
[NLP] Kaggle IMDB_2.구현
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
IMDB 감성 분석-과제-Kaggle 우승자 아이디어 구현
이전에 분석한 IMDB Kaggle 감성 분석 대회 우승자의 논문을 바탕으로, 아이디어를 구현해 보자. 모든 방식을 다 적용하기는 어렵고, 크게 다음의 부분에 초점을 맞추자.
- 데이터 전처리 : 영어 부정어에 해당하는 어휘 목록이 없기 때문에, negation handling은 제외한다.
- 상호 정보량 기반의 MI 점수 계산 : unigram만 진행한다.
- TF-IDF 임베딩과 Doc2Vec 임베딩 결합 : 임베딩 차원은 자유롭게 설정한다.
이후 모델링 방법, (혹시 딥러닝을 사용할 것이라면) 네트워크 구성 등은 자유롭게 결정하도록 한다. Kaggle 대회에서의 리더보드 채점 방식이 Roc-Auc Score이기 때문에, 분류를 수행했을 때 분류 정확도가 어느 정도 나오는지, 해당 경우에 Roc-Auc Score를 계산했을 때 점수가 몇 점 정도 나오는지 확인하도록 하자.
1. 내 풀이
필요한 모듈을 불러 온다. 다음과 같다.
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import re
from nltk import word_tokenize
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
from collections import Counter
import math
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.feature_selection.text import TfidfVectorizer
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Input, Dense, Dropout, Concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
1.1. 전처리
Kaggle에서 제공한 원본 데이터는 id, sentiment, review의 세 컬럼으로 이루어져 있다. 앞의 논문에서 이야기한 것과 같은 방식으로 기본적인 전처리를 수행하는 clean_text 함수를 만들어 데이터를 정제한다. 정제한 후의 텍스트와 라벨을 나타내는 sentiment 만 컬럼으로 남긴다.
def clean_text(x):
x = BeautifulSoup(x, 'lxml').get_text() # HTML 태그 제거
x = re.sub("[^a-zA-Z]", " ", x) # 영문자 제외 제거
x = x.lower() # 소문자화
x = [word for word in x.split() if not word in stopwords.words('english')] # 불용어 제거
x = [PorterStemmer().stem(word) for word in x] # 포터 스테밍으로 어간 추출
return " ".join(x)
df_raw['text'] = df_raw['review'].apply(lambda x: clean_text(x))
df = df_raw[['text', 'sentiment']]
이후 어휘집을 생성하고, 상호 정보량 점수를 계산한다.
def build_vocab(df):
vocabulary = Counter()
for text in df['text']:
for word in list(set(word_tokenize(text))): # 중복 단어 제거
vocabulary[word] += 1
return vocabulary.most_common() #
def calc_MI(pos_df, neg_df):
pos_vocab = build_vocab(pos_df) # 긍정 라벨 어휘집
neg_vocab = build_vocab(neg_df) # 부정 라벨 어휘집
total_cnt = len(pos_df) + len(neg_df) # 총 어휘집 개수
merge_vocab = {} # 각 단어 별 긍정 리뷰, 부정 리뷰 등장 빈도 계산할 dict
for k, v in pos_vocab:
merge_vocab[k] = [v, 0]
for k, v in neg_vocab:
if k in merge_vocab: # 이미 긍정 단어 어휘집에 있었던 단어
merge_vocab[k][1] = v
else:
merge_vocab[k] = [0, v]
# 상호 정보량 계산
clip = 0.000001 # log0 방지
for k, v in merge_vocab.items():
vocab_cnt = v[0] + v[1] # 긍정, 부정 리뷰에 등장한 수
merge_vocab[k] = (v[0] / total_cnt) * math.log(2*(v[0] + clip)) / vocab_cnt + \
(v[1] / total_cnt) * math.log(2*(v[1] + clip)) / vocab_cnt
return {k:v for k, v in sorted(merge_vocab.items(), key=lambda x: x[1], reverse=True)}
# 긍정 리뷰와 부정 리뷰로 분리
df_pos = df[df['sentiment'] == 1]
df_neg = df[df['sentiment'] == 0]
vocabulary = calc_MI(df_pos, df_neg)
# 각 단어 별 MI 점수 계산한 어휘집 생성
vocabulary = calc_MI(df_pos, df_neg)
nltk 패키지의 word_tokenize 함수를 이용해 각 문장을 토큰화하고, Counter 함수를 사용해 각 문장에 등장하는 단어의 빈도를 세서 어휘집을 만드는 build_vocab 함수를 만들었다. 각 문장에서 단어의 등장 빈도를 모두 세지 않고, 한 문장에 등장했으면 1번으로 간주하고 다음 문장으로 넘어 간다.(TF-IDF에서 DF 계산과 같은 원리이다.)
