
[GenAI] GenAI on K8s: 10.4 - GPU 공유: MPS와 Time-slicing
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 10장의 학습 내용을 바탕으로 합니다
이전 글에서 MIG를 통한 GPU 하드웨어 파티셔닝을 다뤘다. 이번 글에서는 소프트웨어 기반의 GPU 공유 기법인 MPS와 time-slicing, 세 기법 비교를 정리한다. Ch10 time-slicing 실습 코드 분석은 10.6에서, 배포·검증·트러블슈팅은 10.7에서 다룬다.
TL;DR
- MPS는 여러 프로세스의 커널을 한 GPU SM에 동시 co-resident시키는 병렬(parallel) 공유, time-slicing은 context를 타이머로 번갈아 전환하는 직렬(serial) 공유다
- MPS의 메모리 격리는 Volta부터 주소공간 접근 분리가 추가됐지만, 용량·대역폭·fault 격리는 여전히 없다
- time-slicing은 ConfigMap의 replicas로 물리 1장을 N개 슬롯으로 광고하며, 메모리 격리가 없어 Σ(모델 메모리) ≤ 물리 VRAM을 사용자가 직접 책임진다
- 세 기법은 배타적이지 않다 — MIG로 큰 칸을 가르고 그 안을 time-slicing으로 다시 공유하는 스택이 가능하다(공식 k8s-device-plugin 기준 MIG+time-slicing은 지원, MIG+MPS는 CUDA 레벨 한정)
NVIDIA MPS
개념
MPS(Multi-Process Service)는 여러 프로세스가 GPU를 동시에(concurrent) 공유하도록 최적화하는 소프트웨어 기능이다. 기본적으로 GPU는 한 시점에 하나의 CUDA context만 실행하는데, MPS는 이를 우회하여 여러 프로세스의 커널이 빈 SM을 채워 동시에 실행되도록 만든다. 저지연 스케줄링과 성능 향상이 가능하다. “동시 실행”이 MPS의 본질이다.
MPS의 구조를 간단히 그리면 다음과 같다:
Process A ──┐
├──→ MPS Server ──→ GPU (SM 0~3: A의 커널, SM 4~7: B의 커널)
Process B ──┘
MPS Server라는 데몬 프로세스가 여러 client 프로세스의 CUDA 작업을 받아 하나의 GPU에 동시에 제출한다. GPU 입장에서는 여러 커널이 동시에 들어오므로, SM 스케줄러가 빈 SM에 서로 다른 프로세스의 커널을 배치할 수 있다. context switching이 발생하지 않으므로 전환 오버헤드가 없다.
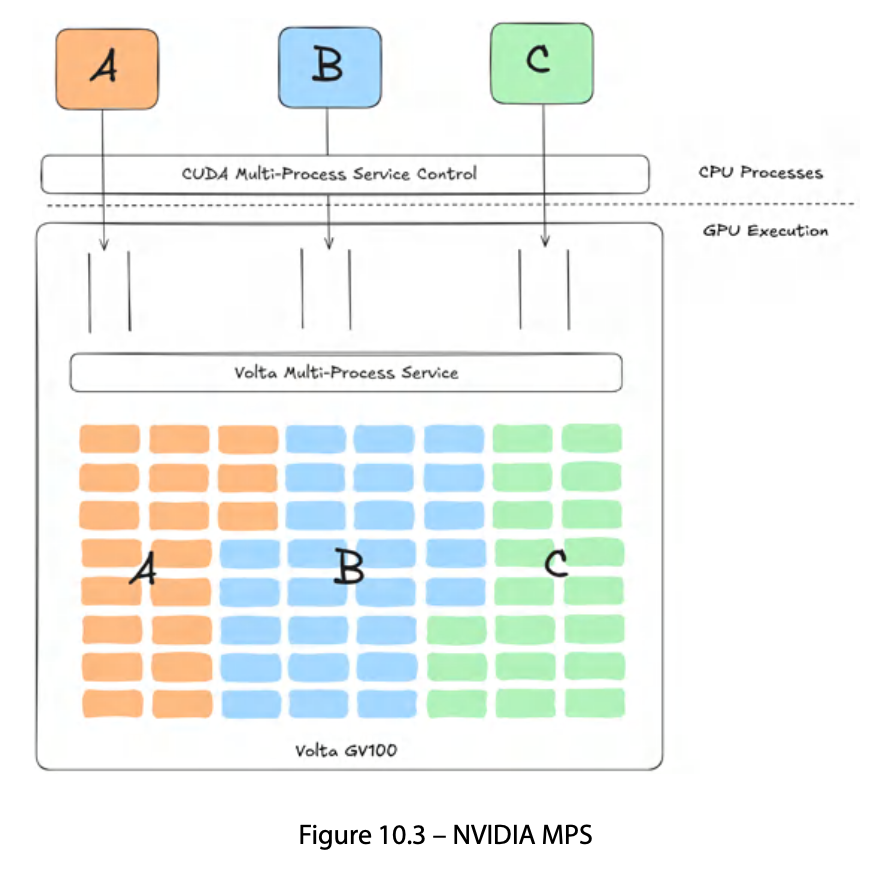
3개 프로세스가 MPS를 통해 SM을 동시에 나눠 쓰는 모습이다. compute는 공간 공유(spatial sharing)다.
