
[GenAI] GenAI on K8s: 11.4 - Argo Workflows와 ML 파이프라인 오케스트레이션
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 11장의 학습 내용을 바탕으로 합니다
11.2에서 Kubeflow Pipelines가 Argo Workflows를 백엔드로 쓴다고 했다. 이번 글은 그 백엔드 자체를 본다. Argo Workflows가 워크플로우를 실제로 어떻게 실행하는지(CRD 구조와 step이 Pod가 되는 과정), Kubeflow Pipelines·Argo CD와의 관계, ML·인프라·CI/CD 유스케이스, 그리고 Ray와 한 클러스터에 있을 때 겹쳐 보이는 parallelism 제한까지 정리한다.
TL;DR
- Argo Workflows = K8s-native 범용 DAG 실행 엔진. 워크플로우를
WorkflowCRD로 정의하고, 그 안의 step/task 하나가 Pod 하나로 뜬다 - Pod 안은
init(입력 artifact·parameter fetch) →main(사용자 이미지 실행) →wait(출력 저장·cleanup) 3컨테이너 구조. v3.4 이후 실행은 Emissary executor(argoexec)가 담당한다 - 템플릿은 일을 하는 것(
container·script·resource·suspend)과 흐름을 짜는 것(steps·dag)으로 갈린다.dag는dependencies로 의존 그래프를,steps는 list-of-lists로 순차·병렬을 표현한다 - Kubeflow Pipelines = Argo 위에 ML DSL·artifact tracking·metadata store를 얹은 layer다. Argo CD = GitOps 상태 reconcile — 같은 Argo 패밀리지만 “절차 실행” vs “상태 동기화”로 책임이 다르다.
parallelism은 세 층위(컨트롤러 = 동시 워크플로우 수, workflowspec.parallelism= 워크플로우 내 동시 Pod 수, template 수준)로 나뉘고, 이는 Ray task scheduling과는 별개 레이어다
Argo Workflows 개요
Argo Workflows는 K8s 위에서 복잡한 파이프라인을 실행하기 위한 범용 워크플로우 엔진이다. 특정 도메인(ML 전용 등)에 묶이지 않고, “여러 단계를 순서·의존 관계에 맞춰 컨테이너로 돌린다”는 일을 K8s-native 방식으로 한다.
핵심 설계는 한 문장으로 줄일 수 있다 — 워크플로우의 각 step을 K8s Pod로 실행한다. 이 결정 하나에서 Argo의 성격 대부분이 따라 나온다.
- step이 Pod이므로, K8s의 스케줄링·자원 할당·fault tolerance·노드 확장을 그대로 물려받는다. Argo가 별도 실행자 인프라를 두지 않는 이유다
- 워크플로우는
DAG(의존 그래프) 또는 step-by-step 시퀀스로 정의하고, step 간에는 artifact(파일)와 parameter(값)를 주고받는다 - 조건 분기, 자동 retry, 에러 핸들링, 수평 확장(수천 워크플로우 동시 실행)이 엔진 차원에서 제공된다
전부 K8s CRD로 표현된다. 워크플로우 정의·재사용·스케줄이 각각 별도 리소스 종류로 나뉘는데, 이건 뒤에서 따로 본다.
Workflow 실행 모델
개요의 “step = Pod”가 실제로 어떻게 돌아가는지를 CRD 구조부터 따라가 보자. 이 절이 이 글에서 다른 Argo 소개 글과 갈리는 지점이다.
Workflow spec — entrypoint와 templates
Workflow 리소스의 spec은 본질적으로 템플릿 목록 + 시작점이다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world- # Workflow 인스턴스 이름 prefix
spec:
entrypoint: main # 어느 템플릿부터 실행할지 (main 함수 격)
arguments: # 워크플로우 전역 입력
parameters:
- name: message
value: hello
templates: # 실행 단위 정의 목록
- name: main
# ...
spec.entrypoint: 워크플로우를 시작할 템플릿 이름. 프로그램의main()에 해당한다spec.templates: 실행 단위(template) 정의의 목록spec.arguments: 워크플로우 전체에 넘기는 입력 parameter·artifact
templates에 정의만 나열한다고 실행 순서가 정해지는 건 아니다. 순서는 흐름을 짜는 템플릿이 따로 표현한다.
