
[DL] AutoEncoder_1.개념
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
오토 인코더 이해하기
1. 개요
오토 인코더는 입력 데이터가 그대로 나오게 하는 네트워크를 말한다. 딥러닝에서의 대표적인 비지도 학습 방법으로, 별도의 label이나 출력값이 없다. 입력과 출력 모두 같은 데이터를 활용한다.
참고
오토 인코더 모델을 self-supervised Learning이라고 하기도 한다.
비지도학습의 지도학습화로서 데이터의 추상화 및 latent feature 추출을 성공적으로 수행해난다는 점에서 각광 받았다.
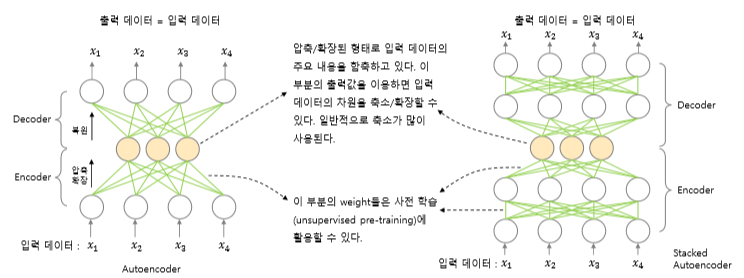
인코더와 디코더 두 부분으로 구성된다.
- 인코더: 입력 데이터를 네트워크 내부의 표현으로 변환한다.
- 디코더: 내부 표현으로 변환된 데이터를 출력으로 변환한다.
즉, 오토 인코더는 데이터를 입력 받아 인코딩과 디코딩 과정을 거쳐 나온 출력 데이터가 입력 데이터와 최대한 비슷하도록 재구성한다. 재구성 성능을 향상시키기 위해 은닉층에서 입력 데이터의 핵심 정보만 학습하는 것이 중요하다. 따라서 인코딩 과정을 거친 Hidden 레이어의 출력값(latent feature)을 확인하면, 입력값의 근사치가 되어 있다.
2. 구성
보통은 은닉층의 노드 수가 입력 층의 입력 feature 수보다 더 작아지도록 구성(이 경우, 모델 전체 구조가 마치 나비넥타이 혹은 모래시계 모양과 같아진다)하지만, 필수는 아니다. 그렇지만 편의를 위해 아래의 구성 예시는 모두 허리가 잘록한(나비 넥타이 모양의) 모델 구조를 가정한다.
참고
더 찾아 보니까, 은닉층의 노드 수가 입력 층의 feature 수보다 큰, 차원 증대 목적의 인코더 모델도 있다고는 한다. 해당 모델을 Sparse 오토 인코더라고 한다. 그러나 결과적으로 성공적이지 못했다. 또한, 노드 별로 sparsity를 계산하여 valid한 노드 수를 줄여 가므로, 엄밀한 의미에서 ‘차원을 증가시키는’ 모델 구조로 볼 수 있을지는 미지수다.
층을 몇 개로 구분하느냐에 따라 단층, 복층으로 구분한다. 이 때 복층 오토인코더의 경우는 Stacked 오토 인코더라고도 하며, 여러 개의 히든 레이어를 갖도록 구성한 것을 말한다. 당연한 말이지만, 층이 추가될수록 더 복잡한 작업을 수행할 수 있다. latent feature를 뽑아 내는 출력층을 기준으로 대칭인 형태를 띤다.
3. 활용
3.1. 차원 축소
PCA, SVD 등의 기존 차원 축소 방법론과 달리, 딥러닝 기반의 차원 축소를 진행할 수 있다. 입력 데이터와 출력 데이터가 같아지도록 학습하는 모델을 구성한다. 이 때 은닉층의 차원을 입력 데이터보다 더 작은 차원으로 설정해 latent feature를 추출하면 차원 축소가 가능해 진다.
3.2. 잡음 제거
기존의 데이터에 의도적으로 잡음을 삽입하고, 잡음이 있는 데이터와 원본 데이터를 입력 및 출력 데이터로 삼아 학습하는 모델을 구성한다. 학습이 완료된 오토인코더에 잡음이 포함된 데이터를 학습하면 잡음이 제거된 데이터가 출력된다. 주로 저해상도의 이미지를 고해상도의 이미지로 복원하는 데에 사용된다.
3.3. 이상치 검출
기존의 데이터를 모두 입력과 출력으로 하는 모델을 학습한다. 그리고 다시 모델에 입력 데이터를 넣어 예측하면, 원래 데이터와 다른 출력이 나오는 경우가 있다. 이를 원본과 비교하여 이상치를 검출하는 데 사용한다.
3.4. 비지도 사전학습
오토 인코더 모델이 가장 자주 사용되던 분야이다. 주로 다음의 두 가지 목적으로 사용한다.
- Pre-train & Fine-tune
- Vanishing Gradients 해결
특히 전자의 목적으로 많이 사용되는데, 상위 모델에 사용될 수 있는 데이터 및 가중치를 업데이트하기 위한 목적으로 사용한다. (약간 단어 임베딩 이런 거랑 비슷한 건가?)

댓글남기기