
[Kubernetes] MinIO distributed 모드에서 existingClaim이 조용히 무시되는 이유
2025년 초, 현장에 배포된 K3s 클러스터에서 루트 파티션이 가득 차 워크플로우가 중단되는 문제가 발생했다. 당시에는 급하게 해결하고 넘어갔는데, 최근 리눅스 스토리지와 Kubernetes 스토리지 구조를 공부하면서 이 문제를 다시 꺼내 정리하게 되었다. 이 글에서는 원인 추적부터 해결, 데이터 이관 삽질까지 복기한다.
TL;DR
- 현상: 루트 파티션 90% 사용, 워크플로우 중단
- 원인:
distributed모드에서existingClaim무시 → K3s default StorageClass가 루트 파티션에 PV 생성 - 해결: SSD 증설 →
standalone모드 전환 →existingClaim으로 SSD 경로의 PVC 연결 - 핵심: StatefulSet의
volumeClaimTemplates는existingClaim과 본질적으로 충돌한다
문제
현상: 루트 파티션 용량 부족
시스템이 배포된 현장 중 한 곳에서 K3s 클러스터 내 워크플로우 실행이 중지되는 현상이 발생했다. 이 현장은 카메라 약 3,000대에서 수신한 영상 프레임을 MinIO에 저장하는 구조로, 데이터가 빠르게 축적되는 환경이었다. 보통 이런 경우 CPU 사용량, 디스크 사용량을 먼저 확인하게 되는데, 서버 접속 시부터 상황이 심상치 않았다.
System information as of Fri Feb 7 02:07:58 PM KST 2025
System load: 0.35 Temperature: 35.0 C
Usage of /: 85.4% of 231.70GB Processes: 349
Memory usage: 13% Users logged in: 1
Swap usage: 1% IPv4 address for enp8s0: 172.5.1.97
루트 파티션이 231.70GB 중 85.4%를 사용 중이었다. df -h로 확인하니 실제로는 90%까지 차 있었다.
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 3.2G 2.8M 3.2G 1% /run
/dev/mapper/ubuntu--vg-lv--0 232G 198G 23G 90% /
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/nvme0n1p2 2.0G 129M 1.7G 8% /boot
/dev/sda 3.6T 65G 3.4T 2% /mnt/data
tmpfs 3.2G 4.0K 3.2G 1% /run/user/1000
용량 분석: 루트 파티션은 누가 먹고 있는가
루트 파티션의 사용량을 추적해 보았다.
$ sudo du -sh /var/lib/*
# ...
137G /var/lib # /var/lib 전체
18G /var/lib/docker
119G /var/lib/rancher
# ...
$ sudo du -sh /var/lib/rancher/k3s/*
565M agent
177M data
145M server
118G storage
/var/lib/rancher/k3s/storage가 118GB를 차지하고 있었다. 이 디렉토리는 K3s의 기본 StorageClass인 local-path가 PV를 생성하는 경로다.
$ sudo du -sh /var/lib/rancher/k3s/storage/*
20M pvc-2df3a114-..._label-studio_label-studio-ls-pvc
118G pvc-84164975-..._minio_export-minio-1
118GB 중 거의 전부가 MinIO의 PVC 하나에 집중되어 있었다. 루트 파티션 232GB 중 절반 이상을 MinIO가 혼자 쓰고 있었던 셈이다.
클러스터 상태 확인
MinIO의 배포 상태를 확인했다.
$ kubectl get all -n minio
NAME READY STATUS RESTARTS AGE
pod/minio-0 1/1 Running 0 87d
pod/minio-2 1/1 Running 0 87d
pod/minio-1 0/1 Pending 0 13d
NAME READY AGE
statefulset.apps/minio 2/3 87d
$ kubectl get pvc -n minio
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
export-minio-2 Bound pvc-44a76.. 200Gi RWO local-path 87d
export-minio-0 Bound pvc-4c779.. 200Gi RWO local-path 87d
export-minio-1 Bound pvc-84164.. 200Gi RWO local-path 87d
$ helm list -n minio
NAME NAMESPACE REVISION STATUS CHART APP VERSION
minio minio 1 deployed minio-5.2.0 RELEASE.2024-04-18T19-09-19Z
몇 가지 의문점이 눈에 들어왔다.
- MinIO가 StatefulSet으로 배포되어 있다 (Pod 이름이
minio-0,minio-1,minio-2) - PVC 이름이
export-minio-0,export-minio-1,export-minio-2로 자동 생성되어 있다 - 모든 PVC가
local-pathStorageClass를 사용하고 있다 minio-1만 Pending 상태이고, age가 13일이다 (나머지는 87일)
minio-1의 age가 다른 Pod들(87일)에 비해 훨씬 짧다는 것은, 원래 Running이었다가 중간에 죽고 재생성되었다는 의미다. 루트 파티션 사용량이 90%에 도달한 상태에서, kubelet이 disk pressure를 감지하고 노드에 node.kubernetes.io/disk-pressure taint를 건 것으로 보인다. 이 taint가 걸리면 해당 노드에 새 Pod를 스케줄링할 수 없으므로, minio-1은 evict된 뒤 재스케줄링이 차단되어 Pending에 머물러 있었다.
아쉬운 점: 당시
kubectl describe node로 taint 상태를 직접 확인했으면 이 추정을 바로 검증할 수 있었다. 하지만 운영 초기인 데다 시간 압박에 쫓기느라 노드 상태까지 확인하지 못했다. 다만, 같은 노드에서 실행 중이던 Label Studio Pod가 동일한 사유로 evict된 기록이 남아 있어, disk pressure가 실제로 발생했음을 뒷받침한다.Status: Failed Reason: Evicted Message: The node was low on resource: ephemeral-storage. Threshold quantity: 12439225938, available: 34765552Ki.QoS Class가
BestEffort인 이 Pod가 먼저 축출된 것은 kubelet의 eviction 우선순위와도 일치한다.
작업 제약
상황에는 일정 압박과 시간 압박이 동시에 있었다.
일정 압박: 시연 일정이 약 2주 뒤로 잡혀 있었다.