일을 하는 템플릿 vs 흐름을 짜는 템플릿
Argo 템플릿은 역할이 둘로 갈린다. 이 구분을 잡아야 YAML이 읽힌다.
| 분류 | 템플릿 타입 | 하는 일 |
|---|---|---|
| 정의 템플릿 (일을 함) | container |
사용자 이미지를 컨테이너로 실행 |
script |
source:에 인라인 스크립트를 넣어 실행 (container의 wrapper) |
|
resource |
클러스터 리소스 조작 (get/create/apply/delete/patch) | |
suspend |
지정 시간 또는 수동 resume까지 일시정지 | |
| 호출 템플릿 (흐름을 짬) | steps |
step들을 순차·병렬로 나열 |
dag |
task 간 의존 관계를 그래프로 선언 |
container·script는 실제로 Pod를 띄워 일을 하고, steps·dag는 그 일들을 어떤 순서로 엮을지만 정한다. 호출 템플릿이 정의 템플릿을 template: 이름으로 참조하는 구조다.
steps vs dag
흐름을 짜는 방식이 둘인데, 표현력과 가독성이 다르다. 결론부터 보면, 단순한 직선·고정 분기는 steps가 읽기 쉽고, 의존 관계가 복잡해질수록 dag가 그래프를 그대로 옮기기 좋다. ML 파이프라인(전처리 → 학습 → 평가 → 배포)처럼 단계가 갈라지고 합쳐지면 보통 dag를 쓴다. 둘을 차례로 본다.
steps
list-of-lists 구조다. 바깥 리스트는 순차 실행, 안쪽 리스트는 병렬 실행이다. - -(이중 하이픈)이 “이 단계는 앞 단계가 끝난 뒤”를 뜻한다.
- name: hello-hello-hello
steps:
- - name: step1
template: prepare-data # 먼저 실행
- - name: step2a
template: run-first-half # step1 이후, step2a·step2b는
- name: step2b # 서로 병렬
template: run-second-half
dag
dag.tasks에 task를 나열하고 각 task의 dependencies로 선행 조건을 선언한다. 의존이 없는 task는 즉시 시작되고, 나머지는 의존이 충족되는 대로 풀린다.
- name: diamond
dag:
tasks:
- name: A
template: echo
- name: B
dependencies: [A] # A가 끝나야 B
template: echo
- name: C
dependencies: [A] # A가 끝나야 C (B와 병렬)
template: echo
- name: D
dependencies: [B, C] # B·C 둘 다 끝나야 D
template: echo
step이 Pod가 되기까지 — controller와 3컨테이너
정의·흐름을 선언했으면, 그걸 실제 Pod로 바꾸는 주체가 있어야 한다. 그게 workflow-controller다.
workflow-controller는Workflow리소스와 그 Pod들을 watch하면서 reconcile한다. 워크플로우를 큐에 넣고 worker goroutine이 하나씩 처리하며, 의존이 충족된 step에 대해 Pod를 생성한다- 사용자가 API·UI로 워크플로우를 제출·조회하는 창구는 별도 컴포넌트인
argo-server다 (API + UI 호스팅)
여기서 핵심은 step Pod 내부 구조다. step/task 하나가 Pod 하나로 뜨는데, 그 Pod 안에는 컨테이너가 셋 들어간다.
| 컨테이너 | 역할 |
|---|---|
init (InitContainer) |
입력 artifact·parameter를 받아 main이 쓸 수 있게 준비 |
main |
사용자가 지정한 이미지 실행. argoexec가 volume mount되어 entrypoint로 들어가고, 원래 커맨드를 subprocess로 실행하며 출력을 캡처 |
wait |
출력 parameter·artifact 저장과 cleanup |
즉 main 컨테이너가 곧장 사용자 커맨드를 PID 1로 실행하는 게 아니라, argoexec(executor)가 한 겹 감싸서 입출력 수집과 라이프사이클 관리를 한다. 이 executor를 Emissary라고 부르며, v3.4 이후로는 유일한 executor다. 과거 docker·pns·k8sapi·kubelet executor는 제거됐으므로, 옛 자료의 containerRuntimeExecutor 설정은 최신 버전에서 더 이상 유효하지 않다.
artifact passing — step 간 파일 전달
step이 각자 다른 Pod라는 건, step 사이에 메모리·로컬 디스크를 공유하지 않는다는 뜻이다. 그래서 단계 간 데이터 전달은 두 갈래로 표현된다.
- parameter: 작은 값(문자열·숫자). 한 step의 output을 다음 step의 input으로 `` 식으로 참조
- artifact: 파일·디렉토리. 한 step이
outputs.artifacts로 내보내고 다음 step이inputs.artifacts로 받는다
artifact는 Pod 로컬에 머물 수 없으므로 artifact repository(S3 호환 object storage 등)를 거쳐 전달된다. init 컨테이너가 저장소에서 받아오고 wait 컨테이너가 올려보내는, 앞 절의 3컨테이너 구조가 여기서 그대로 쓰인다.
