
[NLP] DMN_2.구현
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
DMN 구현-Question Answer
1. 모델 아키텍쳐
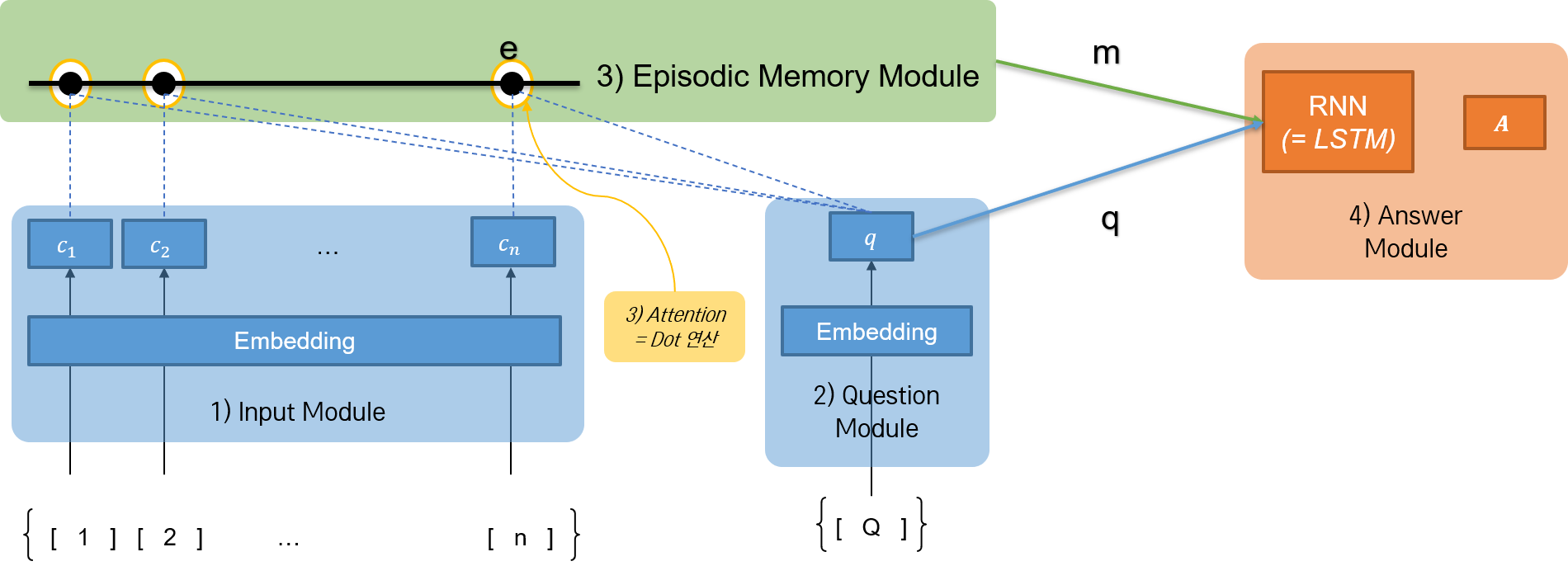
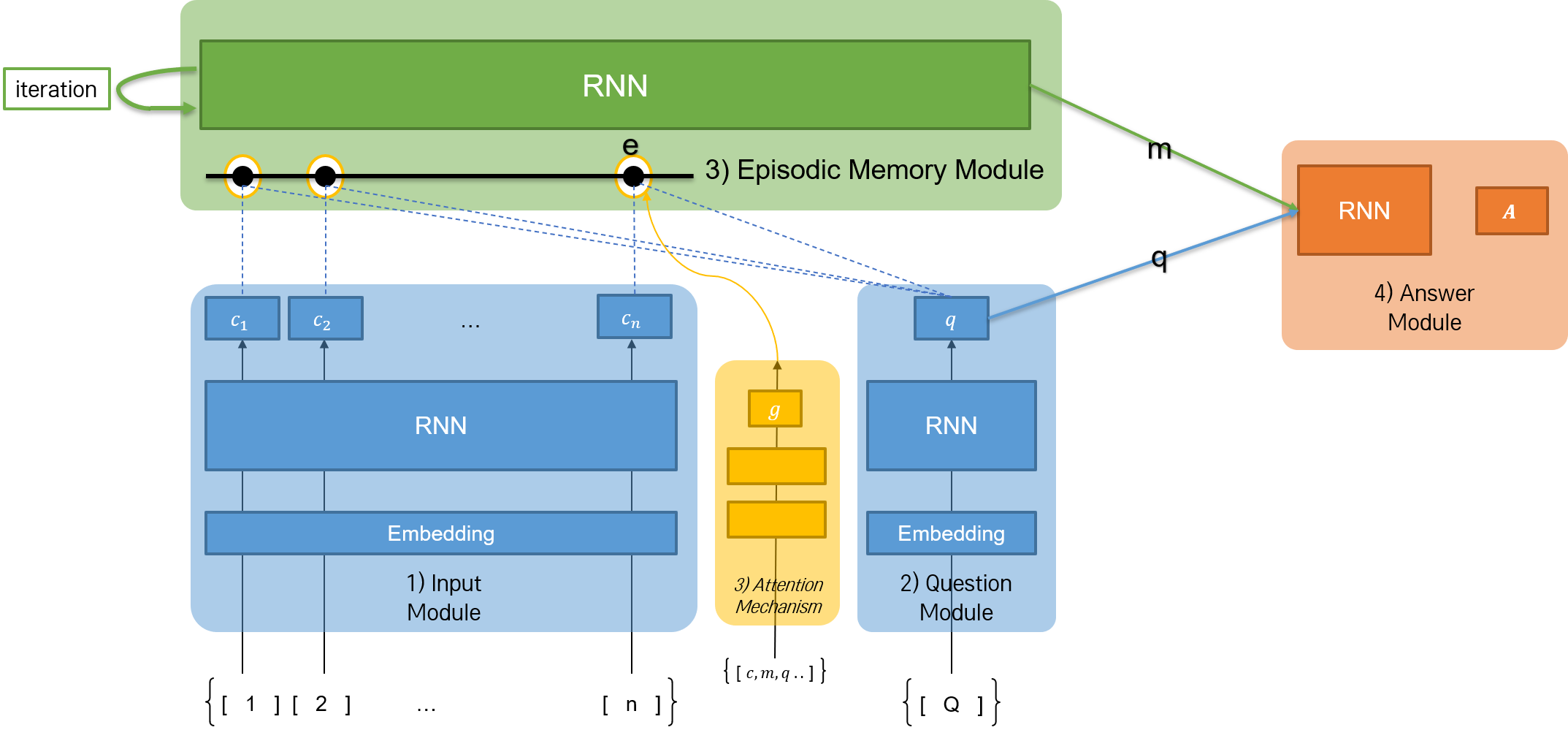
간단한 DMN 모델을 구현해 보자. 논문의 DMN 네트워크를 간소화하여, QA 태스크(데이터를 확인해 보면, 기계번역 태스크이다.)를 해결하도록 한다.
| 실습에서 구현할 네트워크 | 논문에 구현된 네트워크 |
|---|---|
 |
 |
첫째, Input Module과 Question Module에 RNN 네트워크가 존재하지 않는다. Embedding만 거친 후, Episodic Memory Module로 올라 간다.
둘째, Episodic Memory Module에서의 attention score 계산이 dot product 연산이다. 논문에서 제안한 구조는 2층 Feed Forward Network였지만, dot 연산을 수행하더라도 어느 정도 attention score를 계산할 수 있다.
셋째, Episodic Memory Module에도 RNN 네트워크가 존재하지 않는다. 또한 iteration이 일어나지 않는다.
참고
실습에 사용할 episode 구조가 매우 단순하다. 후술하겠지만, 두 개의 episode와 question, answer로 구성되어 있다. 해당 실습 코드에서는 두 개의 episode를 모두 한 개의 문장으로 입력 받고, 하나로 간주한다. 따라서 굳이 iteration을 통해 각각의 episode마다 다른 attention score를 추출해야 할 필요가 없다. 물론 간소화 목적도 있다.
