
[GenAI] GenAI on K8s: 10.3 - GPU 파티셔닝: MIG
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 10장의 학습 내용을 바탕으로 합니다
TL;DR
- MIG는 물리 GPU 하나를 여러 독립 GPU instance로 하드웨어 레벨에서 분할하는 기술이다 (Ampere 이후)
- GPU 다이는 GPC → TPC → SM → SP 계층 구조이고, MIG는 GPC 단위(compute)와 L2+메모리 컨트롤러 단위(memory)를 독립적으로 쪼갠다
- 프로파일
<compute>g.<memory>gb의 최대 인스턴스 수는min(7÷c, 8÷m)으로 결정되며, placement 규칙(연속성·정렬·무중첩)이 추가 제약을 건다 - K8s에서는 GPU Operator + MIG manager로 라벨/ConfigMap만 바꿔 자동 재구성하며, single/mixed strategy로 리소스를 노출한다
이전 글에서 GPU utilization 문제와 파티셔닝 기법의 필요성을 다뤘다. 이번 글에서는 NVIDIA MIG(Multi-Instance GPU)를 GPU 다이 구조부터 K8s 연동까지 깊이 있게 다룬다.
GPU 다이 구조 기초
MIG가 “무엇을 어떻게 쪼개는지” 이해하려면 GPU 다이의 계층 구조를 먼저 알아야 한다. GPU는 단순히 “코어가 많은 프로세서”가 아니라, 여러 겹의 계층으로 묶인 정교한 구조체다. MIG는 이 계층 중 특정 레벨에서만 분할이 가능하므로, 각 레벨이 무엇인지 알아야 MIG의 설계 결정이 자연스럽게 이해된다.
매크로 — 다이 전체 계층
MIG 관점에서 먼저 보면, GPU 다이는 컴퓨트(GPC) 와 메모리(L2 + MC) 가 각각 파티션 단위로 나뉘고, 메모리 컨트롤러가 다이 밖 VRAM(GDDR/HBM)에 연결된다. 아래 도식이 compute slice / memory slice가 하드웨어 어디에 대응하는지 한눈에 보여준다.
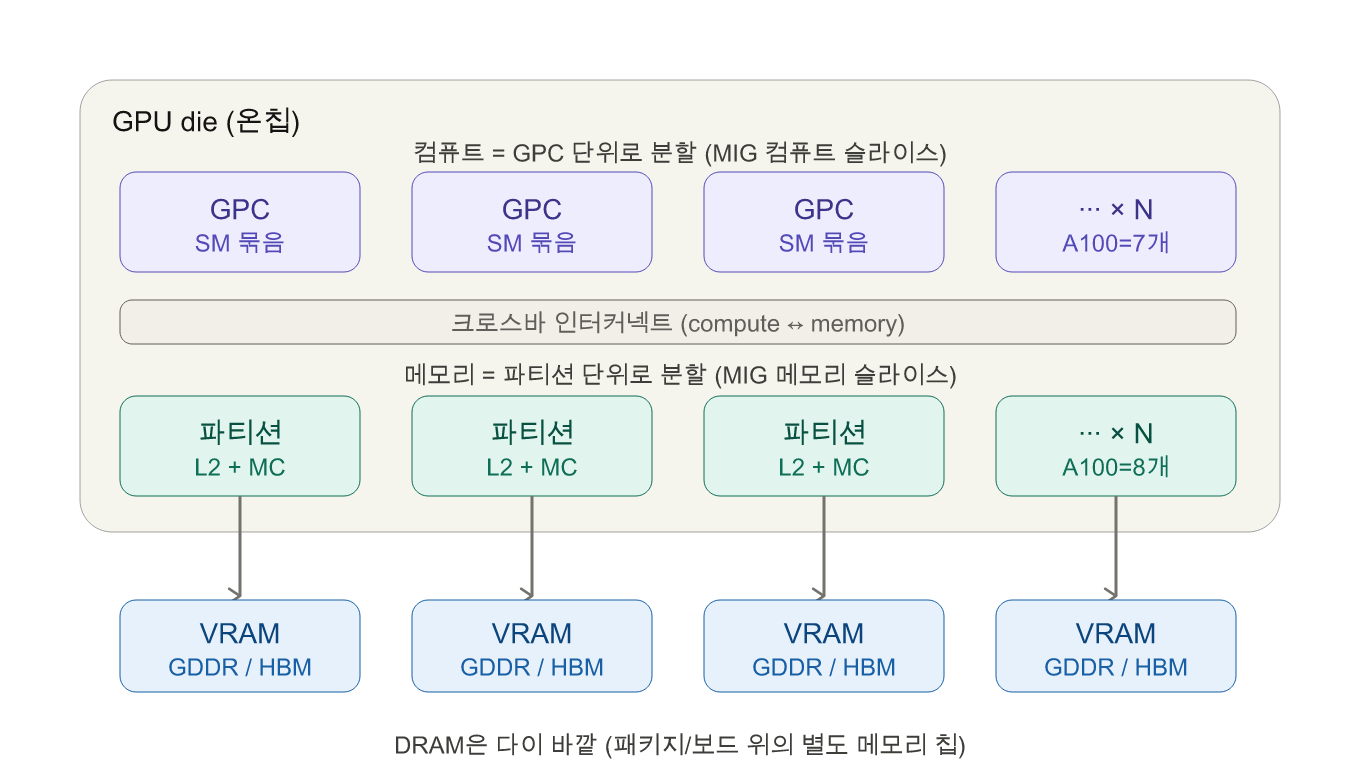
물리적 배치는 다이 평면도로 보면 더 직관적이다. GA104(소비자용 Ampere) 예시로 GPC → TPC → SM 계층을 확인하자.
