
[NLP] Transformer_3.Multi-head Attention_1
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. 논문 출처
Transformer 이해하기_Multi-head Attention
트랜스포머 모델의 또 다른 핵심 중 하나는 Multi-head Attention을 네트워크를 사용한 것이었다. 전체적인 Multi-head Attention 네트워크 구조는 다음과 같다.
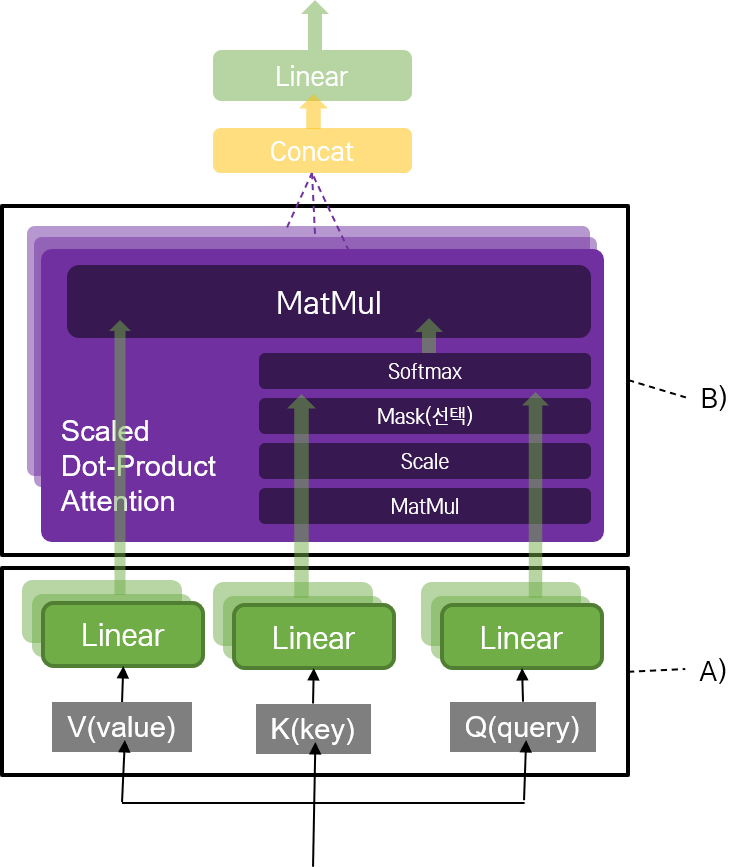
1) Attention 메커니즘으로서 2) Scaled Dot-Product를 수행하는데, 3) 이를 여러 개의 head로 나누어 수행한다. 특이한 것은 4) 입력 문장 자신에 대해 Scaled Dot-Product를 수행하는 Self-Attention 레이어가 있다는 것과, 5) 레이어에 따라 Masking을 진행할 수 있다는 것이다.
1. Scaled Dot-Product Attention
Attention
Transformer 논문에서는 Attention 과정을 설명하기 위해 Query, Key, Value라는 개념을 사용한다. 이를 이해하기 위해 이전에 Seq2Seq 모델 에 Attention 메커니즘으로서 Dot-Product를 적용해 챗봇을 만들었던 내용을 돌이켜 보자.
