
[DL] Hybrid_COVID 예측
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
Hybrid 네트워크 구현-과제-코로나 예측
언제적 수업이었는데, 지금에서야 다 짤 수 있었다..
머리야 조금만 더 똑똑해 줘…
CNN과 LSTM 네트워크를 결합한 Hybrid Network를 통해 시계열 데이터를 예측하는 모델을 만들어 보자. Kaggle에 올라온 코로나 데이터셋을 이용한다. 1월 23일(내 생일!!)부터 6월 30일까지의 데이터를 활용해 이후 30일 간의 데이터를 예측한다.
각 네트워크를 결합하는 방식을 달리 한다. 결합 시, 병렬 및 직렬의 두 가지 방식으로 결합해 보자.
개인적으로 과제를 수행하면서 초점을 맞춘 부분은 다음의 두 가지이다.
- 모델을 구성하는 방식에 따라 예측 결과가 어떻게 달라지는가
- 결합 네트워크를 구성할 때 데이터의 shape을 어떻게 맞춰야 하는가
정말 너무 고통 받았다
각 모델을 구성하는 경우에 있어 데이터 shape을 맞출 때, 은닉 노드 수, 모델의 파라미터 수 등을 조금씩 다르게 구성했다. 따라서 예측 결과는 동일한 조건에서 도출된 것이 아니다. 또한, 직렬 모델 구성 시 강사님께서 과제로 내 주신 LSTM-CNN외에 CNN-LSTM도 모델로 구성해 보았다.
1. 모델 아키텍쳐
각 레이어의 은닉 노드 수, 단층 혹은 복층 여부, 단방향 혹은 양방향 여부 등은 모두 자유롭게 구성한다. 그러나 다음의 두 가지만 지키자.
- LSTM과 CNN을 결합해야 하므로, LSTM latent feature를 모두 모아두기(?) 위해
return_sequences=True옵션을 준다. - CNN 모델의 경우 연습을 위해 시계열 데이터지만 2D-Convolution을 사용한다.
구현할 병렬 모델의 아키텍쳐는 다음과 같다.
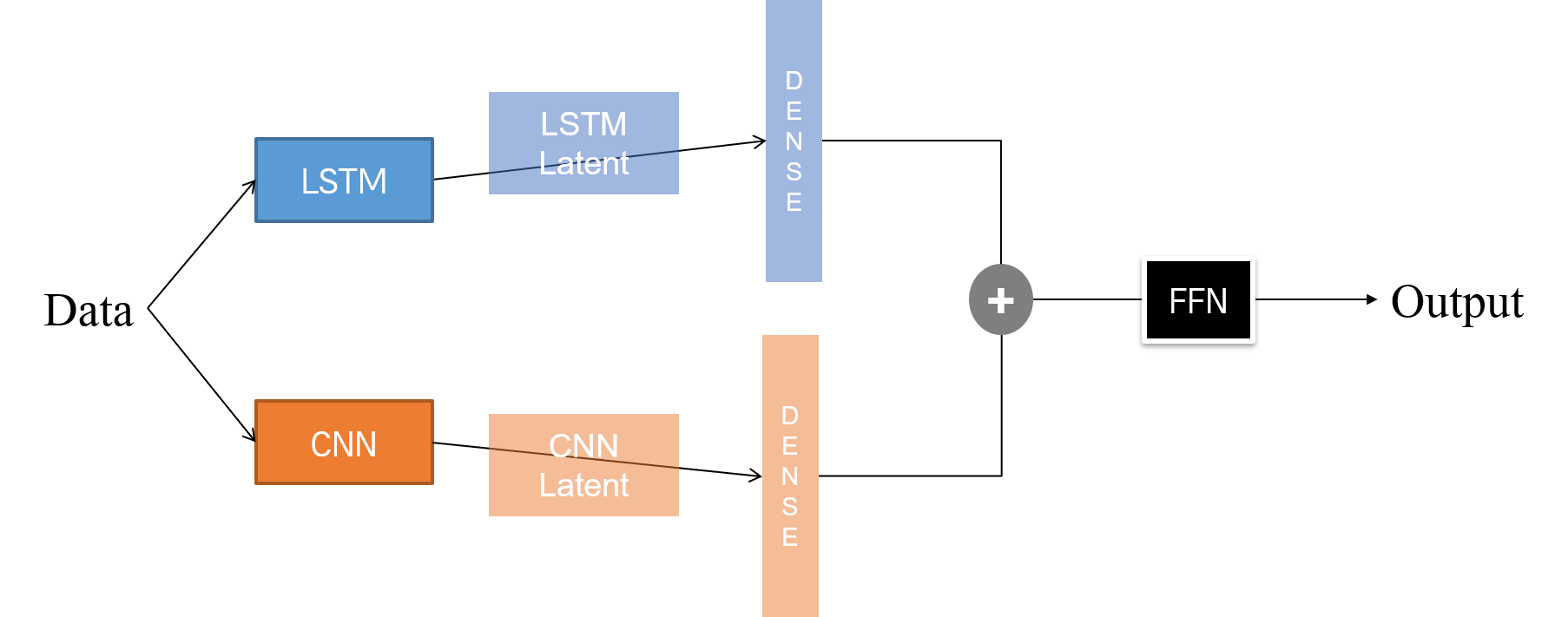
LSTM 및 CNN 모델을 통과해 나온 latent feature를 Dense Layer에 통과시킨다. 둘을 결합하여 FFN 네트워크에 통과시켜 예측값을 뽑아 낸다.