같은 맥락에서, 위에서 언급하지는 않았지만 Input Module에서
<End of Sequence>토큰을 삽입하지 않는다. 사실 오른쪽 그림에서 Input Module의 그림을 더 간단하게 그렸어야 하지만, 비교를 위해 틀을 그대로 유지했다.
넷째, Answer Module에서 RNN 네트워크로서 GRU 모델이 아니라 LSTM 모델을 사용한다.
구현할 모델의 아키텍쳐를 자세히 나타내면 다음과 같다.
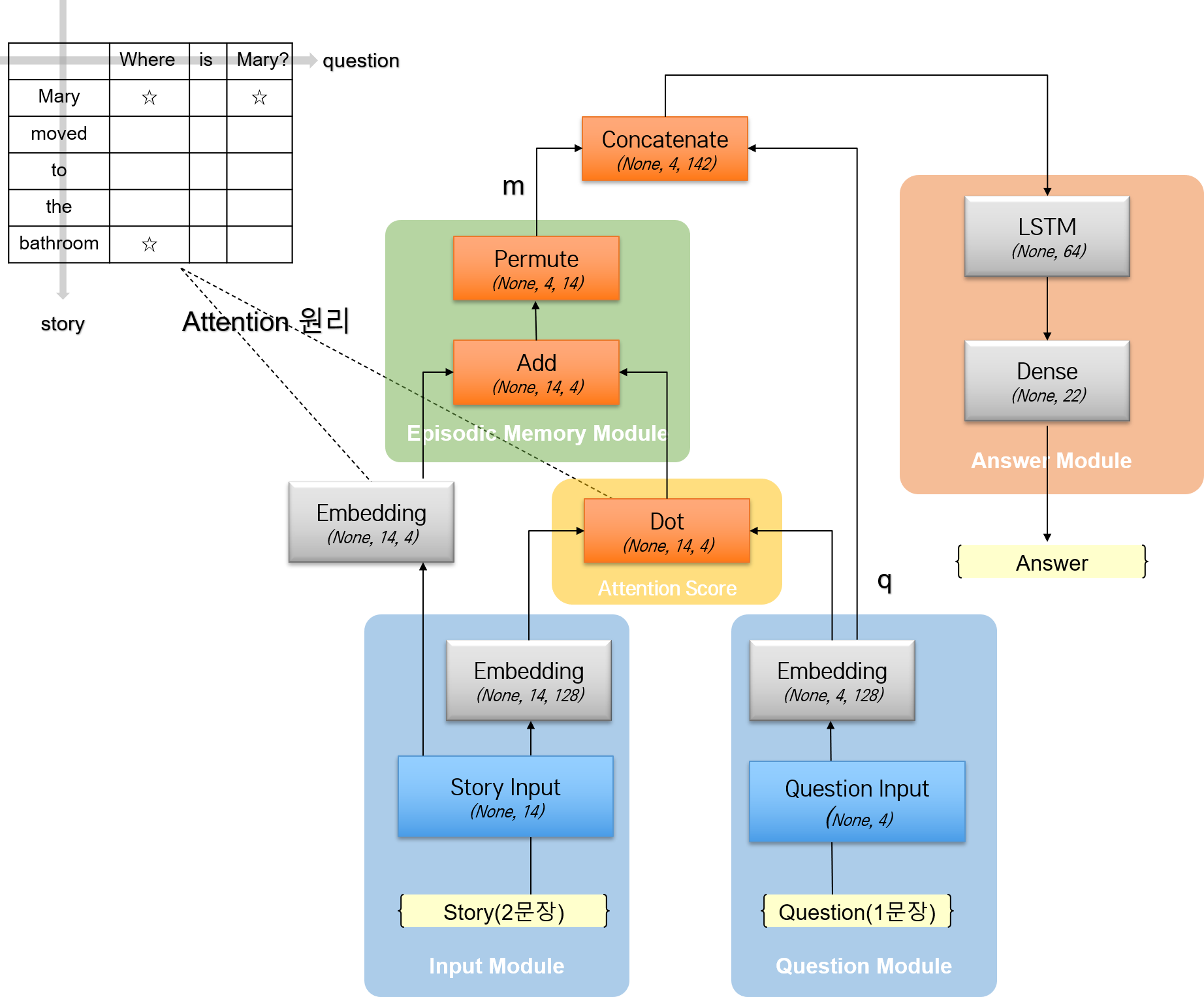
네트워크 구조를 간소화했지만, shape의 변화를 이해하기 어려워서 아키텍쳐 그림에 함께 나타냈다.