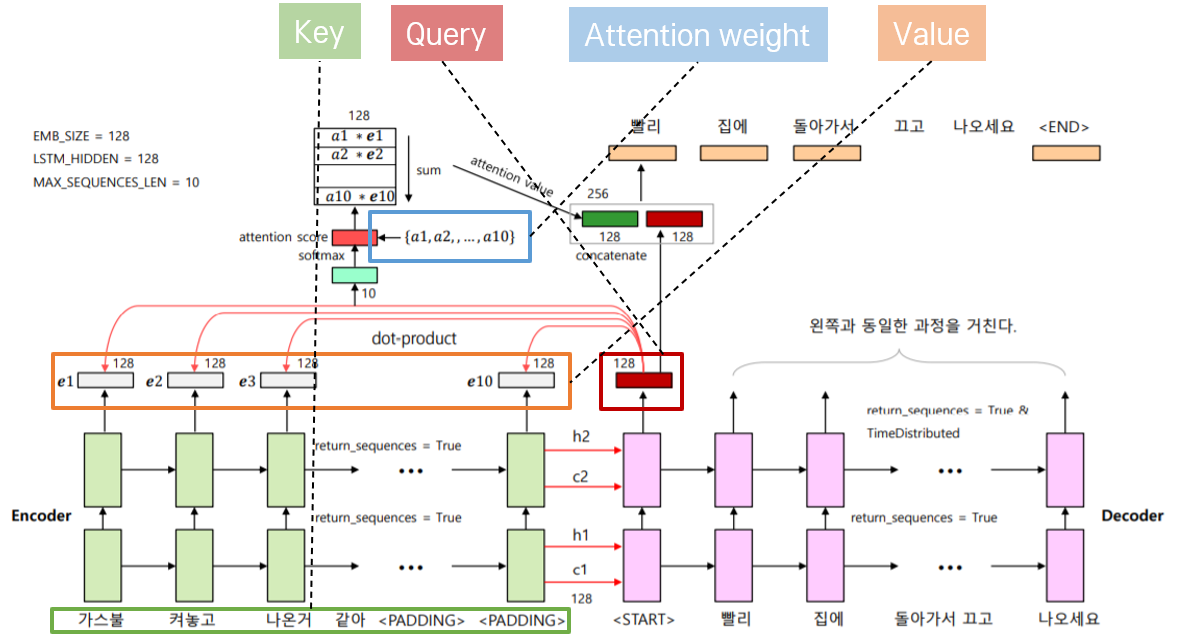
위의 그림에서 Attention Score를 계산하기 위해 입력으로 받은 현재 벡터를 Query라고 한다. 다른 단어와의 점수를 매기기 위해 기준으로 삼을 벡터이다. 주어진 Query와의 Attention Score를 계산할 때 대상이 되는 단어 벡터들을 Key라고 한다. 다른 위치의 단어 벡터이다. Value는 원래 문장의 각 단어가 벡터로 수치화된 값을 의미한다.
Attention에 Query, Key, Value 개념만 입혀 다시 이해해 보자.
| Attention Weight | Attention |
|---|---|
 |
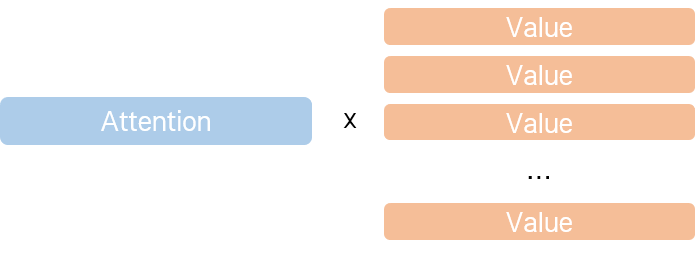 |
왼쪽의 그림에서처럼 Query와 Key 간 Dot-Product 연산을 수행하고, Softmax를 취해 합이 1인 확률 값으로 변환해 주면, 각 Key에 대한 Attention Weight이 나온다. 기존의 설명에 Query, Key 개념만 입혀 다시 이해하자면, Attention Weight은 Query가 각각의 Key에 어느 정도 Attention을 둬야 하는지를 나타내는 비중이다. 그리고 오른쪽의 그림처럼 Value에 Attention Weight을 곱하면, Query와 유사한 Value일수록 더 높은 값을 가지는 Attention Value가 나온다.
결과적으로, Transformer 논문에서의 Attention 개념은 Query, Key, Value 개념만 추가되었을 뿐, 기존의 Attention 개념과 크게 다르지 않다. 이 개념을 활용해 논문의 Attention 함수를 다시 이해해 보자면, Query 벡터와 가장 유사한 Key 벡터를 탐색해 그에 상응하는 Value를 반환하는 dictionary 자료형과 같은 개념이다.

