
[GenAI] GenAI on K8s: 11.2 - Kubeflow 생태계: Notebooks, Katib, Pipelines, KServe
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 11장의 학습 내용을 바탕으로 합니다
11.1에서 GenAI 파이프라인 5단계를 봤다. 이번 글은 그 파이프라인을 K8s-native로 구현하는 Kubeflow 생태계를 정리한다 — Notebooks, Katib, Pipelines, KServe의 책임 경계와 Profile 기반 multi-tenant 구조가 핵심이다.
TL;DR
- Kubeflow는 K8s 추상화 위에 ML 도구를 올린 end-to-end 플랫폼 — 하드웨어 통합이 아니라 CRD·controller 기반 오케스트레이션
- Kubeflow Notebooks = Jupyter + K8s 자원 할당·Profile 격리·S3/IAM wiring
- Katib = HPO 전용 (trial N회), Pipelines = end-to-end DAG — 보완 관계, Pipelines 백엔드는 Argo Workflows
- KServe = InferenceService CRD로 real-time/batch 서빙, Knative 0-to-N, canary/A/B — Kubeflow 밖에서 학습된 모델도 서빙 가능
Kubeflow 개요
K8s 환경에서 GenAI 모델을 관리·실행하기 위한 통합 ML 플랫폼이다. GenAI는 상당한 컴퓨팅 자원과 분산 워크플로우를 필요로 하는데, Kubeflow가 이 지점에서 가치를 더한다.
- 분산 학습: TensorFlow, PyTorch 등과 통합해 거대 모델 학습
- GPU/custom accelerator 병렬 처리: 학습 시간 단축 + 자원 활용 효율화
- K8s 오케스트레이션: 워크로드 수요에 따라 scale up/down. GenAI는 학습·추론 단계마다 컴퓨팅 요구가 들쭉날쭉해서 elasticity가 중요
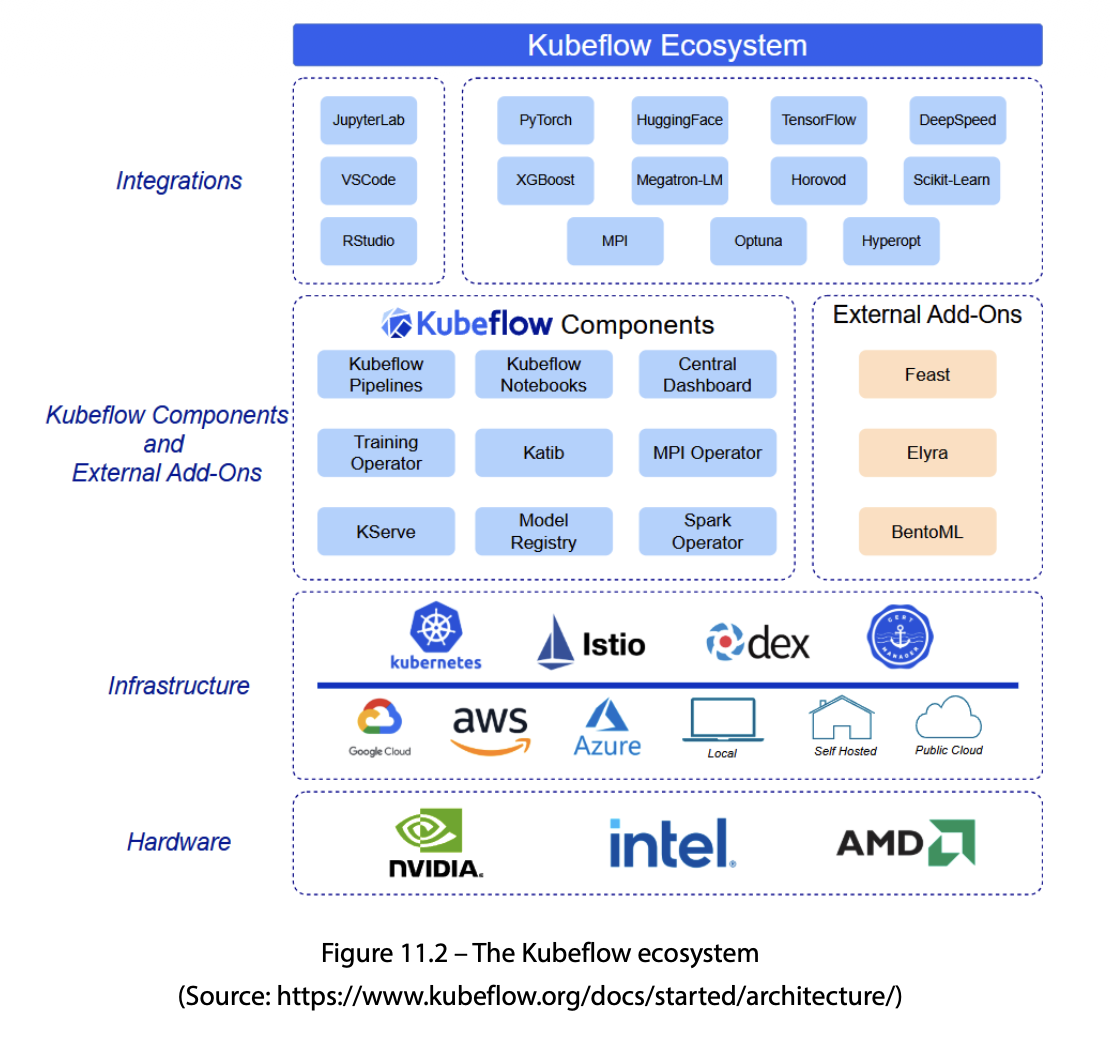
Kubeflow는 하드웨어를 통합하는 것이 아니라, K8s가 제공하는 컴퓨팅·스토리지·네트워킹 추상화 위에 ML 도구들을 올린 묶음이다. 각 컴포넌트는 K8s CRD + controller로 구현되어 kubectl·GitOps와 자연스럽게 통합된다. 이번 글에서 다룰 주요 컴포넌트는 아래와 같다.
