
[AI] BERT4REC: Sequential Recommendation with Bidirectional Encoder Representations from Transformer 리뷰
논문( 출처 ) BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. 출처가 명시되지 않은 모든 자료(이미지 등)는 원 논문의 것입니다.
알리바바에서 Sequential Recommendation 문제를 풀기 위해 자연어처리 모델 BERT 를 적용한 모델이다.
Sequential Recommenation이란 사용자의 과거 행동 시퀀스(주로 구매, 클릭한 아이템 벡터로 표현된다)로부터 이후의 행동을 예측하여 추천하는 추천시스템이다. 사용자의 과거 행동으로부터 동적으로 변화하는 선호를 파악하기 위해 사용한다. 이 논문은 Sequential Recommendation의 발전 과정을 잘 소개했고, BERT를 사용했다는 아이디어가 참신했기 때문에, 리뷰한다. (사실 업무 과정에서 너무 열심히 본 걸 그대로 넘기기 아쉬워서..)
Introduction
사용자의 행동으로부터 sequential dynamics를 파악하기 위해, 다양한 모델들이 제시되어 왔다. 이들은 과거 사용자-아이템 정보로부터, 이후 나타날 연속적인 아이템을 예측하고자 한다.
대부분의 모델은 이를 위해 sequential neural network를 사용한다. 과거 사용자와 상호작용이 있었던 아이템들을 벡터로 인코딩한 뒤, 그 벡터의 hidden representation을 바탕으로 추천을 하는 것이다. 그러나 sequential network를 사용하는 모델들은 태생적으로 left-to-right unidirectional model이기 때문에, 1) 사용자 행동 시퀀스로부터 나타나는 hidden representation이 제한되고, 2) 언어나 시계열 데이터처럼 일정한 순서가 있지 않은 사용자 행동 데이터에 rigid order를 가정해야 한다는 한계를 갖는다.
이에 이 논문은 NLP 분야에서 커다란 성공을 거둔 BERT에 영감을 받아, 사용자 행동 시퀀스를 bidirectional하게 모델링하기 위한 BERT4REC 모델을 제안한다. BERT의 Cloze task를 통해 입력 시퀀스(예컨대, 유저가 구매한 아이템의 순서를 나타낸 벡터)의 hidden representation을 학습한다. 그러나 이러한 학습 방식이 이후 아이템을 예측해야 한다는 Sequential Recommendation의 문제를 푸는 데에 사용될 수 없기 때문에, 예측 시에는 입력 시퀀스의 맨 마지막에 마스킹 토큰을 붙여 hidden representation을 기반으로 해당 위치에 들어와야 할 아이템 벡터를 예측하도록 한다.
BERT4REC
참고: BERT vs. BERT4REC
BERT4REC이 BERT를 적용했지만, 다음과 같은 차이점을 가지고 있다.
- BERT는 언어 임베딩을 위한 사전학습 모델이지만, BERT4REC은 학습을 바탕으로 예측까지 수행하는 end-to-end 모델이다.
- Next Sentence Prediction 학습을 하지 않으므로, Next Sentence Loss와 Segment Embedding을 사용하지 않는다.
Problem Statement
Sequential Recommendation은 특정 사용자 $u$에 대해 $n_u$개의 아이템 벡터가 주어졌을 때, $n_u+1$ 번째에 이 사용자가 상호작용할 아이템을 맞추는 문제를 풀고자 한다. 따라서, 가능한 모든 아이템에 대해 $n_u+1$번째에 등장할 확률을 계산하고자 한다. 이를 식으로 나타내면 다음과 같다.
\[p(v_{n_u+1}^{(u)}=v|\mathcal{S}_u)\]-
\(\mathcal {U}\): 사용자 집합 \(\{u_1, u_2, …, u_\mathcal {U}\}\)
-
\(\mathcal {V}\): 아이템 집합 \(\{v_1, v_2, …, v_\mathcal {V}\}\)
-
\(\mathcal {S_u}\): 사용자 $u$가 각 timestep $t$에 소비한 아이템 리스트 $[v_1^{(u)}, …, v_t^{(u)}, …, v_{n_u}^{(u)}]$
- 입력으로 사용될 시퀀스
- $n_u$는 소비한 아이템의 개수이자 시퀀스의 길이
Model Architecture
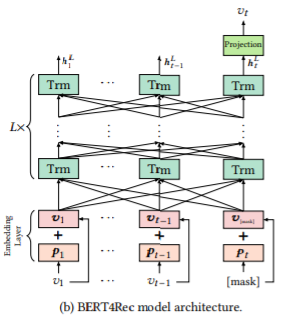
트랜스포머의 인코더 레이어를 \(L\)개 쌓은 BERT 모델 구조를 그대로 사용해 hidden representation을 학습한다.
