
[GenAI] GenAI on K8s: 11.3 - MLflow: Tracking, Model Registry, Models
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 11장의 학습 내용을 바탕으로 합니다
11.2에서 K8s-native Kubeflow를 봤다. MLflow는 반대로 K8s 의존성 없이 동작하는 실험 추적·모델 관리 플랫폼이다. K8s 위에 올리면 HA·영구 볼륨 이점을 얻지만, 핵심은 tracking server + 두 저장소(backend/artifact) 구조다.
TL;DR
- MLflow 4개의 컴포넌트(Tracking, Models, Model Registry, Projects)는 별도 서비스가 아니라 tracking server 1대 + backend store + artifact store 조합
- Tracking 계층: Server → Experiment → Run → params/metrics/tags/artifacts
- Model Registry v2는 alias 포인터 방식 — stage 고정 이름·다중 버전 공존 문제를 해소
- alias = 서빙이 로드할 버전 포인터, tags = compliance-reviewed 같은 감사·컴플라이언스 메타 (alias로 표현 안 되는 정보)
MLflow 개요
ML 라이프사이클 전반(실험·모델 버전 관리·재현성)을 단순화하는 오픈소스 플랫폼이다. MLflow 자체는 K8s 의존성이 없다 — Python 라이브러리 + tracking server로 동작한다.
| 컴포넌트 | 역할 |
|---|---|
| Tracking | 실험·run·파라미터·메트릭·artifact 기록 |
| Models | 모델을 표준 포맷으로 저장/배포 (MLmodel descriptor) |
| Model Registry | 모델 버전 관리, alias 전환 |
| Projects | 재현 가능한 실행 패키징 (MLproject YAML) |
네 컴포넌트는 별도 서비스로 배포되는 게 아니라 한 MLflow tracking server 안에 통합된다. tracking server 1대 + backend store(DB) + artifact store(파일 시스템/S3) 조합이 표준이다.
K8s에 배포하면 영구 볼륨·HPA·HA 이점을 얻고, Model Registry도 같은 server 프로세스 안 컴포넌트이므로 별도 배포 단위가 아니다.
MLflow 핵심 컴포넌트
MLflow Tracking
네 컴포넌트 중 Tracking이 실험 기록을 담당한다. 학습 코드가 남기는 파라미터·코드 버전·메트릭·artifact를 API/UI로 추적한다. 구조를 이해하려면 세 가지를 순서대로 보면 된다 — 데이터가 어떤 계층으로 묶이는지, tracking server가 무엇인지, 메타데이터와 바이너리가 어디에 나뉘어 저장되는지.
Tracking 계층 구조: Experiment → Run
한 번의 fit() 호출이 UI에 어떻게 기록되는지부터 보면 Tracking API 사용법이 자연스럽다. tracking server 아래 Experiment가 관련 run을 묶고, 각 Run이 params/metrics/tags/artifacts를 담는다.
# Tracking Server (http://localhost:5000)
# └── Experiment ("autolog-demo") ← 관련 run 묶음
# └── Run (caring-whale-40) ← 한 번의 학습 실행
# ├── Parameters (C, max_iter, solver, ...)
# ├── Metrics (training_score 등)
# ├── Tags (mlflow.source, autolog 관련 등)
# └── Artifacts (model/ 디렉토리)
- Experiment: 관련 run을 묶는 논리 단위. 보통 프로젝트/태스크 단위
- Run: 모델을 한 번 학습/평가한 단위. autolog가
caring-whale-40등 랜덤 이름 자동 부여
Tracking server
위 계층 구조의 진입점이다. tracking server는 HTTP API·UI를 제공하고, 클라이언트(학습 코드)가 보낸 로그를 backend store·artifact store로 라우팅하는 게이트웨이 역할을 한다.
- 클라이언트(학습 코드)가 로그를 보내는 HTTP 서버
- Experiment/Run 메타데이터와 Artifacts(모델, 체크포인트, plot, confusion matrix 등) 모두 추적
Backend store와 Artifact store
tracking server는 대용량 파일을 자체 보관하지 않는다. Run 메타데이터(경량)와 artifact(대용량 바이너리)를 두 저장소로 분리하는 게 MLflow 운영의 핵심이다.
| 구분 | Backend store | Artifact store |
|---|---|---|
| 저장하는 것 | run/metric/param/tag, 레지스트리 메타 | 모델·이미지·로그 파일 |
| 저장 형태 | DB (관계형) | 파일 시스템 / 오브젝트 스토리지 |
| 설정 | backend-store-uri |
artifacts-destination / artifact-root |
| 운영 권장 | PostgreSQL (HA) | S3 |
backend-store-uri로 메타데이터 DB, artifact-root로 .pkl, .pt, .onnx, 이미지 등 바이너리를 분리 저장한다.
MLflow Model Registry
Experiment Tracking(runs)과 분리된 “배포 가능한 모델 카탈로그”다. 어떤 모델 버전이 어느 환경에서 서빙되는지 팀 전체가 추적한다.
