
[GenAI] GenAI on K8s: 1. 생성형 AI 기초
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 1장의 학습 내용을 바탕으로 합니다
TL;DR
- AI > ML > DL > GenAI 포함 관계. 생성형 AI(GenAI)는 텍스트, 이미지 등 새 데이터 생성에 특화된 딥러닝의 하위 분야다
- Transformer는 self-attention 기반 병렬 처리로 CNN/RNN의 한계를 돌파했다. 이후 BERT(인코더)와 GPT(디코더)로 분화
- GenAI 프로젝트 라이프사이클: 비즈니스 목표 → FM 선택 → 최적화(Fine-tuning, RLHF) → 평가 → 배포 → 모니터링
- GenAI 배포 스택: GPU 컴퓨트, 분산 학습 네트워킹(RDMA), 스토리지, 오케스트레이션(Kubernetes)으로 구성된다
AI와 생성형 AI
AI/ML/DL/GenAI 포함 관계
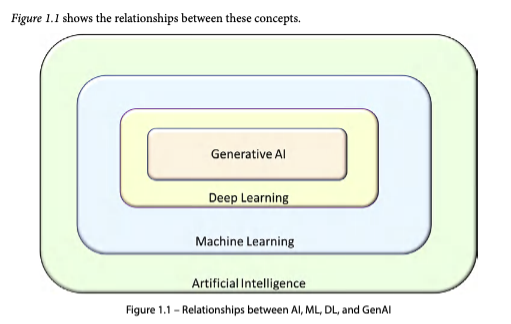
| 계층 | 정의 | 포함 범위 |
|---|---|---|
| 인공지능(Artificial Intelligence, AI) | 추론, 학습, 문제 해결, 인식, 언어 이해 등 인간 지능이 필요한 작업을 수행하는 시스템 | 규칙 기반 시스템, 전문가 시스템, 신경망, GenAI 등을 포함하는 가장 넓은 범주 |
| 머신러닝(Machine Learning, ML) | 명시적 코딩 없이 데이터로부터 학습해 예측하는 알고리즘 | 지도/비지도/준지도/강화학습 |
| 딥러닝(Deep Learning, DL) | 다층 심층 신경망을 사용하는 ML의 한 갈래 | CNN(이미지), RNN(시계열, NLP) 등 |
| 생성형 AI(Generative AI, GenAI) | 텍스트, 이미지, 음악 등 새로운 데이터를 생성하는 데 초점을 둔 DL의 하위 분야 | Foundation Model(FM), Large Language Model(LLM) |
전통 프로그래밍과 ML의 차이
| 구분 | 동작 방식 |
|---|---|
| 전통 프로그래밍 | 개발자가 컴퓨터에게 실행할 명령을 명시적으로 작성 |
| 머신러닝 | 알고리즘이 데이터의 패턴과 관계로부터 학습하여 예측 수행 |
ML의 4가지 학습 유형
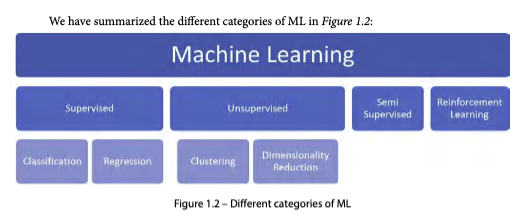
| 유형 | 데이터 | 동작 방식 | 대표 예시 |
|---|---|---|---|
| 지도 학습(Supervised) | 라벨링된 데이터 | 입력-정답 쌍으로 학습하여 분류, 회귀 수행 | 이미지 분류, 주택 가격 예측 |
| 비지도 학습(Unsupervised) | 라벨 없는 데이터 | 데이터의 잠재 패턴과 구조를 스스로 발견 | 군집화(k-means), 차원 축소(PCA) |
| 준지도 학습(Semi-supervised) | 소량 라벨 + 다량 비라벨 | 적은 라벨 데이터로 학습 후 비라벨 데이터에 반복 적용 | 스팸 탐지, 이미지 인식, 음성 인식 |
| 강화 학습(Reinforcement) | 환경과의 상호작용 | 시행착오로 보상을 최대화하는 정책 학습 | 에이전트(agent)가 환경에서 행동 → 보상(reward) → 정책 업데이트 |
Foundation Model과 LLM
| 개념 | 정의 | 특징 |
|---|---|---|
| Foundation Model(FM) | 대규모 다양 데이터로 사전학습되어 광범위한 다운스트림 작업의 기반이 되는 대형 AI 모델 | 사전학습(pre-training) + 도메인별 파인튜닝(fine-tuning) |
| Large Language Model(LLM) | 인간 언어의 이해와 생성에 특화된 FM의 부분집합 | GPT, Claude, BERT 등 |
머신러닝의 진화
지난 20년간 ML은 규칙 기반, 수작업 피처 의존 모델에서 신경망과 Transformer 기반의 문맥 인식 모델로 진화했다. 특히 딥러닝(DL)이 폭발적으로 성장한 배경에는 3가지 핵심 동력이 있다.
