
[GenAI] GenAI on K8s: 10.7 - Ch10 실습: time-slicing 배포·검증·트러블슈팅
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 10장 hands-on 실습 기록입니다
10.6에서 코드를 읽었다면, 이번 글은 실제로 돌려본 결과다. Step 0~7.5까지 전부 실행했고(2026-06-07), 핵심 트러블슈팅은 upstream 코드 그대로면 광고는 되는데 추론은 GPU를 못 본다는 Bottlerocket 주입 채널 문제였다.
TL;DR
- terraform apply → ConfigMap 없이 plugin Init 대기(광고 1) →
nvidia-ts.yamlapply → 광고 1→10 - Llama 5 Pod Running까지 두 겹 장애: HF gated 403(CrashLoopBackOff) +
cuda=False(GPU 미주입) - GPU 미주입:
envvar× Bottlerocket 비특권 ENV 차단(차단 확정) → CDI는 미검증,volume-mountssmoke test 통과로 수정 후 추론 성공 - time-slicing OFF는
sharing블록 제거(광고 1) →gpu:2Pending 확인.replicas: 1은 plugin 크래시 - nvidia-smi: 물리 L4 1장에 python 5프로세스, VRAM 합산 ~12.8GB/23GB — 메모리 격리 없음의 증거
클러스터 구성 및 time-slicing ON
Step 0: 사전 준비
cd week04/hands-on/ch10
set -a; source ../../../.env; set +a # HF_TOKEN
terraform validate
Ch10은 ch9 teardown으로 secret 자산이 사라졌으므로 Step 4.5에서 다시 만든다 — (1) Secrets Manager hugging-face-secret, (2) SecretProviderClass, (3) my-llama-sa SA.
apply 전 체크 — 아래 두 가지를 확인한다.
meta-llama/Llama-3.2-1BHF gated 접근 사전 승인 (미승인이면 403 CrashLoopBackOff)- g6.2xlarge On-Demand ~$1.20/h — 끝나면 즉시 teardown
Step 1: terraform apply
aiml-addons.tf가 한 번의 apply로 (a) NVIDIA device plugin + GFD/NFD, (b) DCGM-Exporter를 올린다. ConfigMap 자체는 여기서 apply하지 않는다 — 광고량 1→10 변화를 Step 2→3에서 직접 보기 위함.
terraform init
terraform plan # Plan: 129 to add
terraform apply -auto-approve
1차 apply는 addons.tf kubecost에서 clusterId is required로 실패했다. kubecost는 거의 마지막 리소스라 그 직전까지(클러스터·GPU 노드·plugin·DCGM)는 이미 생성됐고, kubecost 블록 주석 후 재apply하니 0 added, 0 changed, 0 destroyed.
