
[GenAI] GenAI on K8s: 2. 컨테이너, K8s 아키텍처, GenAI 워크로드 통합
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 2장의 학습 내용을 바탕으로 합니다
TL;DR
- 컨테이너는 Linux namespace + cgroups로 프로세스를 격리한다. VM 대비 빠른 시작/정지, 호스트 커널 공유로 자원 효율이 높다
- GenAI 워크로드에 컨테이너를 쓰는 핵심 이유: ML 프레임워크·GPU 드라이버 등 복잡한 의존성을 이미지 하나로 고정
- K8s 아키텍처: Control Plane(apiserver, etcd, scheduler, controller-manager) + Data Plane(kubelet, kube-proxy, container runtime)
- K8s가 GenAI에 적합한 이유: GPU 스케줄링, HPA/VPA/CA 확장성, Operator/CRD 확장성, HA + 체크포인팅 결합
- 실습: Llama 2 7B(Q2_K 양자화) 컨테이너 이미지 빌드 → 로컬 CPU 추론 ~34초/340토큰
컨테이너 이해
이전 글에서 GenAI 배포 스택의 오케스트레이션 계층으로 Kubernetes를 언급했다. 이번 글에서는 그 기반이 되는 컨테이너(Container) 기술부터 출발한다.
추상화 수준: Physical → VM → Container
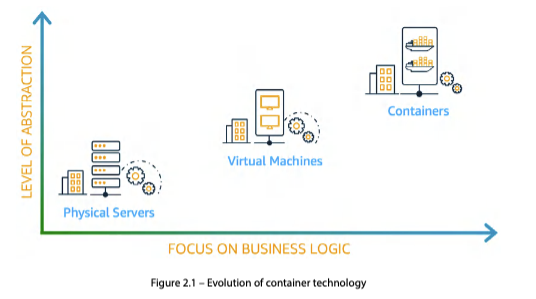
| 구분 | 추상화 수준 | 장점 | 단점 |
|---|---|---|---|
| Physical Server | 가장 낮음. 하드웨어를 직접 노출 | 성능 최적화 여지 큼 | 수동 설정, 자원 비효율 |
| VM | 하이퍼바이저로 하드웨어 추상화 | 한 서버에 여러 VM, 격리·보안 향상 | 부팅 느림, OS 오버헤드 큼 |
| Container | OS 커널을 공유, 가장 높은 추상화 | 빠른 시작·종료, 비즈니스 로직 집중 | 동일 커널 의존 |
VM은 매번 게스트 OS를 부팅해야 한다(가상 BIOS/UEFI → 부트로더 → 커널 초기화 → systemd 서비스 기동). 컨테이너는 호스트 커널을 공유하므로 이 과정 없이 바로 프로세스를 exec한다. 일반적으로 VM cold boot은 30초~수 분, 컨테이너 시작은 100ms~수 초 수준이다.
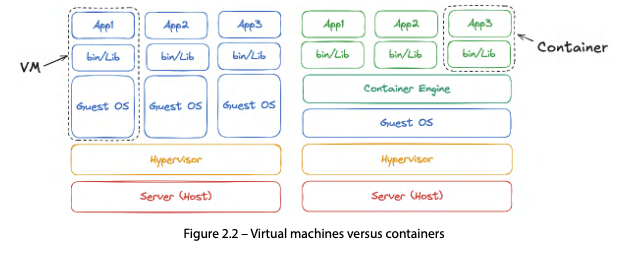
커널 기반 격리 메커니즘
컨테이너 기술은 Linux 커널의 두 가지 기능에 의존한다.