calc_MI 함수는 상호 정보량을 value로, 단어를 key로 하는 dictionary를 반환한다. 그 안에서 각각의 긍정 리뷰 문장과 부정 리뷰 문장에 대해 따로 어휘집을 적용해, 긍정 리뷰 문장에 대한 어휘집, 부정 리뷰 문장에 대한 어휘집을 따로 만들었다.
merge_vocab은 모든 단어에 대한 어휘집으로, 긍정 및 부정 단어집에 등장한 모든 단어를 key로, 그리고 그것의 상호 정보량을 value로 갖는 dictionary이다. 초기 merge_vocab은 긍정 단어집, 부정 단어집에 등장한 모든 단어를 key로, 그리고 긍정 문장에서의 등장 빈도와 부정 문장에서의 등장 빈도의 리스트를 value로 갖도록 설정한다. 그리고 각 단어(dictionary의 key)에 해당하는 value에서 리스트 인덱싱을 이용해 상호 정보량 점수를 계산한다. 상호 정보량 점수 계산 공식은 저자의 논문 및 기존 상호 정보량 계산 공식 ( 정보이론 참고) 을 따른다.
그리고 상호 정보량 크기에 따라 정렬된 dictionaty를 {word : index}의 형태로 만든 어휘집을 반환한다.
이렇게 만든 총 어휘집의 크기는 50593개이다. 논문에서는 7만 개가 넘는 어휘집이 나왔으나, 전처리 방식의 차이인지, 우승자의 논문에서처럼 구현되지는 않았다. MI score가 가장 높은 상위 20개의 단어를 확인했다.
worst
bad
wast
aw
excel
great
stupid
bore
terribl
wors
horribl
beauti
love
perfect
poor
crap
noth
poorli
suppos
lame
전처리 단계에서 어간화를 진행했기 때문에 논문의 Top 20 unigrams와 동일한 결과는 아니지만, 비슷한 형태의 단어들이 추출되었음을 알 수 있다.
이후 MI 점수 기준 상위 50%에 해당하는 단어만을 남긴 word2idx 어휘집을 생성한다. 나중에 문장을 decode해야 할 경우를 대비해 idx2word 어휘집도 만든다. 나중에 OOV이거나 패딩인 경우 0의 인덱스를 사용하게 될 것이므로, 1을 더해 준다.
# 상위 50%에 해당하는 어휘집 생성
num = int(len(vocabulary) * 0.5)
word2idx = {k:i+1 for i, (k, v) in enumerate(vocabulary.items()) if i <= num}
idx2word = {v:k for k, v in word2idx.items()}
생성한 어휘집을 기반으로 단어를 토크나이징한다. try ~ excet … 문을 활용해 OOV를 제거했다. train data 내 OOV로만 이루어진 문장은 없다.
tokens = []
for idx, text in enumerate(df['text']):
temp = []
delete_indices = [] # OOV로만 이루어진 문장
for word in text.split():
try:
temp.append(Word2idx[word])
except KeyError:
continue
if len(temp) > 0:
tokens.append(temp)
else: # OOV로만 이루어진 문장의 index
delete_indices.append(idx)
문장 길이를 확인한 후, 패딩한다. 최대 길이를 200으로 설정했다. 패딩까지 진행한 후, train data의 총 shape은 (25000, 200)이다.
# 문장 길이 체크
def check_len(threshold, sentences):
cnt = 0
for sent in sentences:
if len(sent) <= threshold:
cnt += 1
return f'전체 문장 중 길이가 {threshold} 이하인 샘플의 비율: {(cnt/len(sentences))*100}'
for i in range(10, 300, 10):
print(check_len(i, tokens))
# 문장 패딩
MAX_LENGTH = int(input('문장 최대 길이 설정: '))
X_train = pad_sequences(tokens, maxlen=MAX_LENGTH, padding='post', truncating='post')
X_train = np.array(X_train)
[참고] Keras Embedding
전처리 단계까지 진행한 후, Keras Embedding 레이어를 사용해 기존 수업에서 구성했던 컨볼루션 필터 사이즈를 달리 한 CNN 모델을 훈련시켰다. 총 훈련 데이터에서 검증 데이터셋의 비율을 0.1로 설정한 뒤, 단순 정확도를 측정했다. 기존에는 정확도가 83% 정도였는데, 아무 것도 바꾸지 않았음에도 87.76%의 정확도가 나왔다. 미미하지만, 전처리를 통해 같은 네트워크 구성임에도 불구하고 정확도가 향상될 수 있음을 확인했다.