- 모델 개념에서 episode에 해당하는 story의 최장 길이는 14, question의 최장 길이는 4이다.
- Episodic Memory Module에서는
D2축이 일치하도록 dot 연산이 수행된다. - Story Input의 출력을 또 다른 Embedding 레이어를 통해 Question Input의 Embedding 공간으로 변환한다. 이후
Add연산을 통해 어디의 점수가 높은지 계산한다. 간소화된 attention mechanism이다. - Answer Module에서는 LSTM 네트워크를 사용하며, 답을 뽑아낼 때 정답 후보군이 될 수 있는 단어가
vocab_size만큼 존재한다.
2. 구현
# 모듈 불러오기
from collections import Counter
from nltk import word_tokenize
import itertools
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Input, Dense, Embedding, Dropout, LSTM
from tensorflow.kears.layers import Dot, Add, Permute, Concatenate
from tensorflow.keras.models import Model
import matplotlib.pyplot as plt
import numpy as np
import random
# 1) 데이터 로드
def get_data(inFile):
stories, question, answers = [], [], []
story_text = []
with open(inFile, 'r') as f:
for line in f:
line_no, text = line.split(sep=" ", maxsplit=1)
if '\t' in text: # 질문, 대답 문장인 경우
question, answer, _ = text.split('\t')
questions.append(question)
answers.append(answer)
stories.append(story_text)
story_text = [] # story_text 초기화
else: # 스토리 문장인 경우
story_text.append(text)
return stories, questions, answers
# 데이터 가져 오기
train_data = get_data(train_path)
test_data = get_data(test_path)
# 2) 어휘집 생성
vocab_dict = Counter()
for stories, questions, answers in [train_data, test_data]:
# story 단어 추가
for story in stories:
for sentence in story:
for word in word_tokenize(sentence):
vocab_dict[word.lower()] += 1
# question 단어 추가
for question in questions:
for word in word_tokenize(question):
vocab_dict[word.lower()] += 1
# answer 단어 추가
for answer in answers:
for word in word_tokenize(answer):
vocab_dict[word.lower()] += 1
word2idx = {w:(i+1) for i, (w, _) in enumerate(vocab_dict.most_common())}
word2idx['PAD'] = 0 # 패딩 단어 추가
idx2word = {w:i for i, w in word2idx.items()}
# 어휘집합 크기 설정
vocab_size = len(word2idx)
# 문장 최대 길이 계산
story_maxlen, question_maxlen = 0, 0
for stories, questions, answers in [train_data, test_data]:
# 스토리 문장 최대 길이 계산
for story in stories:
story_len = 0
for sent in story:
story_words = word_tokenize(sent)
story_len += len(story_words)
if story_len > story_maxlen:
story_maxlen = story_len
# question 문장 최대 길이 계산
for question in questions:
question_len = len(word_tokenize(question))
if question_len > question_maxlen:
question_maxlen = question_len
# 4) 데이터 준비
def vectorize_data(data, word2idx, story_maxlen, question_maxlen):
X_s, X_q, Y = [], [], []
stories, questions, answers = data
for story, question, answer in zip(stories, questions, answers):
xs = [[word2idx[w.lower()] for w in word_tokenize(s)] for s in story]
xs = list(itertols.chain.from_iterable(xs)) # 리스트 평활화
xq = [word2idx[w.lower()] for w in word_tokenize(question)]
a = word2idx[answer.lower()]
X_s.append(xs)
X_q.append(xq)
Y.append(a)
X_s = pad_sequences(X_s, maxlen=story_maxlen)
X_q = pad_sequences(X_q, maxlen=question_maxlen)
Y = to_categorical(Y, num_classes=len(word2idx))
return X_s, X_q, Y
# 문장 변환
X_train_s, X_train_q, y_train = vectorize_data(train_data, word2idx, story_maxlen, question_maxlen)