| 기술 | 역할 |
|---|---|
| Linux Namespace | OS 자원(네트워크, 파일시스템 등)을 파티셔닝해 프로세스 그룹마다 다른 자원 뷰를 제공 |
| cgroups(Control Groups) | CPU/메모리/네트워크 등 자원 사용량을 격리하고 한도를 강제 |
컨테이너 용어 정리
| 용어 | 정의 | 예시 |
|---|---|---|
| Container Runtime | 컨테이너를 생성·시작·종료하는 호스트 프로세스 | containerd, CRI-O |
| Container Image | 코드·런타임·라이브러리·환경변수·설정을 모두 담은 실행 가능 패키지 | nginx:latest |
| Container Registry | 이미지를 저장·배포하는 도구 | Docker Hub, Amazon ECR, Harbor |
| Container | 런타임이 이미지를 기반으로 만든 실행 중인 프로세스 인스턴스 | — |
컨테이너 이미지는 4가지 특성을 갖는다.
| 특성 | 의미 |
|---|---|
| Self-contained | 소프트웨어 실행에 필요한 모든 것을 자기 안에 포함 |
| Immutable | 읽기 전용. 변경하려면 새 이미지를 빌드해야 함 |
| Layered | 레이어로 구성. 공통 레이어를 여러 이미지가 공유해 효율적 |
| Portable | 컨테이너 런타임만 있으면 어디서든 실행 |
Docker 아키텍처
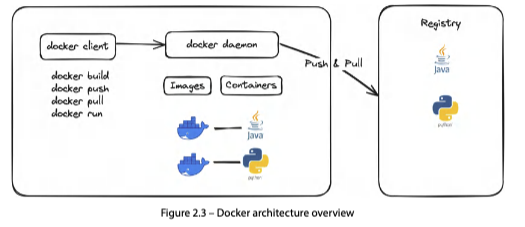
Docker는 전형적인 클라이언트-서버 구조다.
| 구성 요소 | 역할 |
|---|---|
| Docker CLI(Client) | 사용자가 daemon과 통신하는 인터페이스 |
| Docker Daemon(Server) | 이미지 생성·관리, 컨테이너 실행, 네트워킹·스토리지 셋업, 레지스트리 push/pull |
| Container Registry | 이미지 저장소. daemon이 push/pull |
GenAI 워크로드에 컨테이너를 쓰는 이유
도전 과제
- ML 프레임워크가 복잡하고 계속 진화한다(PyTorch, TensorFlow, JAX 등)
- GPU 하드웨어 생태계가 다양하다(NVIDIA, 클라우드 자체 가속기 등)
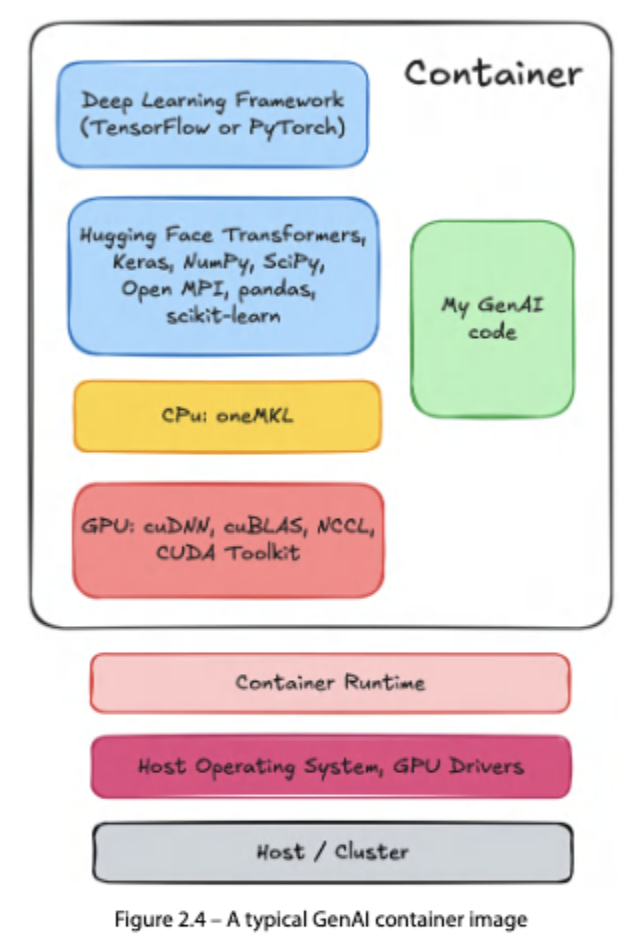
GenAI 컨테이너 이미지는 크게 두 계층으로 나뉜다. 상단에는 DL 프레임워크와 사용자 코드 등 SW 라이브러리, 하단에는 호스트의 GPU/가속기와 통신하는 하드웨어 종속 라이브러리가 위치한다.