| 동력 | 내용 |
|---|---|
| Data | 빅데이터 축적. ImageNet 등 대규모 데이터셋 확보 |
| Hardware | GPU 연산 혁명. NVIDIA GPU를 통한 대규모 병렬 연산 가능 |
| Algorithm | 수학적 한계 극복. ReLU, Dropout, BatchNorm 등 기법 등장 |
Transformer 이전: CNN과 RNN
| 아키텍처 | 영감/원리 | 주요 용도 |
|---|---|---|
| CNN(Convolutional Neural Network) | 시각 피질의 뉴런이 망막 이미지를 처리하는 방식에서 착안. 필터로 특정 피처 검출 | 이미지 처리, 인식 |
| RNN(Recurrent Neural Network) | 역전파(backpropagation) 기반. 시간 단계 t를 내재적으로 인지 |
시계열 분석(주가 예측), NLP(단어 순서가 의미를 좌우) |
RNN은 순서가 중요한 데이터(자연어, 시계열)에 강했지만, 순차 처리 구조 때문에 근본적인 한계가 있었다.
| 한계 | 설명 |
|---|---|
| 병렬 처리 불가 | 앞 단어를 처리해야 다음 단어를 처리 가능 → GPU 활용 효율이 낮음 |
| 장기 의존성 문제 | 문장이 길어질수록 앞부분 정보가 약해짐(vanishing gradient) |
| 학습 속도 느림 | 순차 구조 때문에 대규모 데이터 학습에 시간이 오래 걸림 |
GPU 딥러닝 시대의 시작: ImageNet과 AlexNet
2012년 AlexNet이 ImageNet 대회에서 deep CNN과 GPU 병렬 연산을 활용해 기존 SVM 기반 접근을 압도했다. 단순히 CNN을 썼다는 것이 아니라, GPU를 적극 활용한 대규모 딥러닝 학습이 현실적으로 가능하다는 것을 증명한 사건이다. 이후 GPU 기반 딥러닝이 AI/ML 개발의 핵심 흐름이 됐다.
Transformer의 등장
2017년 논문 Attention Is All You Need에서 제안된 Transformer는 self-attention 기반의 병렬 처리를 도입해 NLP를 근본적으로 바꿨다.
Transformer가 NLP를 뒤집은 이유: RNN처럼 순서대로 기다리지 않고 문장 전체의 토큰 관계를 한 번에 계산할 수 있어, 확장성과 효율성이 비약적으로 개선됐다. BERT는 양방향 문맥 이해를 가능케 했고, 이를 토대로 OpenAI의 GPT 계열, Anthropic의 Claude 등 다양한 LLM이 등장했다.
Transformer 아키텍처
Transformer 모델은 인코더-디코더(encoder-decoder) 구조를 따른다. 아키텍처 세부 구조(인코더-디코더 스택, Positional Encoding, Multi-head Attention, Masking 등)는 이전에 작성한 Transformer 시리즈에서 논문을 따라가며 상세히 정리한 바 있다. 아래에서는 GenAI 인프라 맥락에서 필요한 핵심을 요약한다.
| 구성 | 역할 |
|---|---|
| 인코더(Encoder) | 입력 시퀀스를 self-attention 메커니즘으로 매핑 |
| 디코더(Decoder) | 매핑된 데이터를 이용해 출력 시퀀스를 생성 |
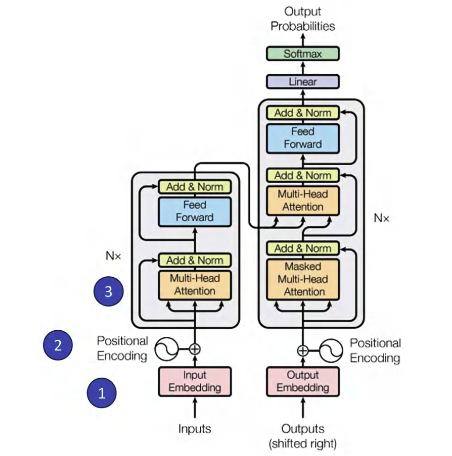
입력 임베딩
입력 시퀀스의 각 토큰을 고차원 벡터 임베딩으로 변환하는 단계다.
- Transformer 모델의 핵심 구성 요소
- 학습된 모델의 출력 임베딩은 벡터 데이터베이스(Elasticsearch, Milvus, Pinecone 등)에 저장할 수 있다
- 벡터 DB는 유클리드 거리, 코사인 유사도 등으로 유사 검색을 수행한다. 유사한 객체일수록 가까이 배치된다
위치 인코딩
토큰의 순서 정보를 임베딩에 주입하는 단계다. RNN은 시간 단계 t를 내재적으로 알지만, Transformer는 self-attention만으로는 토큰 순서를 인지하지 못한다. self-attention은 순열 등가(permutation-equivariant) 연산이기 때문이다.
Attention 수식을 보면 토큰의 위치 인덱스 \(i\)가 어디에도 등장하지 않는다. \(Q_i\)와 \(K_j\)의 내적은 두 벡터의 내용만으로 결정되며, \(i\), \(j\)의 절댓값이나 상대값을 모른다. 즉, 모델 입장에서 “I love you”와 “you love I”가 똑같이 보인다. 위치 인코딩으로 순서 정보를 임베딩에 더해 주는 이유다.
