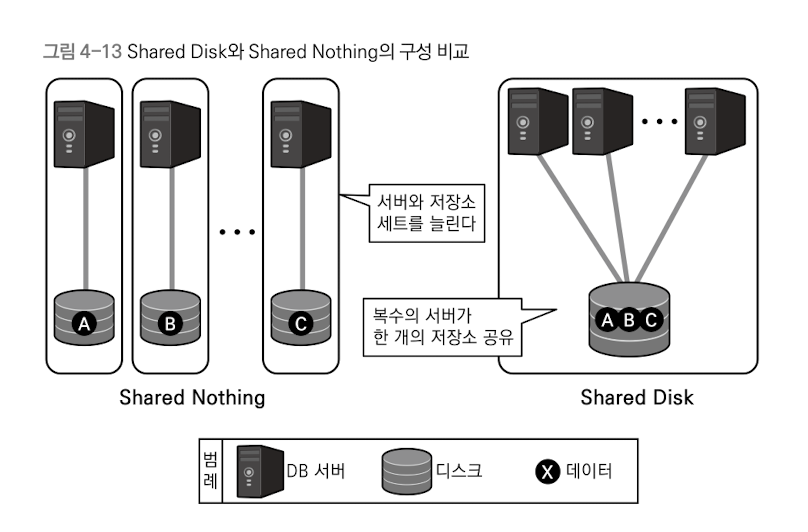
클러스터 내 DB 서버가 각각의 스토리지를 가지고 클러스터를 구축한다. 각각의 서버는 자신의 스토리지에 대한 접근 권한만을 가지며, 클러스터 내 서버는 네트워크 이외에 아무런 자원도 공유하지 않는다.
In a shared nothing architecture, each node in the cluster has its own dedicated set of resources, including processors, memory, and storage. Nodes do not share storage; instead, they operate independently, and data is distributed across the nodes.
Shared Disk DB 클러스터링 유형 중 Active-Active 방식의 문제점을 해결하고자, DB 서버를 늘릴 때 스토리지도 함께 늘리는 방식의 아키텍처이다.
- Active-Active 방식의 DB 클러스터링 아키텍처는 단일 스토리지를 사용하기 때문에, DB 서버를 아무리 늘리더라도 처리율이 향상되지 않는 한계점에 도달할 수밖에 없음
- DB 서버 별로 처리하는 데이터 영역을 나누고, 서버를 늘릴 때 해당 데이터 영역에 대한 스토리지도 함께 구축함
- 장점
- Shared Disk 방식의 Active-Active 아키텍처에 비해 처리율을 늘릴 수 있음
- 스토리지를 공유함으로써 나타나는 관리 포인트 및 비용이 줄어듦
- 단점
- 클러스터 내 노드 간 데이터 분배 정책이 필요할 수 있음
- 클러스터 내 특정 DB 서버 인스턴스가 작동하지 않을 경우, 해당 DB 서버의 스토리지에 접근할 수 없어 나타나는 문제를 해결해야 함
- 클러스터 내 노드 간 관리하는 데이터가 중복될 경우, 데이터 동기화 문제도 고려해야 함
- 로드 밸런싱을 적용하기 어려울 수 있음
참고: Shared Nothing 방식의 클러스터링
위에서 Shared Nothing 방식의 클러스터링이 샤딩에 가깝다고 언급했다. 실제 Google은 Shared Nothing 방식의 클러스터링이 유효함을 증명했고, 자신들이 고안한 Shared Nothing 방식의 DB 클러스터링 아키텍처를 샤딩이라고 부른다고 한다. 그런데 그것이 일반적으로 데이터베이스 쪽에서 사용되는 샤딩이라는 개념과 동일한 지는 정확히 모르겠다. 조금 더 알아봐야 한다.
DB 리플리케이션
데이터베이스 시스템 자체를 복제한다. DB 서버 뿐만 아니라, DB 스토리지까지 복제한다. DB 서버와 스토리지 세트를 복수로 준비하여, 하나의 시스템이 제대로 작동하지 않으면 다른 시스템을 활용하는 개념이다.
