
[Kubernetes] NVIDIA Device Plugin 동작 원리
Kubernetes 환경에서 GPU를 사용하는 방법을 알아본 뒤, 그렇다면 NVIDIA Device Plugin이 어떻게 동작하여 컨테이너에서 GPU를 사용할 수 있는 것인지 공부한 내용을 작성한다.
개요
크게 두 가지의 관점에서 이해하면 좋다. NVIDIA Device Plugin이 쿠버네티스 환경에서 GPU를 인식할 수 있게 해 준다고 했기 때문에, 어떻게 인식할 수 있는 건지(이하 보고라고 하겠다), 인식한 GPU 노드에 어떻게 파드가 스케줄링되어 실행되는지(이하 스케줄링이라고 하겠다)이다.
큰 구조는 아래와 같다. GPU를 사용하기 위해, 아래와 같이 계층 별로 책임이 잘 분리되어 있다.
┌──────────────┐
│ Scheduler │ "어느 노드에 배치할까?" (정책 결정)
└──────┬───────┘
│ Pod.spec.nodeName = "worker-1"
↓
┌──────────────┐
│ Kubelet │ "이 노드에서 어떻게 실행할까?" (실행 조율)
│ (worker-1) │ - Device plugin에게 물어보기
└──────┬───────┘ - Container runtime에게 전달하기
│
├─────→ ┌─────────────────┐
│ │ Device Plugin │ "어떤 GPU 줄까?" (리소스 할당)
│ └─────────────────┘
│
└─────→ ┌─────────────────┐
│Container Runtime│ "어떻게 격리할까?" (실행)
└─────────────────┘
- Scheduler (kube-scheduler): 어느 노드에 배치할지 결정
- 모든 리소스를 동일하게 취급
- 각각의 리소스를 고려했을 때, 파드를 어느 노드에 배치할지가 관심사
- Kubelet: 파드 실행 관리
- 노드별 에이전트
- device plugin과 container runtime 사이 중개자 역할
- device plugin에 물어봐서, container runtime에 실행 요청
