
[EKS] EKS: Networking — 쿠버네티스 네트워킹 모델
서종호(가시다)님의 AWS EKS Workshop Study(AEWS) 2주차 학습 내용을 기반으로 합니다.
TL;DR
AWS VPC CNI를 본격적으로 공부하기에 앞서, VPC CNI가 해결하는 문제 자체를 이해하기 위해 쿠버네티스 네트워킹 모델을 정리한다.
- 핵심 요구사항: 모든 파드가 NAT 없이 고유 IP로 직접 통신할 수 있어야 한다 (flat network)
- 같은 노드 파드 간 통신: veth pair로 네임스페이스 벽을 관통하고, bridge(cni0)가 L2 스위치 역할을 하여 하나의 네트워크로 묶는다
- 다른 노드 파드 간 통신: 물리 네트워크가 파드 IP를 모르는 것이 근본 문제. 해결 방식은 세 가지:
- 오버레이 (Flannel VXLAN 등): 파드 패킷을 노드 IP로 캡슐화하여 터널링
- BGP(Border Gateway Protocol, Calico BGP 모드): 라우팅 정보를 물리 네트워크에 직접 전파
- 클라우드 네이티브 라우팅 (AWS VPC CNI): 파드에게 VPC 실제 IP를 부여하여, 별도 라우팅 메커니즘 없이 도달 가능하게 함
- 세 방식 모두 파드 간 통신에서 src/dst IP가 한 번도 변하지 않는다. 방법만 다를 뿐 “NAT 없이 파드 IP로 직접 통신”이라는 결과는 동일하다.
들어가며
1주차에서 EKS 클러스터를 배포하고 내부 구조를 확인하면서, 이미 AWS VPC CNI의 흔적을 여러 번 만났다.
- EKS Owned ENI: 워커 노드마다 VPC CNI Secondary ENI가 생성되어 파드 IP 할당을 준비하고 있었다
- 엔드포인트 분석:
ss -tnp에서 aws-k8s-agent(VPC CNI 에이전트)가 API 서버와 연결을 유지하며 ENI 관리와 IP 할당 정보를 동기화하고 있었다
2주차의 주제는 이 AWS VPC CNI를 비롯한 EKS 네트워킹을 본격적으로 파헤치는 것이다. 그런데 EKS 네트워킹의 핵심인 AWS VPC CNI가 “무엇을 해결하는지”를 이해하려면, 먼저 쿠버네티스가 네트워킹에 대해 무엇을 요구하는지를 알아야 한다. VPC CNI든 Flannel이든 Calico든, 모든 CNI 플러그인은 쿠버네티스의 네트워킹 모델이 정한 요구사항을 구현하는 것이기 때문이다.
따라서 이 글에서는 쿠버네티스 네트워킹 모델의 요구사항이 무엇이고, 그것을 충족하기 위해 파드 간 통신을 어떻게 해결하는지 살펴본다. 그리고 그 해결 방식들 중 AWS VPC CNI가 어떤 위치에 있는지 확인한다.
쿠버네티스 네트워킹 모델
요구사항
쿠버네티스 공식 문서는 파드 네트워크(클러스터 네트워크)에 다음 두 가지를 요구한다:
- 모든 파드는 같은 노드든 다른 노드든, NAT 없이 다른 모든 파드와 직접 통신할 수 있어야 한다
- 노드의 에이전트(kubelet 등 시스템 데몬)는 동일한 노드의 모든 파드와 통신할 수 있어야 한다
All pods can communicate with all other pods, whether they are on the same node or on different nodes. Pods can communicate with each other directly, without the use of proxies or address translation (NAT).
핵심은 요구사항 1이다. 같은 노드뿐 아니라 다른 노드에 있는 파드까지 NAT 없이 도달 가능해야 한다. 이 글의 본론이 바로 이 요구사항을 어떻게 충족하는지다.
참고: AWS EKS Best Practices에서는 이를 세 가지로 나누어 기술한다 — 1. 같은 노드 파드 간 NAT 없이, 2. 시스템 데몬과 파드 간 통신, 3. host network를 사용하는 파드가 다른 노드의 파드와 NAT 없이 통신. 공식 문서의 요구사항 1이 같은/다른 노드를 모두 포함하므로, 본질적으로 같은 내용이다.
공식 문서는 이 요구사항과 함께 “every Pod in a cluster gets its own unique cluster-wide IP address”라는 원칙을 명시한다. 이를 통해 파드를 VM이나 물리 호스트처럼 포트 할당, 네이밍, 서비스 디스커버리, 로드 밸런싱 관점에서 동일하게 다룰 수 있다.
전제: 파드 안의 컨테이너는 localhost로 통신한다
네트워킹 모델의 요구사항을 다루기 전에, 하나의 전제가 있다. 같은 파드 안의 컨테이너끼리는 localhost로 통신할 수 있다는 것이다.
일반적인 Docker 컨테이너는 각자 자기만의 네트워크 네임스페이스를 갖는다. 컨테이너 하나 = 네트워크 네임스페이스 하나다. 그런데 쿠버네티스의 파드는 여러 컨테이너가 들어갈 수 있고, 이 컨테이너들이 하나의 네트워크 네임스페이스를 공유해야 한다. 같은 파드 안의 컨테이너끼리는 localhost로 통신할 수 있어야 하기 때문이다.
이걸 가능하게 하는 게 pause 컨테이너다. 파드가 생성되면 가장 먼저 pause 컨테이너가 뜨고, 이 pause가 네트워크 네임스페이스를 만든다. 이후에 뜨는 앱 컨테이너(nginx, sidecar 등)들은 자기만의 네트워크 네임스페이스를 만드는 대신 pause의 네트워크 네임스페이스에 합류한다. pause는 사실상 아무 일도 하지 않고(무한 sleep) 네트워크 네임스페이스를 유지하는 역할만 한다. 앱 컨테이너가 죽었다가 재시작되어도 pause가 살아 있으면 네트워크 네임스페이스(IP, 라우팅 테이블)가 유지된다.
그래서 “파드가 자신만의 네트워크 네임스페이스를 갖는다”는 말은 정확히는 “pause 컨테이너가 네트워크 네임스페이스를 소유하고, 파드 안의 모든 컨테이너가 그것을 공유한다“는 뜻이다.
이것은 쿠버네티스 공식 문서의 파드 모델에서 “Containers within a Pod share network namespace including the IP address and network ports”로 명시되어 있다. CNI가 구현해야 할 네트워킹 요구사항이라기보다는, 파드 정의 자체에 내포된 전제다.
핵심: NAT 없이
세 요구사항을 관통하는 키워드는 “NAT 없이”다. 이 말의 무게를 이해하려면 NAT의 본질부터 짚어야 한다.
NAT이란
NAT(Network Address Translation)은 패킷이 네트워크 경계를 넘을 때, 패킷의 IP 헤더를 열어서 출발지/목적지 IP를 다른 값으로 변경하는 L3 계층의 주소 변조 기술이다. (NAT 개념 참고)
-
SNAT (Source NAT): 출발지 IP를 변경한다. 가장 대표적인 용도는 사설 네트워크에서 외부로 나가는 것이다. 사설 IP 대역(10.x, 172.16.x, 192.168.x)은 인터넷에서 라우팅되지 않는다. SNAT 없이 사설 IP가 출발지인 패킷이 밖으로 나가면, 응답 패킷의 목적지가 사설 IP가 되어 인터넷 상에서 돌아올 경로가 없다. 엄밀히 말하면 “나갈 수는 있지만 응답이 올 수 없으니” 실질적으로 통신이 불가능하다. 집에서 공유기를 쓸 때 내 PC의 사설 IP(192.168.0.10)가 공유기를 나가면서 공인 IP로 바뀌는 것이 SNAT의 전형적인 예시다.
[원본 패킷] src=10.244.0.5 dst=10.244.0.6 ↓ SNAT 적용 [변조 패킷] src=192.168.1.10 dst=10.244.0.6 ← 출발지 IP가 바뀜 -
DNAT (Destination NAT): 목적지 IP를 변경한다. 외부에서 내부로 들어올 때 사용한다. 외부 클라이언트가 공인 IP:포트로 요청하면, 그 목적지를 내부 사설 IP:포트로 바꿔 내부 장비에 전달한다.
[원본 패킷] src=203.0.113.50 dst=192.168.1.10:8080 ↓ DNAT 적용 [변조 패킷] src=203.0.113.50 dst=172.17.0.2:80 ← 목적지 IP:포트가 바뀜
참고: SNAT의 가장 대표적인 용도는 “사설 → 공인” 방향의 통신을 가능하게 하는 것이지만, SNAT 자체는 “출발지 IP를 변경하는 것”이므로 공인→공인, 사설→사설 변환에도 사용될 수 있다. DNAT도 마찬가지다.
“NAT 없이”의 의미
이것이 왜 중요한 대원칙인지, 왜 어려운 일인지 생각해 보자.
집 공유기를 떠올려 보면, 같은 공유기에 연결된 내 PC와 엄마 PC는 NAT 없이 통신한다. 공유기 내부 스위치가 L2로 처리하기 때문이다. 하지만 내 PC가 공유기 밖 — 인터넷 너머의 외부 서버 — 과 통신하려면 NAT이 필요하다. 공유기 경계를 넘는 순간, 사설 IP로는 도달할 수 없기 때문이다.
쿠버네티스 네트워킹 모델이 요구하는 것은, 수백~수천 개의 파드가 여러 노드에 흩어져 있는데도, 마치 거대한 하나의 공유기 안에 있는 것처럼 동작해야 한다는 것이다. 노드 경계를 넘어서도 NAT 없이. 일종의 flat network 요구다.
참고: flat network — 모든 노드가 같은 L2/L3 도메인에 있어서, 별도의 NAT이나 터널링 없이 서로 직접 통신 가능한 네트워크. 쿠버네티스 네트워킹 모델이 요구하는 것과 정확히 부합한다.
다만 “NAT 없이”라는 대원칙은 파드 ↔ 파드 직접 통신 경로(인프라 계층)에 한정된다. 구체적으로, 파드 A가 파드 B에게 패킷을 보낼 때 그 경로의 어느 지점에서도 IP가 변조되면 안 된다는 것이다. SNAT이든 DNAT이든 하나라도 있으면 “NAT 없이”를 충족하지 못한다.
파드 A(10.244.1.2) → 파드 B(10.244.1.3)로 HTTP 요청
[요청]
파드 A가 보낸 패킷: src=10.244.1.2 dst=10.244.1.3
파드 B가 받은 패킷: src=10.244.1.2 dst=10.244.1.3 ← 동일해야 함
[응답]
파드 B가 보낸 응답: src=10.244.1.3 dst=10.244.1.2
파드 A가 받은 응답: src=10.244.1.3 dst=10.244.1.2 ← 동일해야 함
요청과 응답 양방향 모두에서 src/dst IP가 한 번도 변하지 않아야 한다는 것이다. 즉:
- 파드 B 입장에서 “이 요청은 10.244.1.2에서 왔다”고 정확히 인식할 수 있어야 한다
- 파드 A 입장에서 “이 응답은 10.244.1.3에서 왔다”고 정확히 인식할 수 있어야 한다
모든 파드가 마치 하나의 거대한 스위치에 연결된 것처럼, 자기 IP로 직접 식별되고 직접 통신할 수 있어야 한다.