apply가 끝나면 콘솔에서 클러스터가 Active 상태인 것을 확인할 수 있다.
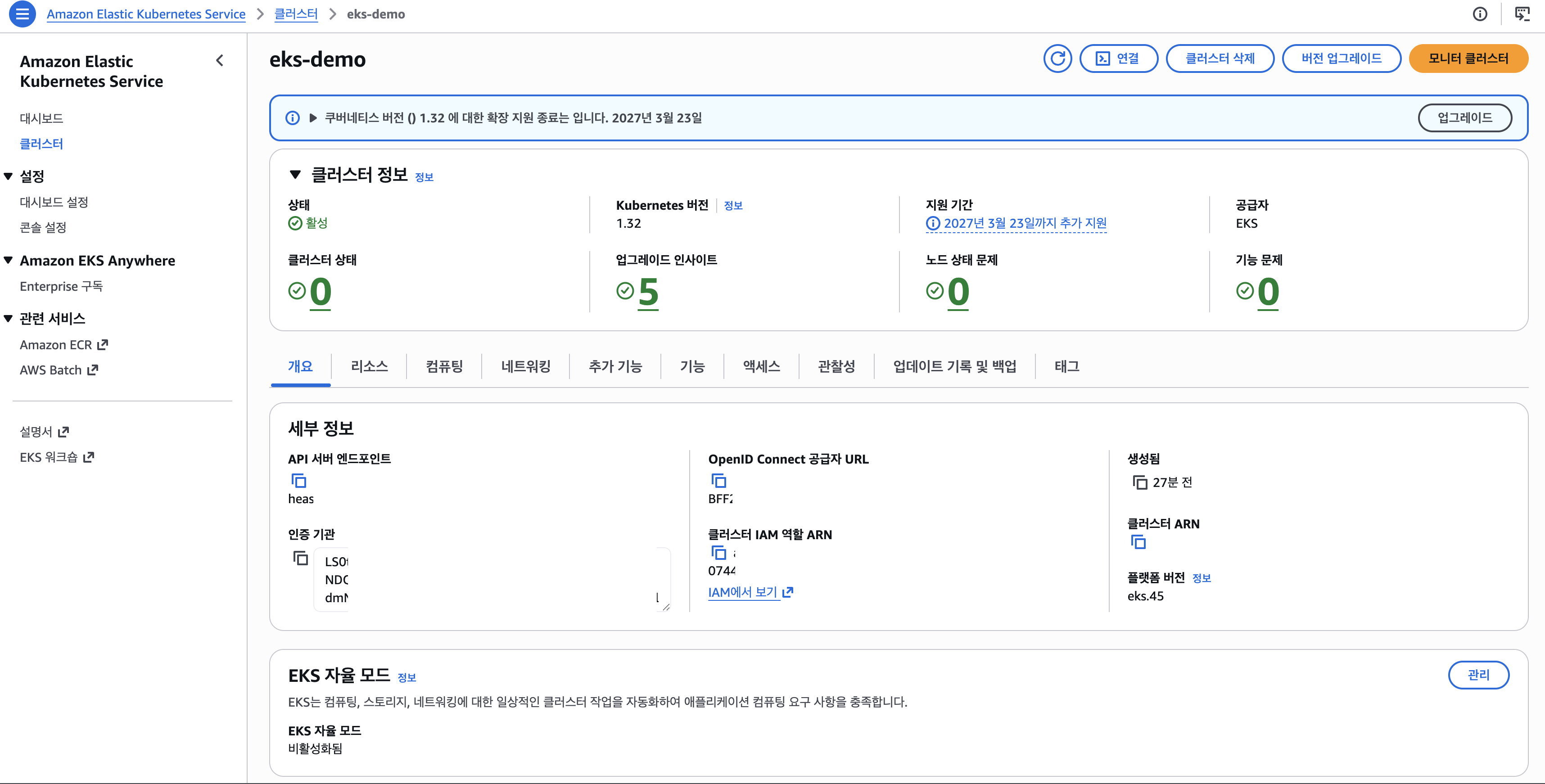
Step 2: ConfigMap 적용 전 (OFF 기준선)
aws eks update-kubeconfig --name eks-demo --region ap-northeast-2
kubectl get nodes -o wide
# GPU 노드: Bottlerocket OS 1.62.0 (aws-k8s-1.32-nvidia)
device plugin은 config.name = time-slicing-config인데 ConfigMap이 없어 init이 막혀 있다. 상태는 다음과 같다.
kubectl get pods -n nvidia-device-plugin
# nvidia-device-plugin-xxx 0/2 Init:0/1
kubectl describe pod -n nvidia-device-plugin <plugin-pod> | grep -A1 FailedMount
# MountVolume.SetUp failed ... configmap "time-slicing-config" not found
kubectl describe node <gpu-node> | grep -A8 Allocatable
# nvidia.com/gpu: 1 ← 아직 1
# ephemeral-storage: 95500736762 ← xvdb 100GB fix (Ch9 18GB 해결)
FailedMount는 kubelet 이벤트다 — init 컨테이너 로그(kubectl logs)에는 안 나온다.kubectl describe pod또는kubectl get events로 본다.
DCGM-Exporter는 ConfigMap과 무관하게 Running 상태다.
kubectl get pods -n dcgm-exporter
# dcgm-exporter-xxx 1/1 Running
Step 3: time-slicing ConfigMap → 광고 1→10
kubectl apply -f nvidia-ts.yaml
# configmap/time-slicing-config created
data.any의 any는 예약어가 아니라 설정 프로파일 이름일 뿐이다. config-manager는 ① 노드 라벨 nvidia.com/device-plugin.config=<키>가 있으면 그 키를, ② helm config.default=<키>가 있으면 그 키를, ③ 둘 다 없고 ConfigMap에 키가 1개뿐이면 그 단일 키를 이름과 무관하게 자동 선택한다. 이 실습은 키가 any 하나뿐이라 ③으로 적용되는 것이고, 이름을 l4-config로 바꿔도 키가 1개면 그대로 광고 10이 된다. 라벨이나 config.default가 필요해지는 건 키를 2개 이상 둘 때이며, 그때 특별 취급되는 이름은 any가 아니라 default다. 자세히는 10.6 — data.any 키.
ConfigMap이 생기면 plugin init의 FailedMount가 풀리고, 보통 1분 안에 Ready가 된다.
