
[EKS] EKS: Networking - 0. 쿠버네티스 네트워킹 모델 - Service와 kube-proxy
서종호(가시다)님의 AWS EKS Workshop Study(AEWS) 2주차 학습 내용을 기반으로 합니다.
TL;DR
- Service는 파드 IP의 휘발성을 해결하는 추상화 계층이다. label selector로 파드를 선택하고, Endpoints가 실제 IP:Port 매핑을 추적한다
- Service 타입: ClusterIP(내부) → NodePort(노드 포트) → LoadBalancer(외부 LB)로 점진 확장된다
- kube-proxy는 모든 워커 노드에서 DaemonSet으로 동작하며, Endpoints 변경을 watch해서 커널에 DNAT/로드밸런싱 규칙을 설치한다
- 네트워크 규칙을 설치하는 두 컴포넌트:
- kube-proxy: Service 추상화 — DNAT(ClusterIP → Pod IP) + MASQUERADE(리턴 경로 보장)
- CNI 플러그인: 파드 네트워크 — SNAT(파드의 외부 통신 시 Pod IP → Node IP)
- 둘 다 POSTROUTING에 규칙을 설치하지만 매칭 조건이 다르므로 충돌하지 않는다. 이 NAT들은 “NAT 없이” 원칙에 위배되지 않는다
- kube-proxy 모드: userspace(초기, 프로세스가 직접 프록시) → iptables(기본, 커널 DNAT) → IPVS(해시 O(1)) → nftables(iptables 후속) → eBPF(커널 스택 우회, Cilium)
들어가며
이전 글에서 쿠버네티스 네트워킹의 핵심인 문제 2 — 파드 간 통신을 다뤘다. 같은 노드에서는 veth pair + 브릿지로, 다른 노드에서는 오버레이/BGP/클라우드 네이티브 라우팅으로 NAT 없이 파드 간 직접 통신을 구현하는 방식이었다.
이 글에서는 첫 번째 글에서 간단히 언급했던 문제 3 — 파드 ↔ 서비스, 그리고 문제 4 — 외부 ↔ 서비스 통신을 본격적으로 다룬다.
Service
배경: 파드 IP의 한계
파드 간 직접 통신(문제 2)이 해결되면, 파드 A가 파드 B의 IP를 알기만 하면 바로 통신할 수 있다. 그런데 실제 운영 환경에서는 이것만으로 부족하다.
파드 IP는 휘발성이다. 파드가 죽으면 IP가 사라지고, 새 파드가 뜨면 다른 IP를 받는다. Deployment로 3개의 nginx 파드를 띄웠다면, 스케일링이나 롤링 업데이트 때마다 IP가 바뀐다. 클라이언트가 특정 파드 IP를 하드코딩하면 파드가 재시작되는 순간 통신이 끊긴다.
이것은 쿠버네티스의 설계 철학에서 비롯된 의도된 결과다:
- 불변 인프라(Immutable Infrastructure): 쿠버네티스는 고장 난 파드를 고치지 않고 교체한다. 파드는 수리 대상이 아니라 교체 대상이다. 교체가 일상이니 IP도 매번 새로 할당되는 것이 자연스럽다. IP를 유지하려면 “이전 파드의 상태를 기억하고 복원”해야 하는데, 이는 불변 인프라 원칙에 위배된다.
- 스케줄링 자유도: 파드 IP가 안정적이려면 IP가 특정 노드나 네트워크 위치에 묶여야 한다. 그러면 스케줄러가 “이 IP가 있는 노드에만 파드를 배치”해야 하는 제약이 생긴다. 쿠버네티스 스케줄러는 리소스, affinity, taint 등 다양한 조건으로 아무 노드에나 파드를 배치할 수 있어야 하므로, IP를 노드에 종속시키면 이 자유도가 깨진다.
- 정체성과 위치의 분리: 가장 근본적인 설계 결정이다. 쿠버네티스는 서비스의 정체성(이름, 역할)과 네트워크 위치(IP)를 의도적으로 분리한다. “nginx 서비스”라는 정체성은 안정적이어야 하지만, 그 뒤에서 실제로 트래픽을 처리하는 파드들의 IP는 언제든 바뀔 수 있다. 이 분리 덕분에 스케일링, 롤링 업데이트, 자가 치유 모두 클라이언트에 영향 없이 동작한다.
파드는 cattle(가축)이지 pet(반려동물)이 아니다. 이 휘발성이 만드는 문제를 해결하기 위해 쿠버네티스가 도입한 추상화가 바로 Service다.
개념
이 문제를 해결하기 위해 쿠버네티스는 Service라는 추상화를 둔다.
[Service 없이]
Client → 10.244.1.5 (Pod A) ← Pod A가 죽으면? 연결 끊김
[Service 있음]
Client → 10.100.0.10 (Service ClusterIP) → 10.244.1.5 (Pod A) ← Pod A가 죽어도 Service IP는 유지
→ 10.244.1.6 (Pod B)
→ 10.244.1.7 (Pod C)
Service는 안정적인 가상 IP(ClusterIP)와 DNS 이름을 제공한다. 클라이언트는 Service IP(또는 my-service.default.svc.cluster.local 같은 DNS)로만 요청하면 된다.
Endpoints와 label selector
Service는 label selector로 백엔드 파드를 선택한다. selector: app=nginx를 지정하면, app=nginx 레이블을 가진 모든 파드가 이 Service의 백엔드가 된다.
쿠버네티스는 selector에 매칭되는 파드들의 실제 IP:Port 목록을 Endpoints(또는 EndpointSlice) 오브젝트에 기록한다. 파드가 생성되면 Endpoints에 추가되고, 죽으면 제거된다. Service 자체는 “어떤 파드를 선택할지”만 정의하고, 실제 IP:Port 매핑의 추적은 Endpoints가 담당한다.