| 컴포넌트 | 역할 |
|---|---|
| Kubeflow Pipelines | end-to-end ML 워크플로우 DAG 오케스트레이션 |
| Kubeflow Notebooks | K8s 위 Jupyter 개발 환경 |
| Katib | 자동화 HPO (Hyperparameter Optimization) |
| Training Operator | PyTorchJob/TFJob 등 분산 학습 CRD |
| KServe | 확장 가능한 model inference |
| Central Dashboard | 통합 UI |
Kubeflow 핵심 컴포넌트
개요의 컴포넌트 표에서 핵심 네 개 — Notebooks · Katib · Pipelines · KServe — 를 책임 경계 중심으로 본다. 실험 환경(Notebooks) → HPO(Katib) → end-to-end DAG(Pipelines) → 서빙(KServe) 순으로, 모델 라이프사이클을 따라간다.
Kubeflow Notebooks
K8s가 관리하는 인프라 위에서 Jupyter notebook을 띄우는 web 기반 개발 환경이다. GenAI 프로젝트의 experimentation 단계에 특히 적합하다.
로컬 Jupyter Notebook과의 차이
Notebook UI는 같지만, 로컬에서 jupyter notebook으로 띄우는 것과 Kubeflow가 K8s Pod로 띄우는 것은 운영 모델이 완전히 다르다. 아래 표로 핵심 차이를 정리한다.
| 항목 | Jupyter Notebook | Kubeflow Notebooks |
|---|---|---|
| 사용자 모델 | 단일 사용자 | multi-tenant (Profile 단위 격리) |
| 자원 할당 | 호스트 머신 | K8s 리소스 요청 — GPU 동적 할당, namespace quota |
| 환경 표준화 | 사용자 직접 설치 | 관리자 표준 notebook image (pre-install) |
| 접근 제어 | OS 사용자 | Kubeflow RBAC (Profile + namespace) |
| 외부 통합 | 별도 설정 | S3·IAM·KMS·시크릿 Profile 단위 wiring |
| 공유·협업 | 파일 전달 / Git | Central Dashboard에서 클러스터 사용자 간 공유 |
본질은 같은 Jupyter지만, 운영 관점에서 K8s-native로 통합된 형태다. GPU-intensive GenAI 워크로드에 유리하다.
참고 — Jupyter Notebook / JupyterHub / Kubeflow Notebooks
위 표는 로컬 Jupyter Notebook(단일 사용자가 자기 머신에서
jupyter notebook으로 띄우는 것)과 Kubeflow Notebooks를 비교했다. K8s 위 노트북 환경까지 넓히면 JupyterHub가 중간 층위다. Ch5·10.6 aiml-addons에서 배포한 JupyterHub는 클러스터 공용 multi-user 허브이고, Kubeflow Notebooks는 Profile·파이프라인·서빙까지 같은 ML 플랫폼에 통합된 형태다. Hub와 Kubeflow Notebooks는 둘 다 K8s 노트북이라 역할이 겹치지만, 플랫폼 통합 범위가 다르다.
Kubeflow RBAC과 Profile
위 표에서 “Kubeflow RBAC”이 나왔는데, 이름만 보면 K8s RBAC과 같은 것처럼 보인다. 실제로는 K8s RBAC을 대체하지 않고, 그 위에 ML 사용자/팀 관점의 추상을 얹은 확장 계층이다.
K8s RBAC은 (User/ServiceAccount, Verb, Resource) 단위로 권한을 정의한다. Kubeflow는 그 위에 Profile 추상을 얹어 multi-user 환경을 표현한다.
- Profile = 사용자/팀 단위 격리. 하나의 Profile = 하나의 namespace + RoleBinding + resource quota
- Profile Controller가 Profile CR 생성 시 K8s namespace · RBAC · quota · serviceaccount를 자동 reconcile
- notebook을 띄우면 해당 Profile namespace 안의 Pod으로 뜨고, 다른 Profile은 접근 불가
정리하면 Kubeflow RBAC은 “Profile + 자동 K8s RBAC 매핑”이다. ML 엔지니어는 Profile 단위로 notebook·파이프라인·서빙 자원을 쓰고, 실제 권한 enforcement는 여전히 K8s RBAC이 담당한다.
