
[EKS] EKS: Public-Public EKS 클러스터 - 5. 워커 노드 내부 확인
서종호(가시다)님의 AWS EKS Workshop Study(AEWS) 1주차 학습 내용을 기반으로 합니다.
TL;DR
이전 글에서는 kubectl과 AWS CLI로 바깥에서 클러스터 구성 요소를 확인했다. 이번 글에서는 SSH로 워커 노드에 접속하여 안에서 확인한다.
- OS: AL2023 (Amazon Linux 2023) 확인
- CRI: containerd 버전,
crictl컨테이너 목록 - kubelet: 서비스 상태, 설정 파일, kubeconfig
- 인증서: CA 인증서 경로,
describe-cluster의certificateAuthority와 비교 - 네트워크: VPC CNI가 만든 ENI, iptables 규칙
- 온프레미스 비교: 경로·설정 방식이 어떻게 다른지
들어가며
온프레미스에서는 배포 후 마스터/워커 노드에 SSH로 접속해서 kubelet, etcd, 인증서, CNI 설정 등을 직접 확인했다. EKS에서 컨트롤 플레인은 AWS 관리 영역이라 접근할 수 없지만, 워커 노드는 일반 EC2 인스턴스이므로 SSH로 접속할 수 있다.
SSH 접속
노드 IP 확인
먼저 워커 노드의 공인 IP를 확인한다. AWS CLI로 조회하거나 EC2 콘솔에서 직접 확인할 수 있다.
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
------------------------------------------------------------------
| DescribeInstances |
+-------------------+---------------+-----------------+----------+
| InstanceName | PrivateIPAdd | PublicIPAdd | Status |
+-------------------+---------------+-----------------+----------+
| myeks-node-group | 192.168.2.21 | xx.xxx.xxx.xx1 | running |
| myeks-node-group | 192.168.3.96 | xx.xxx.xxx.xx2 | running |
+-------------------+---------------+-----------------+----------+
NODE1=<워커 노드 1 공인 IP>
NODE2=<워커 노드 2 공인 IP>
접속 확인
ping으로 네트워크 도달 여부를 먼저 확인한다. 배포 단계에서 확인한 myeks-node-group-sg 보안그룹이 현재 공인 IP에서 오는 모든 트래픽을 허용하고 있으므로 ping이 통과해야 한다.
ping -c 1 $NODE1
PING xx.xxx.xxx.xx1 (xx.xxx.xxx.xx1): 56 data bytes
64 bytes from xx.xxx.xxx.xx1: icmp_seq=0 ttl=116 time=7.085 ms
--- xx.xxx.xxx.xx1 ping statistics ---
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 7.085/7.085/7.085/nan ms
ping이 실패한다면 실습 환경의 공인 IP가 변경된 것일 수 있다. 트러블슈팅: 공인 IP 변경을 참고한다.
SSH 접속
ssh -o StrictHostKeyChecking=no -i ~/.ssh/my-eks-keypair.pem ec2-user@$NODE1 hostname
ip-192-168-2-21.ap-northeast-2.compute.internal
AL2023 기반 EKS 노드의 기본 사용자는 ec2-user다.
참고:
StrictHostKeyChecking=noSSH 클라이언트는 처음 접속하는 서버의 호스트 키를
~/.ssh/known_hosts에 기록하고, 이후 접속 시 키가 일치하는지 확인한다.StrictHostKeyChecking=no로 설정하면 호스트 키 확인 없이 바로 접속한다. 실습 환경에서는 편리하지만, 프로덕션에서는 MITM(중간자 공격) 위험이 있으므로 사용하지 않는다.
Kubernetes 노드 필수 설정 확인
온프레미스 kubeadm 클러스터 구성에서는 시간 동기화, SELinux, Swap 비활성화, 커널 모듈/파라미터 등을 직접 설정했다. EKS에서는 이 모든 설정이 EKS 최적화 AMI(AL2023)에 미리 적용되어 있다. 하나씩 확인해 보자.
root 권한으로 전환 후 진행한다.
sudo su -
OS 및 호스트 정보
hostnamectl
Static hostname: ip-192-168-2-21.ap-northeast-2.compute.internal
Icon name: computer-vm
Chassis: vm 🖴
Machine ID: ec2f54ff8d6082ccd17d47b4c90a4662
Boot ID: 93d4ebb9da304aa4b4000971bc511f7c
Virtualization: amazon
Operating System: Amazon Linux 2023.10.20260302 # AL2023
CPE OS Name: cpe:2.3:o:amazon:amazon_linux:2023
Kernel: Linux 6.12.73-95.123.amzn2023.x86_64
Architecture: x86-64
Hardware Vendor: Amazon EC2
Hardware Model: t3.medium
Firmware Version: 1.0
cat /etc/os-release
NAME="Amazon Linux"
VERSION="2023"
ID="amzn"
ID_LIKE="fedora"
VERSION_ID="2023"
PLATFORM_ID="platform:al2023"
PRETTY_NAME="Amazon Linux 2023.10.20260302"
SUPPORT_END="2029-06-30"
| 항목 | kubeadm (Rocky Linux 10) | EKS (AL2023) |
|---|---|---|
| OS | Rocky Linux 10.0 (직접 설치) | Amazon Linux 2023 (AMI에 포함) |
| 커널 | 6.12.0-55.39.1.el10 | 6.12.73-95.123.amzn2023 |
| 아키텍처 | arm64 (Apple Silicon) | x86-64 (EC2 t3.medium) |
| 가상화 | VirtualBox | Amazon EC2 |
둘 다 동일한 커널 6.12 계열이므로 cgroup v2, eBPF 등 기능 면에서 차이가 없다.
SELinux
getenforce
# Permissive
sestatus
# SELinux status: enabled
# Current mode: permissive
# Mode from config file: permissive
kubeadm에서는 setenforce 0으로 런타임 변경한 뒤 /etc/selinux/config까지 수정해야 했다. EKS AMI에서는 처음부터 Permissive로 설정되어 있다. 설정 파일에도 permissive가 지정되어 있으므로 재부팅 시에도 유지된다.
Swap 비활성화
free -h
# total used free shared buff/cache available
# Mem: 3.7Gi 341Mi 1.7Gi 1.0Mi 1.7Gi 3.2Gi
# Swap: 0B 0B 0B
cat /etc/fstab
# UUID=d306b125-f320-4f7c-8e41-c19d118b25e5 / xfs defaults,noatime 1 1
# UUID=3D07-3F7F /boot/efi vfat defaults,noatime,uid=0,gid=0,umask=0077,shortname=winnt,x-systemd.automount 0 2
kubeadm에서는 swapoff -a 실행과 /etc/fstab에서 swap 라인 삭제를 수동으로 해야 했다. EKS 노드에서는 swap 파티션 자체가 존재하지 않는다. fstab에도 swap 항목이 없으므로 별도 조치가 필요 없다.
cgroup
stat -fc %T /sys/fs/cgroup
# cgroup2fs
kubeadm과 동일하게 cgroup v2를 사용한다.
커널 모듈
lsmod | grep overlay
# overlay 217088 7
lsmod | grep netfilter
# (출력 없음)
lsmod | grep fuse
# fuse 245760 1
| 모듈 | kubeadm | EKS | 비고 |
|---|---|---|---|
overlay |
수동 로드 (modprobe) |
이미 로드됨 | containerd OverlayFS 스냅샷에 필요 |
br_netfilter |
수동 로드 | 로드되지 않음 | VPC CNI는 Linux bridge를 사용하지 않음 |
fuse |
수동 로드 | 이미 로드됨 | lazy-loading snapshotter용 (SOCI, stargz 등) |
kubeadm 환경에서는 Pod 트래픽이 Linux bridge(cni0 등)를 거치므로 br_netfilter가 필수였다. EKS의 VPC CNI는 Pod에 VPC ENI의 보조 IP를 직접 할당하므로 Linux bridge를 사용하지 않고, 따라서 br_netfilter 모듈이 필요 없다.
fuse는 AWS의 SOCI(Seekable OCI) Snapshotter 같은 lazy-loading snapshotter를 위한 모듈이다. 기본 overlayfs는 컨테이너 시작 전 전체 이미지를 다운로드하지만, lazy-loading snapshotter는 FUSE 파일시스템을 통해 필요한 데이터만 on-demand로 fetch하여 대용량 이미지의 콜드 스타트 시간을 줄인다. 현재 EKS 노드는 overlayfs를 기본 snapshotter로 사용하고 있으며, fuse 모듈은 lazy-loading snapshotter를 필요 시 바로 사용할 수 있도록 미리 로드해 둔 것이다.
overlay 스냅샷 확인
현재 containerd가 overlayfs snapshotter를 사용하고 있음을 확인할 수 있다. 상세한 containerd 설정은 아래 CRI 섹션에서 확인한다.
ctr -n k8s.io snapshots ls
# KEY PARENT KIND
# 2cde943143... sha256:49a7e69f58... Active
# ...
# sha256:f6c6aa4280... sha256:67f338cd7d... Committed
스냅샷은 /var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/ 아래에 저장된다.
/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/
├── metadata.db ← 스냅샷 메타데이터 (ID, 부모관계, 상태 등)
└── snapshots/
├── 10/
│ ├── fs/ ← 해당 레이어의 실제 파일들 (bin, etc, usr 등)
│ └── work/ ← overlayfs가 내부적으로 사용하는 작업 디렉토리
├── 12/
├── 13/
└── ...
이미지 pull 시 content store에 blob이 저장되고, unpack 과정에서 snapshotter가 각 레이어를 스냅샷으로 생성한다. 컨테이너 실행 시에는 이 스냅샷들을 overlay 방식으로 쌓아 컨테이너의 rootfs를 만든다.
/var/lib/containerd/아래에는io.containerd.snapshotter.v1.native,io.containerd.snapshotter.v1.blockfile,io.containerd.snapshotter.v1.erofs등 다른 snapshotter 디렉토리도 존재한다. 이들은 containerd에 빌트인으로 컴파일된 snapshotter 플러그인이 초기화하면서 생성한 것으로, 각각 다른 이미지 레이어 저장 방식(단순 파일 복사, 블록 디바이스, EROFS)을 제공한다. SOCI/stargz 같은 lazy-loading snapshotter와는 별개로, 이들은 containerd 자체의 빌트인 플러그인이다. 현재 실제 스냅샷 데이터는overlayfs디렉토리에만 있다.
커널 파라미터
kubeadm에서는 /etc/sysctl.d/k8s.conf를 직접 생성하여 커널 파라미터를 설정했다. EKS 노드에는 용도별로 분리된 4개의 설정 파일이 미리 구성되어 있다.
tree /etc/sysctl.d
# /etc/sysctl.d
# ├── 00-defaults.conf
# ├── 99-amazon.conf
# ├── 99-kubernetes-cri.conf
# └── 99-sysctl.conf -> ../sysctl.conf # /etc/sysctl.conf
sysctl 설정 파일의 번호 체계와 로드 순서에 대해서는 리눅스 커널 파라미터와 sysctl 글을 참고한다.