Service (app=nginx, ClusterIP: 10.100.0.10)
└→ Endpoints
├ 10.244.1.5:80 (Pod A - Running, Ready)
├ 10.244.1.6:80 (Pod B - Running, Ready)
└ 10.244.1.7:80 (Pod C - Running, Ready)
kube-proxy의 역할
kube-proxy는 모든 워커 노드에서 DaemonSet으로 동작하며, API 서버를 watch하면서 Service와 Endpoints의 변경을 감지한다. 변경이 생기면 각 노드의 커널에 네트워크 규칙(iptables/IPVS/nftables)을 생성·갱신하여, Service의 가상 IP로 들어오는 패킷을 실제 파드 IP로 변환(DNAT)하고 로드 밸런싱한다.
정리하면:
| 구성 요소 | 역할 |
|---|---|
| Service | 안정적인 가상 IP + DNS 이름 제공. label selector로 백엔드 정의 |
| Endpoints | selector에 매칭되는 파드의 실제 IP:Port 목록을 추적 |
| kube-proxy | Endpoints 변경을 watch → 각 노드 커널에 DNAT/로드밸런싱 규칙 설치 |
계속해서 강조하지만, 첫 번째 글에서 정리했듯이, Service는 파드 간 통신 위에 얹히는 추상화 계층이다. 문제 2가 풀려야 DNAT 이후의 실제 파드 도달이 가능하다.
유형
Service 타입은 어디에서 Service에 접근할 수 있느냐를 결정한다. 세 가지 타입이 점진적으로 확장되는 구조다.
ClusterIP
클러스터 내부에서만 접근 가능한 가상 IP를 할당한다. Service의 기본 타입이다.
ClusterIP는 어떤 노드의 인터페이스에도 바인딩되지 않는 가상 IP다. kube-proxy가 설정한 iptables/IPVS 규칙에 의해서만 의미를 갖는다. 클러스터 외부에서는 이 IP로 도달할 수 없다.
NodePort
ClusterIP에 더해, 모든 노드의 특정 포트(기본 30000-32767)를 열어 외부에서 접근할 수 있게 한다.
NodePort는 ClusterIP를 포함한다. NodePort Service를 만들면 ClusterIP도 자동으로 할당된다. 외부에서 노드IP:NodePort로 접근하면 kube-proxy 규칙이 실제 파드로 전달한다.
LoadBalancer
NodePort에 더해, 외부 로드 밸런서를 프로비저닝하여 단일 진입점을 제공한다.
LoadBalancer는 NodePort를 포함한다. 즉 ClusterIP + NodePort + 외부 LB라는 3계층 구조다. 클라우드 환경에서는 Cloud Controller Manager가 클라우드 API를 호출하여 로드 밸런서(AWS에서는 NLB/CLB)를 자동으로 생성하고, 노드의 NodePort로 트래픽을 전달한다.
Service 타입과 네트워킹 문제의 관계
첫 번째 글의 문제 분류와 연결해 각 서비스 타입이 4가지 네트워킹 문제 중 어느 문제를 해결하는지 확인해 보자.
| Service 타입 | 해결하는 문제 |
|---|---|
| ClusterIP | 문제 3 (파드 ↔ 서비스): 클러스터 내부에서 안정적인 서비스 디스커버리 |
| NodePort | 문제 4 (외부 ↔ 서비스): 노드 포트를 통한 외부 접근 |
| LoadBalancer | 문제 4 (외부 ↔ 서비스): 외부 LB를 통한 단일 진입점 |
ClusterIP가 문제 3의 기본 해결이다. NodePort와 LoadBalancer는 문제 4(외부 접근)를 풀지만, 내부적으로 ClusterIP를 포함한다는 것이 핵심이다. 외부에서 노드IP:NodePort로 들어온 트래픽도 결국 ClusterIP의 DNAT 규칙을 거쳐 파드에 도달한다. 즉 문제 4의 해결은 문제 3(ClusterIP)이 기반이고, 문제 3의 DNAT 이후 마지막 홉에서는 문제 2(파드 간 통신)의 인프라 위에서 실제 파드에 도달한다. 문제 2 → 문제 3 → 문제 4가 순서대로 쌓이는 계층 구조다.
Service의 동작 원리
ClusterIP는 가상 IP다
Service의 ClusterIP는 어떤 노드의 어떤 인터페이스에도 바인딩되지 않는 가상 IP다. 네트워크 인프라(온프레미스 라우터든, 클라우드 SDN이든)도 이 IP를 모르고, 라우팅 테이블에도 없다. 파드 IP는 CNI 플러그인이 네트워크 인터페이스에 실제로 할당한 IP이기 때문에 커널의 기본 라우팅만으로 도달 가능하지만, ClusterIP로 패킷을 보내면 커널은 이 IP를 모르므로 그대로 드롭한다.
커널에 규칙을 설치해야 한다
따라서 Service가 동작하려면 누군가가 커널에 규칙을 설치해야 한다. ClusterIP로 온 패킷을 실제 파드 IP로 바꾸는 DNAT 규칙, 리턴 경로를 보장하는 MASQUERADE 규칙, 외부 통신을 위한 SNAT 규칙 등 — 커널이 이 가상 IP를 인식하고 처리할 수 있도록 별도의 규칙을 설치해야 한다.
이 규칙을 설치하는 주체는 두 컴포넌트다: kube-proxy와 CNI 플러그인. 전체 네트워킹 인프라 관점에서 보면 두 컴포넌트의 목적이 뚜렷하게 나뉜다:
| 컴포넌트 | 목적 | 설치하는 규칙 |
|---|---|---|
| kube-proxy | Service 추상화 — 가상 IP를 실제 파드 IP로 변환 | DNAT(ClusterIP → Pod IP), MASQUERADE(리턴 경로 보장) |
| CNI 플러그인 | 파드 네트워크 통신 — 파드가 외부와 통신할 수 있게 함 | SNAT(Pod IP → Node IP, 외부 통신 시) |
kube-proxy는 Service라는 상위 추상화 계층의 규칙을, CNI는 파드 네트워크 자체의 규칙을 담당한다. 각각이 설치하는 규칙을 kubeadm 클러스터 기준으로 이전에 정리한 적이 있다.