X_test_s, X_test_q, y_test = vectorize_data(test_data, word2idx, story_maxlen, question_maxlen)
# 모델 파라미터 설정
EMBEDDING_SIZE = int(input('임베딩 결과 차원 설정: '))
n_hidden = int(input('은닉 노드 수 설정: '))
EPOCHS = int(input('학습 에폭 수 설정: '))
BATCH = int(input('배치 사이즈 설정: '))
# 5) DMN 네트워크 구성
# 5)-1. Input Module
X_input_s = Input(shape=(story_maxlen, ))
X_encoder_s = Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_SIZE,
input_length=story_maxlen)(X_input_s)
X_encoder_s = Dropout(0.2)(X_encoder_s)
# 5)-2. Question Module
X_input_q = Input(shape=(question_maxlen, ))
X_encoder_q = Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_SIZE,
input_length=question_maxlen)(X_input_q)
X_encoder_q = Dropout(0.2)(X_encoder_q)
# 5)-3. Episodic Memory Module
X_match = Dot(axes=[2, 2])([X_encoder_s, X_encoder_q]) # D2축 일치하게 dot 연산
X_encoder_c = Embedding(input_dim=vocab_size,
output_dim=question_maxlen,
input_length=story_maxlen)(X_input_s) # story -> question: 임베딩.
X_encoder_c = Dropout(0.3)(X_encoder_c)
X_response = Add()([X_match, X_encoder_c]) # attention: 스토리 벡터와의 결합.
X_response = Permute((2, 1))(X_response)
# 5)-4. Answer Module
y_answer = Concatenate()([X_response, X_encoder_q])
y_answer = LSTM(n_hidden)(y_answer)
y_answer = Dropout(0.2)(y_answer)
y_answer = Dense(vocab_size, activation='softmax')(y_answer)
# 6) 모델 구성
model = Model([X_input_s, X_input_q], y_answer)
model.compile(optimizer='adam', loss='categorical_crossentropy')
print("======= 모델 전체 구조 ======")
print(model.summary())
# 모델 학습
hist = model.fit([X_train_s, X_train_q], [y_train],
batch_size=BATCH,
epochs=EPOCHS,
validation_data=([X_test_s, X_test_q], [y_test]))
# loss 시각화
plt.plot(hist.history['loss'], label='Train Loss')
plt.plot(hist.history['val_loss'], label='Test Loss')
plt.title('Loss Trajectory')
plt.legend()
plt.show()
# 7) 결과 확인
y_test = np.argmax(y_test, axis=1) # true label
y_pred = model.predict([X_test_s, X_test_q])
y_pred = np.argmax(y_pred, axis=1) # pred label
# 랜덤하게 예측된 라벨과 정답 확인
NUM_DISPLAY = int(input('확인할 라벨 수 설정: '))
for i in random.sample(range(X_test_s.shape[0]), NUM_DISPLAY):
story = " ".join([idx2word[x] for x in X_test_s[i].tolist() if x != 0])
question = " ".join([idx2word[x] for x in X_test_q[i].tolist()])
true_label = idx2word[y_test[i]]
pred_label = idx2word[y_pred[i]]
print(story, question)
print(f" True label: {true_label}, Pred label: {pred_label}")
print()
1) 데이터 로드
QA 문제를 구현하기 위한 원래 데이터의 형태를 보면 다음과 같다.
1 Sandra went back to the bedroom.
2 Sandra went to the garden.
3 Where is Sandra? garden 2
4 Daniel travelled to the bathroom.
5 Mary moved to the garden.
6 Where is Mary? garden 5
...
두 개의 story(=episode)가 나오고, 이 story에 해당하는 질문(=question)이 세 번째에 나온다. 질문(question)과 정답(answer)은 \t 기호로 구분되어 있고, 정답을 찾을 수 있는 힌트가 되는 문장의 번호가 또 다른 \t 이후에 나온다.
데이터를 로드하는 함수 get_data에서는 split 함수를 이용해 각 문장을 maxsplit = 1의 옵션으로 설정하여 공백 기준으로 line number와 글 내용의 두 부분으로 분리한다. 한편, 각 라인마다 \t이 있으면 question, answer가 있는 세 번째 문장이라고 판단한다.