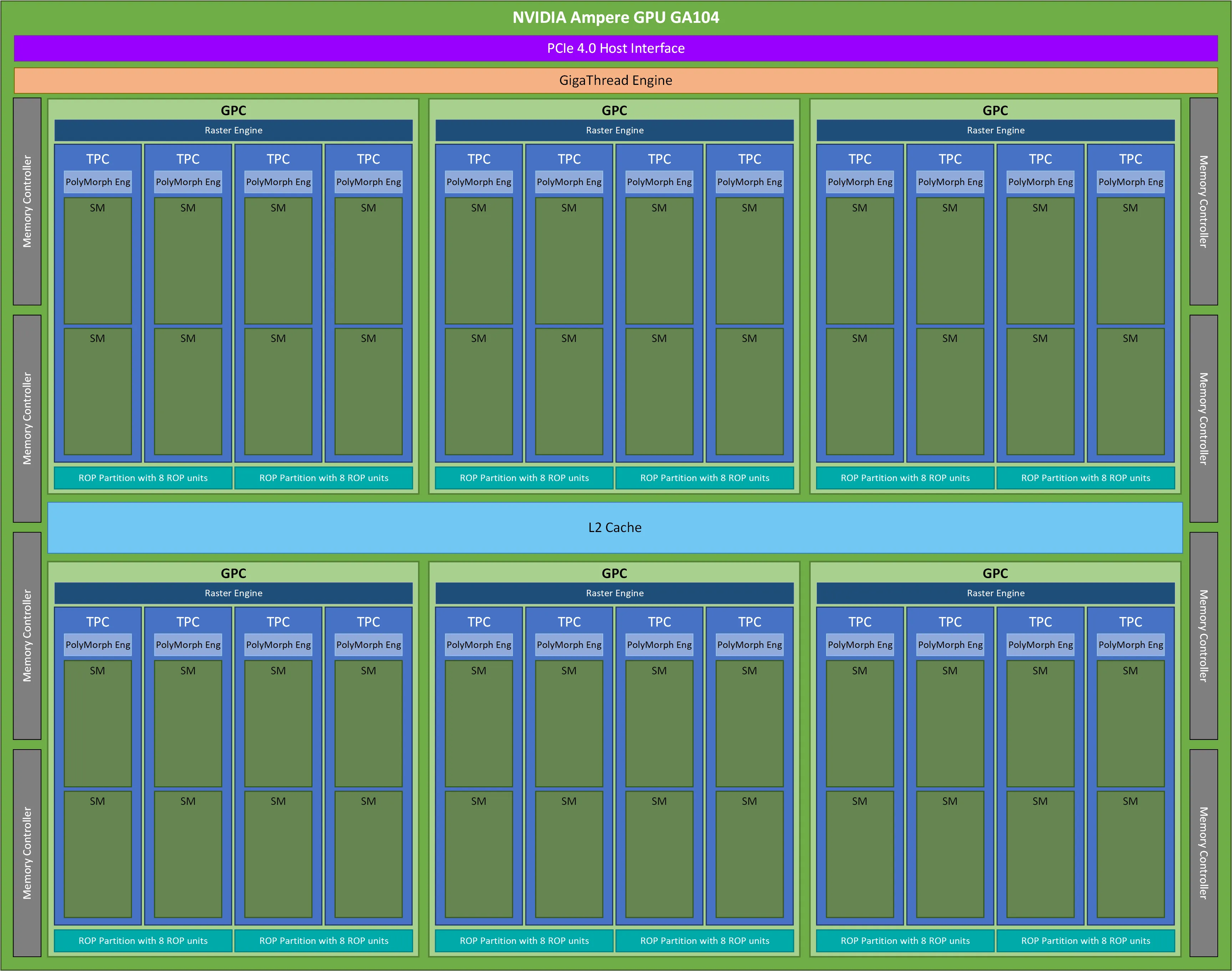
GA104는 소비자용(RTX 3070/3080 등)으로 MIG 대상이 아니다. 구조 이해용으로 참고하자. 데이터센터용 GPU(A100, H100 등)도 동일한 GPC → TPC → SM 계층을 따르되, GPC/SM 수가 훨씬 많다.
| 구성 요소 | 역할 |
|---|---|
| GigaThread Engine | GPU 전체의 작업 분배 엔진. 커널 실행 요청을 받아 GPC/SM에 thread block을 분배한다 |
| GPC (GPU Processing Cluster) | SM들을 묶는 중간 계층. MIG에서 compute 분할의 최소 단위다 |
| TPC (Texture Processing Cluster) | GPC 안의 하위 묶음. 보통 TPC 1개 = SM 2개. MIG 관점에서는 GPC가 단위이므로 TPC를 따로 신경 쓸 필요는 없다 |
| SM (Streaming Multiprocessor) | 실제 연산이 일어나는 핵심 유닛. CUDA Core(SP), Tensor Core, Warp Scheduler 등을 포함한다 |
| L2 Cache | 모든 SM이 공유하는 캐시. MIG에서 memory slice 분할 대상이다 |
| Memory Controller | HBM(또는 GDDR) 메모리와의 인터페이스. L2 Cache와 함께 memory slice에 포함된다 |
마이크로 — SM 내부와 메모리 계층
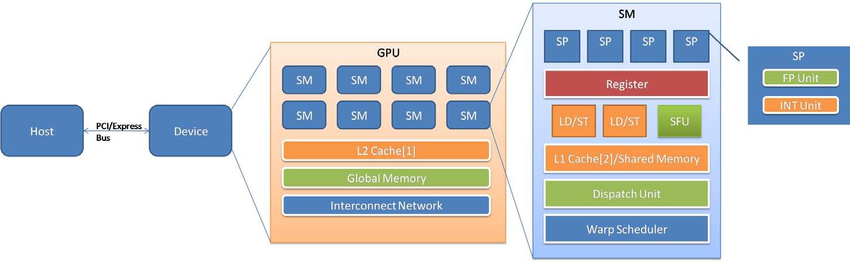
| 구성 요소 | 위치 | 역할 |
|---|---|---|
| SP (Streaming Processor, = CUDA Core) | SM 내부 | 최소 연산 유닛. FP32/INT32 연산 수행 |
| Register | SM 내부, 스레드별 | 스레드의 지역 변수를 저장하는 가장 빠른 메모리 |
| LD/ST Unit | SM 내부 | Load/Store 유닛. 메모리 읽기/쓰기를 담당한다 |
| SFU (Special Function Unit) | SM 내부 | sin, cos, exp 같은 초월함수(transcendental function) 전용 연산기 |
| Warp Scheduler | SM 내부 | 32개 스레드 묶음(warp)을 SM의 실행 파이프라인에 디스패치한다 |
| L1 / Shared Memory | SM 내부 | SM 로컬 캐시. L1(하드웨어 관리)과 Shared Memory(프로그래머 관리)가 같은 SRAM을 공유한다 |
| L2 Cache | 다이 전체 공유 | 모든 SM이 접근하는 공유 캐시. 글로벌 메모리 접근 전 마지막 캐시 계층 |
| Global Memory (HBM) | GPU 보드 | 대용량 고대역폭 메모리. 모든 스레드에서 접근 가능하지만 가장 느리다 |
메모리 접근 속도 계층은 다음과 같다.