같은 노드의 파드 간 통신
네트워킹 모델의 첫 번째 요구사항 — “동일한 노드의 파드가 NAT 없이 통신할 수 있어야 한다” — 이 왜 어렵고, 어떻게 해결되는지 살펴본다.
문제: 네트워크 네임스페이스 격리
각 파드는 자신만의 네트워크 네임스페이스를 가진다. 독립된 네트워크 스택(네트워크 인터페이스, IP 주소, 라우팅 테이블, iptables 규칙, 소켓)을 갖는다는 뜻이다. 물리적으로 분리된 두 대의 컴퓨터와 같다고 생각하면 된다. 실제로는 같은 호스트의 커널 위에서 돌아가지만, 서로의 네트워크를 볼 수 없다. 네트워크 네임스페이스가 격리를 목적으로 만들어진 것이니 당연하다.

참고: 네트워크 스택이라고 하면 엄밀히는 자체 네트워크 인터페이스, 자체 IP, 자체 라우팅 테이블, 자체 iptables 규칙, 자체 소켓까지를 포함한다. 여기서는 독립된 네트워크 환경 자체를 간단히 표현하기 위해 eth0 + IP + 라우팅 테이블로만 그렸다.
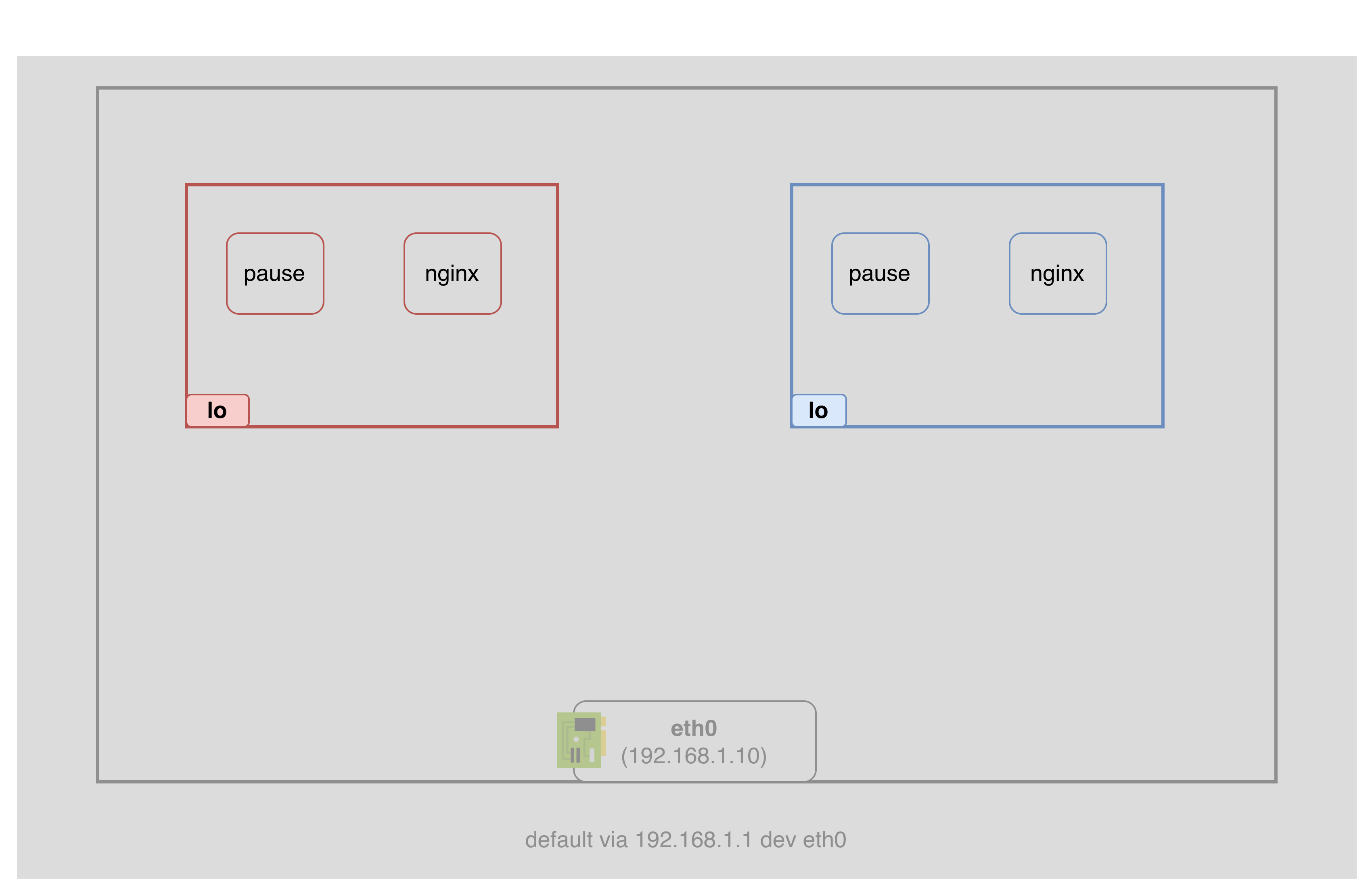
참고: 파드의 네트워크 네임스페이스는 pause 컨테이너가 소유한다. pause가 먼저 뜨면서 네임스페이스를 만들고, 이후 앱 컨테이너가 그 네임스페이스에 합류한다.
해결: veth pair + 브릿지
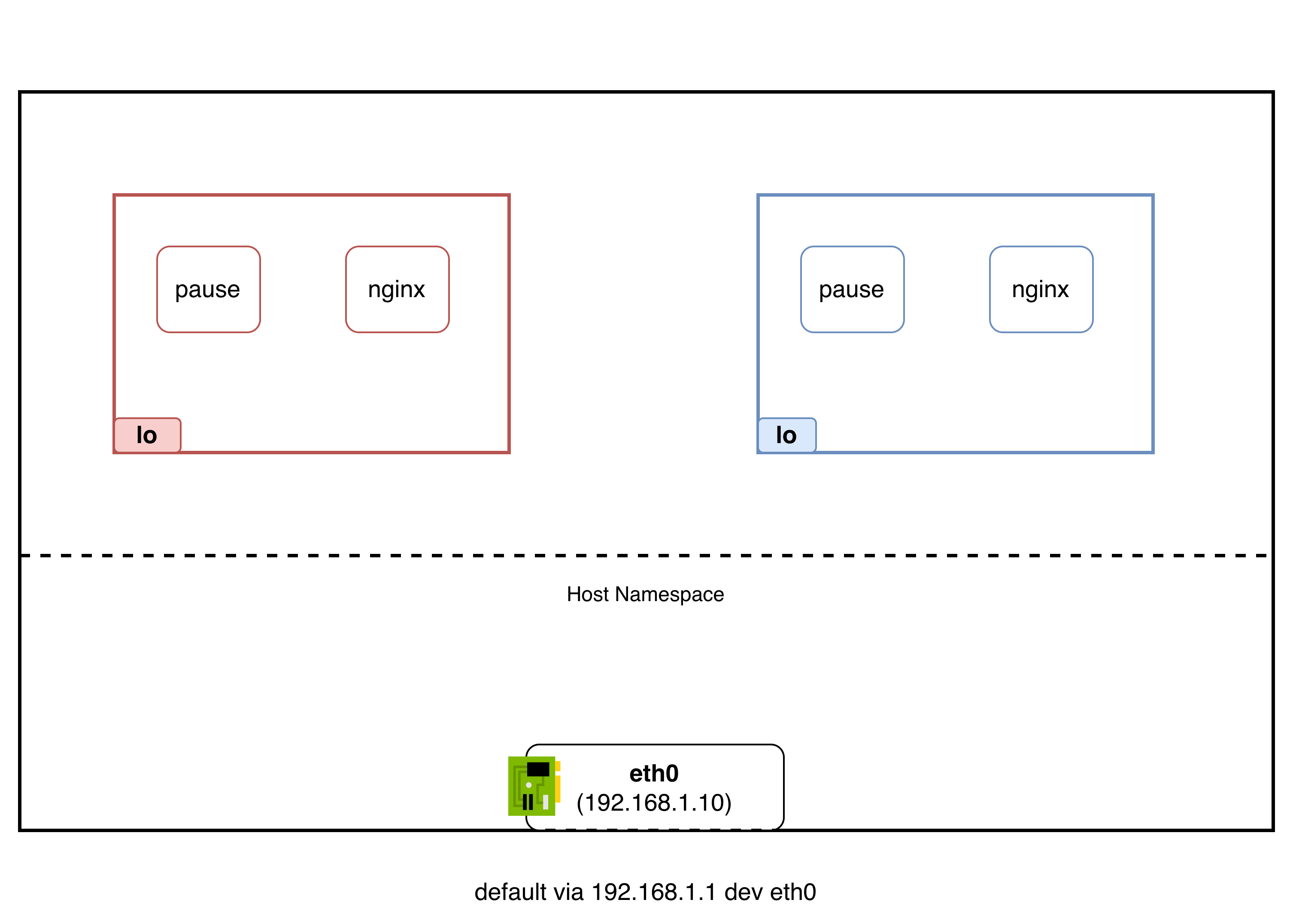
veth pair로 네임스페이스 벽을 관통한다
veth pair는 커널이 만드는 가상 이더넷 케이블이다. 양쪽 끝이 항상 연결되어 있어서, 한쪽에 패킷을 넣으면 반대쪽에서 나온다. 물리적으로 두 NIC를 케이블로 직접 연결한 것과 동일한 효과를 커널 내부에서 소프트웨어로 구현한 것이다.
파드의 eth0이 veth pair의 한쪽 끝이고, 호스트의 veth-xxx가 반대쪽 끝이다. 이 둘은 생성 시점부터 쌍으로 묶여 있다. 파드 안에서 eth0으로 패킷을 보내면, 커널이 그 패킷을 veth pair의 반대쪽 끝(호스트의 veth-xxx)으로 즉시 전달한다. 네임스페이스 경계를 넘는 것처럼 보이지만, 실제로는 커널이 한쪽 인터페이스의 송신 큐 데이터를 반대쪽 인터페이스의 수신 큐로 복사하는 것이다.
veth pair 자체가 네임스페이스 벽을 관통하는 양방향 파이프인 것이다. 파드 입장에서는 그냥 eth0으로 패킷을 보낸 것이고, 호스트 입장에서는 veth-xxx에서 패킷이 나타난 것이다.
여기까지는 일반적인 컨테이너 네트워크 네임스페이스 격리와 같은 원리다. 파드에서 호스트까지는 도달할 수 있지만, 두 파드 간의 직접 통신은 여전히 미지수다. Pod Red의 패킷이 Pod Blue에 도달하려면 어떻게 해야 할까?