kube-proxy가 설치하는 규칙
kube-proxy의 핵심 특성:
- UDP, TCP, SCTP를 프록시한다. HTTP를 이해하지 않는 L4 프록시다
- 로드 밸런싱을 제공한다. Service 뒤의 여러 파드에 트래픽을 분산한다
- Service에 대한 접근에만 사용된다. 파드 간 직접 통신(문제 2)과는 무관하다
kube-proxy가 설치하는 규칙은 두 곳에 들어간다:
PREROUTING / OUTPUT: DNAT
PREROUTING (외부/파드에서 들어오는 패킷)
└→ KUBE-SERVICES
└→ DNAT: Service ClusterIP:Port → Pod IP:Port
OUTPUT (노드 자체 프로세스가 Service에 접근할 때)
└→ KUBE-SERVICES
└→ DNAT: Service ClusterIP:Port → Pod IP:Port
패킷의 목적지를 Service의 가상 IP에서 실제 파드 IP로 바꾼다. PREROUTING은 외부나 파드에서 들어오는 패킷을, OUTPUT은 노드 자체 프로세스(kubelet 등)가 보내는 패킷을 처리한다.
POSTROUTING: MASQUERADE
POSTROUTING
└→ KUBE-POSTROUTING
└→ mark 0x4000인 패킷만 → MASQUERADE (src IP를 노드 IP로 변경)
kube-proxy는 DNAT을 수행할 때 패킷에 마크(0x4000)를 찍는다. POSTROUTING에서 이 마크가 있는 패킷만 골라 MASQUERADE를 적용한다. 목적은 DNAT된 Service 트래픽의 리턴 패킷이 반드시 DNAT을 수행한 노드로 돌아오도록 소스 IP를 노드 IP로 바꾸는 것이다.
왜 리턴 경로를 보장해야 하는가? 파드 B가 응답을 보낼 때 dst는 원래 클라이언트 IP인데, 만약 src가 바뀌지 않았다면 응답이 DNAT을 수행한 노드를 거치지 않고 직접 클라이언트로 갈 수 있다. 그러면 클라이언트는 자신이 보낸 적 없는 IP(파드 IP)에서 응답을 받게 되어 TCP 연결이 깨진다.
CNI 플러그인이 설치하는 규칙
CNI 플러그인(여기서는 AWS VPC CNI를 예시로)도 POSTROUTING에 규칙을 설치한다. 목적은 kube-proxy와 완전히 다르다.
POSTROUTING: SNAT
POSTROUTING
└→ AWS-SNAT-CHAIN-0
└→ dest가 VPC CIDR 밖인 패킷 → SNAT (Pod IP → Node Primary IP)
파드가 VPC CIDR 외부(인터넷 등)로 통신할 때, Pod IP를 Node의 Primary IP로 변환한다. VPC 내부 통신에는 적용하지 않는다. 파드 IP가 VPC의 실제 IP이므로 VPC 안에서는 라우팅 가능하기 때문이다.
AWS_VPC_K8S_CNI_EXTERNALSNAT=true로 설정하면 이 SNAT을 비활성화하고, 외부 NAT Gateway에게 맡길 수도 있다.
POSTROUTING에서의 공존
kube-proxy와 CNI 플러그인 모두 POSTROUTING 체인에 규칙을 설치하지만, 매칭 조건이 다르므로 충돌하지 않는다:
| 누가 | 체인 | 매칭 조건 | 동작 | 목적 |
|---|---|---|---|---|
| kube-proxy | KUBE-POSTROUTING |
mark 0x4000 있는 패킷 |
MASQUERADE | Service DNAT 리턴 경로 보장 |
| AWS VPC CNI | AWS-SNAT-CHAIN-0 |
dest가 VPC CIDR 밖 | SNAT → Node IP | 파드의 외부 통신 |
kube-proxy는 “DNAT했다”는 마크가 찍힌 패킷만, CNI는 “VPC 밖으로 나가는” 패킷만 각각 처리한다.
“NAT 없이” 원칙과의 관계
여기서 의문이 생길 수 있다. 쿠버네티스 네트워킹 모델은 “NAT 없이”를 대원칙으로 내세우는데, kube-proxy의 DNAT과 MASQUERADE, CNI의 SNAT은 전부 NAT이 아닌가?
첫 번째 글에서 정리했듯이, 위배되지 않는다. “NAT 없이” 원칙은 문제 2(파드 ↔ 파드 직접 통신 경로)에만 적용된다.
- kube-proxy의 DNAT/MASQUERADE: Service는 파드 간 직접 통신 위에 얹히는 상위 추상화 계층이다. “파드 A가 파드 B의 IP로 직접 패킷을 보내는” 경로가 아니라, “파드 A가 Service의 가상 IP로 보내면 kube-proxy가 파드 B의 IP로 바꿔주는” 경로다. 계층이 다르다.
- CNI의 외부 SNAT: 파드가 클러스터 외부(인터넷)와 통신하는 것은 파드 ↔ 파드 직접 통신의 범위 밖이다.
파드 A가 파드 B의 IP를 직접 목적지로 지정하고 패킷을 보내면, 그 경로의 어느 지점에서도 IP가 변조되지 않는다. 이것이 “NAT 없이” 원칙이 보호하는 것이고, Service DNAT과 외부 SNAT은 이 경로와 다른 계층/범위에서 동작한다.
kube-proxy 동작 모드
kube-proxy는 Service의 가상 IP를 실제 파드 IP로 변환하는 규칙을 관리한다. 이 규칙을 어떤 메커니즘으로 관리하느냐에 따라 동작 모드가 나뉜다. 역사적으로 userspace → iptables → IPVS → nftables → eBPF 순서로 발전해 왔다.
userspace 모드
kube-proxy의 최초 구현(v1.0 기본값)이다. 이름 그대로 kube-proxy 프로세스가 직접 프록시 역할을 했다. 현재는 사용되지 않지만, 이후 모드들이 왜 커널 기능을 사용하게 됐는지 이해하는 데 중요하다.
Service 10.96.0.100:80 → 백엔드 Pod 10.244.1.5:8080으로 트래픽을 보내는 상황을 가정한다.
