
[DL] LSTM_2.단방향 모델 아키텍쳐
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
단방향 LSTM 모델 아키텍쳐
1. 모델 개요
우리가 알고 있는 일반적인 데이터 형태를 가정(시계열 데이터의 경우 DACON 원자력 발전소 데이터를 생각해 보자)하고, LSTM 모델의 작동 원리를 이해해 보자.
지도 학습을 가정한다. 즉, 입력 데이터에 대한 라벨이 있고, 각 시퀀스 데이터를 넣어서 나온 출력 결과가 기존의 라벨 값과 같아지도록 학습한다.
1.1. 입력 데이터
LSTM 모델에서의 입력 데이터는 3차원 형태이다. row와 column으로 이루어진 2차원 데이터가 익숙 하기 때문에, 데이터가 어떻게 입력되는지 살펴 볼 필요가 있다.
입력 데이터가 3차원 구조가 되기 위한 핵심은 sequence의 기간(혹은 길이(?) 지금 당장은 적당한 말이 생각이 안난다) 어디까지 볼 것인지이다.
물론,
sequence의 길이는 분석자가 분석 준비 및 전처리 단계에서 결정하는 것이다.
| 2차원 데이터 | 3차원 변환 |
|---|---|
 |
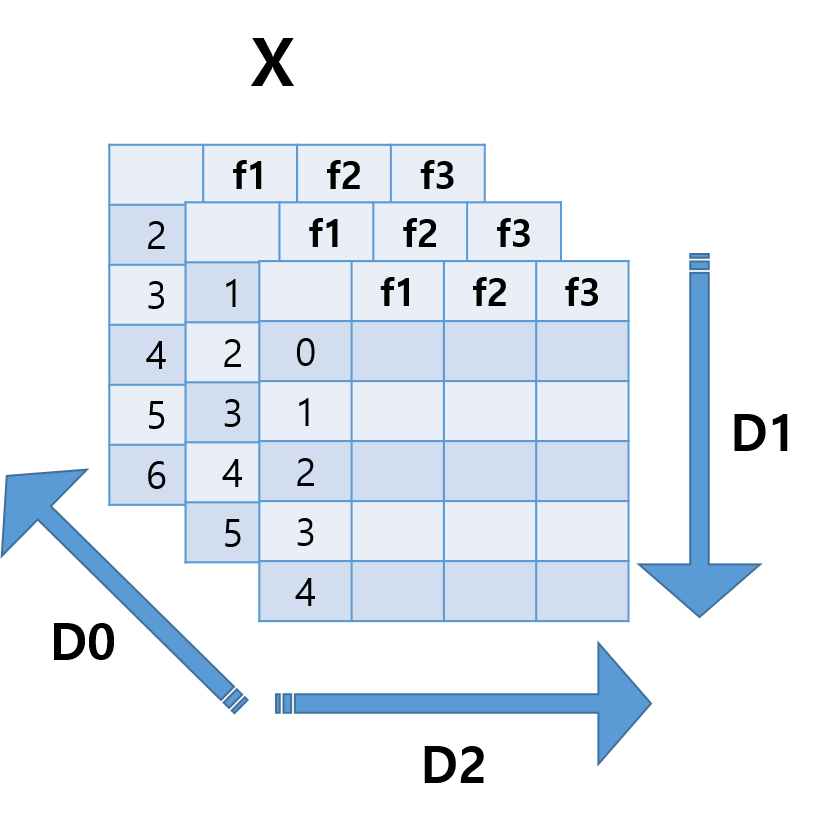 |
왼쪽 그림과 같이 feature가 3개인 데이터가 있다고 가정하자. 해당 데이터를 5개씩 잘라서 5기간을 하나의 sequence로 설정해 분석한다고 하자. (window를 적용한다고 생각해 보자. 혹은 df.rolling?)
