
[NLP] DMN_1.개념
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. 논문 출처
DMN 이해하기
1. 개요
DMN(Dynamic Neural Network)는 NLP 태스크들을 QA(Question answering) 문제로 보고, Input Sequence(입력 문장)과 Question Sequnce(질문)의 인코딩을 통해 어텐션 메커니즘을 구현함으로써 Answer(정답)를 찾아내고자 하는 신경망 모델이다.
논문의 제목부터가 Ask Me Anything이다. Anything을 통해 NLP 분야의 모든 태스크를, Ask, 질문 답변의 문제로 보고 있음을 알 수 있다.
참고 : NLP 태스크의 QA화
논문 원문 표현을 통해 저자들이 기존 NLP 태스크들을 어떻게 QA 구조로 설명하고 있는지 확인하자.
Most, if not all, tasks in natural language processing can be cast as a question answering problem: high level tasks like machine translation (What is the translation into French?); sequence modeling tasks like named entity recognition (Passos et al., 2014) (NER) (What are the named entity tags in this sentence?) or part-of-speech tagging (POS) (What are the part-of-speech tags?); classification problems like sentiment analysis (Socher et al., 2013) (What is the sentiment?); even multi-sentence joint classification problems like coreference resolution (Who does ”their” refer to?).
DMN은 뇌과학 아이디어에 기반하여 Episodic Memory라는 것을 구현한다. 이 메모리 네트워크의 존재로 인해, 아무런 태깅이나 정답 없이도, 네트워크는 이행적 추론만을 통해 질문에 맞는 정답을 찾기 위해 어떤 문장에 주목해야 할지를 찾아낸다. 그 이름에서도 알 수 있듯, Dynamic한 방식으로 작동한다. 후술하겠지만, 어텐션 스코어를 반복적으로 계산함으로써, 기억 위에 기억을 쌓아 나가는 방식으로 작동한다.
2. 네트워크 구조
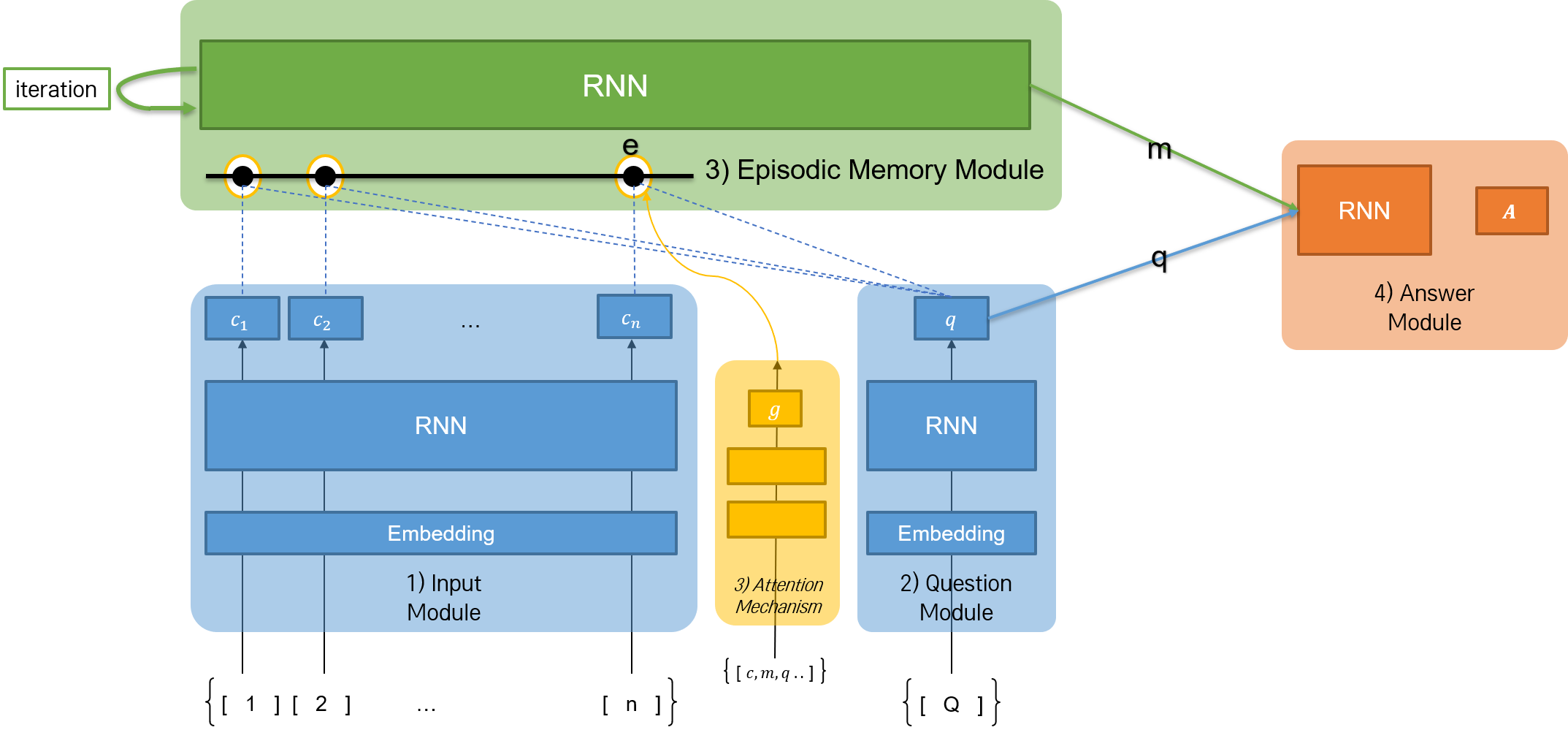
DMN은 위와 같이 4개의 모듈로 구성된 네트워크이다. 각각의 모듈을 동작 순서에 따라 나타내면 1) Input Module, 2) Question Module, 3) Episodic Memory Module, 4) Answer Module이며, 각각의 모듈 역시 네트워크이다. 각 네트워크는 모두 자연어 시퀀스를 다루기 때문에, 순환신경망 계열의 네트워크를 사용한다.
1) Input Module
입력 문장의 시퀀스를 인코딩하고, RNN 네트워크에 의해 hidden state를 출력한다. 여러 개로 구성된 문장의 끝에 <End of Sentence> 토큰을 붙여 하나의 리스트로 만든다. Embedding 레이어를 거친 후, 인코딩된 시퀀스 리스트가 RNN 네트워크로 올라 간다. 그리고 문장의 개수만큼 hidden state \(c\)가 출력된다.
\[h_t = RNN(L[w_t], h_{t-1})\]참고
문장의 길이에 따라 Input Module의 hidden state 출력이 달라진다. 사실, 논문의 표현에 따르면 하나의 문장일 때 Input Module의 출력은 각 토큰이 RNN 셀을 거친 결과이다. 그러나 여러 개의 문장일 때는 Input Module에서는
<End of Sequence>를 만날 때마다 hidden state가 출력된다고 보면 된다. 문장이 한 개만 입력되는 경우는 많지 않기 때문에, 위의 설명에서와 같이 이해해도 무방할 듯하다.
수식은 이전부터 보았던 RNN 네트워크 작동 원리와 동일하다. w는 입력 시퀀스 내의 단어를, L은 임베딩을 나타낸다. 한편, 논문에서는 RNN 네트워크로 GRU 네트워크를 선택한다고 밝혔다.
2) Question Module
질문 시퀀스를 인코딩한다. 작동 원리 자체는 1)의 Input Module과 크게 다르지 않다. 구체적인 수식은 다음과 같다.