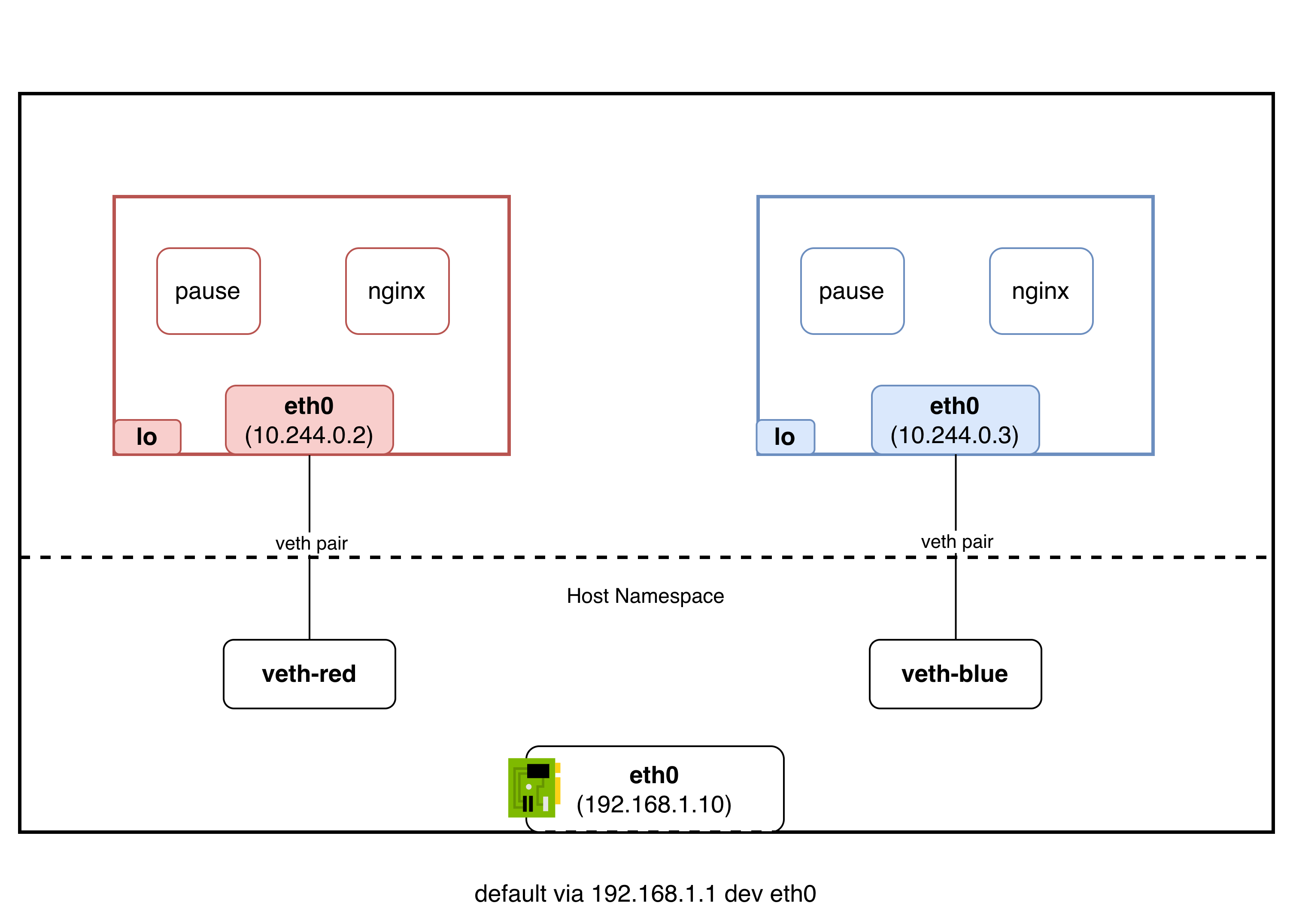
브릿지(cni0)로 하나의 네트워크로 묶는다
이 문제를 브릿지 인터페이스로 해결한다. CNI 플러그인이 만드는 가상 브릿지(Flannel의 경우 cni0)가 L2 스위치 역할을 하며, 같은 노드의 veth들을 하나의 네트워크 세그먼트로 묶는다. Docker의 docker0 브릿지도 같은 원리다.
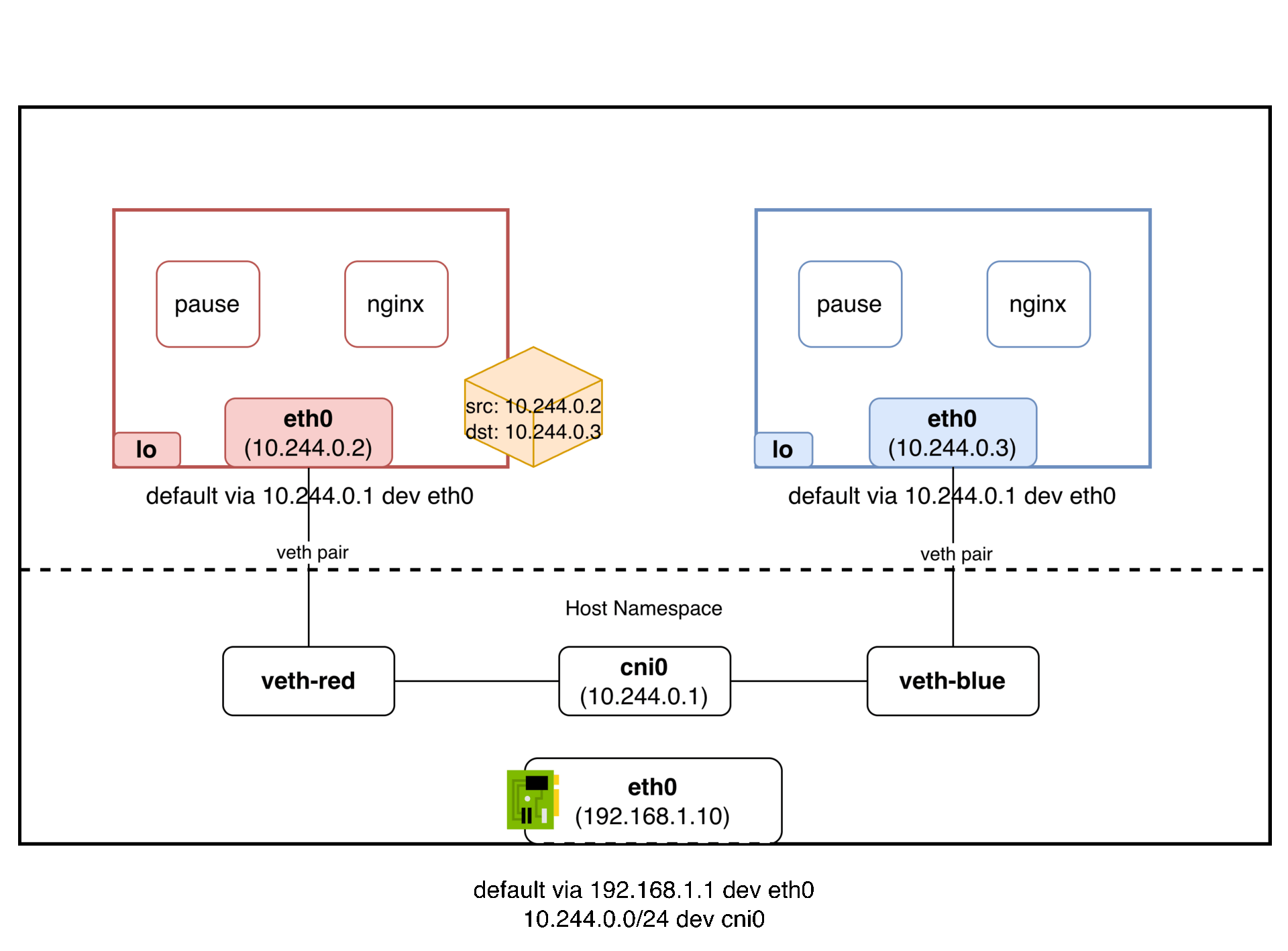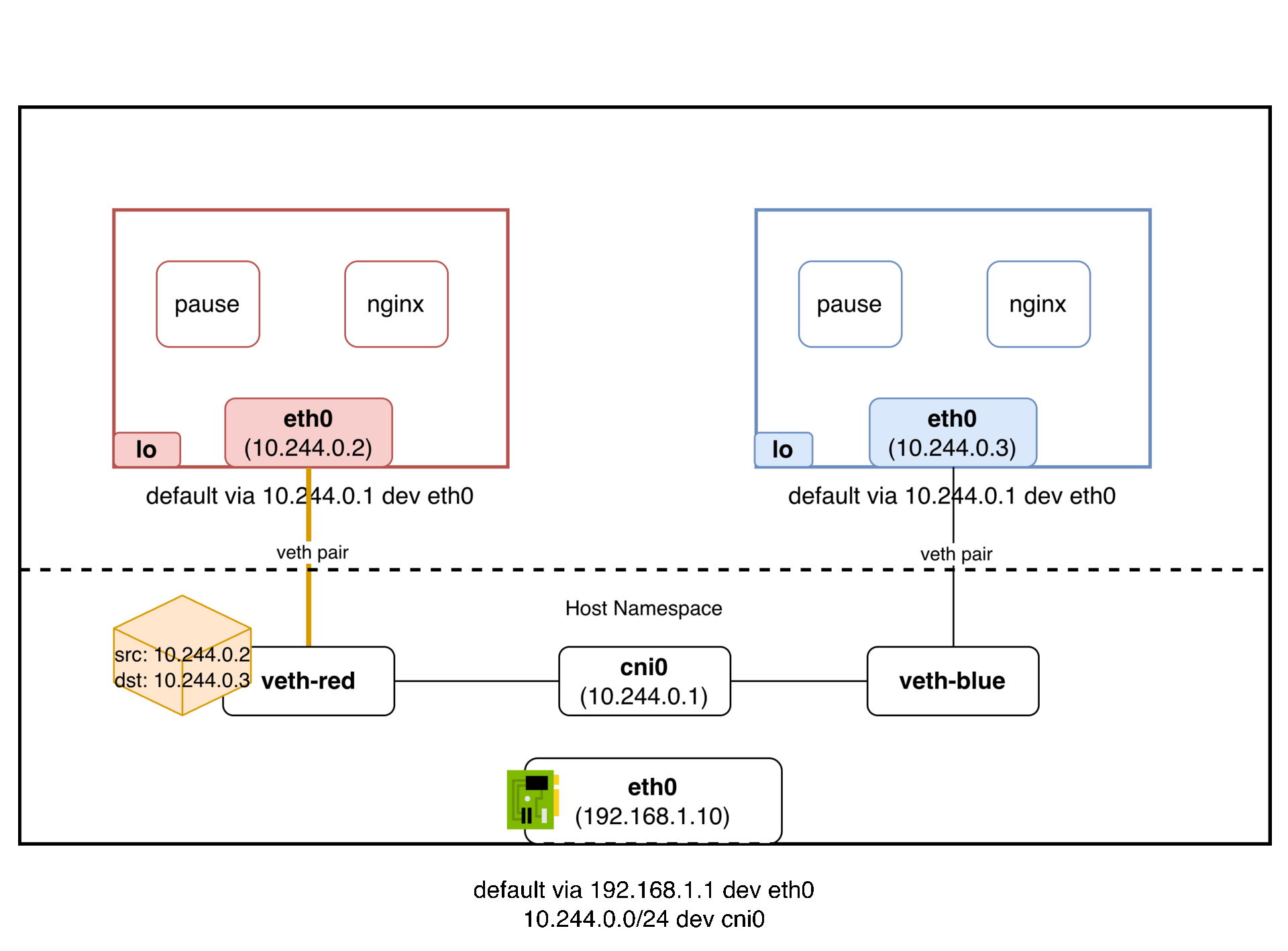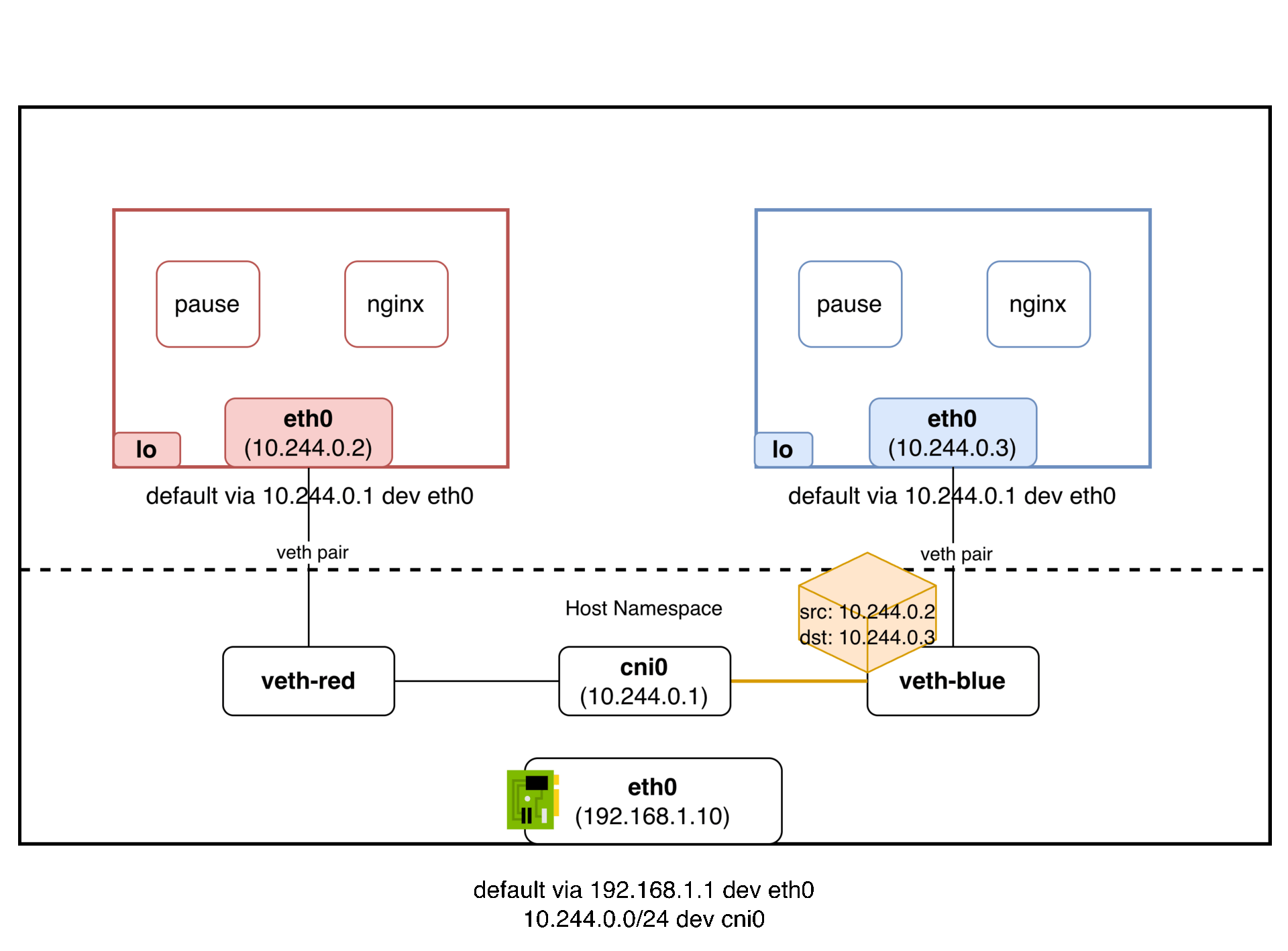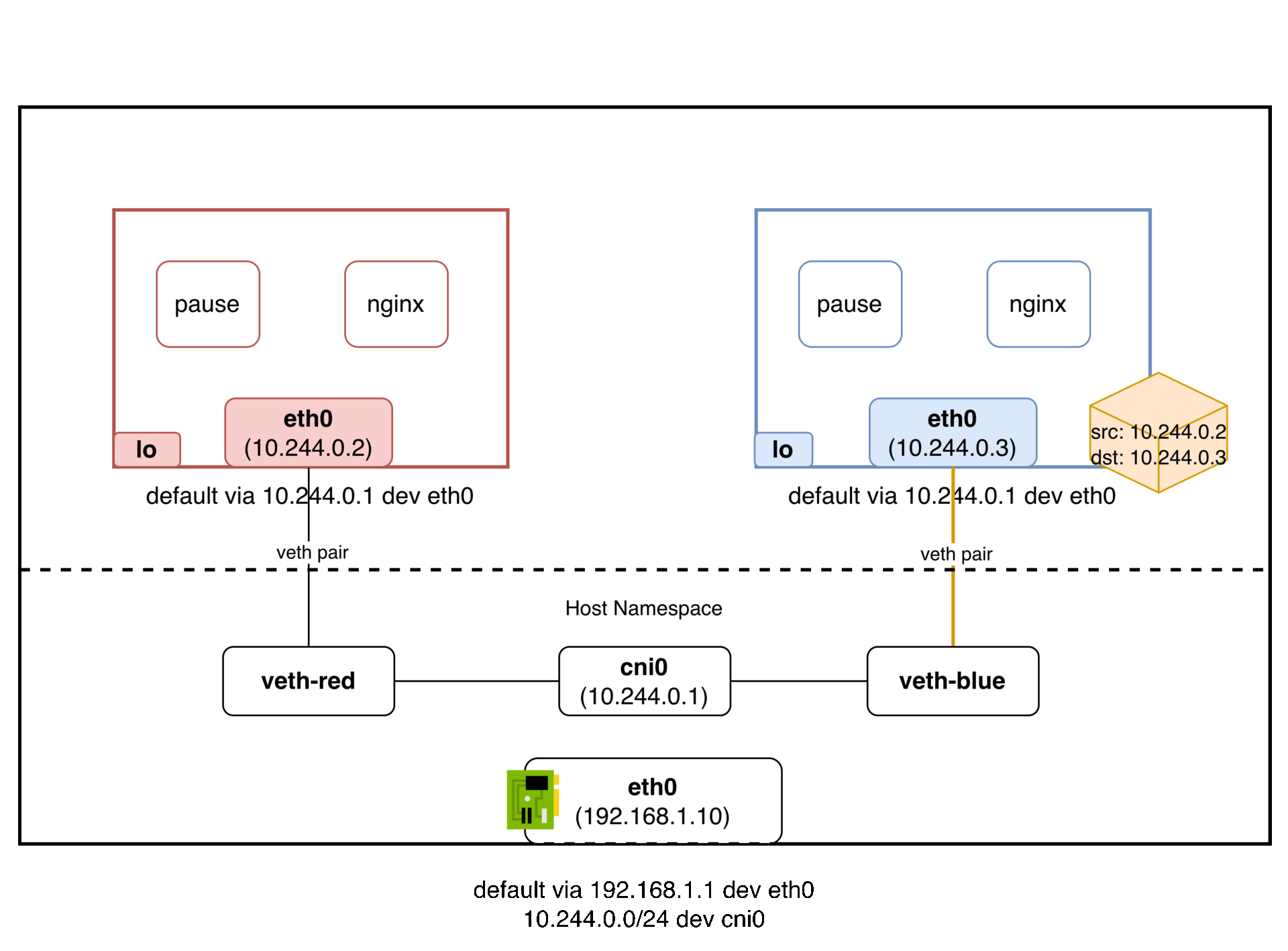
패킷의 흐름은 다음과 같다:
파드 A(10.244.1.2) → veth → cni0 브릿지 → veth → 파드 B(10.244.1.3)
cni0 브릿지가 같은 L2 세그먼트를 만들어주기 때문에, 파드 A가 보낸 패킷의 출발지 IP(10.244.1.2)가 그대로 파드 B에 도착한다. IP를 바꿀 필요가 없다. NAT이 없다는 것이다. 마치 같은 스위치에 물린 두 대의 컴퓨터처럼 동작한다.
브릿지의 MAC 학습도 물리 스위치와 동일한 메커니즘이다:
- 파드가 생기면 CNI 플러그인이 veth pair를 만들고, 호스트 쪽 veth를 cni0 브릿지에 포트로 연결한다 (
ip link set veth-xxx master cni0) - 해당 veth를 통해 프레임이 오면, cni0이 출발지 MAC을 보고 “이 MAC은 이 포트(veth)에 있다”고 MAC 주소 테이블에 기록한다
- 다른 파드가 해당 MAC으로 프레임을 보내면, cni0이 테이블을 참조해서 올바른 veth 포트로 전달한다
정리하면, veth pair로 각 파드의 네임스페이스를 호스트 네임스페이스에 연결하고, 브릿지(cni0)로 같은 노드의 veth들을 하나의 L2 세그먼트로 묶어서 같은 노드 파드 간 통신 문제를 해결한다.