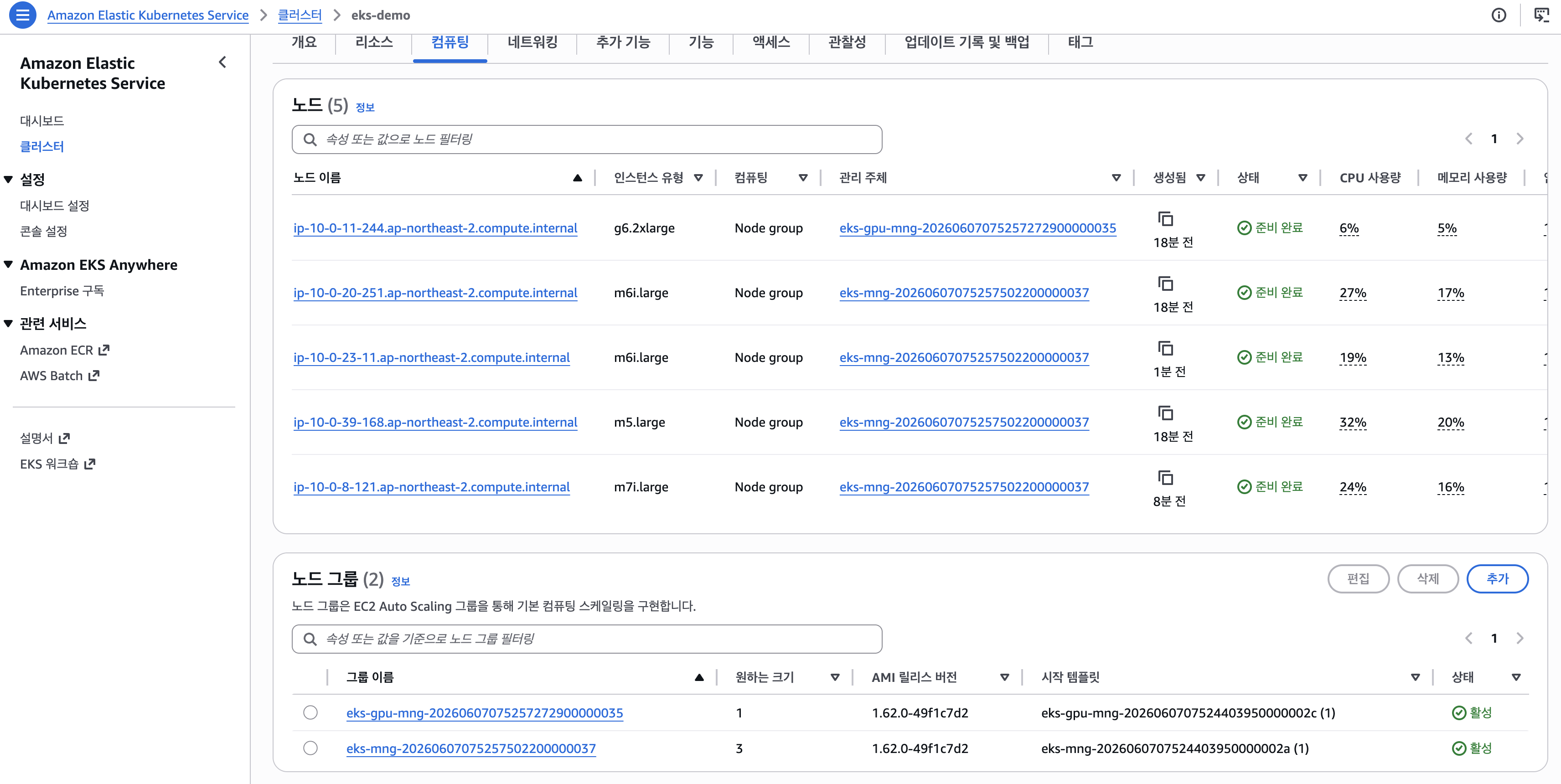
kubectl get ds -n nvidia-device-plugin
# nvidia-device-plugin 1/1 READY
kubectl get nodes -o custom-columns=\
NAME:.metadata.name,INSTANCE:.metadata.labels."node\.kubernetes\.io/instance-type",\
GPUs:.status.allocatable."nvidia\.com/gpu"
# ip-10-0-11-244… g6.2xlarge 10
가드레일 — allocatable이 10이어야 Step 5로 진행한다. 1이면 ConfigMap 미반영이니 kubectl rollout restart ds -n nvidia-device-plugin 후 재확인한다.
Step 4: DCGM 메트릭 (워크로드 전)
kubectl port-forward svc/dcgm-exporter -n dcgm-exporter 9400:9400
curl -s http://localhost:9400/metrics | grep -E "GPU_UTIL|FB_FREE|FB_USED|modelName"
워크로드 전 idle 상태에서 측정한 값은 다음과 같다.
DCGM_FI_DEV_GPU_UTIL{…modelName="NVIDIA L4"…} 0
DCGM_FI_DEV_FB_FREE{…} 22563 # ~22.5GB 여유 (L4 24GB)
DCGM_FI_DEV_FB_USED{…} 0
time-slicing으로 10 슬롯을 광고해도 framebuffer(VRAM)는 쪼개지지 않는다 — 메모리 격리 없음의 첫 증거. 10.2의 DCGM 파이프라인 첫 hop.
Step 4.5: secret 주입
aws secretsmanager create-secret --name hugging-face-secret \
--secret-string "$HF_TOKEN" --region ap-northeast-2
# 이미 있으면 put-secret-value
kubectl apply -f llama32-inf/secret-provider-class.yaml
kubectl create serviceaccount my-llama-sa -n default
# Pod Identity association은 terraform iam.tf에서 생성됨
Llama 배포와 트러블슈팅
Step 5: Llama Deployment & 첫 번째 장애 (HF 403)
kubectl apply -f llama32-inf/llama32-deploy.yaml
kubectl get pods -l app.kubernetes.io/name=my-llama32 -o wide
# 5개 ContainerCreating → 이미지 7.7GB pull ~1m52s → Running (스케줄링 성공)
배치는 성공 — 5 Pod 전부 같은 GPU 노드, time-slicing 10 슬롯에 gpu:2 × 5 = 10 소진.