MPS의 역사
MPS는 Kepler 아키텍처에서 처음 등장했지만, Volta 아키텍처에서 크게 개선됐다.
| 시기 | 동작 | 메모리 |
|---|---|---|
| pre-Volta MPS | 단일 공유 CUDA context로 합쳐 동시 실행 | 한 주소공간에 다 섞임 → 격리 없음 |
| Volta+ MPS | client별 분리 + 하드웨어 가속 MPS | 프로세스별 주소공간 → 접근 격리 |
pre-Volta도 동시 실행은 했다. 바뀐 건 메모리 격리뿐이다. pre-Volta에서는 MPS Server가 모든 client의 작업을 하나의 공유 CUDA context로 합쳤기 때문에, 프로세스 A가 프로세스 B의 메모리 영역에 접근할 수 있었다. Volta 이후에는 client마다 GPU 주소공간이 분리되어 이 문제가 해결됐다.
무엇이 공유되고 무엇이 격리되나
MPS에서는 compute도 memory도 기본이 “공유”다. MPS의 “memory isolation”이라 불리는 것은 주소공간 접근 격리일 뿐, 용량·대역폭·fault 격리는 없다. MIG와 비교하면 차이가 명확하다.
| 자원 | MPS (Volta+) | MIG |
|---|---|---|
| compute (SM) | 동적 공간 공유 — CUDA_MPS_ACTIVE_THREAD_PERCENTAGE |
GPC 단위 하드 분할 |
| 메모리 주소공간 접근 | 프로세스별 격리 | 하드 분할 |
| 메모리 용량 | 공유 풀 — CUDA_MPS_PINNED_DEVICE_MEM_LIMIT |
slice로 하드 분할 |
| 메모리 대역폭 | 공유 (격리 없음) | slice별 보장 |
| fault isolation | 없음 | 있음 |
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE와CUDA_MPS_PINNED_DEVICE_MEM_LIMIT는 MPS 전용 환경 변수다. MIG는 이런 소프트웨어 상한 변수가 필요 없다 — 분할 자체가 곧 한계선이다.
공유 global memory의 도전과제
MPS에서 여러 프로세스가 동일한 global memory 풀을 공유하면 두 가지 문제가 생긴다:
- synchronization overhead: 여러 프로세스의 커널이 동시에 global memory에 접근하므로, 메모리 접근 순서를 조율하는 오버헤드가 발생한다
- resource contention: 메모리 대역폭이 공유되므로, 한 프로세스의 대량 메모리 접근이 다른 프로세스의 성능을 저하시킨다
Volta의 부분적 개선
Volta 아키텍처는 MPS의 주요 한계 몇 가지를 개선했다:
- 프로세스별 GPU 주소공간 도입: client 간 메모리 접근 분리. pre-Volta처럼 한 주소공간에 뒤섞이지 않는다
- client가 공유 context 없이 GPU에 직접 work 제출: MPS Server를 경유하되, GPU 하드웨어 레벨에서 client별 분리된 채널을 통해 커널을 제출한다
- execution resource provisioning:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE로 client별 SM 사용 상한을 설정할 수 있다
남은 한계: 대역폭 공유(한 프로세스가 대역폭을 독식할 수 있음), fault isolation 없음(한 프로세스의 GPU fault가 같은 MPS Server를 쓰는 모든 프로세스에 영향).
