
[NLP] Kaggle IMDB_1.논문 분석
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
IMDB 감성 분석-Kaggle 우승자 아이디어
1. 개요
그 동안 강의에서 다양한 방식으로 IMDB 감성분석을 진행했다. 로지스틱 회귀 분석, 일반적인 feed forward network, CNN, LSTM 등 다양한 방식으로 모델을 구성해 봤음에도 불구하고, 분류 정확도가 0.85 정도 수준에서 향상되지 않았다.
강의에 사용한 데이터셋의 경우, 강사님께서 참고하신 교재에서 이미 전처리를 수행한 데이터셋이었다. 역설적으로, 이미 전처리가 되어 있는 상태에서 알고리즘을 활용해 정확도를 올리려고 하는 데에는 한계가 있음을 시사한다. 이에 Kaggle IMDB 영화리뷰 감성분석 대회에서 1위를 기록한 우승자의 아이디어를 분석해 보자. 구글링을 통해 찾은 우승자의 논문을 바탕으로 한다.
2. 논문 분석
2.1. 전처리
저자가 적용한 전처리는 크게 네 단계를 거친다. 1) 데이터 정체, 2) Negation Handling, 3) 불용어 처리, 4) 상호 정보량 상위 50% 단어 선택이다.
1)단계에서는 html 태그 및 이모티콘을 포함한 모든 구둣점을 제거하고, 단어를 소문자화한다. Porter Stemming 방식을 이용해 어간을 추출한다. 3)단계에서는 NLTK 패키지를 이용해 영어 불용어를 제거했다. 여기까지는 대부분의 NLP 태스크에서 적용하는 전처리 방식이다.
2)와 4)의 단계가 신선한 아이디어였다. 먼저 2)에서는 no, not, hardly 등의 부정어와 함께 오는 단어를 [neg]+[word]와 같은 방식으로 처리했다.
4)에서는 감정과의 상호 정보량이 높은 40~50% 정도의 단어만을 선택했다. 감정을 판단하는 데 있어 중요한 역할을 담당하는 단어일수록, 감정과의 상호 정보량이 높을 것이라는 게 기본 아이디어다. 영화에 대한 각 리뷰가 나타내는 감정(label)과 어휘집 내 모든 단어 간의 상호 정보량(MI)을 계산하고, 상위 40 ~ 50%에 해당하는 단어만을 사용한다. 논문에서는 이러한 방식을 사용했을 때, 거의 모든 알고리즘에서 성능이 개선되었다고 한다. 또한, 40 ~ 50%에 해당하는 단어만을 남긴 것은 그 때 분류 성능이 가장 좋았기 때문이라고 한다. 요컨대, 감정을 판단하는 데에 도움이 되지 않는 단어들을 노이즈로 보고 제거하는 것이다.
참고 : MI 계산과 분류 성능과의 관계
One approach that we found to improve every single one of the algorithms accuracy, is to first compute the mutual information of the words with respect to the class label, and then keep only top X % of the words, where we chose X by cross validating, and we found that keeping between 40% to 50% gives the best results. This is intuitively obvious as we are basically doing feature selection and removing noisy words that do not carry sentiment.
상호 정보량 공식을 바탕으로 추정이 아니라 실제로(empirically) 상호 정보량을 계산할 수 있다는 것이 중요하다. 저자가 unigram과 bigram에 대해 각각 상호 정보량 기반의 MI score를 계산했을 때, 상위 20위까지 등장한 단어들은 다음과 같다.
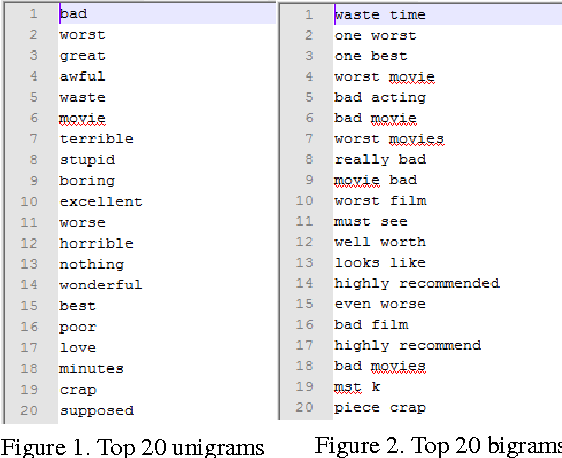
2.2. 모델링
이후 저자가 시도한 모델링은 대표적으로 다음과 같다.