- 시연을 위해 라벨링 파이프라인을 돌려야 했다
- 카메라 약 3,000대에서 영상을 수신하고, 프레임을 추출해 MinIO에 저장하는 구조
- 파라미터:
duration=200(카메라당 최대 200초 연결),max_frames=100(최대 100장 추출) - 예상 데이터량: 100장 × 3,000대 = 최대 300,000장의 프레임 + annotation JSON
- 루트 파티션 잔여 용량 23GB로는 파이프라인 실행 자체가 불가능
시간 압박: 폐쇄망 환경에서 원격 지원과 현장 출장이 병행되는 구조였다.
- 현장 서버가 폐쇄망에 있어 직접 SSH 접속이 불가능했다. 소프트웨어 작업(클러스터 상태 확인, 원인 분석, Helm 재배포 등)은 현장 담당자와 화면 공유를 통해 원격으로 안내해야 했다
- SSD 물리 장착은 원격으로 해결할 수 없는 작업이라, 직접 현장에 가서 디스크를 설치했다
- 원격 세션과 현장 출장의 일정을 조율하고, 문제 확인 → SSD 장착 → 소프트웨어 해결을 최소한의 왕복으로 끝내야 했다
원인 분석
1차 시도: SSD 증설 후 existingClaim 재설정
루트 파티션이 가득 찼으니, 우선 별도 스토리지를 확보해야 했다. 서버에 SSD를 증설하고 /mnt/data에 마운트한 뒤, SSD 마운트 경로에 PV/PVC를 만들었다(상세 과정은 해결 섹션에서 다룬다). 그리고 MinIO 공식 Helm chart의 README - Existing PersistentVolumeClaim 안내를 참고해 persistence.existingClaim에 새 PVC를 지정하고 재배포했다.
# values.yaml (1차 시도)
persistence:
enabled: true
existingClaim: "minio-pvc"
재배포 후에도 데이터가 여전히 /var/lib/rancher/k3s/storage에 쌓이고 있었다. existingClaim이 적용되지 않았다. values.yaml에서 persistence.existingClaim을 분명히 지정했는데, 실제로는 local-path StorageClass가 PVC를 자동 생성해 루트 파티션에 데이터를 쌓고 있었다. 설정한 existingClaim은 어디로 간 것인가?
values.yaml 확인: 설정이 틀린 건가?
설정 방법 자체가 잘못된 건 아닌지, values.yaml의 persistence 섹션을 직접 확인했다.
## Use an existing PVC to persist data
## A manually managed Persistent Volume and Claim
## Requires persistence.enabled: true
## If defined, PVC must be created manually before volume will be bound
existingClaim: ""
existingClaim 필드가 분명히 존재하고, 주석에도 “manually managed Persistent Volume and Claim”이라고 안내되어 있다. README 안내대로 설정한 것이 맞았다. 설정 자체에는 문제가 없었다.
그런데 values.yaml을 더 살펴보다가, 상단의 mode 필드가 눈에 들어왔다.
## MinIO running mode
## Options: "distributed" or "standalone"
mode: distributed
기본값이 distributed다. 처음 배포할 때 mode를 별도로 지정하지 않았으니, distributed 모드로 배포된 것이다. 이 mode에 따라 existingClaim의 동작이 달라지는 건 아닐까?
템플릿 코드 분석: 원인 발견
distributed와 standalone이 어떤 차이를 만드는지 확인하기 위해, Helm chart의 템플릿 코드를 직접 들여다보았다.
statefulset.yaml — distributed 모드
statefulset.yaml 템플릿은 첫 줄부터 조건이 걸려 있다.
{{- if eq .Values.mode "distributed" }}
mode가 distributed일 때만 이 템플릿이 렌더링된다. 스토리지는 volumeClaimTemplates로 정의된다.
volumeClaimTemplates:
- metadata:
name: export
spec:
accessModes: [ ]
storageClassName:
resources:
requests:
storage:
StatefulSet의 volumeClaimTemplates는 각 Pod마다 PVC를 자동으로 생성한다. export라는 이름과 Pod ordinal이 결합되어 export-minio-0, export-minio-1, export-minio-2와 같은 PVC가 만들어진다.
이 템플릿 어디에도 existingClaim을 참조하는 로직이 없다. persistence.enabled, persistence.storageClass, persistence.size는 사용하지만, persistence.existingClaim은 완전히 무시된다.
deployment.yaml — standalone 모드
반면 deployment.yaml 템플릿은 다른 구조다.
{{- if eq .Values.mode "standalone" }}
mode가 standalone일 때만 렌더링되고, 볼륨 정의에서 existingClaim을 직접 참조한다.
volumes:
- name: export
{{- if .Values.persistence.enabled }}
persistentVolumeClaim:
claimName: {{ .Values.persistence.existingClaim | default (include "minio.fullname" .) }}
{{- else }}
emptyDir: {}
{{- end }}
existingClaim이 설정되어 있으면 해당 PVC를, 아니면 chart 이름으로 생성된 PVC를 참조한다. existingClaim은 이 템플릿에서만 동작한다.
핵심: 구조적 충돌
결과적으로 정리해 보면, values.yaml에서 설정할 수 있는 existingClaim 값은 distributed 모드, 즉 MinIO가 Statefulset으로 실행될 때는 무시된다.
| 구분 | distributed (기본값) |
standalone |
|---|---|---|
| 템플릿 | statefulset.yaml | deployment.yaml |
| 리소스 | StatefulSet | Deployment |
| Pod 수 | 여러 개 (erasure coding) | 1개 |
| PVC 생성 | volumeClaimTemplates로 자동 생성 |
existingClaim 또는 기본 PVC 참조 |
existingClaim 동작 |
무시됨 | 정상 동작 |
이것은 버그라기보다 distributed 모드가 필요로 하는 StatefulSet의 설계와 existingClaim의 본질적인 충돌이다. 아래에서 두 층위로 나눠 살펴본다.
distributed 모드와 Statefulset
MinIO의 distributed 모드는 erasure coding으로 데이터를 보호한다. 오브젝트를 데이터 블록과 패리티 블록으로 나눠 erasure set을 이루는 드라이브들에 분산 저장하며, 드라이브 여러 개가 죽어도 나머지 블록으로 복구할 수 있다.