예시: “The Brown hat”
- 토큰 임베딩: 각 단어를 벡터로 변환
The→[0.1, 0.2],Brown→[0.3, 0.4],hat→[0.5, 0.6]
- 위치 인코딩 벡터 생성
- Position 0 →
[0.01, 0.02], Position 1 →[0.03, 0.04], Position 2 →[0.05, 0.06]
- Position 0 →
- 임베딩 + 위치 인코딩
The+ Position 0 →[0.11, 0.22],Brown+ Position 1 →[0.33, 0.44],hat+ Position 2 →[0.55, 0.66]
| 아키텍처 | 순서 정보 출처 |
|---|---|
| RNN | 시간 단계 t를 순차적으로 처리. 순서가 계산 구조에 내재 |
| CNN | 커널이 인접 위치를 합성곱. 지역적 순서는 알지만 장거리는 모름 |
| Transformer | self-attention 자체는 순서 무관 → 명시적 위치 인코딩으로 주입 필수 |
위치 인코딩 방법도 여러 가지가 있다.
| 방법 | 특징 |
|---|---|
| Sinusoidal(원본 Transformer) | sin/cos 함수 사용. 학습 불필요, 추론 시 임의 길이로 확장 가능 |
| Learned positional embedding(BERT, GPT-2) | 위치별 임베딩을 학습. 학습 길이 초과 시 확장 어려움 |
| RoPE(Rotary Position Embedding) | Q, K 벡터를 회전 변환. LLaMA, GPT-NeoX 등 최근 LLM의 사실상 표준 |
| ALiBi | attention score에 거리 기반 bias 추가. 길이 외삽(extrapolation)에 강점 |
원본 Transformer의 Sinusoidal 방식에 대한 수학적 직관과 Python 구현, 2D/3D 시각화는 이전 글에서 다뤘다.
컨텍스트 길이 확장(8K → 128K) 문제는 본질적으로 위치 인코딩 문제다. 지금은 여기까지 알면 충분하고, RoPE/ALiBi의 수학적 디테일이 궁금하다면 RoFormer 논문이나 LLaMA 논문을 별도로 살펴보자.
Multi-head Attention
Self-attention: Q, K, V 벡터
입력 시퀀스(토큰 임베딩 묶음)가 들어오면 각 토큰마다 세 가지 다른 벡터를 만든다. 같은 입력 임베딩 \(x\)에 학습 가능한 가중치 행렬 \(W_Q, W_K, W_V\)를 각각 곱한 것이다.
| 벡터 | 역할 | 의미 |
|---|---|---|
| Query(Q) | 이 토큰이 다른 토큰들에게 던지는 질문 벡터 | “나는 지금 어떤 정보를 찾고 있는가?” |
| Key(K) | 다른 토큰들이 들고 있는 색인 벡터 | “나는 어떤 정보를 제공할 수 있는가?” |
| Value(V) | 가중합으로 섞일 실제 콘텐츠 벡터 | “내가 실제로 전달할 내용” |
Attention 연산은 한 줄로 표현할 수 있다.
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{Q K^\top}{\sqrt{d_k}}\right) V\]직관적으로 세 단계다.
- \(Q K^\top\): 모든 토큰의 Query를 모든 토큰의 Key와 내적 → “토큰 i가 토큰 j에 얼마나 주목해야 하는가” 유사도 행렬
- \(\sqrt{d_k}\)로 나누고 softmax → 각 행이 합 1이 되도록 정규화된 attention weight
- 그 가중치로 모든 토큰의 Value 벡터를 가중합 → 토큰 i의 새 표현(문맥이 반영된 임베딩)
“The brown hat”에서 “hat” 토큰의 Q가 “brown” 토큰의 K와 내적값이 높게 나오면, “hat”의 새 표현은 “brown”의 V를 강하게 섞어 들인다. “갈색 모자”라는 문맥이 hat 벡터에 녹아 들어가는 것이다.
Scaled Dot-Product Attention의 상세 계산 과정과 Self-Attention에서 Q/K/V가 만들어지는 흐름은 이전 시리즈의 Attention 편과 Self-Attention 편에서 시각화와 함께 정리했다.
Multi-head: 왜 head를 여러 개 둘까
위의 self-attention 1회를 head 1개라고 한다. Multi-head는 그 head를 \(h\)개(GPT-3는 96개) 병렬로 돌린다. head마다 \(W_Q, W_K, W_V\)는 별개로 학습된다.
- head 1: 문법적 의존성(주어-동사 관계)에 attend
- head 2: 대명사-선행사 관계
- head 3: 가까운 위치의 수식어
- 어떤 head가 무엇을 학습할지는 강제하지 않는다. 데이터가 결정한다
각 head의 출력을 concat한 뒤 선형 변환 \(W_O\)를 거쳐 다음 레이어로 넘긴다.
왜 나눌까? 하나의 큰 attention보다 작은 attention 여러 개로 쪼개면 (a) 서로 다른 관점을 동시에 포착할 수 있고 (b) 각 head의 차원이 작아 병렬화에 유리(GPU 친화적)하다.
Attention 심화: Q/K/V의 실체
Attention의 Q/K/V는 “사용자가 LLM에 보낸 query”나 “LLM이 학습한 지식의 임베딩”과는 전혀 다른 것이다. 흔히 가지기 쉬운 오해를 정리해 보자.
| 잘못 가지기 쉬운 직관 | 실제 |
|---|---|
| “Query = 사용자가 LLM에 보낸 프롬프트” | Q는 모델 내부에서, 입력 토큰 하나가 같은 시퀀스의 다른 토큰들에게 던지는 가중치 계산용 벡터 |
| “Key = LLM이 사전학습으로 알게 된 지식의 임베딩” | K는 매 forward pass마다 새로 계산되는 임시 벡터. LLM의 지식은 K가 아니라 가중치 행렬에 있다 |
| “Q와 K는 서로 다른 출처에서 온다” | self-attention에서는 Q, K, V 모두 같은 입력 시퀀스의 같은 임베딩으로부터 만들어진다 |
| ”\(W_Q, W_K, W_V\) 안에 토큰/지식 정보가 들어있다” | W는 임의의 d차원 벡터를 받아 곱하는 선형변환 행렬일 뿐, 토큰 개념을 모른다 |
Q/K/V 자체는 어디에도 저장돼 있지 않다. 저장된 건 “어떻게 만들지” 공식인 가중치 행렬 \(W_Q, W_K, W_V\) 뿐이다. Q/K/V는 매 forward pass마다 입력에 이 가중치를 곱해서 새로 계산된다.
