
[NLP] Transformer_1.모델 구조
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. 논문 출처
Transformer 이해하기_모델 아키텍쳐
1. 개요
구글에서 개발한 Transformer는, Attention 메커니즘만 이용해 기계 번역을 수행하는 모델이다. Seq2Seq 모델 과 마찬가지로 인코더-디코더 구조를 따르면서도, RNN 네트워크를 사용하지 않는다.
Transformer 이전에 제안된 언어 모델들은 RNN 네트워크를 사용하는 것이 주를 이루었다(간혹 CNN 네트워크를 사용하기도 했다) . 그러나 RNN 네트워크를 사용할 때는 다음과 같은 문제점이 있다.
- Vanishing Gradient : RNN의 고질적인 문제이다. LSTM, GRU 네트워크를 사용하더라도, time step이 늘어나면 그래디언트가 먼 시퀀스까지는 전달되지 않는다.
- 병렬 처리 불가능 : 한 time step이 끝나야 다음 time step을 처리할 수 있다. 따라서 학습 속도가 느리다.
인코더 디코더에 RNN 네트워크를 사용하는 Seq2seq 언어 모델은 순환 신경망 네트워크가 갖는 위의 두 가지 문제점 외에도 다음과 같은 문제점을 갖는다.
- 하나의 문장 내에 있는 개별 단어 간 관계를 파악할 수 없다. Recurrent Step을 모두 거친 뒤, 하나의 벡터에 문장의 정보가 반영된다. 따라서 각 단어 간 유의미한 관계를 파악하기 힘들다.
- 문장 길이가 길수록 하나의 벡터 안에 문장의 정보를 모두 포함하기 어려워진다. 문장이 길수록 앞서 반영된 단어의 정보는 점차 손실된다.
트랜스포머 모델은 언어 모델에서 RNN 네트워크를 인코더, 디코더 구조에서 제거한다. 동시에 셀프 어텐션 메커니즘을 적용함으로써 문장에서 정보를 추출해 낸다. 이를 통해 기존의 언어 모델이 갖는 문제점을 획기적으로 해결하면서도, 좋은 성과를 냈다.
