
[GenAI] GenAI on K8s: 10.1 - GPU 자원 개요와 K8s 할당 메커니즘
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 10장의 학습 내용을 바탕으로 합니다
K8s에서 GenAI 워크로드를 배포할 때 GPU 효율을 극대화하는 방법을 다룬다. GPU는 비싸고, 대부분 저활용(underutilized) 상태로 방치된다. 이번 글에서는 GPU·커스텀 가속기의 개요와 K8s에서 GPU 자원을 할당하는 메커니즘을 정리한다.
TL;DR
- GPU는 massively parallel processing(MPP)으로 딥러닝 행렬곱에 압도적이지만, K8s가 네이티브로 인식하지 못해 device plugin이 필요하다
- device plugin은 DaemonSet으로 배포되어 kubelet에 GPU를 등록하고, NFD/GFD가 하드웨어 정보를 노드 라벨로 표면화한다
- GPU는 extended resource로 정수 단위로 할당되고,
limits가 필수고,request==limit강제된다 — CPU·메모리와 근본적으로 다른 이산(discrete) 장치다 - GPU “쪼개 쓰기”는 overcommit이 아니라 광고 단위를 재정의하는 별개 메커니즘(MIG / MPS / time-slicing)이다
GPU와 커스텀 가속기
GenAI 워크로드에서 컴퓨팅 자원은 크게 세 가지로 나뉜다.
| 컴퓨팅 | 특징 | 적합 워크로드 | K8s 인식 |
|---|---|---|---|
| CPU | 소수 코어 × 높은 클럭, 분기·순차 로직에 강함 | 범용 애플리케이션, 전처리, 서빙 로직 | 네이티브 (cpu) |
| GPU | 수천 코어 × 낮은 클럭, 동일 연산을 대량 데이터에 병렬 적용(MPP) | 행렬곱 중심의 학습·추론, 이미지·영상 처리 | 네이티브 아님 → device plugin 필요 |
| 커스텀 가속기 | AI/ML 연산만을 위해 설계된 ASIC | 대규모 학습·추론(특정 벤더 SDK 필수) | 네이티브 아님 → device plugin 필요 |
MPP(Massively Parallel Processing), SIMD, SIMT: GPU의 실행 모델은 SIMT(Single Instruction, Multiple Threads)다. 수천 개의 코어가 동일한 명령을 서로 다른 데이터에 동시에 적용한다. 행렬곱을 예로 들면, 결과 행렬의 각 원소 계산이 서로 독립적이므로 수천 개의 스레드에 분배해 한 번에 처리할 수 있다.
CPU도 병렬 처리를 한다. 다만 방식이 다르다. CPU는 SIMD(Single Instruction, Multiple Data) — SSE, AVX, AVX-512 같은 벡터 명령으로, 하나의 코어 안에서 고정 폭(예: 8개 float) 데이터 레인에 같은 연산을 한 번에 적용한다. 코어 수는 GPU 대비 소수(수십~수백)지만 각 코어가 강하고, 분기·캐시·out-of-order 실행에 최적화되어 있다. GPU SIMT는 수천 개의 단순 코어가 수천 개의 스레드를 warp(32개) 단위로 묶어 동시 실행하는 모델이다. 한 줄로 정리하면 CPU SIMD는 “코어 하나가 벡터 레인 여러 개”, GPU SIMT는 “코어 수천 개가 각자 다른 데이터”다.
반면 분기(branch)가 많은 순차 로직은 스레드 간 실행 경로가 갈려 GPU의 강점인 warp 단위 병렬성을 해친다 — 이런 작업은 CPU가 낫다.
커스텀 가속기
GPU가 아닌, AI/ML 전용으로 설계된 커스텀 가속기(ASIC)도 있다.
