
[GenAI] GenAI on K8s: 11.6 - 도구 비교, Bias·Drift 운영, 평가 메트릭
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 11장의 학습 내용을 바탕으로 합니다
11.1~11.5에서 GenAIOps 도구를 각각 봤다. 이번 글은 도구 비교, bias·drift 운영, 평가 메트릭으로 Ch11 이론 파트를 마무리한다. Ch11 hands-on(KubeRay + vLLM 서빙)은 11.7(코드 분석)·11.8(배포 검증)에서 이어질 예정이다.
TL;DR
- Kubeflow = K8s-native end-to-end, MLflow = 실험·레지스트리, Ray = 분산 Python, Argo = 범용 DAG 엔진 — 조합이 일반적
- bias는 data·algorithm·evaluation 경로로 유입 — AIF360/Fairlearn을 파이프라인 step·fairness gate로 임베드
- drift는 covariate/label/concept 등 종류별 대응이 다름 — KS test·KL divergence·chi-square로 정량화
- 재학습 baseline 비교는 accuracy/F1(분류), LLM은 perplexity·LLM-as-judge가 적합
Kubeflow · MLflow · Ray 비교
책 Table 11.1 기준 9항목 비교다.
| 항목 | Kubeflow | MLflow | Ray |
|---|---|---|---|
| Key application | End-to-end ML workflow 오케스트레이션·관리 | 실험 추적·모델 버전·라이프사이클 | 분산 컴퓨팅·스케일러블 학습·서빙 |
| Core strength | Workflow 오케스트레이션, multi-user | 실험 추적, model registry | 분산 실행, HPO, 서빙 |
| K8s 통합 | K8s-native, seamless scaling | K8s 배포 가능 (확장성) | KubeRay로 잘 통합 |
| Model registry | metadata·output 기반 기본 추적 | 중앙 registry + 라이프사이클 | native 없음, MLflow 등 외부 연동 |
| Deployment | KServe / custom workflow | cloud·edge·로컬 | Ray Serve |
| HPO | Katib | 제한적 — 외부 라이브러리 | Ray Tune native |
| Framework | TF, PyTorch, XGBoost 등 | framework-agnostic | TF, PyTorch, XGBoost, custom Python |
| Monitoring | Prometheus 등 K8s 도구 | 배포용 커스텀 필요 | Ray Dashboard + 3rd-party |
| Ideal for | K8s-native MLOps 팀 | 추적·관리·배포 집중 팀 | 스케일러블 분산 AI/ML 팀 |
GenAIOps 관점 한 줄 강점:
- Kubeflow — ML pipeline을 K8s-native로 streamline (11.2)
- MLflow — 견고한 실험 추적·모델 관리 (11.3)
- Argo Workflows — 자동화된 파이프라인 실행 (11.4)
- Ray — 강력한 분산 컴퓨팅·서빙 (11.5)
실무에서는 한 가지만 쓰기보다 Kubeflow Pipelines + MLflow tracking + Ray Train/Serve 조합이 흔하다.
Model Bias와 Fairness
GenAI 운영에서 data privacy · model bias · drift monitoring은 신뢰할 수 있는 AI의 핵심 축이다. K8s 위 ML pipeline·모니터링·분산 프레임워크와 결합해 자동화한다.
Model bias — 특정 집단(인종·성별·나이·언어·지역 등)에 대해 체계적으로 불공정한 예측·출력. “가끔 틀린다”가 아니라 “특정 방향으로 일관되게 다르게 대한다”가 핵심이다.