그런데 로그에는 다음 오류가 보인다.
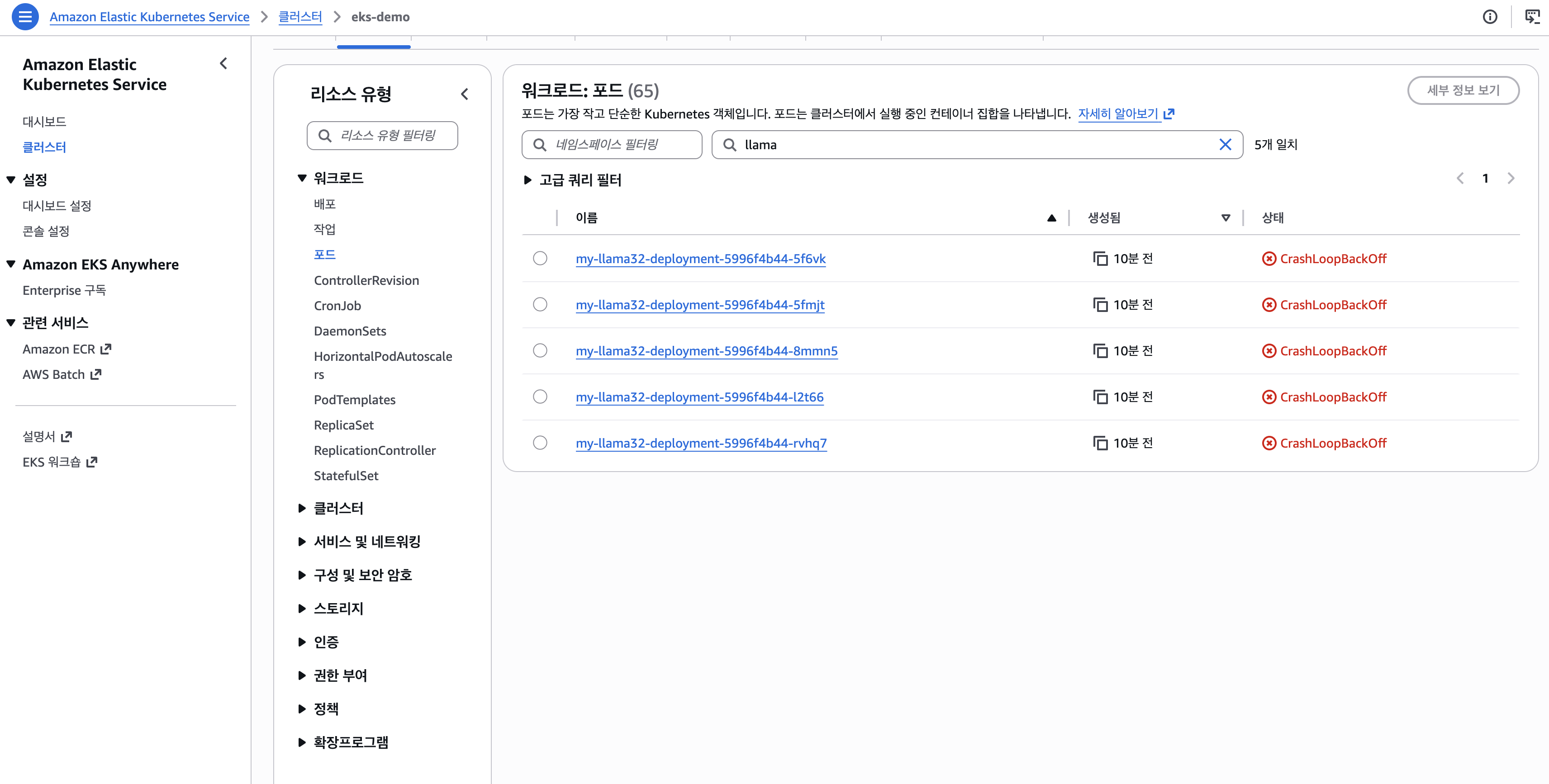
kubectl logs -l app.kubernetes.io/name=my-llama32 --tail=20 | grep -E "gated|403|Model"