Katib — 하이퍼파라미터 튜닝
Notebooks로 실험 환경을 잡았다면, 다음 병목은 종종 하이퍼파라미터다. GenAI에서 HPO는 모델 성능을 결정짓는 핵심 단계이고, Katib은 Kubeflow의 자동화 HPO 도구다.
- 학습 코드를 여러 하이퍼파라미터 조합으로 N번 trial — concurrent 실행으로 탐색 가속
- 알고리즘: Random Search, Grid Search, Bayesian Optimization, Hyperband, TPE, NAS 등
- 각 trial은 K8s Job 또는 워크플로우 step — trial orchestrator plug-in (기본: K8s Job, 옵션: Argo Workflows / Tekton)
Katib와 Kubeflow Pipelines — 책임 경계
Katib만 보면 “하이퍼파라미터만 튜닝하는 도구”로 끝나는데, 전처리·학습·배포까지 묶으려면 Pipelines가 필요하다. 둘 다 워크플로우를 돌리지만 담당 범위가 다르다. Katib는 HPO trial에 특화되고, Pipelines는 end-to-end ML DAG 전체를 오케스트레이션한다.
| 항목 | Katib | Kubeflow Pipelines |
|---|---|---|
| 목적 | HPO 전용 | end-to-end ML 워크플로우 자동화 |
| 단위 | 같은 코드, 다른 하이퍼파라미터 N회 (trial) | 전처리·학습·평가·배포 DAG |
| 결과 | 최적 하이퍼파라미터 + 모델 | 실행 기록 + artifact + 메트릭 |
| 워크플로우 엔진 | 옵션 (K8s Job / Argo / Tekton) | Argo Workflows (default) |
Pipelines 안에 Katib step을 두는 조합이 흔하다 (전처리 → Katib HPO → 최적 모델 학습 → 배포). 경쟁 관계가 아니라 보완 관계다. 다음 절에서 Pipelines 자체를 본다.
Kubeflow Pipelines
Katib가 HPO trial에 집중한다면, Pipelines는 데이터 전처리·모델 학습·배포를 포함한 복잡한 워크플로우 전체를 오케스트레이션한다.
- 파이프라인을 DAG(Directed Acyclic Graph)로 정의 — 재현성 + manual intervention 최소화
- 각 step은 컨테이너화된 컴포넌트, step 간 입출력은 artifact로 전달
- 백엔드는 Argo Workflows — Pipelines가 high-level DSL, 실행은 Argo가 담당 (11.4에서 Argo 상세)
- ML metadata store 통합 — run, parameter, metric, artifact 추적
KServe — 모델 서빙
Pipelines로 학습·평가까지 끝냈다면 다음은 서빙이다. KServe는 학습 완료된 모델을 K8s 클러스터에 확장 가능·효율적으로 배포하는 inference 플랫폼이다.
- Batch / Real-time inference 모두 지원
- InferenceService CRD — 모델 URI(S3, GCS 등)와 framework 지정 → predictor Pod 자동 생성
- Dynamic scaling (Knative serverless 0-to-N), A/B testing, canary deployment, multi-model serving
- framework predictor: TensorFlow, PyTorch, ONNX, Scikit-learn, XGBoost, HuggingFace, vLLM 등
- Kubeflow 외부에서 학습된 모델도 서빙 가능 — KServe는 Kubeflow 일부이지만 Kubeflow 의존성 없이 단독 사용 가능
책이 “Once models are trained, KServe provides…“라고 쓴 것은 라이프사이클 흐름 강조이지, Kubeflow 내부 학습 모델만 다룬다는 뜻이 아니다.
Kubeflow가 GenAI에 가치 있는 이유
위 컴포넌트를 묶으면 GenAI 워크로드에 왜 Kubeflow를 쓰는지가 보인다.
- 전처리(augmentation, feature extraction)를 파이프라인에 통합 → 일관된 data preparation 강제
- dataset·모델·메트릭을 artifact repository에 저장 → 재현성
- metadata tracking으로 pipeline run·artifact·실험 추적 → debugging·retraining 간소화
- LLM 워크플로우 템플릿 → fine-tuning·배포 효율화
- multi-tenant + namespace isolation → 팀 간 자원 충돌 방지, compliance
- full ML cycle 자동화로 데이터 사이언티스트·DevOps 부담 감소
정리
| 컴포넌트 | CRD/패턴 | 책임 |
|---|---|---|
| Notebooks | Notebook CR | K8s 위 실험 환경, Profile 격리 |
| Katib | Experiment/Trial CR | HPO trial 오케스트레이션 |
| Pipelines | PipelineRun CR → Argo | end-to-end ML DAG |
| Training Operator | PyTorchJob/TFJob | 분산 학습 |
| KServe | InferenceService CR | real-time/batch inference, canary |
Kubeflow Training Operator(PyTorchJob)와 Ray Train의 선택 기준은 11.5에서 비교한다.

댓글남기기