이 artifact 저장소를 직접 설정하고 MinIO를 붙여 ML 파이프라인 step 간에 데이터를 넘긴 실습은 따로 정리해 둔 적이 있다 — Argo Workflow Artifact 기능 사용하기에서
workflow-controller-configmap의artifactRepository설정과 S3 호환 저장소 연동을 다룬다.
CRD 패밀리 — Workflow / WorkflowTemplate / CronWorkflow
Argo는 “한 번 실행”, “재사용 정의”, “스케줄 실행”을 각각 다른 CRD로 나눈다.
| CRD | 성격 |
|---|---|
Workflow |
워크플로우 한 번의 실행 인스턴스. 제출하면 곧장 돈다 |
WorkflowTemplate |
클러스터에 저장해 두는 재사용 정의(namespace 범위). 그 자체로는 실행 단위가 아니라, 다른 워크플로우가 참조하거나 --from으로 인스턴스화 |
ClusterWorkflowTemplate |
WorkflowTemplate의 클러스터 범위 버전 |
CronWorkflow |
cron 스케줄에 맞춰 Workflow를 주기 생성 |
WorkflowTemplate은 두 방식으로 참조된다 — 전체 spec을 끌어다 쓰는 workflowTemplateRef, 그리고 steps·dag 안에서 개별 템플릿만 불러오는 templateRef다. 같은 전처리·학습 정의를 여러 워크플로우가 공유할 때 정의를 한 곳에 모으는 용도다.
Argo와 다른 도구의 관계
Argo가 범용 엔진이다 보니, 여러 도구가 Argo를 자기 백엔드로 끌어다 쓰거나(Pipelines) 같은 패밀리로 역할을 나눠 갖는다(Argo CD). 이 관계를 세 각도로 본다.
Argo를 내부 엔진으로 쓰는 도구
여러 ML 도구가 자기 실행 백엔드로 Argo를 끌어다 쓴다.
| 도구 | 사용 방식 |
|---|---|
| Kubeflow Pipelines | Pipelines DSL → Argo Workflow로 컴파일해 실행 |
| Katib (옵션) | trial orchestrator로 Argo 선택 가능 |
| Seldon Core | 모델 배포 워크플로우 일부 |
| MLflow Projects | mlflow run을 Argo step으로 오케스트레이션 |
이 중 가장 밀접한 Kubeflow Pipelines와의 관계를 다음 절에서 본다.
Kubeflow Pipelines와의 레이어 관계
Kubeflow Pipelines와 Argo Workflows는 같은 백엔드(Argo)를 공유하지만, 추상화 레벨과 타깃 사용자가 다르다.
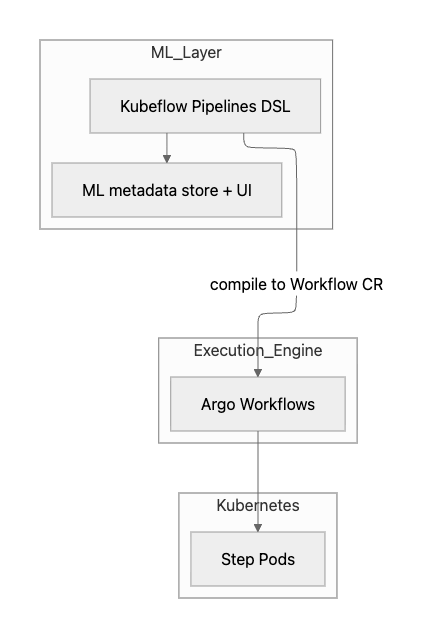
| 항목 | Argo Workflows | Kubeflow Pipelines |
|---|---|---|
| 카테고리 | 범용 K8s workflow engine | ML 특화 플랫폼 |
| 인터페이스 | YAML / WorkflowTemplate | Python DSL (@dsl.component, @dsl.pipeline) |
| 타깃 사용자 | 플랫폼/DevOps | 데이터 사이언티스트 |
| ML 통합 | 일반 컨테이너 step | artifact tracking, metadata, metric 시각화 |
| 백엔드 | (본인) | Argo Workflows (default) |
Kubeflow Pipelines는 Argo 위에 ML metadata·UI·SDK를 얹은 layer다. 데이터 사이언티스트는 Python DSL로 파이프라인을 짜고, 그게 내려가면 결국 앞에서 본 Workflow CRD로 컴파일돼 같은 controller가 Pod를 띄운다. 둘은 경쟁이 아니라 레이어 관계다.