다른 노드의 파드 간 통신
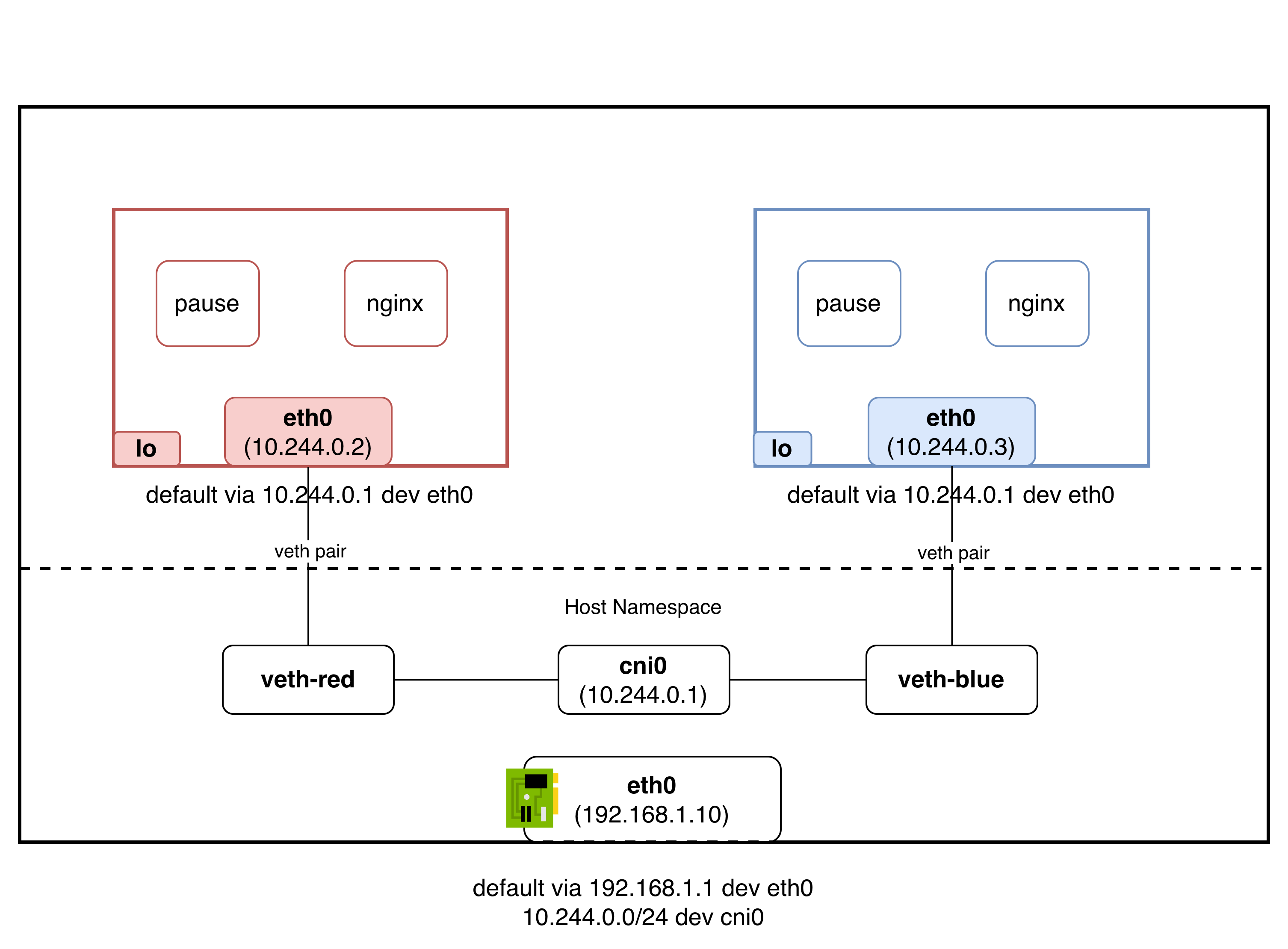
같은 노드 안에서는 브릿지로 해결됐다. 하지만 요구사항 1은 “같은 노드든 다른 노드든”이라고 말한다. 노드 A의 파드 a(10.244.0.5)가 노드 B의 파드 b(10.244.1.3)에게도 NAT 없이 패킷을 보낼 수 있어야 한다. 여기가 진짜 어려운 부분이다.
과제: 파드 IP가 다른 노드에서도 도달 가능해야 한다
같은 노드 안에서는 브릿지가 L2 세그먼트를 만들어줬지만, 노드 밖으로 나가면 그런 보장이 없다. 노드 A의 파드 IP가 노드 B에서 도달 가능하려면, 그 사이의 물리 네트워크(또는 클라우드 네트워크)가 파드 IP를 라우팅할 수 있어야 한다. 그리고 쿠버네티스 네트워킹 모델은 이 과정에서 NAT을 사용하지 말라고 요구한다.
이 과제를 어떻게 풀 것인지는, 파드에 어떤 IP를 부여하느냐에 따라 문제의 성격 자체가 달라진다:
- 별도의 파드 전용 대역(예:
10.244.x.x)을 사용하면, 물리 네트워크가 이 대역을 모른다.10.244.1.3이라는 IP는 노드 B 내부에서만 의미가 있고, 물리 네트워크 라우터는 이 대역에 대한 경로 정보를 갖고 있지 않다. 이 경우 “물리 네트워크가 파드 IP를 모른다”는 문제를 해결해야 한다. - 인프라의 실제 IP(예: VPC 대역)를 파드에 직접 부여하면, 물리 네트워크가 이미 그 IP를 라우팅할 수 있으므로 이 문제가 애초에 발생하지 않는다.
비유하면 이렇다. 서울 아파트(노드 A)에서 부산 아파트(노드 B)로 택배를 보내는 상황이다. 아파트마다 자체적인 동호수 체계(별도 파드 대역)를 쓰면, 택배 시스템은 “부산 아파트”까지만 알고 “305동 402호”가 어디인지는 모른다. 반면 전국 공통 주소 체계(인프라 IP)를 쓰면 택배 시스템이 처음부터 해당 주소를 안다. 어느 쪽이든 쿠버네티스가 요구하는 것은 동일하다 — 305동 402호까지 어떻게든 찾아가되, 송장을 바꿔 붙이지 마라.
NAT을 허용했다면: Docker bridge 모드
이 문제를 이해하기 위해, 먼저 NAT을 허용했을 때 어떤 방식이 가능한지 살펴보자. 이것이 Docker의 기본 bridge 모드 동작이다.
호스트 IP: 192.168.1.10
컨테이너 A: nginx (172.17.0.2:80) → -p 8080:80 → 192.168.1.10:8080
컨테이너 B: nginx (172.17.0.3:80) → -p 8081:80 → 192.168.1.10:8081
컨테이너 C: nginx (172.17.0.4:80) → -p 8082:80 → 192.168.1.10:8082
Docker bridge 모드에서는 컨테이너마다 별도 네트워크 네임스페이스를 가지고, veth pair로 docker0 브릿지에 연결되며, 고유한 사설 IP(172.17.0.x)를 할당받는다. 여기까지는 쿠버네티스의 같은 노드 파드 간 통신과 동일한 원리다.
차이는 외부와의 통신에서 나타난다. Docker 데몬이 iptables에 NAT 규칙을 자동으로 추가한다:
# DNAT: 외부 → 컨테이너 (포트 매핑)
-A DOCKER -p tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80
# SNAT(MASQUERADE): 컨테이너 → 외부
# 172.17.0.0/16 대역에서 출발한 패킷이 docker0가 아닌 다른 인터페이스(즉, 외부)로 나갈 때
# 출발지 IP를 호스트 IP로 바꿔라
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
- 외부 → 컨테이너 A:
192.168.1.10:8080으로 보내면, 패킷이 호스트의 외부 인터페이스로 들어오고 iptables PREROUTING 체인에서 DNAT이 적용되어 목적지가172.17.0.2:80으로 변환된다. 커널이 변환 후docker0브릿지를 통해 컨테이너로 전달한다. 브릿지는 그냥 전달만 할 뿐, 이미 그 전에 IP 주소가 바뀌어 있다. - 컨테이너 A → 외부: 컨테이너에서 veth를 통해
docker0브릿지로 나오고, 호스트 네트워크 스택을 타면서 iptables POSTROUTING 체인의 MASQUERADE 규칙이 출발지를172.17.0.2에서 호스트 IP192.168.1.10으로 바꾼다.
이 방식의 문제는 명확하다:
- IP 불일치: 컨테이너 A 입장에서 자기 IP는
172.17.0.2인데, 외부에서 보는 주소는192.168.1.10:8080이다. 컨테이너가 자기 IP를 다른 서비스에 알려줄 때172.17.0.2를 알려주면 외부에서 도달할 수 없다. - 포트 충돌: 두 컨테이너가 같은 호스트 포트(예: 8080)를 쓸 수 없다. 컨테이너가 100개면 포트 100개를 수동으로 매핑해야 한다.
쿠버네티스 네트워킹 모델은 이것을 거부한다. 파드가 고유 IP를 갖고, 그 IP로 NAT 없이 직접 통신할 수 있어야 한다. 패킷 관점에서 Docker bridge 모드와 비교하면 차이가 명확하다:
[Docker bridge 모드]
외부 → 컨테이너 A: src=203.0.113.50 dst=192.168.1.10:8080
↓ DNAT
src=203.0.113.50 dst=172.17.0.2:80 ← dst가 바뀜
컨테이너 A → 외부: src=172.17.0.2 dst=203.0.113.50
↓ SNAT (MASQUERADE)
src=192.168.1.10 dst=203.0.113.50 ← src가 바뀜
[쿠버네티스]
파드 A → 파드 B: src=10.244.1.2 dst=10.244.1.3
↓ (경로 전체)
src=10.244.1.2 dst=10.244.1.3 ← 아무것도 안 바뀜
쿠버네티스에서는 파드마다 고유 IP를 가지므로 같은 포트도 충돌 없이 사용할 수 있고, 경로 전체에서 src/dst IP가 한 번도 변하지 않는다.
참고: Docker와 쿠버네티스의 네트워킹 모델이 다른 이유
Docker는 단일 호스트에서 컨테이너를 실행하는 도구로 시작했다. 단일 호스트에서 컨테이너를 격리하면서 외부 접근을 허용하려면 NAT 포트 매핑이 가장 간단하다. 물리 네트워크 인프라를 건드릴 필요 없이 iptables 규칙만 추가하면 된다.
반면 쿠버네티스는 처음부터 멀티 노드 클러스터를 전제로 설계했고, 수백~수천 개 파드가 서로 직접 통신해야 하니 포트 매핑 방식이 성립하지 않았다. 풀어야 하는 문제 자체가 다르니 네트워킹 모델도 근본적으로 달라진 것이다.
Docker도 네트워크 모드를 여러 가지 제공한다:
- bridge (기본): 컨테이너마다 별도 네트워크 네임스페이스 + veth pair + docker0 브릿지 연결. 고유 사설 IP를 가지지만, 외부 접근은
-p로 포트 매핑(NAT)- host (
--network=host): 컨테이너가 호스트의 네트워크 네임스페이스를 그대로 공유한다. 별도 IP 없이 호스트 IP를 직접 사용한다. NAT이 없지만 격리도 없다. 컨테이너 두 개가 같은 포트(80)를 쓰면 충돌- none: 네트워크 인터페이스가 루프백(lo)만 있다. 외부 통신 불가
해결 방식
이 과제를 직접 풀어야 한다고 생각해 보자. NAT을 쓰면 간단하지만, 네트워킹 모델이 금지한다. 그렇다면 NAT 없이 파드 IP를 노드 밖에서도 도달 가능하게 만들어야 한다. 앞서 봤듯이 파드에 어떤 IP를 부여하느냐에 따라 접근이 달라진다:
-
방법 1 — 물리 네트워크를 우회한다 (오버레이): 물리 네트워크가 파드 IP를 모른다면, 물리 네트워크한테 알려주는 대신 우회하면 된다. 각 노드에 파드 대역을 할당하고(노드 A는
10.244.0.0/24, 노드 B는10.244.1.0/24), 파드 패킷을 노드 IP로 한 번 감싸서 보낸다. 물리 네트워크는 파드 대역을 여전히 모르지만, 노드 간 IP 통신만 되면 패킷이 전달된다. -
방법 2 — 물리 네트워크한테 파드 IP 대역을 알려준다 (BGP): 우회 대신 정면 돌파도 가능하다. 물리 네트워크 라우터에게 “10.244.1.0/24는 노드 B로 보내라”는 경로 정보를 BGP 프로토콜로 직접 광고한다. 라우터가 이 정보를 반영하면, 캡슐화 없이 파드 IP가 물리 네트워크를 날것 그대로 돌아다닐 수 있다.
-
방법 3 — 인프라 자체가 알게 만들어 버린다 (클라우드 네이티브 라우팅): 여기가 발상이 다르다. 별도의 파드 전용 대역을 만드는 게 아니라, 파드나 노드나 같은 IP 대역을 사용하게 만들어 버린다. 파드 IP가 인프라 IP와 같은 대역이니, 인프라의 라우팅 테이블이 이미 해당 IP를 라우팅할 수 있다. 별도의 오버레이나 BGP 광고가 애초에 필요 없다. 인프라 네트워크는 원래 하던 대로 자기 대역의 IP를 라우팅하는 것이고, 파드가 그 대역의 IP를 받은 것뿐이다. 이번 주차에 집중적으로 살펴볼 AWS VPC CNI가 바로 이 방식이다.