- NVIDIA Device Plugin: 어떤 장치를 할당할지 결정
- 노드 GPU 세부사항 관리
- Kubelet에게 파드 실행 시 어떤 GPU를 사용하라고 알려 줌
- Container Runtime: 실제 컨테이너 실행
보고
NVIDIA Device Plugin daemonset이 배포되어 있는 클러스터라면, GPU 노드에 라벨링했을 때, 각 노드에 NVIDIA Device Plugin이 배포된다고 했다. 이후, 노드의 GPU 상태가 아래와 같이 관리된다.
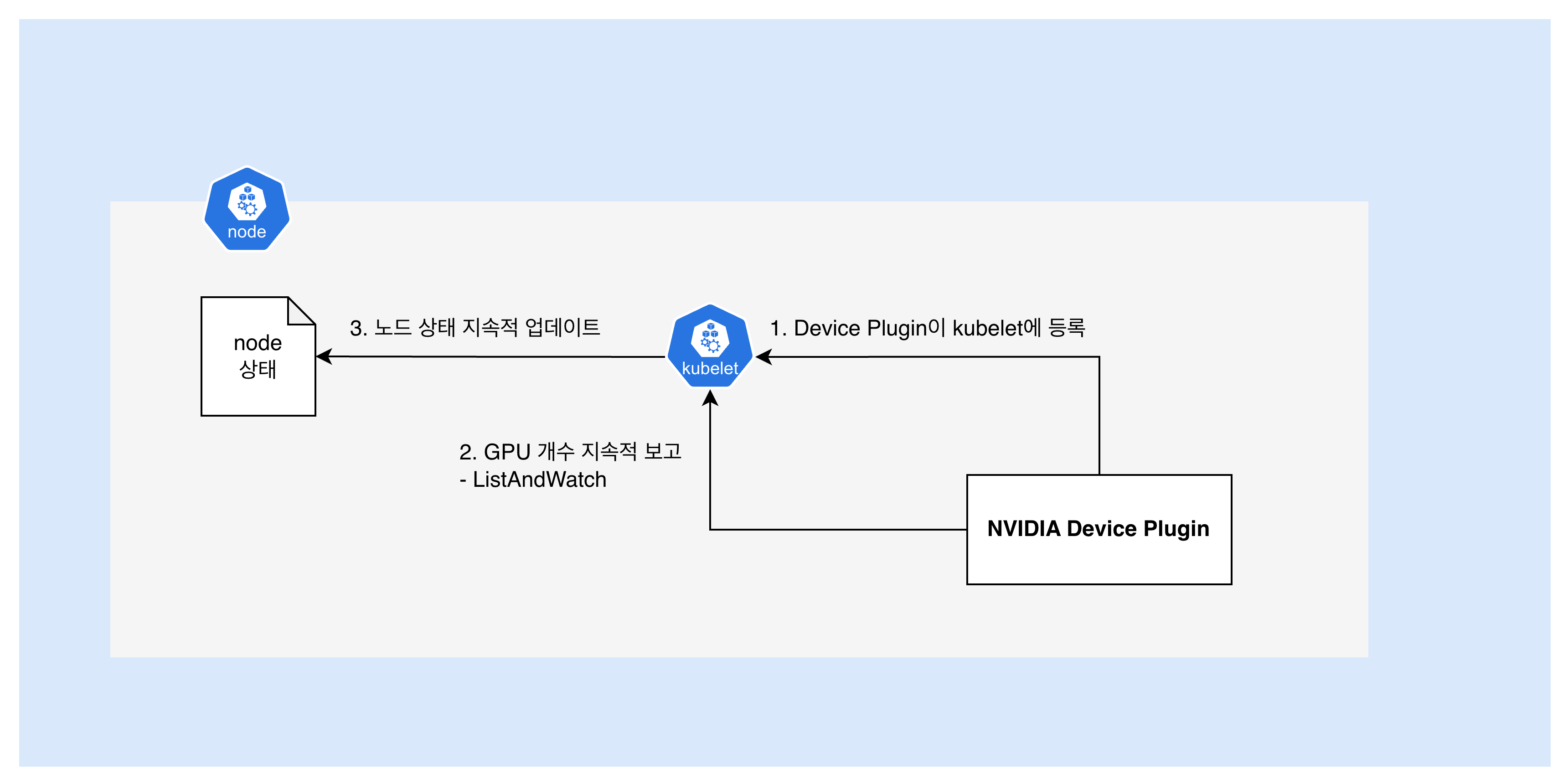
- NVIDIA Device Plugin Pod 시작
- 노드에 배포된 daemonset pod가 자동 시작
- Device Plugin → Kubelet 등록 (Register)
- Device Plugin이 kubelet의 unix socket에 연결
- Kubelet은 NVIDIA Device Plugin Pod를 인식하게 됨
nvidia.com/gpu 리소스를 관리하겠습니다선언
- Device Plugin → Kubelet GPU 개수 보고 (ListAndWatch, 지속적)
- Device Plugin이 구현해야 하는 메서드 중 하나인 ListAndWatch를 실행함
- NVML(NVIDIA Management Library)로 GPU 스캔
- 발견한 GPU 개수를 gRPC stream으로 지속 보고
- Kubelet은 노드 상태에 GPU 자원을 지속적으로 반영하여 업데이트함
- GPU 상태 변경 시 즉시 업데이트
이렇게 보고된 GPU 자원을 노드 상태를 통해 확인할 수 있게 되는 것이다.
apiVersion: v1
kind: Node
metadata:
name: worker-1
status:
capacity:
nvidia.com/gpu: "8" # device plugin이 보고한 값
cpu: "16"
memory: "64Gi"
allocatable:
nvidia.com/gpu: "8"
스케줄링
그렇다면 사용자가 GPU 파드 생성을 요청했을 때는 어떤 일이 발생할까.