구조
데이터베이스 리플리케이션에는 Primary-Secondary/Standby 구조와 Multi Master 구조가 있다.
- Primary/Standby: 하나의 DB 시스템(Primary)에서 다른 DB 시스템으로 데이터를 복제하는 구조
- Multimaster: 모든 시스템이 Primary가 되는 쌍방향 복제 구조
두 가지 구조 중 Multimaster 리플리케이션의 경우, 모든 시스템이 데이터 읽기 및 쓰기 작업을 처리할 수 있으나, 시스템 간 데이터 동기화 및 정합성 유지를 위해 매우 복잡한 구성이 필요하고, 시스템 운영 비용이 많이 들게 된다. 이러한 이유로 쉽게 보기 어려운 아키텍처라고 한다. 따라서 이 글에서는 리플리케이션을 전자의 개념에 국한해 이해하고자 한다.
그렇다고 Multimaster 구조를 아예 볼 수 없는 것은 아니며, 실제 DBMS 별로 적용할 수 있는 솔루션 중에서도 Multimaster 구조를 따르는 것들이 있다. 로드 밸런싱과 데이터 안정성 확보 측면에서 장점이 있지만, 그에 따르는 비용도 큰 만큼, DB 시스템의 고가용성 확보를 위해 해당 구조를 적용하고자 할 경우, 모든 시스템이 Primary가 되어야 하는 이유를 명확히 할 필요가 있어 보인다.
개념
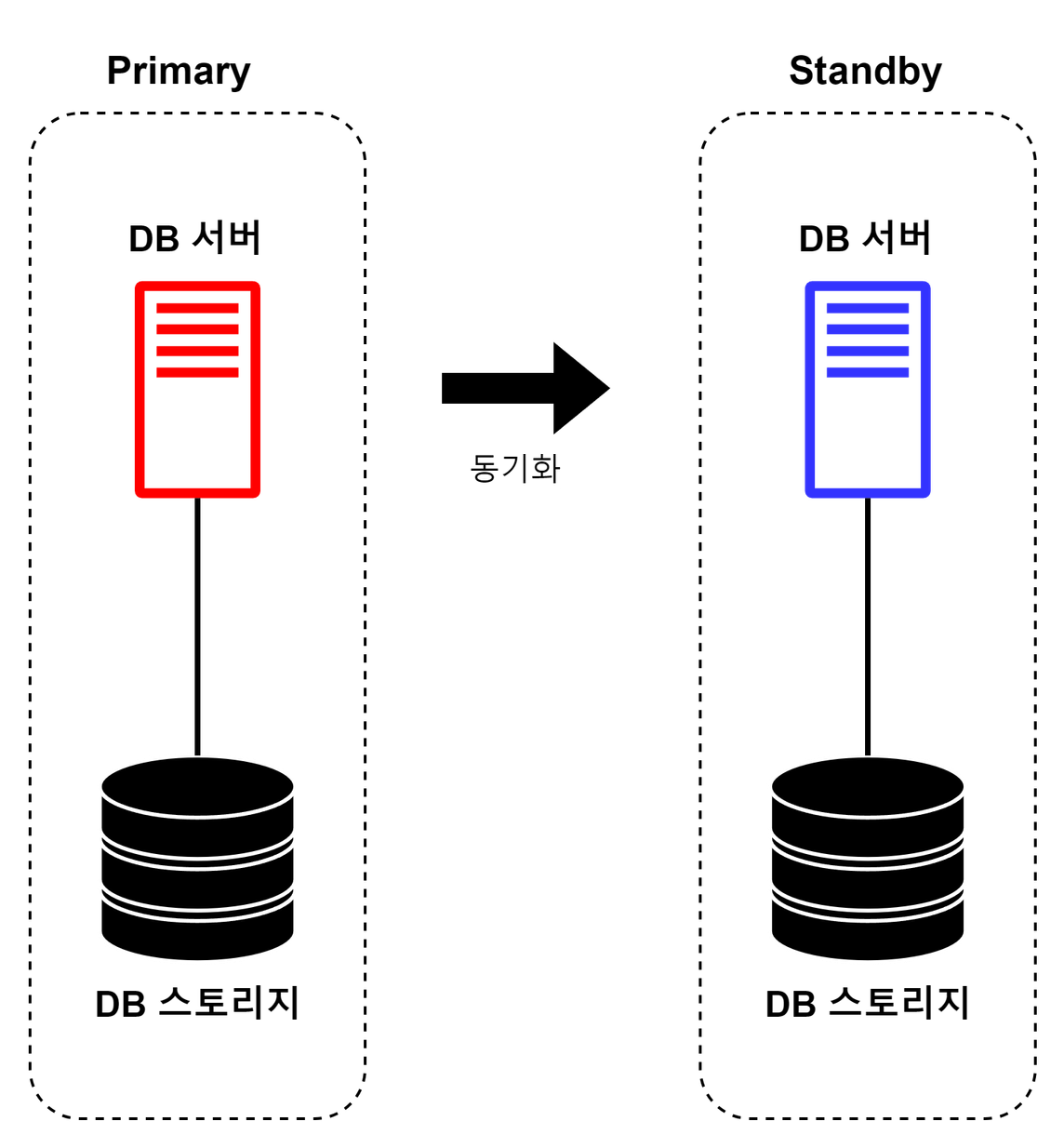
