
[ML/DL] 분류 문제의 구분
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다.
Classification 문제의 구분
Classification 문제를 출력 라벨이 몇 개인지에 따라 이진 분류(Binary Classification), 다중 클래스 분류(Multi-class Classification), 다중 레이블 분류(Multi-label Classification)로 나눌 수 있다. 각 문제에 따라 활성화 함수와 손실 함수를 알맞게 선택해야 한다. 각 문제별로 정확도를 측정하는 방법도 달라진다.
간단해 보이지만, 개념이 제대로 잡혀 있지 않으면 문제를 알맞은 방식으로 풀 수 없기 때문에, 확실히 정리하고 넘어가도록 하자.
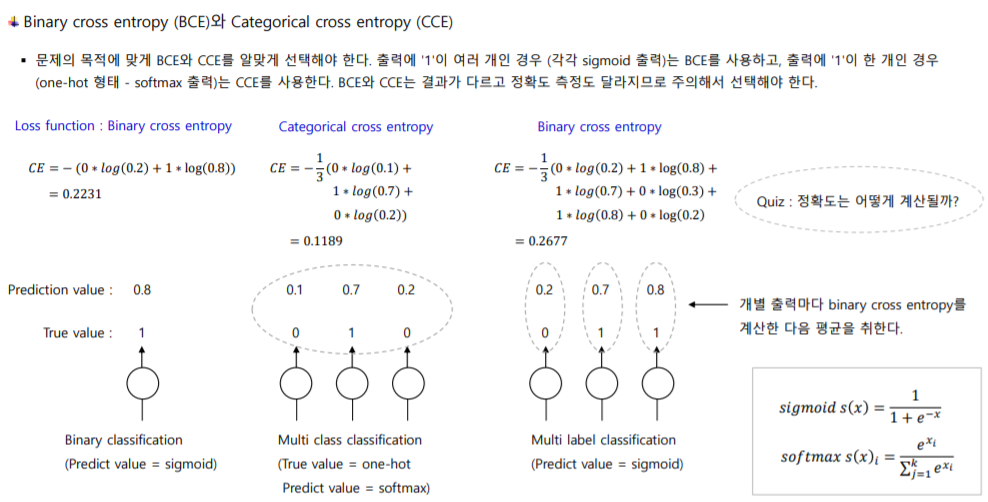
1. 이진 분류
출력해야 할 라벨(y값)이 2개로 구분된다. 활성화 함수로 sigmoid를 사용하고, 손실 함수로는 Binary Crossentropy를 사용한다.
참고
로지스틱 회귀분석에서는 일반 회귀분석처럼 손실 함수로 Mean Squared Error를 사용해도 된다. 그러나 일반적으로 Crossentropy를 사용할 때 수렴 속도가 더 빠르고 성능도 좋음이 알려져 있다. 딥러닝에서는 주로 Binary Crossentropy를 사용한다.
딥러닝에서는 출력층의 뉴런을 1개만 두고, sigmoid 함수의 로짓 값을 0.5를 기준으로 나누어 분류한다. 실제 라벨(y)과 예측 라벨(y_hat)이 다음과 같을 때, 정확도 계산은 전체 o, x의 개수 중 o의 개수이므로, 2/3이다.
| \(y\) | \(\hat {y}\) | 정답 여부 |
|---|---|---|
| 0 | 0 | o |
| 0 | 1 | x |
| 1 | 1 | o |
2. 다중 클래스 분류
출력해야 할 라벨(y값)이 3개 이상으로 구분된다. 그리고 각 입력 데이터에 대한 출력 라벨은 1개씩이다. 즉, 3개 이상의 라벨 중 하나의 값 만을 라벨로 가져야 한다. 따라서 라벨이 원핫(one-hot) 벡터 구조이다. 활성화 함수로 softmax를 사용하고, 손실 함수로는 Categorical Crossentropy를 사용한다.
딥러닝에서는 출력층의 뉴런을 라벨의 개수만큼 둔다. 그러나 나와야 하는 최종 출력 값은 1개이다. 한편, 딥러닝, 특히 케라스에서 라벨이 정수형으로 제공될 때는 Sparse Categorical Crossentropy를 사용한다. 아래와 같은 예시일 때, 정확도는 2/3이다.
| \(y\) | \(\hat {y}\) | 정답 여부 |
|---|---|---|
| 0 1 0 | 0 1 0 | o |
| 0 0 1 | 0 1 0 | x |
| 1 0 0 | 1 0 0 | o |
3. 다중 레이블 분류
출력해야 할 라벨(y값)이 3개 이상이고, 각 입력 데이터가 라벨을 2개 이상씩 가질 수 있는 경우이다. 각각의 데이터에 대해 이진 분류를 수행한다. 따라서 활성화 함수로 sigmoid를 사용하고, 손실 함수로는 Binary Crossentropy를 사용한다. 보통 각 라벨에 대해 출력된 sigmoid 로짓 값이 0.5보다 큰 경우, 해당 라벨을 가질 수 있다고 판단한다.