bias 유입 경로
| 종류 | 원인 | 예시 |
|---|---|---|
| Data bias | 학습 데이터 편향 | 이력서에 남성 합격자 과대표 |
| Historical bias | 과거 차별이 데이터에 내재 | 역사적 대출 거절 패턴 학습 |
| Sampling bias | 그룹 과·과소 표현 | 의료 영상이 특정 인종 위주 |
| Algorithmic bias | 보호 속성 proxy feature | 우편번호가 인종 proxy |
| Evaluation bias | 메트릭이 소수 그룹 가림 | 전체 accuracy만 보면 소수 성능 은폐 |
GenAI/LLM 특유 bias
- Representation bias — 코퍼스에 언어·문화 과소 표현
- Stereotyping — “doctor”→”he”, “nurse”→”she” 디폴트
- Toxicity — 특정 그룹에 offensive 응답
- Fairness in decisions — LLM 기반 채용·대출·평가 시 보호 속성별 다른 결과
fairness metrics
| 지표 | 의미 |
|---|---|
| Disparate impact ratio | 보호/비보호 그룹 긍정 비율 — 0.8 미만이면 차별 (US four-fifths rule) |
| Demographic parity | 그룹별 긍정 예측 확률 동일 여부 |
| Equal opportunity | 그룹별 TPR 동일 (자격 있는 사람 중 합격률) |
| Equalized odds | TPR + FPR 둘 다 그룹별 동일 |
Fairness · Explainability 라이브러리
K8s pipeline에 컨테이너 step으로 통합 가능하다.
| 도구 | 역할 |
|---|---|
| AIF360 (IBM) | bias 측정 + mitigation (reweighing, adversarial debiasing 등) |
| Fairlearn (Microsoft) | fairness metric + constraint-based mitigation |
| SHAP | feature 의존도 explainability — 보호 속성 proxy 발견 |
AIF360 적용 흐름 (대출 승인 모델 예시):
- AIF360을 K8s Pod로 배포
- 공유 storage에서 예측 결과 + 테스트 데이터 회수
- disparate impact·equal opportunity difference 계산
- bias 검출 시 mitigation 포함 재학습 잡 트리거
- 전처리 단계에서 학습 데이터 bias 사전 검출
운영 패턴
- AIF360·Fairlearn → Argo/Kubeflow Pipeline step
- 배포 전 fairness gate (CI/CD test 위치) — 실패 시 rollback
- 운영 중 ground truth review로 bias가 drift와 함께 변하는지 모니터링
Drift 운영
11.1에서 data·concept·label drift 기초를 봤다. 운영에서는 drift를 종류별로 세분화해 통계로 정량화하고, 임계치를 넘으면 자동 재학습으로 잇는다.
모니터링과 통계 측정
운영 관점에서 drift는 더 세분화된다.
| 종류 | 정의 | 예시 |
|---|---|---|
| Covariate drift | 입력 분포 변화, 관계 유지 | holiday 시즌 검색어 급증 |
| Label drift | 타깃 분포 변화 | 프리미엄 상품 구매율 상승 |
| Concept drift | 입력↔타깃 관계 변화 | 경쟁자 진입으로 ad-click 패턴 변화 |
| Temporal drift | 시간에 따른 점진적 변화 | SNS 해시태그 트렌드 변화 |
| Sampling drift | 수집 프로세스 변화 | 설문 방법 변경으로 demographic shift |
| Feature interaction drift | feature 간 상호작용 변화 | 프로모션이 보완재에 예기치 않은 영향 |
Target Drift Detection (TDD) — 타깃 변수 분포 변화. KL divergence, chi-square로 현재 vs historical 분포 비교.
| 측정 | 비교 대상 | 직관 |
|---|---|---|
| KL divergence D(P‖Q) | 두 확률 분포 P(관측), Q(기준) | Q로 P를 설명할 때 정보 손실 — 0=동일, 비대칭 |
| Chi-square test | 범주형 관측 vs 기대 빈도 | p-value로 유의성 판단 |
Kolmogorov-Smirnov (KS) test — 두 분포 CDF(누적분포함수) 최대 차이. covariate drift 검출에 유용. non-parametric이라 분포 가정 불필요.
| 함수 | 표현 |
|---|---|
| PDF/PMF | 각 지점 확률 밀도 |
| CDF F(x)=P(X≤x) | 누적 확률 — KS test가 수직 거리로 비교 |
| Quantile | CDF 역함수 — “상위 95% 지점” |
Concept Drift Detection (CDD) — 입력↔타깃 관계 변화. 추천·신용 평가처럼 “같은 입력, 다른 정답”이 되는 영역에서 중요.