정리하면 다음과 같다:
| 방식 | 핵심 발상 | 파드 IP 대역 | 복잡도 | 단점 |
|---|---|---|---|---|
| 오버레이 (VXLAN, IPIP) | 물리 네트워크를 우회 — 노드 IP로 감싸서 터널링 | 별도 대역 (10.244.x.x) | 중간 | 캡슐화/디캡슐화 오버헤드, 디버깅 어려움 |
| BGP 라우팅 전파 (Calico 방식) | 물리 네트워크에 알려줌 — 라우팅 정보를 BGP로 전파 | 별도 대역 (10.244.x.x) | 높음 | 모든 노드가 BGP 피어링 필요, 라우터 설정 필요 |
| 클라우드 네이티브 라우팅 (AWS VPC CNI 등) | 인프라가 원래부터 앎 — 같은 대역 IP를 부여 | 인프라와 같은 대역 | 클라우드가 다 해줌 | 클라우드 환경에 종속, 인스턴스 타입별 IP 제한 |
참고: ARP/GARP 방식: 같은 L2 서브넷 내에서 ARP/GARP로 “이 IP 여기 있어요”라고 브로드캐스트하는 원시적인 방법도 이론적으로 가능하다(NIC에 IP를 여러 개 붙이는 가장 단순한 형태). 하지만 같은 서브넷 안에서만 동작하고 스케일이 안 되므로, 실제 프로덕션 쿠버네티스 환경에서는 거의 사용되지 않는다. 개념 이해 차원에서만 참고하자.
오버레이: 별도 대역 + 터널링
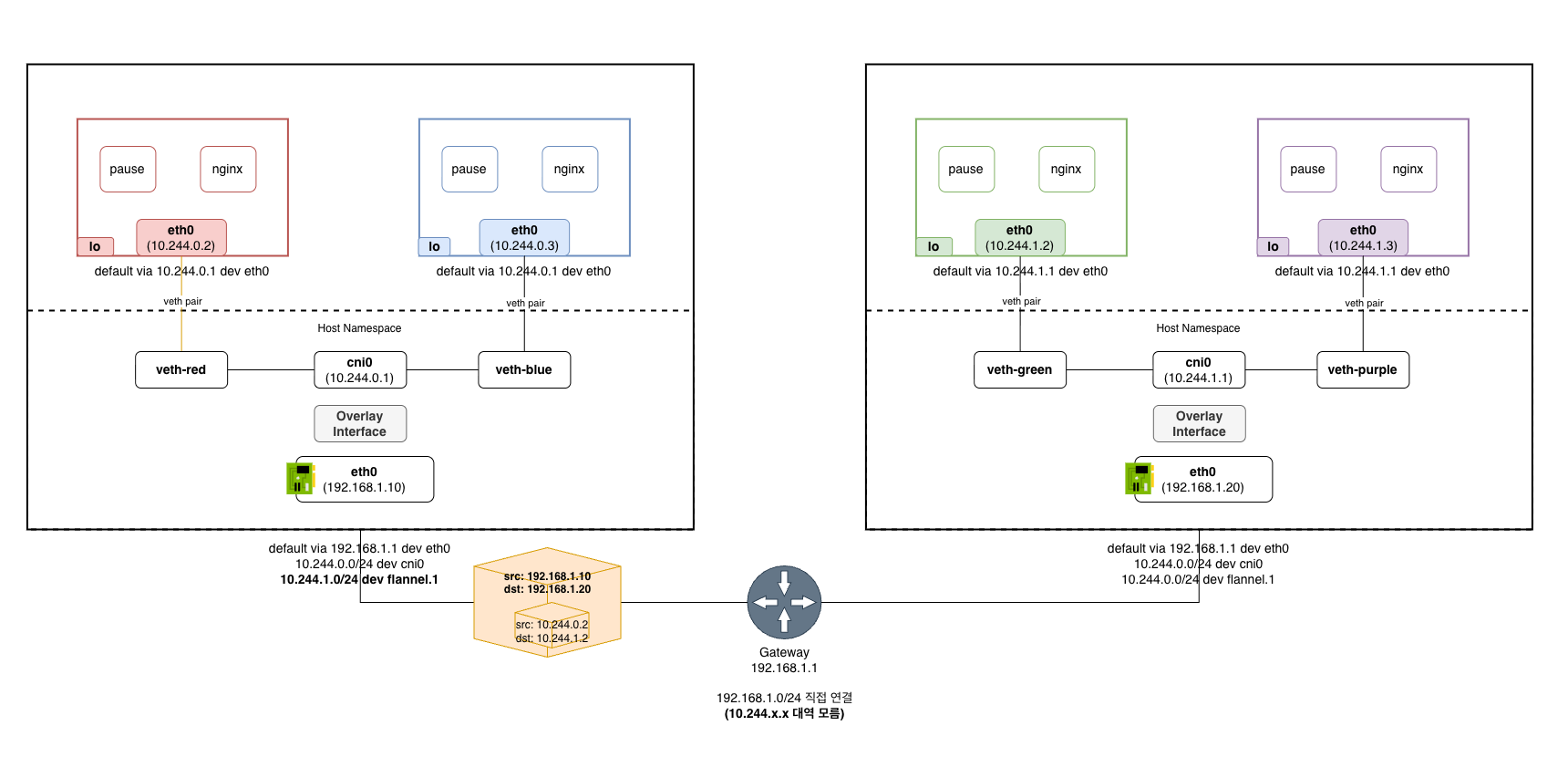
Flannel(VXLAN), Calico(IPIP) 등이 사용하는 방식이다. 각 노드에 파드 대역을 할당하고(노드 A는 10.244.0.0/24, 노드 B는 10.244.1.0/24), 각 파드마다 별도의 가상 인터페이스(veth)를 만들어 별도 대역의 IP를 할당한다. 물리 네트워크가 모르는 이 파드 IP 대역을 노드 IP로 한 번 감싸서(캡슐화) 전달한다.
노드의 라우팅 테이블에 오버레이 인터페이스를 통한 경로가 설정된다:
# flannel(VXLAN) 설치한 노드 A의 라우팅 테이블
10.244.0.0/24 → cni0 (로컬 파드, 브릿지로 직접 전달)
10.244.1.0/24 → flannel.1 (노드 B의 파드, VXLAN 터널로 전달)
로컬 파드는 cni0 브릿지로 직접 전달하고(같은 노드 파드 간 통신과 동일), 다른 노드의 파드 대역은 오버레이 인터페이스(flannel.1, tunl0 등)로 보낸다. 이 오버레이 인터페이스가 원본 패킷을 노드 IP로 캡슐화한다:
[오버레이 패킷 구조]
┌─────────────────────────────────┐
│ Outer: src=192.168.1.10 (노드) │ ← 물리 네트워크가 아는 IP
│ dst=192.168.1.20 (노드) │
│ ┌─────────────────────────────┐ │
│ │ Inner: src=10.244.1.5 (파드) │ │ ← 물리 네트워크가 모르는 IP
│ │ dst=10.244.2.3 (파드) │ │
│ └─────────────────────────────┘ │
└─────────────────────────────────┘
물리 네트워크 입장에서는 그저 노드 간 통신으로만 보인다. 목적지 노드에서 디캡슐화하면 원래 파드 IP가 나온다.
파드 IP가 변하지 않는지 경로를 검증해 보자. 파드 X(10.244.0.5, 노드 A)가 파드 Y(10.244.1.3, 노드 B)에게 패킷을 보내는 경우다:
- 파드 X가 패킷 생성:
src=10.244.0.5,dst=10.244.1.3 - veth를 통해 호스트로 나옴: 노드 A의 라우팅 테이블에서
10.244.1.0/24 → flannel.1경로를 타고 오버레이 인터페이스로 전달 - VXLAN 캡슐화:
flannel.1이 원본 패킷을 건드리지 않고 바깥에 노드 IP 헤더를 씌움- Outer IP:
src=192.168.1.10(노드 A),dst=192.168.1.20(노드 B)— 물리 네트워크가 아는 IP - Inner IP:
src=10.244.0.5(파드 X),dst=10.244.1.3(파드 Y)— 그대로
- Outer IP:
- 물리 네트워크 전달: 라우터는 Outer IP만 보고 노드 B로 전달
- 노드 B에서 디캡슐화:
flannel.1이 Outer 헤더를 벗기면 원본 파드 패킷이 나옴.src=10.244.0.5,dst=10.244.1.3— 그대로 - 파드 Y가 수신: 노드 B의 라우팅 테이블
10.244.1.0/24 → cni0 → veth를 거쳐 파드 Y에 도착.src=10.244.0.5,dst=10.244.1.3— 변하지 않음
Outer IP 헤더가 추가/제거될 뿐, Inner IP(파드 IP)는 출발부터 도착까지 한 번도 변하지 않는다. 캡슐화는 NAT이 아니다. NAT은 IP를 변조하는 것이고, 캡슐화는 IP를 건드리지 않고 바깥에 새 헤더를 씌우는 것이다.
참고: 오버레이 네트워크(VXLAN 캡슐화, VTEP 등)의 더 상세한 구조는 CNI 글에서 확인할 수 있다.