Register → L1/Shared Memory → L2 Cache → Global Memory(HBM)
(가장 빠름) (가장 느림)
MIG 관점에서 중요한 두 가지 포인트가 있다.
- compute는 GPC → TPC → SM → SP로 계층적으로 묶인다 → MIG는 이 중 GPC 단위로만 쪼갤 수 있다. SM이나 SP 단위의 분할은 하드웨어 설계상 불가능하다
- 메모리는 L2 Cache + Memory Controller가 공유 서브시스템을 형성한다 → MIG는 이 레벨에서 격리한다. L2 캐시를 물리적으로 파티셔닝하고, 각 파티션에 전용 메모리 컨트롤러를 할당한다
compute(연산)과 memory(메모리)가 독립적인 두 축이라는 점이 핵심이다. MIG 프로파일의
<compute>g.<memory>gb표기도 이 두 축을 반영한 것이다. 뒤에서 프로파일을 해석할 때 이 구조를 계속 참조하게 된다.
NVIDIA MIG
개념
MIG(Multi-Instance GPU)는 물리 GPU 하나를 여러 독립된 GPU instance로 하드웨어 레벨에서 분할하는 기술이다. Ampere 아키텍처(A100) 이후에 도입되었다.
각 MIG instance는 다음을 전용으로 갖는다.
- 연산 코어(SM) — GPC 단위로 할당
- 메모리(HBM) — 메모리 컨트롤러 + L2 캐시 파티션 단위로 할당
- 기타 GPU 엔진 — copy engine(DMA)은 instance마다 할당된다. NVDEC/NVENC/NVJPG 같은 media engine은
+me프로파일에서만 전용 할당되며, GPU당 물리적으로 1세트뿐이다
이렇게 분할된 각 instance는 독립된 mini-GPU처럼 동작하며, 엄격한 하드웨어 격리를 제공한다. 한 instance의 오류가 다른 instance에 영향을 주지 않고(fault isolation), 메모리 대역폭 경합도 발생하지 않는다.
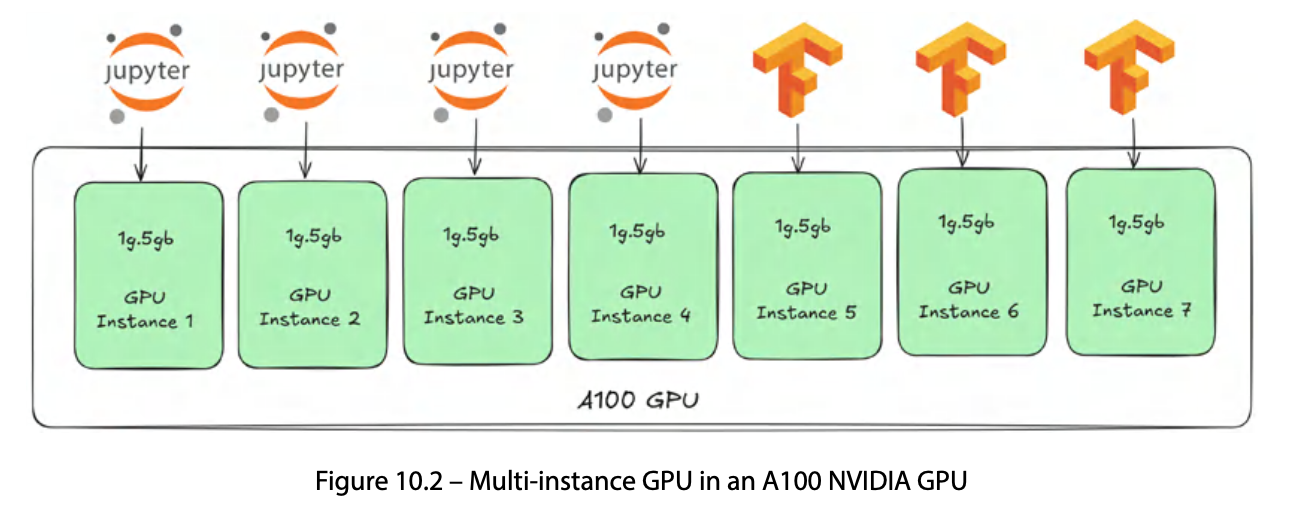
예를 들어, A100 40GB GPU 하나를 최대 7개의 MIG instance로 나누면 각각 약 5GB 메모리와 해당 비율의 연산 자원을 전용으로 갖게 된다. 각 instance 사이에는 어떤 자원도 공유되지 않으며, 한 instance가 크래시해도 다른 instance에 전혀 영향이 없다. 이것이 time-slicing이나 MPS와 근본적으로 다른 점이다.
MIG 프로파일 이름 해석
MIG 프로파일은 <compute>g.<memory>gb 형식으로 표기한다. 이 이름 자체가 해당 instance가 확보하는 자원을 직관적으로 알려준다.
| 구성 요소 | 의미 | 예시 |
|---|---|---|
<compute>g |
compute slice 개수 (SM 묶음 = GPC 단위) | 1g = GPC 1개, 2g = GPC 2개 |
<memory>gb |
메모리 용량(GB) | 18gb = HBM 18GB |
+me (선택) |
media engine 포함 | 1g.18gb+me |
+me 접미사는 NVDEC(비디오 디코더), NVJPG(JPEG 디코더), OFA(Optical Flow Accelerator) 같은 미디어 엔진을 instance에 포함시킨다는 뜻이다. NVDEC는 GPU 하나에 여러 개라 어느 정도 나뉘지만, NVJPG·OFA는 GPU당 1개뿐이라 이 단일 엔진이 병목이 된다. 그래서 미디어 엔진을 한 슬라이스에 통째로 몰아 주고, +me가 붙은 프로파일은 GPU당 최대 1개만 생성할 수 있다. 영상 전처리(디코딩·리사이즈)를 GPU에서 직접 처리하는 워크로드에 사용한다. LLM 추론·학습처럼 텍스트/텐서 연산만 하는 GenAI 워크로드는 media engine이 필요 없으므로 +me 없는 프로파일을 쓰면 된다.
핵심은 이름 = compute.memory라는 것이다. instance의 최대 개수는 compute와 memory 중 더 빡빡한(적은) 자원이 결정한다.
예를 들어 3g.70gb 프로파일은:
- compute slice 3개 (GPC 3개 분량의 SM 할당)
- memory 70GB (memory slice 약 4개 분량의 HBM + L2 + 메모리 컨트롤러)
를 하나의 MIG instance에 묶는다.