Erasure set은 드라이브(스토리지)들의 묶음인데, 이 Helm 배포에서는 Pod 하나가 드라이브 하나(마운트된 볼륨)를 담당한다. MinIO는 초기화 시점에 erasure set 구성을 확정한다. Pod 재시작 후 드라이브 구성이 바뀌면 MinIO가 인식하는 erasure set이 흔들릴 수 있다. 따라서 Distributed 모드에서는 Pod가 재시작돼도 항상 같은 드라이브에 연결돼야 한다.
그러나 Deployment는 Pod 재시작 시 어느 PVC를 마운트할지 보장하지 않는다. 재시작된 Pod이 이전과 다른 PVC에 붙거나, 여러 Pod이 같은 PVC에 마운트를 시도할 수 있다. 극단적으로는 두 Pod가 같은 노드에 스케줄되어 한 PVC를 공유하게 되거나, 반대로 한 Pod만 PVC에 붙고 나머지는 마운트에 실패해 Pending에 머무를 수도 있다. 따라서 Pod와 드라이브의 1:1 고정이 필요한 distributed 모드에는 StatefulSet이 필연적이다.
그래서 existingClaim이 무시되는 이유
StatefulSet은 Pod마다 독립된 PVC를 갖는 것을 전제로 설계된다. existingClaim으로 PVC 하나를 지정하는 것은 모든 Pod이 같은 스토리지를 가리키라는 뜻이 되어 이 전제와 충돌한다. 그래서 statefulset.yaml 템플릿에는 existingClaim을 참조하는 로직 자체가 없다.
이는 템플릿 설계의 문제지만, 스토리지 접근 모드 측면에서도 같은 결론에 이른다. K3s의 local-path-provisioner처럼 ReadWriteOnce 접근 모드를 사용하는 hostPath 기반 스토리지는 하나의 PVC를 여러 Pod이 동시에 마운트할 수 없다. 설령 템플릿이 existingClaim을 참조했더라도 이 환경에서는 기술적으로 동작하지 않았을 것이다.
참고: distributed(Statefulset) + RWX 스토리지였다면?
NFS처럼 ReadWriteMany를 지원하는 스토리지였다면 하나의 PVC를 여러 Pod이 동시에 마운트하는 것은 기술적으로 가능하다. 그러나 두 가지 이유로 distributed 모드에서는 의미가 없다.
첫째, 템플릿 구조의 문제다. statefulset.yaml이 existingClaim을 참조하는 로직 자체가 없으므로, RWX PVC를 지정해도 어차피 무시된다.
둘째, erasure coding의 전제가 깨진다. erasure coding은 물리적으로 독립된 드라이브 여러 개에 블록을 나눠서 저장해야 의미가 있다. RWX로 PVC 하나를 공유하면 Pod이 여러 개여도 결국 같은 스토리지 하나를 보는 것이므로, 그 스토리지가 죽으면 모든 블록이 한꺼번에 날아간다. 실제로 이런 이유에서인지, MinIO GitHub Discussion #16506을 보면, MinIO 측 답변자가 네트워크 PVC 사용 시 ReadWriteOnce(RWO)만 지원하고 ReadWriteMany(RWX)는 지원하지 않으며, RWX는 자기 책임 하에 실험적으로만 사용할 수 있다고 밝히고 있다.
참고: standalone(Deployment) + RWX 스토리지였다면?
트러블슈팅 과정의 핵심이 distributed 모드를 살펴 보는 것이긴 하지만, 동작 비교 차원에서 standalone 모드일 경우를 상상해 보자. 결론부터 말하자면, 동작은 하지만 의미가 없다.
standalone 모드는 Pod이 1개이므로 RWX든 RWO든 마운트하는 Pod이 어차피 하나뿐이다. 접근 모드가 실질적으로 의미 없고, deployment.yaml이 existingClaim을 정상적으로 참조하므로 RWX PVC를 지정해도 그냥 동작한다. 다만 RWX는 여러 Pod이 같은 스토리지를 동시에 읽고 써야 하는 상황을 위한 접근 모드다. standalone은 그 상황 자체가 없으므로 RWX를 쓸 이유가 없다.
문제
진짜 문제는 이 제약이 어디에도 문서화되어 있지 않다는 것이다. values.yaml의 existingClaim 주석에도, README의 Existing PersistentVolumeClaim 섹션에도, mode에 따른 제한사항은 언급되지 않았다. 설정은 받아들이되 조용히 무시하는, 전형적인 silent failure다.
K3s local-path provisioner
K3s는 기본 StorageClass로 local-path를 제공한다. 이 프로비저너는 PVC가 요청되면 /var/lib/rancher/k3s/storage 경로 아래에 hostPath 기반으로 PV를 동적 생성한다. 이 경로는 루트 파티션(/)에 위치하므로, PV에 데이터가 쌓이면 곧바로 루트 파티션 사용량이 증가한다.
정리
결국 문제의 전체 경로는 다음과 같다.
values.yaml: mode 미지정 → distributed (기본값)
↓
Helm이 statefulset.yaml 렌더링 (deployment.yaml은 무시)
↓
volumeClaimTemplates로 export-minio-{0,1,2} PVC 자동 생성
↓
persistence.existingClaim 무시됨 (statefulset.yaml에 참조 로직 자체가 없음)
↓
local-path StorageClass가 /var/lib/rancher/k3s/storage에 PV 생성
↓
MinIO 데이터가 루트 파티션에 축적 → 용량 부족
해결
대안 검토 및 의사 결정
원인 분석을 통해 distributed 모드에서는 existingClaim이 구조적으로 무시된다는 것을 확인했다. SSD 증설과 PV/PVC 준비는 1차 시도에서 이미 완료한 상태였으므로, 남은 문제는 어떤 방식으로 MinIO가 SSD의 PV를 사용하게 할 것인가였다. 세 가지 방법을 검토했다.
대안 1: local-path provisioner 기본 경로 변경
K3s의 local-path-provisioner는 kube-system 네임스페이스의 ConfigMap(local-path-config)에서 PV 생성 경로를 관리한다. 이 경로를 /var/lib/rancher/k3s/storage → /mnt/data(SSD)로 변경하면, 이후 생성되는 PVC가 SSD에 프로비저닝된다. distributed 모드를 유지하면서 디스크 문제만 해결하는 방법이다.
