
[DL] LSTM_4.양방향 모델 아키텍쳐 및 구현
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 1.X
양방향 LSTM 모델 아키텍쳐 및 구현
1. 모델 개요
LSTM 모델이 기존 RNN 모델에서의 Vanishing Gradient 문제를 해결하고, 기간 의존적인 학습을 하기 위해 만들어진 모델이라 하였다.
이전까지 살펴 본 LSTM 모델은 사실 엄밀히 구분하면, 단방향 모델이다. 단방향 LSTM 모델의 경우, 이전의 기억만을 바탕으로 얼마나 먼 과거의 데이터를 반영할 것인지 결정한다. 이제부터 볼 양방향 LSTM 모델의 경우, 이전의 기억뿐만 아니라 이후에 무엇이 올지도 반영하여 학습한다.
“이전에 뭐가 나왔지?”하고 공부하는 게 단방향 LSTM이라면, “이전에 뭐였지? 그 다음에는 뭐가 나오지?”하고 공부하는 게 양방향 LSTM이다.
똑똑한 놈…
RNN 기반의 시퀀스 학습 모델은 데이터를 데이터를 시간 순서대로 입력하기 때문에, 학습 결과가 직전 패턴에 의존해 버린다는 한계가 있다. RNN 모델에서도 Vanishing Gradient 문제와 별개로 이 문제를 해결하고자 하는 시도가 있었고, 그래서 양방향 RNN 모델이라는 개념을 고안했다. 그러나 양방향 RNN 모델(Bi-RNN)이 태생적으로 Vanishing Gradient 문제를 보인다.
따라서 해당 문제를 해결한 LSTM 모델 아키텍쳐에 양방향 개념을 추가하면, 그것이 바로 양방향 LSTM (a.k.a Bi-LSTM) 모델이다.
