
[DL] Deep Reinforcement Learning for Asset Allocation in US Equities 리뷰
논문( 출처 ): Miquel Noguer i Alonso, Sonam Srivastava (2020). Deep Reinforcement Learning for Asset Allocation in US Equities
팀 세미나 발표자의 리뷰 내용을 기반으로 합니다. 출처가 명시되지 않은 모든 자료(이미지 등)는 원 논문의 것입니다.
Deep Reinforcement Learning for Asset Allocation in US Equities
자산배분에 딥러닝 강화학습을 적용한 논문이다. citation이 많이 되었다거나 (지금까지) 큰 의미가 있지는 않고, 나온 지 1개월 정도 밖에 되지 않았다. 논문에서 사용한 방법이나 결과 등이 잘 설명되어 있지는 않다. 자산배분에 심층 강화학습을 어떻게 적용할 수 있을지에 대해 rough하게 알아본다고 생각하고 리뷰한다.
1. 방법론
데이터
미국 상위 24개 회사의 주식 OHLC 데이터를 사용한다. 사용한 주식 목록은 다음과 같다.
OHLC daily bar 중 High, Low, Close를 가져 와 50일 단위의 시퀀스로 만들어 아래와 같은 텐서를 만든다.
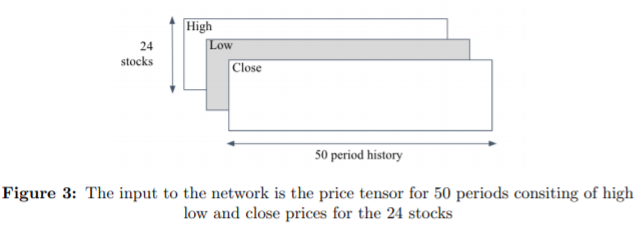
2008년 1월부터 2020년 6월까지의 데이터를 사용하며, 그 중 75%(2017년 2월까지)를 train에, 25%를 (2017년 3월부터)를 test에 사용한다. 자산배분을 위한 모델에는 위에서 만든 input 텐서 외에 현금까지 넣는다.
RL 프레임워크
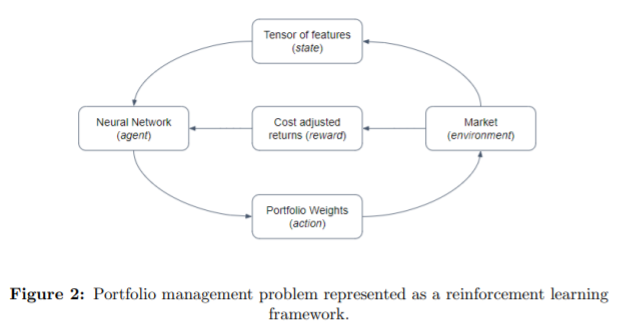
큰 아키텍쳐는 다음과 같다.
- agent: 자산배분을 하는 neural net
- state: input tensor
- action: 자산(24개 주식과 현금)간 자산 배분 weight
- reward: environment(시장 상황 snapshot)에서 자산 배분이 잘 되었는지
즉, 이 논문에서는 강화학습의 agent가 neural net이 된다. 이 주체는 자산배분을 잘 하는 NN이 되어야 한다. 이를 위해 24개 input tensor를 받은 state 에서 자산 간 weight을 뽑아 주는 action을 한다. 이 때 reward는 시장 상황에 적용해 본 뒤 자산이 잘 배분되었는지 확인하는 아래와 같은 식을 사용했다.
\(R^T = \frac {1} {T} * \Sigma_{t=0}^{T}(r_t)\)
- \(R^T\) : $T$ 시점에서의 reward
- \(V^T\) : $T$ 시점에서의 portfolio value
- \(r^T\) : $T$ 시점에서의 portfolio log return
Agent로 사용한 Neural Net은 CNN, RNN, LSTM이다. (논문 상에 소개되어 있는 구조로만 보면, 복잡한 네트워크는 아니고 simpleCNN, simpleRNN, simpleLSTM을 사용한 것 같다.)