수식을 조금 더 엄밀히 살펴 보자면 질문 내 단어 시퀀스들을 각각 RNN 네트워크에 넣어 time step마다 recurrent하며, 마지막 단어 시퀀스에서의 RNN 네트워크의 hidden state 출력을 q로 나타낸다. 역시나, 이번 단계에서도 GRU 네트워크를 선택한다.
3) Episodic Memory Module
DMN 네트워크의 핵심이다. attention score g를 계산하는 scoring function G에 의해 question q와 attention score가 가장 높은 문장 c를 찾아 낸다.
이 때, 각 입력 시퀀스들은 여러 개의 episode로 구성된다. 다음의 예를 보자.
- I : Jane went to the hallway.
- I : Mary walked to the bathroom.
- I : Sandra went to the garden.
- I : Daniel went back to the garden.
- I : Sandra took the milk there.
위의 모든 문장들은 하나의 입력 시퀀스(I)를 구성하지만, 각각은 서로 다른 episode(사건 정도로 이해해도 무방할 듯하다.)로 구성되어 있다.
특히, DMN 네트워크에서는 입력 시퀀스에 대해 이와 같이 attention score가 가장 높은 문장을 찾아 내는 과정을 여러 번 반복(iteration)한다. 그러면 각각의 iteration마다, 각 episode에서 나오는 attention score가 달라지게 된다. 마치 사람이 똑같은 책을 한 번 읽을 때와 여러 번 읽을 때 주목하는 부분이 달라지는 것과 같다. 이것이 바로 해당 네트워크 내에서 memory가 dynamic하는 원리이다.
우선 논문에서 설명하는 attention mechanism부터 보자. attention score를 계산하는 과정과, 메모리 모듈 내에서 업데이트 하는 과정 두 가지로 이루어진다.
먼저 attention score를 계산하는 네트워크이다. 위의 그림에서 보듯, 2층 구조의 네트워크이다. 공간 상의 한계로 모두 표현하지는 못했지만, Input Module에서의 hidden state c, Episodic Memory Module에서의 출력 m, Question Module에서의 출력 q, 그리고 각각을 수학적으로 계산하여 만들어 낸 여러 가지 feature를 입력으로 받는다. 이를 z라고 한다. 그리고 scoring function G는 z를 2층 구조의 네트워크에 넣어 각 층에서 hyperbolic tangent, sigmoid 활성화 함수를 적용한 attention score g를 출력한다. 수식으로 확인하면 다음과 같다.
당연히 2층에서 sigmoid 함수를 거치기 때문에, attention score의 값은 0과 1 사이로 나오게 된다. 또한, 첫 번째 iteration에서는 episodic memory module의 출력값 m이 없기 때문에, q를 사용한다.
다음으로 메모리를 업데이트하는 메커니즘이다. attention score g를 가중치로 삼아 해당 단계에서의 메모리 출력과 이전 단계에서의 hidden state의 가중 평균을 계산한다. 각각의 time step에서 같은 방식으로 hidden state를 업데이트한 뒤, 각 입력 시퀀스 문장에 대한 attention score로는 마지막 time step에서의 hidden state를 선택한다. 수식으로 확인하면 다음과 같다.
Criteria for Stopping
강사님께서 설명하시지는 않았지만, 논문을 보면 iteration을 언제까지 반복할지 gate function에 special end-of-passes representation을 넘김으로써 조절한다고 한다.
4) Answer Module
마지막으로 Answer Module에서는 시퀀스의 형태로 질문에 대한 정답을 찾아 낸다. GRU 네트워크를 사용하며, softmax를 활성화 함수로 한 hidden state를 GRU 네트워크의 입력으로 받는다.
\[y_t = softmax(W^{(a)}a_t) \\ a_t = GRU([y_{t-1}, q], a_{t-1})\]3)에서와 마찬가지로, 첫 iteration에서는 예측 정답 a가 없기 때문에, episodic memory module에서의 출력값 m을 사용한다.
3. 논문 그림으로 이해하기
논문에서 네트워크의 구조를 나타낸 그림은 아래와 같다.