MIG 아키텍처 설계 원칙
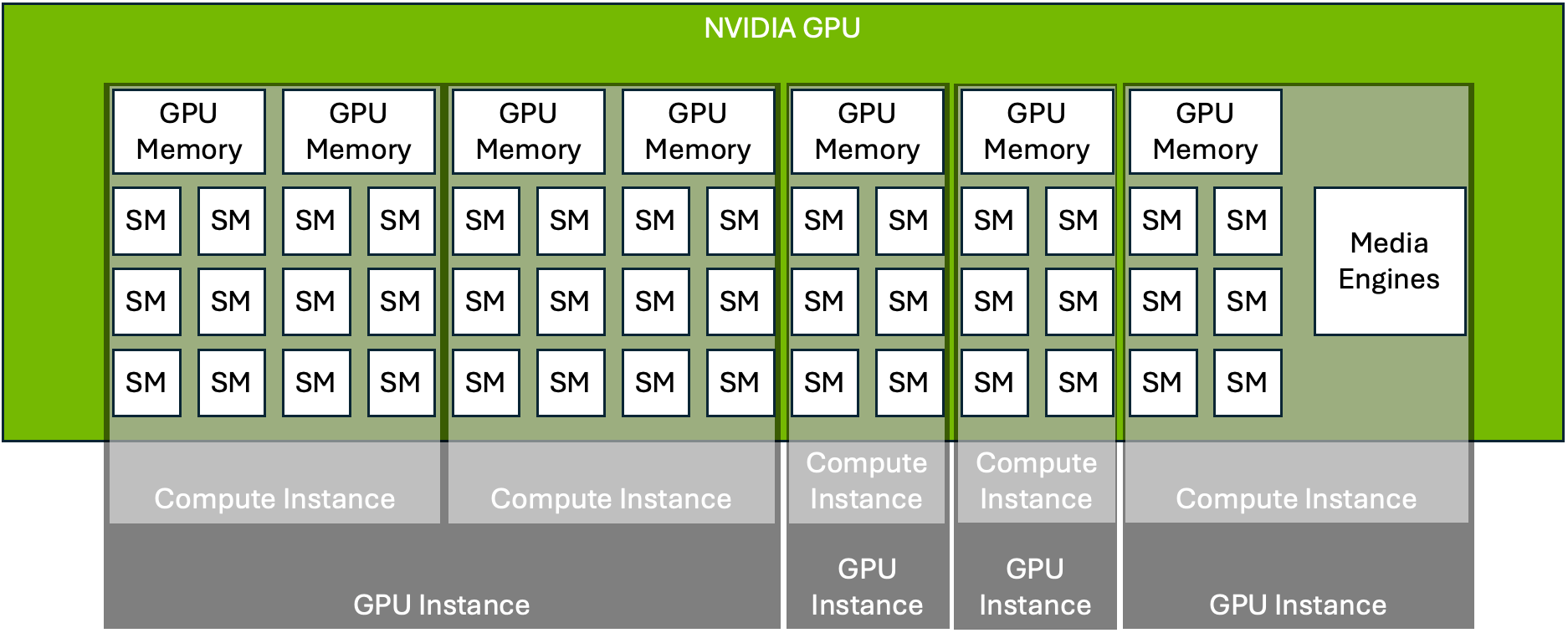
compute slice vs memory slice — 독립적으로 쪼갠다
MIG의 핵심 설계 원칙은 compute와 memory를 독립된 두 축으로 나눈다는 것이다.
| slice | 나누는 대상 | 단위 기준 |
|---|---|---|
| compute slice | 코어(SM) | GPC 기반. GPC 1개 = compute slice 1개 |
| memory slice | HBM / L2 Cache | L2 캐시 파티션 + 메모리 컨트롤러 기반 |
memory slice가 단순한 “메모리 용량 분배”가 아니라는 점이 중요하다. HBM 용량뿐 아니라 L2 캐시 파티션과 메모리 컨트롤러(메모리 경로)를 한 묶음으로 떼어내야 진짜 하드웨어 격리가 성립한다. 단순히 “너는 20GB, 나는 20GB”로 주소 공간만 나누면 L2 캐시와 메모리 대역폭은 여전히 공유되어 상호 간섭이 발생한다.
noisy neighbor 문제: MIG 없이 GPU를 공유하면 한 워크로드가 L2 캐시를 오염(cache thrashing)시키거나 메모리 대역폭을 독점하여 같은 GPU의 다른 워크로드 성능이 저하된다. MIG는 L2 캐시·메모리 컨트롤러·HBM을 물리적으로 파티셔닝하여 이 문제를 원천 차단한다. time-slicing이나 MPS로는 해결할 수 없는 격리 수준이다.
GPU Instance(GI) vs Compute Instance(CI)
MIG에는 두 계층의 instance가 있다.
| 계층 | 무엇을 묶나 | 격리 수준 |
|---|---|---|
| GPU Instance (GI) | memory slice + compute slice + media engine | 메모리까지 완전 격리. 각 GI는 독립된 메모리 주소 공간을 갖는다 |
| Compute Instance (CI) | GI 안에서 compute(SM)만 추가 분할 | 메모리는 같은 GI 내에서 공유하고, 연산만 분리한다 |
GI가 메모리 격리의 경계이고, CI는 그 안에서 compute를 더 잘게 나누는 선택적 계층이다. 대부분의 사용 사례에서는 GI 하나에 CI 하나(기본값)로 운영한다. CI를 여러 개 만드는 건 같은 메모리를 공유하면서 연산만 분리하고 싶을 때(예: 같은 모델의 여러 추론 스레드)에 사용하는 고급 패턴이다.
slice 개수: 7/8 표준
모든 풀사이즈 데이터센터 GPU는 compute slice = 7, memory slice = 8이라는 표준을 따른다.
| GPU | compute slices | memory slices |
|---|---|---|
| A30 | 4 | 4 |
| A100 40GB | 7 | 8 |
| A100 80GB | 7 | 8 |
| H100 | 7 | 8 |
| H200 | 7 | 8 |
| B200 | 7 | 8 |
-
compute = 7인 이유: GPC가 MIG에서 compute 격리의 최소 단위인데, 반도체 제조의 수율(yield)과 비닝(binning) 때문에 모든 칩이 7개 GPC를 보장한다. 실제 다이에는 8개 이상의 GPC가 있을 수 있지만, 불량 유닛을 비활성화하고도 7개는 항상 동작하도록 설계한다.