모델에 영구 저장된 것 vs 매번 계산되는 것
| 저장(학습됨, 모델 파일 안) | 매번 계산(forward pass마다) | |
|---|---|---|
| 임베딩 테이블 | O | |
| \(W_Q, W_K, W_V\) (레이어, head별) | O | |
| \(W_O\), FFN 가중치 | O | |
| 토큰 임베딩 \(x_1 \ldots x_n\) | O (테이블 룩업) | |
| Q, K, V (각 토큰 벡터) | O (행렬곱) | |
| Attention score matrix (\(QK^\top\)) | O | |
| 각 레이어 hidden state | O |
“사전학습된 K가 어딘가에 저장되어 있다”는 그림이 틀린 이유가 여기 있다. 저장된 건 K를 만드는 공식(\(W_K\))일 뿐이다.
Q/K/V 행렬곱 계산 상세
시퀀스 “오늘 서울 날씨 가 어때 ?” 6개 토큰을 임베딩 테이블에서 룩업한 결과를 쌓으면 입력 행렬 X가 된다.
X (입력 행렬, shape = (6, 4096))
row 0 = x_1 ← "오늘"의 임베딩 (4096차원 행벡터)
row 1 = x_2 ← "서울"
row 2 = x_3 ← "날씨"
row 3 = x_4 ← "가"
row 4 = x_5 ← "어때"
row 5 = x_6 ← "?"
단일 토큰의 Q 계산:
# "오늘" 토큰 하나의 Query 벡터
x_1 shape: (1, 4096)
W_Q shape: (4096, 4096) # 안쪽 4096이 맞아야 곱셈 가능
Q_1 = x_1 @ W_Q
→ (1, 4096) @ (4096, 4096)
= (1, 4096)
같은 \(x_1\)에서 \(W_K, W_V\)로 곱하면 \(K_1, V_1\)이 나온다. 같은 입력이 세 가지 다른 벡터로 나오는 이유는 세 W가 모두 다르게 학습됐기 때문이다.
시퀀스 전체 한 번에 계산(실제 구현):
# 토큰별 for 루프가 아니라, 시퀀스 통째로 한 번의 행렬곱
X shape: (6, 4096) # 6개 토큰 한꺼번에
W_Q shape: (4096, 4096)
Q = X @ W_Q
→ (6, 4096) @ (4096, 4096)
= (6, 4096)
↑ ↑
행 = 토큰 순서 열 = 각 토큰의 Q 벡터 차원
# Q[0] = Q_1(오늘), Q[1] = Q_2(서울), ..., Q[5] = Q_6(?)
K, V도 동일하게 K = X @ W_K, V = X @ W_V로 만든다. 6개 토큰의 Q/K/V를 행렬곱 3회로 모두 생성한다. GPU의 cuBLAS가 행렬곱에 특화돼 있어 토큰별 루프보다 수십~수백 배 빠르다.
Multi-head 차원 분할
실제로는 \(d_{model}\) 차원을 N개 head로 쪼개서 병렬 attention을 수행한다.
| 모델 | \(d_{model}\) | num_heads | \(d_{head}\) |
|---|---|---|---|
| GPT-2 small | 768 | 12 | 64 |
| LLaMA 7B | 4096 | 32 | 128 |
| LLaMA 70B | 8192 | 64 | 128 |
head별로 독립 attention을 수행한다. 한 head는 문법, 한 head는 거리 관계, 한 head는 공동참조(coreference) 등 서로 다른 관심사를 학습한다.
LLM의 지식은 어디에 저장되는가
가중치(weights)에 저장돼 있고, K 벡터에 저장돼 있지 않다.
학습으로 고정되는 것은 각 attention 레이어의 \(W_Q, W_K, W_V, W_O\)(head별), 각 FFN(Feed-Forward Network) 레이어의 가중치, 임베딩 테이블 등이다. 특히 사실적 지식(factual knowledge)이 주로 FFN 가중치에 저장된다는 게 mechanistic interpretability 분야의 현재 가설이다.
“한국의 수도는?” 추론 과정을 대략적으로 따라가 보면 다음과 같다.
- 입력 토큰화 → 임베딩(학습된 임베딩 테이블 사용)
- 각 레이어에서 attention을 돌면서 토큰 간 문맥 결합(“한국” Q ↔ “수도” K 매칭 등)
- 문맥이 반영된 hidden state가 FFN 가중치를 통과 → 여기서 “한국 ≈ 서울” 같은 사실 결합이 활성화됨(학습된 가중치 패턴)
- 마지막 logits → softmax → 다음 토큰(“서”) 확률 최대
K 벡터에 “서울”이 저장되어 있어서 매칭되는 게 아니라, FFN 가중치 안에 “한국 → 서울” 매핑 회로가 학습돼 있어서 그 회로가 활성화되는 구조다.
Cross-attention: Q/K/V 직관이 맞는 경우
원조 Transformer의 디코더 부분에는 cross-attention(또는 encoder-decoder attention)이 있다.