구현해야 할 직렬 모델의 아키텍쳐는 다음과 같다.

주의할 것은 LSTM 네트워크에서 many-to-many 유형으로 구현할 때, return_sequences=True 옵션을 주어야 하지만, TimeDistributed 함수를 써서는 안 된다는 것이다.
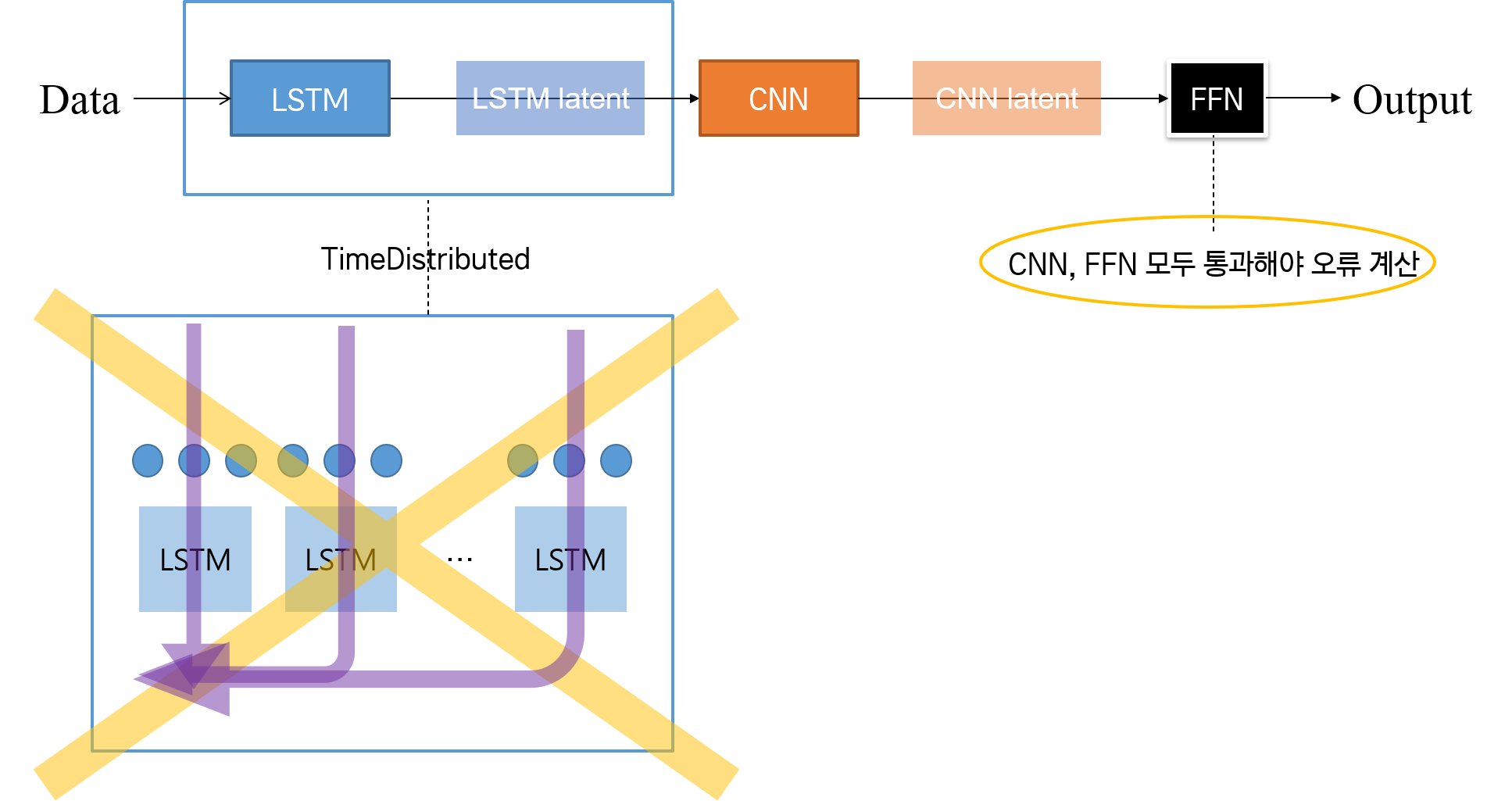
TimeDistributed 함수는 오류를 계산할 때 각 시퀀스 스텝에 모두 분배하라는 의미이다. 그러나 직렬 모델의 경우는 위의 그림에서 보듯, 모든 네트워크를 다 통과한 후, 그 때 오류를 계산하여 모든 네트워크에 전부 오류를 역전파해주어야 한다. LSTM 네트워크 단계에서 TimeDistributed를 적용하면, 해당 단계에서만 오류를 계산하고, 해당 네트워크에서 CNN으로 넘어가기 전에 오류를 역전파하라는 의미가 된다.
한편, 추가적으로 CNN 네트워크를 먼저 구성한 작업에서 모델 아키텍쳐는 위의 직렬 아키텍쳐를 나타낸 그림에서 네트워크 위치를 바꾸면 된다.
2. 풀이
사용한 모듈은 다음과 같다.
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.layers import LSTM, Bidirectional # LSTM
from tensorflow.keras.layers import Conv2D, MaxPooling2D # CNN
from tensorflow.keras.layers import Input, Dense, Flatten, Concatenate, Reshape # 모델 네트워크 구성