그러면 각 sequence별로 잘린 데이터들이 여러 묶음 나올 것이다. 그 데이터들을 모아 보자. 그러면 오른쪽 그림과 같이 2차원 데이터가 sequence별로 묶인 3차원 형태가 된다.
이렇게 머릿속에서 데이터를 3차원으로 변환해 보면 D0축은 데이터의 개수, D1 축은 sequence 길이, D2 축은 feature 개수가 된다. LSTM 모델에 데이터를 입력할 때, 이 순서가 절대로 바뀌면 안 된다.
참고
3차원 축은 전산학에서 공통적으로 사용하는 축이다. 2차원에서는 행, 열 순서고, 3차원이 되면 면, 행, 열 순서다. 그리고 3차원 육면체 구조의 데이터를 생각했을 때,
면방향으로 데이터의개수,행방향으로 시퀀스의길이,열방향으로feature 개수가 있음을 잊지 말자.
1.2. LSTM 모델 구조
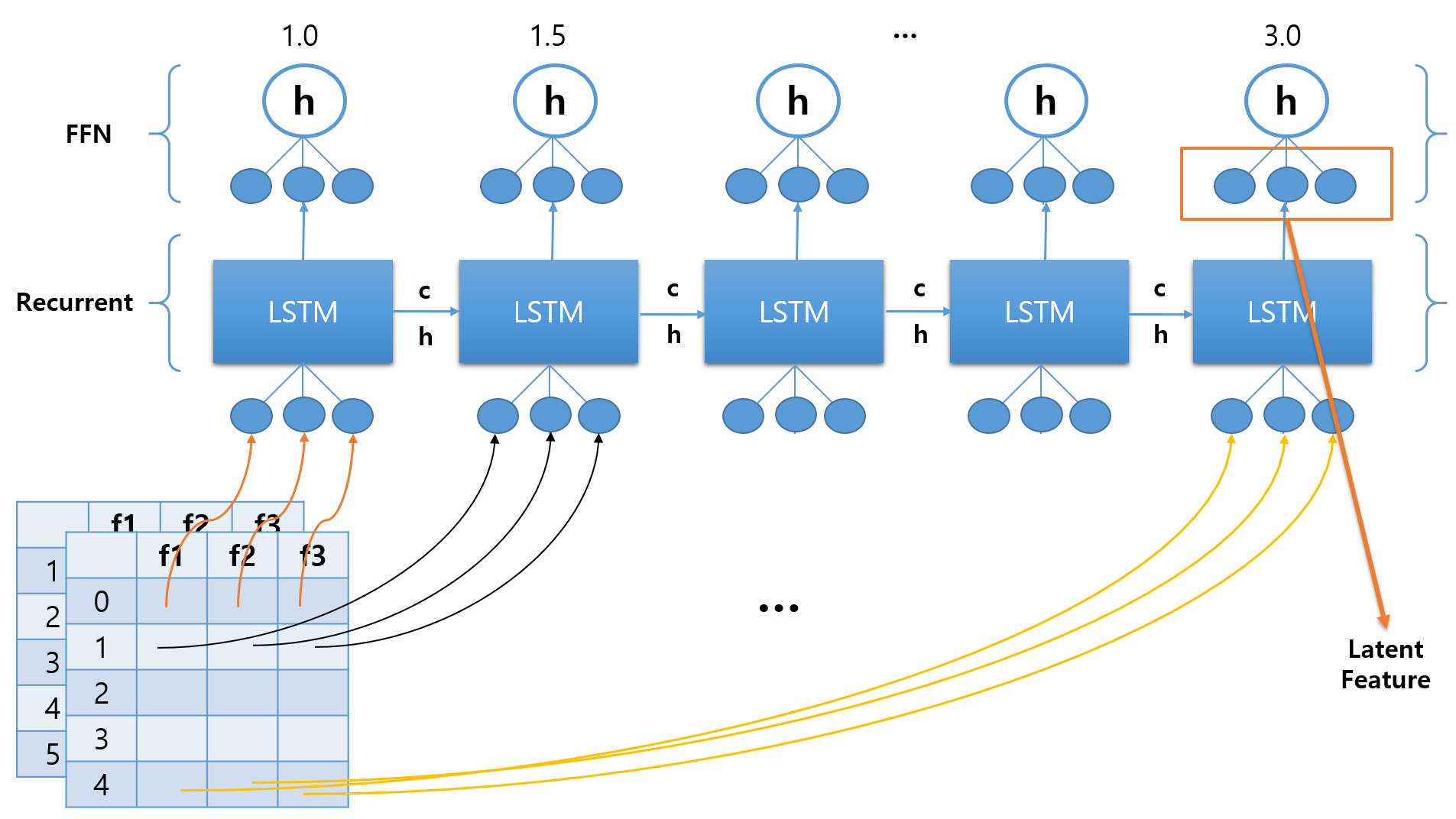
이제 변환한 데이터를 LSTM 모델 구조에 넣을 차례다. 아래 쪽에서 Recurrent 스텝이 이루어지고, 위쪽에서 Feed Forward 스텝이 이루어진다.