- Q: 디코더의 현재 토큰에서 생성
- K, V: 인코더가 처리한 입력 시퀀스(예: 번역 모델이라면 영어 원문)에서 생성
이건 “Q는 내 질문, K/V는 참고할 자료”라는 직관에 가깝다. 단, K/V도 “LLM의 사전학습 지식”이 아니라 “이번 입력으로 들어온 인코더 출력” 이라는 점은 동일하다.
RAG와 용어 충돌
같은 단어 “query/key”가 ML 스택의 서로 다른 레이어에서 따로 쓰인다. 혼동하지 않도록 정리해 두자.
| 레이어 | “query” | “key” |
|---|---|---|
| API/사용자 인터페이스 | 사용자가 LLM에 보낸 자연어 프롬프트 | (해당 없음) |
| RAG/벡터DB | 검색 입력 임베딩(사용자 query를 임베딩한 것) | 벡터DB에 인덱싱된 문서 청크 임베딩 |
| Transformer attention | 한 토큰이 다른 토큰들에게 던지는 가중치 계산용 벡터(\(Q = xW_Q\)) | 한 토큰이 자신을 광고하는 색인 벡터(\(K = xW_K\)) |
이 세 레이어는 서로 독립적이다. 사용자 query가 토큰화 → 임베딩 → attention의 Q로 “변환”되는 게 아니라, 모든 토큰이 매 레이어마다 자기 Q/K/V를 만들어 자기들끼리 attention 계산하는 것이다.
인코더-only vs 디코더-only
원본 Transformer는 인코더+디코더 양쪽을 모두 쓰는 번역 모델이었고, 이후 두 갈래로 분화되었다.
| 모델 | 구조 | Attention 종류 | 주 용도 |
|---|---|---|---|
| 원본 Transformer(Vaswani 2017) | Encoder + Decoder | 인코더: 양방향 self-attention, 디코더: causal self-attention + cross-attention | 기계 번역 |
| BERT(Google 2018) | Encoder only | 양방향(bidirectional) self-attention | 분류, 이해(NLU, Natural Language Understanding). 감성 분석, QA, NER(Named Entity Recognition) |
| GPT 계열(OpenAI) | Decoder only | Causal(masked) self-attention. 미래 토큰 차단 | 생성(NLG, Natural Language Generation). autoregressive |
| T5, BART | Encoder + Decoder | 원본과 동일 | seq2seq. 요약, 번역, QA |
핵심 차이: Attention mask
- BERT의 양방향 attention: 토큰 i가 시퀀스의 모든 토큰(과거+미래)을 볼 수 있다. “이 빈칸에 들어갈 단어는?” 같은 MLM(Masked Language Modeling) 학습에 적합하다
- GPT의 causal attention: 토큰 i는 i 이전 토큰만 볼 수 있다(upper triangular mask). “다음 토큰 예측” 학습에 필수다. 미래를 보면 cheat이 되기 때문이다
| Attention 종류 | Q 출처 | K, V 출처 | 사용처 |
|---|---|---|---|
| Self-attention | 같은 시퀀스 | 같은 시퀀스 | 모든 Transformer(인코더/디코더) |
| Masked self-attention | 같은 시퀀스 | 같은 시퀀스(미래 토큰 마스킹) | 디코더, GPT 계열(자기회귀 생성) |
| Cross-attention | 디코더 | 인코더 출력 | 원조 Transformer(번역), T5, BART 등 |
GPT 계열(decoder-only)은 cross-attention 없이 masked self-attention만 쓴다. 사용자 prompt도, 모델이 지금까지 생성한 출력도 다 한 시퀀스로 이어 붙여서 self-attention 한 번에 처리한다.
왜 GPT 계열이 LLM의 주류가 됐나? 생성 능력 자체가 더 다양한 다운스트림 작업으로 확장 가능하다(few-shot, in-context learning). BERT 계열은 분류나 임베딩 추출에는 여전히 강점이 있다(RAG의 retriever 임베딩 등).
GenAI 프로젝트 라이프사이클
GenAI 프로젝트가 폭증하면서 ROI(Return on Investment) 정량화가 점점 중요해진다. 비즈니스 목표 정의 → FM 선택 → 파인튜닝/프롬프트 튜닝으로 최적화 → 평가 → 배포 → 모니터링의 전체 흐름을 이해해 두는 게 유용하다.
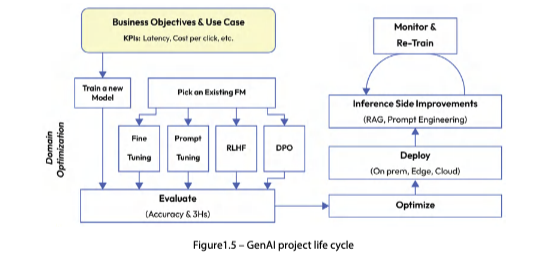
비즈니스 목표와 FM 선택
- 비즈니스 목표와 KPI 정의: GenAI로 풀려는 문제가 무엇인지부터 정한다
- 핵심 KPI: 추론 비용이 프로젝트가 창출할 가치보다 크면 의미가 없다
| KPI | 설명 | 예시 |
|---|---|---|
| Cost per inference | 한 번 응답 생성 비용 | 질문 1건당 X원 |
| Latency | 응답 지연 시간 | 1초 이하 응답 필요 |
| Throughput | 초당 처리량 | tokens/sec, requests/sec |
| Accuracy | 답변 정확도 | 평가 점수, 정답률 |
| Safety | 안전성 | 유해 답변 비율 |
- FM 선택: 새 FM 학습은 수십억 달러와 수개월이 들 수 있어, 대부분의 경우 기존 FM을 선택해 도메인 최적화하는 편이 합리적이다
| 구분 | 오픈소스 모델 | 상용 API 모델 |
|---|---|---|
| 예시 | Llama, Mistral, Qwen | ChatGPT, Claude |
| 장점 | 직접 제어 가능, 온프레미스 운영 | 빠른 도입, 운영 부담 낮음 |
| 단점 | GPU/운영/보안 직접 관리 | 데이터 외부 전송, 비용 종속성 |
| K8s 관련 | 직접 서빙 인프라 필요 | 앱만 K8s에 배포 가능 |
라이선스 조건(상업적 사용 가능 여부, 재배포 가능 여부, Fine-tuning 후 배포 가능 여부) 확인은 필수다.