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE의 동작: 이 변수를 50으로 설정하면 해당 client가 쓸 수 있는 SM 비율의 상한(cap)이 50%로 걸린다. 핵심은 이게 상한이지 예약(reservation)이 아니라는 점이다 — 쓰지 않는 나머지 SM이 그 client용으로 떼어 잡히지도, 다른 client의 사용을 막지도 않는다. 즉 한 client가 자기 몫을 넘겨 독식하는 것만 막을 뿐, 각 client에 최소 성능(floor)을 보장하지는 않는다. 비슷하게CUDA_MPS_PINNED_DEVICE_MEM_LIMIT는 메모리 할당 상한을 설정하지만, 할당이 상한 안이라고 해서 대역폭이나 성능이 보장되는 것은 아니다.
K8s에서의 MPS
책 기준으로는, 공식 NVIDIA k8s-device-plugin이 MPS partitioning을 지원하지 않아 nebuly-ai fork로 우회하는 방법이 안내되어 있다.
공식 NVIDIA k8s-device-plugin은 2024년 v0.15.0부터 MPS 공유를 지원한다(릴리스 노트에 experimental로 표기됨). ConfigMap의
sharing.mps.resources[].replicas(축약하면sharing.mps.replicas)를 설정하면 time-slicing과 동일한 방식으로 슬롯이 광고되며, MPS daemon이 Pod 내에서 관리된다. experimental 단계인 만큼 현재 시점의 플러그인 문서를 확인하는 것을 권장한다.
GPU Time-slicing
개념
Time-slicing은 GPU 실행 시간을 슬라이스로 쪼개 여러 프로세스가 순차적으로(sequential) 공유하는 기법이다. GPU가 프로세스 사이를 시간으로 번갈아 가며 실행한다. MPS가 “동시에 여럿”이라면, time-slicing은 “번갈아 하나씩”이다.
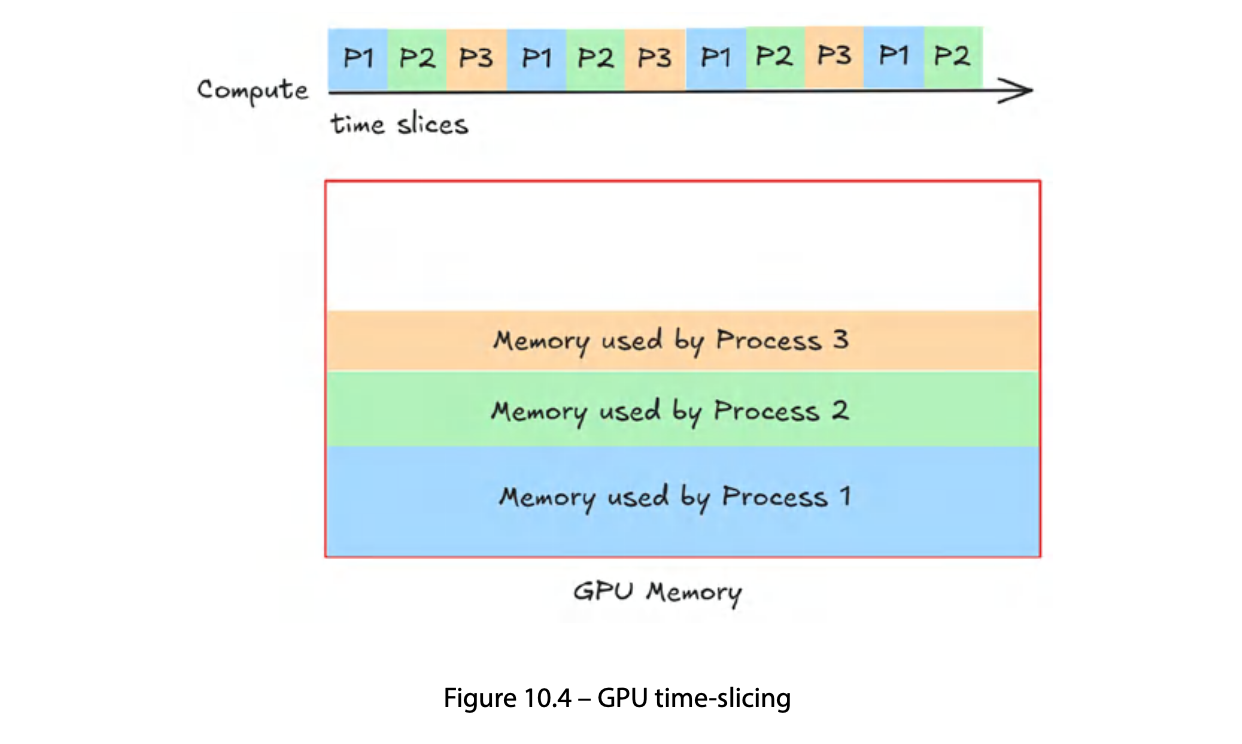
MPS와 대조하면 실행 패턴이 명확해진다:
[MPS — 동시 실행]
시간: ──────────────────────────────→
SM 0~3: [A의 커널][A의 커널][A의 커널]...