3차원 데이터 구조의 각각의 면을 이루는 2차원 데이터 형태(sequence 길이 x feature 수의 shape을 갖는다)가 한 번의 입력이 된다.
이 데이터들이 입력될 LSTM 뉴런을 보자. LSTM 뉴런들은 Recurrent 스텝을 수행한다. sequence의 길이만큼 뉴런의 개수를 구성한다. 그리고 각각의 뉴런에는 하나 하나의 sequence를 이루는 데이터가 들어가게 된다. 따라서 각각의 LSTM 뉴런은 feature 수와 같은 개수의 input 뉴런을 갖는다.
그렇다면 이렇게 입력된 데이터는 어떠한 과정을 거쳐 학습되는 것일까?
각각의 행을 이루는 sequence를 seq1, seq2, …, seq5라 하자. 그리고 각각의 열을 이루는 feature를 f1, f2, f3이라 하자. 마지막으로, 각각의 LSTM 뉴런을 LSTM1, LSTM2, …, LSTM5라 하자.
seq1의 f1, f2, f3이 LSTM1의 입력으로 들어간다. 그러면 해당 뉴런에서 Feed Forward 과정을 거쳐 h1 값이 나온다.
참고
FFN단계에서 hidden layer 및 뉴런 수를 결정하는 것은 전적으로 분석자의 몫이다. 위의 그림에서는Recurrent Step을 거친 후 hidden layer의 뉴런 수를 3개로 설정했고, 그것이 결과적으로 하나의 값으로 나오도록 했다.
이렇게 나온 h1 값과, LSTM1 뉴런에서의 Cell State 값인 c1 값을 그 다음 LSTM 뉴런으로 넘긴다. 다시 seq2의 f1, f2, f3이 LSTM2의 입력으로 들어간다. 해당 뉴런에서 위의 과정을 반복한다.
이렇게 마지막 시퀀스까지 입력하고 나면 하나의 데이터 입력을 마치게 된다. 그리고 3차원 데이터의 면을 이루는 데이터 개수만큼 입력을 마치게 되면, 한 번(epoch)의 학습을 마치게 된다.
참고 _
그 때는 미처 몰랐던 진실…댓글 분석 프로젝트 를 다시 생각해 보자.
우리가 가진 180만 개의 댓글 개수는
D0축이 된다. 각각의 문장을Word2Vec을 통해 50차원 혹은 100차원으로 임베딩했을 때 그 차원의 수는D2축이 된다. 또한 입력 문장 시퀀스의 길이인 80 혹은 128은sequence의 길이를 나타내는D1축이 된다. sequence의 길이가 동일하게 되도록padding,truncating을 진행해 80으로 맞춰줬던 작업은,D1축의 수를 결정하는 작업이었다.