Primary 시스템에서 Standby 시스템으로 데이터를 동기화하는 아키텍처이다.
- Primary: 데이터를 동기화하는 측. Write 작업을 처리할 수 있음
- Secondary/Standby: 데이터가 동기화되는 측. Write 작업을 처리할 수 없음
동기화 방식은 구현에 따라 다를 수 있다. 보편적인 리플리케이션 방식 중 하나는 Primary 측의 데이터베이스 로그를 Standby 측에서 읽어 동일한 작업을 진행하는 방식이다.
데이터 동기화 주기에 따라, 아키텍처를 아래와 같이 구분할 수 있다.
- 구분
- 동기 방식: Primary 측의 데이터에 Write 작업이 발생할 때마다, 실시간으로 Standby 측에 데이터를 동기화한다. Primary와 Standby 시스템이 항상 동기화된 상태를 유지하게 된다
- 비동기 방식: 일정 시간 간격을 두고 Primary 측의 데이터를 Standby 측에 동기화한다. Primary와 Standby 시스템이 서로 다른 상태를 유지하게 되는 간격이 발생한다.
- 데이터 정합성 및 성능 간의 트레이드오프
- 데이터 동기화 주기가 짧아질 수록 두 시스템 간의 동기화 정도는 높아지지만, 동기화를 위한 비용이 커짐
- 데이터 동기화 주기가 길어질 수록 두 시스템 간 동기화 정도는 낮아지나, 동기화 비용은 적어짐
특징
- 장점