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
2.1. 데이터 전처리
데이터 형태에 예측에 적합한 형태로 전처리한다. 사용할 훈련 데이터를 2차원 array 형태로 만든다.
df_raw = df_raw.groupby(by='ObservationDate').sum() # 날짜별로 각 수치 그룹핑
df_raw = (df_raw - df_raw.shift(1)).drop(columns=['SNo'], axis=1).dropna()
# 날짜별 누적합 해체, 인덱스 열 삭제, 결측치(1개) 제거.
# 표준화
scaler = StandardScaler()
train_data = scaler.fit_transform(df_raw)
print(train_data.shape) # (160, 3)
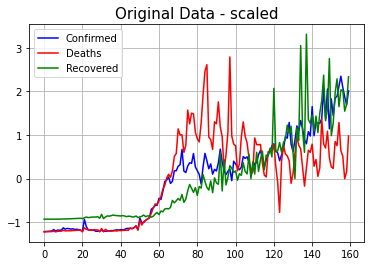
# 데이터 시각화하여 확인
plt.plot(train_data[:, 0], label='Confirmed', color='blue')
plt.plot(train_data[:, 1], label='Deaths', color='red')
plt.plot(train_data[:, 2], label='Recovered', color='green')
plt.title('Original Data - scaled', size=15)
plt.legend()
plt.grid()
plt.show()
표준화한 데이터를 이용해 기존 데이터의 추세선을 그려 보면 다음과 같다.