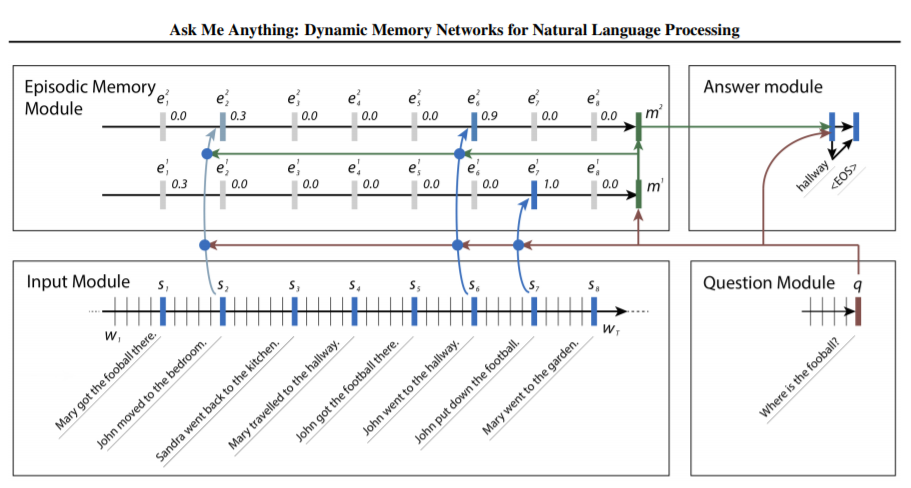
기계번역의 예시라고 보면 된다. 입력 시퀀스가 8개의 에피소드로 구성되어 있고, 대답해야 할 질문은 Where is the football?이다.
첫 번째 iteration 과정을 보자. Input Module에서 입력 시퀀스가 각각 Embedding되어 RNN 셀로 올라 가고, 출력이 나온다. Question Module에서 q값이 계산되고, Input Module에서 각 문장의 출력값과 attention score를 계산한다. 이 때는 m 값이 없기 때문에, attention score를 계산하기 위해 feature로서 Input Module의 출력값 외에 Question Module의 출력값 q를 2번 이용한다.
Question Module에서 timestep을 거치며 최종 출력으로의 q는 football에 가중치가 높을 것이다. 그리고 attention score를 계산할 때에 있어서도 football이 있는 문장에 대한 점수가 높게 나온다. 물론, 멀수록 그 점수는 낮아진다.
두 번째 iteration 과정을 본다. 첫 번째 iteration에서 계산된 m 값에 의해, 이제는 John put down the football 문장과 관련성이 높은 John went to the hallway라는 문장의 attention score가 높게 계산된다.
이 과정을 반복함으로써 결과적으로 hallway를 찾아내게 된다. 각 iteration 과정을 거치며, 이전 문장들을 살펴보며 어떤 episode에 attention을 주어야 할지를 dynamic하게 찾아 낸다. 즉, Episodic Memory Module에서 각각의 문장에 대한 정보를 m에 태워 Answer Module로 보내고, Question Module에서의 q와 각 iteration에서의 정보 m을 종합하여 정답을 찾아내게 된다.
4. 의의
현재 NLP 태스크의 단계를 나누어 보면 다음과 같다.
- 1단계: 한 문장 안에서 단어 간 의미 파악. 한 개의 문장 분석.
- 2단계: 문장 간 관계 및 의미 파악. 여러 개의 문장 분석.
→“시의 영역” - 3단계: 문단 간 관계 및 의미 파악.
→“소설의 영역”
지금 NLP 수준은 대부분 1단계에 있다. 그러나 이 논문은 2단계에 도전하기 위한 메커니즘을 제시한다. attention score를 계산함으로써 여러 개의 episodic story 간에서 question에 대한 답을 찾는다. 문장 간 관계를 attention score라는 수치화 메커니즘을 통해 파악한다는 점에 그 의의가 있는 것이다.

댓글남기기