감지와 자동 재학습
모니터링이 drift 임계치를 넘기면 Argo Workflows·Kubeflow로 event-driven 재학습을 트리거한다.
재학습 잡
- 최신 프로덕션 데이터를 S3 등 data lake에서 pull
- 컨테이너 이미지 또는 training job CRD로 학습/fine-tuning
- AIF360·SHAP·Fairlearn bias 체크 임베드 — 성능 + fairness 양쪽 통과
검증·배포
- established baseline과 비교
- accuracy·F1 등 메트릭을 이전 버전과 비교 (아래 분류 메트릭 참조)
- acceptance 통과 → container registry push → blue-green / canary rollout
- 이벤트·artifact는 versioned bucket/DB에 로깅
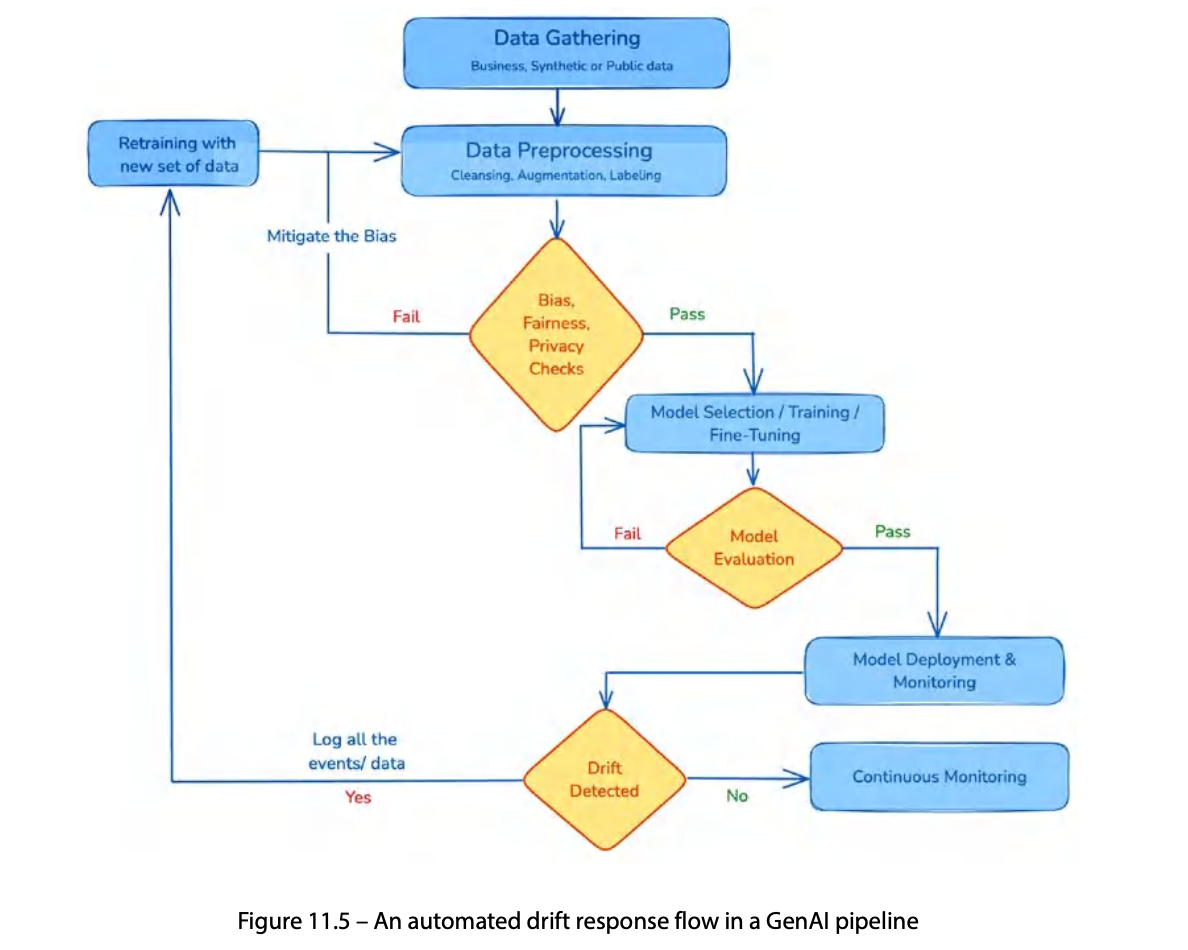
- Bias, Fairness, Privacy Checks — 전처리 직후·학습 전. 실패 시 Mitigate the Bias 경로
- Drift Detected — 재학습 루프 진입, 미감지 시 Continuous Monitoring 회귀
참고: 모델 평가 메트릭
책 p237의 “accuracy and F1 score”는 분류 모델 재학습 baseline 비교용이다. GenAI는 별도 메트릭 카테고리다.