- Confirmed : 확진자 수
- Deaths : 사망자 수
- Recovered : 완치자 수
2.2. 병렬 모델
# 시계열 데이터(3차원) 생성
def createData(X_data, step, feature):
m = np.arange(len(X_data)-step)
x, y = [], []
for i in m:
a, b = X_data[i:i+step], X_data[i+step] # a 다음에 나오는 데이터: b
x.append(a)
y.append(b)
X = np.array(x).reshape(len(m), step, feature)
y= np.array(y).reshape(len(m), feature)
return X, Y
# 시계열 데이터 파라미터 설정
n_step = int(input('시계열 스텝 설정: ')) # 30
n_features = int(input('피쳐 수 설정: ')) # train_data.shape[1]
# 훈련 데이터 생성
X_train, y_train = createData(train_data, n_step, n_features)
X_train_lstm = np.copy(X_train)
X_train_cnn = X_train_lstm[:, :, :, np.newaxis] # 채널 축 추가
# 1) LSTM 모델 네트워크 구성
X_input_lstm = Input(batch_shape=(None, n_step, n_features))
X_lstm = Bidirctional(LSTM(128, return_sequences=True), merge_mode='concat')(X_input_lstm)
X_lstm = Flatten()(X_lstm)
X_dense_lstm = Dense(64)(X_lstm)
# CNN 모델 파라미터 설정
n_channel = X_train_cnn.shape[3] # 추가한 채널 축
# 2) CNN 모델 네트워크 구성
X_input_cnn = Input(batch_shape=(None, n_step, n_features, n_channel))
X_conv = Conv2D(filters=30, kernel_size=(4, 4), strides=1, padding='same', activation='relu')(X_input_cnn)
X_pool = MaxPooling2D(pool_size=(2,2), strides=1, padding='valid')(X_conv)
X_flat = Flatten()(X_flat)
X_dense_cnn = Dense(64)(X_flat)
# 3) 병렬 모델 구성
X_concat = Concatenate()([X_dense_lstm, X_dense_cnn])
y_output = Dense(n_features, activation='linear')(X_concat)
model_parallel = Model([X_input_lstm, X_input_cnn], y_output)
model_parallel.compile(loss='mse', optimizer=Adam(learning_rate=0.001))
print(f"========= (병렬) 전체 모델 구조 확인 =========")
print(model_parallel.summary())
# 4) 모델 학습
EPOCHS = int(input('학습 횟수 설정: '))
BATCH = int(input('배치 사이즈 설정: '))
es = EarlyStopping(monitor='loss', patience=10, verbose=1)
hist = model_parallel.fit([X_train_lstm, X_train_cnn], y_train,
batch_size=BATCH,
epochs=EPOCHS,
callbacks=[es])
# loss 시각화
plt.plot(hist.history['loss'], label='Train Loss')
plt.title('Loss Function: Parallel Model', size=18)
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()
# 5) 예측
n_futures = int(input('예측 기간 설정: '))
X_test = np.copy(train_data)
X_estimates = [X_test[-1]] # 예측값 저장할 배열
for _ in range(n_futures):
x_lstm = X_test[-n_step:].reshape(-1, n_step, n_features)
x_cnn = x_lstm[:, :, :, np.newaxis] # 채널 축 추가
y_pred = model_parallel.predict([x_lstm, x_cnn])[0] # 예측 데이터 형태 주의
X_estimates.append(y_pred) # 예측값 배열에 저장
X_test = np.insert(X_test, len(X_test), y_pred, axis=0) # 이렇게 해야 예측 제대로 됨.
# 예측 결과 시각화
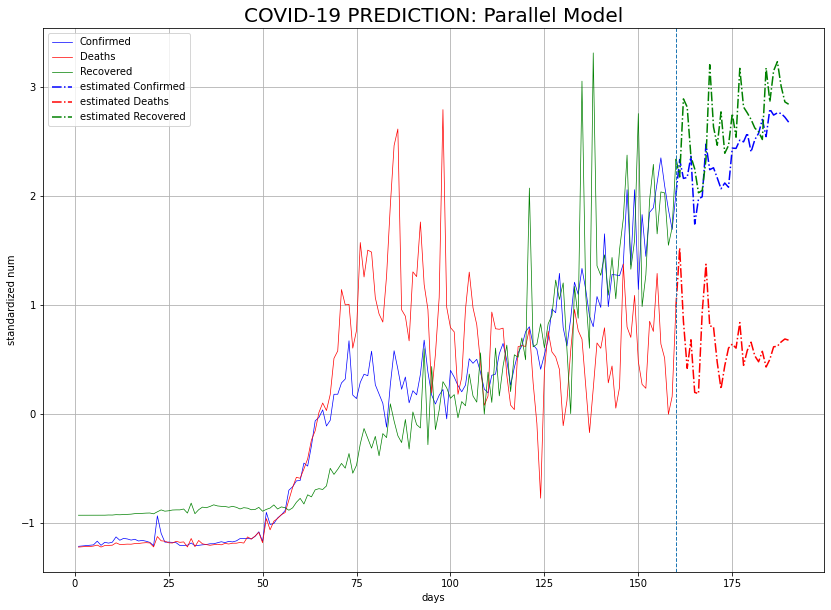
last_data = X_test[:len(train_data)]
estimated_data = np.array(X_estimates)
ax1 = np.arange(1, len(train_data)+1)
ax2 = np.arange(len(train_data), len(last_data)+len(estimated_data))
plt.figure(figsize=(14, 10))
plt.plot(ax1, last_data[:, 0], label='Confirmed', linewidth=0.7, color='blue')
plt.plot(ax1, last_data[:, 1], label='Deaths', linewidth=0.7, color='red')