- AWS Inferentia — 추론 최적화 칩. Inf1/Inf2 인스턴스
- AWS Trainium — 학습 최적화 칩. Trn1/Trn2 인스턴스
- Google TPU — TensorFlow/JAX 학습·추론
- FPGA(Field-Programmable Gate Array, 현장 재구성 가능 게이트 배열) — 회로 배선을 소프트웨어로 바꿀 수 있는 재구성 가능 가속기. 벤더 중립적 개념이며, Xilinx(AMD)·Intel(Altera) 등 여러 제조사 제품이 있다
- ASIC(Application-Specific Integrated Circuit, 용도 특화 집적회로) — 특정 연산만을 위해 설계된 맞춤 칩. 벤더 중립적 개념이며, 위 TPU·Trainium·Inferentia도 모두 ASIC의 한 종류다
GPU vs 커스텀 가속기(ASIC) 비교
구분 GPU 커스텀 가속기(ASIC) 출발 그래픽 렌더링 → GPGPU로 범용 병렬 컴퓨팅 확장 처음부터 AI/ML 연산 전용으로 설계 그래픽 기능 있음 (렌더링, 디스플레이 출력) 없음 AI 가속 Tensor Core로 행렬곱 가속 (범용 코어와 공존) systolic array 등 AI 연산 전용 데이터패스 유연성 CUDA/OpenCL로 다양한 알고리즘 실행 가능 특정 프레임워크·SDK에 종속 효율 범용성 대가로 AI 전용 대비 전력·면적 오버헤드 특정 워크로드에서 와트당 처리량 우위 GPU는 그래픽에서 출발해 범용 병렬 컴퓨팅(GPGPU)으로 진화했고, Tensor Core가 추가되며 AI 가속기 역할을 겸하게 되었다. 반면 커스텀 가속기는 처음부터 AI 연산만을 위해 설계된 ASIC으로, systolic array 같은 전용 데이터패스를 통해 특정 워크로드에서 와트당 처리량을 극대화한다.
AWS Trainium 라인업은 다음과 같다.
| 칩 | 인스턴스 | 특징 |
|---|---|---|
| Trainium (Trn1) | Trn1 | NeuronCore-v2 탑재, 학습용 최적화. BF16/FP16 지원 |
| Trainium2 (Trn2 / UltraServers) | Trn2, UltraServers | NeuronCore-v3, Trn1 대비 4배 성능. 대규모 학습용 UltraServer 구성 가능 |
NeuronSDK: Trainium/Inferentia는 GPU와 ISA(명령어 집합)가 다르기 때문에 CUDA를 쓸 수 없다. 대신 AWS가 제공하는 Neuron SDK(컴파일러 + 런타임 + 라이브러리)를 통해 PyTorch·TensorFlow 모델을 Neuron 디바이스용으로 컴파일하고 실행한다. SDK가 프레임워크 수준의 호환 레이어를 제공하므로, 코드 변경을 최소화하면서 커스텀 가속기를 활용할 수 있다.
용어 정리
용어 풀네임 설명 SIMD Single Instruction, Multiple Data 하나의 명령이 여러 데이터에 동시 적용. CPU의 벡터 확장(AVX 등)이 대표적 SIMT Single Instruction, Multiple Threads SIMD의 GPU 확장. Warp(32스레드) 단위로 같은 명령을 실행하되, 각 스레드가 독립 레지스터·PC를 가짐 GPGPU General-Purpose computing on GPU 그래픽 외 범용 병렬 연산에 GPU를 사용하는 것. CUDA가 대표 프레임워크 FPGA Field-Programmable Gate Array 회로를 소프트웨어로 재구성할 수 있는 칩. 벤더 중립적 기술 분류 ASIC Application-Specific Integrated Circuit 특정 용도 전용 집적회로. AI 가속기(TPU, Trainium)가 이에 해당
K8s에서의 GPU 자원 할당
K8s는 CPU·메모리를 네이티브로 인식하지만, GPU·커스텀 가속기는 그렇지 않다. 이들을 사용하려면 device plugin과 device driver 두 가지가 모두 필요하다.
| 가속기 | device plugin | resource name |
|---|---|---|
| NVIDIA GPU | NVIDIA device plugin | nvidia.com/gpu |
| AWS Inferentia / Trainium | Neuron device plugin | aws.amazon.com/neuroncore |
| Google TPU | TPU device plugin | google.com/tpu |
드라이버는 노드 OS에 미리 설치되어야 한다. EKS처럼 관리형 서비스에서는 accelerated AMI에 NVIDIA 드라이버·CUDA toolkit·Neuron 드라이버 등이 사전 설치되어 있어 별도 설정 없이 사용할 수 있다.