모델 최적화 기법
| 기법 | 핵심 아이디어 | 특징 |
|---|---|---|
| Fine-tuning | 도메인별 라벨링 데이터(prompt + completion)로 모델 재학습 | PEFT(Parameter-Efficient Fine-Tuning), LoRA, QLoRA로 학습 자원 절감 가능 |
| Prompt tuning | 입력 쿼리에 soft prompt token을 추가하고 이 토큰만 도메인 데이터로 학습 | 본체 가중치는 freeze. 저비용 |
| RLHF(Reinforcement Learning from Human Feedback) | 인간 피드백으로 보상 모델 학습 후 RL로 LLM 정렬 | 인간 평가 → 보상 모델 → RL |
| DPO(Direct Preference Optimization) | RL 없이 선호 쌍(\(A_p\) vs \(A_{np}\))으로 분류 목적함수 최적화 | RLHF보다 단순. 선호 답변 확률을 직접 높이도록 학습 |
PEFT 계열 변형
- LoRA(Low-Rank Adaptation): 원본 행렬을 저랭크 표현으로 재매개변수화 → 업데이트할 파라미터 수 대폭 감소
- QLoRA(Quantized LoRA): 양자화로 가중치 크기를 압축 → 모델 크기와 메모리 요구량 감소, 작은 GPU에서도 학습 가능
Fine-tuning vs Prompt Tuning 비교
| 구분 | Fine-tuning | Prompt Tuning |
|---|---|---|
| 변경 대상 | 모델 가중치 | 프롬프트 토큰 |
| 비용 | 높음 | 낮음 |
| 효과 | 강력한 도메인 적응 | 비교적 가벼운 최적화 |
| 적합한 경우 | 전문 도메인 응답 필요 | 답변 형식/스타일 최적화 |
RLHF 동작 흐름
- LLM이 다양한 프롬프트에 대해 여러 응답 생성
- 인간이 응답을 평가하고 순위화(정확성, 관련성, 윤리)
- 순위 데이터로 보상 모델(인간 선호 점수 예측) 학습
- 보상 모델을 가이드 삼아 RL로 LLM 파인튜닝
DPO 동작 흐름
- 입력 프롬프트에 대해 LLM이 여러 출력 생성
- 인간 평가자가 쌍으로 비교해 선호 표시
- 선호 쌍(\(A_p\): 선호, \(A_{np}\): 비선호)으로 손실함수 구성. 선호 출력의 확률을 비선호 출력보다 높게 만든다
- 모든 선호 쌍에 대해 손실 최소화 방향으로 파라미터 최적화
평가 지표
| 지표 | 측정 대상 |
|---|---|
| BLEU(Bilingual Evaluation Understudy) | 기계 생성 텍스트가 참조 텍스트와 얼마나 일치하는가 |
| ROUGE(Recall-Oriented Understudy for Gisting Evaluation) | 요약, 번역 생성 텍스트의 품질 |
| 3H(Honesty / Harmlessness / Helpfulness) | 정직성, 무해성, 유용성. 학습 데이터의 편향과 유해성 점검 포함 |
배포 최적화
| 기법 | 핵심 아이디어 | 효과 |
|---|---|---|
| Quantization | 모델 가중치 정밀도 변경(FP32 → FP16/BF16 → Int8) | 메모리 최대 4배 절감. 정확도는 약간 손실 |
| Distillation | 소형 student 모델이 대형 teacher 모델의 동작을 모사하도록 학습 | teacher 성능에 근접하면서 계산 자원 절약 |
| Pruning | 0에 가까운 가중치 등 중요도가 낮은 파라미터 제거 | 모델 크기와 복잡도 감소 |
배포 옵션은 하드웨어 가용성, 비용, 데이터 거주(residency) 요건 등을 기준으로 선택한다.
| 배포 방식 | 장점 | 단점 | 적합한 경우 |
|---|---|---|---|
| Cloud | 빠른 시작, 관리형 서비스, 확장성 | 지속 비용, 데이터 외부 반출 우려 | 빠른 PoC, 유연한 확장 |
| On-premises | 데이터 통제, 내부망 운영 | 초기 투자, 운영 난이도 | 보안/규제 강한 기업 |
| Hybrid | 민감 데이터는 내부, 확장은 클라우드 | 구조 복잡 | 대기업, 규제 산업 |
추론 단계 개선
| 기법 | 핵심 아이디어 |
|---|---|
| RAG(Retrieval Augmented Generation) | 프롬프트와 함께 관련 문서를 모델에 제공 → 지식 컷오프와 실시간 정보 문제 해결, 재학습 없이 비용 절감 |
| Prompt engineering | 예시와 문맥을 프롬프트에 포함. zero-shot(예시 없이 지시만), few-shot(예시 몇 개 포함해 출력 포맷과 스타일 학습 유도) |
모니터링
배포 후에도 결과가 드리프트(drift)하거나 진부해지지 않는지 지속 모니터링한다.