# GatedRepoError: 403 Client Error.
# Access to model meta-llama/Llama-3.2-1B is restricted ...
- 토큰은 주입됨(describe에서
HUGGING_FACE_HUB_TOKEN <set>) → 401 아님, 403 = 토큰 유효하나 계정이 gated 접근 미승인 main.py가 import 시점에 모델 로드 → 403 → uvicorn 실패 → CrashLoopBackOff
해결 — HF 모델 페이지에서 Meta 라이선스 동의 → 승인 → kubectl rollout restart deployment my-llama32-deployment
| gated 모델 카드 | 접근 신청 | 승인 |
|---|---|---|
 |
 |
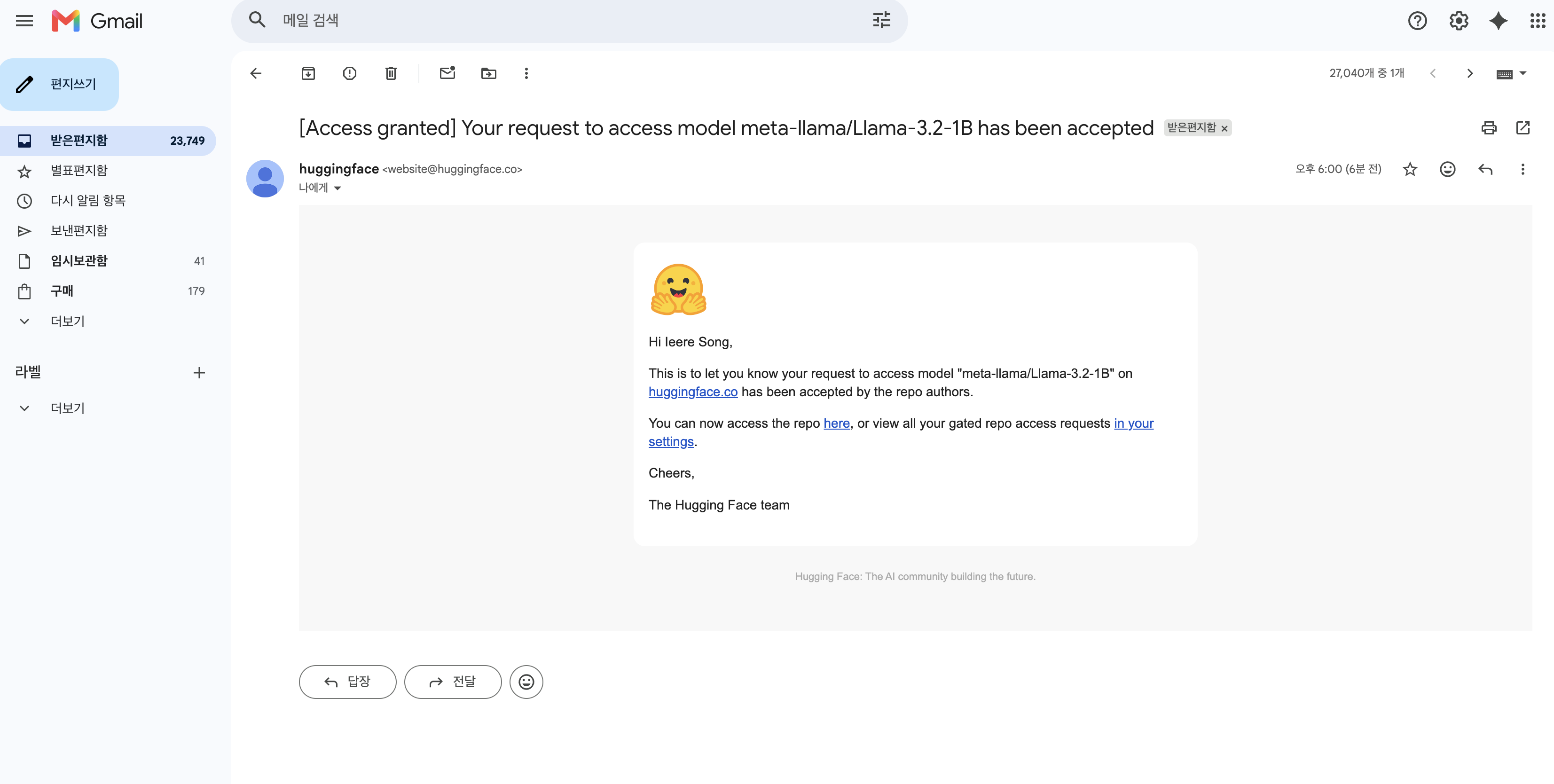 |
Step 5.5: GPU 주입 실패 (진짜 트러블슈팅)
403을 풀어도 로그 상단에는 다음 메시지가 남는다.
NVIDIA Driver was not detected ... torch.cuda.is_available() == False
광고량은 10인데 추론 파드는 GPU를 못 본다.
증상
| 관측 | 값 |
|---|---|
| 노드 광고 | nvidia.com/gpu: 10 (정상) |
| GFD 라벨 | nvidia.com/gpu.product=NVIDIA-L4-SHARED (정상) |
| llama 파드 내부 | cuda=False, nvidia-smi 없음, /dev/nvidia* 없음 (실패) |
| device plugin·DCGM | GPU 정상 인식 (정상) |
진단
# ① 비특권 cuda 파드 gpu:1 → /dev/nvidia* 없음
# ② device plugin 설정
kubectl logs -n nvidia-device-plugin <plugin-pod> -c nvidia-device-plugin-ctr \
| grep -A2 deviceListStrategy
# "deviceListStrategy": ["envvar"] ← ENV로만 전달
# ③ Bottlerocket nvidia-container-runtime (privileged 파드로 /host 마운트)
# accept-nvidia-visible-devices-envvar-when-unprivileged = false ← 비특권 ENV 차단
# ④ device plugin 메인 컨테이너: capabilities.add=[SYS_ADMIN]
# → libnvidia-container가 "privileged"로 간주 → ENV 차단 우회
# ⑤ 동일 cuda 이미지 + SYS_ADMIN만 추가 → nvidia-smi 즉시 동작 (진단용)
근본 원인 — device plugin 기본값 envvar × Bottlerocket 보안 정책. SYS_ADMIN/privileged 인 인프라 파드만 GPU를 받고, 비특권 llama는 못 받는다.