컨테이너의 이점
| 이점 | 내용 |
|---|---|
| 의존성 관리 | 모델·프레임워크·드라이버 조합을 이미지 하나로 고정 |
| 버전 관리·롤백 | 모델 버전마다 이미지를 따로 두어 추적·롤백 용이 |
| 보안 | 데이터 접근 정책 강제, 공격 표면 최소화, 호스트와 격리 |
| 빠른 라이프사이클 | VM 대비 수십~수백 배 빠른 시작/정지 → 스케일 응답 시간 단축 |
책에서는 “Resource access — fine-grained control”도 컨테이너 이점으로 분류하지만, 이는 오케스트레이터(K8s)의 스케줄링 기능이 더 크게 기여하는 부분이다. 컨테이너 자체의 핵심 고유 이점은 의존성 스택 격리로 보는 편이 정확하다. 같은 호스트에 PyTorch 2.0 + CUDA 11.8 환경과 PyTorch 2.4 + CUDA 12.4 환경을 동시에 격리 실행할 수 있다는 점이 GenAI 워크로드에서 가장 실질적인 가치다.
실습: GenAI 컨테이너 이미지 빌드
Llama 2 7B 모델을 컨테이너로 패키징하고 Flask 기반 추론 엔드포인트를 띄우는 실습이다.
구성 요소
| 컴포넌트 | 설명 |
|---|---|
| HuggingFace | 사전학습 모델 허브. TensorFlow / PyTorch / ONNX 지원 |
| llama.cpp | Llama 모델을 GPU 없이 다양한 플랫폼에서 효율적으로 실행하기 위한 오픈소스 추론 엔진. GGUF 포맷 양자화로 모델 크기를 축소 |
| Flask API | :5000/predict POST 엔드포인트. JSON으로 prompt/system message를 받아 Llama 출력 반환 |
Docker 이미지 빌드 및 실행
Dockerfile 구성:
FROM python
WORKDIR /app
EXPOSE 5000
RUN pip install --no-cache-dir flask llama-cpp-python
COPY . /app
CMD ["python", "app.py"]
COPY . /app이 모델 GGUF 파일(2.83 GB)까지 통째로 이미지에 포함시킨다. 별도 볼륨 마운트 없이 동작하지만, 결과적으로 이미지가 4.16 GB로 커진다.
docker build -t my-llama .
docker run -p 8000:5000 my-llama
빌드 로그 발췌
[+] Building 105.8s (6/8) docker:desktop-linux
=> [1/4] FROM docker.io/library/python:latest@sha256:6928... 51.3s
=> [internal] load build context
=> => transferring context: 2.87GB 17.3s
=> [2/4] WORKDIR /app 0.7s
=> [3/4] RUN pip install --no-cache-dir flask llama-cpp-python 92.0s
=> [4/4] COPY . /app
=> exporting to image 6.6s
=> => naming to docker.io/library/my-llama
추론 결과 및 관찰
curl -X POST http://localhost:8000/predict \
-H "Content-Type: application/json" \
-d '{"prompt":"Will AIs replace humans?","sys_msg":"You are a helpful assistant."}'
| 항목 | 값 |
|---|---|
| 모델 | llama-2-7b-chat.Q2_K.gguf (2-bit 양자화, 2.83 GB) |
| 이미지 크기 | 4.16 GB |
| 빌드 시간 | ~106초 |
| 추론 응답 시간 | ~34초 (340 토큰 생성, 로컬 CPU) |
| 처리량 | ~10 토큰/초 |
로컬 CPU 추론이 느린 이유는 세 가지가 복합적으로 작용한다.