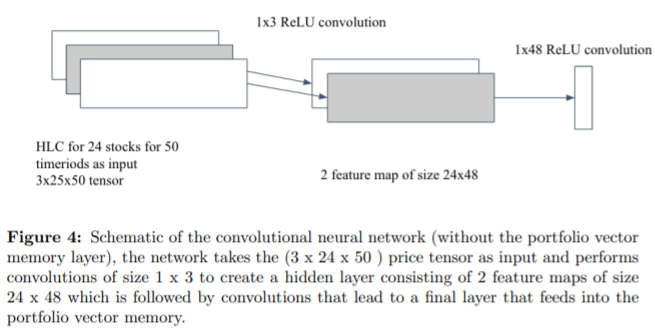
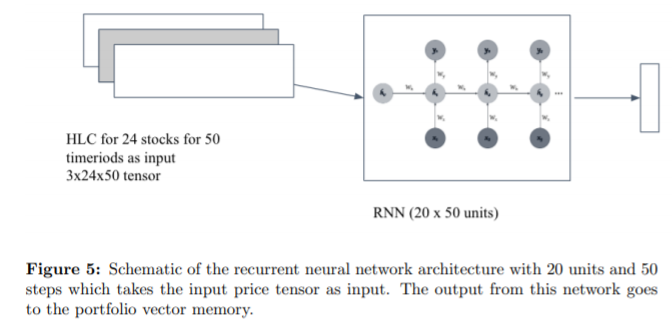
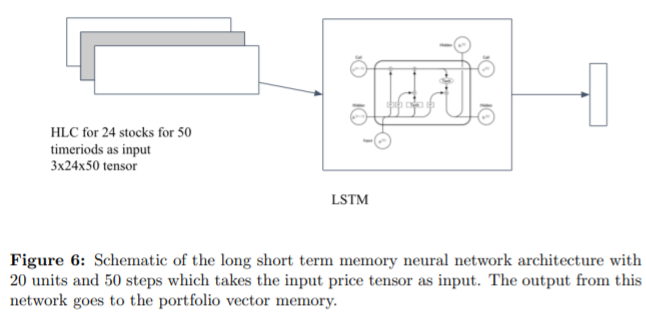
강화학습에서의 policy gradient 방식을 사용해 강화학습을 진행하였다.
2. 성능 검증
이 논문에서 Deep RL 프레임워크의 성능 검증을 위해 비교에 사용한 전통적인 자산배분 알고리즘은 다음과 같다.
- Equal Weighted Portfolio
- Markowitz Mean-Variance Optimization
- Risk Parity
- Minimum Variance
성능 검증을 위해 사용한 지표로는 다음의 것들이 있다. 다만, 각 지표를 구성할 때 무위험자산의 수익률을 무엇으로 삼았는지, 턴오버를 어떤 방식으로 적용했는지(예: 리밸런싱 주기가 어떻게 되는지 등) 등에 대한 자세한 설명은 없다.
- Total Return
- Sharpe Ratio
- MDD
- Daily Turnover
3. 결과
자산배분
각 방식을 적용했을 때 자산배분 결과는 다음과 같다.