세 deviceListStrategy는 모두 kubelet Allocate()로 “이 GPU를 이 컨테이너에” 전달하는 건 같고, 전달 형태와 주입 실행 주체가 다르다. OCI hook(envvar·volume-mounts) vs runtime-native(CDI) 구분은 컨테이너 장치 주입: OCI Runtime Hook과 CDI 참조. 코드 분석은 10.6.
| 전략 | device plugin이 넘기는 것 | 주입 실행 | 분류 |
|---|---|---|---|
envvar (기본값) |
NVIDIA_VISIBLE_DEVICES=<uuid> |
nvidia-container-runtime OCI hook | hook |
volume-mounts |
/var/run/nvidia-container-devices/<uuid> 마운트 |
같은 hook, mount basename 읽음 | hook |
cdi |
CDI device 이름 / 어노테이션 | containerd가 CDI spec을 OCI spec에 병합 | runtime-native |
envvar vs volume-mounts — 둘 다 같은 nvidia-container-cli hook이 주입한다. Bottlerocket config.toml은 accept-...-envvar-when-unprivileged=false로 env 채널만 비특권에서 차단하고, accept-as-volume-mounts=true로 mount 채널은 허용한다. env는 파드가 NVIDIA_VISIBLE_DEVICES=all을 자가 주장할 수 있는 채널이라 막고, mount는 device plugin Allocate가 세팅한 경로로 신뢰한다.
/var/run/nvidia-container-devices/<uuid> vs /dev/nvidia* — 전자는 plugin이 넣는 요청 신호용 빈 마운트(basename uuid가 “이 GPU” 신호), 후자는 hook 주입 후 컨테이너에 나타나는 진짜 장치 노드다. smoke test의 ls /dev/nvidia0가 주입 성공 증거. 이 volume-mounts 채널은 libnvidia-container 범용 기능이며 Bottlerocket 특유가 아니다 — /dev를 숨기는 게 아니라 env 대신 mount로 요청하라고 강제할 뿐이다.
CDI — hook 없이 /etc/cdi/nvidia.json 선언 + containerd enable_cdi=true로 런타임이 직접 병합하는 패러다임. 이번 노드에 CDI 인프라가 있어 deviceListStrategy=cdi도 됐을 가능성은 높지만, 직접 검증하지 않았다.
이번 실습 검증 결과는 다음과 같다.
envvar: 비특권 cuda gpu:1 →/dev/nvidia*없음 — 차단 확정cdi: 미검증volume-mounts: 비특권 cuda gpu:1 smoke test →nvidia-smi,/dev/nvidia0— 실측 통과. 노드mode=legacy와도 정합
→ env는 막혔고, CDI는 파지 않았고, 확실한 volume-mounts로 확정.
해결: deviceListStrategy: volume-mounts
helm upgrade nvidia-device-plugin nvdp/nvidia-device-plugin --version 0.17.1 \
-n nvidia-device-plugin --reuse-values --set deviceListStrategy=volume-mounts
kubectl -n nvidia-device-plugin rollout restart ds nvidia-device-plugin
# 검증: 비특권 cuda 파드 gpu:1
kubectl run gpu-smoke1 --restart=Never \
--image=nvcr.io/nvidia/cuda:12.4.1-base-ubuntu22.04 \
--overrides='{"spec":{"tolerations":[{"key":"nvidia.com/gpu","operator":"Exists","effect":"NoSchedule"}],"containers":[{"name":"g","image":"nvcr.io/nvidia/cuda:12.4.1-base-ubuntu22.04","command":["sh","-c","nvidia-smi -L; ls /dev/nvidia0"],"resources":{"limits":{"nvidia.com/gpu":"1"}}}]}}'
kubectl logs gpu-smoke1
# GPU 0: NVIDIA L4 (UUID: GPU-…)
# /dev/nvidia0
코드 반영은 aiml-addons.tf device plugin values에 deviceListStrategy: volume-mounts + 주석을 추가한 것이다. 10.6 참조.
주의 — llama에 SYS_ADMIN을 주는 건 해결책이 아니다. 진단 ⑤처럼 cap만 주면 동작하지만 보안 안티패턴이다.
수정 후: 추론 성공
kubectl get pods -l app.kubernetes.io/name=my-llama32
# 5/5 Running, RESTARTS 0
kubectl logs <pod> | grep -iE "device|cuda"
# Device set to use cuda
# Uvicorn running on http://0.0.0.0:80
kubectl run curltest --rm -i --restart=Never --image=curlimages/curl:8.10.1 --command -- \
sh -c 'curl -s -X POST http://my-llama32-svc.default.svc.cluster.local/generate \
-H "Content-Type: application/json" \
-d "{\"prompt\":\"Explain GPU time-slicing in one sentence.\"}"'
# {"response":[{"generated_text":"…GPU time-slicing is the method by which…"}]}
volume-mounts 수정 + HF 승인 → time-sliced 단일 L4 위 5 Pod에서 Llama-3.2-1B 추론이 실제 응답한다.
time-slicing 동작 검증
Step 6: time-slicing OFF → Pending 대조
책에는 없지만, time-slicing이 placement 전제임을 확인한다.