SM 4~7: [B의 커널][B의 커널][B의 커널]...
같은 시점에 둘 다 실행
[Time-slicing — 번갈아 실행]
시간: ──────────────────────────────→
SM 전체: [Context A][Context B][Context A][Context B]...
한 시점에 하나만 실행
특징:
- MIG 미지원 구형 GPU에 유용: Pascal 이후 아키텍처면 사용 가능하다. Ampere 이후만 지원하는 MIG보다 호환성이 넓다
- MIG 보완 가능: MIG 인스턴스 위에 time-slicing을 얹어 MIG 인스턴스를 다시 공유할 수 있다
- latency 유발: context-switching 오버헤드가 존재한다. 전환 시 GPU 레지스터·상태를 저장/복원해야 하므로 idle 구간이 생긴다
oversubscription vs interleave: time-slicing은 단일 GPU를 여러 프로세스에 “초과 배정(oversubscription)”하는 것이다. GPU가 시간을 쪼개 프로세스를 번갈아(interleave) 실행하며, 각 프로세스 입장에서는 자기만의 GPU를 가진 것처럼 보인다.
GPU 드라이버의 preemptive context switch가 내부적으로 어떻게 동작하는지(Compute Preemption, timer interrupt, instruction-level vs thread-block-level preemption)에 대해서는 time-slicing 개념·동작 원리에서 상세히 다뤘다.
K8s에서 time-slicing 적용
핵심 흐름: ConfigMap에 timeSlicing.replicas 정의 → device plugin이 물리 1장을 N개 가상 슬롯으로 광고 → Pod들이 슬롯에 배치돼 시분할.
“슬롯”의 정확한 의미: time-slicing의 슬롯은 시간 지분이 아니라 스케줄 토큰이다.
계층 의미 K8s 슬롯 (replicas) “여기에 Pod를 배치할 수 있다”는 스케줄링 단위. 시간이나 메모리의 비율을 보장하지 않는다 실제 시분할 (GPU driver) GPU 드라이버가 timer interrupt로 context를 전환. 슬롯 수와 무관하게 round-robin 즉 replicas를 10으로 설정해도 “각 Pod에 10%의 GPU 시간이 보장된다”는 뜻이 아니다. GPU 드라이버가 시간을 공평하게 나눈다는 QoS 보장도 없다.
ConfigMap 정의
time-slicing 설정의 시작점은 ConfigMap이다. 아래 예시에서 replicas: 10은 물리 GPU 1장을 10개 슬롯으로 광고하겠다는 뜻이다:
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config
namespace: nvidia-gpu-operator
data:
any: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 10
replicas 값 정하기 — MIG와의 결정적 차이
MIG에서 인스턴스 수는 GPU 하드웨어 프로파일에 의해 산술적으로 정해진다. A100이 7개, H100이 7개 — 그 이상은 물리적으로 불가능하다. 그리고 각 인스턴스의 메모리도 하드 분할된다.
time-slicing의 replicas는 임의로 정할 수 있다. 10이든 100이든 ConfigMap에 숫자만 쓰면 된다. 하지만 메모리를 쪼개주지 않는다. 모든 Pod가 동일한 물리 VRAM 풀을 공유한다. replicas를 10으로 잡고 각 Pod가 4GB씩 쓰면 40GB가 필요한데, L4는 24GB다 — OOM이다.