| 모니터링 영역 | 주요 지표 |
|---|---|
| 인프라 | GPU 사용률, GPU 메모리, CPU, Memory |
| 모델 성능 | Latency, Tokens/sec, Throughput |
| 비용 | Cost per inference, GPU 사용 시간 |
| 품질 | 정확도, Hallucination 비율, 사용자 만족도 |
| 안전성 | 유해 응답, 정책 위반 응답 |
| Drift | 데이터/질문 패턴 변화, 답변 품질 저하 |
| RAG | 검색 정확도, 문서 freshness, vector index 상태 |
GenAI 배포 스택
인프라 계층(컴퓨트, 스토리지, 네트워킹)부터 오케스트레이션, 도구, 배포 계층까지 GenAI 배포 스택은 여러 층으로 구성된다.
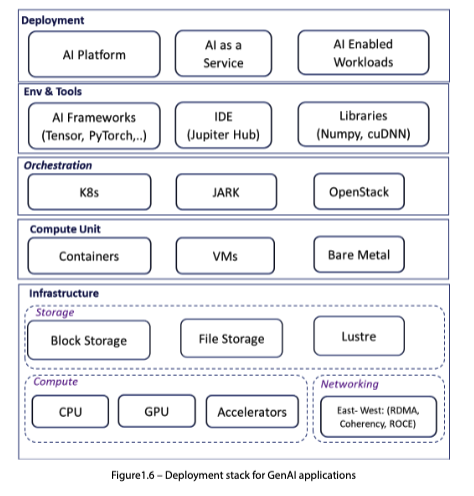
컴퓨트
| 종류 | 특징 |
|---|---|
| CPU | 범용. 추론에 사용 가능하지만 대형 LLM에는 한계 |
| GPU | 대규모 병렬 행렬 곱. 학습 워크로드에 주로 선호. 수십억 파라미터 LLM은 추론에도 GPU 필요 |
| 커스텀 가속기(AWS Inferentia/Trainium 등) | ML 전용으로 설계된 실리콘. 수학 연산에 고도로 최적화 |
네트워킹
LLM에서는 학습과 추론이 분산 시스템 문제가 되므로 네트워킹이 핵심 병목이 된다.
| 방향 | 의미 | 예시 |
|---|---|---|
| North-South | 데이터센터 외부 ↔ 내부 트래픽 | 사용자 HTTP 요청, 외부 API 호출 |
| East-West | 데이터센터 내부 서버/노드 간 트래픽 | GPU 간 gradient all-reduce, DB 복제 |
분산 학습(특히 data parallelism + tensor/pipeline parallelism)은 매 step마다 GPU 간 gradient 또는 activation 동기화가 필요하다. 모델이 클수록 동기화할 데이터도 커지므로, East-West 네트워킹 성능이 학습 효율을 좌우한다.
| 기술 | 특징 |
|---|---|
| RDMA(Remote Direct Memory Access) | NIC가 호스트 CPU/커널 개입 없이 원격 노드 메모리에 직접 R/W. 마이크로초 단위 지연 |
| InfiniBand | RDMA의 원조 네트워크. HPC/AI 클러스터 표준 |
| RoCE(RDMA over Converged Ethernet) | 일반 이더넷 위에서 RDMA. v2는 L3 라우팅 가능 |
| GPUDirect RDMA | NIC가 호스트 메모리 거치지 않고 GPU 메모리에 직접 접근 |
왜 70B 모델 학습에 840 GB 메모리가 필요한가?
학습 시에는 모델 가중치(weights)만 GPU에 올리면 되는 게 아니다. 가중치 하나당 최대 6개의 관련 값을 저장해야 한다.
| 요소 | 설명 |
|---|---|
| Model Weights | 학습된 기본 파라미터 |
| Gradients | 오차를 줄이기 위해 계산되는 변화량 |
| Optimizer States | Adam 등 옵티마이저가 학습 안정화를 위해 저장하는 값 |
| Activations | Forward pass 중간 계산 결과 |
| Temporary Variables | 학습 중 임시 계산값 |
정밀도별 가중치 하나당 메모리: FP32 = 24 bytes, FP16/BF16 = 12 bytes, FP8/INT8 = 6 bytes.
70B 모델을 FP16/BF16로 학습한다면: 70B × 12 bytes = 840 GB. NVIDIA H200(141 GB) 기준으로 완전 샤딩 가정 시 약 6장의 GPU가 필요하고, 실제로는 합리적인 학습 시간을 위해 더 많은 GPU가 필요하다.
이러한 분산 학습 환경에서는 Memory Coherence(시스템 내 모든 캐시가 최신 메모리 정보를 갖도록 보장하는 기술)와 RDMA가 함께 작동해 지연 시간을 줄이고 처리량을 높인다. NCCL all-reduce, GPUDirect RDMA 토폴로지 등 구체적인 내용은 후속 챕터(Ch 10)에서 다시 다룬다.