딥러닝에서는 출력층의 뉴런이 여러 개인데, 나와야 하는 최종 출력값도 여러 개인 경우이다. 아래와 같은 예시일 때, 정확도를 계산하면 7/9가 된다.
| \(y\) | \(\hat {y}\) | 정답 여부 |
|---|---|---|
| 0 1 0 | 0 1 0 | o o o |
| 0 0 1 | 0 1 0 | x x o |
| 1 0 0 | 1 0 0 | o o o |
0803 추가
N-gram을 이용해 다음 단어를 예측하는 과제에서, Multi-label Classification 개념이 등장한다. 3-gram 다음에 나올 2-gram을 예측하는 문제였다. 라벨(다음에 나와야 할 단어) 1로 표시되는 단어 인덱스의 위치가 2개이기 때문에, 출력층에 1이 2개 나오도록 해야 한다.
모델 네트워크 구성은 마음대로 하면 된다. 다만, 컴파일 시 학습 환경을 어떻게 설정해야 할지에 대한 부분만 주의해서 보자.
# FFN 네트워크 설정
X_input = Input(shape=(X_train.shape[1], ))
X_dense_1 = Dense(256, activation='relu')(X_input)
X_dense_1 = Dropout(0.2)(X_dense_1)
X_dense_2 = Dense(128, activation='relu')(X_dense_1)
X_dense_3 = Dense(256, activation='relu')(X_dense_2)
X_dense_3 = Dropout(0.3)(X_dense_3)
y_output = Dense(y_train.shape[1], activation='sigmoid')(X_dense_3)
# 모델 구성
model = Model(X_input, y_output)
model.compile(optimizer=RMSprop(learning_rate=0.01), loss='binary_crossentropy')
print("======= 모델 전체 구조 ======")
print(model.summary())
참고로, 결과를 확인했을 때 그다지 좋지는 않다. 출력층에서 2개만 출력되도록 하지는 않고, sigmoid 로짓 값 중 가장 높은 2개의 인덱스를 찾아 원래 어휘로 변환해 주었다. 다만, 기존 sigmoid 로짓 값의 분포가 0과 1의 양쪽으로 잘 갈라지지는 않는다. 학습이 잘 안 되었다는 말이다.
랜덤으로 10개의 테스트 데이터에서 실제로 어떤 단어가 예측되었는지를 봤을 때, 잘 맞추지 못하고 and, the 등의 단어가 많이 나오는 것을 볼 수 있다.
6189 and it don | let him | at all
6415 on if you | don know | to you
1571 never forgotten that | if you | they very
3923 dripping wet cross | and uncomfortable | little was
7025 like this fury | to said | the in
7159 replied in an | offended tone | of or
6386 that nothing more | happened she | you to
2627 were writing down | things stupid | the and
2152 the english coast | find you | was the
1266 their verdict the | king said | and the
성능이 만족스럽게 나오지 않는 원인으로 여러 가지가 있을 수 있다. 그러나 기본적으로는 다음의 2가지를 생각해 볼 수 있다.
- 단순 빈도 기반으로 수치화했다.
제대로 하려면임베딩이 필요하다. - 데이터 자체가 불충분하다.
참고 : 다른 방식의 모델 구성
처음에는 이 문제를 다중 레이블 분류 문제로 풀지 않고, 다음의 방식으로 풀었다.
5-gram중(0, 1, 2)번째 단어를 가지고3번째 단어를 예측하도록,(1, 2, 3)번째 단어를 가지고4번째 단어를 예측하도록 학습하는 모델을 각각 구성한다.5-gram중(0, 1, 2)번째 단어를 가지고3번째 단어를 예측하도록 학습하고, 동일한 모델의 예측값을 활용해(1, 2, 3)번째 단어를 가지고4번째 단어를 예측한다.5-gram중(0, 1, 2)번째 단어를 가지고3번째 단어를 예측하고,4번째 단어를 예측하도록 학습하는 모델을 각각 구성한다.위의 경우들에서는 모델을 어떻게 구성하느냐만 달라질 뿐, 문제 목적 자체는 다중 클래스 분류 문제가 된다. 그러나 위의 방식 중 그 어느 것도 loss 값이 만족스럽게 떨어진 것이 없었으며, 예측 단계에서도 제대로 맞춘 것이 없었다.


댓글남기기