메모리 안전은 사용자 책임이다.
Σ(각 Pod의 메모리 사용량) ≤ 물리 VRAM이어야 한다.
ConfigMap의
renameByDefault,failRequestsGreaterThanOne등 추가 필드의 의미와 설정 방법은 time-slicing ConfigMap 설정에서 다뤘다.
device plugin 또는 GPU Operator에 연결
ConfigMap을 정의한 뒤에는, 이를 device plugin이나 GPU Operator에 연결해야 한다. 세 가지 경로가 있다.
경로 1: device plugin에 직접 연결 (Helm)
helm upgrade -i nvidia-device-plugin nvdp/nvidia-device-plugin \
--version=0.14.5 \
--namespace nvidia-device-plugin \
--create-namespace \
--set config.name=time-slicing-config
경로 2: GPU Operator ClusterPolicy로 연결
kubectl patch clusterpolicies.nvidia.com/cluster-policy \
-n nvidia-gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config", "default": "any"}}}}'
경로 3: Terraform으로 연결
resource "helm_release" "nvidia_gpu_operator" {
name = "nvidia-gpu-operator"
repository = "https://helm.ngc.nvidia.com/nvidia"
chart = "gpu-operator"
namespace = "nvidia-gpu-operator"
version = "v24.9.0"
set {
name = "devicePlugin.config.name"
value = "time-slicing-config"
}
set {
name = "devicePlugin.config.default"
value = "any"
}
}
설정 업데이트의 두 가지 경우
- 최초 연결 (ConfigMap 자체를 처음 연결): device plugin Pod 재시작이 필요하다. Helm upgrade, ClusterPolicy patch, 또는 Terraform apply 후 device plugin DaemonSet이 rolling restart된다
- 내용만 변경 (이미 연결된 ConfigMap의 replicas 등 수정): 버전·구성에 따라 device plugin이 변경을 감지해 자동 반영하기도 하지만, 반영되지 않으면
kubectl rollout restart ds/nvidia-device-plugin으로 device plugin을 재시작해 새 ConfigMap을 다시 읽게 해야 한다
노드별 다른 설정
클러스터에 다양한 GPU가 혼재하는 경우, 노드별로 다른 time-slicing 설정을 적용할 수 있다. ConfigMap에 여러 named key를 정의하고, 노드 라벨로 매핑한다:
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config
namespace: nvidia-gpu-operator
data:
a100: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 8
l4: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 10
노드에 라벨을 붙여 어떤 설정을 적용할지 지정한다:
kubectl label node <a100-node> nvidia.com/device-plugin.config=a100
kubectl label node <l4-node> nvidia.com/device-plugin.config=l4
ClusterPolicy에서 default 키도 지정할 수 있다. 라벨이 없는 노드에는 default 설정이 적용된다.
kubectl patch clusterpolicies.nvidia.com/cluster-policy \
-n nvidia-gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config", "default": "l4"}}}}'
위 예시에서 default: "l4"로 설정하면, nvidia.com/device-plugin.config 라벨이 없는 노드에는 l4 키의 replicas 10 설정이 자동 적용된다.
보고된 GPU 개수 확인
time-slicing 적용 후, 노드의 allocatable GPU 수가 물리 수 × replicas로 뻥튀기되는지 확인한다:
kubectl get nodes -o custom-columns=NAME:.metadata.name,INSTANCE:.metadata.labels."node\.kubernetes\.io/instance-type",GPUs:.status.allocatable."nvidia\.com/gpu"
물리 GPU 1장 + replicas 10이면 allocatable이 10으로 보여야 한다.
time-slicing 적용 전후의 allocatable 변화, 실제 Pod 배치 동작의 검증은 time-slicing 적용·검증에서 상세히 다뤘다.