# 트레인 테스트 스플릿
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.1, random_state=42)
# CNN 네트워크 파라미터
VOCAB_SIZE = X_train.max() + 1
EMB_SIZE = 32
NUM_FILTER = 64
# CNN 네트워크 구성
X_input = Input(batch_shape=(None, X_train.shape[1]))
X_embed = Embedding(input_dim=VOCAB_SIZE, output_dim=EMB_SIZE)(X_input)
X_embed = Dropout(rate=0.5)(X_embed)
X_conv_1 = Conv1D(filters=NUM_FILTER, kernel_size=3, activation='relu')(X_embed)
X_pool_1 = GlobalMaxPool1D()(X_conv_1)
X_conv_2 = Conv1D(filters=NUM_FILTER, kernel_size=4, activation='relu')(X_embed)
X_pool_2 = GlobalMaxPool1D()(X_conv_2)
X_conv_3 = Conv1D(filters=NUM_FILTER, kernel_size=5, activation='relu')(X_embed)
X_pool_3 = GlobalMaxPool1D()(X_conv_3)
X_concat = Concatenate()([X_pool_1, X_pool_2, X_pool_3])
X_hidden = Dense(64, activation='relu')(X_concat)
X_hidden = Dropout(rate=0.5)(X_hidden)
y_output = Dense(1, activation='sigmoid')(X_hidden)
# CNN 모델 구성
model = Model(X_input, y_output)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0005))
print("========= 모델 전체 구조 확인 =========")
print(model.summary())
# 모델 학습
es = EarlyStopping(monitor='val_loss', patience=3, verbose=1)
hist = model.fit(X_train, y_train
validation_data = (X_test, y_test),
batch_size = 500,
epochs = 30,
callbacks=[es])
1.2. 임베딩
논문에 소개된 것처럼 TF-IDF 행렬을 활용한 임베딩과 Doc2Vec 임베딩을 진행한다.
train_features = np.copy(X_train)
# TF-IDF 임베딩
corpus = [" ".join(sequence) for sequence in sequences]
vectorizer = TfidfVectorizer().fit(corpus)
tfidf_vec = vectorizer.transform(corpus).toarray()
# Doc2Vec 임베딩
doc2vec_features = int(input('Doc2Vec 임베딩 차원 설정: '))
model_path = f"{data_path}/IMDB_{doc2vec_features}features.doc2vec" # 사용할/로드할 모델 경로 설정
try:
doc_model = Doc2Vec.load(model_path)
except: # 저장된 모델 없는 경우
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(sequences)]
doc_model = Doc2Vec(vector_size=doc2vec_features,
alpha=0.005,
min_alpha=0.0001,
min_count=1,
workers=4,
dm=1)
doc_model.build_vocab(documents)
doc_model.train(documents, total_examples=doc_model.corpus_count, epochs=10)
doc_model.save(model_path)
doc2vec_vec = [doc_model.docvecs[i] for i in range(len(sequences))] # Doc2Vec 임베딩 벡터
doc2vec_vec = np.array(doc2vec_vec)
TF-IDF 임베딩을 진행할 때 max_features를 제한하지 않았다. TF-IDF 임베딩 벡터의 shape은 (25000, 24530)다.
또한, Doc2Vec 임베딩에서는 400차원의 임베딩을 진행했다. Doc2Vec 임베딩 벡터의 shape은 (25000, 400)이며, 해당 모델 안의 단어 개수는 24539개였다. 한편, Doc2Vec 임베딩을 진행하는 과정에 시간이 오래 소요될 것을 생각해 저장해 놓았다.