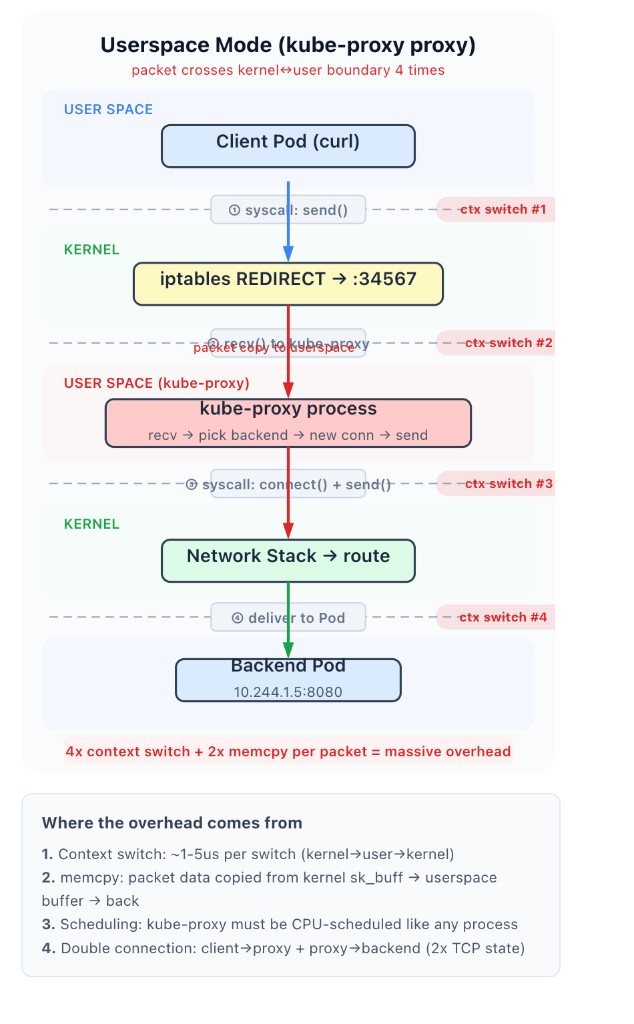
userspace 모드에서는 iptables REDIRECT로 Service IP 트래픽을 kube-proxy의 로컬 포트로 전환하고, kube-proxy 프로세스가 직접 recv() → 백엔드 선택 → connect() + send()를 수행한다.
# 1) iptables가 Service IP 트래픽을 kube-proxy의 로컬 포트로 REDIRECT
iptables -t nat -A PREROUTING \
-d 10.96.0.100 -p tcp --dport 80 \
-j REDIRECT --to-port 34567
# 2) kube-proxy 프로세스가 :34567에서 listen
# recv()로 패킷 수신 → 백엔드 선택 → 새 TCP 연결 생성
# connect(10.244.1.5:8080) → send(data)
이 과정에서 패킷 데이터가 커널 버퍼(sk_buff)에서 kube-proxy의 userspace 버퍼로 복사되고, 다시 새 소켓을 통해 커널로 돌아간다. 패킷 하나당 커널↔유저 경계를 4번 넘는다.
성능 문제
| 문제 | 설명 |
|---|---|
| Context switch | 커널↔유저 전환마다 레지스터 저장/복원, TLB flush, 스택 전환이 발생한다. 1회에 ~1-5μs인데, 초당 수만 패킷이면 누적된다 |
| Memory copy | recv() 시 sk_buff → 유저 버퍼, send() 시 유저 버퍼 → sk_buff로 2번 복사한다. 커널 모드에서는 sk_buff의 헤더만 수정하면 되므로 복사가 없다 |
| Double TCP state | client→kube-proxy, kube-proxy→backend로 TCP 연결이 2개 필요하다. 핸드셰이크, 윈도우 관리, 타이머가 모두 2배다 |
| SPOF | kube-proxy 프로세스가 죽으면 모든 Service 트래픽이 즉시 중단된다. 프로세스가 패킷 경로 한가운데 있기 때문이다 |
Kubernetes 초기(2014~2015)에는 클러스터가 수십 노드·수백 파드 규모였고, 이 스케일에서는 userspace 프록시의 오버헤드가 체감되지 않았다. 설계 우선순위가 성능보다 정확성과 구현 단순성이었기 때문에, Go로 net.Listener + net.Dial 몇 줄이면 동작하는 가장 단순한 구현을 택한 것이다. Kubernetes가 급속히 성장하면서 성능 문제가 드러나자 커널 기반으로 전환했고, 이름만 “proxy”로 남았다.
iptables 모드
커널 netfilter 서브시스템의 iptables API로 패킷 포워딩 규칙을 관리하는 모드다. v1.2부터 기본값이 되었고, EKS를 포함한 대부분의 쿠버네티스 클러스터에서 현재도 기본값으로 사용된다.