| 요인 | 영향 |
|---|---|
| 하드웨어(가장 큼) | 클라우드 LLM은 H100/H200 GPU 추론. GPU 메모리 대역폭이 CPU 대비 10-20배 |
| 스트리밍 부재 | ChatGPT/Claude는 SSE/WebSocket으로 토큰 단위 푸시 → 즉시 응답 체감. Flask 호출은 모든 토큰 생성 완료 후 반환 |
| 양자화 수준 | Q2_K는 크기 축소 효과는 있지만 CPU의 근본 한계는 넘지 못함 |
GPU + 적절한 양자화(Q4_K_M) + 스트리밍 도입 시 같은 7B 모델로 50-100 토큰/초가 가능하다.
발견한 버그: max_tokens 하드코딩
책의 app.py 11행이 max_tokens=1000으로 하드코딩되어 있어, 요청 body의 max_tokens 값이 무시된다.
# 원본 (책 예제) — 요청 body 값 무시
response = model(prompt, max_tokens=1000)
# 수정 — 요청 body에서 읽고, 없으면 기본값 1000
response = model(prompt, max_tokens=data.get('max_tokens', 1000))
라이브러리 시그니처에 노출된 파라미터 중 일부만 받는 코드는 silent failure 위험이 있다. API 응답의 usage.completion_tokens가 요청 의도와 맞는지 확인하는 습관이 필요하다.
컨테이너 오케스트레이션
로컬에서 컨테이너 한두 개를 띄우는 건 쉽지만, 수백~수천 대의 노드에 걸쳐 가용성·확장성·로드밸런싱·자원 할당·자동 배포를 보장하려면 오케스트레이션(orchestration) 계층이 필요하다.
오케스트레이터가 제공하는 기능
| 기능 | 설명 |
|---|---|
| High Availability | 헬스체크 → 실패 컨테이너 자동 재시작/교체, 원하는 인스턴스 수 유지 |
| Scaling | 부하에 따라 컨테이너 자동 생성·제거, 하부 컴퓨트도 함께 확장 |
| Automated Deployments | 멀티 호스트 배포·롤백 자동화. canary, blue/green 전략 지원 |
| Load Balancing | 내장 LB로 트래픽을 여러 인스턴스에 분산 |
| Service Discovery | ephemeral 컨테이너의 엔드포인트를 동적으로 발견 |
| Observability | 모니터링·로깅 도구와 통합 |
| Resource Management & Scheduling | CPU/메모리/GPU 할당·한도 강제. 특수 하드웨어 요구를 가진 워크로드를 적절한 노드에 배치 |
이 중 다중 호스트 스케줄링과 서비스 디스커버리가 가장 오케스트레이터 고유한 기능이다. 나머지(HA, Scaling, Deployments 등)는 “단일 컨테이너 → 다호스트 시스템”으로 규모가 바뀌면서 필요해지는 기능들로, 컨테이너 단독으로도 원리적으로는 가능하지만 수동으로는 비현실적인 것들이다.
주요 오케스트레이터
| 분류 | 제품 |
|---|---|
| 비-K8s 오케스트레이터 | Amazon ECS, Azure Container Apps, Docker Swarm, Apache Mesos |
| Kubernetes(오픈소스) | Kubernetes |
| Managed Kubernetes | Amazon EKS, Google GKE, Azure AKS, Red Hat OpenShift |
쿠버네티스 아키텍처
K8s는 2014년 Google 엔지니어 Joe Beda, Brendan Burns, Craig McLuckie가 시작한 오픈소스 컨테이너 오케스트레이션 플랫폼이다. 현재는 CNCF(Cloud Native Computing Foundation) 가 유지보수한다.