Scale
논문에서는 위의 Attention 과정에서 각 Attention Value를 차원에 루트를 씌운 값으로 나눠 주어 Scaling한 뒤, Softmax 함수를 취해 주었다. Dot-Product 값이 너무 커져서 계산량이 커지는 것을 방지하기 위함이다.
참고 : Scaling이 필요한 이유
We suspect that for large values of \(d_k\), the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. (…) To illustrate why the dot products get large, assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product, \(q · k = \Sigma_{i=1}^{d_k} qiki\), has mean 0 and variance \(d_k\).
결과적으로, 논문에 구현된 Scaled Dot-Product Attention의 공식은 다음과 같다.
\[Attention(Q, K, V) = softmax(\frac {QK^T} {\sqrt {d_k}})V\]2. Multi-head Attention
Attention을 수행하기 위해 입력 문장을 A)에서와 같이 Query, Key, Value로 나누고, linear projection 네트워크를 거친다.
참고 : 디코더의 Q, K, V
이후에 더 자세히 살펴보겠지만, 트랜스포머 모델에서는 Multi-head Attention 레이어의 종류가 2가지이다. Self-Attention을 하는 레이어와 Encoder-Decoder Attention을 수행하는 레이어이다. 인코더는 전자만 사용하지만, 디코더는 전자와 후자 모두를 사용한다. 이 때, 디코더에서는 레이어별로 Q, K, V 가 다음과 같이 달라진다.
- Encoder-Decoder Attention: Q는 디코더의 이전 레이어 output, K와 V는 인코더의 output.
- Self-Attention: Q, K, V 모두 인코더의 output.
이제 Transformer 모델의 또 다른 핵심인 Multi-head Attention 개념이 등장한다. 위의 Scaled Dot-Product Attention을 여러 개의 head로 나누어 진행하는 것이다. 병렬 처리를 통해 속도를 향상시키기 위함이다.
교재의 예시에서와 같이 "I love you so much"라는 문장을 6차원으로 임베딩한 후, 3개의 head로 나누어 Attention을 진행한다고 하자.