- lineage·versioning·aliasing·tagging·annotation을 중앙 관리
- v1: staging/production/archived stage → v2~: alias 방식이 표준 (stage는 공식 deprecated — 향후 메이저 릴리스에서 제거 예정)
Stage (v1): 고정 4단계
v1에서는 각 버전에 None → Staging → Production → Archived 고정 상태가 있었다.
# serving 코드 — 버전 번호 대신 stage 이름 참조
model = mlflow.sklearn.load_model("models:/fraud-detector/Production")
모델을 교체할 때는 UI에서 각 버전의 stage를 옮기면 된다. 예를 들면 Version 1을 Production에서 Archived로, Version 2를 Staging에서 Production으로 바꾸는 식이다.
Version 1: Production → Archived
Version 2: Staging → Production
serving 코드를 건드리지 않아도 다음 load_model() 호출 시 Version 2가 올라온다.
다만 stage 방식은 운영이 복잡해질수록 한계가 드러난다.
- 이름 고정:
None·Staging·Production·Archived네 이름이 고정되어 있어shadow,canary,champion처럼 팀이 실제로 쓰는 배포 상태를 표현하기 어렵다 - 버전 공존: 같은 stage에 여러 버전이 공존할 수 있어서 “지금 serving 중인 게 정확히 어떤 버전이야?”가 불명확해지기도 한다
- 팀마다 다른 해석: Staging이 QA 환경인지 pre-prod인지 팀마다 해석이 달라 충돌이 생긴다
이런 운영 한계가 v2에서 alias 방식을 도입한 배경이 된다.
Alias (v2~): 포인터 방식
자유롭게 이름 붙이는 포인터로 전환한다.
# serving 코드 — @alias 형식
model = mlflow.sklearn.load_model("models:/fraud-detector@champion")
모델 교체는 API 한 줄로도 가능하다.
from mlflow import MlflowClient
client = MlflowClient()
# alias "champion"이 가리키는 버전을 2로 변경
client.set_registered_model_alias("fraud-detector", "champion", 2)
serving 코드(@champion)는 그대로인데, 다음 load_model() 호출 시 Version 2가 올라온다. alias를 옮긴다 = 포인터가 가리키는 버전이 바뀐다 = 서빙되는 모델이 바뀐다. 네트워크 트래픽 라우팅이 아니라 “어떤 모델 파일을 로드하느냐”가 전환되는 것이다.
v1 stage와 v2 alias는 이름·배타성·전환 API·serving 참조 방식이 아래와 같이 다르다.
| 항목 | Stage (v1) | Alias (v2~) |
|---|---|---|
| 이름 | Staging / Production / Archived 고정 | 자유 지정 |
| 배타성 | 동일 stage에 여러 버전 공존 가능 | alias 하나 = 하나의 버전 |
| 전환 API | transition_model_version_stage() |
set_registered_model_alias() |
| serving 참조 | models:/name/Production |
models:/name@champion |
Champion / Challenger 패턴
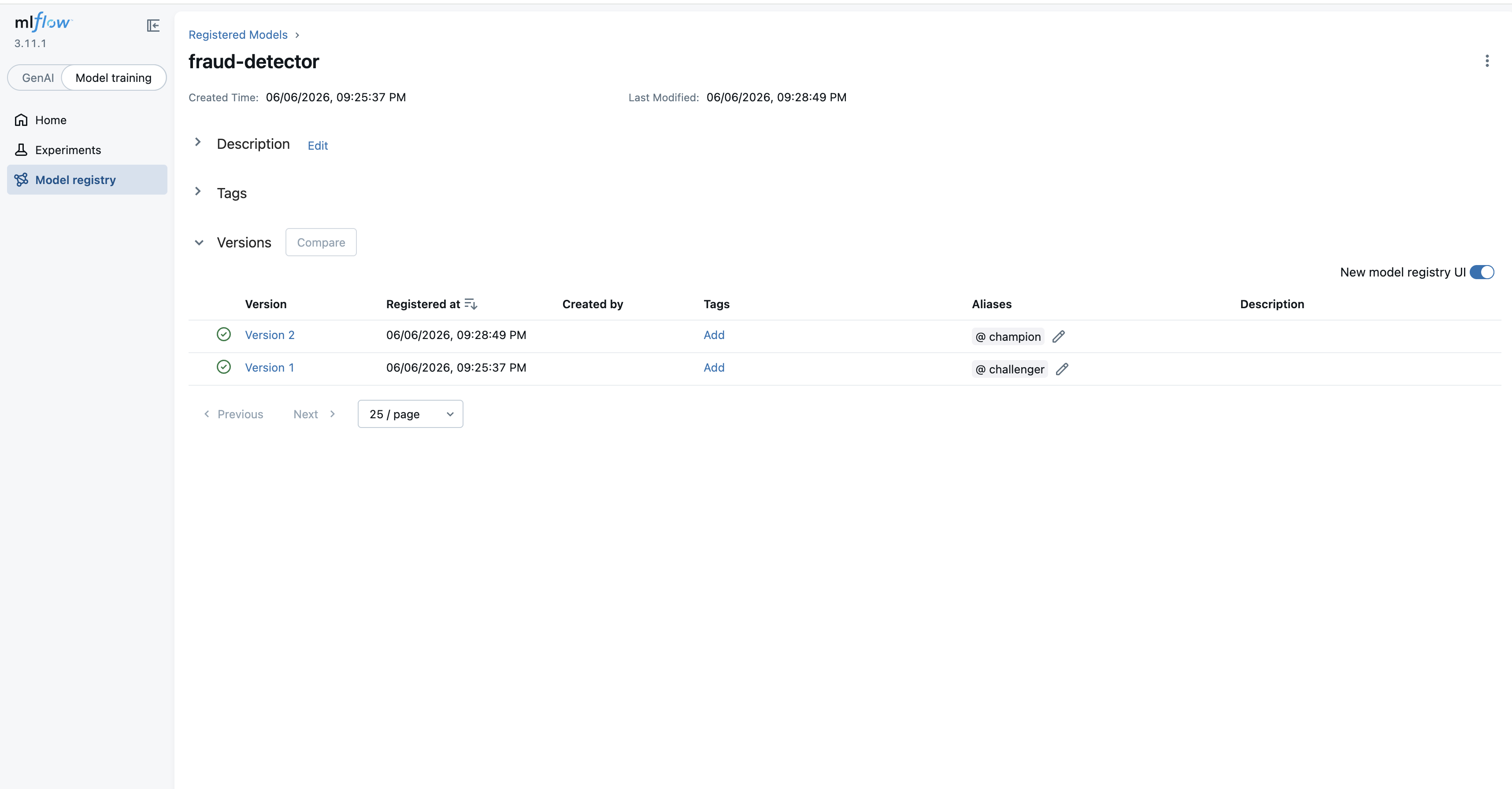