-
memory = 8인 이유: HBM 메모리 서브시스템이 8개 파티션으로 깔끔하게 나뉘도록 설계되어 있다. HBM 스택의 채널과 메모리 컨트롤러가 8등분에 맞춰 배치된다.
이 두 숫자에서 핵심 공식이 도출된다. 두 공식은 역할이 다르다 — 위는 하드웨어 파티션 1칸의 용량, 아래는 같은 프로파일만 꽉 채울 때의 이론적 상한이다.
slice당 GB = 총 GPU 메모리 ÷ 8
memory slice 1개가 담당하는 HBM 용량이다. 프로파일 이름의 GB가 항상 이 값의 정수배인 이유가 여기 있다.
예를 들어 H200의 총 메모리가 141GB면, memory slice 1개 = 141 ÷ 8 ≈ 17.6GB(반올림하여 ~18GB)가 된다.
최대 인스턴스 수 = min(7 ÷ c, 8 ÷ m)
동일 프로파일을 GPU 하나에 최대한 많이 생성할 때의 이론적 상한이다. c는 instance당 compute slice 수, m은 instance당 memory slice 수(= 프로파일 memory GB ÷ slice당 GB)이다. compute와 memory 중 먼저 소진되는 쪽이 병목이 된다.
이 공식이 말해 주지 않는 것도 있다.
- 프로파일 혼합:
2g.35gb3개 +1g.18gb1개처럼 여러 프로파일을 섞으면 bin packing 문제가 되어, 이 공식만으로는 답을 구할 수 없다 - placement 규칙: memory slice는 연속·정렬 배치가 필요하므로, 이론 상한보다 실제 최대 개수가 적을 수 있다(아래 MIG placement 절)
+me(media engine): NVDEC/NVENC 등은 compute/memory slice와 별도 자원이라,+me프로파일은 GPU당 최대 1개라는 추가 제약이 걸린다
왜 소비자용 GPU(RTX 4090 등)는 MIG를 지원하지 않는가? 흔한 오해는 “GDDR이라서 구조적으로 못 한다”는 것이지만, 사실이 아니다. 분할의 토대가 되는 구조(GPC·L2·메모리 컨트롤러)는 라인업 전반에 깔려 있다. MIG는 그 위에 인스턴스 간 메모리·fault 격리, L2/대역폭 QoS 분할 같은 하드 격리 실리콘을 추가로 얹느냐의 문제이고, 이 하드웨어가 소비자/Ada 칩엔 실제로 탑재돼 있지 않아 지금 그 칩으론 못 켜는 것이다.
이것이 “기술적 불가”가 아니라 NVIDIA의 비용·검증·시장세분화 결정이라는 근거가 둘 있다.
- Ada Lovelace 반례: AD102는 A100(GPC 8개)보다 신세대 데이터센터 아키텍처이고 GPC가 오히려 12개로 더 많은데도, L4/L40/L40S는 MIG를 지원하지 않는다(time-sliced vGPU만). 구조가 더 충분한 신세대인데 빠졌다는 건 “구조상 불가”가 아님을 못박는다
- Blackwell RTX PRO 반례: RTX PRO 6000/5000 Blackwell은 GDDR 기반 워크스테이션 GPU인데도 MIG를 다시 탑재했다(6000은 최대 4 instance, 5000은 2 instance). “HBM 데이터센터 GPU만 MIG”라는 단정을 직접 반증한다
그래서 HBM↔MIG의 상관은 “MIG를 데이터센터 라인에 넣기로 한 결정의 결과적 상관”이지 인과가 아니다. 소비자 GPU도 공유 자체가 막힌 건 아니다 — time-slicing·MPS(소프트 공유)는 되고, MIG(하드 격리)만 안 된다(차이는 격리의 강도). 본 실습의 L4가
migStrategy: none인 이유가 정확히 이것이다.참고로 DRAM 계통은 다음과 같이 나뉜다. 단 아래는 “어느 라인에 주로 쓰이나”일 뿐, MIG 가부를 정하는 기준이 아니다.
유형 특성 주 사용처 DDR (DDR4/5) CPU용 범용 메모리 메인보드 시스템 RAM GDDR (GDDR6/6X/7) 핀 기반 넓은 버스 소비자 GPU + 일부 워크스테이션(RTX PRO Blackwell 등) HBM (HBM2e/3e) 스택-채널 구조, 초고대역폭 데이터센터 GPU(A100/H100/H200/B200)
H200 프로파일 표 해석
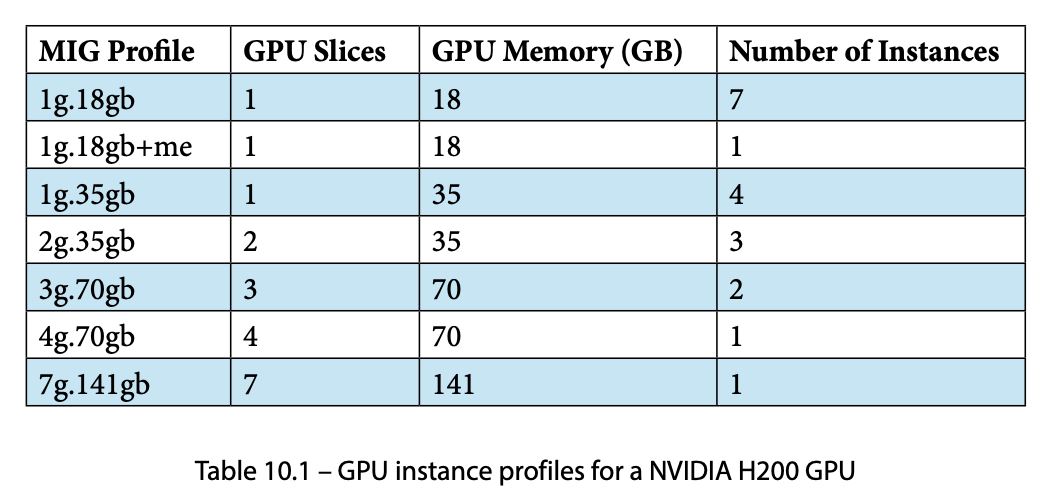
H200 스펙 참고: 141GB HBM3e, ~4.8 TB/s 대역폭, Hopper 아키텍처(H100과 동일 컴퓨트 다이), 132 SM(풀 다이 GH100은 144 SM이지만 수율 binning으로 132개). 물리 GPC는 8개이고, MIG compute slice는 7개라 slice당 ≈ 132 ÷ 7 ≈ 18 SM이다(GPC 8개 ≠ compute slice 7개 — slice 7은 결함 칩까지 보장 가능한 수로 8 중 하나를 마진으로 뺀 것). H200은 H100에 더 큰 메모리(80GB → 141GB)와 더 빠른 HBM3e를 결합한 제품이다. Compute slice 7개, memory slice 8개(slice당 ≈18GB)로 동일한 MIG 프레임워크가 적용된다.