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
현재 자연어 처리 분야에서 가장 fancy하고 hot한 모델이기도 하다. 논문을 하나씩 톺아 보며, 모델을 이해해 보자.
2. 아키텍쳐
Remember 인코더와 디코더, 그리고 각각을 구성하는 레이어의 구조는 조금 더 세세하게 살펴볼 예정이다. 그러나 그 전에, 반드시 모델의 전체 구조를 머릿 속에 그리고 넘어가도록 하자.
논문에 소개되어 있는 아키텍쳐에서, 큰 그림을 이해하는 데 필요한 것은 다음의 세 가지이다.
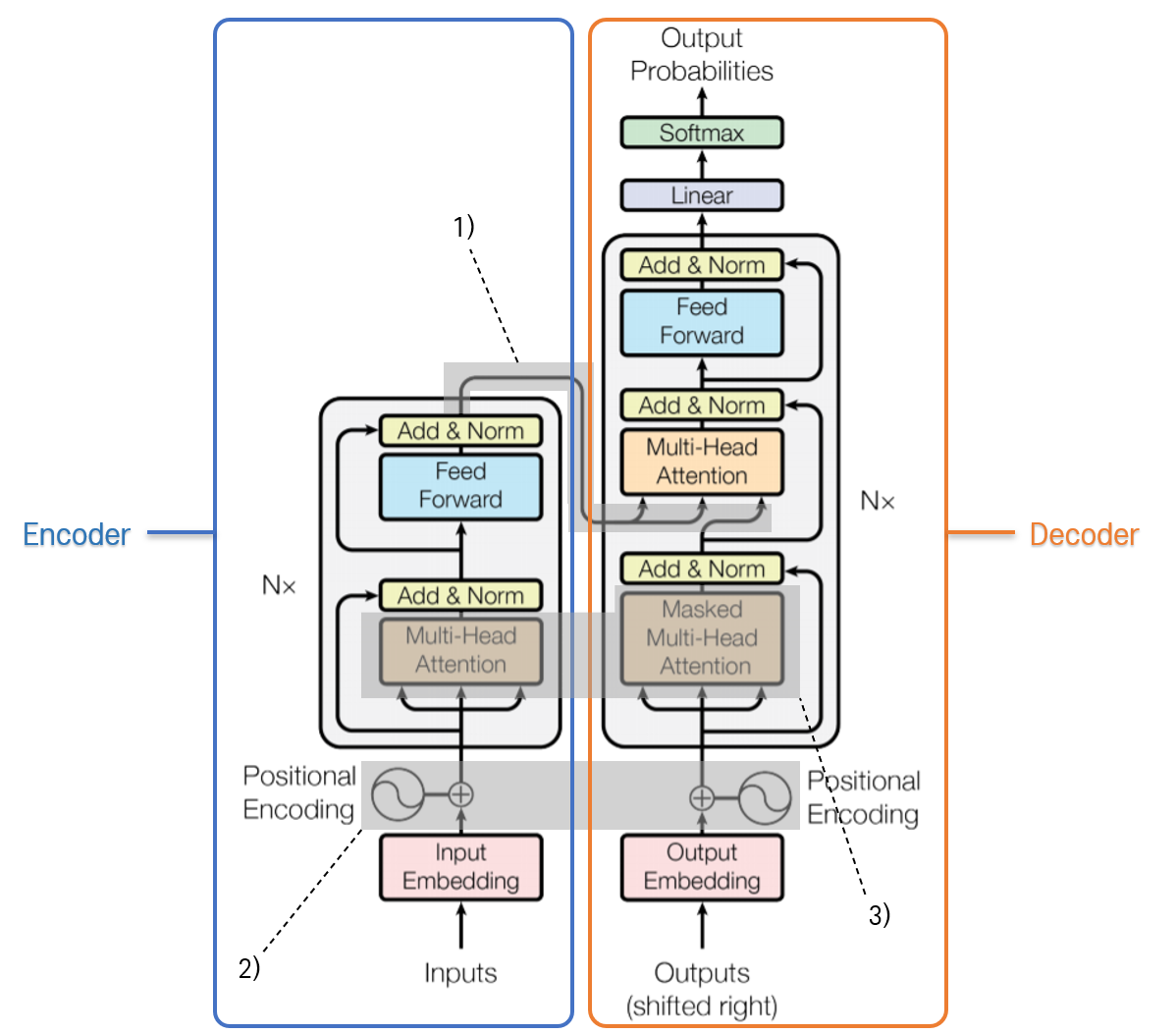
전체적으로 인코더-디코더의 구조이다. RNN 기반의 Seq2Seq 모델과 동일하다. 인코더에 문장을 입력하면, 인코더에 입력된 문장 정보와 디코더에 입력된 문장 정보를 조합해 대답을 출력한다. 인코더를 거친 입력이 1)의 흐름을 따라 디코더로 연결된다. 연결된 후, Attention 메커니즘에 따라 인코더와 디코더 문장 정보를 조합하여 주목할 부분을 결정한다.
RNN 네트워크를 제거했기 때문에, 시퀀스의 흐름을 파악하기 위한 장치가 필요하다. 이를 2)의 Positional Encoding으로 구현한다. 임베딩 레이어에 대응되는 것으로, 임베딩을 거친 각각의 인코더 입력, 디코더 입력이, 순서 정보를 갖도록 한다. 번호 부여의 개념으로 이해하자.
임베딩, Positional Encoding을 거친 인코더, 디코더에서의 입력은 각각 3)에서 Multihead Self-Attention 과정을 거치게 된다. Self-Attention이므로, Attention 메커니즘을 자기 자신에게 적용한다는 의미이다. 인코더와 디코더에 입력되는 문장 내에 각 단어 간 Attention을 계산한다. 요컨대, 자기 자신에서 어떤 단어가 중요한지에 대한 정보를 갖고 있다고 생각하자.