학습 단계에서 각 시퀀스 데이터의 순서는 종속적이지만, 각 면을 이루는 2차원의 데이터 자체는 독립적이다. 1번의 입력을 진행할 때 각 시퀀스 안에서 입력되는 순서는 바뀌면 안 되지만, 1번의 에폭 안에서 seq1을 먼저 넣고 반드시 seq2를 넣어야 하는 것은 아니라는 것이다.
LSTM에서의 recurrent step의 출력이자 FFN의 입력으로 들어갈 hidden layer의 벡터를 Latent Feature라고 한다.
다시 처음으로 돌아가 보면, FFN 네트워크는 최초의 2차원 데이터를 받아서는 그 데이터의 시퀀스 구조를 파악할 수 없다. 그래서 RNN 혹은 LSTM 등 recurrent 네트워크를 활용해 시퀀스 데이터의 정보를 1차원 데이터에 함축시켜 놓고, 그 1차원 데이터를 FFN 네트워크의 입력 값으로 사용하는 것이다. 데이터의 정보와 시퀀스 흐름을 함축하고 있다는 의미로 받아들이면 된다.
결국 순환신경망 모델의 구조는 feature가 있고, 데이터 간 sequence를 가지고 있는 데이터를 3차원으로 만들어 sequence와 feature을 모두 분석하고, 그 정보를 1차원의 latent feature에 함축하여 FFN에 전달하는 구조다.
참고
RNN 외에, 데이터의 부분적 특징을 중시한다면, 데이터를 CNN으로 분석해서, CNN에 의해 전체 데이터를 포함한 latent feature를 만들어낼 수도 있다.
비유
RNN, CNN 등 네트워크를 감각기관이라고 보자. 감각기관에서 외부 자극을 받아들여서 정보를 함축시켜서 그걸 뇌에 전달한다. 그러면 뇌에 전달되는 정보가 latent feature다. 뇌는 이 latent feature를 분석한다.
2. 학습 유형 분류
단층 LSTM 모델을 입력값에 대응하는 출력값의 개수에 따라 분류해 보자. 입력값의 개수와 출력값의 개수에 따라 다음의 4가지 유형으로 분류할 수 있다.
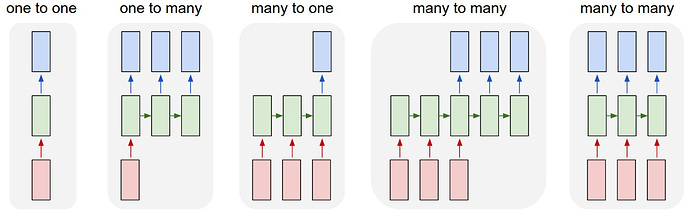
특히 분류를 위한 목적으로는 many-to-one 유형을, 시게열 분석을 위한 목적으로는 many-to-one, many-to-many 유형을 사용할 수 있다.
우선 간단한 예제를 통해 many-to-one, many-to-many 유형을 살펴보도록 한다. one-to-many 유형의 경우 CNN으로 이미지를 학습하고 RNN으로 문장을 생성하는 image captioning 등에 자주 사용되므로, 나중에 다시 살펴보도록 한다.
다음과 같은 회귀 문제를 단방향 LSTM 모델로 푼다고 가정하자.
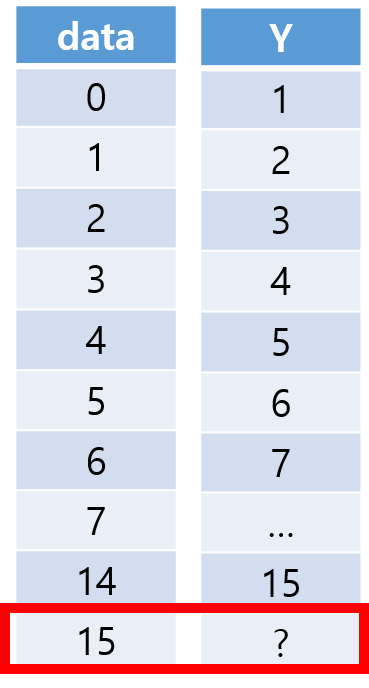
0, 1, 2, …, 14를 입력했을 때 1, 2, 3, …, 15가 출력되도록 학습시키고, 입력 데이터에 15를 넣었을 때 무슨 수가 나올지 예측하는 문제이다. feature 수가 1이 되고, sequence 길이는 5로 설정한다.