검토했으나, 아래와 같은 이유로 기각했다:
- 기존 PVC가 이전되지 않는다: 경로를 바꿔도 이미 생성된
export-minio-0/1/2PVC는 여전히 기존 경로를 가리킨다. 결국 PVC 삭제 → 재생성 → 데이터 이관이 필요하다 - 클러스터 전역에 영향: local-path provisioner 설정 변경은 MinIO뿐 아니라 Label Studio 등 모든 워크로드의 이후 PVC 생성에 영향을 준다. 폐쇄망 프로덕션 클러스터에서 전역 설정을 건드리는 건 부담이 크다
- K3s 업그레이드 시 리셋 위험: K3s가 업그레이드되면 내부 컴포넌트가 재배포되며 ConfigMap이 초기화될 수 있다. 설정이 조용히 원복되면 같은 문제가 재발한다
- existingClaim 문제는 여전히 남는다: 경로를 바꿔도 distributed 모드의
volumeClaimTemplates가 PVC를 자동 생성하는 구조는 변하지 않는다. 특정 PV/PVC를 명시적으로 지정하려는 원래 의도와 맞지 않는다
대안 2: distributed 모드 유지 + custom StorageClass
SSD 경로를 사용하는 custom StorageClass를 등록하고, volumeClaimTemplates가 이를 참조하도록 values.yaml의 persistence.storageClass를 변경하는 방법이다. distributed 모드와 erasure coding을 유지할 수 있다.
이 대안 역시 검토했으나, 아래와 같은 이유로 기각했다:
- 동작은 하겠지만, 클러스터 상황 상 굳이 distributed 모드로 운영할 이유가 없어 불필요한 복잡성이다
최종 결정: standalone 전환
| 방법 | 디스크 문제 해결 | existingClaim 사용 | 영향 범위 | 복잡도 |
|---|---|---|---|---|
| local-path 경로 변경 | O (이후 PVC만) | X | 클러스터 전역 | 중 |
| distributed + custom StorageClass | O | X | MinIO만 | 중 |
| standalone 전환 | O | O | MinIO만 | 낮음 |
결론적으로 standalone 전환이 합리적이라고 판단했다. standalone 모드는 deployment.yaml에 replicas: 1이 하드코딩되어 있어 Pod가 항상 1개만 뜨지만, 이 현장은 폐쇄망 환경이라 클러스터 규모가 크지 않았고, distributed 모드의 핵심인 erasure coding(분산 복제/복구)은 실질적인 이점이 크지 않다고 판단했다. 데이터 보호는 별도 백업 정책(주기적 스냅샷 + 외부 저장소 복제)으로 대응하는 것이 이 환경에 맞다.
이 결정에 따른 해결 과정은 다음과 같다.
- SSD 증설 →
/mnt/data에 마운트 - SSD 경로에 PV 디렉토리 생성 → PV/PVC 매니페스트 작성
- MinIO values.yaml에서
mode: standalone+existingClaim지정 → 재배포
SSD 물리 장착, 파티션 생성, 포맷(
mkfs.ext4), fstab 등록, 마운트 적용 과정의 상세는 리눅스 스토리지 기초 시리즈에서 다룬다. 여기서는 Kubernetes 관점의 해결 과정에 집중한다.
SSD 마운트 (요약)
서버에 SSD 2개를 SATA 포트로 장착하고, /mnt/data에 ext4로 마운트했다. fstab에 UUID로 등록하여 부팅 시 자동 마운트되도록 설정했다.


$ df -h | grep mnt
/dev/sda 3.6T 65G 3.4T 2% /mnt/data
PV 디렉토리 생성 및 권한 설정
SSD 마운트 경로 아래에 MinIO PV용 디렉토리를 생성했다.
$ cd /mnt/data
$ sudo mkdir minio-pv
$ sudo chmod 777 minio-pv
권한을 777로 설정하지 않으면 MinIO Pod가 디렉토리에 접근하지 못한다. sudo mkdir로 만든 디렉토리는 호스트에서 root 소유·기본 755 권한이고, MinIO 컨테이너는 non-root 사용자로 실행된다. hostPath로 마운트된 디렉토리는 그 소유·권한이 그대로 전달되므로, 755에서는 others에게 쓰기가 허용되지 않아 MinIO 프로세스가 쓰기를 시도할 때 접근이 거부된다. chmod 777은 others에게도 rwx를 주어 이 문제를 피한다.
ERROR Unable to use the driver /export: driver access denied
주의:
chmod 777은 빠른 해결을 위한 임시 조치다. production 환경에서는 Pod의securityContext.fsGroup을 설정하거나, initContainer에서chown을 실행하는 방식이 권장된다.# Helm values.yaml 예시 (MinIO Bitnami 이미지 등 UID 1001 사용 시) podSecurityContext: fsGroup: 1001 containerSecurityContext: runAsUser: 1001
PV/PVC 매니페스트 작성
apiVersion: v1
kind: PersistentVolume
metadata:
name: minio-pv
spec:
capacity:
storage: 3Ti
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: minio-storage-class
hostPath: # 노드 경로를 그대로 마운트. 스케줄러가 "이 PV가 어느 노드에 있는지" 모름
path: "/mnt/data/minio-pv"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- server01-mlops01
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: minio-pvc
namespace: minio
spec:
accessModes:
- ReadWriteOnce
storageClassName: minio-storage-class
resources:
requests:
storage: 1Ti
hostPath PV에 nodeAffinity를 수동으로 지정했다. SSD가 장착된 노드(server01-mlops01)에서만 PV가 사용되도록 하기 위함이다. PV의 capacity를 3Ti(SSD 전체 용량)로, PVC의 requests를 1Ti로 설정한 것은 의도적이다. PVC의 requests.storage는 “최소 이만큼의 용량이 필요하다”는 하한이므로, 3Ti PV가 이 요청을 만족하여 바인딩된다. 실제로 MinIO는 PV의 전체 용량을 사용할 수 있다.