device plugin 동작 흐름
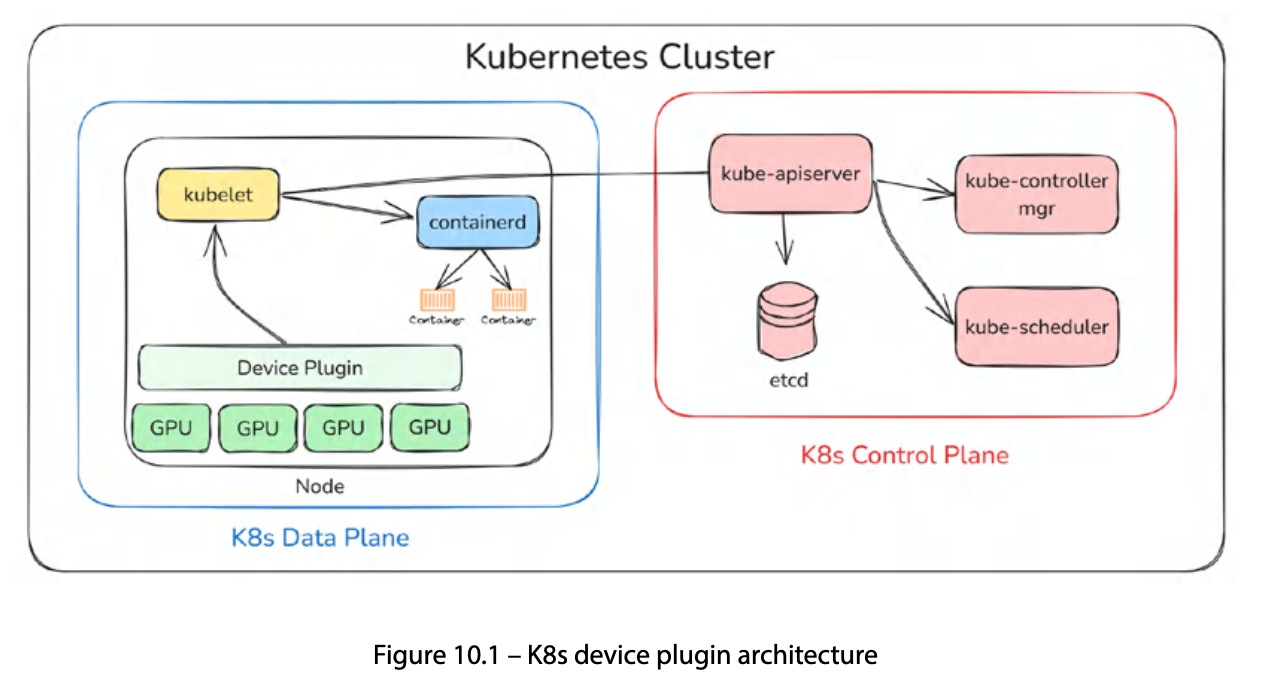
device plugin은 다음 6단계로 동작한다.
- DaemonSet 배포: device plugin이 DaemonSet으로 각 노드에 배포된다
- 벤더별 초기화 + device ready 확인: 플러그인이 해당 벤더의 장치(GPU 등)를 탐색하고 사용 가능 상태를 확인한다
- kubelet에 등록 + custom resource 선언: 플러그인이 kubelet의 Registration gRPC 서비스에 자신을 등록하고, 관리할 리소스 이름(
nvidia.com/gpu등)을 선언한다 - device 목록 제공 → kubelet이 node status 갱신 → API server에 광고(advertise): 플러그인이
ListAndWatchgRPC를 통해 사용 가능한 device 목록과 상태를 kubelet에 스트리밍한다. kubelet은 이를node.status.capacity/allocatable에 반영하고, API server가 이 정보를 스케줄러에 노출한다 - Pod 스케줄 시 kubelet이 plugin에 할당 요청: 스케줄러가 해당 노드에 Pod를 배치하면, kubelet이
AllocategRPC로 플러그인에 device 할당을 요청한다. 플러그인은 환경변수·마운트 등을 반환하고, kubelet이 이를 컨테이너 설정에 주입한다 - device health 지속 모니터링: 플러그인이 device 상태를 지속적으로 모니터링하고, unhealthy 상태가 감지되면 kubelet에 알린다
다음과 같이 노드에 광고된 GPU 수를 확인할 수 있다.