이렇게 자기 자신과의 Attention을 계산하는 과정을, 여러 번 수행하고 그 결과를 합치기 때문에 Multihead라는 단어가 붙는다. 쉽게 이해하기 위해 비유를 들자면, CNN에서 특징을 뽑아 내기 위해 여러 개의 필터를 적용하는 것과 같다. head의 개수만큼 Self-Attention을 진행하여 각 문장 내에서 단어 간의 관계를 더 자세히 알아내겠다는 것이다.
결과적으로 질문과 문장 각각에 대해 자기 자신을 이루는 단어들 간의 Attention 관계를 알아 내고, 또 질문과 문장 각각의 관계에서 단어들 간 Attention 관계를 알아 낸다. “더 복잡하고, 시간이 오래 걸리는 것이 아닐까?”하는 생각이 들 수도 있다. 그러나 Transformer 모델은 RNN 네트워크를 제거하고, 병렬 계산이 가능하게 하는 Positional Encoding을 도입한다. 그렇기 때문에 병렬 처리가 가능하여 시간은 더 적게 소요되면서도, 더 많은 단어 간 관계를 모델링할 수 있게 된다.
이제 모델 구조를 확인해 보자.
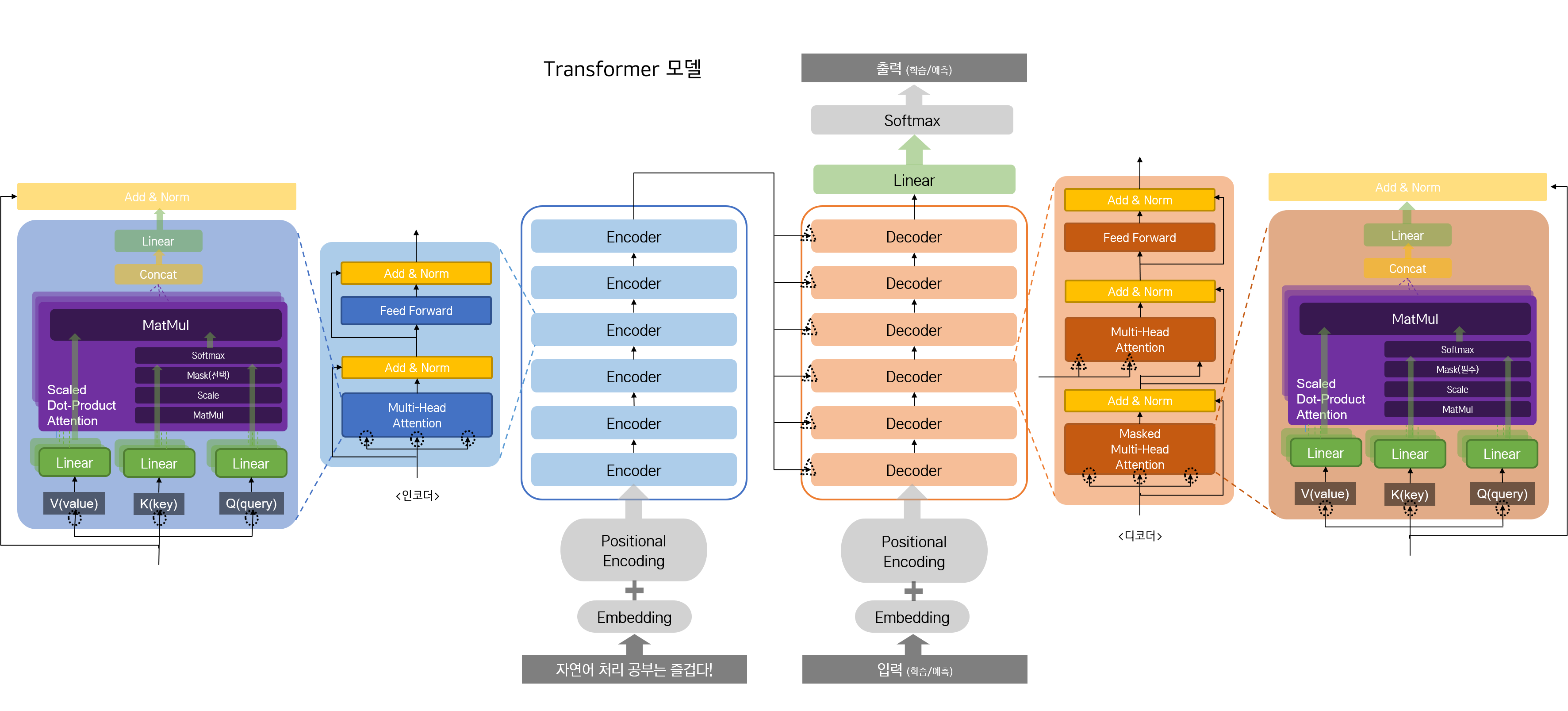
참고 :
학습/예측디코더 입력 및 출력 부분에
학습/예측이라고 표현한 이유는 이후 구현 단계에서 Seq2Seq 모델과 마찬가지로, 학습 시에는 Teacher Forcing 방식을, 예측(채팅 모듈) 시에는 한 단어씩 입력하는 방식을 사용하기 때문이다. 원래 논문에 소개된 대로라면, Softmax 활성화 함수를 거쳐 다음 단어가 나올 확률을 예측해야 한다.At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities.
인코더와 디코더는 여러 개의 레이어로 구성되어 있다. 각 부분을 구성할 레이어의 수는 분석자가 설정하면 된다. 다만 디코더 레이어 개수와 인코더 레이어 개수가 같아야 한다. 논문에서는 각 레이어를 6개로 구성했다.