BGP: 별도 대역 + 라우팅 정보 전파
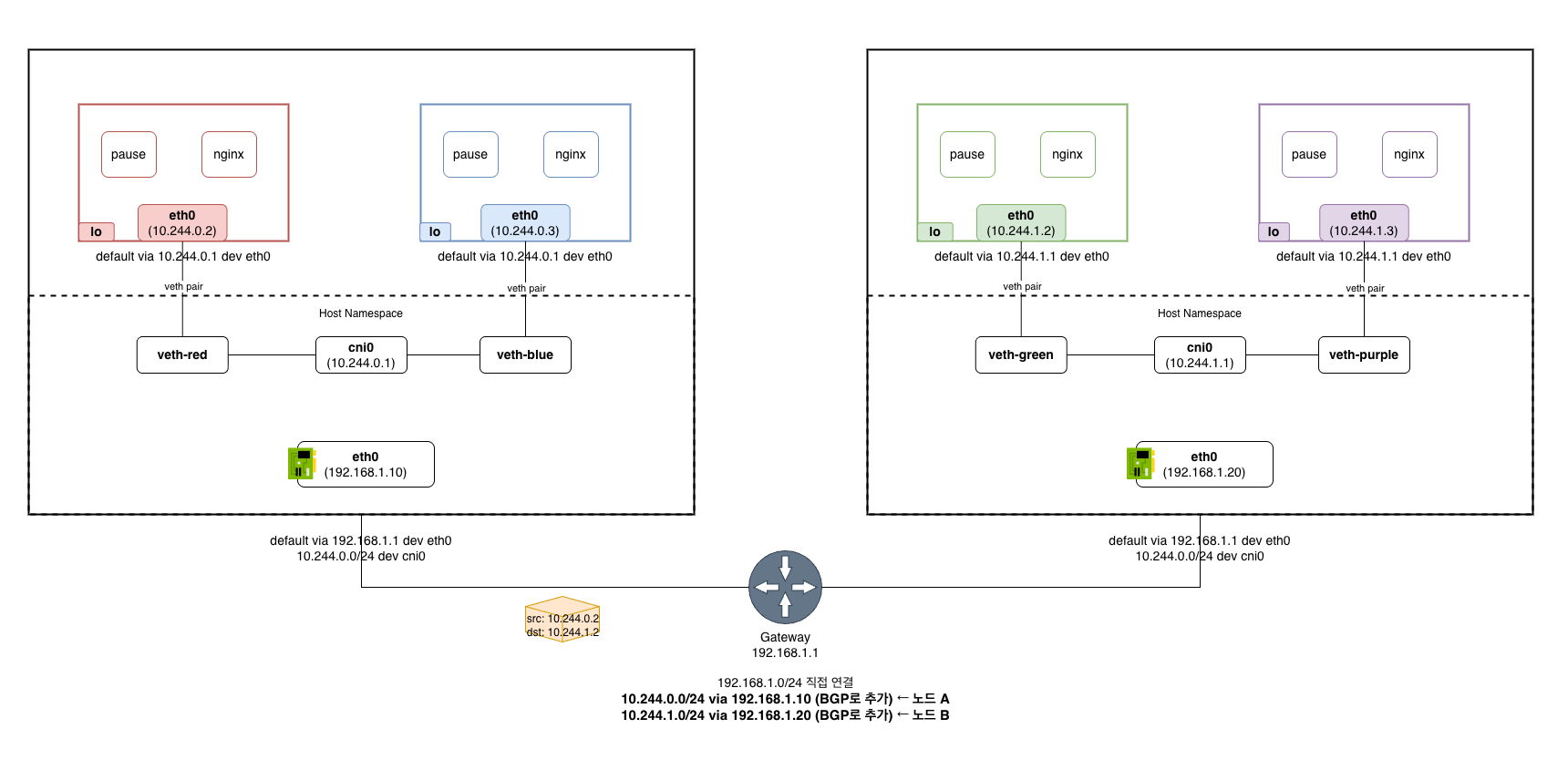
Calico BGP 모드가 사용하는 방식이다. 각 노드에 파드 대역을 할당하는 것은 오버레이와 동일하지만, 캡슐화 대신 물리 네트워크 라우터에게 경로 정보를 직접 광고한다는 것이 차이다.
Calico 에이전트(bird)가 “10.244.1.0/24는 노드 B(192.168.1.20)로 보내라”는 경로 정보를 BGP 프로토콜로 다른 노드와 물리 라우터에게 전파한다. 물리 라우터가 이 정보를 받아 자신의 라우팅 테이블에 반영하면, 파드 IP 대역의 패킷을 올바른 노드로 직접 전달할 수 있게 된다.
캡슐화 오버헤드가 없지만, 네트워크 인프라가 BGP를 지원해야 한다.
파드 IP가 변하지 않는지 경로를 검증해 보자. 파드 X(10.244.0.5, 노드 A)가 파드 Y(10.244.1.3, 노드 B)에게 패킷을 보내는 경우다. 캡슐화도 없다. 파드 IP가 물리 네트워크 위를 날것 그대로 돌아다닌다. 물리 라우터가 BGP로 파드 대역의 경로를 알고 있으니 가능한 것이다.
- 파드 X가 패킷 생성:
src=10.244.0.5,dst=10.244.1.3 - veth를 통해 호스트로 나옴: 노드 A의 라우팅 테이블에서
10.244.1.0/24 → via 192.168.1.20(노드 B)경로를 탐 — BGP가 심어준 경로 - 캡슐화 없이 그대로 물리 네트워크로 전달:
src=10.244.0.5,dst=10.244.1.3— 파드 IP 그대로 - 물리 라우터가 전달: 라우터의 라우팅 테이블에도 BGP로
10.244.1.0/24 → 192.168.1.20경로가 전파되어 있으므로, 노드 B로 전달 - 노드 B가 수신:
src=10.244.0.5,dst=10.244.1.3— 파드 IP 그대로. 노드 B의 라우팅 테이블10.244.1.3 → veth를 거쳐 파드 Y에 도착 - 파드 Y가 수신한 패킷:
src=10.244.0.5,dst=10.244.1.3— 변하지 않음
클라우드 네이티브 라우팅: 인프라가 파드 IP를 직접 라우팅
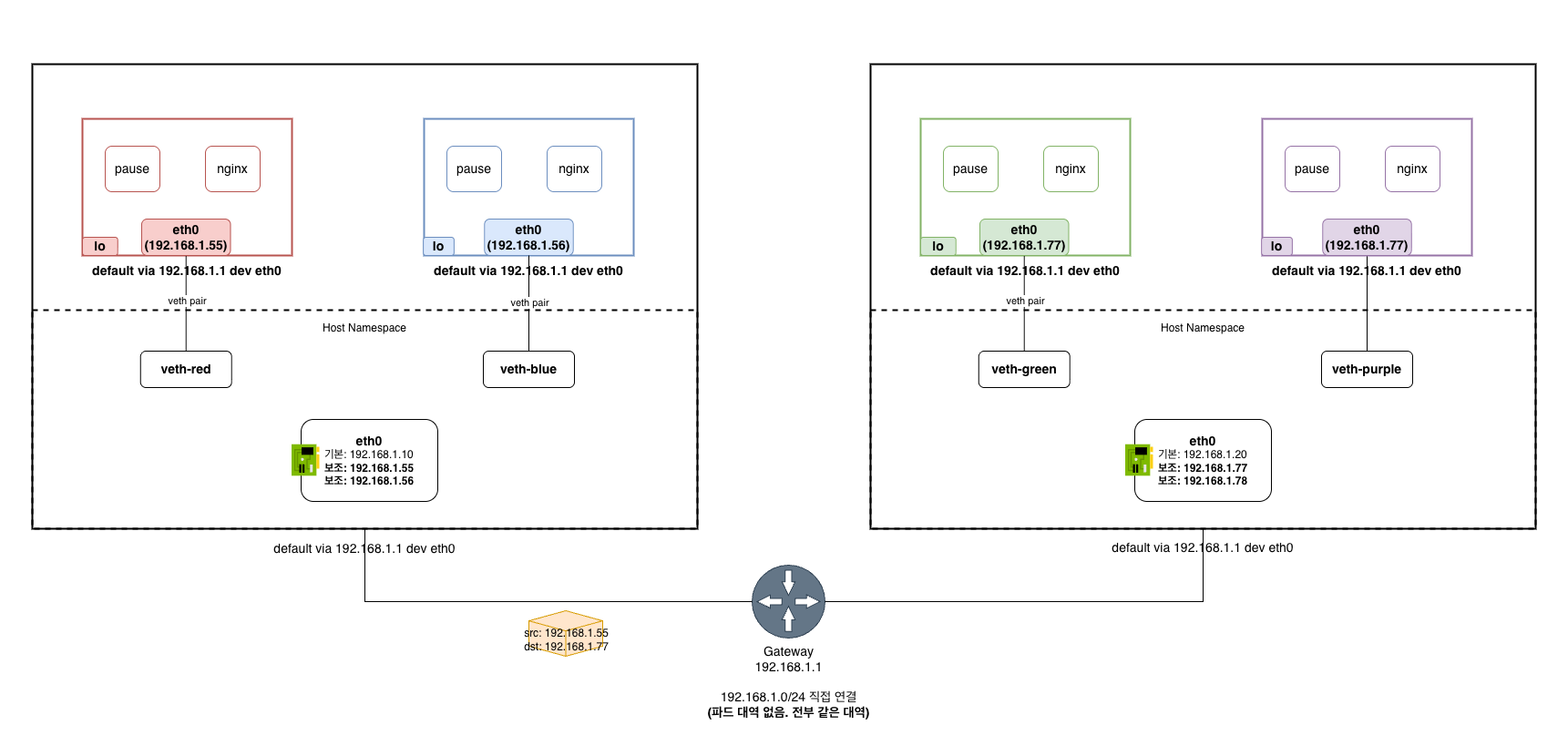
오버레이와 BGP는 모두 파드 전용 대역(10.244.x.x)을 별도로 만들고, 그 대역을 물리 네트워크가 어떻게든 도달할 수 있게 만드는 방식이다. 클라우드 네이티브 라우팅은 접근 자체가 다르다. 별도의 파드 전용 대역을 만드는 대신, 파드에게 클라우드 인프라의 실제 IP를 부여한다. 파드 IP와 노드 IP의 경계를 없앤다.
핵심은 클라우드 SDN이 파드 IP를 1급 시민으로 인지하고 라우팅해준다는 것이다. 프로그래밍에서 1급 시민이 “변수에 담을 수 있고, 함수에 넘길 수 있고, 반환할 수 있는” 것처럼, 클라우드 네트워크에서 파드 IP가 1급 시민이라는 건 “라우팅 테이블에 등록되고, 보안 정책이 적용되고, 네트워크 어디서든 직접 라우팅 가능한” 것을 의미한다. 오버레이에서 파드 IP(10.244.x.x)는 클라우드 네트워크가 “모르는” IP다. 라우팅 테이블에 등록되지 않고, 보안 그룹도 적용할 수 없고, 네트워크 패브릭이 직접 전달할 수도 없다. 캡슐화라는 우회 수단 없이는 도달 자체가 불가능하니, 1급 시민이 될 수 없다.
파드 IP가 인프라와 같은 대역이니, 클라우드의 라우팅 테이블이 이미 해당 IP를 해당 노드로 라우팅할 수 있다. 별도의 오버레이나 BGP 광고가 필요 없다. 클라우드 네트워크 패브릭은 원래 하던 대로 자기 대역의 IP를 라우팅하는 것이고, 파드가 그 대역의 IP를 받은 것뿐이다. 오버레이나 BGP도 필요 없지만, 클라우드 환경에 종속된다.
주요 클라우드 모두 비슷한 메커니즘을 제공한다. 구현 디테일은 다르지만, 클라우드 SDN이 파드 IP를 직접 라우팅한다는 핵심 원리는 동일하다:
| 클라우드 | CNI | 방식 |
|---|---|---|
| AWS | VPC CNI | ENI 보조 IP + VPC 패브릭 자동 라우팅 |
| GCP | GKE VPC-native | Alias IP ranges — 서브넷의 secondary range를 파드에 할당, VPC가 자동 라우팅 |
| Azure | Azure CNI | VNet의 IP를 파드에 직접 할당 |
오버레이와의 구조 차이를 비교하면 명확하다:
[클라우드 네이티브 라우팅 (예: AWS VPC CNI)]
호스트 ENI (192.168.1.10) ← 클라우드 네트워크가 이 IP들을 다 알고 있음
├ 보조 IP: 192.168.1.11 → Pod A에 할당 ← 같은 대역!