99-kubernetes-cri.conf
cat /etc/sysctl.d/99-kubernetes-cri.conf
# net.bridge.bridge-nf-call-ip6tables = 1
# net.bridge.bridge-nf-call-iptables = 1
# net.ipv4.ip_forward = 1
kubeadm에서 /etc/sysctl.d/k8s.conf에 직접 작성했던 것과 동일한 3개 파라미터다. 다만 br_netfilter 모듈이 로드되지 않았으므로 net.bridge.bridge-nf-call-* 설정은 실제로는 적용되지 않는다. VPC CNI가 Linux bridge를 사용하지 않기 때문에 영향은 없으며, EKS AMI가 다양한 CNI 환경에 대비하여 설정 파일을 포함해 둔 것으로 보인다.
99-amazon.conf
cat /etc/sysctl.d/99-amazon.conf
# vm.overcommit_memory=1
# kernel.panic=10
# kernel.panic_on_oops=1
| 파라미터 | 값 | 설명 |
|---|---|---|
vm.overcommit_memory |
1 | 메모리 할당 요청을 항상 허용 |
kernel.panic |
10 | 커널 패닉 발생 시 10초 후 자동 재부팅 |
kernel.panic_on_oops |
1 | 커널 oops(비치명적 에러) 발생 시 패닉으로 격상 |
99-amazon.conf라는 이름이지만, Amazon Linux 고유 설정이라기보다 Kubernetes 노드에서 공통으로 설정하는 값이다. kubeadm 환경에서 kubelet이 변경하는 커널 파라미터, kubespray의 sysctl 설정에서도 동일한 값을 확인할 수 있다.
kernel.panic과 kernel.panic_on_oops는 fail-fast 철학을 반영한다. oops 이후 커널이 불안정한 상태로 계속 동작하면 데이터 손상이나 예측 불가능한 동작이 발생할 수 있으므로, 빠르게 재부팅하여 노드를 복구한다. EKS에서는 Auto Scaling Group이 비정상 노드를 교체할 수 있으므로 이 전략이 더욱 효과적이다.
00-defaults.conf
cat /etc/sysctl.d/00-defaults.conf
# kernel.printk = 8 4 1 7
# kernel.panic = 5
# net.ipv4.neigh.default.gc_thresh1 = 0
# net.ipv6.neigh.default.gc_thresh1 = 0
# net.ipv4.neigh.default.gc_thresh2 = 15360
# net.ipv6.neigh.default.gc_thresh2 = 15360
# net.ipv4.neigh.default.gc_thresh3 = 16384
# net.ipv6.neigh.default.gc_thresh3 = 16384
# net.ipv4.tcp_wmem = 4096 20480 4194304
# net.ipv4.ip_default_ttl = 127
# kernel.unprivileged_bpf_disabled = 1
kubeadm에서는 설정하지 않았던 AL2023 고유 설정이다. 대규모 서브넷 환경에서의 ARP/neighbor 테이블 튜닝(gc_thresh)과 보안 설정(unprivileged_bpf_disabled)이 포함되어 있다.
kernel.panic = 5가 설정되어 있지만, sysctl 로드 순서(번호 오름차순)에 의해99-amazon.conf의kernel.panic = 10이 최종 적용된다.
99-sysctl.conf
cat /etc/sysctl.d/99-sysctl.conf
# fs.inotify.max_user_watches=524288
# fs.inotify.max_user_instances=8192
# vm.max_map_count=524288
# kernel.pid_max=4194304
/etc/sysctl.conf의 심볼릭 링크로, inotify와 PID 관련 제한값을 늘리는 설정이다. 많은 Pod와 컨테이너가 실행되는 환경에서 파일 감시(inotify)와 프로세스 수 제한에 여유를 두기 위한 것이다.
시간 동기화
kubeadm에서는 chrony를 통해 공용 NTP 서버와 시간을 동기화했다. EKS 노드도 chrony를 사용하지만, AWS 자체 NTP 인프라를 활용한다.
timedatectl status
# Local time: Wed 2026-03-18 08:41:45 UTC
# Universal time: Wed 2026-03-18 08:41:45 UTC
# RTC time: Wed 2026-03-18 08:41:45
# Time zone: n/a (UTC, +0000)
# System clock synchronized: yes
# NTP service: active
# RTC in local TZ: no
chronyc sources -v
# MS Name/IP address Stratum Poll Reach LastRx Last sample
# ===============================================================================
# ^* 169.254.169.123 3 4 377 14 +30us[ +33us] +/- 432us
# ^- ec2-3-87-127-143.compute> 4 10 377 531 -1502us[-1506us] +/- 87ms
# ^- ec2-54-197-201-248.compu> 4 10 377 698 -646us[ -649us] +/- 88ms
# ^- ec2-54-81-127-33.compute> 4 10 377 811 -957us[ -956us] +/- 90ms
# ^- ec2-44-201-148-133.compu> 4 10 377 699 +2462us[+2459us] +/- 91ms
| 소스 | 설명 |
|---|---|
169.254.169.123 (^*) |
AWS 링크 로컬 NTP 서버. 네트워크 홉 없이 하이퍼바이저에서 직접 제공하므로 오차가 ±432us로 매우 작다 |
time.aws.com (^-) |
Amazon 공용 NTP 풀. 보조 소스로 사용 |
kubeadm 환경에서는 공용 NTP 서버(한국 서버 등)와 동기화하여 오차가 수 ms 수준이었다. AWS 링크 로컬 NTP는 마이크로초 단위의 정밀도를 제공한다.
온프레미스(kubeadm)와 비교
| 항목 | kubeadm (직접 설정) | EKS (AMI에 포함) |
|---|---|---|
| SELinux | setenforce 0 + config 수정 |
처음부터 Permissive |
| Swap | swapoff -a + fstab 수정 |
swap 파티션 자체가 없음 |
| cgroup | v2 확인만 | 동일 (v2) |
| 커널 모듈 | overlay, br_netfilter, fuse 수동 로드 | overlay, fuse 로드됨. br_netfilter 불필요 (VPC CNI) |
| 커널 파라미터 | /etc/sysctl.d/k8s.conf 직접 생성 |
4개 파일로 분리되어 미리 설정 |
| 시간 동기화 | chrony + 공용 NTP | chrony + AWS 링크 로컬 NTP (±μs 정밀도) |
| 방화벽 | firewalld 비활성화 | 보안 그룹이 대신 담당 |
| hosts 설정 | /etc/hosts 수동 편집 |
VPC DNS가 대신 담당 |
설정의 내용 자체가 크게 다르지 않다. Kubernetes 노드가 동작하기 위한 필수 요구사항(SELinux Permissive, Swap 비활성화, ip_forward 활성화 등)은 동일하며, EKS는 이를 AMI 수준에서 미리 적용해 둔다. 차이가 있다면 VPC CNI 사용으로 br_netfilter가 불필요하다는 점, 그리고 방화벽·DNS·NTP 같은 인프라 설정을 AWS 관리형 서비스가 대체한다는 점이다.
CRI: containerd
온프레미스에서는 containerd를 직접 설치하고 설정해야 했지만, EKS 최적화 AMI에는 이미 포함되어 있다. containerd 설정 파일의 구조와 주요 옵션에 대한 상세한 설명은 containerd 설정 파일 톺아 보기를 참고한다.
프로세스 트리
pstree로 노드의 전체 프로세스 구조를 확인한다.
pstree -a
전체 출력
systemd --switched-root --system --deserialize=32
├─agetty -o -p -- \\u --noclear - linux
├─agetty -o -p -- \\u --keep-baud 115200,57600,38400,9600 - vt220
├─amazon-ssm-agen
│ └─8*[{amazon-ssm-agen}]
├─auditd
│ └─{auditd}
├─chronyd -F 2
├─containerd
│ └─10*[{containerd}]
├─containerd-shim -namespace k8s.io -id cd0fd257eea6c8faee671df972cfe1196d0...
│ ├─kube-proxy --v=2 --config=/var/lib/kube-proxy-config/config...
│ │ └─5*[{kube-proxy}]
│ ├─pause
│ └─12*[{containerd-shim}]
├─containerd-shim -namespace k8s.io -id 5f0aa52e7cb1a7c511ebd7a5de1a2e90376...
│ ├─aws-vpc-cni
│ │ ├─aws-k8s-agent
│ │ │ └─8*[{aws-k8s-agent}]
│ │ └─4*[{aws-vpc-cni}]
│ ├─controller --enable-ipv6=false --enable-network-policy=false...
│ │ └─7*[{controller}]
│ ├─pause
│ └─14*[{containerd-shim}]
├─containerd-shim -namespace k8s.io -id eb50b8c741f20563558c549020de9ef0451...
│ ├─coredns -conf /etc/coredns/Corefile
│ │ └─7*[{coredns}]
│ ├─pause
│ └─12*[{containerd-shim}]
├─dbus-broker-lau --scope system --audit
│ └─dbus-broker --log 4 --controller 9 --machine-id ...
├─gssproxy -D
│ └─5*[{gssproxy}]
├─irqbalance --foreground
│ └─{irqbalance}
├─kubelet --hostname-override=ip-192-168-2-21.ap-northeast-2.compute.internal --con...
│ └─11*[{kubelet}]
├─sshd
│ └─sshd
│ └─sshd
│ └─bash
│ └─pstree -a
├─systemd --user
│ └─(sd-pam)
├─systemd-homed
├─systemd-journal
├─systemd-logind
├─systemd-network
├─systemd-resolve
├─systemd-udevd
└─systemd-userdbd
├─systemd-userwor
├─systemd-userwor
└─systemd-userwor
Kubernetes 관련 프로세스만 발췌하면:
systemd
├─containerd ← CRI 런타임 (systemd 데몬)
│ └─10*[{containerd}]
├─containerd-shim ... ← kube-proxy 파드
│ ├─kube-proxy --v=2 --config=...
│ └─pause
├─containerd-shim ... ← aws-node 파드
│ ├─aws-vpc-cni
│ │ └─aws-k8s-agent
│ ├─controller --enable-ipv6=false ...
│ └─pause
├─containerd-shim ... ← coredns 파드
│ ├─coredns -conf /etc/coredns/Corefile
│ └─pause
└─kubelet --hostname-override=... ← kubelet (systemd 데몬)
- systemd: PID 1. 모든 프로세스의 루트
- containerd: CRI 런타임. systemd가 직접 관리하는 데몬
- containerd-shim: 파드마다 하나씩. containerd와 실제 컨테이너(runc) 사이의 중간 프로세스
- 각 shim 아래에 pause 컨테이너(네트워크 네임스페이스 홀더)와 실제 워크로드 프로세스가 있다
kube-proxy,aws-vpc-cni+aws-k8s-agent+controller,coredns— 이전 글에서 확인한 시스템 파드들
- kubelet: systemd가 직접 관리하는 데몬. 컨테이너가 아닌 호스트 프로세스로 실행
서비스 상태
systemctl status containerd --no-pager -l
● containerd.service - containerd container runtime
Loaded: loaded (/usr/lib/systemd/system/containerd.service; disabled; preset: disabled)
Drop-In: /etc/systemd/system/containerd.service.d
└─00-runtime-slice.conf
Active: active (running) since Fri 2026-03-13 14:06:00 UTC; 4 days ago
Docs: https://containerd.io
Main PID: 2201 (containerd)
Tasks: 52
Memory: 1.0G
CPU: 1h 15min 2.676s
CGroup: /runtime.slice/containerd.service
├─ 2201 /usr/bin/containerd
├─ 2700 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id ...