데모: Llama-3.2-1B
Llama-3.2-1B는 약 1.8GB의 VRAM만 쓴다(정밀도·KV 캐시·런타임에 따라 달라지는 근사값). L4 24GB 기준으로 90%가 넘게 논다. time-slicing으로 10 슬롯을 만들면, Deployment에서 replicas: 5 × nvidia.com/gpu: 2로 설정해 5개 Pod가 각각 2 슬롯을 점유하도록 구성할 수 있다. 1.8GB × 5 = 9GB이므로 24GB VRAM 안에 충분히 들어간다.
Deployment 매니페스트 예시:
apiVersion: apps/v1
kind: Deployment
metadata:
name: llama-3-2-1b
spec:
replicas: 5
selector:
matchLabels:
app: llama-3-2-1b
template:
metadata:
labels:
app: llama-3-2-1b
spec:
containers:
- name: llama
image: <llama-nim-image>
resources:
limits:
nvidia.com/gpu: 2
이 Deployment가 요청하는 총 GPU 슬롯: 5 Pod × 2 슬롯 = 10. time-slicing replicas가 10이므로 물리 L4 1장의 모든 슬롯을 정확히 소진한다.
공유 기법 비교
MPS vs time-slicing
MPS와 time-slicing의 근본적인 차이는 실행 방식이다.
| 항목 | MPS | time-slicing |
|---|---|---|
| 실행 방식 | 동시(concurrent) | 번갈아(serial) |
| 메커니즘 | client들을 합쳐 커널 동시 co-resident | context switch round-robin |
| 비유 | 테이블에 여럿이 같이 앉아 동시에 먹음 | 테이블을 번갈아 쓰는 예약제 |
| 목적 | 빈 SM 채워 활용률↑ | 여러 작업이 GPU에 접근 |
| 메모리 격리 | 주소공간 접근만 (Volta+) | 자원 격리 없음 |
CPU에 빗대 이해: MPS는 멀티코어 병렬(parallelism)에, time-slicing은 단일코어 시분할 동시성(concurrency)에 대응한다. CPU에서 4코어 머신이 4개 스레드를 진짜 동시에 돌리는 게 MPS라면, 단일 코어가 운영체제 스케줄러의 타이머로 4개 프로세스를 번갈아 돌리는 게 time-slicing이다.
GPU의 기본 멀티프로세스 동작이 곧 time-slicing이다. 여러 프로세스가 GPU를 요청하면 드라이버가 context를 번갈아 전환하며 실행한다. MPS는 그 스위칭을 없애고 동시 실행하려고 나온 기능이다. MPS를 끄면 GPU는 자연스럽게 time-slicing으로 돌아간다.
time-slicing의 메모리
time-slicing에서 각 프로세스는 자기 메모리를 따로 잡아(allocate) 쓰고, VRAM에 그대로 남는다. context switch가 발생해도 메모리는 swap-out되지 않는다. allocation ≠ isolation이다.
| 항목 | time-slicing | 비고 |
|---|---|---|
| 주소공간 접근 분리 | 있음 | allocation이 각자이므로 기본적으로 분리 |
| 용량 격리 | 없음 — 공유 VRAM | OOM 위험 |
| 대역폭 격리 | 없음 | 한 프로세스가 대역폭 독식 가능 |
| fault 격리 | 없음 | 한 프로세스의 GPU fault가 다른 프로세스에 영향 |
주소공간 분리의 아이러니: time-slicing은 각 프로세스가 독립된 CUDA context를 가지므로 주소공간이 자연스럽게 분리된다. 반면 pre-Volta MPS는 여러 프로세스를 하나의 공유 context로 합치므로 주소공간이 섞인다. “동시 실행”을 위해 context를 합친 결과, 오히려 격리가 약해진 것이다. Volta+ MPS는 하드웨어 지원으로 context를 분리하면서도 동시 실행을 유지한다.
방식 context 구조 실행 주소공간 분리 time-slicing 각자 context, 직렬 번갈아 있음 pre-Volta MPS 단일 공유 context, 동시 동시 없음 Volta+ MPS 분리 context, 동시 동시 있음
세 기법 종합 비교
MIG, MPS, time-slicing 세 기법을 한눈에 비교한다.