└ 보조 IP: 192.168.1.12 → Pod B에 할당
[오버레이 (Calico/Flannel)]
호스트 NIC (192.168.1.10) ← 물리 네트워크가 아는 IP는 이것뿐
└ cni0 브릿지
├ veth → Pod A (10.244.1.5) ← 완전 다른 대역
└ veth → Pod B (10.244.1.6) ← 물리 네트워크는 이 IP를 모름
파드 IP가 변하지 않는지 경로를 검증해 보자. 파드 X(192.168.1.55, 노드 A)가 파드 Y(192.168.1.77, 노드 B)에게 패킷을 보내는 경우다:
- 파드 X가 패킷 생성:
src=192.168.1.55,dst=192.168.1.77 - veth를 통해 호스트로 나옴:
192.168.1.77은 같은 VPC 서브넷 대역 → 별도 처리 없이 그냥 VPC 패브릭으로 보냄 - VPC 패브릭이 전달:
src=192.168.1.55,dst=192.168.1.77— VPC가 아는 IP.192.168.1.77은 노드 B의 ENI에 붙어 있으므로 노드 B로 전달. 캡슐화 없음 - 노드 B가 수신:
src=192.168.1.55,dst=192.168.1.77— 파드 IP 그대로. 노드 B의 라우팅192.168.1.77 → veth를 거쳐 파드 Y에 도착 - 파드 Y가 수신한 패킷:
src=192.168.1.55,dst=192.168.1.77— 변하지 않음
AWS VPC CNI를 예로 들어 보면, 파드 IP 대역이 VPC 서브넷 대역과 동일하니 VPC 입장에서 파드 IP는 그냥 자기 서브넷의 IP이므로 특별한 처리 없이 기존 라우팅으로 전달할 수 있다. 오버레이처럼 캡슐화할 필요도 없고, BGP처럼 별도 경로를 광고할 필요도 없다.
정리
세 가지 방식 비교
세 가지 방식 모두 파드 X가 보낸 패킷의 src/dst IP가 파드 Y에 도착할 때까지 한 번도 변하지 않는다. 방법만 다를 뿐 “NAT 없이 파드 IP로 직접 통신”이라는 결과는 동일하다. 일관된 기준으로 비교해 보자.
노드 내부 구조
파드에게 IP를 어떻게 부여하고, 그 IP가 물리 네트워크와 같은 대역인지 다른 대역인지에서 차이가 시작된다.
| 오버레이 (Flannel VXLAN) | BGP (Calico) | 클라우드 네이티브 (AWS VPC CNI) | |
|---|---|---|---|
| 파드 IP 대역 | 별도 대역 (10.244.x.x) | 별도 대역 (10.244.x.x) | VPC와 같은 대역 (192.168.x.x) |
| IP 할당 방식 | 파드마다 veth를 만들고 별도 대역 IP 할당 | 파드마다 veth를 만들고 별도 대역 IP 할당 | ENI에 보조 IP를 추가하고 파드에 할당 |
| 물리 네트워크의 인지 | 파드 IP를 모름 | BGP 전파 후 알게 됨 | 원래부터 앎 (같은 대역) |
[오버레이 / BGP]
호스트 NIC (192.168.1.10) ← 물리 네트워크가 아는 IP는 이것뿐
└ cni0 브릿지
├ veth → Pod A (10.244.1.5) ← 완전 다른 대역
└ veth → Pod B (10.244.1.6) ← 물리 네트워크는 이 IP를 모름
[AWS VPC CNI]
호스트 ENI (192.168.1.10)
├ 보조 IP: 192.168.1.11 → Pod A에 할당 ← 같은 대역!
├ 보조 IP: 192.168.1.12 → Pod B에 할당
└ VPC가 이 IP들을 다 알고 있음
노드 간 도달 방법
파드 IP를 다른 노드에서 어떻게 도달 가능하게 만드느냐가 각 방식의 핵심 차이다.
| 오버레이 | BGP | 클라우드 네이티브 | |
|---|---|---|---|
| 도달 방법 | 캡슐화 (노드 IP로 감싸서 터널링) | 라우팅 정보를 물리 네트워크에 전파 | 인프라가 원래부터 라우팅 가능 |
| 누가 알려주나 | 알려주지 않음 (캡슐화로 우회) | Calico 에이전트(bird)가 BGP로 광고 | ipamd가 AssignPrivateIpAddresses API 호출 |
| 누가 반영하나 | 노드의 오버레이 인터페이스가 처리 | 물리 라우터/다른 노드가 BGP 수신 후 스스로 반영 | VPC 패브릭이 API 호출을 받아 즉시 자동 반영 |
| 캡슐화 | O (VXLAN, IPIP) | X | X |
| 인프라 요구 | 노드 간 IP 통신만 되면 됨 | 라우터가 BGP를 지원해야 함 | 클라우드 환경 (AWS, GCP, Azure) |
| 오버헤드 | 캡슐화/디캡슐화 처리 비용 | 없음 | 없음 |
NAT 없음 검증
세 방식 모두 파드 간 통신에서 src/dst IP가 경로 전체에서 변하지 않는다.
| 오버레이 | BGP | 클라우드 네이티브 | |
|---|---|---|---|
| 패킷이 물리 네트워크를 탈 때 | Outer 헤더 추가, Inner IP 불변 | 파드 IP 그대로 노출 | 파드 IP 그대로 노출 |
| NAT 여부 | Inner IP 불변 → NAT 없음 | IP 불변 → NAT 없음 | IP 불변 → NAT 없음 |
네트워킹 모델 요구사항은 어떻게 충족되는가
다시 처음으로 돌아가 요구사항 두 가지를 꺼내고, 각각이 어떻게 충족되는지 짚어 보자.
요구사항 1 — 모든 파드는 같은 노드든 다른 노드든, NAT 없이 직접 통신할 수 있어야 한다
이 글의 본론 전체가 이 요구사항에 대한 답이다.
- 같은 노드: 같은 노드의 파드 간 통신에서 다뤘다. veth pair로 네임스페이스 벽을 관통하고, 브릿지가 L2 스위치 역할을 하여 파드들을 하나의 네트워크 세그먼트로 묶는다. 브릿지 내부에서는 IP 변환이 일어나지 않으므로 NAT 없이 통신된다.
- 다른 노드: 다른 노드의 파드 간 통신에서 다뤘다. 파드 IP를 노드 밖에서도 도달 가능하게 만들어야 하며, 오버레이(터널링으로 우회), BGP(라우팅 정보 전파), 클라우드 네이티브(인프라 IP 직접 부여) 세 가지 방식이 있다.
요구사항 2 — 노드의 에이전트(kubelet 등)는 동일한 노드의 모든 파드와 통신할 수 있어야 한다
이 요구사항은 별도로 다루지 않았는데, 요구사항 1이 해결되면 자연스럽게 충족된다.
- 오버레이 / BGP의 경우: 브릿지(cni0)에 IP가 부여되면 호스트 네임스페이스도 파드 네트워크에 참여하게 된다. kubelet이 파드에 접근할 때, 호스트에서 cni0 브릿지를 거쳐 veth를 통해 파드에 도달한다. 호스트도 브릿지에 연결된 “또 하나의 참여자”인 셈이다.
- 클라우드 네이티브(AWS VPC CNI)의 경우: 호스트의 ENI와 파드가 같은 VPC 대역을 공유하므로, 호스트 프로세스가 파드 IP로 직접 통신할 수 있다.
참고:
hostNetwork: true파드의 경우
hostNetwork: true파드는 별도의 네트워크 네임스페이스를 만들지 않고 노드의 네트워크 네임스페이스를 그대로 공유한다. 즉 노드의 라우팅 테이블을 그대로 타므로, 오버레이라면10.244.1.0/24 → flannel.1같은 룰이, BGP라면 전파된 경로가, VPC CNI라면 VPC 라우팅이 이미 호스트에 있다. 목적지 파드까지의 도달 메커니즘은 동일하다. 차이는 출발지뿐이다. 일반 파드는src=파드IP로 보내지만, hostNetwork 파드는src=노드IP로 보낸다. 노드 IP는 물리 네트워크에서 원래 라우팅 가능하므로 응답 경로는 오히려 더 단순하다. 어느 쪽이든 경로상 NAT은 일어나지 않는다.
정리하면:
| 요구사항 | 충족 메커니즘 |
|---|---|
| 1. 모든 파드 ↔ 모든 파드 (NAT 없이) | 같은 노드: veth pair + 브릿지로 L2 세그먼트 구성 / 다른 노드: 오버레이·BGP·클라우드 네이티브 중 하나로 도달 가능하게 함 |
| 2. 노드 에이전트 ↔ 같은 노드 파드 | 브릿지에 IP 부여 → 호스트도 파드 네트워크에 참여 (요구사항 1의 부산물) |
이 두 요구사항을 모두 충족하는 구현체가 CNI 플러그인이다. AWS VPC CNI는 클라우드 네이티브 라우팅 방식에 해당한다. 1주차에서 확인했던 VPC CNI Secondary ENI와 aws-k8s-agent가 바로 이 메커니즘의 구성 요소였던 것이다. ENI에 보조 IP를 추가하고 파드에 할당하는 방식으로, VPC 패브릭이 파드 IP를 1급 시민으로 라우팅한다.
다음 글에서는 AWS VPC CNI의 구체적인 동작 — ENI 관리, IP 할당, warm pool, maxPods 계산 등 — 을 본격적으로 살펴본다.
이 글의 위치: 쿠버네티스 네트워킹의 4가지 문제
앞서 다룬 2개 요구사항은 파드 네트워크가 지켜야 하는 규칙이다. 한편 쿠버네티스 공식 문서는 클러스터 네트워킹을 통신 범위에 따라 4가지 문제로 분류한다:
| # | 문제 | 해결 주체 |
|---|---|---|
| 1 | 컨테이너 ↔ 컨테이너 (같은 파드 내) | Pause 컨테이너가 만든 공유 네트워크 네임스페이스 + localhost |
| 2 | 파드 ↔ 파드 (같은/다른 노드) | CNI 플러그인 (veth + 브릿지, 오버레이/BGP/클라우드 네이티브) |
| 3 | 파드 ↔ 서비스 | kube-proxy (iptables/IPVS 규칙으로 Service ClusterIP → 파드 IP 변환) |
| 4 | 외부 ↔ 서비스 | NodePort, LoadBalancer, Ingress 등 |
이 2개 요구사항(NAT 없이 모든 파드 간 통신, 에이전트-파드 통신)은 2번 문제를 어떻게 풀어야 하는지의 규칙이다. 이 글은 1번과 2번을 다뤘다. 1번(컨테이너 간 통신)은 Pause 컨테이너의 네트워크 네임스페이스 공유로 해결되고, 2번(파드 간 통신)이 이 글의 본론이었다.
3번과 4번은 kube-proxy와 Ingress 등 Service 계층의 영역으로, 2번이 풀려야 성립한다. 여기서 한 가지 의문이 생길 수 있다. 3번(파드 ↔ 서비스)에서 kube-proxy가 DNAT을 하는데, 이것은 “NAT 없이” 규칙에 위배되지 않는가? 위배되지 않는다. 요구사항이 말하는 “NAT 없이”는 파드 ↔ 파드 직접 통신 경로(인프라 계층)에 대한 것이고, Service는 그 위의 상위 추상화 계층이기 때문이다. 실제로 엔드포인트 분석에서 확인했던 것처럼, Pod가 kubernetes Service의 ClusterIP(10.100.0.1)로 요청하면 kube-proxy의 iptables가 ENI 사설 IP로 DNAT하는 것도 이 Service 추상화 계층의 동작이다.
이번 주차에서 살펴볼 AWS VPC CNI는 2번 문제의 해법이다. 다음 글부터 그 구체적인 원리 및 동작에 대해 알아본다.

댓글남기기