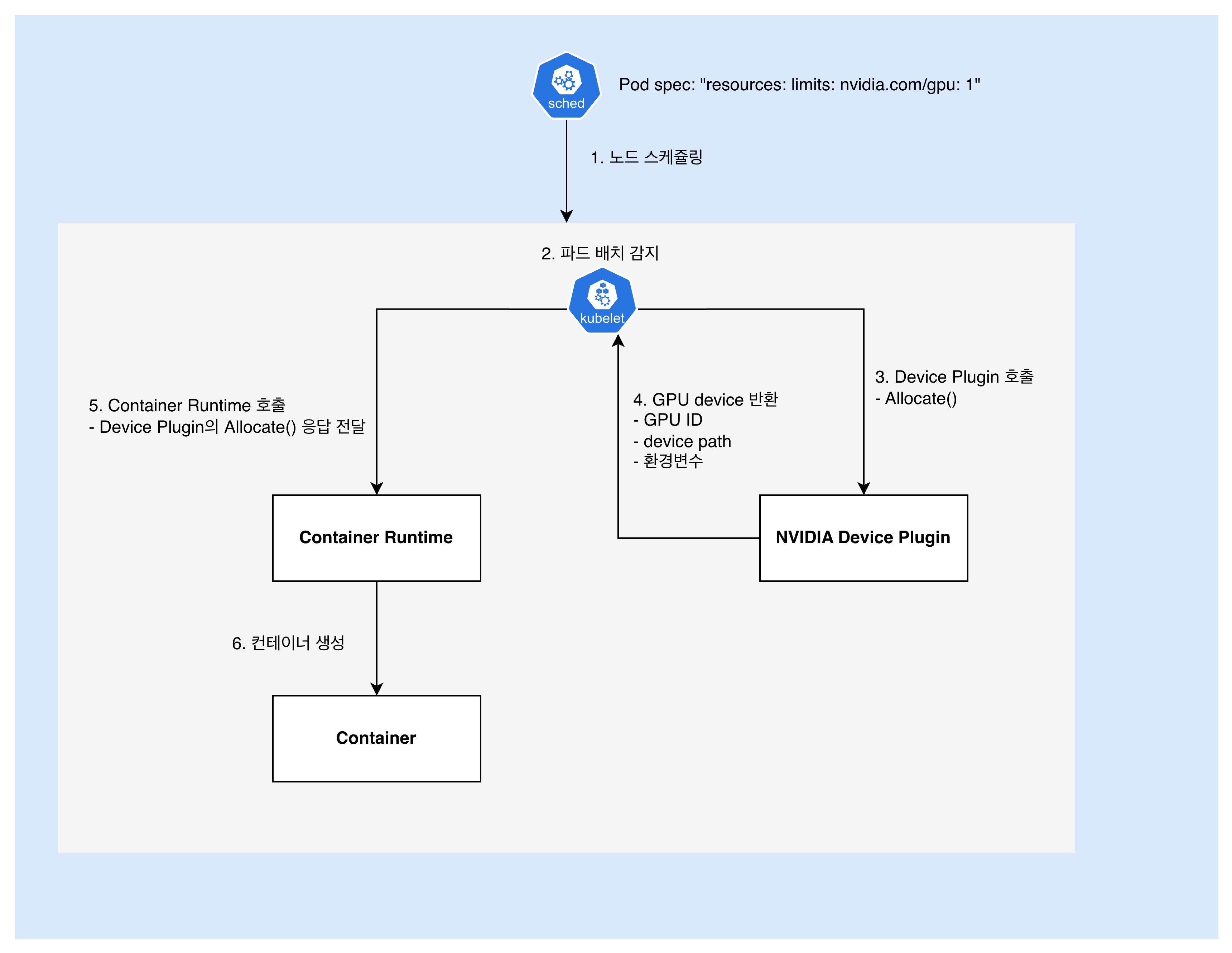
- 사용자:
nvidia.com/gpu: 1파드 생성 요청 - Scheduler: 노드 스케줄링
- 위 보고 단계에서 노드 상태가 계속해서 보고되고 있음
- 이렇게 보고된 노드 상태를 바탕으로, 가용
nvidia.com/gpu자원을 확인해 적절한 노드에 배치
- Kubelet: 파드 배치 감지
아, 내 노드에 파드가 배치되었구나. 컨테이너 생성을 시작해야지!
- Kubelet: NVIDIA GPU Device Plugin에게 GPU 할당 요청
이 pod에 nvidia.com/gpu 자원이 1개 필요해. 어떤 GPU를 사용하면 돼?
- NVIDIA Device Plugin: GPU 할당 결과 응답 반환
GPU-<uuid>를 할당해줄게. /dev/nvidia0 경로에 있어. 환경 변수는 이렇게 설정해- GPU ID: GPU-abc123…
- Device Path: /dev/nvidia0, /dev/nvidiactl, /dev/nvidia-uvm
- 환경변수: NVIDIA_VISIBLE_DEVICES=GPU-abc123
- 마운트: CUDA 라이브러리 경로들
- Kubelet: Container Runtime에
4에서 받은 응답과 함께 컨테이너 실행 요청- Kubelet은 NVIDIA Device Plugin의 응답을 신뢰. 받은 것을 그대로 전달
- Container Runtime에, 예컨대 아래와 같은 정보를 주입
{ "Devices": [ { "Path": "/dev/nvidia0", "Type": "c", "Major": 195, "Minor": 0 } ], "Mounts": [ "/usr/local/nvidia/lib64", // CUDA 라이브러리들 ], "Env": [ "NVIDIA_VISIBLE_DEVICES=0", "CUDA_VISIBLE_DEVICES=0" ] }
- Container Runtime: 컨테이너 실행
Container Runtime의 GPU 처리
NVIDIA Container Runtime에 대해 알아본 결과를 바탕으로, 위의 5와 6 사이에 어떤 일이 일어나는지 조금 더 자세히 살펴보자.