plt.plot(ax1, last_data[:, 2], label='Recovered', linewidth=0.7, color='green')
plt.plot(ax2, estimated_data[:, 0], label='estimated Confirmed', linestyle='dashdot', color='blue')
plt.plot(ax2, estimated_data[:, 1], label='estimated Deaths', linestyle='dashdot', color='red')
plt.plot(ax2, estimated_data[:, 2], label='estimated Recovered', linestyle='dashdot', color='green')
plt.axvline(ax1[-1], linestyle='dashed', linewidth=1)
plt.grid()
plt.legend()
plt.xlabel('days')
plt.ylabel('standardized num')
plt.title('COVID-19 PREDICTION: Parallel Model', size=20)
plt.show()
1), 2) 각 모델 네트워크 구성
return_sequences=True 옵션을 주었기 때문에, 양방향 LSTM 모델을 통과한 결과는 3차원 텐서이다다. 평활화하여 2차원으로 만들어 준다. CNN 네트워크의 경우, 2D-Convolution 네트워크이기 때문에, 훈련 데이터에 채널 축을 1로 설정하여 추가해 주었다. LSTM의 은닉 노드 수, 컨볼루션 필터 및 풀링 레이어 커널의 수는 임의로 지정했다. Latent Feature를 뽑아내기 위한 Dense 레이어의 노드 수 역시 임의로 지정했다.
3) 결합 모델 구성
Concatenate를 활용해 직전 단계에서 Dense 레이어를 통과한 두 네트워크의 latent feature를 결합한다. 시계열 데이터를 예측하는 문제이기 때문에, 출력층의 활성화 함수로 linear를 사용한다. 따라서4)단계에서 학습 시 loss는 MSE로 측정한다.
이렇게 구성한 병렬 모델의 전체 구조를 확인하면 아래와 같다.
========= (병렬) 전체 모델 구조 확인 =========
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 20, 3, 1)] 0
__________________________________________________________________________________________________
input_1 (InputLayer) [(None, 20, 3)] 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 20, 3, 30) 510 input_2[0][0]
__________________________________________________________________________________________________
bidirectional (Bidirectional) (None, 20, 256) 135168 input_1[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 19, 2, 30) 0 conv2d[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 5120) 0 bidirectional[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 1140) 0 max_pooling2d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 64) 327744 flatten[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 64) 73024 flatten_1[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 128) 0 dense[0][0]
dense_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 3) 387 concatenate[0][0]
==================================================================================================
Total params: 536,833
Trainable params: 536,833
Non-trainable params: 0
__________________________________________________________________________________________________
None
4), 5) 학습 및 예측
모델 구성 시 두 네트워크를 결합하기 때문에, 학습할 때 LSTM 네트워크용, CNN 네트워크용 데이터를 각각 입력해 주어야 한다. early stopping patience를 10으로 줬더니 399번째 에폭에서 학습이 종료되었다.
예측할 때도, 역시 모델 입력 형태에 맞게 구성해 주어야 한다. 예측한 값을 테스트 데이터 배열에 저장할 때 np.insert에서 axis=0으로 설정해주어야 함에 주의하자.
시행착오
처음에 shape만 맞춰주면 되겠지 하는 생각으로 아래와 같이 설정했는데, 예측값이 30일 내내 똑같았다. 배열 업데이트가 되지 않는 것 같은데, 그 이유를 뜯어 보지는 못했다. 나중에 다시 연구해볼 것!
X_test = np.insert(X_test, len(X_test), y_pred).reshape(-1, n_features) # 제대로 예측되지 않음. X_test = np.insert(X_test, len(X_test), y_pred, axis=0) # 이렇게 해야 예측 제대로 됨.