$ kubectl apply -f minio-pv-pvc.yaml
values.yaml 변경 및 재배포
MinIO 설정을 변경해 재배포한다.
persistence:
enabled: true
existingClaim: "minio-pvc"
mode: standalone
# 다중 노드 클러스터에서 hostPath PV를 쓸 경우, 해당 노드로 스케줄을 고정하려면 추가:
# 참고: https://github.com/minio/minio/blob/master/helm/minio/values.yaml#L266
# nodeSelector:
# kubernetes.io/hostname: server01-mlops01
$ helm uninstall minio -n minio
$ helm install minio -n minio ./minio-5.2.0.tgz --values minio-values.yaml
변경 사항은 두 가지다.
mode: standalone: Deployment로 배포되어existingClaim이 정상 동작하도록 변경persistence.existingClaim: "minio-pvc": 위에서 생성한 SSD 경로의 PVC를 지정
참고: 더 나은 구성 — local PV
당시에는 hostPath + nodeAffinity로 PV를 구성했다. MinIO Pod에 nodeSelector를 걸었는지 기억은 나지 않지만, PV에 nodeAffinity를 설정해 두었으므로 스케줄러가 이를 인식하여 올바른 노드에 배치했다. 관련해 Kubernetes PV 공식 문서는 아래와 같이 설명한다.
Pods that use a PV will only be scheduled to nodes that are selected by the node affinity.
이는 볼륨 타입을 가리지 않으므로 hostPath PV에도 적용된다. 동작에는 문제가 없다.
다만 복기해 보니, hostPath에는 두 가지 아쉬운 점이 있다. 첫째, nodeAffinity가 선택 사항이라 빠뜨려도 API 검증에서 걸리지 않는다. 둘째, hostPath 전용 문서에는 스케줄러의 nodeAffinity 인식에 대한 별도 언급이 없어, 동작의 근거를 일반 PV 문서에서 찾아야 한다. 지금 돌이켜 보면 Kubernetes가 노드 로컬 스토리지를 표현하기 위해 제공하는 local 볼륨 타입을 쓰는 편이 더 나았다. local은 nodeAffinity가 API 레벨에서 필수이고, 전용 문서에서 스케줄러 인식을 명시적으로 보장한다.
local PV
local은 노드에 물리적으로 부착된 로컬 스토리지(디스크, 파티션, 디렉토리 등)를 나타내는 PV 소스 타입이다.
참고: PV 소스
Kubernetes PV에는 해당 PV의 실제 스토리지가 어디에 있는지를 지정하기 위한 스토리지 타입이 있다:
hostPath,nfs,csi,local등.local은 그 중 하나다. 공식 문서에서도 “A local volume represents a mounted local storage device such as a disk, partition or directory.”라고 표현하는데, mounted local storage device라는 것이 PV 소스임을 나타낸다.
local과hostPath는 모두 노드의 로컬 스토리지에 접근하지만, 모델링하는 대상이 다르다.hostPath는 “이 경로를 마운트하라”로, 어느 노드의 경로인지는 hostPath의 관심사가 아니다. 따라서 nodeAffinity는 선택 사항이다. 반면local은 “이 노드에 물리적으로 부착된 이 스토리지 장치”를 모델링한다. node-3에 꽂힌 SSD는 node-3에만 존재하므로, “어떤 스토리지인가”에 “어떤 노드에 있는가”가 본질적으로 포함된다. 노드 정보 없이는 PV 정의 자체가 불완전하므로,local에서 nodeAffinity는 필수다.
hostPath와 local이 가리키는 대상은 같다 — 둘 다 노드의 로컬 스토리지(디스크, 파티션, 디렉토리)에 접근한다. 차이는 접근 경로, 즉 PV 계층을 강제하는지 여부다.
hostPath는 두 가지 방식으로 쓸 수 있다. Pod spec의 spec.volumes[].hostPath에 경로를 넣어 PV/PVC 없이 직접 마운트하거나, PV의 .spec.hostPath에 경로를 지정해 PVC를 통해 접근할 수 있다. 반면 local은 PV의 .spec.local.path로만 존재하며, Pod spec에서 직접 쓰는 방법이 없다. 반드시 PV/PVC를 거쳐야 한다.
이 “강제”가 local의 핵심 설계다. PV 계층을 반드시 거치니까:
- nodeAffinity가 필수다 → 빠뜨릴 수 없으므로 스케줄러가 항상 인식한다
- 관리자가 노출 경로를 통제한다 → Pod가 임의 경로를 마운트할 수 없다
- StorageClass 연동이 자연스럽다 →
WaitForFirstConsumer등 바인딩 제어가 가능하다
hostPath를 Pod spec에서 직접 쓰면 이런 보호가 전혀 없이 노드 파일시스템의 아무 경로나 마운트할 수 있고, 이것이 공식 문서가 보안 위험을 경고하는 이유다. hostPath를 PV 소스로 쓰면 PV 계층은 거치지만, nodeAffinity가 선택 사항이라 빠뜨릴 수 있고, 보안 경고도 그대로 남는다.
이 구조적 차이에서 파생되는 실질적인 차이를 정리해 보면 아래와 같다.
| 구분 | hostPath |
local |
|---|---|---|
| 정의 | 노드의 특정 경로를 그대로 마운트 | 노드 로컬 스토리지를 표현하는 전용 볼륨 타입 |
| 사용 범위 | Pod spec에서 직접 사용 가능 + PV 소스로도 사용 가능 | PV 소스로만 존재. Pod spec에서 직접 사용 불가 |
| nodeAffinity | 선택 사항. 일반 PV 문서상 스케줄러가 인식하며 hostPath PV에도 적용되지만, hostPath 전용 문서에는 별도 언급 없음 |
필수 (없으면 API validation error). 전용 문서에서 스케줄러 인식을 명시 |
| Pod nodeSelector | nodeAffinity를 설정했다면 스케줄러가 인식하므로 기능적으로는 불필요. 다만 nodeAffinity가 선택 사항이라 누락 가능성이 있어, 방어적으로 거는 것을 권장 | 불필요 — nodeAffinity가 필수이므로 누락 자체가 불가능 |
| volumeBindingMode | StorageClass 설정에 따름. WaitForFirstConsumer 적용 가능하나, 공식 문서에서 hostPath와의 조합을 별도로 안내하지는 않음 |
공식 문서에서 WaitForFirstConsumer와의 조합을 명시적으로 안내 |
| 보안 | Pod spec에서 직접 사용 시 노드의 아무 경로나 마운트 가능 → 공식 문서에서 보안 위험 경고, 사용 자제 권장 | 반드시 PV/PVC를 거쳐야 하므로 관리자가 노출 경로를 통제 |
매니페스트 제안
앞서 작성한 hostPath 기반 PV/PVC에서 local PV로 전환할 때, PV 매니페스트의 차이는 hostPath → local로 변경하는 것뿐이다. PVC는 동일하다. 다만 local PV의 이점을 최대로 활용하려면 StorageClass도 함께 구성하는 것이 좋다(아래에서 별도로 다룬다).