방법 A (권장) — ConfigMap에서 sharing 블록을 제거한다.
kubectl -n nvidia-device-plugin patch cm time-slicing-config --type merge \
-p '{"data":{"any":"version: v1\nflags:\n migStrategy: none\n"}}'
kubectl -n nvidia-device-plugin rollout restart ds nvidia-device-plugin
kubectl describe node <gpu-node> | grep 'nvidia.com/gpu:' # 10 → 1
kubectl scale deployment my-llama32-deployment --replicas=0
kubectl rollout restart deployment my-llama32-deployment
kubectl get pods -l app.kubernetes.io/name=my-llama32
# Pending + FailedScheduling: Insufficient nvidia.com/gpu
# 복구
kubectl apply -f nvidia-ts.yaml && kubectl rollout restart ds -n nvidia-device-plugin
replicas: 1은 OFF가 아니다 — plugin이replicas must be >= 2로 크래시, 광고 0. OFF는 sharing 블록 제거. 배경은 time-slicing 적용·검증 — replicas 값 제한 참조.
방법 B (비권장) — aiml-addons.tf에서 config.name을 제거한 뒤 terraform apply한다.
helm wait=true, timeout=300s 때문에 DaemonSet 롤아웃 실패 → Error: context deadline exceeded, plugin 0·광고 0. 복구는 helm rollback + 코드 원복. OFF 시연은 방법 A만.
Step 7: VRAM 공유 확인 (nvidia-smi)
time-slicing은 VRAM을 격리하지 않는다. hostPID + SYS_ADMIN 파드로 호스트 전체 GPU 프로세스를 본 결과는 다음과 같다.
| 0 NVIDIA L4 | 12831MiB / 23034MiB |
| Processes: |
| 0 151635 C /usr/bin/python3 2546MiB |
| 0 151653 C /usr/bin/python3 2546MiB |
| 0 151801 C /usr/bin/python3 2618MiB |
| 0 151855 C /usr/bin/python3 2546MiB |
| 0 151972 C /usr/bin/python3 2546MiB |
물리 L4 1장에 서로 다른 Pod의 python3 5개 공존, 합산 12831MiB / 23034MiB. MIG M. N/A = 파티션 없이 한 장 공유. 3B 모델이었다면 5×6GB=30GB > 24GB로 깨졌을 것.
Step 7.5: GPU utilization (부하 → DCGM)
5 Pod Running 상태에서 /generate에 동시 부하를 걸면 DCGM 측정값은 다음과 같다.
# baseline (idle)
DCGM_FI_DEV_GPU_UTIL 0
DCGM_FI_DEV_POWER_USAGE 35.4W
DCGM_FI_DEV_FB_USED 12830
# 부하 ~18초 후
DCGM_FI_DEV_GPU_UTIL 100
DCGM_FI_DEV_POWER_USAGE 71.9W # L4 캡
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE 0.0026 # ~0.3% — tensor-core 포화 아님
부하를 주면 GPU_UTIL 0→100, POWER 35→72W로 명확히 반응 — 10.5 HPA가 이 지표를 쓰는 근거. 단 GPU_UTIL=100% ≠ GPU를 알차게 쓴다 — 1B generation은 latency/메모리 바운드. time-slicing 환경에서 GPU_UTIL은 물리 1장(공유) 기준이라 임계치만 보고 스케일하면 over-scaling 위험.
Step 8: HPA (개념만)
DCGM DCGM_FI_DEV_GPU_UTIL → HPA 연동은 prometheus-adapter 파이프라인이 필요하다(Ch12). 이번 실습에서는 Step 7.5로 지표 반응만 확인.
대조군 검증
| 대조 | 기대 |
|---|---|
| 비특권 cuda gpu:1 (volume-mounts 후) | nvidia-smi 출력 = 주입 정상 |
| gpu:11 요청 | Pending — 광고 10이 하드 상한 |
| time-slicing OFF + gpu:2 | Pending — placement 불가 |
| replicas 6 | 6번째 Pending — 5×2=10 소진 |
volume-mounts 수정 전에는 비특권 파드 gpu:1도
nvidia-smi: not found— 이미지 문제가 아니라 GPU 주입 실패.
Teardown & orphan 주의
kubectl delete -f llama32-inf/llama32-deploy.yaml
kubectl delete -f llama32-inf/secret-provider-class.yaml
terraform destroy -auto-approve
aws secretsmanager delete-secret --secret-id hugging-face-secret \
--force-delete-without-recovery --region ap-northeast-2
terraform state 밖 orphan 3종은 아래와 같다.
| 잔존 리소스 | 정체 | 처리 |
|---|---|---|
| EBS 50GB (available) | JupyterHub hub-db-dir PVC 동적 볼륨 | aws ec2 delete-volume |
| ENI (available) | VPC-CNI 파드용 ENI | aws ec2 delete-network-interface |
eks-cluster-sg-* |
EKS 자동 생성 cluster SG | aws ec2 delete-security-group |
destroy 후 available EBS / 잔존 ENI / cluster SG / VPC audit 필수.