2.3. 직렬 모델
아무리 강조해도 지나치지 않을 shape의 중요성 (Hㅏ…)
2.2에서 병렬 모델을 구성할 때, shape을 맞출 필요가 없다는 것이 얼마나 감사한 일인지 깨달았다. 위에서는 그냥 Concatenate만 하면 되기 때문에, shape을 크게 고민하지 않아도 되었다. 그러나 직렬 모델의 경우 이전 네트워크를 통과한 latent feature의 shape을 맞추어 다음 네트워크에 통과시켜야 한다. Reshape 레이어를 사용해 텐서의 shape을 바꾸려고 했는데, 과장 없이, 진짜로 아래와 같은 에러를 20번은 만난 것 같다.
InvalidArgumentError: Input to reshape is a tensor with 35840 values, but the requested shape has 8400 [[node model_6/reshape_12/Reshape (defined at <ipython-input-132-a76351a6c48a>:6) ]] [Op:__inference_train_function_43525] Function call stack: train_function
처음에는 노드 수 바꿔 가면서 어떻게든 나중에는 맞겠지 생각했다. 그런데 LSTM을 먼저 놓고 CNN을 통과시키든, CNN을 먼저 놓고 LSTM을 통과시키든 에러 메시지의 뒷 부분이 but the requested shape has 8400으로 동일한 것을 발견했다.
뜯어 보다 보니, 위에서 생성한 시계열 3차원 데이터 셋이 (140, 20, 3)의 shape을 갖고 있었고, 이 데이터 안에 있는 모든 value 개수가 8400(=140 x 20 x 3)이다. 따라서 직렬 모델에서 나처럼 Reshape 레이어를 사용해 shape을 맞춰 주려면, 직전 네트워크를 통과한 모든 value 개수가 8400이 되면 된다.
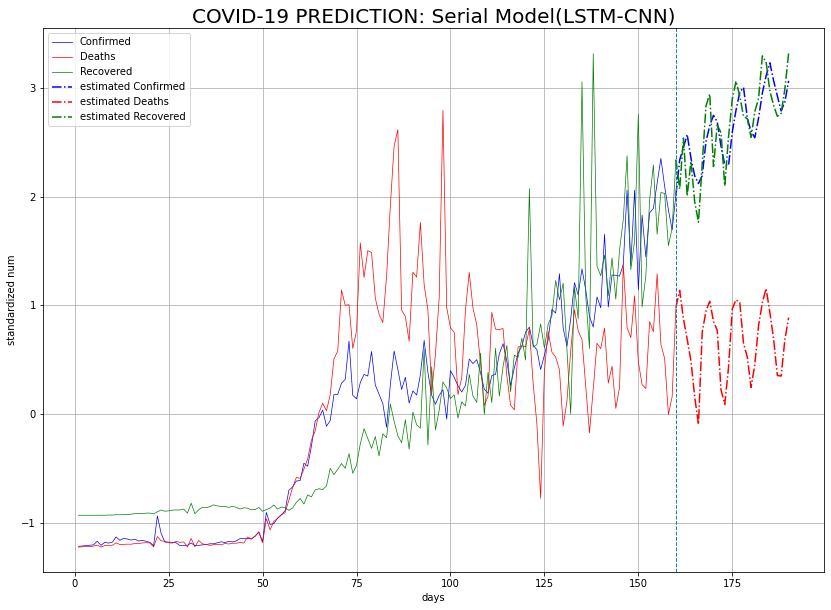
예측 단계에서 데이터를 concat 형태로 바꿔줄 필요가 없다는 것만 제외하면, 다른 과정은 모두 2.2에서와 동일하다. shape을 맞춰주기 위해 커널 사이즈나 Dense 레이어 추가 등을 진행했기 때문에, 어떻게 모델을 구성했는지만 정리한다.
LSTM-CNN
LSTM 네트워크를 통과시킨 후, 평활화한 2차원 텐서를 Dense 레이어에 통과시켰다. 노드 수를 n_step * n_features로 지정해서 60으로 맞춰 주었다.