Loaded: loaded(서비스 파일 로드 완료), Active: active (running)(실행 중)으로 정상 동작한다. disabled; preset: disabled는 systemctl enable로 부팅 시 자동 시작이 등록되어 있지 않다는 뜻이지만, EKS 노드 초기화 과정에서 직접 시작하므로 문제없다. Drop-In의 00-runtime-slice.conf가 서비스를 /runtime.slice cgroup에 배치하여 kubelet·containerd를 시스템 프로세스와 분리한다.
systemd Unit 파일
cat /usr/lib/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target dbus.service
[Service]
ExecStartPre=-/sbin/modprobe overlay # 시작 전 overlay 파일시스템 커널 모듈 로드
ExecStart=/usr/bin/containerd
Type=notify
Delegate=yes # containerd가 자식 프로세스의 cgroup을 직접 관리할 수 있도록 허용
KillMode=process # 서비스 중지 시 메인 프로세스만 종료. containerd-shim(→ 컨테이너)은 유지
Restart=always
RestartSec=5
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=infinity # 파일 디스크립터 제한 해제. 다수의 컨테이너를 관리해야 하므로 필요
TasksMax=infinity
OOMScoreAdjust=-999 # OOM Killer에서 거의 마지막에 죽도록 보호
[Install]
WantedBy=multi-user.target
온프레미스에서 직접 작성하던 Unit 파일과 내용이 동일하다. EKS AMI에 미리 포함되어 있을 뿐이다.
데몬 설정: config.toml
cat /etc/containerd/config.toml
version = 3 # containerd 2.x 설정 형식
root = "/var/lib/containerd" # 이미지, 스냅샷 등 영속 데이터 저장 경로
state = "/run/containerd" # 런타임 상태 (소켓, PID 등) 저장 경로
[grpc]
address = "/run/containerd/containerd.sock" # 유닉스 도메인 소켓. kubelet, crictl 등이 이 소켓으로 통신
[plugins.'io.containerd.cri.v1.images']
discard_unpacked_layers = true # 압축 해제된 이미지 레이어를 캐시하지 않아 디스크 절약
[plugins.'io.containerd.cri.v1.images'.pinned_images]
sandbox = "localhost/kubernetes/pause" # pause 컨테이너 이미지. ECR이 아닌 로컬 이미지 사용
[plugins."io.containerd.cri.v1.images".registry]
config_path = "/etc/containerd/certs.d:/etc/docker/certs.d"
[plugins.'io.containerd.cri.v1.runtime']
enable_cdi = true
[plugins.'io.containerd.cri.v1.runtime'.containerd]
default_runtime_name = "runc" # OCI 런타임으로 runc 사용
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
base_runtime_spec = "/etc/containerd/base-runtime-spec.json"
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc.options]
BinaryName = "/usr/sbin/runc"
SystemdCgroup = true # cgroup 관리를 systemd에 위임. kubelet의 cgroupDriver: systemd와 일치해야 함
[plugins.'io.containerd.cri.v1.runtime'.cni]
bin_dir = "/opt/cni/bin" # CNI 플러그인 바이너리 경로
conf_dir = "/etc/cni/net.d" # CNI 설정 파일 경로
온프레미스에서도 SystemdCgroup = true, default_runtime_name = "runc" 등은 동일하게 설정했다. EKS 고유한 부분은 discard_unpacked_layers(디스크 최적화)와 sandbox 이미지가 로컬 경로를 가리키는 점이다.
기본 OCI 런타임 스펙: base-runtime-spec.json
config.toml에서 base_runtime_spec으로 참조하는 파일이다. 컨테이너를 생성할 때 적용하는 기본 OCI 런타임 스펙을 정의한다.
cat /etc/containerd/base-runtime-spec.json | jq
전체 출력
{
"linux": {
"namespaces": [ // 컨테이너 격리에 사용하는 5가지 Linux 네임스페이스
{ "type": "ipc" },
{ "type": "mount" },
{ "type": "network" },
{ "type": "pid" },
{ "type": "uts" }
],
"maskedPaths": [ "/proc/acpi", "/proc/kcore", "..." ], // 컨테이너에서 접근 차단하는 호스트 경로
"readonlyPaths": [ "/proc/bus", "/proc/sys", "..." ], // 읽기 전용으로 마운트하는 경로
"..."
},
"mounts": [ "..." ],
"ociVersion": "1.1.0",
"process": {
"capabilities": { "bounding": [ "CAP_NET_BIND_SERVICE", "CAP_SYS_CHROOT", "..." ] },
"cwd": "/",
"noNewPrivileges": true, // setuid 바이너리를 실행해도 권한 상승 불가
"rlimits": [
{
"type": "RLIMIT_NOFILE", // 컨테이너 프로세스의 파일 디스크립터 제한
"soft": 65536, // 기본 사용 가능
"hard": 1048576 // 튜닝 시 여기까지 올릴 수 있음
}
],
"user": {
"gid": 0, // 기본 root 실행.
"uid": 0 // 파드 스펙의 securityContext로 오버라이드 가능
}
}
}
유닉스 도메인 소켓
kubelet과 containerd 클라이언트(ctr, nerdctl, crictl)가 containerd와 통신할 때 사용하는 소켓을 확인한다.
containerd config dump | grep -n containerd.sock
11: address = '/run/containerd/containerd.sock'
ls -l /run/containerd/containerd.sock
srw-rw----. 1 root root 0 Mar 13 14:06 /run/containerd/containerd.sock
ss로 소켓 연결 상태를 확인하면, containerd 프로세스(pid=2201)와 각 containerd-shim 프로세스 간의 유닉스 도메인 소켓 연결을 볼 수 있다.
ss -xl | grep containerd
u_str LISTEN 0 4096 /run/containerd/containerd.sock.ttrpc 5837 * 0
u_str LISTEN 0 4096 /run/containerd/containerd.sock 5838 * 0
두 개의 소켓이 LISTEN 상태다:
containerd.sock: gRPC 소켓. kubelet,crictl등이 CRI API로 통신containerd.sock.ttrpc: ttrpc 소켓. containerd-shim이 containerd와 통신할 때 사용하는 경량 프로토콜
버전 및 플러그인
ctr --address /run/containerd/containerd.sock version
Client:
Version: 2.1.5
Revision: fcd43222d6b07379a4be9786bda52438f0dd16a1
Go version: go1.24.12
Server:
Version: 2.1.5
Revision: fcd43222d6b07379a4be9786bda52438f0dd16a1
UUID: 00eabdb5-6e77-42b9-91c9-05c528908b82
containerd 2.1.5가 설치되어 있다. config.toml의 version = 3과 일치한다(containerd 2.x는 설정 버전 3을 사용).
containerd는 플러그인 아키텍처로 구성되어 있다. snapshotter, 런타임, 이미지 서비스, CRI 등 각 기능이 모두 독립된 플러그인으로 동작한다.
ctr plugins ls
전체 출력
TYPE ID PLATFORMS STATUS
io.containerd.content.v1 content - ok
io.containerd.image-verifier.v1 bindir - ok
io.containerd.internal.v1 opt - ok
io.containerd.warning.v1 deprecations - ok
io.containerd.snapshotter.v1 blockfile linux/amd64 skip
io.containerd.snapshotter.v1 devmapper linux/amd64 skip
io.containerd.snapshotter.v1 erofs linux/amd64 skip
io.containerd.snapshotter.v1 native linux/amd64 ok
io.containerd.snapshotter.v1 overlayfs linux/amd64 ok
io.containerd.snapshotter.v1 zfs linux/amd64 skip
io.containerd.event.v1 exchange - ok
io.containerd.monitor.task.v1 cgroups linux/amd64 ok
io.containerd.metadata.v1 bolt - ok
io.containerd.gc.v1 scheduler - ok
io.containerd.differ.v1 walking linux/amd64 ok
io.containerd.lease.v1 manager - ok
io.containerd.streaming.v1 manager - ok
io.containerd.transfer.v1 local - ok
io.containerd.service.v1 containers-service - ok
io.containerd.service.v1 content-service - ok
io.containerd.service.v1 diff-service - ok
io.containerd.service.v1 images-service - ok
io.containerd.service.v1 introspection-service - ok
io.containerd.service.v1 namespaces-service - ok
io.containerd.service.v1 snapshots-service - ok
io.containerd.shim.v1 manager - ok
io.containerd.runtime.v2 task linux/amd64 ok
io.containerd.service.v1 tasks-service - ok
io.containerd.grpc.v1 containers - ok
io.containerd.grpc.v1 content - ok
io.containerd.grpc.v1 diff - ok
io.containerd.grpc.v1 events - ok
io.containerd.grpc.v1 images - ok
io.containerd.grpc.v1 introspection - ok
io.containerd.grpc.v1 leases - ok
io.containerd.grpc.v1 namespaces - ok
io.containerd.sandbox.store.v1 local - ok
io.containerd.cri.v1 images - ok
io.containerd.cri.v1 runtime linux/amd64 ok
io.containerd.podsandbox.controller.v1 podsandbox - ok
io.containerd.sandbox.controller.v1 shim - ok
io.containerd.grpc.v1 sandbox-controllers - ok
io.containerd.grpc.v1 sandboxes - ok
io.containerd.grpc.v1 snapshots - ok
io.containerd.grpc.v1 streaming - ok
io.containerd.grpc.v1 tasks - ok
io.containerd.grpc.v1 transfer - ok
io.containerd.grpc.v1 version - ok
io.containerd.monitor.container.v1 restart - ok
io.containerd.nri.v1 nri - ok
io.containerd.grpc.v1 cri - ok
io.containerd.grpc.v1 healthcheck - ok
핵심 플러그인:
| 타입 | ID | 역할 |
|---|---|---|
snapshotter.v1 |
overlayfs |
이미지 레이어를 overlay 파일시스템으로 관리. 기본 snapshotter |
runtime.v2 |
task |
OCI 런타임(runc)을 통해 컨테이너 프로세스 생성·관리 |
cri.v1 |
images, runtime |
kubelet이 사용하는 CRI(Container Runtime Interface) 구현 |
grpc.v1 |
cri |
CRI gRPC 서비스 엔드포인트 |
nri.v1 |
nri |
Node Resource Interface. 컨테이너 생성/시작 시 외부 플러그인이 개입할 수 있는 확장점 |
skip 상태인 blockfile, devmapper, zfs 등은 해당 환경에 드라이버가 없어 자동으로 건너뛴 것이다.
kubelet
온프레미스에서는 kubelet을 직접 설치하고 설정 파일을 작성해야 했다(CRI 및 kubeadm 구성 요소 설치, kubeadm init 실행). EKS에서는 AMI에 kubelet이 포함되어 있고, nodeadm이 설정을 자동 생성한다. nodeadm은 AL2023 기반 EKS AMI에 포함된 노드 부트스트랩 에이전트로, 이전 세대 AL2 AMI의 bootstrap.sh를 대체한다. Launch Template의 userdata에 작성한 NodeConfig를 읽어 kubelet 설정, 인증서 배치, 클러스터 등록 등 노드 초기화를 자동으로 수행한다.