H200의 MIG 프로파일별 최대 인스턴스 수를 유도해 보자. slice당 메모리는 141 ÷ 8 ≈ 18GB이다.
| 프로파일 | compute 한계 (7÷c) | memory 한계 (8÷m) | 최대 인스턴스 | 병목 |
|---|---|---|---|---|
| 1g.18gb | 7÷1 = 7 | 8÷1 = 8 | 7 | compute |
| 1g.18gb+me | 7÷1 = 7 | 8÷1 = 8 | 1 | media engine |
| 1g.35gb | 7÷1 = 7 | 8÷2 = 4 | 4 | memory |
| 2g.35gb | 7÷2 = 3 | 8÷2 = 4 | 3 | compute |
| 3g.70gb | 7÷3 = 2 | 8÷4 = 2 | 2 | compute·memory 동시 |
| 4g.70gb | 7÷4 = 1 | 8÷4 = 2 | 1 | compute |
| 7g.141gb | 7÷7 = 1 | 8÷8 = 1 | 1 | 전체 사용 |
각 행의 유도 과정을 하나씩 살펴보자.
- 1g.18gb: compute 1개씩 7개 가능, memory 1개씩 8개 가능 → min(7, 8) = 7. compute가 먼저 소진된다. memory slice 1개(18GB)가 남지만 배정할 compute가 없다
- 1g.18gb+me: 산술상으로는 7개 가능하지만, media engine(NVDEC/NVJPG/OFA)은 GPU당 물리적으로 한 세트뿐이다 → 최대 1개
- 1g.35gb: compute 1개, memory 2개(35GB ≈ 18×2)를 쓰는 프로파일이다. compute 한계 7, memory 한계 4 → min(7, 4) = 4. memory가 병목이다
- 2g.35gb: compute 2개, memory 2개. compute 한계 3, memory 한계 4 → min(3, 4) = 3. compute가 병목이다
- 3g.70gb: compute 3개, memory 4개(70GB ≈ 18×4). compute 한계 2, memory 한계 2 → 양쪽 동시에 병목. GPU 자원이 정확히 절반씩 나뉜다
- 4g.70gb: compute 4개, memory 4개. compute 한계 1, memory 한계 2 → compute가 병목. memory는 절반이 남는다
- 7g.141gb: compute slice 7 + memory slice 8 = GPU 전체를 하나의 MIG instance로 점유한다
왜 1g.25gb 같은 프로파일은 없는가? memory slice는 하드웨어 파티셔닝 단위(18GB)의 정수배로만 할당할 수 있다. 1.5개(≈25GB)처럼 중간 크기는 물리적으로 불가능하다. 따라서 프로파일의 memory는 항상 18GB의 배수(18, 35≈36, 70≈72, 141≈144)에 근사한다. 약간의 오차는 시스템 예약 메모리와 반올림 때문이다.
멀티 GPU 시스템에서의 MIG: 각 물리 GPU는 독립적으로 MIG 프로파일을 구성한다. 예를 들어 p5.48xlarge(H100 × 8)에서 모든 GPU를
1g.10gb로 구성하면 7 × 8 = 56개 MIG instance가 생긴다. 각 instance가 독립된 GPU처럼 K8s에 리소스로 노출되므로, 소규모 추론 워크로드 56개를 하나의 노드에서 격리된 상태로 돌릴 수 있다.
7g.141gb vs MIG OFF
7g.141gb는 MIG 모드가 켜진 상태에서 compute·memory slice를 모두 하나의 GPU Instance에 할당한 프로파일이다. MIG 프레임워크 안에서 “전체 GPU를 한 instance가 독점”하는 설정이라, H200 프로파일 표에서 slice를 다 쓰는 유일한 형태다.
MIG OFF는 MIG 분할 자체를 비활성화하고, 물리 GPU를 통째로 하나의 디바이스로 노출하는 상태다. nvidia-smi에는 일반 GPU로 보이고, time-slicing이나 MPS로 다른 프로세스와 공유하는 전통적인 사용 방식이다.
둘 다 GPU 전체를 사용하지만 차이가 있다.
| 항목 | MIG OFF | 7g.141gb |
|---|---|---|
| 사용 가능 자원 | GPU 전체 (모든 SM + 전체 메모리) | GPU 전체 (동일) |
| MIG 격리 | 없음 | MIG 프레임워크 내에서 동작 |
| 다른 instance와 공존 | 가능 (time-slicing/MPS로 공유) | 불가 (이미 전체 점유) |
| nvidia-smi 표시 | 일반 GPU | MIG instance로 표시 |
| 용도 | 단일 워크로드 전용 | MIG 체계 안에서 전체 GPU를 하나에 할당하고 싶을 때 |
단일 워크로드에 GPU 전체를 주고 MIG 격리가 필요 없다면 MIG OFF가 낫다. MIG 오버헤드(소량이지만 있다)를 피할 수 있다. 반대로 클러스터 전체가 MIG 기반으로 운영 중이라면, 같은 노드의 다른 GPU들과 설정을 맞추기 위해 7g.141gb를 쓰는 경우도 있다.
MIG placement 규칙
min(7÷c, 8÷m)은 이론적 최대값이다. 실제로는 placement 규칙이 추가 제약을 건다.
MIG의 memory slice 배치를 슬롯 모델로 시각화하면 다음과 같다.