apiVersion: v1
kind: PersistentVolume
metadata:
name: minio-pv
spec:
capacity:
storage: 3Ti
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: minio-storage-class
local: # hostPath → local로만 변경
path: /mnt/data/minio-pv
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- server01-mlops01
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: minio-pvc
namespace: minio
spec:
accessModes:
- ReadWriteOnce
storageClassName: minio-storage-class
resources:
requests:
storage: 1Ti
여기에 StorageClass를 함께 두면, local PV의 이점을 최대로 활용할 수 있다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: minio-storage-class
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
provisioner: kubernetes.io/no-provisioner는 동적 프로비저닝을 사용하지 않는다는 선언이다. PV를 수동으로 만들거나 외부 프로비저너(local static provisioner 등)가 미리 생성해 두는 경우에 쓴다. 핵심은 volumeBindingMode: WaitForFirstConsumer다.
효과
local PV 자체의 이점과, WaitForFirstConsumer StorageClass와 조합했을 때의 이점이 있다.
nodeAffinity의 강제성과 문서 명시성
앞서 살펴본 대로 local PV는 nodeAffinity가 필수이므로, 설정 누락으로 Pod가 엉뚱한 노드에 스케줄되는 문제가 원천 차단된다. 또한 전용 문서에서 “The system is aware of the volume’s node constraints by looking at the node affinity on the PersistentVolume”이라고 명시적으로 보장하므로, 동작의 근거를 일반 PV 문서에서 찾을 필요가 없다. Pod에 nodeSelector를 따로 걸 필요 없이 PV 한 곳에만 의도가 드러나므로 유지보수가 수월하다.
바인딩 지연 (WaitForFirstConsumer)
별도 StorageClass 없이 PVC를 만들면 기본적으로 Immediate 바인딩이 일어나, Pod가 스케줄되기 전에 PVC가 PV와 먼저 바인딩된다. 이 경우 나중에 Pod 스케줄 시 CPU·메모리 등 다른 제약과 맞지 않아 Pending에 빠질 수 있다. WaitForFirstConsumer를 쓰면 Pod가 어느 노드에 갈지 정해질 때까지 바인딩을 미루므로, 자원·노드 제약에 맞게 배치된 뒤 바인딩되어 스케줄링이 안정적이다.
hostPath의 보안 위협
Kubernetes 공식 문서는 hostPath 볼륨에 대해 다수의 보안 위험이 있다고 경고하며, 가능한 한 사용을 피하라고 권장한다(Volumes — hostPath).
HostPath volumes present many security risks, and it is a best practice to avoid the use of HostPaths when possible. When a HostPath volume must be used, it should be scoped to only the required file or directory, and mounted as ReadOnly.
같은 문서는 대안으로 local PV를 명시적으로 권장한다
For example, define a local PersistentVolume, and use that instead.”
핵심 위험은 hostPath가 Pod spec에서 직접 사용 가능하다는 점이다. Pod을 생성할 수 있는 사용자라면 누구나 spec.volumes[].hostPath.path에 노드의 아무 경로(/etc/shadow, kubelet 자격 증명 등)를 지정하여 PV/PVC 없이 마운트할 수 있다. 반면 local은 PV 소스로만 존재하며 Pod spec에서 직접 사용할 수 없다. 반드시 PV/PVC를 거쳐야 하므로, 어떤 경로를 노출할지는 클러스터 관리자가 통제한다.
이 글의 맥락(관리자가 PV를 직접 만드는 경우)에서는 hostPath PV든 local PV든 관리자가 경로를 지정하므로, PV 수준의 보안 차이는 크지 않다. 그러나 hostPath라는 타입 자체가 Pod spec 직접 사용이라는 넓은 위험 표면을 갖고 있고, PodSecurity 정책에서도 hostPath는 제한 대상으로 분류된다. 노드 로컬 스토리지가 필요할 때 local PV를 쓰면 이 위험 표면을 원천적으로 피할 수 있다.
데이터 이관 삽질기
MinIO를 재배포한 뒤, 기존 데이터(/var/lib/rancher/k3s/storage 아래의 PVC 디렉토리)를 새 PV 경로(/mnt/data/minio-pv)로 이관해야 했다. 단순해 보이는 작업이었지만, 예상치 못한 문제들이 연달아 발생했다.
파일 복사
1차 시도: cp로 복사 → 버킷이 보이지 않음
$ sudo cp -r /var/lib/rancher/k3s/storage/pvc-84164975-..._minio_export-minio-1/* /mnt/data/minio-pv/
복사는 완료되었으나, MinIO 콘솔에서 버킷이 하나도 보이지 않았다. 파일 자체는 디스크에 존재하는데 MinIO가 인식하지 못하는 상태였다.
원인: glob 패턴에 의한 숨김 파일 누락
MinIO는 버킷 데이터 외에 .minio.sys/ 등의 숨김 디렉토리에 메타데이터를 저장한다. 버킷 목록, 오브젝트 메타데이터, IAM 정보 등이 이 숨김 파일들에 포함되어 있다. 문제는 소스 경로에 사용한 glob 패턴(*)이었다. 셸의 *는 .으로 시작하는 파일·디렉토리를 매칭하지 않으므로, .minio.sys/ 등 MinIO 메타데이터가 통째로 누락되었다. 소스 디렉토리를 명시적 경로로 지정(cp -r 소스디렉토리/ 대상/)했다면 이 문제는 발생하지 않았을 것이다.
2차 시도: rsync로 숨김 파일 포함 복사 → 성공
$ sudo rsync -av /var/lib/rancher/k3s/storage/pvc-84164975-..._minio_export-minio-1/ /mnt/data/minio-pv/
rsync -a(archive 모드)는 숨김 파일, 심볼릭 링크, 퍼미션 등을 보존하여 복사한다. 이 방식으로 복사한 뒤에는 MinIO 콘솔에서 버킷이 정상적으로 표시되었다.
glob 패턴 대신 명시적 경로를 사용하면
cp -r이나cp -a로도 숨김 파일을 포함하여 복사할 수 있다. 다만 대용량 데이터 이관에서는rsync가 중단 후 재개(--partial), 진행률 표시(--progress) 등에서 유리하다.