서비스 상태
systemctl status kubelet --no-pager
● kubelet.service - Kubernetes Kubelet
Loaded: loaded (/etc/systemd/system/kubelet.service; disabled; preset: disabled)
Active: active (running) since Fri 2026-03-13 14:06:00 UTC; 4 days ago
Docs: https://github.com/kubernetes/kubernetes
Main PID: 2236 (kubelet)
Tasks: 12 (limit: 4516)
Memory: 83.5M
CPU: 1h 18min 58.057s
CGroup: /runtime.slice/kubelet.service
└─2236 /usr/bin/kubelet --hostname-override=ip-192-168-2-21.ap-northeast-2.compute.internal --config=/etc/kubernet…
containerd와 마찬가지로 runtime.slice에서 동작한다.
systemd Unit 파일
cat /etc/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=containerd.service # containerd가 먼저 시작된 후 kubelet 시작
Wants=containerd.service # containerd 서비스를 함께 활성화
[Service]
Slice=runtime.slice # containerd와 같은 cgroup 슬라이스에서 실행
EnvironmentFile=/etc/eks/kubelet/environment # nodeadm이 생성한 환경변수 파일 로드
ExecStartPre=/sbin/iptables -P FORWARD ACCEPT -w 5 # 시작 전 iptables FORWARD 체인을 ACCEPT로 설정
ExecStart=/usr/bin/kubelet $NODEADM_KUBELET_ARGS # 환경변수에서 읽은 인자로 kubelet 실행
Restart=on-failure
RestartForceExitStatus=SIGPIPE
RestartSec=5
KillMode=process
CPUAccounting=true
MemoryAccounting=true
[Install]
WantedBy=multi-user.target
온프레미스에서는 ExecStart에 --config, --kubeconfig 등 kubelet 실행 인자를 직접 지정했다. EKS에서는 nodeadm이 환경변수 파일(/etc/eks/kubelet/environment)에 NODEADM_KUBELET_ARGS를 써 놓고, systemd가 EnvironmentFile로 로드한 뒤 $NODEADM_KUBELET_ARGS를 ExecStart에 전달하는 간접 참조 구조다.
디렉터리 구조
tree /etc/kubernetes
/etc/kubernetes/
├── kubelet
│ ├── config.json # kubelet 메인 설정 파일
│ └── config.json.d
│ └── 40-nodeadm.conf # nodeadm이 생성하는 추가 설정 (config drop-in)
├── manifests # Static Pod 매니페스트 디렉터리. 비어 있음
└── pki
└── ca.crt # 클러스터 CA 공개 인증서
manifests/는 비어 있다. 워커 노드이므로 온프레미스에서도 이 디렉터리는 비어 있는 것이 정상이다. Static Pod 매니페스트(kube-apiserver.yaml, etcd.yaml 등)는 컨트롤 플레인 노드에만 존재한다.
tree /var/lib/kubelet -L 2
/var/lib/kubelet
├── actuated_pods_state
├── allocated_pods_state
├── checkpoints
├── cpu_manager_state
├── device-plugins
│ └── kubelet.sock
├── dra_manager_state
├── kubeconfig # kubelet이 API 서버에 인증할 때 사용하는 설정
├── memory_manager_state
├── pki # kubelet 서버 인증서. serverTLSBootstrap으로 자동 발급·갱신
│ ├── kubelet-server-2026-03-13-14-06-19.pem
│ └── kubelet-server-current.pem -> kubelet-server-2026-03-13-14-06-19.pem
├── plugins
├── plugins_registry
├── pod-resources
│ └── kubelet.sock
└── pods # 실행 중인 파드의 볼륨, 로그 등 런타임 데이터
├── 60668e60-... # 시스템 파드 3개 (kube-proxy, aws-node, coredns)
├── 831c9e67-...
└── b5c7a191-...
설정 파일: config.json
cat /etc/kubernetes/kubelet/config.json | jq
전체 출력
{
"address": "0.0.0.0",
"authentication": {
"x509": {
"clientCAFile": "/etc/kubernetes/pki/ca.crt"
},
"webhook": {
"enabled": true,
"cacheTTL": "2m0s"
},
"anonymous": {
"enabled": false
}
},
"authorization": {
"mode": "Webhook",
"webhook": {
"cacheAuthorizedTTL": "5m0s",
"cacheUnauthorizedTTL": "30s"
}
},
"cgroupDriver": "systemd",
"cgroupRoot": "/",
"clusterDNS": [
"10.100.0.10"
],
"clusterDomain": "cluster.local",
"containerRuntimeEndpoint": "unix:///run/containerd/containerd.sock",
"evictionHard": {
"memory.available": "100Mi",
"nodefs.available": "10%",
"nodefs.inodesFree": "5%"
},
"featureGates": {
"DynamicResourceAllocation": true,
"MutableCSINodeAllocatableCount": true,
"RotateKubeletServerCertificate": true
},
"hairpinMode": "hairpin-veth",
"kubeReserved": {
"cpu": "70m",
"ephemeral-storage": "1Gi",
"memory": "442Mi"
},
"kubeReservedCgroup": "/runtime",
"logging": {
"verbosity": 2
},
"maxPods": 17,
"protectKernelDefaults": true,
"providerID": "aws:///ap-northeast-2b/i-00f6ca51ff8fe7975",
"readOnlyPort": 0,
"serializeImagePulls": false,
"serverTLSBootstrap": true,
"shutdownGracePeriod": "2m30s",
"shutdownGracePeriodCriticalPods": "30s",
"systemReservedCgroup": "/system",
"tlsCipherSuites": [
"TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256",
"TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384",
"TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305",
"TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256",
"TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384",
"TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305",
"TLS_RSA_WITH_AES_128_GCM_SHA256",
"TLS_RSA_WITH_AES_256_GCM_SHA384"
],
"kind": "KubeletConfiguration",
"apiVersion": "kubelet.config.k8s.io/v1beta1"
}
주요 설정을 카테고리별로 정리한다.
런타임·cgroup
| 설정 | 값 | 의미 |
|---|---|---|
cgroupDriver |
systemd |
containerd의 SystemdCgroup = true와 일치해야 함 |
cgroupRoot |
/ |
파드 cgroup 생성 기준 경로 |
containerRuntimeEndpoint |
unix:///run/containerd/containerd.sock |
CRI 소켓 경로 |
kubeReserved |
cpu: 70m, memory: 442Mi, ephemeral-storage: 1Gi | Kubernetes 시스템 컴포넌트를 위한 리소스 예약 |
kubeReservedCgroup |
/runtime |
kubelet·containerd가 속한 cgroup |
systemReservedCgroup |
/system |
OS 시스템 프로세스가 속한 cgroup |
네트워크·DNS
| 설정 | 값 | 의미 |
|---|---|---|
clusterDNS |
10.100.0.10 |
CoreDNS Service IP |
clusterDomain |
cluster.local |
클러스터 내부 DNS 도메인 |
maxPods |
17 |
노드당 최대 파드 수. ENI 수 × (ENI당 IP 수 - 1) + 2로 계산됨. t3.medium은 ENI 3개 × IP 6개 기준 |
hairpinMode |
hairpin-veth |
파드가 자기 자신의 Service IP로 접근할 때 트래픽이 돌아올 수 있도록 허용 |
보안
| 설정 | 값 | 의미 |
|---|---|---|
authentication.anonymous.enabled |
false |
익명 접근 차단 |
authentication.webhook.enabled |
true |
kubelet API 접근 시 API 서버에 인증 위임 |
authorization.mode |
Webhook |
kubelet API 요청의 권한을 API 서버에 위임 |
readOnlyPort |
0 |
10255 읽기 전용 kubelet API 비활성화 |
protectKernelDefaults |
true |
kubelet이 커널 파라미터를 변경하지 않음. 커널 파라미터가 미리 설정되어 있어야 한다 |
serverTLSBootstrap |
true |
kubelet TLS 서버 인증서를 API 서버에서 자동 발급 |
tlsCipherSuites |
(8개 명시) | 허용된 TLS 암호화 스위트만 사용 |
리소스 관리
| 설정 | 값 | 의미 |
|---|---|---|
evictionHard |
memory: 100Mi, nodefs: 10%, inodes: 5% | 노드 리소스 부족 시 파드를 강제 축출하는 임계값 |
serializeImagePulls |
false |
이미지를 병렬로 다운로드. 배포 속도 향상 |
shutdownGracePeriod |
2m30s |
노드 종료 시 파드에 주어지는 종료 유예 시간 |
shutdownGracePeriodCriticalPods |
30s |
그 중 크리티컬 파드에 예약된 시간 |
Feature Gates
| 게이트 | 의미 |
|---|---|
DynamicResourceAllocation |
GPU·디바이스 플러그인 리소스 할당 개선 |
MutableCSINodeAllocatableCount |
CSI 볼륨 attach limit 동적 조정 |
RotateKubeletServerCertificate |
kubelet TLS 서버 인증서 자동 갱신 |
nodeadm drop-in 설정 파일
cat /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf
{
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"clusterDNS": [
"10.100.0.10"
],
"kind": "KubeletConfiguration",
"maxPods": 17
}
nodeadm이 별도로 clusterDNS와 maxPods를 설정한다. drop-in 설정은 메인 config.json을 오버라이드하는 구조로, nodeadm이 노드 스펙(인스턴스 타입, ENI 수)에 맞춰 동적으로 생성한다.
maxPods: 17은 추후 ENI와 IP 할당 구조를 다룰 때 자세히 살펴본다.
kubeconfig: kubelet → API 서버
kubelet이 API 서버에 요청을 보낼 때(파드 상태 보고, 이벤트 전송 등) 사용하는 인증 설정이다.
cat /var/lib/kubelet/kubeconfig
---
apiVersion: v1
kind: Config
clusters:
- name: kubernetes
cluster:
certificate-authority: /etc/kubernetes/pki/ca.crt
server: https://461A1FA334847E0E1B597AF07FF0CCE0.gr7.ap-northeast-2.eks.amazonaws.com
current-context: kubelet
contexts:
- name: kubelet
context:
cluster: kubernetes
user: kubelet
users:
- name: kubelet
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
command: aws
args:
- "eks"
- "get-token"
- "--cluster-name"
- "myeks"
- "--region"
- "ap-northeast-2"
온프레미스와의 결정적인 차이가 여기에 있다:
| 온프레미스 (kubeadm) | EKS | |
|---|---|---|
| 인증 방식 | X.509 클라이언트 인증서 (client-certificate, client-key) |
AWS STS 토큰 (aws eks get-token) |
| 서버 주소 | https://<마스터 IP>:6443 |
EKS API 서버 엔드포인트 (NLB 뒤) |
| CA 인증서 | /etc/kubernetes/pki/ca.crt |
/etc/kubernetes/pki/ca.crt (동일) |
users.exec 블록이 핵심이다. kubelet이 API 서버에 요청할 때마다 aws eks get-token을 실행하여 STS(Security Token Service) 토큰을 발급받는다. 이 토큰은 EC2 인스턴스에 연결된 IAM 역할을 기반으로 생성된다.