스토리지
책에서는 “block storage system, e.g., Amazon S3”라고 표기하고 있지만, S3는 오브젝트 스토리지다. 인터페이스 계층 기준으로 정리하면 다음과 같다.
| 종류 | 인터페이스 단위 | 예시 |
|---|---|---|
| 블록 스토리지(Block) | 고정 크기 블록(512 B ~ 64 KB) | AWS EBS, NVMe-oF |
| 파일 스토리지(File) | 파일, 디렉터리 | NFS, AWS EFS, Lustre |
| 오브젝트 스토리지(Object) | 객체(key + value + metadata) | AWS S3, GCS |
물리적으로 모든 스토리지는 결국 블록 디바이스(SSD/HDD) 위에서 동작하지만, 소비자가 보는 추상화 수준이 다르다. 블록은 raw 디바이스(/dev/sda), 파일은 이미 제공되는 마운트 포인트(/mnt/data), 오브젝트는 HTTP REST API로 접근하는 key-value 저장소다.
GenAI에서 특히 주목할 파일 시스템으로 Lustre(러스터)가 있다. HPC 분야에서 오래 사용된 대규모 병렬 파일 시스템으로, 리소스를 추가해 수평 확장할 수 있다. 대규모 학습 데이터셋 병렬 읽기, 분산 학습 시 여러 GPU 노드의 동시 데이터 접근, 체크포인트 저장 등에 유용하다.
데이터베이스 선택도 고려해야 한다.
| DB 유형 | 적합한 데이터 |
|---|---|
| SQL | 테이블 구조가 명확한 정형 데이터 |
| NoSQL | 이미지, 비디오, JSON, 로그 등 비정형 데이터 |
| Vector DB | Embedding 벡터 검색(Milvus, Pinecone, Elasticsearch). RAG 파이프라인의 핵심 |
컴퓨트 단위와 오케스트레이션
| 단위 | 특징 |
|---|---|
| 컨테이너 | 의존성을 이미지로 패키징. 여러 컨테이너가 노드/커널 공유 → VM 대비 자원 효율 우수 |
| 가상머신(VM) | 각 VM이 별도 OS/런타임 필요. 하이퍼바이저로 물리 서버 공유 |
| 베어메탈 | 단일 테넌트에 전용 할당된 물리 서버 |
| 오케스트레이션 플랫폼 | 대상 | 비고 |
|---|---|---|
| Kubernetes | 컨테이너 | 사실상 표준. OpenAI, Anthropic 등이 GenAI 워크로드에 사용 |
| OpenStack | VM | 오픈소스 |
Kubernetes가 GenAI에 중요한 이유:
| K8s 기능 | GenAI 운영 의미 |
|---|---|
| Scheduling | GPU가 있는 노드에 모델 Pod 배치 |
| Autoscaling | 요청량 증가 시 Pod/Node 확장 |
| Self-healing | 장애난 Pod 자동 재시작 |
| PVC | 모델 파일, 데이터셋, 벡터DB 저장 |
| Operator | GPU Operator, KServe, Ray Operator 등 |
프레임워크와 엔드포인트
| 영역 | 옵션 |
|---|---|
| AI 프레임워크 | PyTorch(FSDP, Fully Sharded Data Parallel), TensorFlow distributed. 다수 GPU에 파라미터와 학습 데이터 분산 |
| IDE/라이브러리 | JupyterHub, cuDNN, NumPy, pandas 등 |
| 엔드포인트 | API/플랫폼/워크로드. 확장성, 비용, 지연, 재해복구 고려 |
GenAI 유즈 케이스
GenAI는 “문서 작성/요약/추천/상담/설계/분석/콘텐츠 생성”처럼 지식 노동이 들어가는 거의 모든 산업에 적용될 수 있다. 산업마다 구체적인 활용 방식은 다르지만, 기술적으로 보면 대부분 “사용자 입력 → 데이터 검색/분석 → LLM 생성 → 검증/전달” 흐름이다.
| 산업 | 대표 유즈 케이스 |
|---|---|
| Retail/E-commerce | 제품 디자인, 개인화 추천(자연어로 상품 검색), 리뷰 요약 |
| Finance | 재무 보고서/분석 자동 생성, 챗봇 기반 고객 서비스 |
| Healthcare | 신약 후보 발굴(약물-표적 상호작용 예측), 개인 맞춤 의료(환자 프로필 기반 치료 반응 예측) |
| Education | 사용자 여정 기반 개인화 학습 경로, 언어 학습 |
| Legal | 법률 문서 검토/요약, 계약서 생성, 고객 상담 챗봇 |
| Entertainment | 콘텐츠 제작(스크립트, 음악, 아트워크), VR 환경 생성, 개인화 추천 |
정리
- AI와 GenAI의 차이: AI는 인간 지능을 모사하는 기술을 포괄하는 매우 넓은 용어다. GenAI는 그 안에서 텍스트, 이미지, 동영상 등 새 콘텐츠 생성에 특화된 분야다
- ML의 진화: CNN/RNN에서 Transformer로. Transformer는 시퀀스 처리의 효율성을 비약적으로 끌어올려 NLP 중심의 GenAI 응용의 기반이 됐다
- GenAI 프로젝트 라이프사이클: 비즈니스 목표와 KPI → FM 선택 → 학습/파인튜닝 → 평가 → 배포 → 모니터링
- 다양한 산업 적용: 리테일/이커머스(제품 디자인, 개인화 추천), 금융(재무 분석, 고객 응대), 헬스케어(신약 개발), 교육(개인화 학습), 법률(문서 요약), 엔터테인먼트(콘텐츠 제작, VR) 등
참고 링크
- Kubernetes for Generative AI Solutions - GitHub
- Attention Is All You Need (Vaswani et al. 2017)
- BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al. 2018)
- Language Models are Few-Shot Learners (GPT-3, Brown et al. 2020)
- LoRA: Low-Rank Adaptation of Large Language Models (Hu et al. 2021)

댓글남기기