Disk Pressure로 인한 Pod 축출
데이터 이관 자체는 루트 파티션에서 SSD로 복사하는 작업이므로, 루트 파티션의 사용량을 늘리지는 않는다. 문제는 이관을 준비하는 과정에서, MinIO가 아직 루트 파티션의 기존 PV에 데이터를 쓰고 있었다는 점이다. 잔여 용량 23GB 상태에서 MinIO가 계속 데이터를 쌓으면서 kubelet의 hard eviction threshold를 넘어섰고, Pod 축출이 시작되었다. 에러 메시지가 ephemeral-storage를 명시하고 있는데, 이는 kubelet의 nodefs.available 기본 hard eviction threshold(15%) 기준으로 축출이 발생했음을 의미한다. MinIO뿐 아니라 같은 노드의 다른 워크로드에도 영향이 미쳤다.
Status: Failed
Reason: Evicted
Message: The node was low on resource: ephemeral-storage.
Threshold quantity: 12439225938, available: 34765552Ki.
BestEffort QoS 클래스의 Pod부터 축출되며, 축출된 Pod는 데이터 복사 중간에 죽어버린다. 이관 작업을 안전하게 진행하려면 MinIO Pod를 먼저 중지(scale down)한 상태에서 복사해야 했다.
PV 재배포 시 경로 변경 불가
기존 PV의 hostPath.path를 변경하려고 시도했으나, PV 스펙은 생성 후 변경할 수 없다(immutable). 경로를 바꾸려면 기존 PV/PVC를 삭제하고 새로 생성해야 한다. StatefulSet이 자동 생성한 PVC(export-minio-*)는 StatefulSet을 삭제해도 남아 있으므로(데이터 보존 설계), 수동으로 정리가 필요하다.
$ kubectl delete pvc export-minio-0 export-minio-1 export-minio-2 -n minio
결과
재배포 후 MinIO 콘솔에서 버킷이 정상 표시되었고, 이후 라벨링 파이프라인을 수차례 실행하면서 데이터가 SSD에 정상적으로 축적되는 것을 확인했다.
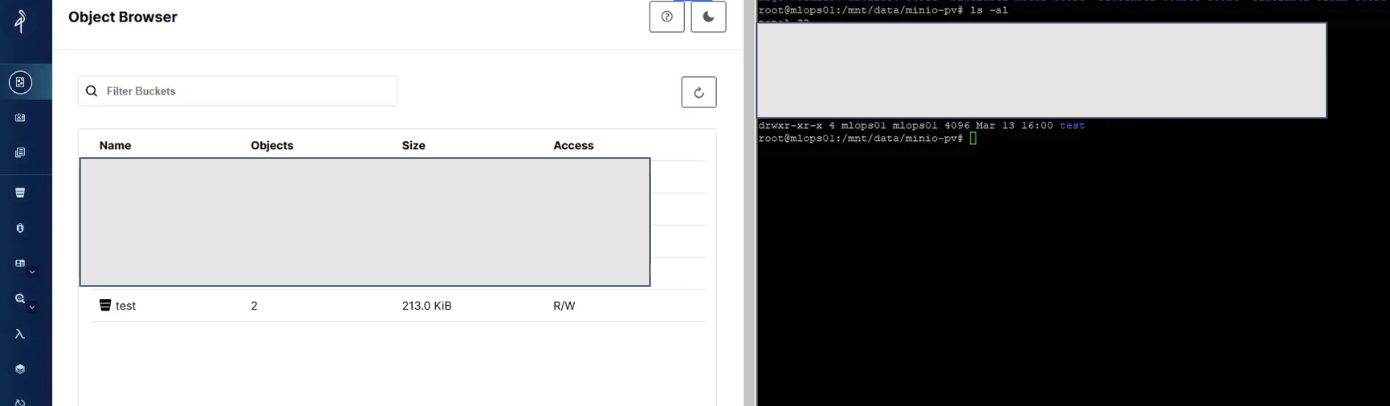
파이프라인을 여러 차례 실행한 뒤 디스크 사용량을 확인했을 때, 데이터가 SSD 경로에 쌓이고 루트 파티션은 안정적으로 유지되고 있었다.
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-lv--0 232G 80G 140G 37% /
/dev/sda 3.6T 960G 2.5T 28% /mnt/data
- 루트 파티션: 90% → 37%로 감소 (MinIO 데이터 118GB가 빠져나간 효과)
- SSD(
/mnt/data): 파이프라인 실행으로 약 960GB 데이터 축적, 잔여 공간 2.5TB 확보
에필로그: PR #21689과 레포 archive
이 문제를 겪으면서, distributed 모드에서 existingClaim이 조용히 무시되는 것이 다른 사용자들에게도 혼란을 줄 수 있겠다는 생각이 들었다. 그래서 MinIO 공식 레포에 PR #21689를 올렸다.
PR 내용
- NOTES.txt:
distributed모드 +existingClaim설정 시 경고 메시지 출력 - values.yaml:
existingClaim의 제한사항을 명시하는 주석 보강 - 대안 제시: standalone 전환 또는 custom StorageClass 사용
WARNING: persistence.existingClaim is set but will be ignored in distributed mode.
In distributed mode, MinIO automatically creates multiple PersistentVolumeClaims
using StatefulSet's volumeClaimTemplates for erasure coding.
Your specified PVC 'my-custom-pvc' will not be used.
결과
PR을 올린 것은 2025년 11월이었다. 리뷰나 코멘트 없이 open 상태로 남아 있었고, 2026년 2월 13일 레포 자체가 archive 되면서 PR은 영구히 열린 상태로 남게 되었다.