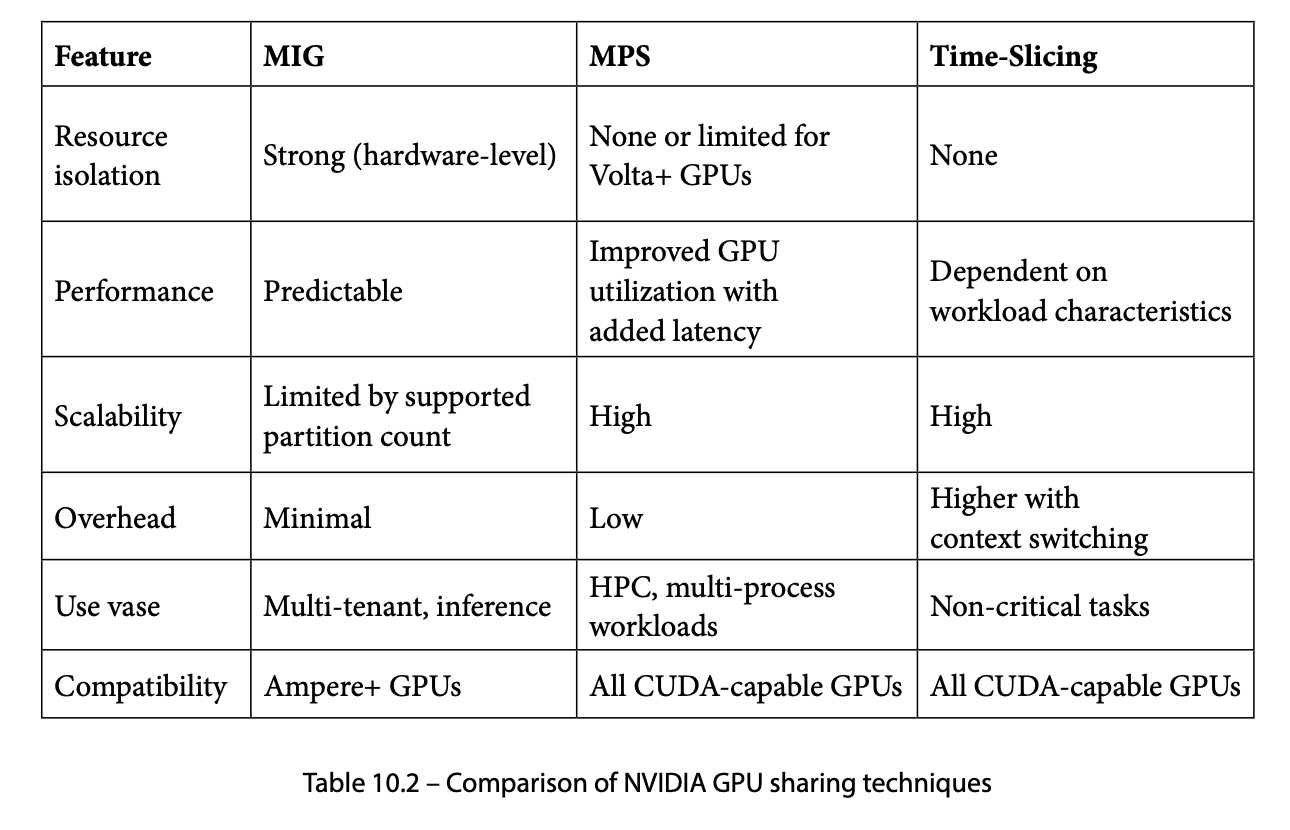
| 항목 | MIG | MPS | Time-slicing |
|---|---|---|---|
| 자원 격리 | 완전 (SM/L2/메모리 하드 분할) | 제한적 (주소공간 접근만) | 없음 |
| 성능 예측 가능성 | 높음 — 전용 SM/메모리 | 중간 — 동적 SM 공유 | 낮음 — context switch 오버헤드 |
| 확장성 | 최대 7 인스턴스 | 최대 48 client (pre-Volta 16) | 제한 없음 (VRAM이 허용하는 한) |
| 오버헤드 | 최소 | 낮음 (context switch 없음) | 높음 (context switch) |
| 사용 사례 | 멀티테넌트 추론, 프로덕션 | HPC/MPI, 경량 추론 병렬화 | 개발/테스트, burst 워크로드 |
| 호환성 | Ampere 이후 (A100, H100, H200) | Kepler+ (격리·HW가속은 Volta+) | Pascal 이후 |
언제 무엇을 쓰나
| 상황 | 추천 기법 | 이유 |
|---|---|---|
| 멀티테넌트 프로덕션, SLA 필요 | MIG | 유일한 하드웨어 격리 |
| GPU 활용률 최적화, 각 작업이 GPU를 조금씩 사용 | MPS | 빈 SM을 다른 프로세스로 채움 |
| 개발/테스트, 간헐적 추론 | time-slicing | 설정 간단, GPU 호환성 넓음 |
| MIG로 큰 파티션 + 파티션 내 추가 공유 | MIG + time-slicing | 격리와 활용률 모두 확보 (k8s-device-plugin은 MIG+time-slicing 지원; MIG+MPS는 CUDA 레벨만) |
셋은 배타적이지 않다. MIG로 큰 칸을 가르고 그 안을 다시 공유하는 스택 구성이 가능하다. 예를 들어 A100을 3g.40gb 2개 MIG 인스턴스로 나눈 뒤, 각 인스턴스 안에서 time-slicing replicas 4를 적용하면 물리 1장으로 8개 슬롯(격리된 2그룹 × 4)을 운용할 수 있다. 단 K8s 맥락에서는 구분이 필요하다 — MIG + time-slicing은 공식 k8s-device-plugin이 지원하지만, MIG + MPS는 현재 k8s-device-plugin이 MIG 활성 장치의 MPS 공유를 지원하지 않는다(CUDA 레벨에선 MIG 인스턴스 위 MPS가 동작하나 플러그인 밖에서 별도로 구성해야 한다).
5가지 GPU 공유 메커니즘(CUDA Streams, Time Slicing, MPS, MIG, vGPU) 전체를 비교한 개요는 GPU 공유 메커니즘 개요를 참고하자.