인증서
CA 인증서
cat /etc/kubernetes/pki/ca.crt | openssl x509 -text -noout
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 173080814291216835 (0x266e815654369c3)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=kubernetes # 자체 서명(Self-signed) CA
Validity
Not Before: Mar 13 13:56:20 2026 GMT
Not After : Mar 10 14:01:20 2036 GMT # 2026.03.13 ~ 2036.03.10 (10년)
Subject: CN=kubernetes # Issuer = Subject → 자기 자신이 서명
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment, Certificate Sign # 다른 인증서를 서명할 수 있는 CA
X509v3 Basic Constraints: critical
CA:TRUE # CA 인증서임을 명시
X509v3 Subject Alternative Name:
DNS:kubernetes
tree /etc/kubernetes에서 확인했듯이 pki/ 디렉터리에는 ca.crt만 존재한다. 워커 노드에 ca.key가 없는 것은 온프레미스에서도 마찬가지다. 다만 온프레미스에서는 관리자가 컨트롤 플레인 노드에 접속하면 ca.key를 직접 확인할 수 있었던 반면, EKS에서는 컨트롤 플레인이 AWS 관리 영역이므로 ca.key에 아예 접근할 수 없다. 이전 글에서 “CA 프라이빗 키는 AWS만 보유한다”고 한 내용의 실증이다.
kubelet 서버 인증서
API 서버가 kubelet에 접근할 때(kubectl exec, kubectl logs 등), kubelet은 서버 역할을 한다. 이때 사용하는 TLS 서버 인증서다.
cat /var/lib/kubelet/pki/kubelet-server-current.pem | openssl x509 -text -noout
Certificate:
Data:
Version: 3 (0x2)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=kubernetes # 위의 CA 인증서가 서명
Validity
Not Before: Mar 13 14:01:00 2026 GMT
Not After : Apr 27 14:01:00 2026 GMT # ~45일 유효. RotateKubeletServerCertificate로 자동 갱신
Subject: O=system:nodes, CN=system:node:ip-192-168-2-21.ap-northeast-2.compute.internal
# ↑ 그룹 ↑ 노드의 프라이빗 DNS가 CN
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey # ECDSA P-256. CA(RSA 2048)보다 짧은 키로 동등한 보안 강도
Public-Key: (256 bit)
NIST CURVE: P-256
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature
X509v3 Extended Key Usage:
TLS Web Server Authentication # 서버 인증서 용도
X509v3 Subject Alternative Name: # API 서버가 어떤 경로로 접근하든 검증 통과하도록 4개 모두 포함
DNS:ec2-xx-xxx-xxx-xx1.ap-northeast-2.compute.amazonaws.com, # 공인 DNS
DNS:ip-192-168-2-21.ap-northeast-2.compute.internal, # 프라이빗 DNS
IP Address:xx.xxx.xxx.xx1, # 공인 IP
IP Address:192.168.2.21 # 프라이빗 IP
kubelet-server-current.pem은 심볼릭 링크로, 인증서 갱신 시 새 파일을 가리키도록 변경된다. 온프레미스에서도 kubelet 인증서 자동 갱신(RotateKubeletServerCertificate) 사용 시 동일한 심볼릭 링크 패턴이다:
kubelet-server-current.pem -> kubelet-server-2026-03-13-14-06-19.pem
CSR: 인증서 발급 요청
kubelet 서버 인증서는 serverTLSBootstrap: true 설정에 의해 kubelet이 API 서버에 CSR(Certificate Signing Request)을 보내 자동 발급받는다. 자신의 PC에서 CSR 목록을 확인할 수 있다:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
csr-6c562 60m kubernetes.io/kubelet-serving system:node:ip-192-168-2-110.ap-northeast-2.compute.internal <none> Approved,Issued
csr-rjkxd 60m kubernetes.io/kubelet-serving system:node:ip-192-168-3-99.ap-northeast-2.compute.internal <none> Approved,Issued
각 워커 노드마다 CSR이 하나씩 있고, 모두 Approved,Issued 상태다. EKS 컨트롤 플레인이 자동으로 CSR을 승인하고 인증서를 발급해 준다. 온프레미스에서는 kubeadm이 이 과정을 처리하거나, 수동으로 kubectl certificate approve를 실행해야 했다.
CSR은 노드 등록 직후에만 확인할 수 있다.
Approved,Issued상태의 CSR은 Kubernetes CSR 클리너가 일정 시간 후 자동 삭제하므로, 시간이 지나면kubectl get csr결과가 비어 있을 수 있다. 위 결과는 가시다님의 실행 결과를 참고한 것이다.
인증서 요약
+----------------------------------+
| CA (AWS 관리) |
| ca.crt (공개) + ca.key (비공개) |
+--------+----------------+--------+
| |
서명 서명
| |
v v
+-----------------+ +-------------------+
| kubelet 서버 | | API 서버 TLS |
| 인증서 (~45일) | | 인증서 (AWS 관리) |
| 자동 갱신 | | |
+-----------------+ +-------------------+
| 온프레미스 (kubeadm) | EKS | |
|---|---|---|
| CA 키 위치 | 컨트롤 플레인 노드 /etc/kubernetes/pki/ca.key |
AWS 관리 영역 (접근 불가) |
| kubelet 서버 인증서 | kubeadm이 발급, 1년 유효 | CSR → API 서버 자동 발급, ~45일 유효, 자동 갱신 |
| kubelet 클라이언트 인증 | X.509 클라이언트 인증서 | AWS STS 토큰 (aws eks get-token) |
| 인증서 갱신 | kubeadm certs renew 수동 실행 |
RotateKubeletServerCertificate로 자동 |
네트워크
온프레미스에서는 Calico나 Flannel 같은 오버레이 네트워크 CNI를 설치했다. EKS에서는 AWS VPC CNI를 사용한다. 파드에 VPC 서브넷의 실제 IP를 직접 할당하여, 오버레이 없이 VPC 네이티브로 통신한다.
CNI 바이너리
tree -pug /opt/cni/bin/
/opt/cni/bin/
├── [-rwxr-xr-x root root] aws-cni
├── [-rwxr-xr-x root root] aws-cni-support.sh
├── [-rwxr-xr-x root root] bandwidth
├── [-rwxr-xr-x root root] bridge
├── [-rwxr-xr-x root root] dhcp
├── [-rwxr-xr-x root root] dummy
├── [-rwxr-xr-x root root] egress-cni
├── [-rwxr-xr-x root root] firewall
├── [-rwxr-xr-x root root] host-device
├── [-rwxr-xr-x root root] host-local
├── [-rwxr-xr-x root root] ipvlan
├── [-rw-rw-r-- root root] LICENSE
├── [-rwxr-xr-x root root] loopback
├── [-rwxr-xr-x root root] macvlan
├── [-rwxr-xr-x root root] portmap
├── [-rwxr-xr-x root root] ptp
├── [-rwxr-xr-x root root] sbr
├── [-rwxr-xr-x root root] static
├── [-rwxr-xr-x root root] tap
├── [-rwxr-xr-x root root] tuning
├── [-rwxr-xr-x root root] vlan
└── [-rwxr-xr-x root root] vrf
바이너리는 두 종류로 나뉜다:
AWS VPC CNI 전용
| 바이너리 | 역할 |
|---|---|
aws-cni |
메인 CNI 플러그인. ENI의 보조 IP를 파드에 할당 |
aws-cni-support.sh |
트러블슈팅용 스크립트 (로그, ENI 상태 등 수집) |
egress-cni |
외부 SNAT 관련 처리 |
CNI 표준 플러그인 (containernetworking/plugins)
bridge, host-local, loopback, portmap, bandwidth, ptp, vlan, macvlan, ipvlan 등은 CNI 레퍼런스 플러그인이다. 온프레미스에서도 동일하게 /opt/cni/bin/에 존재한다. EKS에서는 체이닝(chaining)이나 보조 용도로 일부 사용된다.
이 바이너리들은 이전 글에서 확인한 aws-node DaemonSet의 init container(aws-vpc-cni-init)가 호스트의 /opt/cni/bin/에 복사해 놓은 것이다. 온프레미스에서 Calico나 Flannel도 동일한 패턴으로 자기 CNI 바이너리를 배포한다.
CNI 설정
cat /etc/cni/net.d/10-aws.conflist | jq
전체 출력
{
"cniVersion": "0.4.0",
"name": "aws-cni",
"disableCheck": true,
"plugins": [
{
"name": "aws-cni",
"type": "aws-cni",
"vethPrefix": "eni",
"mtu": "9001",
"podSGEnforcingMode": "strict",
"pluginLogFile": "/var/log/aws-routed-eni/plugin.log",
"pluginLogLevel": "DEBUG",
"capabilities": {
"io.kubernetes.cri.pod-annotations": true
}
},
{
"name": "egress-cni",
"type": "egress-cni",
"mtu": "9001",
"enabled": "false",
"randomizeSNAT": "prng",
"nodeIP": "",
"ipam": {
"type": "host-local",
"ranges": [
[
{
"subnet": "fd00::ac:00/118"
}
]
],
"routes": [
{
"dst": "::/0"
}
],
"dataDir": "/run/cni/v4pd/egress-v6-ipam"
},
"pluginLogFile": "/var/log/aws-routed-eni/egress-v6-plugin.log",
"pluginLogLevel": "DEBUG"
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
},
"snat": true
}
]
}
kubelet이 파드를 생성할 때, 이 conflist를 읽고 plugin chain 순서대로 CNI 바이너리를 호출한다:
kubelet → /etc/cni/net.d/10-aws.conflist 읽음 → /opt/cni/bin/aws-cni 실행
| 플러그인 | 역할 | 비고 |
|---|---|---|
aws-cni |
메인. ENI 보조 IP를 파드에 할당하고 veth pair 생성 | vethPrefix: "eni" → 호스트 쪽 인터페이스 이름이 eni로 시작 |
egress-cni |
IPv6 egress 처리 | enabled: "false" — 현재 비활성 |
portmap |
hostPort 매핑 |
HostPort를 사용하는 파드가 있을 때 iptables DNAT 규칙 생성 |
네트워크 인터페이스
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 ...
inet 127.0.0.1/8 scope host lo
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 ...
inet 192.168.2.21/24 metric 512 brd 192.168.2.255 scope global dynamic ens5
4: ens6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 ...
inet 192.168.2.24/24 brd 192.168.2.255 scope global ens6
5: enib3a22542c88@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 ...
link-netns cni-f9dda356-dddd-042f-d53a-34368d3e4c7b
| 인터페이스 | 타입 | IP | 역할 |
|---|---|---|---|
lo |
루프백 | 127.0.0.1 | 로컬 통신 |
ens5 |
Primary ENI | 192.168.2.21 | 노드의 메인 네트워크 인터페이스. DHCP로 IP 할당 |
ens6 |
Secondary ENI | 192.168.2.24 | VPC CNI가 파드 IP 할당을 위해 추가한 ENI |
enib3a22542c88 |
veth pair (호스트 쪽) | - | 파드 네트워크 네임스페이스와 연결되는 가상 인터페이스. CNI 설정의 vethPrefix: "eni"에 의해 eni로 시작 |
온프레미스(Calico/Flannel)에서는 cali*나 flannel.* 같은 오버레이 인터페이스가 보였다(Kubernetes CNI). EKS에서는 ens*(실제 ENI)와 eni*(veth pair)만 있고 오버레이 터널이 없다. 파드 IP가 VPC 서브넷의 실제 IP이므로 캡슐화(encapsulation) 없이 직접 라우팅된다. ens5, ens6 등 ENI 구조는 다음 글에서 자세히 살펴본다.