MinIO 레포 archive는 갑작스러운 것이 아니라, 수 년에 걸친 변화의 끝이었다.
| 시점 | 사건 |
|---|---|
| 2021년 | Apache 2.0 → GNU AGPLv3 라이선스 변경 |
| 2022~2023년 | Nutanix, Weka 등 라이선스 위반 소송 |
| 2025년 5월 | 커뮤니티 에디션에서 Admin Console 제거 |
| 2025년 10월 | 보안 취약점 공개 시점에 바이너리/Docker 배포 중단 |
| 2025년 12월 | 유지보수 모드 선언 |
| 2026년 2월 | 레포 archive (read-only 전환) |
MinIO는 사실상 오픈소스 프로젝트로서의 생명을 마감하고, 상용 제품(AIStor)으로 완전히 전환했다. AGPLv3 라이선스 덕분에 커뮤니티 포크(Pigsty 등)가 가능하긴 하지만, 공식 Helm chart가 더 이상 관리되지 않는다는 점은 운영 환경에서 MinIO를 사용하는 모든 팀이 인지해야 할 사안이다.
돌이켜 보면, 이 PR은 머지되지 못했지만, 문제를 분석하고 해결 방안을 정리하는 과정 자체가 StatefulSet의 스토리지 동작, Helm 템플릿의 조건부 렌더링, K3s의 StorageClass 구조를 깊이 이해하는 계기가 되었다.
참고
디스크 증설 후 마운트
SSD 인식 확인
서버에 SSD를 물리적으로 장착한 뒤, 리눅스에서 디스크 인식 여부 확인
sudo fdisk -l
Disk /dev/sda: 1.82 TiB, 2000398034016 bytes, 3907029168 sectors
Disk model: Samsung SSD 870
Units: sectors of 1 * 512 = 512 bytes
...
Disk /dev/sdb: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Samsung SSD 870
Units: sectors of 1 * 512 = 512 bytes
- 새로 장착한 SSD가 /dev/sda, /dev/sdb 등으로 표시되는지 확인
- 만약 인식되지 않으면 케이블 연결, SATA 포트 등을 점검해야 함
파티션 생성 및 포맷
fdisk를 이용해 새 SSD에 파티션을 생성하고, ext4 파일 시스템으로 포맷해야 함
sudo fdisk /dev/sda
n→p→Enter→Enter→w순서로 파티션 생성 후 저장
sudo mkfs.ext4 /dev/sda
mke2fs 1.47.0 (5-Feb-2023)
Discarding device blocks: done
Creating filesystem with 488278646 4k blocks and 122101760 inodes
Filesystem UUID: <uuid> # uuid 확인
Superblock backups stored on blocks:
....
- 출력 중에 block device ID가
UUID=<uuid>줄을 통해 표시되므로, 나중에 fstab에 등록하기 위해 복사해 둠
마운트 경로 생성
SSD를 마운트할 디렉토리를 생성해야 함
sudo mkdir -p /mnt/data
sudo mkdir -p /mnt/sdb
sudo mkdir -p /mnt/sdc
/mnt/data를 주 마운트 경로로 사용할 예정
fstab 등록 (자동 마운트 설정)
/etc/fstab 파일을 수정하여 부팅 시 자동으로 마운트되도록 설정함
sudo blkid
/dev/sda: UUID="abcd-1234" TYPE="ext4"
/dev/sdb: UUID="efgh-5678" TYPE="ext4"
- UUID 확인
- 디스크 파티션 포맷 시 생성되는 UUID와 동일
참고:
blkid를 통한 UUID 확인$ sudo blkid ... /dev/sda: UUID="<uuid>" BLOCK_SIZE="4096" TYPE="ext4" /dev/sdb: UUID="<uuid>" BLOCK_SIZE="4096" TYPE="ext4" ...
- SSD는 블록 단위로 데이터를 읽고 쓰는 장치(block device)
- 새 디스크 장착 후 포맷 시, block device ID가 생성됨
blkid: block device의 정보를 보여 주는 리눅스 명령어blkid를 통해 각 디스크/파티션의 정보(장치 이름, 파일 시스템 타입, UUID 등) 확인 가능
sudo vi /etc/fstab
UUID=abcd-1234 /mnt/data ext4 defaults 0 0
UUID=efgh-5678 /mnt/sdb ext4 defaults 0 0
- 위와 같이 fstab 설정 추가
-
fstab 설정 추가 후 파일 예시
# /etc/fstab: static file system information. # # Use 'blkid' to print the universally unique identifier for a # device: this may be used with UUID= as a more robust way to name devices # that works even if disks are added and removed. See fstab(5). # # <file system> <mount point> <type> <options> <dump> <pass> # / was on /dev/sda3 during curtin installation UUID=<uuid> /mnt/data ext4 defaults 0 0 # 추가 UUID=<uuid> /mnt/sdb ext4 defaults 0 0 # 추가 ...
마운트 적용
fstab 변경 후 시스템에 적용
sudo mount -a
sudo systemctl daemon-reload
-
mount 시 systemd가 설정 파일을 읽도록 daemon-reload 명령어를 실행하라는 안내 확인 가능
sudo mount -a mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload.
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda 1.8T 28K 1.7T 1% /mnt/data
/dev/sdb 1.8T 28K 1.7T 1% /mnt/sdb
- 마운트 상태 확인
참고:
systemctl daemon-reload리눅스 시스템에서
systemd프로세스로 하여금 설정 파일을 다시 읽도록 강제로 갱신
- 대부분의 리눅스 시스템에서는
systemd라는 init 시스템 사용- 부팅 과정에서
/etc/fstab파일을 읽고, 안에 정의된 파일 시스템을 mount unit으로 변환해 관리함
- 예를 들어,
UUID=abcd-1234 /mnt/data ext4 defaults 0 0와 같은 줄을 읽고,mnt-data.mount와 같은 내부 유닛으로 등록함- 즉,
systemd가 fstab 파일을 읽고 “이 장치를 이렇게 마운트하라”고 기억하고 있는 것- fstab 수정 시,
systemd는 메모리에 예전 내용을 가지고 있기 때문에, 갱신 내용이 반영되지 않음- 따라서 fstab 파일에 새 UUID를 추가하는 등의 수정이 발생했을 때, 해당 내용을 다시 읽도록 명령해야 함
- fstab 고친 직후, mount 관련 경고가 뜰 때는 꼭 실행해 주어야 함
(주의) SSD 제거 시 부팅 문제
- 나중에 SSD를 제거하면, /etc/fstab에 등록된 UUID가 존재하지 않아 부팅이 멈출 수 있음
- 이 경우 fstab에서 해당 항목을 주석 처리하거나 삭제해야 함

댓글남기기