2.1. Many-to-Many
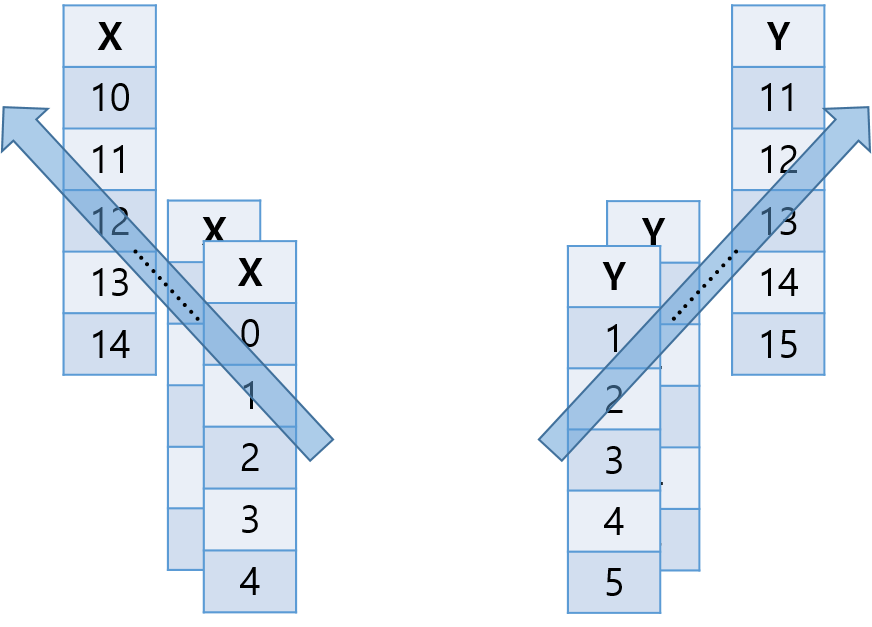
입력 데이터 [0, 1, 2, 3, 4]에 대해 라벨 [1, 2, 3, 4, 5]가 모두 출력되도록 하고자 할 때 적합한 모델이다.
| 라벨 | 모델 |
|---|---|
 |
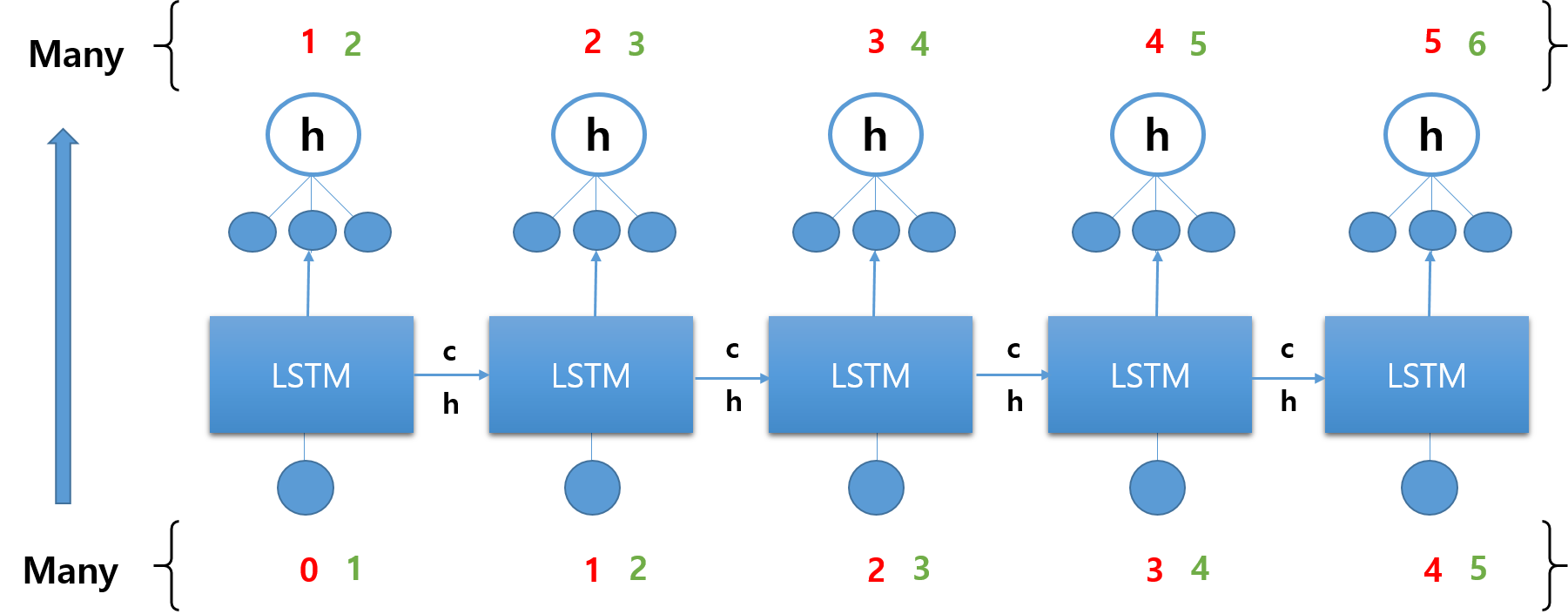 |