- Lexicon Classifier :
VADER알고리즘과 같은 사전 기반의 감성 분석 기법, - Bayes Classifier :
Naive Bayes분류 알고리즘. - SVM Classifier + Bag-of-Words : 출현 빈도 5000 제한.
- Random Forest
- Logistic Regression
- Deep Learning
위의 여러 시도 중 가장 좋은 성능을 낸 것은 Deep Learning 모델이었다. 특히 단어 임베딩을 위해 Doc2Vec, TF-IDF 방법을 모두 사용했을 때 가장 좋은 성능이 났다고 한다.
TF-IDF 임베딩을 사용한 것은 모든 전처리 과정을 거쳤음에도 단어의 감정을 판단하는 데 필요하지 않은 단어가 남아 있기 때문이었다. 예컨대, movie와 같은 것이다. 여러 리뷰에 등장하기 때문에, 상호 정보량이 높게 계산되었을 수도 있다. 따라서 TF-IDF 방식을 이용해 이러한 단어들의 중요성을 낮춰주는 임베딩을 진행했다.
참고 : TF-IDF 임베딩을 사용한 이유
Returning to the word
movie. This made us think that we still had garbage, and we had the idea that maybe a word can be very important to be the whole set of reviews, but not to any single review by itself, and thus we needed a way of computing which words were important to which revuews.
이후 단어 간 의미를 임베딩에 반영하기 위해 Doc2Vec 방식을 사용했다. 단어와 문서 간 구조적 관계를 반영하기 위해 TF-IDF 임베딩을, 의미적 관계를 반영하기 위해 Doc2Vec 임베딩을 진행하고, 둘을 결합했을 때 성능이 좋았던 것이다. (둘 모두 NLP, 감성 분석에 잘 사용되는 방법이지만, 이를 임베딩에 결합할 생각을 한 것이 신선하다.)
3. 느낀 점, 더 생각해 볼 점
아직 구현해 보지는 않았지만, 전처리 과정에서는 아이디어가 중요하다. 특히 상호 정보량 등 수학적 아이디어가 기반이 되어야 다양한 전처리 방식을 시도해볼 수 있다. 이론을 모른다면, 구현할 수 있는 아이디어도 적어진다. 한편, 논문 전반적으로 최적의 성능을 찾기 위해 여러 전처리와 알고리즘의 결합을 계산하고, 성능을 높이기 위해 각종 파라미터를 조정한 과정에서 엄청난 시간이 들었을 것이라 생각한다. 마지막으로, 물론 저자가 딥러닝 네트워크를 사용했을 때 가장 성능이 좋기는 했지만, 로지스틱 회귀를 사용했을 때에도 그 성능이 많이 떨어지지는 않았음을 통해, 최신 알고리즘의 적용, 복잡한 네트워크 구성 등보다도 전처리 싸움이라는 생각이 들었다.
무엇보다도, 데이터 분석을 잘 하고, 좋은 결과를 얻기 위해서는 이렇게 다른 사람들의 아이디어를 보고, 그것으로부터 신선한 충격을 느껴야 할 것 같다. 논문을 보지 못했다면 어떻게 이런 아이디어를 적용했을지, 어떻게 최적의 성능을 찾아 나가는지, 어떠한 순서로 알고리즘을 적용해 나가야 되는지 등에 대해 고민해볼 기회조차 없었을 것이다. 더 열심히 보고 느낄 필요가 있다. 갈 길이 멀다. 열공하자.
공유하기
Twitter Facebook LinkedIn

댓글남기기