- Linux 다음으로 세계 2위 규모의 오픈소스 프로젝트
- Fortune 100 기업의 71%가 사용
- Gartner 전망: 2027년까지 글로벌 조직의 90% 이상이 컨테이너화된 앱을 프로덕션에서 운영
K8s가 사실상 표준이 된 이유
| 요인 | 설명 |
|---|---|
| Rich Community & Ecosystem | 77K+ contributor, 44개국, 8K+ 기업 참여 |
| Comprehensive Features | 자동 롤아웃·롤백, self-healing, 수평 스케일, 서비스 디스커버리, 로드밸런싱 |
| Portability | 온프레미스, 퍼블릭/프라이빗/하이브리드 클라우드, 엣지에서 일관 실행 |
| Declarative Configuration | YAML/JSON으로 desired state 선언 → 컨트롤러가 actual state와 reconcile |
| Extensibility | 가장 결정적. 모듈러 아키텍처 + 잘 정의된 API → 업스트림 수정 없이 기능 확장 가능 |
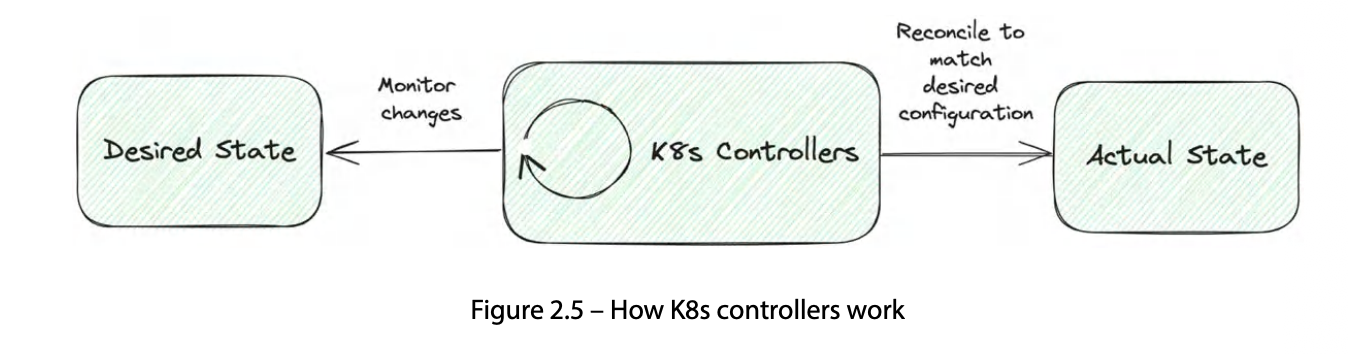
K8s의 핵심 동작 모델은 선언적 reconciliation이다. 사용자가 desired state를 선언하면 컨트롤러가 지속적으로 actual state와 비교해 차이를 해소한다.
K8s 클러스터 구조
K8s 클러스터는 두 종류의 노드로 구성된다.