라우팅 테이블
ip route
default via 192.168.2.1 dev ens5 proto dhcp src 192.168.2.21 metric 512
192.168.0.2 via 192.168.2.1 dev ens5 proto dhcp src 192.168.2.21 metric 512
192.168.2.0/24 dev ens5 proto kernel scope link src 192.168.2.21 metric 512
192.168.2.1 dev ens5 proto dhcp scope link src 192.168.2.21 metric 512
192.168.2.210 dev enib3a22542c88 scope link
마지막 줄이 핵심이다: 192.168.2.210(파드 IP)이 enib3a22542c88(veth pair)를 통해 직접 연결된다. 오버레이 네트워크에서는 파드 IP가 별도의 CIDR(예: 10.244.0.0/16)에 있고 터널을 통해 라우팅되지만, VPC CNI에서는 파드 IP가 노드와 같은 VPC 서브넷(192.168.2.0/24)에 속한다.
네트워크 네임스페이스
lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 115 1 root unassigned /usr/lib/systemd/systemd --s
4026532213 net 2 1773089 65535 0 /run/netns/cni-f9dda356-dddd-042f-d53a-34368d3e4c7b /pause
네트워크 네임스페이스가 2개뿐이다:
| NS | 프로세스 | 설명 |
|---|---|---|
4026531840 |
115개 | 호스트 네임스페이스. systemd, kubelet, containerd, 그리고 hostNetwork: true인 파드(aws-node, kube-proxy)가 모두 여기에 속함 |
4026532213 |
2개 | CoreDNS 파드의 네임스페이스. pause 컨테이너가 네임스페이스를 유지하고, CoreDNS 프로세스가 이 안에서 실행 |
aws-node과 kube-proxy는 hostNetwork: true로 동작하므로 별도의 네트워크 네임스페이스가 없고, 호스트 네트워크 스택을 직접 사용한다. 현재 사용자 워크로드가 없으므로 독립된 네트워크 네임스페이스는 CoreDNS 파드의 것 하나뿐이다.
샘플 워크로드(kube-ops-view, mario)를 배포한 후 다시 확인하면:
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 118 1 root unassigned /usr/lib/systemd/systemd --s
4026532213 net 2 1773089 65535 0 /run/netns/cni-f9dda356-dddd-042f-d53a-34368d3e4c7b /pause
4026532326 net 2 2193513 65535 1 /run/netns/cni-e561fcda-44dd-be99-1260-76e8c12945df /pause
네트워크 네임스페이스가 3개로 늘었다. 새로 생긴 4026532326은 이 노드에 스케줄링된 사용자 파드의 네임스페이스다. 파드마다 pause 컨테이너가 네트워크 네임스페이스를 생성·유지하고, 워크로드 컨테이너가 이 안에서 실행된다.
kubectl로 보는 것이 API 관점의 추상화라면, lsns는 리눅스 커널 레벨에서 실제 격리 상태를 보여준다.
iptables: NAT 규칙
kube-proxy와 VPC CNI가 생성한 iptables NAT 규칙을 확인한다.
iptables -t nat -S
전체 출력
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N AWS-CONNMARK-CHAIN-0
-N AWS-SNAT-CHAIN-0
-N KUBE-KUBELET-CANARY
-N KUBE-MARK-MASQ
-N KUBE-NODEPORTS
-N KUBE-POSTROUTING
-N KUBE-PROXY-CANARY
-N KUBE-SEP-47K6B2ZWNQSDOHG3
-N KUBE-SEP-5FSXLGNBDOTNNMI4
-N KUBE-SEP-G2BLRKGIIGUGBIED
-N KUBE-SEP-JY3ERXLJSTX3QEV5
-N KUBE-SEP-PLKFYPYWRGK62UIW
-N KUBE-SEP-TWCSZHER46CBBLVZ
-N KUBE-SEP-VZ3VRTSMCJ4XVHYS
-N KUBE-SEP-XIRPJZFULYGCDZRT
-N KUBE-SEP-XYDDOFWXZXQGZRSQ
-N KUBE-SERVICES
-N KUBE-SVC-ERIFXISQEP7F7OF4
-N KUBE-SVC-I7SKRZYQ7PWYV5X7
-N KUBE-SVC-JD5MR3NA4I4DYORP
-N KUBE-SVC-NPX46M4PTMTKRN6Y
-N KUBE-SVC-TCOU7JCQXEZGVUNU
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -i eni+ -m comment --comment "AWS, outbound connections" -j AWS-CONNMARK-CHAIN-0
-A PREROUTING -m comment --comment "AWS, CONNMARK" -j CONNMARK --restore-mark --nfmask 0x80 --ctmask 0x80
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -m comment --comment "AWS SNAT CHAIN" -j AWS-SNAT-CHAIN-0
-A AWS-CONNMARK-CHAIN-0 -d 192.168.0.0/16 -m comment --comment "AWS CONNMARK CHAIN, VPC CIDR" -j RETURN
-A AWS-CONNMARK-CHAIN-0 -m comment --comment "AWS, CONNMARK" -j CONNMARK --set-xmark 0x80/0x80
-A AWS-SNAT-CHAIN-0 -d 192.168.0.0/16 -m comment --comment "AWS SNAT CHAIN" -j RETURN
-A AWS-SNAT-CHAIN-0 ! -o vlan+ -m comment --comment "AWS, SNAT" -m addrtype ! --dst-type LOCAL -j SNAT --to-source 192.168.2.21 --random-fully
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
-A KUBE-SEP-47K6B2ZWNQSDOHG3 -s 192.168.3.35/32 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-MARK-MASQ
-A KUBE-SEP-47K6B2ZWNQSDOHG3 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 192.168.3.35:53
-A KUBE-SEP-5FSXLGNBDOTNNMI4 -s 192.168.2.210/32 -m comment --comment "kube-system/kube-dns:metrics" -j KUBE-MARK-MASQ
-A KUBE-SEP-5FSXLGNBDOTNNMI4 -p tcp -m comment --comment "kube-system/kube-dns:metrics" -m tcp -j DNAT --to-destination 192.168.2.210:9153
-A KUBE-SEP-G2BLRKGIIGUGBIED -s 192.168.3.35/32 -m comment --comment "kube-system/kube-dns:metrics" -j KUBE-MARK-MASQ
-A KUBE-SEP-G2BLRKGIIGUGBIED -p tcp -m comment --comment "kube-system/kube-dns:metrics" -m tcp -j DNAT --to-destination 192.168.3.35:9153
-A KUBE-SEP-JY3ERXLJSTX3QEV5 -s 192.168.1.61/32 -m comment --comment "default/kubernetes:https" -j KUBE-MARK-MASQ
-A KUBE-SEP-JY3ERXLJSTX3QEV5 -p tcp -m comment --comment "default/kubernetes:https" -m tcp -j DNAT --to-destination 192.168.1.61:443
-A KUBE-SEP-PLKFYPYWRGK62UIW -s 192.168.2.210/32 -m comment --comment "kube-system/kube-dns:dns" -j KUBE-MARK-MASQ
-A KUBE-SEP-PLKFYPYWRGK62UIW -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 192.168.2.210:53
-A KUBE-SEP-TWCSZHER46CBBLVZ -s 192.168.2.250/32 -m comment --comment "default/kubernetes:https" -j KUBE-MARK-MASQ
-A KUBE-SEP-TWCSZHER46CBBLVZ -p tcp -m comment --comment "default/kubernetes:https" -m tcp -j DNAT --to-destination 192.168.2.250:443
-A KUBE-SEP-VZ3VRTSMCJ4XVHYS -s 192.168.3.35/32 -m comment --comment "kube-system/kube-dns:dns" -j KUBE-MARK-MASQ
-A KUBE-SEP-VZ3VRTSMCJ4XVHYS -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 192.168.3.35:53
-A KUBE-SEP-XIRPJZFULYGCDZRT -s 192.168.2.210/32 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-MARK-MASQ
-A KUBE-SEP-XIRPJZFULYGCDZRT -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 192.168.2.210:53
-A KUBE-SEP-XYDDOFWXZXQGZRSQ -s 172.0.32.0/32 -m comment --comment "kube-system/eks-extension-metrics-api:metrics-api" -j KUBE-MARK-MASQ
-A KUBE-SEP-XYDDOFWXZXQGZRSQ -p tcp -m comment --comment "kube-system/eks-extension-metrics-api:metrics-api" -m tcp -j DNAT --to-destination 172.0.32.0:10443
-A KUBE-SERVICES -d 10.100.213.67/32 -p tcp -m comment --comment "kube-system/eks-extension-metrics-api:metrics-api cluster IP" -m tcp --dport 443 -j KUBE-SVC-I7SKRZYQ7PWYV5X7
-A KUBE-SERVICES -d 10.100.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SERVICES -d 10.100.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SERVICES -d 10.100.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-SVC-JD5MR3NA4I4DYORP
-A KUBE-SERVICES -d 10.100.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp -> 192.168.2.210:53" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-XIRPJZFULYGCDZRT
-A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp -> 192.168.3.35:53" -j KUBE-SEP-47K6B2ZWNQSDOHG3
-A KUBE-SVC-I7SKRZYQ7PWYV5X7 -m comment --comment "kube-system/eks-extension-metrics-api:metrics-api -> 172.0.32.0:10443" -j KUBE-SEP-XYDDOFWXZXQGZRSQ
-A KUBE-SVC-JD5MR3NA4I4DYORP -m comment --comment "kube-system/kube-dns:metrics -> 192.168.2.210:9153" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-5FSXLGNBDOTNNMI4
-A KUBE-SVC-JD5MR3NA4I4DYORP -m comment --comment "kube-system/kube-dns:metrics -> 192.168.3.35:9153" -j KUBE-SEP-G2BLRKGIIGUGBIED
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https -> 192.168.1.61:443" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-JY3ERXLJSTX3QEV5
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https -> 192.168.2.250:443" -j KUBE-SEP-TWCSZHER46CBBLVZ
-A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns -> 192.168.2.210:53" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-PLKFYPYWRGK62UIW
-A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns -> 192.168.3.35:53" -j KUBE-SEP-VZ3VRTSMCJ4XVHYS
iptables NAT 규칙은 kube-proxy가 생성한 Service 라우팅 규칙과 VPC CNI가 생성한 SNAT 규칙으로 나뉜다.
kube-proxy: Service → Pod DNAT
kube-proxy는 Service ClusterIP로 들어오는 트래픽을 실제 파드 IP로 DNAT한다. KUBE-SERVICES → KUBE-SVC-* → KUBE-SEP-* 체인 순서로 처리된다.
| Service | ClusterIP | 백엔드 파드 IP | 로드밸런싱 |
|---|---|---|---|
kube-dns (DNS UDP) |
10.100.0.10:53 | 192.168.2.210, 192.168.3.35 | 50:50 랜덤 |
kube-dns (DNS TCP) |
10.100.0.10:53 | 192.168.2.210, 192.168.3.35 | 50:50 랜덤 |
kube-dns (metrics) |
10.100.0.10:9153 | 192.168.2.210, 192.168.3.35 | 50:50 랜덤 |
kubernetes (API) |
10.100.0.1:443 | 192.168.1.61, 192.168.2.250 | 50:50 랜덤 |
eks-extension-metrics-api |
10.100.213.67:443 | 172.0.32.0:10443 | 단일 백엔드 |
default/kubernetes Service의 백엔드 IP(192.168.1.61, 192.168.2.250)는 컨트롤 플레인의 ENI IP다. EKS Owned ENI에서 이 ENI의 정체를 확인하고, 엔드포인트 분석에서 API 서버 접근 경로를 상세히 다룬다.