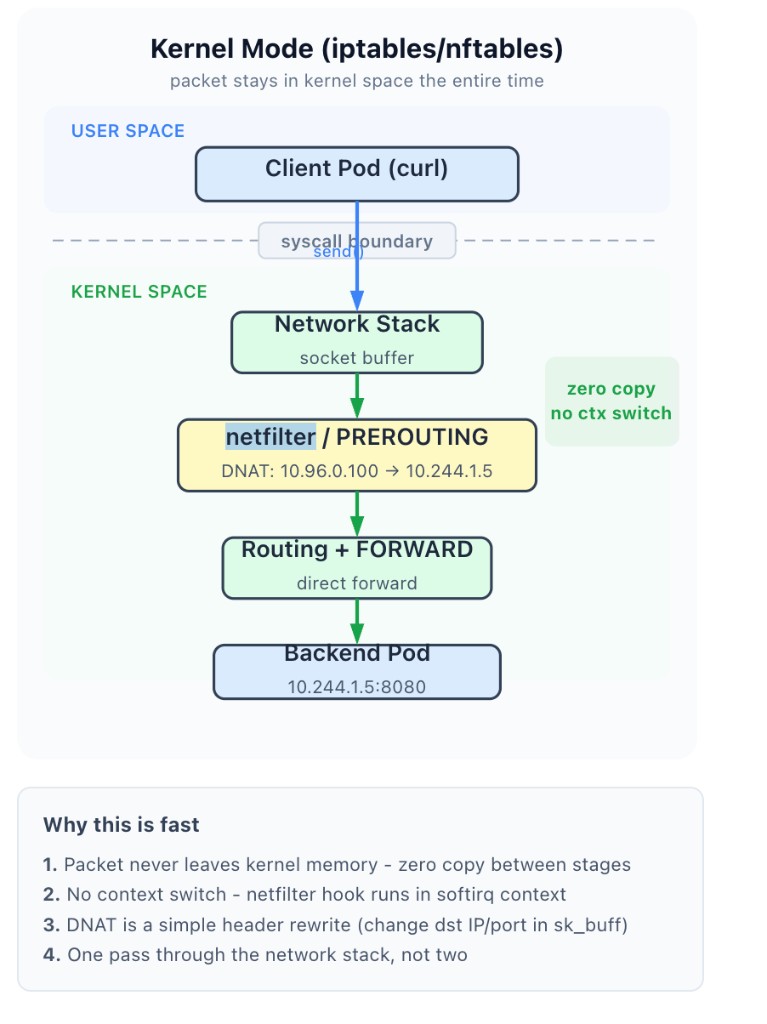
userspace 모드와의 핵심 차이는 kube-proxy가 직접 프록시를 하지 않는다는 것이다. kube-proxy는 netfilter 규칙만 설정하고, 실제 패킷 처리는 커널의 netfilter가 전부 담당한다.
# netfilter PREROUTING chain에서 바로 DNAT — userspace를 거치지 않는다
iptables -t nat -A PREROUTING \
-d 10.96.0.100 -p tcp --dport 80 \
-j DNAT --to-destination 10.244.1.5:8080
패킷의 dst IP 헤더가 커널 메모리(sk_buff) 안에서 직접 10.96.0.100 → 10.244.1.5로 바뀌고, 그대로 라우팅되어 파드에 도달한다. context switch도 memcpy도 없다.
- kube-proxy의 역할: iptables 규칙 생성·갱신 (규칙 관리)
- netfilter의 역할: 패킷 매칭 → DNAT 수행 (실제 패킷 처리)
kube-proxy가 죽어도 이미 설정된 규칙은 커널에 남아 있으므로 기존 Service 통신은 계속된다. 규칙 추가·삭제만 안 될 뿐이다. userspace 모드에서는 kube-proxy가 패킷 경로 한가운데에 있어서 죽으면 Service 통신이 전부 끊겼던 것(SPOF)과 대비된다.

iptables 체인의 패킷 흐름을 정리하면:
- 패킷이 노드에 들어오면(PREROUTING) 또는 로컬 프로세스가 보내면(OUTPUT),
KUBE-SERVICES체인으로 진입한다 KUBE-SERVICES에서 목적지 ClusterIP:Port를 매칭하여 해당 서비스의KUBE-SVC-*체인으로 분기한다KUBE-SVC-*체인에서 확률 기반으로 백엔드 파드를 선택한다 — 랜덤 로드 밸런싱. 예를 들어 파드가 3개면 각각 1/3, 1/2, 1 확률로 iptables 규칙이 체이닝된다- 선택된
KUBE-SEP-*체인에서 DNAT을 수행한다. 목적지 IP:Port를 실제 파드 IP:Port로 변환한다
한계: 서비스 수가 늘어나면 KUBE-SERVICES 체인이 길어진다. iptables는 규칙을 선형 탐색(O(n))하므로, 서비스가 수천 개를 넘어가면 성능이 저하된다. 또한 규칙을 업데이트할 때 전체 테이블을 재작성해야 한다.
IPVS 모드
커널의 IPVS(IP Virtual Server)와 iptables API를 함께 사용하는 모드다. IPVS는 리눅스 커널에서 제공하는 L4 로드 밸런서로, netfilter 훅을 기반으로 하지만 해시 테이블을 사용하여 커널 스페이스에서 동작한다.
iptables: 선형 탐색 O(n) → 규칙이 많을수록 느려짐
IPVS: 해시 조회 O(1) → 규칙 수에 무관하게 일정한 성능
iptables 모드 대비 핵심 차이는:
- 조회 성능: 해시 기반 O(1) 조회로, 서비스가 수천~수만 개여도 성능이 일정하다
- 업데이트 비용: 전체 재작성 대신 테이블 항목 단위로 수정할 수 있다
- 다양한 LB 알고리즘: iptables는 랜덤만 지원하는 반면, IPVS는 Round Robin(RR), Least Connection(LC), Source Hashing(SH) 등 6가지 알고리즘을 지원한다
IPVS 모드를 사용하려면 노드에 ip_vs 커널 모듈이 로드되어 있어야 한다. 모듈이 없으면 kube-proxy가 iptables 모드로 자동 폴백한다.
IPVS 모드 지원 중단 예정: Kubernetes v1.35부터 kube-proxy의 IPVS 모드 지원이 중단될 예정이다 (KEP-5495). 대안으로 nftables 모드가 권장된다. 실습 환경 확인 편에서도 확인한다.
nftables 모드
커널 netfilter 서브시스템의 nftables API로 규칙을 관리하는 모드다. nftables는 iptables의 후속 기술이다.
커널 5.13 이상이 필요하다. Kubernetes 1.31 기준 아직 상대적으로 새로운 모드다.
nftables가 iptables를 대체하려는 이유는 명확하다:
- 셋(set) 기반 조회 O(1): iptables의 선형 탐색 대신 셋 자료구조를 사용한다
- 업데이트 효율: 전체 재작성 없이 셋 항목만 수정하면 된다
- API 통합: iptables, ip6tables, arptables, ebtables가 각각 별도였던 것을 nftables 하나로 통합한다
iptables와 nftables의 관계를 짚으면, 둘 다 커널의 netfilter 서브시스템 위에서 동작한다. netfilter가 커널의 패킷 처리 프레임워크이고, iptables와 nftables는 이 프레임워크를 제어하는 인터페이스(API)다. nftables는 iptables보다 효율적인 방식으로 netfilter를 제어한다.
eBPF 모드 (Cilium)
kube-proxy를 완전히 대체하는 방식이다. Cilium CNI가 eBPF(extended Berkeley Packet Filter) 프로그램을 커널에 로드하여, netfilter/iptables 스택 자체를 우회한다.