각 레이어에서의 hidden representation \(H\)는 이전 레이어의 hidden representation을 다시 트랜스포머 네트워크에 통과시킨 것이다.
\[\mathbf{H}^l = Trm(\mathbf{H}^{l-1}),\ \forall i \in [1, ..., L] \\\]- $Trm$: 트랜스포머 레이어
- $L$: 트랜스포머 레이어의 개수
트랜스포머 레이어는 multi-head self-attention을 진행한다. 그 결과를 Position-wise Feed-Forward Network에 통과시키는데, 이 때 활성화함수로 GELU를 사용한다. 여기에 Dropout을 적용하고, residual connection으로 Layer Normalization 레이어를 거친다.
\[Trm(\mathbf{H}^{l-1}) = LN(\mathbf{A}^{l-1}+Dropout(PFFN(\mathbf{A}^{l-1}))) \\ \mathbf{A}^{l-1} = LN(\mathbf{H}^{l-1} + Dropout(MH(\mathbf{H}^{l-1})))\]- $PFFN$: Positon-wise Feed Forward Network
- \(MH\): Multi-head self-attention
첫 레이어(0번째)에서 입력 시퀀스의 아이템 $i$는 아이템 임베딩과 위치 임베딩의 합으로 표현된다.
\[h_i^0 = v_i + p_i\]마지막 레이어에서는 모든 아이템에 대한 softmax 확률값을 계산한다.
\[P(v) = softmax(GELU(h_t^LW^P+b^P)E^T+B^O)\]Model Learning
BERT의 Cloze 태스크(a.k.a. Masked Language Model)를 통해 hidden representation을 학습한다. 이 때 loss는 마스킹된 위치의 원래 아이템에 대한 negative log-likelihood 값이다. 마지막 레이어에서 마스킹된 위치의 원래 아이템에 대한 softmax 확률값이 커질수록 loss가 작아진다.
시퀀스의 마지막에 마스킹 토큰을 붙여 예측하는 만큼, 학습 도중 마지막 아이템에만 마스킹한 샘플들도 넣는다.
Experiments
Amazon Beauty, Steam, MovieLens 평점 데이터셋을 이용해 실험을 진행한다. 평점이 있다는 것은 사용자가 아이템을 소비했다는 의미이기 때문이다. 데이터셋 별로 5개 이상의 평점을 남긴 사용자와 일정 수준 이상의 평점을 받은 아이템만 남긴 후, 사용자별로 평점이 있는 아이템의 id만을 모아 timestamp에 따라 시퀀스 형태로 만들고, 길이를 일정하게 만든다.
2개의 레이어, 각 레이어별로 2개의 헤드를 갖도록 모델을 설계한다. 시퀀스의 마지막 한 개를 테스트 용으로 남기고, 학습을 위한 데이터 중에서 마지막 한 개를 검증을 위해 사용한다. 사용자가 소비하지 않은 아이템을 인기도에 따라 negative sampling한 뒤, 이를 ground truth 아이템과 함께 순위를 매기는 방식으로 성능을 측정한다. 이 때 사용한 지표는 HR, NDCG, MRR이다.
결과적으로 봤을 때, 모든 데이터셋에 대해, 모든 지표에서 SOTA이다.
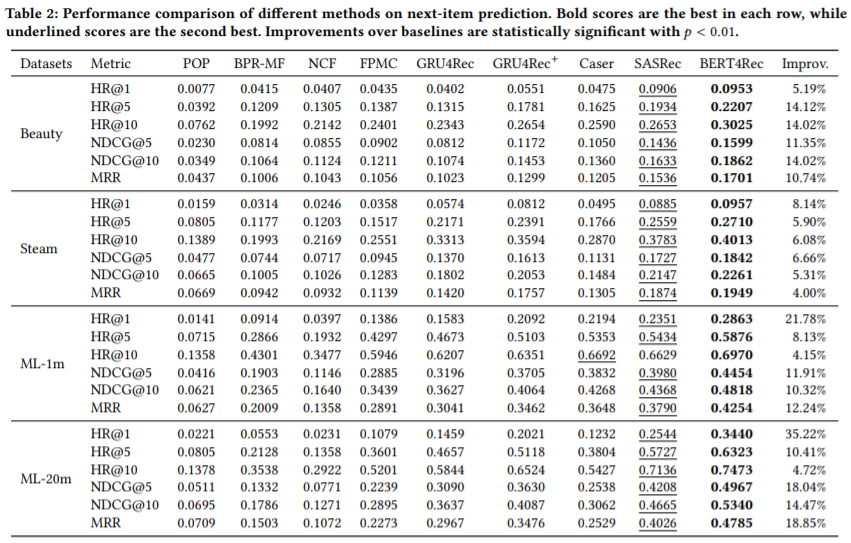
마스킹이 의미 있었는지를 알아보기 위해, BERT4REC 이전의 SOTA를 달성하던 SASRec 모델과, 1개의 마스킹만 적용했을 때의 모델을 비교했다. 그리고 1개의 마스킹을 적용했을 때와 원래 BERT4REC 모델을 비교했다. 마스킹에 따라 성능이 향상되는 것을 확인할 수 있다.