아이디어는 간단하다. 기존의 단방향 LSTM 모델을 Forward용, Backward용 2개로 만들어서 합친다. Forward LSTM에서는 입력 데이터가 시퀀스 순서대로 들어가고, Backward LSTM에서는 시퀀스의 반대 순서대로 데이터가 들어간다.
이렇게 각 시퀀스의 순서를 반대로 하여 학습하기 때문에, Recurrent가 순방향, 역방향으로 2번 일어난다. 학습 후 Feed Forward 네트워크로 들어갈 때에는, 각 모델의 출력을 연결(concat)한다. 이렇게 출력을 연결하기 때문에, FFN으로 입력되는 Latent Feature의 수가 기존 LSTM 모델에 비해 2배가 된다.
양방향 LSTM 모델도 역시 입력과 출력의 수에 따라 2가지 유형으로 구분할 수 있다. 이전에 단방향 LSTM 모델을 이해할 때 사용했던 예시를 변형하여, 양방향 Many-to-One LSTM 모델 유형과 양방향 Many-to-Many LSTM 모델 유형의 아키텍쳐를 나타내면 다음과 같다.
그림 한 번 그려놓으니까 편하긴 하다 ^0^
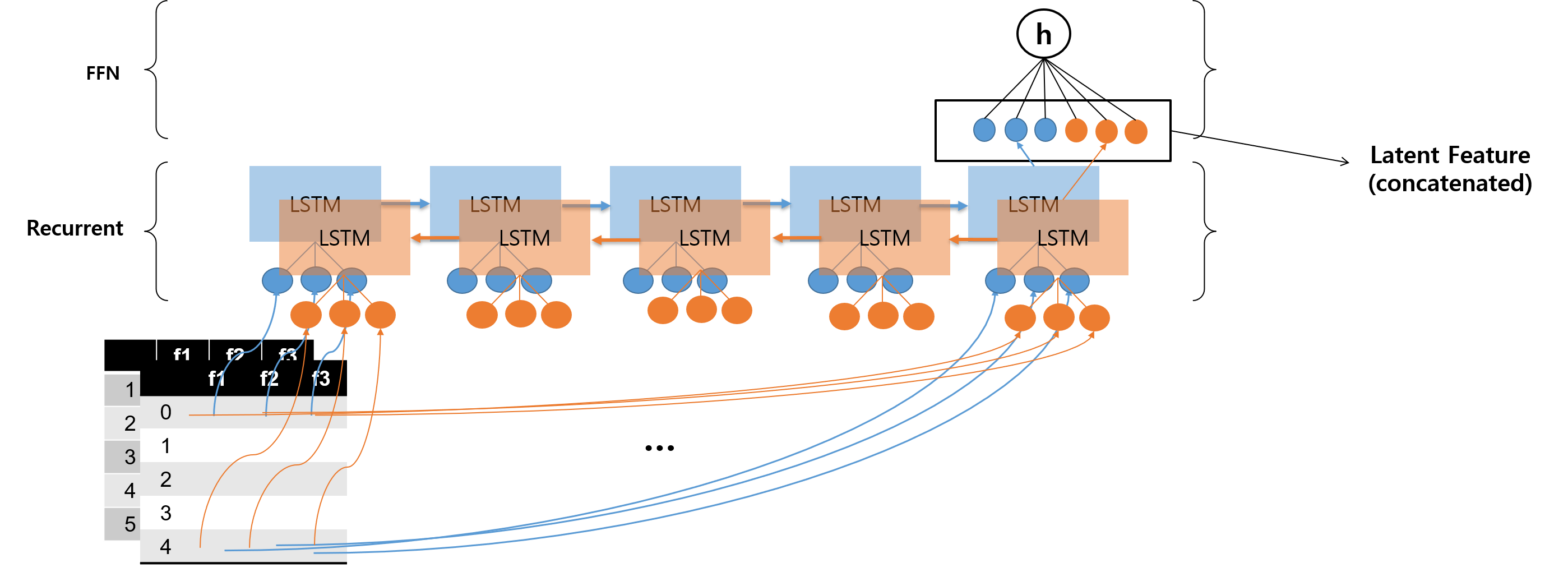
BiLSTM Many-to-One
BiLSTM Many-to-Many
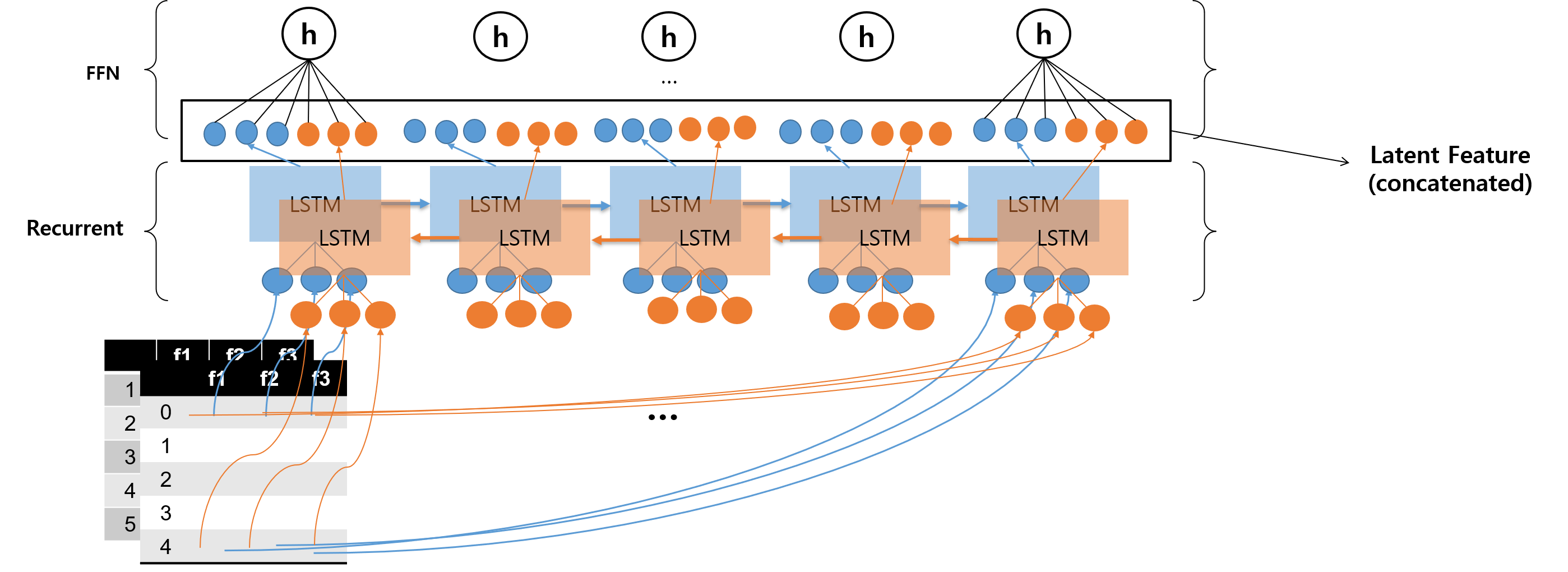
위의 두 그림에서 파란색 모델이 Forward 방향으로 진행되는 LSTM 모델, 주황색 모델이 Backward 방향으로 진행되는 LSTM 모델을 나타낸다.
LSTM 모델에서 Recurrent 스텝이 일어날 수록 정보량이 많아지기 때문에, 두 방향으로 Recurrent 스텝이 일어나는 양방향 LSTM 모델에서는 각 시퀀스 내 스텝에서 정보량이 균등해지는 경향을 갖는다.