위치: [0][1][2][3][4][5][6][7] ← memory slice 8칸
세 가지 규칙이 적용된다.
| 규칙 | 설명 |
|---|---|
| 연속성 (contiguous) | 프로파일이 차지하는 memory slice들은 연속된 칸에 배치되어야 한다. 떨어진 칸에 분산 배치 불가 |
| 정렬 (aligned start) | 시작 위치가 프로파일 크기의 배수여야 한다. 예: 2-slot 프로파일은 0, 2, 4, 6에서만 시작 가능 |
| 무중첩 (no overlap) | 이미 배치된 instance와 겹칠 수 없다 |
프로파일별 유효 시작 위치와 최대 개수를 표로 정리하면 다음과 같다.
| 프로파일 | slot 수 | 유효 시작 위치 | 이론 최대 (min 공식) | placement 최대 |
|---|---|---|---|---|
| 1g.18gb | 1 | 0, 1, 2, 3, 4, 5, 6 | 7 (compute 한계) | 7 |
| 1g.35gb | 2 | 0, 2, 4, 6 | 4 (memory 한계) | 4 |
| 2g.35gb | 2 | 0, 2, 4, 6 | 3 (compute 한계) | 3 |
| 3g.70gb | 4 | 0, 4 | 2 | 2 |
| 4g.70gb | 4 | 0, 4 | 1 (compute 한계) | 1 |
| 7g.141gb | 8 | 0 | 1 | 1 |
혼합 배치 예시: 4g.70gb + 3g.70gb
위치: [0][1][2][3][4][5][6][7]
├──4g.70gb─┤├──3g.70gb─┤ (slot 7은 빈다)
slot 0~3 slot 4~6
4g.70gb는 slot 4개(0~3), 3g.70gb는 slot 4개(4~7) 중 compute 3개분만 사용하고 memory slot 7은 비게 된다. 이렇게 깔끔하게 들어맞지만, 반대 순서(3g를 먼저 0~3에, 4g를 4~7에)도 가능하다. 핵심은 정렬·연속성·무중첩이 모두 만족되어야 한다는 것이다.
단편화(fragmentation) 문제
placement 규칙 때문에, 이론적으로 자원이 남아 있어도 배치가 불가능한 경우가 생긴다.
위치: [0][1][2][3][4][5][6][7]
├1g┤ ├1g┤ ├1g┤
0 빈 2 빈 4 5 6 7
여기서 2g.35gb를 추가하려면 연속 2칸이 필요하지만,
빈 칸이 1, 3, 5, 6, 7에 흩어져 있어 정렬 규칙을 만족하는
연속 2칸 시작점(0, 2, 4, 6)에 빈 공간이 없을 수 있다.
이런 단편화 문제는 MIG instance를 삭제하고 재배치하지 않으면 해결할 수 없다. 그리고 MIG 재구성은 GPU가 idle 상태여야 가능하므로, 운영 중 재배치는 비용이 크다.
구체적으로 정렬 규칙 때문에 발생하는 제약의 예를 하나 더 보자. memory slice 8칸 중 slot 0과 slot 2에 1g instance가 각각 하나씩 올라가 있다.
현재 상태:
위치: [0][1][2][3][4][5][6][7]
├─1g─┤ ├─1g─┤
slot 0 slot 2
여기에 2g.35gb(memory slice 2칸)를 추가하려면 연속 2칸이 필요하고, 2-slot 프로파일의 유효 시작 위치는 0, 2, 4, 6뿐이다. slot 0과 slot 2는 이미 1g가 차지하고 있어 무중첩 규칙에 걸린다. 남는 후보는 slot 4와 slot 6이다 — slot 4에서 시작하면 [4][5]에, slot 6에서 시작하면 [6][7]에 배치할 수 있다.
결과 (둘 중 하나):
위치: [0][1][2][3][4][5][6][7]
├1g┤빈├1g┤빈├2g.35gb┤빈 빈
또는
├1g┤빈├1g┤빈 빈 빈├2g.35gb┤
빈칸이 흩어져 있어도 정렬된 시작 위치(0, 2, 4, 6) 중 하나에 연속 2칸이 비어 있으면 배치는 가능하다. 반대로 유효 시작 위치마다 이미 instance가 있거나 연속 칸이 부족하면, slice가 남아 있어도 추가 생성은 불가능하다.
slot 1, 3이 비어 있어도 정렬 조건(2의 배수 시작)을 만족하지 못해 1g 이외의 프로파일은 들어갈 수 없다. 이것이 단편화다.
균일 배치가 흔한 이유
실무에서는 같은 프로파일로 균일하게 배치하는 경우가 대부분이다.
| 이유 | 설명 |
|---|---|
| 단편화 회피 | 같은 크기로 채우면 빈 틈이 발생하지 않는다 |
| 재구성 비용 | MIG 변경 시 GPU idle 필요 → 균일 배치면 재구성 빈도가 낮다 |
| 스케줄링 단순화 | K8s 리소스 타입이 하나로 통일되어 스케줄링이 단순해진다 |
K8s 연동
K8s에서 MIG instance는 (GI ID, CI ID) 쌍으로 식별된다. NVIDIA Device Plugin은 각 MIG instance를 별도의 extended resource로 노출한다(예: nvidia.com/mig-1g.18gb).
Pod이 MIG instance를 사용하려면 해당 리소스를 요청하면 된다.
apiVersion: v1
kind: Pod
metadata:
name: mig-inference-pod
spec:
containers:
- name: inference
image: nvcr.io/nvidia/tritonserver:24.01-py3
resources:
limits:
nvidia.com/mig-1g.18gb: 1
Pod 매니페스트에 프로파일 이름(
mig-1g.18gb)을 직접 써야 하므로, 사용자(또는 플랫폼 엔지니어)가 노드에 어떤 MIG 프로파일이 구성되어 있는지 알아야 한다. 이는 migStrategy 설정에 따라 달라진다.
single vs mixed MIG strategy
Device Plugin의 migStrategy 설정은 MIG instance를 K8s에 어떻게 보고할지를 결정한다. MIG 자체를 켜거나 끄는 것이 아니라, 이미 생성된 MIG instance를 K8s extended resource로 어떤 이름으로 광고할지를 정하는 설정이다.
| strategy | 리소스 이름 | 제약 | 적합한 경우 |
|---|---|---|---|
| single | nvidia.com/gpu |
노드의 모든 MIG instance가 같은 프로파일이어야 한다 | 균일 배치 (예: 전부 1g.18gb) |
| mixed | nvidia.com/mig-<profile> (예: nvidia.com/mig-1g.18gb) |
서로 다른 프로파일 공존 가능 | 혼합 배치 (예: 3g.70gb + 1g.18gb 3개) |
| none | nvidia.com/gpu |
MIG를 인식하지 않음. 물리 GPU를 그대로 보고 | MIG 미사용 GPU (L4, T4 등) |
single 전략에서는 기존 nvidia.com/gpu: 1 요청으로 MIG instance가 할당되므로, 기존 워크로드 매니페스트를 수정할 필요가 없다. mixed 전략에서는 프로파일별 리소스 이름을 명시해야 한다.