VPC CNI: AWS SNAT
VPC CNI가 추가한 AWS-SNAT-CHAIN-0 규칙은 파드에서 VPC 외부로 나가는 트래픽을 처리한다:
-A AWS-SNAT-CHAIN-0 -d 192.168.0.0/16 -j RETURN
-A AWS-SNAT-CHAIN-0 ! -o vlan+ -m addrtype ! --dst-type LOCAL -j SNAT --to-source 192.168.2.21
- VPC 내부(192.168.0.0/16)로 가는 트래픽은 SNAT 안 함 — 파드 IP가 이미 VPC IP이므로 그대로 통신
- VPC 외부(인터넷 등)로 가는 트래픽은 노드 IP(192.168.2.21)로 SNAT — 인터넷 통신을 위해 필요
iptables: filter 규칙
iptables -t filter -S
전체 출력
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-N KUBE-EXTERNAL-SERVICES
-N KUBE-FIREWALL
-N KUBE-FORWARD
-N KUBE-KUBELET-CANARY
-N KUBE-NODEPORTS
-N KUBE-PROXY-CANARY
-N KUBE-PROXY-FIREWALL
-N KUBE-SERVICES
-A INPUT -m conntrack --ctstate NEW -m comment --comment "kubernetes load balancer firewall" -j KUBE-PROXY-FIREWALL
-A INPUT -m comment --comment "kubernetes health check service ports" -j KUBE-NODEPORTS
-A INPUT -m conntrack --ctstate NEW -m comment --comment "kubernetes externally-visible service portals" -j KUBE-EXTERNAL-SERVICES
-A INPUT -j KUBE-FIREWALL
-A FORWARD -m conntrack --ctstate NEW -m comment --comment "kubernetes load balancer firewall" -j KUBE-PROXY-FIREWALL
-A FORWARD -m comment --comment "kubernetes forwarding rules" -j KUBE-FORWARD
-A FORWARD -m conntrack --ctstate NEW -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A FORWARD -m conntrack --ctstate NEW -m comment --comment "kubernetes externally-visible service portals" -j KUBE-EXTERNAL-SERVICES
-A OUTPUT -m conntrack --ctstate NEW -m comment --comment "kubernetes load balancer firewall" -j KUBE-PROXY-FIREWALL
-A OUTPUT -m conntrack --ctstate NEW -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -j KUBE-FIREWALL
-A KUBE-FIREWALL ! -s 127.0.0.0/8 -d 127.0.0.0/8 -m comment --comment "block incoming localnet connections" -m conntrack ! --ctstate RELATED,ESTABLISHED,DNAT -j DROP
-A KUBE-FORWARD -m conntrack --ctstate INVALID -m nfacct --nfacct-name ct_state_invalid_dropped_pkts -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding conntrack rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
filter 테이블은 kube-proxy가 관리한다. FORWARD 체인의 기본 정책이 ACCEPT인데, 이는 kubelet Unit 파일의 ExecStartPre=/sbin/iptables -P FORWARD ACCEPT에서 설정한 것이다. KUBE-FORWARD 체인에서 INVALID 패킷을 DROP하고, kube-proxy가 마킹한 패킷(0x4000)과 기존 연결의 응답 패킷을 ACCEPT한다.
iptables: mangle 규칙
iptables의 mangle 테이블은 패킷을 직접 변환하지 않고 메타데이터(mark)를 부착하는 용도다. nat(주소 변환)이나 filter(허용/차단)와 달리, 패킷에 표시만 해 두고 다른 테이블에서 이 표시를 보고 판단하도록 한다.
iptables -t mangle -S
-A PREROUTING -i ens5 -m comment --comment "AWS, primary ENI" -m addrtype --dst-type LOCAL --limit-iface-in -j CONNMARK --set-xmark 0x80/0x80
-A PREROUTING -i eni+ -m comment --comment "AWS, primary ENI" -j CONNMARK --restore-mark --nfmask 0x80 --ctmask 0x80
-A PREROUTING -i vlan+ -m comment --comment "AWS, primary ENI" -j CONNMARK --restore-mark --nfmask 0x80 --ctmask 0x80
VPC CNI가 추가한 규칙이다. Primary ENI(ens5)로 들어오는 로컬 목적지 트래픽에 CONNMARK(0x80)를 설정하고, 파드 veth(eni+)나 vlan 인터페이스를 통해 나갈 때 이 마크를 복원한다. nat 테이블의 AWS-SNAT-CHAIN-0이 이 마크를 보고 SNAT 적용 여부를 결정한다.
스토리지
디스크·파일시스템
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 20G 0 part / # 루트 파일시스템 (xfs)
├─nvme0n1p127 259:2 0 1M 0 part # BIOS boot 파티션
└─nvme0n1p128 259:3 0 10M 0 part /boot/efi # EFI 시스템 파티션
EBS 볼륨 하나(nvme0n1, 20GB)에 3개 파티션이 있다. disk_size = 30으로 설정했지만, 실제로는 AMI 기본 크기인 20GB가 적용되었다.
df -hT
전체 출력
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs tmpfs 767M 1.1M 766M 1% /run
/dev/nvme0n1p1 xfs 20G 3.9G 17G 20% /
tmpfs tmpfs 1.9G 0 1.9G 0% /tmp
/dev/nvme0n1p128 vfat 10M 1.3M 8.7M 13% /boot/efi
tmpfs tmpfs 3.3G 12K 3.3G 1% /var/lib/kubelet/pods/.../kube-api-access-q98lf
shm tmpfs 64M 0 64M 0% /run/containerd/.../shm
overlay overlay 20G 3.9G 17G 20% /run/containerd/.../rootfs
...
핵심만 추출하면:
| 파일시스템 | 타입 | 용도 |
|---|---|---|
/dev/nvme0n1p1 |
xfs | 루트. 이미지, containerd 데이터, 로그 등 모두 여기 |
tmpfs (kubelet pods) |
tmpfs | 파드의 projected 볼륨(ServiceAccount 토큰 등) |
shm |
tmpfs | 파드별 공유 메모리 (/dev/shm) |
overlay |
overlay | 컨테이너 루트 파일시스템. containerd의 overlayfs snapshotter가 생성 |
Swap이 없다 — lsblk에도 swap 파티션이 없고 df에도 swap이 보이지 않는다. Kubernetes는 swap이 비활성화되어 있어야 하며, EKS AMI에서 이를 사전 적용해 둔다.
overlay 마운트가 여러 개 — 파드마다 pause 컨테이너와 워크로드 컨테이너의 rootfs가 각각 overlay로 마운트된다. 이것이 containerd의 overlayfs snapshotter가 동작하는 방식이며, config.toml에서 확인한 overlayfs 플러그인이 이를 관리한다.
cgroup
cgroup v2 확인
stat -fc %T /sys/fs/cgroup/
cgroup2fs
cgroup v2가 사용되고 있다. containerd의 SystemdCgroup = true와 kubelet의 cgroupDriver: systemd가 이 위에서 동작한다.
슬라이스 구조
tree /sys/fs/cgroup/ -L 1
EKS 노드의 cgroup은 3개 슬라이스로 분리된다:
/sys/fs/cgroup/
├── system.slice ← systemReservedCgroup (/system)
│ ├── sshd
│ ├── journald
│ └── systemd ...
│
├── runtime.slice ← kubeReservedCgroup (/runtime)
│ ├── kubelet.service
│ └── containerd.service
│
└── kubepods.slice ← 파드
├── kubepods-guaranteed.slice
├── kubepods-burstable.slice
└── kubepods-besteffort.slice
| 슬라이스 | kubelet 설정 | 내용 |
|---|---|---|
system.slice |
systemReservedCgroup: "/system" |
OS 시스템 프로세스 (sshd, journald 등) |
runtime.slice |
kubeReservedCgroup: "/runtime" |
kubelet, containerd. systemctl status에서 확인한 Slice=runtime.slice가 이것 |
kubepods.slice |
- | 파드. QoS 클래스별로 guaranteed, burstable, besteffort로 세분화 |
이 구조 덕분에 파드가 리소스를 아무리 사용해도 system.slice(OS)와 runtime.slice(kubelet/containerd)의 리소스는 보호된다. kubelet config.json에서 확인한 kubeReserved(cpu: 70m, memory: 442Mi)가 runtime.slice에 예약되는 리소스다.
systemd-cgls로 전체 cgroup 트리를, systemd-cgtop으로 슬라이스별 실시간 리소스 사용량을 확인할 수 있다.
온프레미스 비교
| 항목 | 온프레미스 워커 노드 (kubeadm) | EKS 워커 노드 |
|---|---|---|
| OS | Ubuntu/CentOS (직접 설치) | AL2023 (AMI에 포함) |
| CRI | containerd (직접 설치·설정) | containerd (AMI에 포함, config.toml 사전 설정) |
| kubelet 설치 | apt/yum 또는 바이너리 | AMI에 포함 |
| kubelet 설정 경로 | /var/lib/kubelet/config.yaml |
/etc/kubernetes/kubelet/config.json + nodeadm drop-in |
| API 서버 인증 | X.509 클라이언트 인증서 | AWS STS 토큰 (aws eks get-token) |
| CA 인증서 | ca.crt만 존재 (ca.key는 컨트롤 플레인 노드에 있음) |
ca.crt만 존재 (ca.key는 AWS 관리, 접근 불가) |
| kubelet 서버 인증서 | kubeadm 발급, 1년 유효, 수동 갱신 | CSR 자동 발급, ~45일 유효, 자동 갱신 |
| CNI | Calico/Flannel (오버레이) | VPC CNI (ENI 기반, 오버레이 없음) |
| 파드 IP | 별도 CIDR (예: 10.244.0.0/16) | VPC 서브넷 IP (노드와 같은 CIDR) |
| 노드 등록 | kubeadm join (bootstrap token) |
자동 (IAM + NodeConfig) |
| manifests/ | 비어 있음 (Static Pod는 컨트롤 플레인 노드에만 존재) | 비어 있음 (컨트롤 플레인은 AWS 관리) |
| 커널 파라미터 | 수동 설정 (sysctl) | AMI에 사전 적용 |
| Swap | 수동 비활성화 (swapoff -a) |
AMI에서 파티션 자체가 없음 |
| cgroup | cgroup v1 또는 v2 (OS에 따라) | cgroup v2. system/runtime/kubepods 슬라이스 분리 |
정리
온프레미스에서 직접 설치·설정했던 컴포넌트(containerd, kubelet, 인증서, CNI)가 EKS에서는 AMI에 미리 포함되어 있고, nodeadm이 NodeConfig(userdata)를 기반으로 자동 설정한다. 노드 내부에서 확인해보면 구조 자체는 크게 다르지 않지만, “직접 설치 vs AMI에 포함”, “수동 설정 vs 자동 설정”의 차이가 일관되게 나타난다.
가장 눈에 띄는 차이는 세 가지다:
- 인증: X.509 인증서 대신 AWS STS 토큰 기반.
ca.key는 온프레미스에서도 워커 노드에 없지만, EKS에서는 컨트롤 플레인 자체에 접근할 수 없어 완전히 AWS 관리 영역 - 네트워크: 오버레이 없는 VPC 네이티브 CNI. 파드 IP가 VPC 서브넷 IP
- 설치·설정 자동화: 직접 설치(apt/yum)와 수동 설정(sysctl, swapoff) 대신 AMI + nodeadm이 모든 것을 대체
샘플 워크로드 배포
노드 내부 확인을 마쳤으니, 실제로 워크로드를 배포해 클러스터가 정상 동작하는지 확인한다.