중간 스텝의 결과를 모두 이용한다. 각 스텝에서 출력이 이루어질 때마다 모두 loss가 계산되고, 각 지점에서 모두 오류가 전파된다. 중간 단계마다 모두 Feed Forward 네트워크를 두는 형태이다.
2.2. Many-to-One
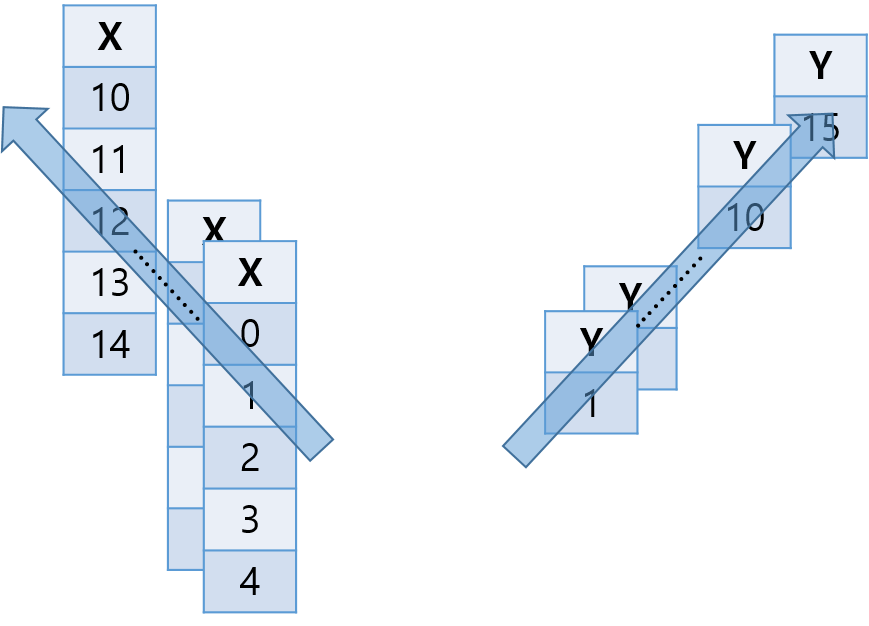
입력 데이터 [0, 1, 2, 3, 4]에 대해 라벨이 [5]만 출력되도록 하고자 할 때 적합한 유형이다.
