
[ML] KNN_1.개념
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다.
KNN 알고리즘
1. 개념
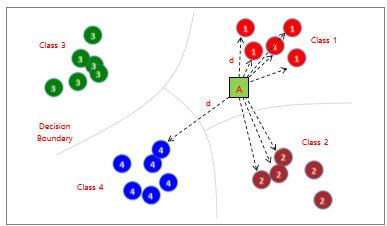
새로운 데이터가 들어왔을 때, 기존의 모든 점들과의 거리를 전부 계산한 후, 가장 가까운 K개의 점들을 기준으로 분류한다. 해당 K개의 점들 중 가장 많은 점이 속해 있는 클래스가 새로운 데이터의 클래스가 된다.
다른 알고리즘과 달리, 학습이라고 할 만한 절차가 별로 없다. 새로운 데이터가 들어왔을 때, 기존 데이터 간의 거리를 재서 이웃을 뽑기 때문이다. 알고리즘적으로 하는 일이 크게 없어서 lazy algorithm이라고도 한다. 미리 학습해 두는 방식이 아니라, 새로 시험 데이터를 추정할 때마다 학습하는 방식이기 때문에 시간이 오래 걸린다.
2. 거리 계산 방식

- 맨하탄 거리 : 같은 성분끼리의 거리.
- 유클리드 거리 : 두 점 사이의 기하학적인 최소 거리.
- 민코프스키 거리 : 맨하탄 거리와 유클리드 거리의 일반화. m제곱한 후 m제곱근을 씌워주는 거리. 두 성분 중 더 크게 떨어진 성분으로 수렴하게 된다. 많이 떨어진 특성을 부각시킬 때 사용한다.
어떤 게 더 좋은 거리 계산 방식인지는 모른다. 각각의 특징이 있기 때문에 모두 다르다.
3. 차원의 저주
KNN 알고리즘은 ‘차원의 저주’에 취약한 알고리즘이다. ‘차원의 저주’란, 차원이 증가할수록 학습 데이터의 수가 차원의 수보다 적어져 알고리즘의 성능이 저하되는 것을 의미한다.
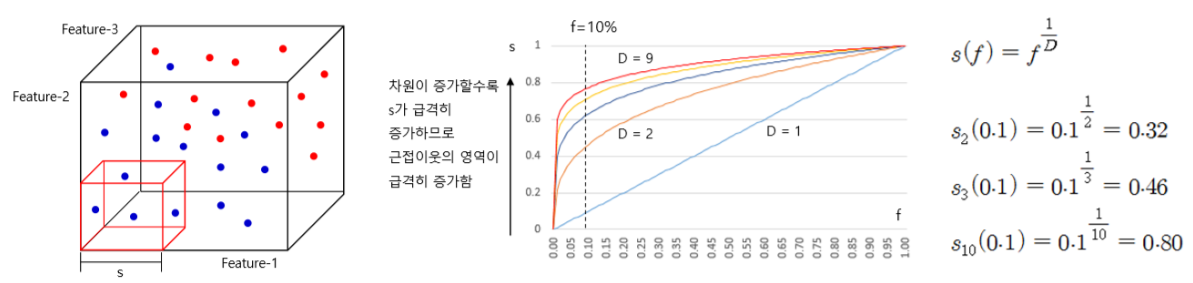
KNN 알고리즘의 경우, 차원이 증가할수록 더 멀리 떨어진 훈련 데이터를 참고해야 하기 때문에, ‘근접 이웃’을 활용하는 알고리즘임에도 불구하고 ‘가까이 있는’ 이웃이 아니라 ‘멀리 있는’ 이웃을 참조하게 되는 모순이 발생한다. 차원의 저주에 취약하다는 문제점을 항상 생각해야 한다.
공유하기
Twitter Facebook LinkedIn

댓글남기기