1.3. 모델링
# 검증 셋 분리
X_train_tf, X_test_tf, X_train_doc, X_test_doc, y_train, y_test = train_test_split(tfidf_vec, doc2vec_vec, train_labels,
test_size=0.2,
random_state=42)
# FFN 네트워크 설정
X_input_1 = Input(batch_shape=(None, tfidf_vec.shape[1])) # TFIDF 입력
X_dense_1 = Dense(64, activation='linear')(X_input_1) # 선형 projection
X_input_2 = Input(batch_shape=(None, doc2vec_vec.shape[1])) # Doc2Vec 입력
X_dense_2 = Dense(64, activation='linear')(X_input_2)
X_concat = Concatenate()([X_dense_1, X_dense_2])
y_output = Dense(1, activation='sigmoid')(X_concat)
# 모델 구성
K.clear_session()
model = Model([X_input_1, X_input_2], y_output)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001))
print("====== 전체 모델 구조 확인 ======")
print(model.summary())
# 학습
es = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
hist = model.fit([X_train_tf, X_train_doc], y_train,
epochs=300,
batch_size=300,
callbacks=[es],
validation_data=([X_test_tf, X_test_doc], y_test))
각각의 임베딩 벡터를 선형 projection하여 Concatenate 레이어를 이용해 단순히 두 임베딩 벡터를 결합했다. 가장 기본적인 Feed Forward 네트워크를 구성했는데, 이 모델의 구조를 나타내면 다음과 같다.
====== 전체 모델 구조 확인 ======
Model: "functional_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 24530)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 400)] 0
__________________________________________________________________________________________________
dense (Dense) (None, 64) 1569984 input_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 64) 25664 input_2[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 128) 0 dense[0][0]
dense_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 129 concatenate[0][0]
==================================================================================================
Total params: 1,595,777
Trainable params: 1,595,777
Non-trainable params: 0
__________________________________________________________________________________________________
None
2. 결과
조기 종료 조건을 검증셋 손실, patience를 10으로 하여 모델을 훈련시켰다. loss의 변화 추이는 다음과 같다.
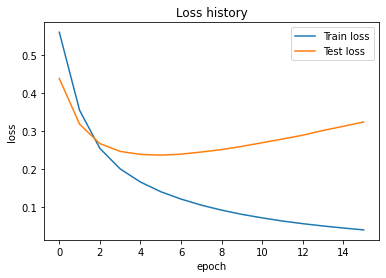
단순 정확도는 88.2%로, 기존에 얻었던 결과보다 향상되었음을 알 수 있었다. Kaggle에 제출하기 위해 검증셋에 대한 Roc-Auc를 측정해 본 결과, 0.8819 정도가 나왔다. 이후 Kaggle 테스트 데이터셋을 동일한 방식으로 전처리하고, 예측했다. 제출한 후 점수는 82228이었다(…). 매우 낮다.
이후 다른 모델 및 학습 방식(조기 종료 조건을 주지 않고, 배치 사이즈를 변경했으며, shuffle 옵션을 주었다.)을 적용했다.
# 학습 : early stopping 없이
K.clear_session()
# FFN 네트워크 설정
X_input_1 = Input(batch_shape=(None, tfidf_vec.shape[1]))
X_dense_1 = Dense(200, activation='relu')(X_input_1)
X_dense_1 = Dropout(0.5)(X_dense_1)
X_input_2 = Input(batch_shape=(None, doc2vec_vec.shape[1]))
X_dense_2 = Dense(200, activation='relu')(X_dense_2)
X_dense_2 = Dropout(0.5)(X_dense_2)
X_concat = Concatenate()([X_dense_1, X_dense_2])
y_output = Dense(1, activation='sigmoid')(X_concat)
model = Model([X_input_1, X_input_2], y_output)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0001))
model.fit([X_train_tf, X_train_doc], y_train,
batch_size = 512,
epochs = 500,
shuffle = True,
validation_data = ([X_test_tf, X_test_doc], y_test))
검증셋에 대한 정확도는 0.8654로 떨어졌지만, Roc-Auc Score가 0.9391로 증가했다. 기대감을 안고 Kaggle 데이터를 예측해서 채점했지만, 캐글 채점 서버 상에서 Roc-Auc Score는 0.80172로 떨어졌다(…). 과적합 + 예측 상의 다른 오류가 있는지 점검해보아야 겠다.