kubectl get node -o json | jq '.items[] | {name: .metadata.name, capacity: .status.capacity}'
출력 예시
{
"name": "gpu-worker-1",
"capacity": {
"cpu": "8",
"ephemeral-storage": "104845292Ki",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "32874496Ki",
"nvidia.com/gpu": "4",
"pods": "110"
}
}
참고: device plugin의 광고
광고(advertise)란 device plugin이 kubelet을 통해 API server에 “이 노드에
nvidia.com/gpu4개가 있다”고 알리는 과정이다. 스케줄러는 이 광고된 수량을 기반으로 Pod 배치 여부를 결정한다. device plugin은 gRPC로 kubelet과 통신하며, 핵심 RPC는ListAndWatch(device 목록·상태 스트리밍)와Allocate(device 할당 요청 처리)다.NVIDIA 환경에서는 device plugin이
Allocate시NVIDIA_VISIBLE_DEVICES환경변수로 할당할 GPU ID를 지정하고, NVIDIA Container Runtime이 이를 받아 실제 GPU 장치를 컨테이너에 주입한다. 이 흐름에 대해서는 이전 글을 참고하자.
노드·플러그인 프로비저닝
EKS에서 NVIDIA device plugin과 GPU 노드 그룹을 프로비저닝하는 Terraform 예시다.
NVIDIA device plugin을 EKS addon으로 배포한다.
resource "aws_eks_addon" "nvidia_device_plugin" {
cluster_name = module.eks.cluster_name
addon_name = "nvidia-device-plugin"
}
GPU 워커 노드 그룹에는 taint와 label을 설정한다.
gpu_node_group = {
ami_type = "AL2_x86_64_GPU"
instance_types = ["g5.xlarge"]
min_size = 0
max_size = 4
desired_size = 2
taints = {
gpu = {
key = "nvidia.com/gpu"
value = "true"
effect = "NO_SCHEDULE"
}
}
labels = {
"hardware-type" = "gpu"
}
}
- taint
nvidia.com/gpu=true:NoSchedule: GPU가 필요한 Pod만 GPU 노드에 스케줄되도록 한다. GPU를 요청하지 않는 일반 Pod가 비싼 GPU 노드에 올라가는 것을 방지한다 - label
hardware-type=gpu:nodeSelector나nodeAffinity로 GPU 워크로드를 특정 노드에 타겟팅할 수 있게 한다
배포 확인 명령이다.
helm list -n nvidia-device-plugin
kubectl get ds -n nvidia-device-plugin --no-headers
노드 피쳐 라벨링 — NFD / GFD
K8s 스케줄러는 하드웨어를 직접 알지 못한다. 스케줄러가 아는 것은 노드 라벨과 리소스 requests/limits뿐이다. 따라서 “이 노드에 어떤 GPU가 있는지”를 라벨로 표면화해야 스케줄러가 올바른 배치 결정을 내릴 수 있다. 이 역할을 하는 것이 NFD(Node Feature Discovery)와 GFD(GPU Feature Discovery)다.
| 컴포넌트 | 무엇을 라벨링 | 용도 |
|---|---|---|
| NFD | 범용 노드 피쳐 — feature.node.kubernetes.io/pci-10de.present=true (10de = NVIDIA 벤더 ID) |
“이 노드에 NVIDIA 장치 있음” → 1차 필터 |
| GFD | GPU 상세 — nvidia.com/gpu.product=NVIDIA-L4, nvidia.com/gpu.memory 등 |
“어떤 GPU냐” → 워크로드 배치·MIG/공유 인지 |
NVIDIA GPU Operator는 NFD 라벨을 기반으로 nodeAffinity를 설정해, GPU가 탐지된 노드에만 device plugin·드라이버 컨테이너를 배포한다. GFD는 NFD 위에 GPU 상세 정보를 추가하는 구조다.
정리하면 NFD = “GPU가 있나” / GFD = “어떤 GPU냐”다.
실습에서 GPU 노드에 올라간 NVIDIA 스택 DaemonSet은 다음과 같다. device plugin, GFD, NFD worker가 GPU 노드 1대에 각각 배포되고, MPS control daemon은 replicas 0으로 대기 상태다.