Argo Workflows vs Argo CD
이름이 비슷해 헷갈리지만, 같은 Argo 패밀리 안에서 책임이 명확히 다르다.
| 도구 | 책임 |
|---|---|
| Argo Workflows | step-by-step task DAG 실행. “build → test → deploy” 절차 자동화 |
| Argo CD | GitOps 컨트롤러. Git의 desired state ↔ K8s의 actual state 상태 reconcile |
한쪽은 “정해진 절차를 한 번 끝까지 돌린다”(Workflows), 다른 쪽은 “선언된 상태를 계속 맞춰 둔다”(Argo CD)는 점이 다르다. CI/CD에서는 둘이 보완 관계로 엮인다 — Workflows로 빌드·테스트·이미지 push까지 하고, 그 결과 manifest를 Git에 반영하면, Argo CD가 그 Git 상태를 클러스터에 지속적으로 동기화한다.
유스케이스
범용 엔진이라 적용 범위가 넓다. 책이 드는 대표 사례는 네 갈래다.
- ML 파이프라인 — 데이터 전처리 → 학습 → 평가 → 배포를 DAG로 묶는다. 11.1 파이프라인 5단계 중 adaptation·serving 사이를 자동화하는 지점이다
- 데이터 배치 처리 — ETL, 스케줄된 데이터 sync. 주기 실행은
CronWorkflow로 표현한다 - 인프라 자동화 — EKS 프로비저닝, namespace·RBAC 자동 생성, 테넌트 온보딩.
resource템플릿으로 클러스터 리소스를 직접 다루는 패턴이 여기 들어맞는다 - CI/CD — 코드 빌드 → 테스트 → 이미지 push → manifest apply
parallelism 세 층위와 Ray scheduling
Argo Workflows와 Ray가 같은 클러스터에 있으면 “동시 실행 제한”이 겹쳐 보이지만 레이어가 다르다. 먼저 Argo 안에서도 parallelism이 한 가지가 아니라는 점부터 짚는다.
| 층위 | 설정 위치 | 무엇을 제한 |
|---|---|---|
| 컨트롤러 | controller configmap parallelism / namespaceParallelism |
동시에 도는 워크플로우 개수(전체 / namespace 단위) |
| 워크플로우 | spec.parallelism |
한 워크플로우 안에서 동시에 뜨는 Pod(step) 수 |
| 템플릿 | steps/dag 템플릿의 parallelism |
그 템플릿 범위 내 동시 실행 수 |
이 셋은 전부 Argo가 띄우는 워크플로우 step Pod를 대상으로 한다. 반면 Ray와는 다음과 같이 갈린다.
| 레이어 | 제한 주체 | 무엇을 제한 |
|---|---|---|
| Argo | 위 세 층위의 parallelism |
동시 실행 워크플로우 step Pod 수 |
| Ray | Ray scheduler + autoscaler | task/actor/PG bundle이 Ray node에 배치되는 수 |
| K8s | Resource quota, scheduler | namespace·노드 단위 Pod·자원 |
Argo step 안에서 Ray cluster를 띄우는 구성을 생각하면 경계가 분명해진다. Argo는 “이 step Pod가 떠 있는가”까지만 관리하고, 그 Pod 안에서 Ray가 task를 어느 raylet에 배치하는지는 Ray scheduler의 몫이다. 병목이 Argo의 동시 Pod 상한인지, Ray의 logical resource인지, K8s 노드 capacity인지를 분리해서 봐야 한다 — Ray 쪽 계층적 스케줄링은 11.5에서 다룬다.
정리
| 영역 | 핵심 |
|---|---|
| 실행 모델 | Workflow CRD, step/task = Pod 1개, 그 안 init/main/wait 3컨테이너 |
| executor | v3.4+ Emissary(argoexec)가 사용자 커맨드를 subprocess로 감싸 입출력 수집 |
| 흐름 표현 | steps(list-of-lists) vs dag(dependencies 그래프) |
| CRD 패밀리 | Workflow(1회) / WorkflowTemplate(재사용 정의) / CronWorkflow(스케줄) |
| vs Pipelines | Argo = 엔진, Pipelines = 그 위 ML layer |
| vs Argo CD | 절차 실행 vs GitOps 상태 reconcile |
| parallelism | 컨트롤러·워크플로우·템플릿 세 층위 — Ray task scheduling과는 별개 레이어 |
참고 링크
- Argo Workflows
- Argo Workflows — Core Concepts
- Argo Workflows — Architecture
- Argo Workflows — Workflow Executors
- Argo Workflows — Limiting Parallelism
- Argo CD
- Argo Workflow Artifact 기능 사용하기

댓글남기기