인코더 레이어와 디코더 레이어의 구성은 다음과 같다.
- 인코더 레이어 = Self Attention + Feed Forward Network
- 디코더 레이어 = Self Attention + Encoder-Decoder Attention + Feed Forward Network
인코더, 디코더를 구성하는 각각의 레이어는 모두 Residual Connection 으로 연결되어 있다. (그림에서는 Add & Norm 으로 표현되어 있다.) 기존에 레이어에 입력된 정보와 레이어를 거쳐 출력된 정보를 더하고 정규화함으로써, 앞 단에 존재하던 정보를 보존하는 것이라 이해하면 된다.
한편, 인코더 내 각 레이어, 디코더 내 각 레이어는 동일한 구조를 가지고 있기는 하나, weight을 공유하지는 않는다.
인코더에 문장이 입력되고, 각각의 레이어를 거쳐 나온 인코더의 최종 출력이 각각의 디코더에 전달된다. 정확하게는, 디코더의 레이어 중 두 번째 레이어인 Encoder-Decoder Attention 레이어에 전달된다.
디코더로 입력된 값(Value)에 대해, 인코더의 결괏값을 Query, Key로 삼아 Attention Score를 계산하는 것이다. 논문에서는 이 과정을 통해 모든 디코더 레이어가 인코더에 입력된 문장의 각 부분(RNN 네트워크의 타임 스텝에 비유할 수 있다)에서 가장 주목해야 할 부분에 집중할 수 있도록 한다고 말한다.
In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence.
이렇게 인코더와 디코더를 모두 거친 후, Linear 레이어와 Softmax 활성화 함수 레이어를 거쳐 다음 단어를 출력하게 된다. (더 정확하게 표현하자면, 어휘 집합의 크기와 같은 크기를 갖는 1차원 벡터를 출력한다. 이를 통해 예측된 단어를 알 수 있음은, 너무나도 자명하다.)
공유하기
Twitter Facebook LinkedIn

댓글남기기