[iptables/IPVS/nftables 모드]
패킷 → netfilter 훅 → 규칙 매칭 → DNAT → 전달
[eBPF 모드 (Cilium)]
패킷 → XDP/TC 훅 → eBPF 맵 조회 → 직접 전달 ← netfilter 스택을 거치지 않음
eBPF 프로그램이 커널의 XDP(eXpress Data Path)나 TC(Traffic Control) 훅에 붙어서, 패킷이 네트워크 스택을 타기 전에 처리한다. netfilter 체인을 거치는 오버헤드가 없으므로 가장 높은 성능을 낸다. 맵(map) 기반 O(1) 조회를 사용하고, L7 정책 적용도 가능하다.
Cilium CNI + 커널 4.9 이상이 필요하다. kube-proxy를 아예 배포하지 않고(--kube-proxy-replacement=true) Cilium이 Service 구현을 전부 담당한다.
모드 비교 정리
| 항목 | userspace | iptables | IPVS | nftables | eBPF (Cilium) |
|---|---|---|---|---|---|
| 처리 위치 | kube-proxy 프로세스 | netfilter 훅 | netfilter + IPVS | netfilter nftables | XDP / TC (스택 우회) |
| 패킷 경로 | 커널↔유저 왕복 | 커널 내부에서 완결 | 커널 내부에서 완결 | 커널 내부에서 완결 | 커널 내부에서 완결 |
| 조회 방식 | 프로세스 내 선택 | 선형 탐색 O(n) | 해시 조회 O(1) | 셋 조회 O(1) | 맵 조회 O(1) |
| 업데이트 비용 | 없음 (런타임 선택) | 전체 재작성 | 테이블 항목 수정 | 셋 항목만 수정 | 맵 항목만 수정 |
| LB 알고리즘 | Round Robin | 랜덤만 | RR, LC, SH 등 6종 | 랜덤 | 다양 + L7 가능 |
| kube-proxy 필요 | 필요 (SPOF) | 필요 | 필요 | 필요 | 불필요 (대체) |
| 요구사항 | — | 기본 내장 | ip_vs 모듈 필요 |
커널 5.13+ | Cilium CNI + 커널 4.9+ |
| 상태 | v1.0 기본 → 폐기 | 현재 기본값 | v1.35 deprecated | beta (v1.31+) | Cilium 전용 |
userspace → iptables로의 전환이 가장 근본적인 변화다. 프로세스가 패킷을 직접 처리하던 구조에서 커널이 처리하는 구조로 바뀌면서 성능과 안정성이 모두 해결됐다. 이후 iptables → IPVS → nftables → eBPF는 커널 내부에서 어떤 자료구조와 API를 쓰느냐의 차이다.
EKS 기본값은 iptables다. 서비스가 수천 개 이상이면 nftables 전환을 고려하고, 고성능 + L7 정책이 필요하면 Cilium eBPF를 검토한다.
네트워크 스택과 패킷 흐름
앞에서 Service의 개념과 네트워크 규칙을 다뤘다. 이제 이것들이 노드의 네트워크 스택에서 실제로 어떻게 배치되고, 패킷이 어떤 경로를 타는지 살펴본다.
단일 노드 네트워크 스택
먼저 한 노드 안에 어떤 레이어가 있고, 누가(kube-proxy, CNI) 어디에 규칙을 설치하는지 전체 그림을 잡는다.
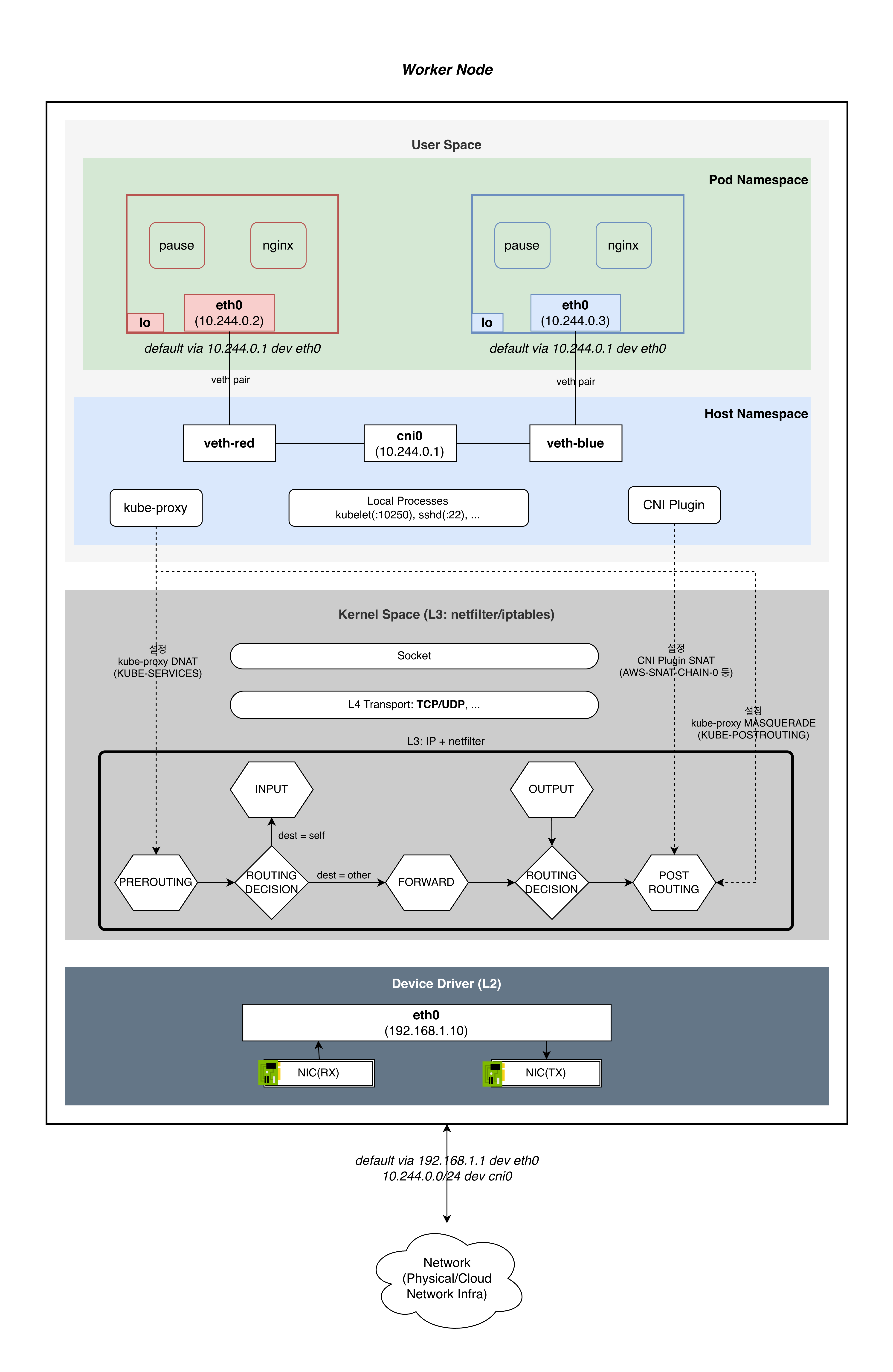
구성 요소
| 레이어 | 요소 | 설명 |
|---|---|---|
| User Space / Pod NS | Pod A, Pod B | pause + app 컨테이너. 각자 lo, eth0, IP를 가진다 |
| User Space / Pod NS | veth pair | Pod NS와 Host NS를 연결하는 가상 이더넷 케이블 |
| User Space / Host NS | veth-a, veth-b | veth pair의 호스트 측 끝 |
| User Space / Host NS | cni0 bridge | L2 스위치 역할 (Flannel/Calico bridge 모드). VPC CNI는 bridge 없이 호스트 라우트 사용 |
| User Space / Host NS | Local Processes | kubelet, kube-proxy, aws-node(CNI), sshd 등 |
| Kernel Space | PREROUTING | kube-proxy가 KUBE-SERVICES 점프 설치 (DNAT) |