분류 메트릭
Confusion matrix에서 파생한다.
| 예측: Positive | 예측: Negative | |
|---|---|---|
| 실제: Positive | TP | FN (놓침) |
| 실제: Negative | FP (잘못 잡음) | TN |
| 메트릭 | 공식 | 한 줄 의미 | 약점 |
|---|---|---|---|
| Accuracy | (TP+TN)/전체 | 전체 맞춘 비율 | 불균형에 취약 |
| Precision | TP/(TP+FP) | 양성 예측 중 실제 양성 | recall 무시 |
| Recall (TPR) | TP/(TP+FN) | 실제 양성 중 회수 | precision 무시 |
| F1 | 2PR/(P+R) | P·R 조화평균 | 불균형 가중은 F-beta |
| AUC-ROC | TPR vs FPR 곡선 면적 | threshold-independent ranking | 극단 불균형에선 AUC-PR |
비용으로 메트릭 선택
| 시나리오 | FP 비용 | FN 비용 | 우선 |
|---|---|---|---|
| 스팸 필터 | 큼 | 작음 | Precision |
| 암 진단 | 추가 검사 | 생명 위험 | Recall |
| 사기 탐지 | 고객 불만 | 금전 손실 | F1 |
불균형 데이터 예시 (accuracy 함정)
실제 양성 100명, 음성 900명, 총 1000명
TP=80, FN=20, FP=50, TN=850
Accuracy = 93%
Precision = 61.5%
Recall = 80%
F1 = 69.6%
Accuracy 93%가 좋아 보여도 precision 61.5% — 양성 예측 중 40%가 실제 음성이다.
GenAI 평가
| 태스크 | 메트릭 |
|---|---|
| 번역 | BLEU |
| 요약 | ROUGE-1/2/L |
| 언어모델 | Perplexity (낮을수록 좋음) |
| QA (extractive) | Exact Match, token-level F1 |
| 생성형 LLM | LLM-as-a-judge, HELM, MT-Bench |
| Bias | BBQ, StereoSet, ToxiGen + fairness 라이브러리 |
LLM 재학습 baseline 비교에는 perplexity / LLM-as-judge가 classification accuracy보다 적합하다.
Ch11 이론 마무리 · 실습 예고
Ch9(보안) → Ch10(GPU 효율) → Ch11(운영·서빙 오케스트레이션) 흐름에서, 이번 장 hands-on은 11.5에서 본 RayService + vLLM으로 GenAIOps의 “Ops”를 체험한다.
| 예정 포스트 | 내용 |
|---|---|
| 11.7 Ch11 실습 코드 분석 | aiml-addons.tf KubeRay delta, ray-service-vllm.yaml |
| 11.8 Ch11 실습 배포·검증 | terraform apply, 추론 호출, Dashboard, 트러블슈팅 |
정리
| 영역 | 핵심 |
|---|---|
| 도구 | Kubeflow/MLflow/Ray/Argo — 역할 분리·조합 |
| Bias | fairness gate, AIF360 파이프라인 step |
| Drift | 종류별 대응, KS/KL/chi-square 정량화 |
| 재학습 | event-driven workflow, canary 배포 |
| 메트릭 | 분류=F1/accuracy, GenAI=perplexity·LLM-judge |

댓글남기기