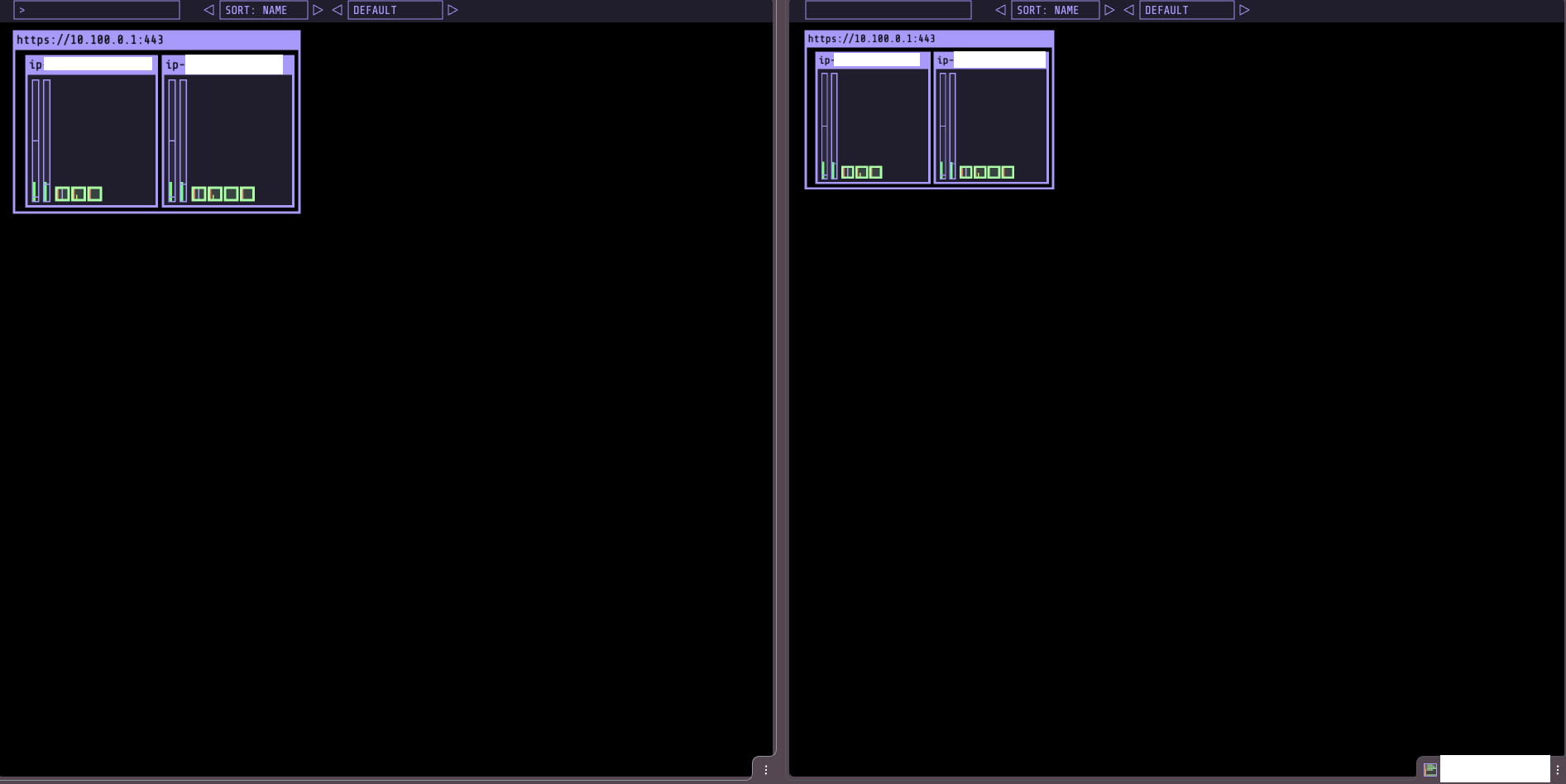
kube-ops-view
kube-ops-view는 클러스터의 노드와 파드 배치를 실시간으로 시각화해 주는 읽기 전용 대시보드다. Helm으로 설치한다.
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 \
--set service.main.type=NodePort,service.main.ports.http.nodePort=30000 \
--set env.TZ="Asia/Seoul" \
--namespace kube-system
kubectl get deploy,pod,svc,ep -n kube-system -l app.kubernetes.io/instance=kube-ops-view
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-ops-view 1/1 1 1 23s
NAME READY STATUS RESTARTS AGE
pod/kube-ops-view-97fd86569-b5kd5 1/1 Running 0 23s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-ops-view NodePort 10.100.150.191 <none> 8080:30000/TCP 23s
NAME ENDPOINTS AGE
endpoints/kube-ops-view 192.168.3.204:8080 23s
노드의 공인 IP와 NodePort 30000으로 접속하면 클러스터 상태를 시각적으로 확인할 수 있다.
open "http://$NODE1:30000/#scale=1.5"
게임 파드 (Super Mario)
NodePort 30001로 간단한 게임 애플리케이션을 배포한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mario
labels:
app: mario
spec:
replicas: 1
selector:
matchLabels:
app: mario
template:
metadata:
labels:
app: mario
spec:
containers:
- name: mario
image: pengbai/docker-supermario
---
apiVersion: v1
kind: Service
metadata:
name: mario
spec:
selector:
app: mario
ports:
- port: 80
protocol: TCP
targetPort: 8080
nodePort: 30001
type: NodePort
kubectl get deploy,pod,svc,ep mario
curl -I http://$NODE1:30001
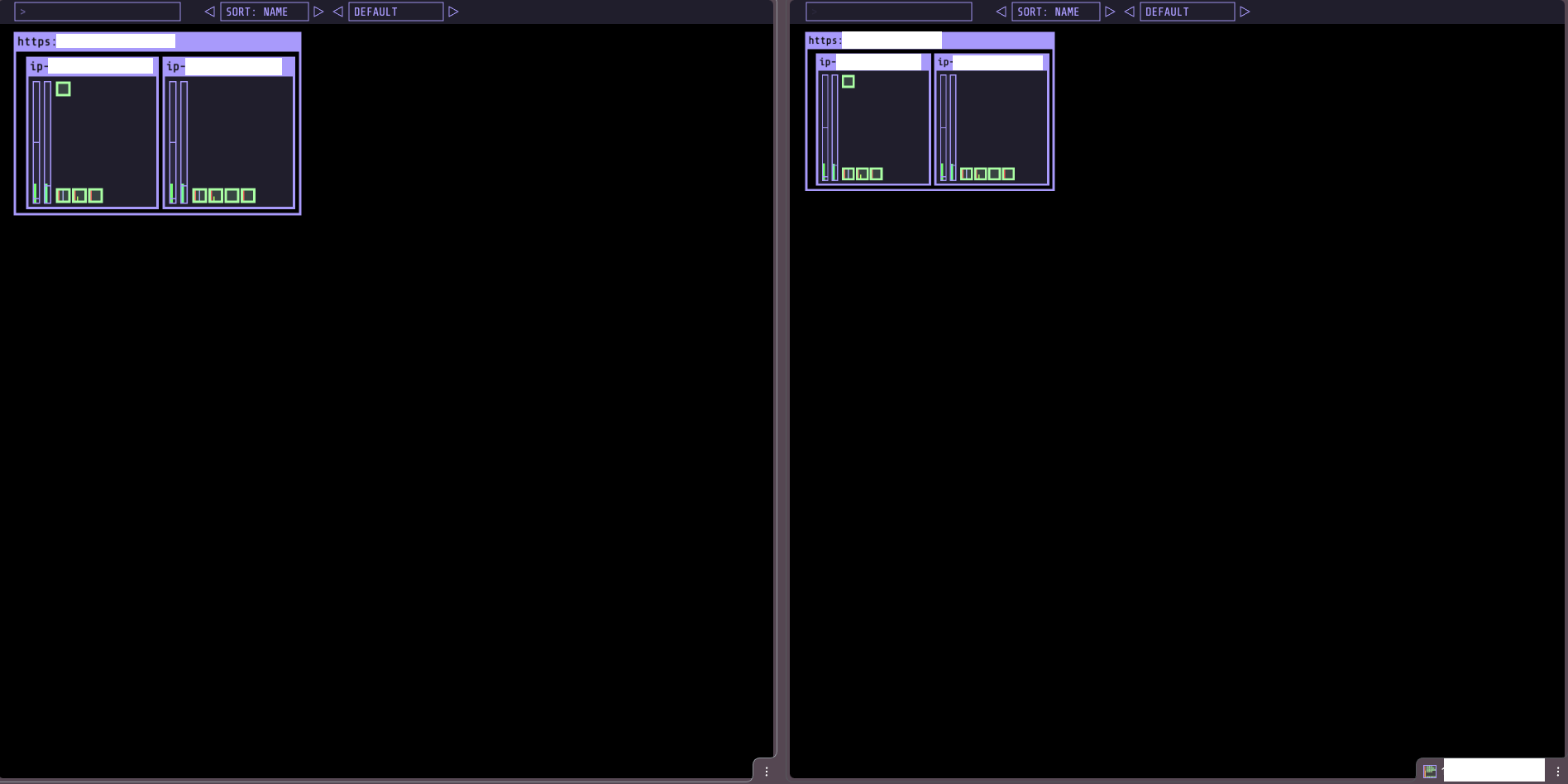

두 워크로드 모두 NodePort 서비스로 노출되어 노드 공인 IP로 직접 접속할 수 있다. 이것이 가능한 이유는 보안 그룹에서 30000-30002 포트가 허용되어 있기 때문이다.
결론
SSH로 워커 노드에 직접 들어가 확인한 결과, EKS 노드의 내부 구조는 온프레미스 Kubernetes 노드와 본질적으로 같다. containerd가 CRI로 동작하고, kubelet이 systemd 데몬으로 실행되며, 커널 파라미터·cgroup·인증서·iptables 규칙이 Kubernetes 노드로서 필요한 요구사항을 충족한다. 직접 설치하고 설정했던 것을 AMI와 nodeadm이 대신 해줄 뿐, 근본적인 메커니즘은 동일하다.
다만 “동일하다”고만 하기엔 놓칠 수 없는 차이가 있다. kubelet의 kubeconfig에서 X.509 클라이언트 인증서 대신 aws eks get-token이 들어간 순간, 인증 체계 전체가 AWS IAM으로 옮겨갔다. ca.key가 노드 어디에도 없다는 것은 클러스터의 신뢰 루트를 AWS가 독점적으로 관리한다는 뜻이다. VPC CNI가 오버레이 없이 ENI의 실제 IP를 파드에 할당하면서 br_netfilter가 불필요해진 것도, 단순한 구현 차이가 아니라 네트워크 모델 자체가 다르다는 것을 보여준다.
결국 EKS 워커 노드는 “Kubernetes 노드의 공통 요구사항은 그대로 충족하되, 인증·네트워크·인증서 관리를 AWS 인프라에 위임한 노드”다. 온프레미스 경험이 있으면 노드 내부를 읽는 데 어려움이 없고, AWS 통합 지점만 파악하면 된다.

댓글남기기