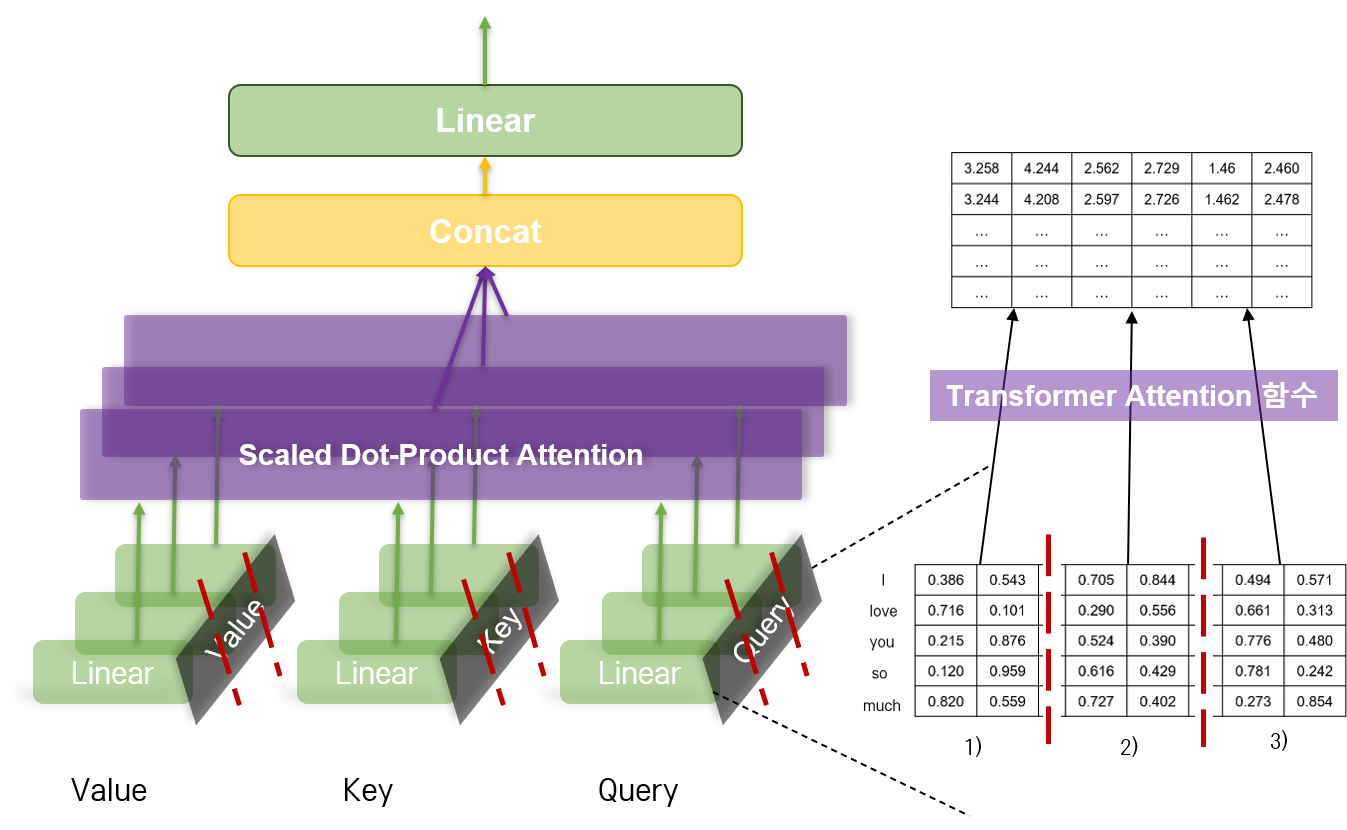
임베딩 차원 \(d_{model}\) 이 6이고, 이를 head 의 개수를 3으로 나누었을 때, 나누어진 차원의 수를 \(d_k\)라고 하자. 그러면 각각의 head는 Query에서 \((Vocab\_size, d_{k})\) 만큼의 행렬을 처리하게 된다.
쉽게 이해하자면, 쪼개진 각각의 부분을
1),2),3)이라 했을 때 각각의 head는 Query에서1),2),3)의 부분을 맡아 처리하는 것이라고 볼 수 있다.
그림에서는 Query 벡터 밖에 나타내지 않았지만, Key, Value 벡터에 대해서도 동일한 과정을 진행한다. Key, Value 벡터 모두 Query 벡터와 동일한 크기를 가지고 있을 것이므로,각각의 head는 \((Vocab\_size, d_{k})\) shape의 Query, Key, Value에 대해 Scaled Dot-Product Attention을 진행하게 된다.
그 이후, 각각의 head가 Scaled Dot-Product Attention을 진행한 결과를 모두 concat한다. 그러면 Multi-head Attention을 거쳐 나오는 결과는 기존에 입력으로 들어온 벡터의 shape과 같아진다.
이렇게 Multi-head로 나누어 Scaled Dot-Product Attention을 진행한 결과를 다시 linear projection 네트워크에 통과시킨다.
참고 : Multi-head Attention에서의 \(d_k\)
논문에서는 \(d_k\)를 원래의 임베딩 차원인 \(d_{model}\)보다 작게 설정했다. 이를 통해 계산 복잡도를 낮출 수 있었다.
In this work we employ h = 8 parallel attention layers, or heads. For each of these we use dk = dv = dmodel/h = 64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
그러나 구글링해보니, 이 숫자가 꼭 작아야만 하는 것은 아니라고 한다. multi-head attention의 계산 복잡도를 일정하게 만들고자 내린 구조적인 선택일 뿐이라고 하는데, 논문에서 관련한 구절을 정확하게 찾지는 못했다. 제대로 확인해 보자.
공유하기
Twitter Facebook LinkedIn

댓글남기기