| 라벨 | 모델 |
|---|---|
 |
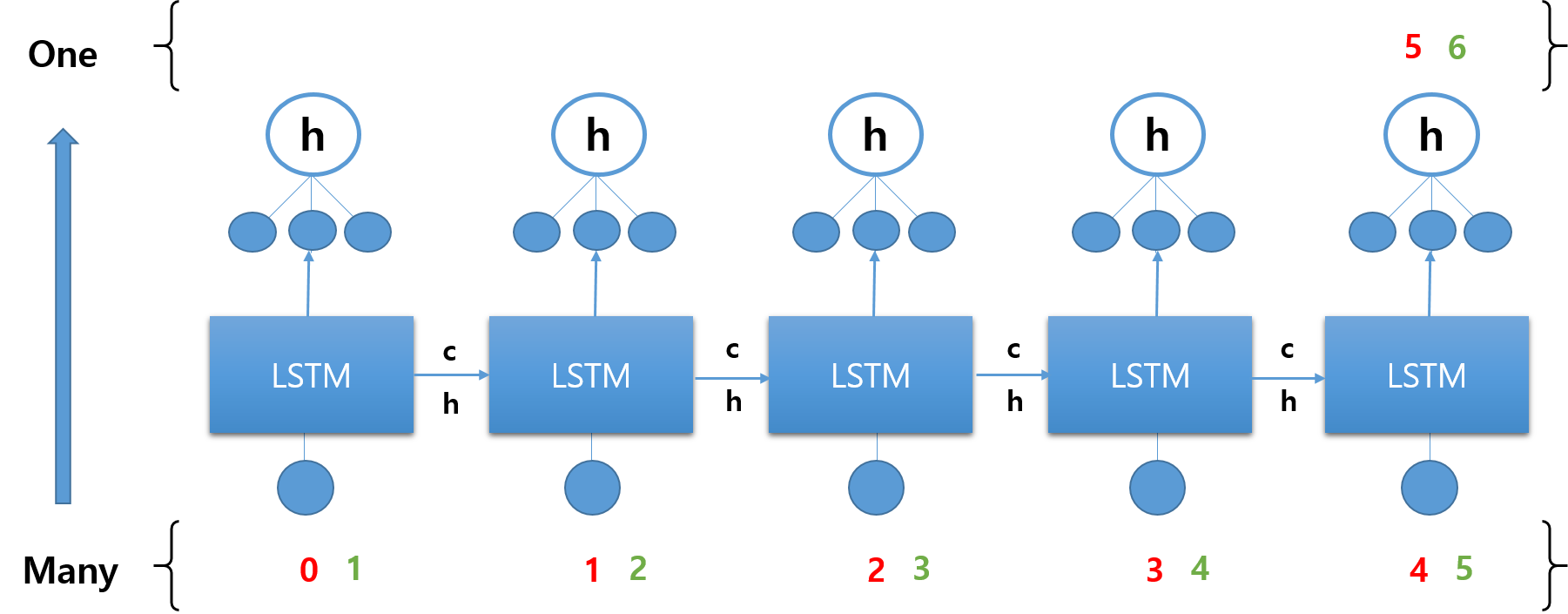 |
어차피 마지막 스텝에서 이전 스텝의 결과가 모두 반영될 것이라는 가정을 바탕으로 한다. 마지막 LSTM 뉴런까지 오는 과정에서 이전 LSTM 뉴런에서의 값이 계속해서 전달되므로, 중간 스텝의 결과는 굳이 반영하지 않아도 된다는 것이다. 맨 마지막 스텝에서 한 번만 loss를 계산하고, 오류는 끝까지 전파된다.

댓글남기기