# 모델 네트워크 구성
X_input_s = Input(batch_shape=(None, n_step, n_features))
X_lstm_s = Bidirectional(LSTM(30, return_sequences=True), merge_mode='concat')(X_input_s) # 1200
X_lstm_s = Flatten()(X_lstm_s)
X_lstm_s = Dense(n_step * n_features)(X_lstm_s)
X_reshape_s = Reshape((n_step, n_features, 1))(X_lstm_s)
X_conv_s = Conv2D(filters=30, kernel_size=(k_size, k_size), strides=1, padding='same', activation='relu')(X_reshape_s)
X_pool_s = MaxPooling2D(pool_size=(p_size, p_size), strides=1, padding='valid')(X_conv_s)
X_flat_s = Flatten()(X_pool_s)
X_dense_s = Dense(64)(X_flat_s)
y_output_s = Dense(n_features, activation='linear')(X_dense_s)
# 모델 구성
model_serial = Model(X_input_s, y_output_s)
print(f"========= (직렬 1) 전체 모델 구조 확인 =========")
print(model_serial.summary())
# 모델 컴파일
model_serial.compile(loss='mse', optimizer=Adam(learning_rate=0.001))
전체 모델 구조를 확인하면 다음과 같다.
========= (직렬 1) 전체 모델 구조 확인 =========
Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 20, 3)] 0
_________________________________________________________________
bidirectional_2 (Bidirection (None, 20, 60) 8160
_________________________________________________________________
flatten_3 (Flatten) (None, 1200) 0
_________________________________________________________________
dense_5 (Dense) (None, 60) 72060
_________________________________________________________________
reshape_1 (Reshape) (None, 20, 3, 1) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 20, 3, 30) 510
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 19, 2, 30) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 1140) 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 73024
_________________________________________________________________
dense_7 (Dense) (None, 3) 195
=================================================================
Total params: 153,949
Trainable params: 153,949
Non-trainable params: 0
_________________________________________________________________
None
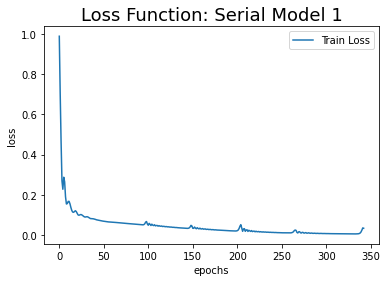
학습은 병렬 모델과 동일한 조건에서 진행했는데, 343번째 에폭에서 조기 종료되었다.
CNN-LSTM
Conv2D 레이어, MaxPooling2D 레이어 stride, padding 옵션 조절하며 Pooling 레이어를 통과했을 때 value 개수가 60이 되도록 했다.
# 모델 네트워크 구성
X_input_s2 = Input(batch_shape=(None, n_step, n_features, n_channel)) # 채널 축 추가: (None, 20, 3, 1) = 8400개.
X_conv_s2 = Conv2D(filters=30, kernel_size=(10, 1), strides=2, padding='valid', activation='relu')(X_input_s2)
X_pool_s2 = MaxPooling2D(pool_size=(3, 1), strides=2, padding='valid')(X_conv_s2)
X_flat_s2 = Flatten()(X_pool_s2)
X_reshape_s2 = Reshape((n_step, n_features))(X_flat_s2) # (None, 20, 3): LSTM 입력 형태 = 8400개로 맞춰져야 함.
X_lstm_s2 = Bidirectional(LSTM(30, return_sequences=True), merge_mode='concat')(X_reshape_s2)
X_lstm_s2 = Flatten()(X_lstm_s2)
X_dense_s2 = Dense(64)(X_lstm_s2)
y_output_s2 = Dense(n_features, activation='linear')(X_dense_s2)
# 모델 구성
model_serial2 = Model(X_input_s2, y_output_s2)
print(f"========= (직렬 2) 전체 모델 구조 확인 =========")
print(model_serial2.summary())
# 모델 컴파일
model_serial2.compile(loss='mse', optimizer=Adam(learning_rate=0.001))
모델 전체 구조를 확인하면 다음과 같다.