또한, get_data 함수에 의해 데이터를 로드하면, 스토리, 질문, 답변의 세 가지로 나누어 반환하는 구조가 계속 유지되기 때문에, 앞으로 데이터를 변수에 할당할 때에도 stories, questions, answers의 묶음을 사용한다.
2) 어휘집 생성
Counter 함수와 반복문을 이용해 stories, questions, answers 안에 들어 있는 모든 단어들의 빈도를 세서 어휘집을 만든다. train, test 데이터 모두 사용한다. most_common() 메소드를 사용하면 모든 단어에 대해 각 단어와 해당 단어의 등장 빈도가 튜플 로 묶여 있는 리스트를 얻을 수 있다.
다만 어휘집 생성 시, 패딩에 사용할 단어가 없다. 따라서 이전과 동일한 방식으로 word2idx, idx2word의 두 종류의 어휘집을 생성하되, Counter 함수를 사용해 만든 vocab_dict에서 인덱스를 1씩 더한 뒤 패딩용 단어를 인덱스 0에 할당한다. 결과적으로 만들어진 어휘집 word2idx는 다음과 같다. 이 어휘집의 크기를 어휘 집합의 크기 vocab_size로 설정한다.
{'to': 1, 'the': 2, '.': 3, 'where': 4, 'is': 5, '?': 6, 'went': 7, 'john': 8, 'sandra': 9, 'mary': 10, 'daniel': 11, 'bathroom': 12, 'office': 13, 'garden': 14, 'hallway': 15, 'kitchen': 16, 'bedroom': 17, 'journeyed': 18, 'travelled': 19, 'back': 20, 'moved': 21, 'PAD': 0}
4) 훈련 데이터 준비 및 벡터화
vectorize_data 함수를 이용해 stories, questions, answers에 사용된 각 단어를 어휘집에서 찾아 인덱스로 바꿔 주고, 문장 최대 길이에 맞게 패딩한다. 한편, answers의 경우 범주형 변수로 바꾼다. stories의 경우 두 문장이 하나로 구성되어 있기 때문에, itertools.chain.from_iterable을 이용해 2차원 리스트를 평활화하는 과정을 거친다.
5) 모델 구성
모델을 구성한다. 원래 논문에서 구현한 네트워크와의 차이, 모델 아키텍쳐에 대해서는 위에서 대략 이야기했기 때문에, 어떤 레이어를 사용해 실제로 코드로 구현하는지에 초점을 맞춘다.
가장 중요한 것은 5)-3으로, attention score를 계산하는 과정이다. 앞에서도 말했듯, iteration 및 네트워크 구조 없이, 한 번만, dot 연산으로 수행된다.
Episodic Memory Module에서의 dot 연산은 케라스의 Dot 레이어를 통해 구성한다. 이 때 axes 옵션은 각 레이어에서 어떤 축을 맞춰서 연산을 수행할 것인지를 나타내는데, stories와 questions 모두 각각 128차원으로 임베딩했기 때문에, 임베딩 차원의 축인 D2 축을 기준으로 연산을 수행한다. 아키텍쳐 그림에서도 나타냈듯, 이 연산을 수행하고 난 결과로 나오는 X_match 레이어의 결과 텐서는 각 question의 답을 찾기 위해 story에서 어떤 부분에 attention을 주어야 할지를 나타낸다.
X_encoder_c 레이어에서는 stories를 questions의 길이에 맞게 임베딩한다. 그리고 결과 텐서와 X_match 레이어 결과 텐서 사이에 Add 연산을 수행함으로써 스토리 텐서와 dot 연산 후의 결과 텐서를 더한다. Permute 레이어는 축을 바꿔 주는 레이어이다. 이후 연산 과정에서 결합한 텐서와 인코딩된 questions 텐서 간 shape을 맞춰 주기 위해 진행한다고, 일단 지금은 이해하자.