champion과 challenger는 MLflow가 정해 둔 고정 이름이 아니다. alias(v2~)에서 팀이 관례적으로 쓰는 이름이고, shadow, canary, prod-a처럼 자유롭게 정해도 된다. stage(v1)에는 Staging / Production / Archived 네 가지만 있어서 shadow·challenger 후보를 별도 포인터로 두는 패턴 자체가 불가능했다. Production을 사실상 champion처럼 쓰기는 했지만, 두 버전을 동시에 추적·전환하는 건 alias에서나 가능하다.
- champion: 현재 프로덕션 serving 중인 최선의 모델을 가리키는 alias (관례적 이름)
- challenger: champion에 도전 중인 후보를 가리키는 alias (shadow test, A/B test 대상)
alias가 가리키는 버전만 바꾸면 serving 대상이 전환되므로, 서빙 코드를 수정하지 않고도 모델을 롤아웃할 수 있다.
alias vs tags: alias는 “지금 서빙할 버전” 포인터다.
compliance-reviewed,eval-passed-2026-06같이 alias로 표현되지 않는 메타데이터는 tags로 분리하는 게 일반적이다. tags는 버전에 붙는 주석이고, serving 참조와는 별개다.
MLflow Projects
ML 코드와 환경을 패키징하는 표준 포맷이다.
MLprojectYAML에 entrypoint·conda·docker·git 의존성 기술mlflow run <project-uri>한 줄로 어디서든 동일 실행- K8s에서는 Argo Workflows / Kubeflow Pipelines로 distributed job 오케스트레이션
Projects는 tracking server 일부가 아니라 클라이언트 측 spec이다. mlflow CLI가 spec을 보고 실행한다.
MLflow Models
ML 모델을 패키징하는 표준 포맷 — real-time serving REST API, Spark batch inference 등 downstream에서 같은 모델을 활용한다.
- MLmodel descriptor + 모델 파일 디렉토리
- Flavor = framework backend 추상:
mlflow.sklearn.save_model()→ scikit-learn + python_function flavor 동시 생성mlflow.pytorch.save_model(),mlflow.transformers.save_model()등- 한 모델이 여러 flavor 동시 보유 가능
Models vs Model Registry
| 항목 | Models | Model Registry |
|---|---|---|
| 무엇인가 | 저장·포장 포맷 | 카탈로그·라이프사이클 관리 |
| 단위 | 한 모델 디렉토리 | registered model → version·alias |
| 위치 | artifact store (파일) | backend store (메타) |
| 책임 | 어떻게 저장/로드할 것인가 | 어느 버전이 어디서 서빙되는가 |
K8s에서는 KServe / Seldon Core / Ray Serve로 MLflow Models를 서빙한다.
통합 유스케이스
- HPO 동안 모든 run의 메트릭·파라미터·artifact 기록 → 재현성·분석성
- best 모델을 Registry에 등록 → KServe Pod로 배포 → real-time serving
- K8s autoscaling으로 트래픽 peak 시 dynamic scale
정리
| 영역 | 핵심 |
|---|---|
| Tracking | Experiment → Run, backend + artifact store 분리 |
| Registry | v2 alias 포인터, champion/challenger 롤아웃 |
| Models | Flavor 기반 표준 포맷, Registry와 책임 분리 |
| K8s 배포 | server Pod + PV + (선택) HPA, Registry는 같은 server |

댓글남기기