GPU를 요청하는 Pod
GPU를 사용하는 Pod는 다음과 같이 작성한다.
apiVersion: v1
kind: Pod
metadata:
name: gpu-workload
spec:
tolerations:
- key: "nvidia.com/gpu"
operator: "Equal"
value: "true"
effect: "NoSchedule"
nodeSelector:
hardware-type: gpu
containers:
- name: training
image: my-training-image:latest
resources:
limits:
nvidia.com/gpu: 1
tolerations— 앞서 설정한 GPU 노드의 taint를 허용한다nodeSelector—hardware-type=gpu라벨이 있는 노드에만 배치한다resources.limits— GPU는 반드시limits로 요청한다.requests만 단독으로 지정할 수 없다
Trainium/Inferentia를 사용하는 경우 리소스 이름만 다르다.
resources:
limits:
aws.amazon.com/neuroncore: 2
GPU request/limit 동작 — CPU·메모리와 다른 점
GPU의 request/limit 규칙이 CPU·메모리와 다른 것은 우연이 아니다. nvidia.com/gpu는 K8s의 extended resource이며, 다음 세 가지 규칙이 적용된다.
| 규칙 | 설명 |
|---|---|
| 정수만 허용 | nvidia.com/gpu: 0.5 같은 소수 지정 불가. 1, 2, 3… 정수 단위만 가능 |
| limits 필수 | requests만 단독 지정 불가. limits가 반드시 있어야 한다 |
| request == limit | requests를 생략하면 limits 값으로 자동 설정된다. requests를 명시하면 limits와 같아야 한다 |
따라서 유효한 지정 형태는 두 가지뿐이다.
- (가)
limits만 지정 →requests가 자동으로 같은 값으로 설정 - (나)
requests와limits를 둘 다 지정 → 반드시 같은 값
CPU·메모리처럼 request < limit으로 burst를 허용하는 것이 불가능하다. GPU는 연속량(continuous quantity)이 아니라 이산 장치(discrete device)이기 때문이다.
| 리소스 | 분할 모델 | request < limit burst | 한계 초과 시 |
|---|---|---|---|
| CPU | 연속량 (밀리코어 단위 분할) | 가능 | throttle |
| Memory | 연속량 (바이트 단위 분할) | 가능 | OOM kill |
| GPU (device) | 이산 장치 (분할 불가, 정수) | 개념 자체가 없음 | 해당 없음 |
CPU·메모리에서 말하는 compressible(압축 가능 — CPU)과 incompressible(비압축 — 메모리) 축은 연속량을 전제로 한 구분이다. GPU는 그 전 단계에서 이미 이산 장치라 이 분류 자체가 적용되지 않는다.
device plugin이 N개의 이산 장치를 kubelet에 광고하면, 스케줄러는 남은 개수만으로 배치 가능 여부를 판단한다. kubelet은 Allocate 시 특정 device ID를 컨테이너에 pin한다(NVIDIA의 경우 NVIDIA_VISIBLE_DEVICES 환경변수). 해당 device는 Pod 수명 동안 독점(exclusive)이다. GPU 하나를 “절반만” 쓰게 해주는 커널 수준의 메커니즘은 기본적으로 없다.
그렇다면 GPU를 “쪼개 쓰기”는 불가능한가? 아니다. 하지만 이것은 CPU·메모리 스타일의 overcommit이 아니다. MIG(Multi-Instance GPU), MPS(Multi-Process Service), time-slicing은 device plugin이 광고하는 단위 자체를 재정의하는 별개 메커니즘이다. 예를 들어 MIG는 물리 GPU 하나를 여러 개의 독립 인스턴스로 파티셔닝하고, 각 인스턴스를 별개 device로 광고한다. 이에 대해서는 다음 글에서 다룬다.
정리
| 영역 | 핵심 포인트 |
|---|---|
| GPU 종류 | CPU(범용) → GPU(병렬·행렬곱) → custom accelerator(AI 전용 ASIC) |
| K8s 인식 | 네이티브 아님 → device plugin + driver |
| 라벨링 | NFD(GPU 유무) + GFD(GPU 상세) |
| 할당 규칙 | extended resource: 정수, limits 필수, req==limit |
| 공유 | overcommit 불가 → 광고 단위 재정의(MIG/MPS/time-slicing) |
참고 링크
- Kubernetes for Generative AI Solutions — GitHub
- NVIDIA Device Plugin for Kubernetes
- Kubernetes Device Plugin Framework
- AWS Neuron SDK

댓글남기기