- 데이터 백업이 가능해, 데이터 손실 문제에 대비할 수 있음
- 단점
- 데이터 복제 및 정합성 유지에 초점이 맞춰져 있기 때문에, 로드 밸런싱 및 Failover 방안을 고려해야 함
- Primary 시스템에서의 장애를 감지하고, Standby 시스템을 승격시키는 과정이 필요함
- Primary 시스템에만 부하가 집중될 수 있음
- 다만, 아키텍처 구성에 따라 로드 밸런싱이 가능할 수도 있음
- 데이터 동기화 주기에 따라, Primary 시스템의 데이터가 동기화되기 전에 장애가 발생하면, 데이터가 유실될 수 있는 위험이 여전히 존재함
- 스토리지까지 모두 복제해야 하기 때문에, 확장성이 떨어질 수 있음
- Primary 시스템의 스토리지가 정상 작동하지 않는다면, 복구 및 대처가 어려울 수 있음
- 데이터 복제 및 정합성 유지에 초점이 맞춰져 있기 때문에, 로드 밸런싱 및 Failover 방안을 고려해야 함
아키텍처 응용
기본
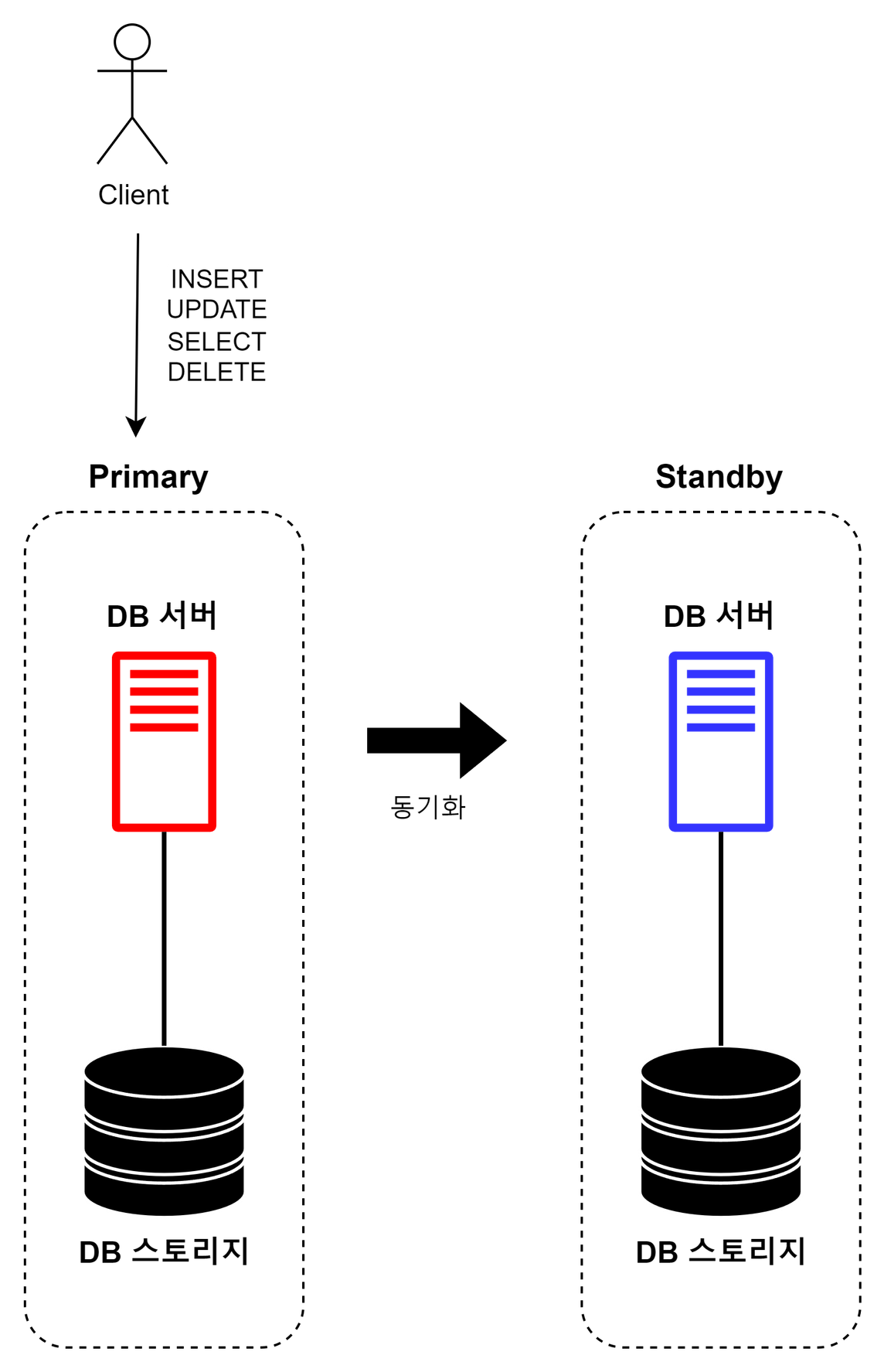
Primary 시스템에서 모든 Read/Write 작업을 처리한다. Standby 시스템은 Primary 시스템의 데이터를 백업하다, Primary 시스템이 작동하지 않을 경우 Primary로 승격되어 작동한다. 기본적인 구조로, Standby 시스템 자원을 활용할 수 없다는 단점이 있다.