BERT를 도입한 양방향 모델이 어떻게 작동하는지 알아보기 위해, 논문에서는 아마존 Beauty 데이터셋에 대해 attention weight이 어떻게 달라지는지 시각화해 보았다.
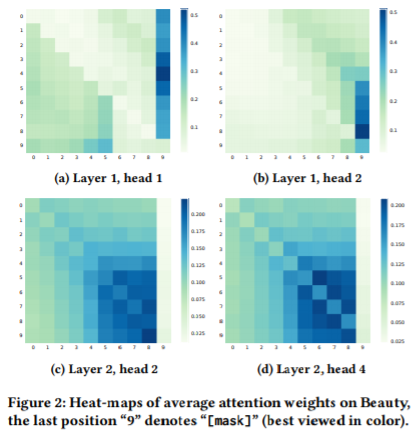
이를 통해, 다음의 결과를 얻을 수 있었다.
- 헤드별로 attention 결과가 달라진다. 모델이 마스킹을 알아맞추고자 할 때 첫 번째 레이어의 첫 번째 헤드는 왼쪽 부분을, 두 번째 헤드가 오른쪽 부분에 더 집중한다.
- 레이어별로 attention 결과가 달라진다. 두 번째 레이어는 결과 층과 직접적으로 연결되어 있어서 그런지 최신의 아이템에 더 집중한다.
Ablation Analysis를 통해 다음의 사실을 파악할 수 있다.
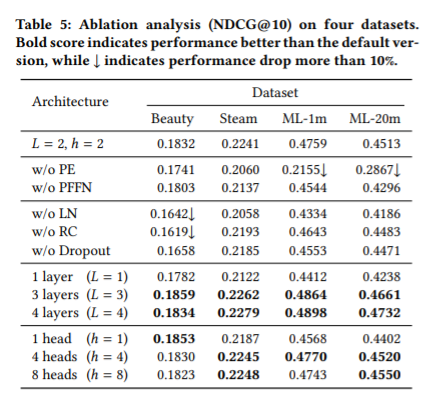
- Positional Encoding: 아이템의 위치에 대한 임베딩이 없을 때 모델 성능이 하락한다. 특히, 시퀀스의 길이가 긴 데이터셋(Movielens)일 수록 그 정도가 심했다.
- PFFN: 시퀀스의 길이가 긴 데이터셋일수록 PFFN으로 얻을 수 있는 성능 향상이 많다.
- LN, RC, Dropout: 과적합을 방지하기 위한 것인 만큼, 크기가 작은 데이터셋(아마존 Beauty)일수록 이를 없앴을 때 성능 하락이 크다.
- 레이어 수: 큰 데이터셋(Movielens)일수록 트랜스포머 레이어를 더 많이 얹을 때 그 성능이 향상되는 정도가 크다. 이를 통해 데이터가 많을 때 그 복잡한 패턴을 파악하기 위해서는 더 많은 self-attention이 필요하다는 것을 알 수 있다.
- 헤드 수: 시퀀스 길이가 길수록 헤드 수가 많을 때 도움이 된다.
그 외 hidden dimensionality, 마스킹 비율, 시퀀스 길이 등에 대한 결과도 있었다.
Conclusion and Future Work
Sequential Recommendation 모델에 처음으로 깊은 양방향 self-attention을 적용한 결과, 그것이 성능 향상에 도움이 된다는 것을 알 수 있었다. 가능한 후속 연구의 방향으로는 다음과 같은 것이 있다.
- category, price 등 다양한 item feature를 BERT4REC 모델링에 함께 사용하는 방안
- 사용자가 여러 개의 세션을 가질 때 explicit user modeling에 사용자 컴포넌트를 도입하는 방안
결론
원래 NLP에 관심이 많았던 터라, BERT를 추천시스템에서도 적용할 수 있다는 점이 굉장히 참신한 논문이었다.
그러나 실제 추천시스템 서비스에 적용했을 때에도 동일한 성능이 나올 수 있을지에 대해서 의문이 드는 부분도 있다. 만약 더 연구를 할 수 있게 된다면, 계산량이 증가하는 것이나 실시간으로 변화하는 사용자, 아이템 데이터를 가지고도 성능을 유지시킬 수 있을지에 대해서 많은 고민이 필요하리라 보인다.
공유하기
Twitter Facebook LinkedIn

댓글남기기