| Kernel Space | ROUTING DECISION | dest IP 기반 분기: 노드 자체면 INPUT, 다른 곳이면 FORWARD |
| Kernel Space | INPUT | 노드 자체 수신 → Socket → local process |
| Kernel Space | OUTPUT | local process → Socket → kube-proxy KUBE-SERVICES 점프 (DNAT) |
| Kernel Space | FORWARD | 파드 트래픽 전달 (veth → veth 또는 veth → NIC) |
| Kernel Space | POSTROUTING | CNI: AWS-SNAT-CHAIN-0(외부 SNAT), kube-proxy: KUBE-POSTROUTING(Service MASQUERADE) |
| Kernel Space | Socket, TCP/UDP | 프로토콜 스택. INPUT ↔ Socket ↔ OUTPUT 경로 |
| Device Driver | eth0/ens5 | 물리/가상 NIC (192.168.1.10) |
| Hardware | NIC RX/TX | 패킷 수신/송신 하드웨어 |
netfilter 체인과 규칙 설치자
핵심은 누가 어떤 체인에 무엇을 설치하는가다:
| 체인 | 설치자 | 규칙 | 설명 |
|---|---|---|---|
| PREROUTING | kube-proxy | KUBE-SERVICES → DNAT |
Service ClusterIP → Pod IP 변환 |
| OUTPUT | kube-proxy | KUBE-SERVICES → DNAT |
노드 자체 프로세스가 Service 접근 시 |
| POSTROUTING | kube-proxy | KUBE-POSTROUTING → MASQUERADE |
mark 0x4000 패킷의 src IP를 노드 IP로 변환 |
| POSTROUTING | CNI (aws-node) | AWS-SNAT-CHAIN-0 → SNAT |
Pod IP → Node IP (외부 통신) |
CNI 방식별 변형
위 다이어그램은 Flannel/Calico의 bridge 모드 기준이다. CNI에 따라 Host NS 영역이 달라진다:
| CNI | Host NS 영역 차이 |
|---|---|
| Flannel/Calico (bridge) | cni0 bridge 존재. veth들이 bridge에 연결 |
| VPC CNI | bridge 없음. 각 veth에 대한 호스트 라우트(/32 dev eniXXX) + policy routing(ip rule) |
| Cilium (eBPF) | eBPF가 netfilter 일부를 바이패스. TC/XDP 훅 포인트가 추가 |
ClusterIP 패킷 흐름
클러스터 내부 파드가 Service ClusterIP를 통해 다른 파드에 접근하는 경우다. VPC CNI 기준으로 설명한다.
시작점은 NIC(RX)가 아니라 파드의 veth다. ClusterIP는 클러스터 내부 접근이므로, 패킷이 외부에서 NIC로 들어오는 게 아니라 파드의 veth에서 호스트 네임스페이스로 진입한다. veth로 들어오는 트래픽도 커널에서는 “인터페이스 수신”이므로 PREROUTING을 거친다.

| 단계 | 위치 | 동작 |
|---|---|---|
| (1) | Pod A eth0 → veth | 파드가 ClusterIP:port로 패킷 전송. veth pair를 통해 호스트 NS 진입 |
| (2) | PREROUTING | veth에서 수신된 패킷. KUBE-SERVICES 체인에서 DNAT: ClusterIP → Pod B IP |
| (3) | ROUTING DECISION | DNAT 후 dest가 Pod B IP로 변경됨. 이 IP가 어디에 있는지 라우팅 판단 |
| (4)-A | FORWARD → veth-b | 같은 노드: host route 매칭 → veth pair로 Pod B에 전달 |
| (4)-B | FORWARD → POSTROUTING → ENI | 다른 노드: default route → ENI → VPC로 전송. VPC 내부이므로 SNAT은 RETURN(미적용) |
| (5) | Pod B eth0 | 패킷 도착. dest=Pod B IP(DNAT 후), src=Pod A IP(변경 없음) |
NodePort 패킷 흐름
외부 클라이언트가 NodeIP:NodePort로 접근하는 경우다.