Traditional Methods
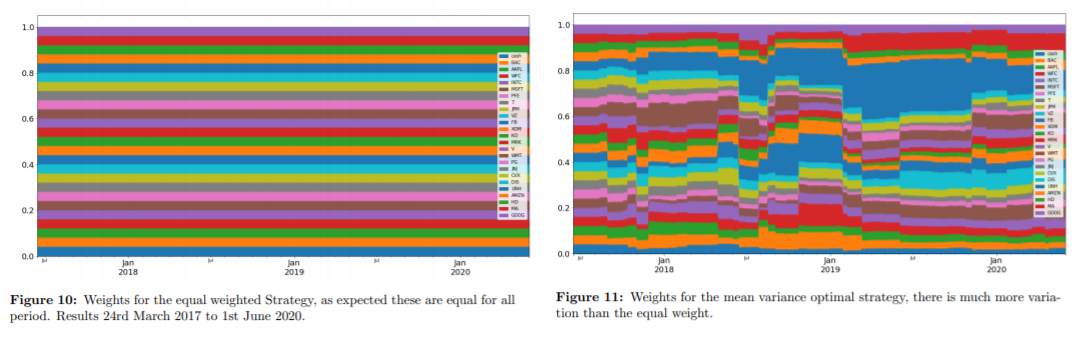
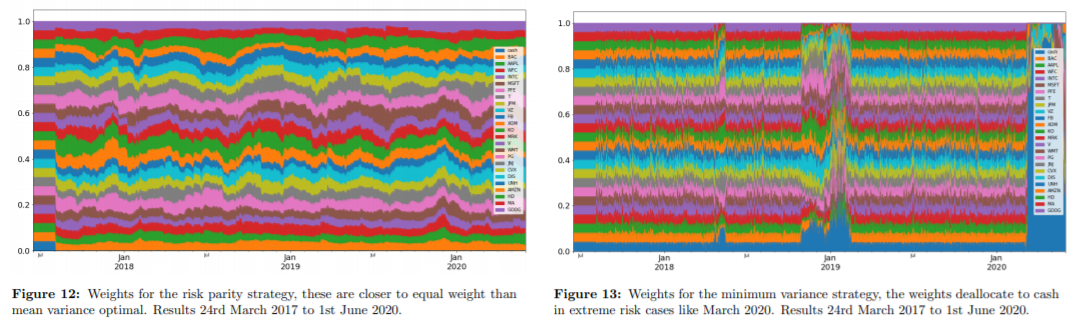
CNN
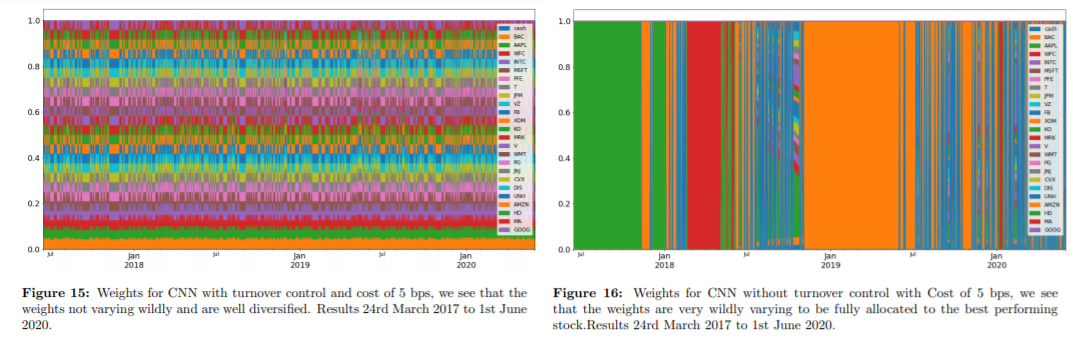
특이한 것은 CNN 알고리즘을 적용했을 때 turnover 컨트롤을 하지 않으면(Figure 16) 기간 별로 자산을 하나에만 투자하는(소위 말하는 몰빵) 결과가 나타났다는 것이다.
