
[NLP] Transformer_4. 네트워크 구조
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. 논문 출처
Transformer 이해하기_Encoder, Decoder
이제 트랜스포머 모델을 구성하는 인코더 및 디코더 스택이 어떻게 구성되는지 살펴 보자.
1. Encoder
전체적인 인코더 모듈의 구조는 다음과 같다.
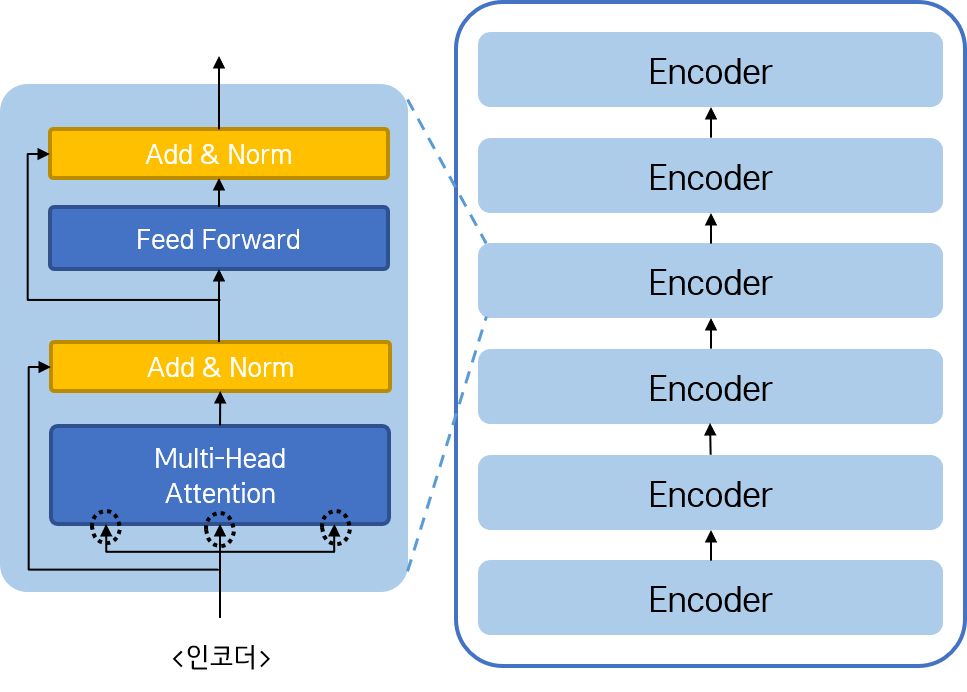
인코더 모듈은 여러 개의 인코더 스택으로 구성된다. 그리고 하나의 인코더 스택은 Multi-head Attention 네트워크와 Feed Forward 네트워크의 2층 구조로 구성된다. 그리고 각 네트워크는 Add & Norm이 진행되는 Residual Connection 네트워크를 거쳐 다음 층으로 연결된다.
하나의 인코더 층은 이전 인코더 층을 통과한 결과를 입력으로 받는다. 첫 인코더 층에 입력되는 행렬은 입력 문장에 Embedding과 Positional Encoding을 진행한 결과이다. 그리고 마지막 인코더 층을 통과한 결과는 각각의 디코더 층(그 중에서도 Encoder-Decoder Attention을 진행하는 두 번째 네트워크)으로 연결된다.
Multi-head Attention 네트워크는 이전에 살펴 보았기 때문에, 간단히 Feed-Forwark와 Residual Connection 네트워크를 알아보도록 하자. 참고로, 인코더의 Multi-head Attention 네트워크는 Self-Attention이며, Masking이 필수는 아니다.
Residual Connection
이전의 네트워크에 입력된 정보를 \(x\)라고 하고, 이전의 네트워크(Self-Attention 혹은 Feed Forward)를 통과해서 나온 정보를 \(F(x)\)라고 하자. 다음 네트워크로 올라가기 전에 \(x\)와 \(F(x)\)를 더하고, Layer Normalization을 적용한다. 인코더 스택을 쌓을수록 층이 깊어지면서 과적합 혹은 학습이 잘 되지 않을 수 있음을 고려한 것으로 보인다.
참고
논문에서는 Residual Connection의 적용에 대한 부분을 다음과 같이 설명한다. (이전의 레이어를 Sublayer라고 표현한다.)
We employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is \(LayerNorm(x + Sublayer(x))\), where \(Sublayer(x)\) is the function implemented by the sub-layer itself.
한편, Sublayer를 통과한 결과에 0.1의 Dropout을 적용한다는 부분도 있었다.
Feed-Forward Network
Self-Attention 네트워크를 거친 후 Feed-Forward 네트워크를 거친다. 각 문장을 이루는 단어 벡터 각각에 적용되는 Position-wise 네트워크이다. 두 개의 선형층, 그리고 그 사이의 ReLU 활성화 함수를 거치도록 되어 있다. 논문에 소개된 수식은 다음과 같다. (앞 부분이 ReLU 함수 그대로의 식이고, 그 함수에 Linear 함수를 적용한 것이다.)
\[FFN(x) = max(0, xW1 + b1)W2 + b2\]참고 : Feed-Forward Network의 역할
이 글을 참고하면, Feed-Forward Network를 통과함으로써 각 head가 만들어 낸 Self-Attention이 균등하게 섞인다고 한다. Attention이 한 쪽으로만 치우쳐지지 않도록 하는 과정이라고 하는데, 논문에서 다음과 같이 서로 다른 가중치를 사용한다고 한 부분에서 해당 글의 저자가 왜 이렇게 해석했는지에 대한 힌트를 찾을 수 있을 듯하다.