Read Only 쿼리 분산
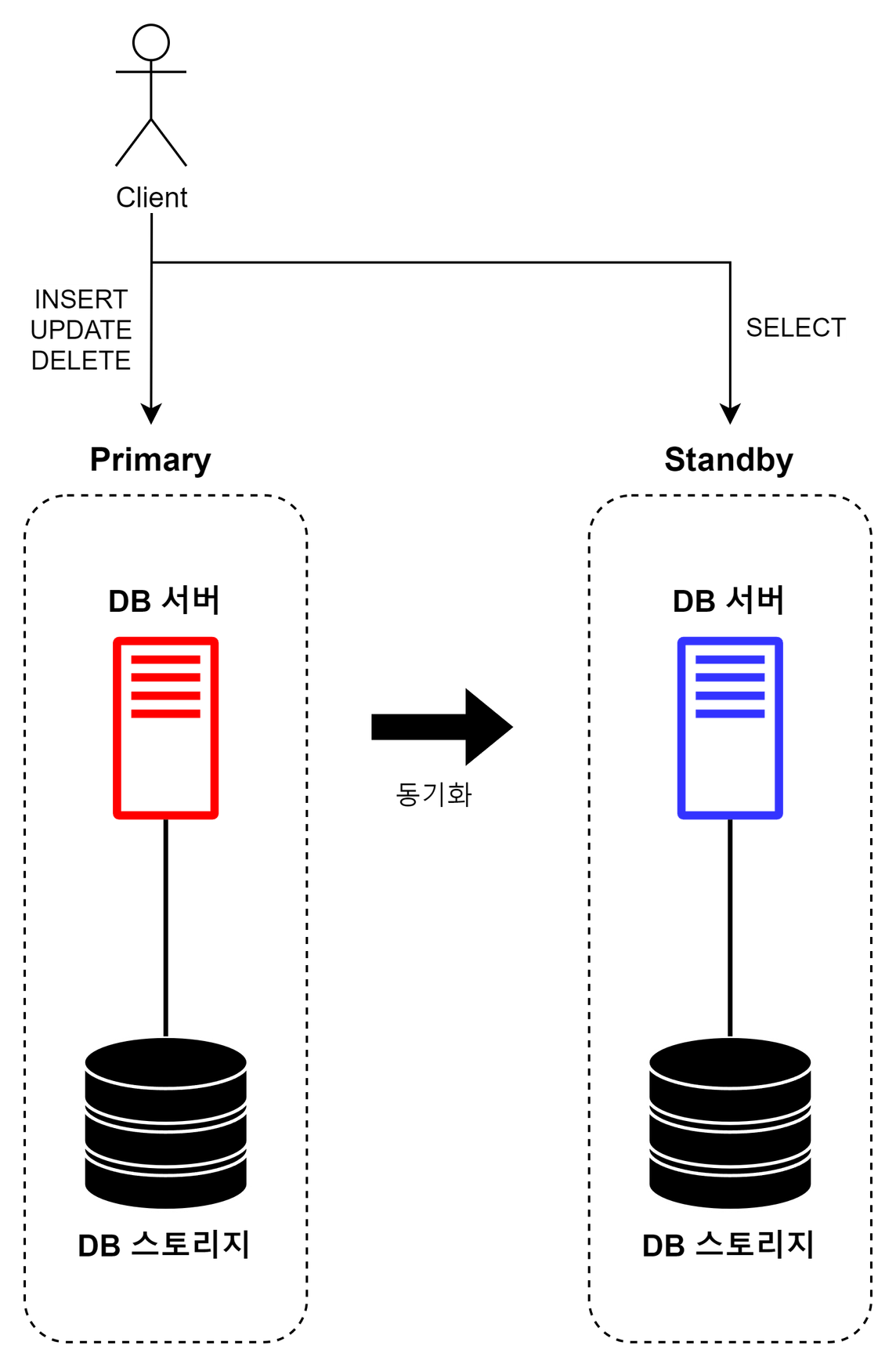
Primary 시스템에서 Write 작업을 처리한다. Standby 시스템은 Primary 시스템과의 동기화를 유지한 채, Read 작업을 처리한다.