MIG 활성화 계층 — strategy는 보고 방식일 뿐
MIG를 실제로 사용하려면 아래 계층이 모두 갖춰져야 한다. migStrategy만 바꿔선 MIG가 켜지지 않는다.
| 단계 | 무엇 | 누가 |
|---|---|---|
| ① 하드웨어 | MIG 지원 GPU (A100, H100, H200 등) | NVIDIA 하드웨어 |
| ② 드라이버 MIG 모드 ON | nvidia-smi -mig 1 |
드라이버 |
| ③ MIG instance 생성 | nvidia-smi mig -cgi <profile> -C |
드라이버 |
| ④ K8s 보고 | migStrategy (single/mixed) | Device Plugin |
L4 같은 MIG 미지원 GPU에서는 migStrategy: none이 정답이다. single이나 mixed로 설정하면 Device Plugin이 MIG instance를 찾으려다 실패하고 GPU 리소스를 제대로 보고하지 못한다.
GPU Operator 자동화
수동으로 nvidia-smi 명령을 실행해 MIG 모드를 켜고 instance를 만드는 것은 노드가 많아지면 현실적이지 않다. GPU Operator의 nvidia-mig-manager가 이를 자동화한다.
동작 흐름은 다음과 같다.
- 관리자가 노드의 MIG 프로파일 라벨을 변경한다
nvidia-mig-managerDaemonSet이 라벨 변경을 감지한다- 해당 노드를 drain(워크로드 퇴거)한다
- GPU를 idle로 만든 후 MIG 모드를 활성화하고 프로파일에 맞는 instance를 생성한다
- 완료되면 노드를 uncordon(스케줄링 재개)한다
GPU Operator Helm 설치 시 MIG 관련 설정 예시:
migManager:
enabled: true
config:
name: mig-config # ConfigMap 이름
devicePlugin:
config:
name: device-plugin-config
mig:
strategy: mixed # single 또는 mixed
MIG 프로파일을 정의하는 ConfigMap 예시:
apiVersion: v1
kind: ConfigMap
metadata:
name: mig-config
namespace: gpu-operator
data:
config.yaml: |
version: v1
mig-configs:
all-1g.18gb:
- devices: all
mig-enabled: true
mig-devices:
1g.18gb: 7
all-3g.70gb:
- devices: all
mig-enabled: true
mig-devices:
3g.70gb: 2
mixed-config:
- devices: all
mig-enabled: true
mig-devices:
3g.70gb: 1
1g.18gb: 3
노드에 MIG 프로파일을 적용하려면 라벨을 변경한다.
kubectl label node <node-name> nvidia.com/mig.config=all-1g.18gb --overwrite
적용 확인 명령:
# MIG device 확인
kubectl exec -it <gpu-pod> -- nvidia-smi mig -lgi
# K8s 리소스로 노출 확인
kubectl describe node <node-name> | grep nvidia.com/mig
# MIG 모드 상태 확인
kubectl exec -it <gpu-pod> -- nvidia-smi --query-gpu=mig.mode.current --format=csv
# 전체 MIG 구성 확인
kubectl exec -it <gpu-pod> -- nvidia-smi mig -lgip
MIG 프로파일 변경 시 발생하는 이벤트 순서를 보면 GPU Operator의 자동화가 어떻게 동작하는지 이해할 수 있다.
1. 관리자: kubectl label node gpu-node nvidia.com/mig.config=all-1g.18gb
2. nvidia-mig-manager: 라벨 변경 감지
3. nvidia-mig-manager: kubectl drain gpu-node (워크로드 퇴거)
4. nvidia-mig-manager: nvidia-smi -mig 1 (MIG 모드 ON, 필요 시)
5. nvidia-mig-manager: nvidia-smi mig -dci && nvidia-smi mig -dgi (기존 instance 제거)
6. nvidia-mig-manager: nvidia-smi mig -cgi 19,19,19,19,19,19,19 -C (1g.18gb × 7 생성)
7. nvidia-mig-manager: kubectl uncordon gpu-node (스케줄링 재개)
8. device-plugin: 새로운 MIG instance를 K8s 리소스로 광고
GPU Operator의 MIG 설정에 대한 상세 가이드는 GPU Operator MIG 설정 문서를 참고하자.
전체 흐름을 정리하면, MIG를 K8s에서 운영하는 것은 결국 세 가지 레이어의 조합이다.
- 하드웨어 레이어: MIG 지원 GPU가 물리적으로 파티셔닝을 가능하게 한다
- 드라이버 레이어:
nvidia-smi(또는 GPU Operator의 MIG Manager)가 MIG 모드를 켜고 GI/CI를 생성한다 - K8s 레이어: Device Plugin이 migStrategy에 따라 MIG instance를 extended resource로 노출하고, Pod이 이를 요청한다
플랫폼 엔지니어는 ConfigMap과 노드 라벨로 원하는 프로파일을 선언하고, GPU Operator가 drain → 재구성 → uncordon 사이클을 자동으로 처리한다. 워크로드 개발자는 Pod spec에 리소스 이름만 쓰면 된다.
정리
| 영역 | 핵심 포인트 |
|---|---|
| 다이 구조 | GPC → TPC → SM. MIG는 GPC 단위로만 compute 분할 가능 |
| 격리 수준 | compute(SM) + memory(HBM + L2 + MC) 하드웨어 분할 → noisy neighbor 제거 |
| 프로파일 | <c>g.<m>gb, 최대 = min(7÷c, 8÷m) + placement 규칙 |
| K8s 연동 | single(nvidia.com/gpu) vs mixed(nvidia.com/mig-*), GPU Operator로 자동화 |
MIG는 GPU 공유 메커니즘 중 유일하게 하드웨어 레벨의 완전 격리를 제공하는 기술이다. 다만 MIG 격리 하드웨어를 탑재한 GPU(주로 Ampere 이후 데이터센터 라인, 그리고 Blackwell RTX PRO 등 일부 워크스테이션)에서만 지원되고, 프로파일 변경 시 GPU idle이 필요하다는 운영 제약이 있다. time-slicing이나 MPS와 달리 격리가 강력한 만큼, 멀티테넌트 추론 서빙이나 SLA가 중요한 프로덕션 환경에 적합하다.
참고 링크
- Kubernetes for Generative AI Solutions — GitHub
- NVIDIA MIG User Guide
- GPU Operator — MIG 설정
- NVIDIA H200 Datasheet

댓글남기기