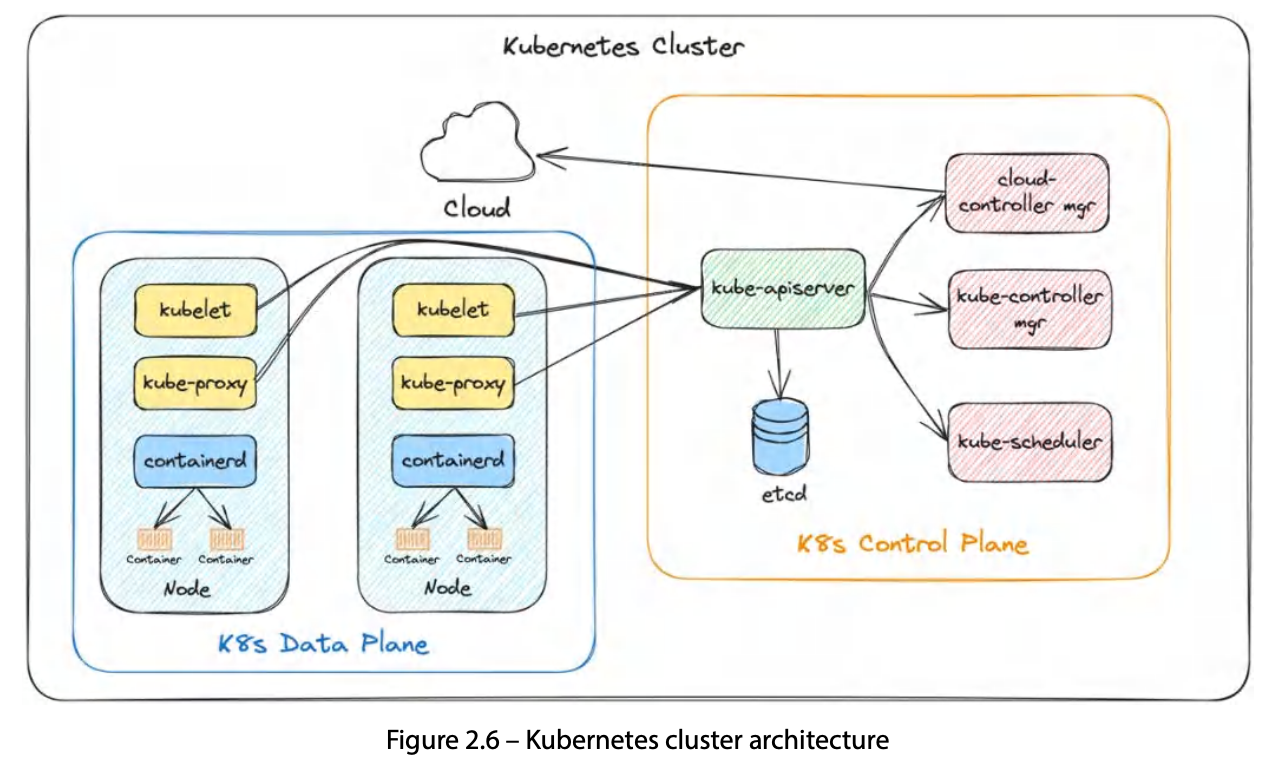
| 영역 | 역할 | 주요 컴포넌트 |
|---|---|---|
| Control Plane | 클러스터 두뇌. 상태 관리·스케줄링·API 처리 | kube-apiserver, etcd, kube-controller-manager, kube-scheduler, cloud-controller-manager |
| Data Plane(Worker Nodes) | 실제 컨테이너 실행 | kubelet, kube-proxy, Container Runtime, CNI plugin |
Control Plane 컴포넌트
| 컴포넌트 | 역할 |
|---|---|
| kube-apiserver | 클러스터의 frontend. K8s API를 노출하고 etcd와 통신해 상태를 저장한다. authn/authz·validation 처리. 모든 컴포넌트가 이를 통해 통신 |
| etcd | 분산 key-value 저장소. 모든 K8s 객체의 설정·상태를 저장 → 정기 백업 필수 |
| kube-controller-manager | 컨트롤러들을 관리. Deployment 컨트롤러가 Deployment 객체를 watch하고 Pod 업데이트 수행 |
| kube-scheduler | Pod를 worker node에 배치. nodeSelector·affinity·topology spread·resource 가용성 고려. 배치 불가 시 Pod를 Pending 상태로 둠 |
| cloud-controller-manager | 클라우드 API 호출 게이트웨이. Node controller(노드 헬스·추가/제거), Service controller(클라우드 LB 생성·수정·삭제) 등 포함 |
Data Plane 컴포넌트
| 컴포넌트 | 역할 |
|---|---|
| kubelet | 모든 워커 노드의 에이전트. kube-apiserver 지시를 받아 컨테이너를 실행하고 상태를 보고. Container Runtime·CNI·CSI와 상호작용 |
| kube-proxy | 워커 노드의 네트워크 프록시. K8s Service 개념을 구현. iptables/IPVS로 라우팅 규칙 유지 |
| Container Runtime | 컨테이너 라이프사이클 관리. containerd가 사실상 표준(CRI-O도 지원) |
애드온 컴포넌트
프로덕션 운영에는 코어 외 애드온 설치가 필수다.