Ch10 실습으로 이어지기
time-slicing 개념을 EKS + L4 환경에서 검증하려면, 인프라 코드(nvidia-ts.yaml, aiml-addons.tf)와 워크로드 코드(llama32-deploy.yaml)를 먼저 읽고 배포해야 한다. upstream 코드에는 Bottlerocket NVIDIA AMI와 맞지 않는 설정이 남아 있어, 그대로 돌리면 스케줄링은 되는데 추론은 GPU를 못 보는 상태가 된다.
- 10.6 — Ch10 실습 코드 분석: ConfigMap·device plugin·DCGM·Llama Deployment, upstream 결함과 수정 포인트
- 10.7 — Ch10 실습 배포·검증: terraform apply → time-slicing ON/OFF 대조 → HF gated 모델·GPU 주입 트러블슈팅 → nvidia-smi·DCGM 검증
정리
| 항목 | MPS | Time-slicing | MIG |
|---|---|---|---|
| 핵심 원리 | 커널 동시 co-resident (공간 공유) | context switch round-robin (시간 공유) | SM/메모리 하드 분할 |
| 실행 | 동시(concurrent) | 직렬(serial) | 독립(isolated) |
| 메모리 격리 | 주소공간 접근만 (Volta+) | 없음 | 완전 (물리 분할) |
| fault 격리 | 없음 | 없음 | 있음 |
| K8s 적용 | ConfigMap + MPS replicas | ConfigMap + timeSlicing replicas | MIG 프로파일 + 별도 리소스 타입 |
| 호환 GPU | Kepler+ (격리는 Volta+) | Pascal 이후 | Ampere 이후 |
| 스택 가능 | MIG 위 MPS: CUDA 레벨만 (k8s 미지원) | MIG 위 time-slicing: k8s 지원 | 단독 또는 MPS/TS 결합 |
GPU 공유의 핵심은 결국 allocation과 isolation의 균형이다. 격리가 강할수록 안전하지만 유연성이 줄고, 격리가 약할수록 유연하지만 운영 책임이 늘어난다. 워크로드의 특성과 운영 환경에 맞는 기법을 선택하되, 필요하면 스택으로 조합하는 것이 실무적 접근이다.
참고 링크
- Kubernetes for Generative AI Solutions — GitHub
- NVIDIA Multi-Process Service Documentation
- NVIDIA GPU Time-Slicing — Device Plugin

댓글남기기