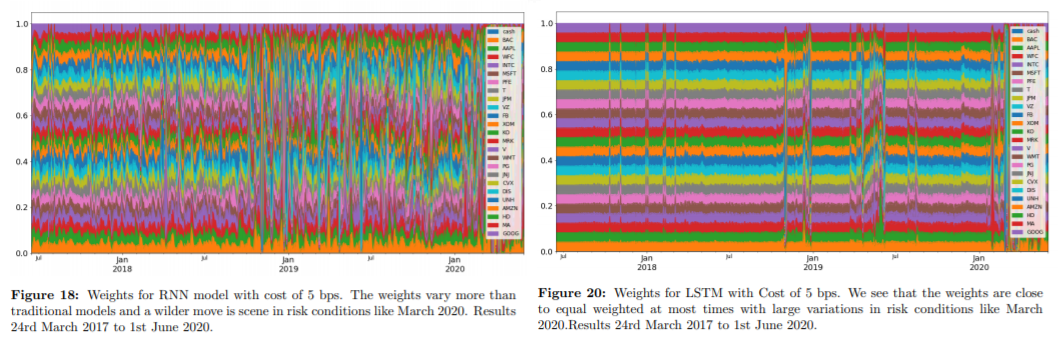
RNN, LSTM
성능 비교
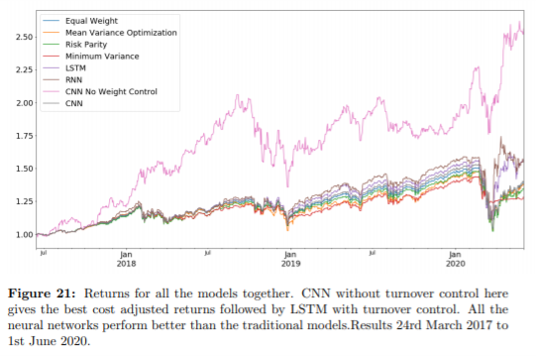
아래는 각 자산배분 알고리즘의 수익률을 나타낸 그래프이다. 내가 가진 자산을 1(=100%)로 보고, 수익률이 어느 정도 났는지를 나타냈다. 수익률을 기준으로, 전통적인 자산배분 알고리즘보다 Deep Reinforcement Learning을 적용했을 때 자산배분 결과가 더 좋았다.
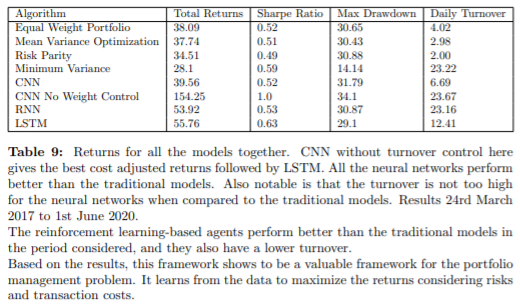
다른 성능 지표를 적용했을 때도 마찬가지로, Deep Reinforcement Learning을 사용하는 것이 더 좋았다.
4. 결론
자산배분에 어떻게 Deep Reinforcement Learning을 적용할 수 있는지, 어떻게 성능을 검증해야 하는지 등에 대해 개괄적으로 배울 수 있었다.
그러나 팀 발표자도 지적했듯 전반적으로 논문이 허술하고(혹은 일부러 결과를 상세하게 기술하지 않았거나), 방법론이 명확하지 않았다. 다만, 그만큼 구현 과정에서 더 커스텀하거나 고민해볼 부분이 많은 듯하다.
개인적으로 드는 의문은 다음과 같다.
- 전통적인 자산배분 알고리즘에는 RL을 적용할 수 없나?
- 이 논문에서만 보면 턴오버를 적용하지 않은 CNN 알고리즘에 따라 자산배분을 해야 하는데, 그게 맞을까?
- 자산 배분의 관점에서, 몰빵은 맞지 않는 듯하다.
- 거래 비용, 수수료 등이 많이 나오지 않을까?
- turnover와 관련하여 리밸런싱 주기, weight 변화에 있어 적정한 수준이 있는 것일까? 실제 필드에서는 어떻게 turnover를 적용하는가?
- total returns에서 turnover cost는 고려하지 않아도 되는가?
공유하기
Twitter Facebook LinkedIn

댓글남기기