- Primary 시스템의 부하를 분산하는 효과를 얻을 수 있다
- SQL 작업의 대부분이 읽기 요청인 시스템일수록, 부하 분산 효과를 크게 얻을 수 있음
- 데이터 분석이 필요한 경우가 대표적인 예시입니다. 데이터베이스를 복제한 후, 데이터 분석용 서버에서 조회 및 집계 연산을 처리하도록 함
- SQL 작업의 대부분이 읽기 요청인 시스템일수록, 부하 분산 효과를 크게 얻을 수 있음
- 스토리지 내 데이터 자체가 많은 경우, 성능 향상 효과는 크지 않을 수 있다
- 테이블 자체에 데이터가 매우 많다면, Standby 시스템이 몇 개가 되더라도 원하는 데이터를 조회하는 데에 시간이 걸릴 수 있음
- 샤딩 등의 데이터 분산 기법을 추가적으로 도입해야 할 수도 있음
결론
데이터베이스 시스템의 가용성을 높이기 위한 아키텍처는 크게 클러스터링과 리플리케이션이 있다. 세부적으로 들어가면 더 많다. 실제 솔루션들을 살펴 보면, 더 많다. 따라서 각각의 특징에 따라 어떠한 고가용성 아키텍처를 도입할 지가 달라진다.
각 아키텍처 별 특징을 나름대로 아래와 같이 정리해 볼 수 있다. 계속해서 말하지만, 정답은 아니다.
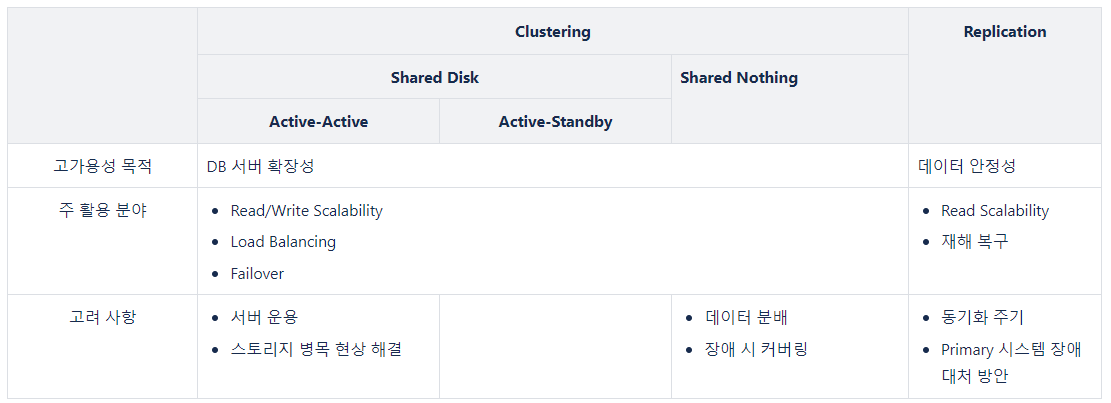
따라서 실제 데이터베이스 고가용성을 확보하기 위해 특정 솔루션을 도입하고자 할 경우, 위의 내용은 개념 숙지 차원에서 이해하고, 우리 시스템에가장 적합한 솔루션이 무엇일지 그 자체를 고려해 채택할 필요가 있을 것이다.
공유하기
Twitter Facebook LinkedIn

댓글남기기