구체적으로 말하면 다음과 같다. Forward 방향에서의 첫 번째 노드를 보면, 이전에 진행된 스텝이 없기 때문에 정보량이 0이다. 그러나 동시에 Backward 방향에서 본다면, 마지막 스텝으로 오기까지 이전까지의 정보량이 누적되어 있기 때문에 정보량이 제일 많다. 이렇게 본다면, 각 스텝에서의 합쳐진 값들은 정보량이 (어느 정도) 균등하게 분산되어 있다는 것이다. Feed Forward 네트워크로 올라갈 때는 균등하게 정보량이 맞춰진 상태에서 Latent Feature가 입력된다.
Recurrent 스텝이 두 방향으로 이루어지기 때문에, 오류의 전파도 두 가지 방식으로 이루어진다. 하나는 Forward 방향으로, 다른 하나는 Backward 방향으로 일어난다. 그리고 두 방향으로의 Back Propagation은 Many-to-One 유형인지 Many-to-Many 유형인지에 따라 각 스텝으로 오류가 전파되는 여부가 달라지게 된다. 이 부분은 앞의 수업 내용과 조합해서 유형을 잘 생각해 보면 이해할 수 있다!
2. 구현
코드로 구현하는 것은 매우 간단하다. tensorflow.keras.layers에서 Bidirectional을 이용해 LSTM 레이어에 붙여주기만 하면 된다.
2.1. Many-to-One
from tensorflow.keras.layers import Input, Dense, LSTM, Bidirectional
# LSTM 모델 생성
x_Input = Input(batch_shape=(None, n_step, n_input))
x_Lstm = Bidirectional(LSTM(n_hidden), merge_mode='concat')(x_Input)
y_output = Dense(n_output)(x_Lstm)
model = Model(x_Input, y_output)
Bidirectional 레이어에서 merge_mode가 Latent Feature를 구성할 때 어떻게 만들지를 결정하는 방식이다. 디폴트 설정은 concat이다.
Bidirectional Documentation을 참고하면, merge_mode로 'sum', 'mul', 'concat', 'ave', None의 5가지를 지원한다고 한다. None은 그냥 리스트로 리턴하기 때문에, 거의 쓸 일이 없을 것 같다. concat은 위의 그림에서 설명한 방식대로 말 그대로 concatenate하는 방식이고, 나머지는 이름 그대로 이해하면 될 듯하다.
Sine 함수 예제에 merge_mode를 다르게 하여 Many-to-One 양방향 LSTM 층을 적용한 결과는 다음과 같다. 파라미터는 이전과 동일하게 적용했으며, 이후 20기간을 예측한 결과다.
| merge_mode | 예측 결과 |
|---|---|
| concat | 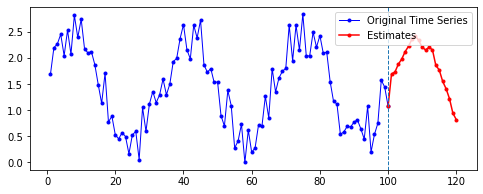 |
| sum | 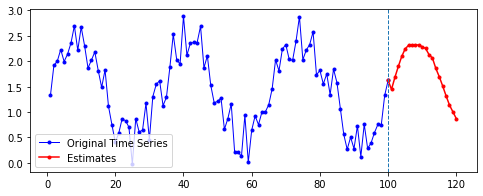 |
| mul | 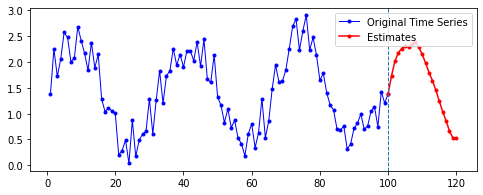 |
| ave | 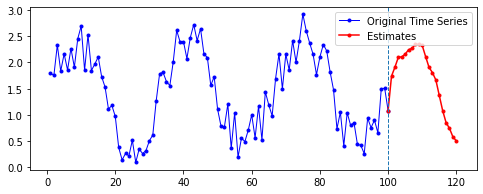 |
2.2. Many-to-Many
이제는 Many-to-Many 유형이기 때문에, 이전에 했던 대로 return_sequences = True 옵션과 TimeDistributed 함수를 사용하면 된다.
from tensorflow.keras.layers import Input, Dense, LSTM, Bidirectional, TimeDistributed
# LSTM 모델 생성
x_Input = Input(batch_shape=(None, n_step, n_input))
x_Lstm = Bidirectional(LSTM(n_hidden, return_sequences=True), merge_mode='concat')(x_Input)
y_output = TimeDistributed(Dense(n_output))(x_Lstm)
model = Model(x_Input, y_output)
3. Multi Layer LSTM 네트워크
이제 여태까지 배운 모든 내용을 종합하면 LSTM 모델을 여러 층으로 구성할 수도 있다. 여러 층으로 구성하여 고차원 정보를 담을 수 있도록 해 보자.