| 애드온 | 역할 | 대표 구현체 |
|---|---|---|
| CNI plugin | Pod에 IP 할당, Pod 간 통신 | Cilium, Calico, Amazon VPC CNI |
| CSI plugin | Pod에 영속 볼륨 제공·라이프사이클 관리 | Amazon EBS CSI Driver, Portworx CSI |
| CoreDNS | 클러스터 내 DNS 해상도 | CoreDNS(기본 탑재) |
| Monitoring plugins | 로그/메트릭/트레이스 수집 | Prometheus, CloudWatch, Datadog |
| Device plugins | 특수 하드웨어(GPU 등)를 kubelet/control plane에 광고 → 스케줄링 의사결정에 활용 | NVIDIA Device Plugin |
K8s가 GenAI에 적합한 이유
GenAI 운영의 도전 과제
| 과제 | 내용 |
|---|---|
| Computational Requirements | 학습·추론에 GPU/TPU/가속기 등 대규모 컴퓨트 필요 |
| Scalability | 수요 증가에 따른 매끄러운 스케일링 — 성능·비용 양쪽을 잡아야 함 |
| Observability | 비즈니스 KPI + 시스템 헬스 동시 모니터링 |
| Data Management | 대규모 데이터 준비·보안·관리가 모델 품질의 핵심 |
| Deployment Complexity | 커스텀 프레임워크·플러그인·의존성으로 배포가 복잡 |
K8s의 대응
| 강점 | 설명 |
|---|---|
| Efficient Resource Management | kube-scheduler가 Pod를 노드에 배치. 커스텀 스케줄러로 AWS Trainium·Inferentia 같은 가속기에 워크로드 배치 가능 |
| Seamless Scalability | HPA(Pod 개수) + VPA(CPU/메모리 limit) + Cluster Autoscaler(노드 수) 조합 |
| Extensibility | 업스트림 수정 없이 확장. Kubeflow, PyTorch/TensorFlow용 커스텀 오퍼레이터, GPU 장치 플러그인 |
| Security | RBAC, K8s Secrets, 네트워크 정책, 감사 로그, Pod Security Standards(PSS) |
| High Availability & Fault Tolerance | FM 학습은 수주~수개월 소요 → 노드/Pod 장애 시 자동 재스케줄. AI 프레임워크의 체크포인팅과 결합 |
| Rich Ecosystem | Kubeflow, MLflow, KServe, Seldon, RayServe 등 — CNCF Cloud Native AI Whitepaper 참고 |
위 6개 강점은 GenAI 운영의 5대 과제와 거의 1:1로 대응한다. K8s가 GenAI 인프라의 de facto 표준이 된 이유다.
정리
| 영역 | 핵심 |
|---|---|
| 컨테이너 | namespace + cgroups 격리. VM 대비 빠른 시작, 의존성 포함, portable |
| GenAI + 컨테이너 | 복잡한 ML 의존성을 이미지로 고정. GPU 드라이버 호환은 여전히 과제(NVIDIA Container Toolkit 필요) |
| 오케스트레이션 | 다호스트 스케줄링, 서비스 디스커버리, 자동 스케일 — 단일 컨테이너로는 불가능 |
| K8s 아키텍처 | Control Plane(apiserver/etcd/scheduler/controller-manager) + Data Plane(kubelet/kube-proxy/runtime) |
| K8s + GenAI | GPU 스케줄링, HPA/VPA/CA, Operator 확장, HA + 체크포인팅 |
참고 링크
- Kubernetes for Generative AI Solutions - GitHub
- Kubernetes 공식 문서
- CNCF Cloud Native AI Whitepaper
- llama.cpp - GitHub

댓글남기기