정답을 찾아 내는 Answer Module에서는 Concatenate 레이어를 통해 questions와 결합한 텐서 response를 합친다. LSTM 레이어에 이를 태워 보내면, 정답을 찾을 수 있게 된다. 정답이 될 수 있는 단어는 어휘 집합 내 모든 단어이므로, 어휘 집합의 크기 만큼 Dense 레이어의 출력 노드를 설정한 뒤, softmax 활성화 함수를 사용해 출력값을 얻는다.
모델 전체 구조를 확인하면 다음과 같다.
======= 모델 전체 구조 ======
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 14)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 4)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 14, 128) 2816 input_1[0][0]
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 4, 128) 2816 input_2[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 14, 128) 0 embedding[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 4, 128) 0 embedding_1[0][0]
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 14, 4) 88 input_1[0][0]
__________________________________________________________________________________________________
dot (Dot) (None, 14, 4) 0 dropout[0][0]
dropout_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 14, 4) 0 embedding_2[0][0]
__________________________________________________________________________________________________
add (Add) (None, 14, 4) 0 dot[0][0]
dropout_2[0][0]
__________________________________________________________________________________________________
permute (Permute) (None, 4, 14) 0 add[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 4, 142) 0 permute[0][0]
dropout_1[0][0]
__________________________________________________________________________________________________
lstm (LSTM) (None, 64) 52992 concatenate[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 64) 0 lstm[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 22) 1430 dropout_3[0][0]
==================================================================================================
Total params: 60,142
Trainable params: 60,142
Non-trainable params: 0
__________________________________________________________________________________________________
None
3. 결과
학습 과정에서 loss의 변화 추이를 나타내면 다음과 같다.
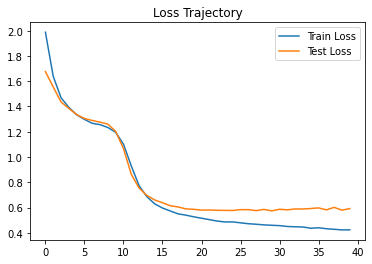
임의로 15개의 예측 데이터를 확인하면 다음과 같다.
john went back to the hallway . john moved to the office . where is john ?
True label: office, Pred label: office
john went to the hallway . mary moved to the kitchen . where is daniel ?
True label: office, Pred label: garden
john travelled to the garden . mary went back to the office . where is mary ?
True label: office, Pred label: office
daniel journeyed to the office . sandra moved to the bedroom . where is sandra ?
True label: bedroom, Pred label: bedroom
mary journeyed to the kitchen . sandra went back to the garden . where is sandra ?
True label: garden, Pred label: garden
sandra journeyed to the hallway . john went back to the garden . where is john ?
True label: garden, Pred label: garden
mary moved to the kitchen . mary went back to the bathroom . where is mary ?
True label: bathroom, Pred label: bathroom
john travelled to the kitchen . john went back to the bathroom . where is john ?
True label: bathroom, Pred label: bathroom
john went to the office . sandra went back to the bathroom . where is daniel ?
True label: garden, Pred label: bathroom
sandra went to the bathroom . john went to the bathroom . where is sandra ?
True label: bathroom, Pred label: bathroom
sandra went to the bathroom . john travelled to the bedroom . where is mary ?
True label: garden, Pred label: office
sandra travelled to the office . sandra moved to the garden . where is sandra ?
True label: garden, Pred label: garden
daniel went back to the hallway . john journeyed to the bedroom . where is sandra ?
True label: office, Pred label: kitchen
john went to the hallway . mary went to the bathroom . where is sandra ?
True label: office, Pred label: office
daniel went back to the hallway . mary went to the bathroom . where is sandra ?
True label: kitchen, Pred label: hallway
DMN 네트워크를 완벽하게 구현하지 않았음에도 불구하고, 정보가 있는 문장에서는 정답을 잘 찾아내는 것을 확인할 수 있다. 여기서 정보가 있는이라는 단서를 건 이유는, 두 번째 예시나 마지막 예시와 같이, 스토리에서 등장하지 않은 정보가 들어 있는 질문을 물어 보면 정답을 찾지 못한다는 것을 확실히 하기 위함이다. DMN, 참 똑똑한 친구다!

댓글남기기