이 실습으로 확인한 것
| Step | 확인 |
|---|---|
| 1 | terraform apply — kubecost 주석 후 클러스터·GPU 노드·plugin·DCGM 생성 |
| 2 | ConfigMap 전: plugin Init 대기, 광고 1, ephemeral 95.5GB |
| 3 | ConfigMap apply → 광고 1→10 |
| 4 | DCGM idle: util 0, FB_FREE ~22.5GB (VRAM 미분할) |
| 5 | 5 Pod 한 GPU Running — 403 + cuda=False 두 겹 장애 |
| 5.5 | volume-mounts → 비특권 GPU 주입 + Llama 추론 성공 |
| 6 | sharing 제거 → 광고 10→1 → gpu:2 Pending |
| 7 | nvidia-smi: 5 python 프로세스, VRAM 합산 ~12.8GB |
| 7.5 | 부하 → GPU_UTIL 100%, TENSOR_ACTIVE ~0.3% |
결론
Ch10은 GenAI 워크로드를 K8s에서 돌릴 때 GPU 자원을 어떻게 할당·분할·공유·관측·스케일링할지를 다룬 장이다. GPU는 비싸고 대부분 저활용 상태로 놓인다는 전제에서, “더 많이 산다”보다 “가진 것을 더 잘 쓴다”가 핵심이다.
할당의 출발점은 10.1에서 정리했다. NVIDIA GPU뿐 아니라 AWS Inferentia·Trainium, Google TPU 같은 커스텀 AI/ML 가속기도 device plugin을 통해 K8s extended resource로 광고·스케줄링할 수 있다. LLM 학습·저지연 추론처럼 워크로드 특성에 맞는 칩을 고르고, NFD/GFD와 device plugin이 노드 특성을 라벨·allocatable로 올려 주는 흐름이 전제다.
활용률을 보려면 측정이 먼저다. 10.2에서 DCGM이 GPU utilization·memory·power 같은 텔레메트리를 수집하고, DCGM-Exporter가 Prometheus 포맷으로 노출하는 파이프라인을 봤다. “GPU가 바쁘다”와 “워크로드가 잘 돌아간다”는 같지 않다 — 이후 스케일링에서 다시 마주친다.
한 장을 나눠 쓰는 기법은 격리 수준과 실행 방식이 다르다.
- 10.3 MIG — SM·메모리를 하드웨어로 분할. 멀티테넌트·SLA에 가장 강한 격리
- 10.4 MPS — 여러 프로세스가 SM을 동시에 공유. 빈 SM을 채워 활용률을 올림
- 10.4 time-slicing — context를 번갈아 실행. MIG 미지원 GPU에서도 슬롯을 늘려 placement 가능. 메모리 격리는 없어 VRAM 합산은 사용자 책임
셋은 배타적이지 않다. MIG로 큰 칸을 가른 뒤 그 안을 MPS·time-slicing으로 다시 공유하는 스택도 가능하다.
스케일링과 서빙은 10.5에서 마무리했다. DCGM 메트릭 → Prometheus → prometheus-adapter → HPA 체인으로 GPU 사용률 기반 오토스케일링이 가능하지만, GPU_UTIL 단독은 phantom utilization·공유 GPU 왜곡에 취약하다. throughput·latency 같은 application 지표 병행이 필요하다. NVIDIA NIM은 모델 + 최적화 엔진 + 서빙 런타임 + 표준 API를 한 컨테이너에 포장한 추론 마이크로서비스로, “인프라에서 GPU를 나눠 쓰기”와 “애플리케이션에서 모델을 서빙하기”를 연결한다.
실습(10.6 · 10.7)은 time-slicing 한 축을 EKS + L4에서 끝까지 검증했다. 물리 GPU 1장을 10 슬롯으로 광고하고 Llama-3.2-1B 5 Pod를 한 노드에 올리는 placement, OFF 시 gpu:2 Pending, nvidia-smi로 VRAM 공유 확인까지 — 10.4의 개념이 코드·클러스터에서 어떻게 드러나는지를 붙였다. 동시에 upstream 그대로면 스케줄링은 되는데 추론은 GPU를 못 보는 함정(deviceListStrategy=envvar × Bottlerocket env 차단)과 HF gated 403처럼, 이론만으로는 안 보이는 운영 이슈도 확인했다.
클라우드 GPU는 수요가 공급을 앞서는 경우가 많아, Ch10에서 다룬 분할·공유·관측·스케일링은 “있는 GPU를 더 잘 쓰는” 쪽에 무게가 실린다. 다음 장(Ch11)에서는 K8s observability best practice로 더 깊이 들어간다.
참고 링크
- NVIDIA k8s-device-plugin — device list strategy
- 컨테이너 장치 주입: OCI Runtime Hook과 CDI
- time-slicing 적용·검증 — replicas 값 제한
- Bottlerocket — NVIDIA variant
- meta-llama/Llama-3.2-1B (gated)

댓글남기기