주의해야 할 것은 여러 층으로 모델을 구성한다고 항상 좋을 수는 없다는 것이다. LSTM 모델이 RNN의 Vanishing Gradient 문제를 해결하는 모델이긴 하지만, 층이 깊어지면 LSTM 모델도 해당 문제에서 벗어날 수는 없다. 또한, 층이 깊어질수록 과적합에 대한 위험도 늘어난다.
참고 _ 왜 그 때는 성능이 더 떨어졌을까?
댓글 분석 프로젝트 를 다시 생각해 보자.
그 때 LSTM 레이어를 2층, 3층으로 구성해 봤는데, 성능이 더 떨어졌다. 심지어 RNN에서 LSTM으로 바꿨을 때 향상된 정확도 비율보다 LSTM 1층에서 2층으로 갈 때, 2층에서 3층으로 갈 때 떨어진 정확도 비율이 더 컸다.
더 고차원적으로 모델을 구성할 수 있지만, 학습에 사용한 데이터는 커뮤니티 셋이었던 데 비해, 테스트에 사용한 데이터는 댓글 데이터여서 였을 수도 있고, 아니면 강사님께서 말씀해주신 대로, 순수하게 기술적으로 LSTM 레이어를 더 쌓는다고 더 좋아지는 것만은 아닐 수도 있어서 있을 것도 같다.
(many-to-one, many-to-many), (단방향, 양방향), (단층, 다층)의 조합을 사용하여 여러 가지 구조의 LSTM 네트워크를 만들 수 있다.
주의할 것은 1층의 LSTM 모델은 단방향이든 양방향이든 Many-to-Many 유형으로 구성해주어야 한다는 것이다. 첫 번째 LSTM 레이어에서의 출력이 두 번째 LSTM 레이어의 입력으로 사용되어야 하기 때문이다.
간단한 2층 구조의 LSTM 모델을 구성하는 예시 코드들을 살펴 봄으로써, 어떤 유형의 네트워크를 구성할 수 있는지 생각해 보자. 아키텍쳐를 그림으로 나타내지는 않고, 모델의 summary를 확인함으로써 각 모델 간 입력과 출력 shape이 어떻게 연결되는지 이해하는 데에 초점을 맞추자.
3.1. 2층, 단방향-양방향, ManytoOne-ManytoOne
from tensorflow.keras.layers import Input, Dense, LSTM, Bidirectional
x_Input = Input(batch_shape=(None, n_step, n_input))
x_Lstm_1 = LSTM(n_hidden, return_sequences=True)(x_Input)
x_Lstm_2 = Bidirectional(LSTM(n_hidden), merge_mode='concat')(X_Lstm_1)
y_output = Dense(n_output)(x_Lstm_2)
model = Model(x_Input, y_output)
주의할 것은 1층 LSTM 레이어를 구성할 때 return_sequences 옵션의 의미이다. 1층 레이어가 Many-to-One 유형임에도 불구하고 return_sequences=True 옵션을 설정해 주었다. Many-to-Many가 아니니까 TimeDistributed를 통해 오류를 스텝별로 분배할 필요는 없지만, 1층 레이어의 출력값을 모두 계산해야 올려보낼 수 있기 때문에, 해당 옵션이 필요하다.
3.2. 2층, 단방향-양방향, ManytoOne-ManytoMany
from tensorflow.keras.layers import Input, Dense, LSTM, Bidirectional, TimeDistributed
x_Input = Input(batch_shape=(None, n_step, n_input))
x_Lstm_1 = LSTM(n_hidden, return_sequences=True)(x_Input)
x_Lstm_2 = Bidirectional(LSTM(n_hidden, return_sequences=True), merge_mode='concat')(X_Lstm_1)
y_output = TimeDistributed(Dense(n_output))(x_Lstm2)
model = Model(x_Input, y_output)
위의 예에서 2층만 Many-to-Many 유형으로 변경해 본 결과다. 이런 식으로 이전에 배웠던 모든 내용들을 결합하여 다양한 경우의 수에 해당하는 LSTM 네트워크를 구성할 수 있다. 양방향일 때 어떤 함수를 써야 하는지, 입력값과 출력값에 따른 유형 구분에 따라 어떤 옵션과 함수를 추가해서 써야 하는지만 잘 기억하고 있으면 어렵지 않다!
한 가지 더. shape에, 제발, 주의하자!

댓글남기기