ClusterIP와의 핵심 차이는 시작점이다. ClusterIP는 veth에서 시작하지만, NodePort는 NIC(RX)에서 시작한다. 외부에서 노드 IP로 패킷이 들어오기 때문이다. 그리고 externalTrafficPolicy 설정에 따라 POSTROUTING에서 MASQUERADE 적용 여부가 달라진다.

| 단계 | 위치 | 동작 |
|---|---|---|
| (1) | NIC(RX) → PREROUTING | 외부에서 NodeIP:NodePort로 도착. KUBE-NODEPORTS에서 DNAT |
| (2) | ROUTING DECISION | DNAT 후 dest가 Pod IP로 변경. 이 IP가 어디에 있는지 판단 |
| (3)-A | FORWARD → veth | 이 노드에 Pod 있음: host route → veth → Pod. SNAT 없음 → 클라이언트 IP 보존 |
| (3)-B | FORWARD → POSTROUTING | 다른 노드에 Pod 있음: FORWARD 후 POSTROUTING |
| (4) | POSTROUTING | Cluster 정책 → MASQUERADE(src=ClientIP → Node1IP). Local 정책 → 이 노드에 Pod 없으면 DROP |
| (5) | Pod | 수신. Case A: src=Client IP. Case B(Cluster): src=Node1 IP (클라이언트 IP 손실) |
externalTrafficPolicy
externalTrafficPolicy는 NodePort/LoadBalancer에서 외부 트래픽이 다른 노드로 전달될 때의 동작을 결정한다:
| 정책 | 장점 | 단점 |
|---|---|---|
Cluster (기본) |
모든 노드가 트래픽 수용, 부하 분산 | 클라이언트 IP 손실(SNAT), 추가 홉 |
Local |
클라이언트 IP 보존, 홉 감소 | Pod 없는 노드는 DROP, 불균등 분배 |
LoadBalancer 패킷 흐름
LoadBalancer = NodePort 앞에 외부 로드 밸런서를 추가한 것이다. 로드 밸런서의 Target Mode에 따라 두 가지 경로가 나뉜다.

Instance Target Mode (기본)
LB가 노드 IP:NodePort로 트래픽을 보낸다. 노드에서의 처리는 NodePort 흐름과 완전히 동일하다. PREROUTING에서 DNAT하고, FORWARD를 거쳐 파드에 도달한다.
IP Target Mode
VPC CNI + NLB 조합에서 사용 가능하다. LB가 파드 IP:Port로 직접 트래픽을 보낸다. 파드 IP가 VPC에서 라우팅 가능한 IP이므로, LB가 NodePort를 거치지 않고 파드에 직접 도달할 수 있다. NodePort → DNAT 단계를 통째로 건너뛴다.
| Mode | LB 목적지 | 노드에서의 처리 | 비고 |
|---|---|---|---|
| Instance (기본) | Node IP:NodePort | NodePort 흐름과 동일 (DNAT → FORWARD → …) | 모든 CNI에서 사용 가능 |
| IP | Pod IP:Port 직접 | DNAT 불필요. PREROUTING → FORWARD → veth → Pod | VPC CNI + NLB. 파드 IP가 VPC에서 라우팅 가능하므로 직접 도달 |
IP Target Mode는 VPC CNI의 “파드 IP = VPC IP” 특성을 활용한다. 이 구조의 세부 동작 —
externalTrafficPolicy설정, Pod Readiness Gate, 헬스 체크 등 — 은 EKS 서비스 실습에서 구체적으로 다룬다.
정리
이 글에서는 쿠버네티스 네트워킹의 문제 3(파드 ↔ 서비스)과 문제 4(외부 ↔ 서비스)를 다뤘다.
- Service:
- 파드 IP의 휘발성을 해결하는 추상화 계층. label selector로 파드를 선택하고, Endpoints가 실제 IP:Port를 추적한다
- 유형: ClusterIP(내부) → NodePort(노드 포트) → LoadBalancer(외부 LB)로 점진 확장
- 네트워크 규칙 (두 컴포넌트가 각각의 목적으로 설치):
- kube-proxy(모든 워커 노드의 DaemonSet): Service 추상화 — DNAT(ClusterIP → Pod IP) + MASQUERADE(리턴 경로 보장)
- CNI 플러그인: 파드 네트워크 — SNAT(파드의 외부 통신 시 Pod IP → Node IP)
- 둘 다 POSTROUTING에 있지만 매칭 조건이 다르므로 충돌하지 않는다. “NAT 없이” 원칙에 위배되지 않는다
- kube-proxy 모드: userspace(초기, SPOF) → iptables(기본, 커널 DNAT) → IPVS(해시) → nftables(후속) → eBPF(스택 우회)
- 패킷 흐름:
- ClusterIP: veth → PREROUTING(DNAT) → FORWARD → veth(같은 노드) 또는 ENI(다른 노드)
- NodePort: NIC(RX) → PREROUTING(DNAT) → FORWARD → Pod.
externalTrafficPolicy에 따라 MASQUERADE 분기 - LoadBalancer: Instance mode는 NodePort와 동일, IP target mode는 DNAT 없이 파드 직접 도달
여기까지 쿠버네티스 네트워킹 모델의 세 가지 문제를 개념 수준에서 정리했다. 다음 글부터는 EKS 환경에서 이 개념들이 어떻게 구현되는지 본격적으로 살펴본다.
참고 링크
- Kubernetes Service 공식 문서
- Virtual IPs and Service Proxies
- kube-proxy 공식 문서
- 커피고래 - k8s network 02
- Finda Tech - Kubernetes 네트워크 정리
- IPVS - Linux Virtual Server
- nftables 프로젝트
- iptables와 nftables의 관계 - Red Hat


댓글남기기