========= (직렬 2) 전체 모델 구조 확인 =========
Model: "model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 20, 3, 1)] 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 6, 2, 30) 330
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 2, 1, 30) 0
_________________________________________________________________
flatten_5 (Flatten) (None, 60) 0
_________________________________________________________________
reshape_2 (Reshape) (None, 20, 3) 0
_________________________________________________________________
bidirectional_3 (Bidirection (None, 20, 60) 8160
_________________________________________________________________
flatten_6 (Flatten) (None, 1200) 0
_________________________________________________________________
dense_8 (Dense) (None, 64) 76864
_________________________________________________________________
dense_9 (Dense) (None, 3) 195
=================================================================
Total params: 85,549
Trainable params: 85,549
Non-trainable params: 0
_________________________________________________________________
None
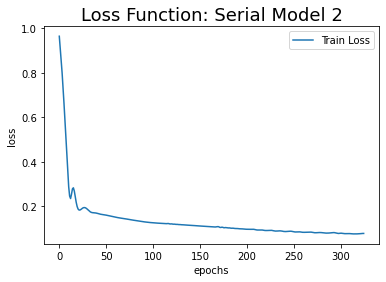
CNN 네트워크를 통과한 후, 특성이 축소된 상태에서 LSTM 네트워크를 통과해서 그런지 params 개수가 줄어 들었다. 그래서 그런지 loss값이 세 모델 중 가장 큰 상태에서 조기 종료되었고, 조기 종료되는 에폭 역시 325로 가장 작았다. 이것이 예측에 영향을 미칠지 모르겠지만, 일단 지금 단계에서는 shape 맞추기에 집중하고, 모델 성능 자체는 크게 고민하지 않기로 한다.
3. 결과
모든 모델의 loss 변화 추이와 예측값의 추이를 시각화한 결과는 다음과 같다.
| loss | prediction | |
|---|---|---|
| 병렬 | 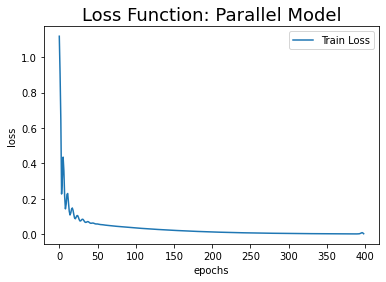 |
 |
| 직렬 (LSTM-CNN) |
 |
 |
| 직렬 (CNN-LSTM) |
 |
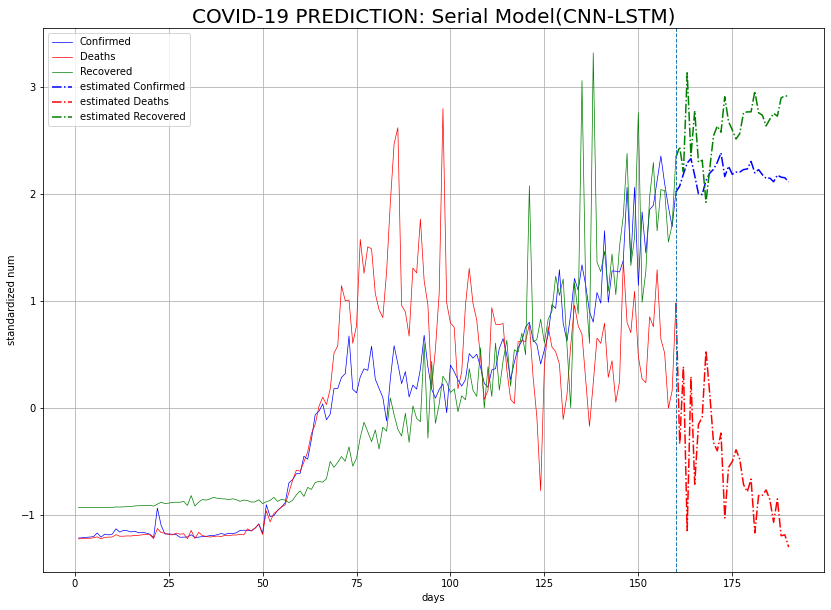 |
병렬 모델과 첫 번째 직렬 모델의 경우가 어느 정도 비슷한 추이로 간다. 두 번째 직렬 모델의 경우가 다른 두 모델과 한 눈에 봐도 추이가 다르다. 확진자 및 완치자 수의 그래프가 같이 가지도 않고, 혼자서 사망자 수가 줄어들 것이라 예측했다.
시계열 예측은 어려운 문제인 듯하다. 물론 모델 성능 조정은 1도 하지 않았지만 나중에 코로나 추이 더 보면서 어떤 식으로 예측하는 것이 옳았는지 회고해 보자.
공유하기
Twitter Facebook LinkedIn

댓글남기기