While the linear transformations are the same across different positions, they use different parameters from layer to layer.
이렇게 모든 인코더 네트워크를 통과하고 나면, 입력 문장의 임베딩 차원이 그대로 유지된다. 논문에서 구현한 인코더 네트워크 각각의 세부적 구성은 다음과 같다.
- 인코더 레이어 개수 = 6.
- 임베딩 차원(\(d_{model}\)) = 512.
- Multi-head Attention 헤드 개수(\(d_{k}\)) = 8.
- Feed-Forward 네트워크 은닉 노드 개수(\(d_{ff}\)) = 2048.
2. Decoder
전체적인 인코더 모듈의 구조는 다음과 같다.
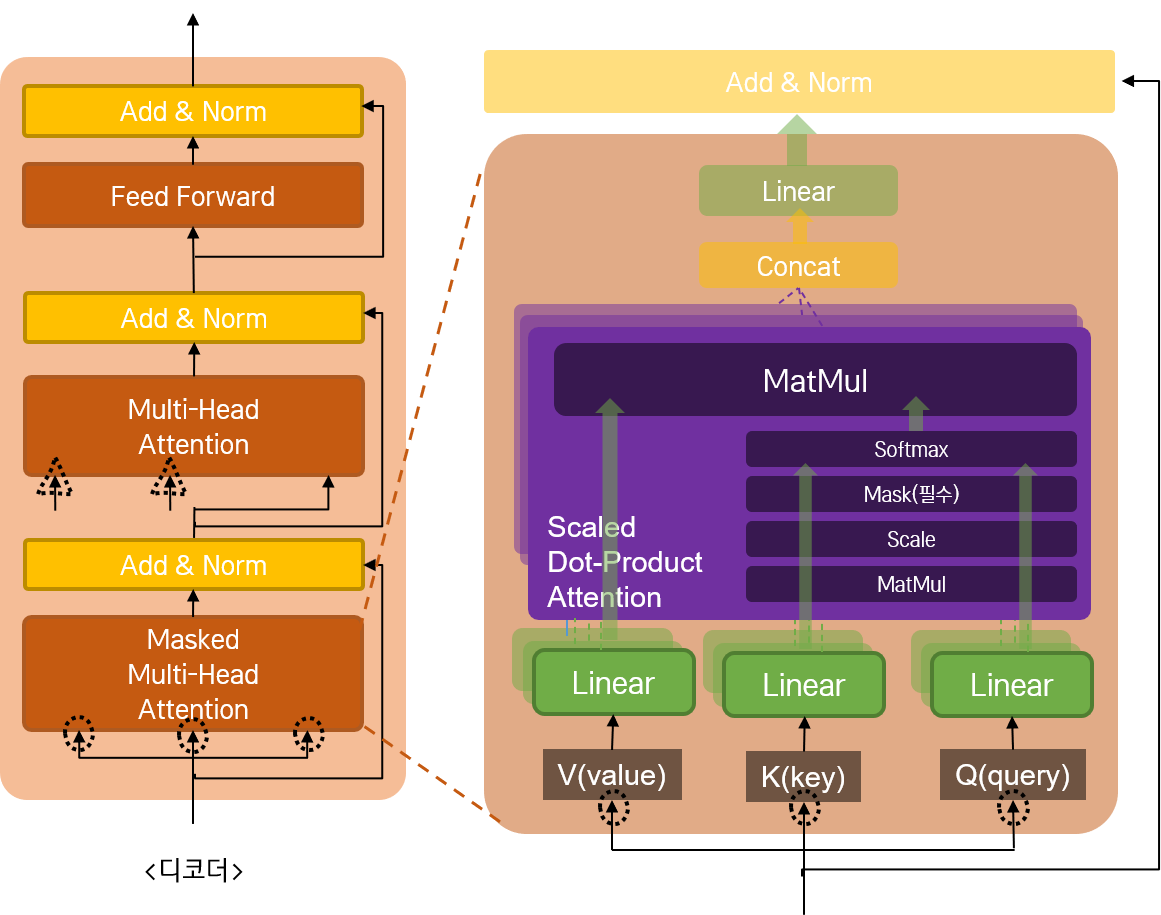
디코더 스택의 경우, 전체적인 구조는 인코더와 비슷하나, 중간에 하나의 네트워크가 추가된다. 두 개의 Multi-head Attention 네트워크와 Feed 하나의 Feed-Forward 네트워크로 구성된 3층 구조이다. 각 네트워크를 통과한 결과에 Residual Connection이 적용되는 것도 동일하다.
Multi-head Attention이 Self Attention과 Encoder-Decoder Attention의 두 층으로 구성된다는 것과, Self Attention을 적용할 때 Masking이 필수라는 점(이전 글에서 설명했듯, 디코더에서는 예측을 수행해야 하기 때문이다.) 만 달라진다. Self Attention을 적용한 뒤, 그 결과를 가지고 인코더의 결과와 Attention을 수행한다. 인코더와 디코더 간의 관계를 확인하는 것이다. (이전에 Seq2Seq 모델에 Attention을 적용하여 챗봇을 만들었을 때와 동일한 구조라고 보면 된다.) 따라서 Encoder-Decoder Attention을 수행할 때에는 Query, Key의 입력이 Encoder에서 넘어 오게 된다.(그림에서는 삼각형 모양으로 표현되어 있다.)
이렇게 두 개의 Attention을 수행한 후, 인코더 모듈과 동일하게 Feed Forward 네트워크를 적용하면 된다. 논문에서 디코더 모델에 적용한 각각의 파라미터도 인코더의 그것과 동일하다.
공유하기
Twitter Facebook LinkedIn

댓글남기기