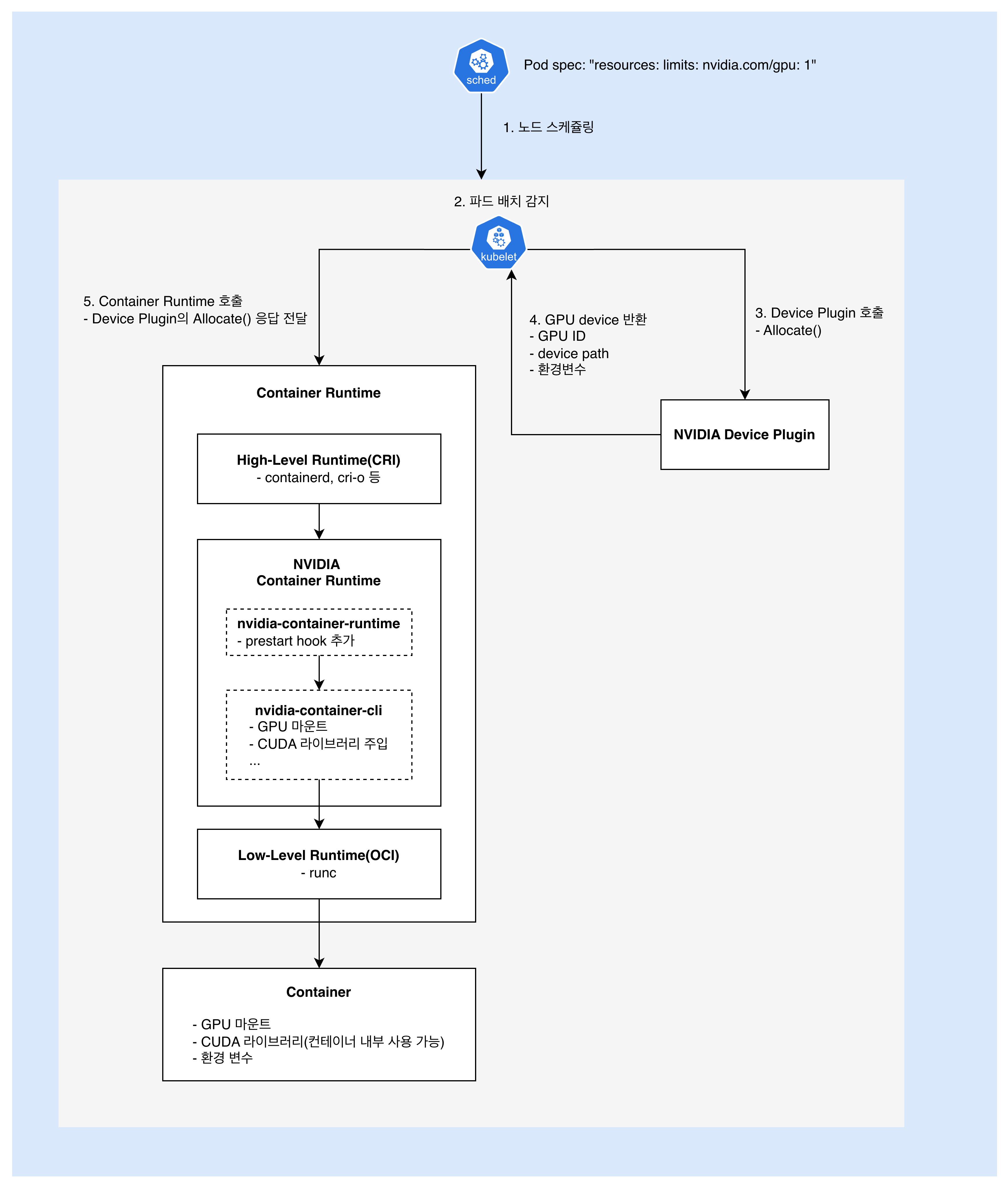
- Kubelet: High-Level Container Runtime에 컨테이너 생성 요청
- High-Level Container Runtime: NVIDIA Container Runtime 호출
- NVIDIA Container Runtime 동작
- GPU 장치 파일 마운트
- CUDA 라이브러리 마운트
- NVIDIA driver 파일 마운트
- 컨테이너 namespace 설정
- …
- NVIDIA Container Runtime: Low-Level Container Runtime 호출
- Low-Level Container Runtime: 컨테이너 실행
결론
위와 같은 단계를 거쳐, 최종적으로 쿠버네티스 환경에서 컨테이너가 GPU를 사용할 수 있게 된다. 알고 보면, 그 속에 숨어 있는 추상화 레벨과 책임 분리가, 놀라운 수준이다.


댓글남기기