3. 강사님 풀이
강사님의 풀이에서 가장 배우고 싶은 부분은 MI score 계산 방식이었다. 내 방식에 비해 훨씬 깔끔했다. 강사님께서는 Keras의 tokenizer를 이용해 word2idx 어휘집을 미리 만들어 놓으신 후, MI 점수를 계산하셨다. 또한, numpy와 문장 라벨(0, 1)을 이용해 훨씬 깔끔하게 MI 점수 계산 과정을 구현하셨다. (난 언제쯤!)
from tensorflow.keras.preprocessing.text import Tokenizer
# 1차 vocabulary
tokenizer = Tokenizer()
tokenizer.fit_on_texts(reviews)
word2idx = tokenizer.word_index
idx2word = {v:k for k, v in word2idx.items()}
text_sequences = tokenizer.texts_to_sequences(reviews)
# 단어-label 리스트
word_label = []
for review, label in zip(text_sequences, sentiments):
for w in review:
word_label.append([w, label])
word_label = np.array([w, label])
# y=0인 단어 목록과 y=1인 단어 목록
X = np.array([np.where(word_label[:, 1] == i)[0] for i in [0, 1]])
# p(y=0), p(y=1) 계산: 인덱싱 이용
py = np.array([(word_label[:, 1] == i).mean() for i in [0, 1]])
N = len(idx2word)
# MI 계산
mi_word = []
for i in range(1, N):
px = (word_label[:, 0] == i).mean()
mi = 0
for y in [0, 1]:
pxy = (word_label[x[y], 0] == i).mean()
mi += (pxy * py[y]) * np.log(1e-8 + pxy)/px
mi_word.append([mi, i])
if i % 100 == 0: # 확인
print(i, '/', N)
# 정렬 후 상위 20개 단어 확인
mi_word.sort(reverse=True)
print([idx2word[y] for x, y in mi_word[:20]])
또한, 강사님께서는 두 임베딩 벡터의 차원을 일치시키셨다. 생각해 보니, 나는 TF-IDF 벡터의 차원을 제한하지 않았었는데, 코드를 짜면서 이것을 전혀 고려하지 못했다.
# 전체 리뷰 문서 TF-IDF 변환
sentences = []
for review in reviews:
sentences.append(' '.join(review))
vectorizer = TfidfVectorizer(min_df = 1, analyzer="word", sublinear_tf=True,
ngram_range=(1,1), max_features=EMB_SIZE)
tfidf = vectorizer.fit_transform(sentences).toarray()
마지막으로, 강사님께서는 다음과 같은 네트워크를 구성하셨다. 검증셋으로 측정한 단순 정확도는 0.8776이며, Roc-Auc Score는 0.9478이었다.
adam = optimizers.Adam(lr=0.0001)
x1 = Input(batch_shape=(None, EMB_SIZE))
x2 = Input(batch_shape=(None, EMB_SIZE))
h1 = Dense(200, activation='linear')(x1)
h1 = LeakyReLU(0.5)(h1)
h2 = Dense(200, activation='linear')(x2)
h2 = LeakyReLU(0.5)(h2)
concat = Concatenate()([h1, h2])
yOutput = Dense(1, activation='sigmoid')(concat)
model = Model([x1, x2], yOutput)
model.compile(loss='binary_crossentropy', optimizer=adam)
4. 배운 점, 더 생각해 볼 점
그 동안 강의에서의 네트워크 구성으로는 0.85 이상의 정확도를 얻지 못했는데, 그 이상의 정확도를 얻을 수 있었던 것은 수확이다. 그러나 검증셋 상으로는 0.9 이상의 Roc-Auc Score를 기록했음에도 실제 Kaggle 리더보드 채점에서는 그만한 점수가 나오지 않았다. 딥러닝 모델 외에 논문의 저자가 시도했던 것처럼, 기초적인 분류기 모델부터 시도해 볼 필요가 있다.
한편, 더 연구해보아야 할 점은 다음과 같다.
- 두 임베딩 벡터의 차원을 일치시켜야 하는가?
- 테스트셋 상
Roc-Auc Score와 Kaggle 예측 리더보드 상Roc-Auc Score간 관계가 있을까?
20200810 추가
조금 더 고민해 보다가, 네트워크 구성, Roc-Auc Score 계산 방식 외에 Kaggle Train Set과 Test Set의 리뷰 및 단어 구성이 달라서 그런 것은 아닐까 하는 생각이 들었다. 강사님께 여쭤 보고 저자의 논문을 다시 찾아 보니, 다음과 같은 구절이 있었다.
참고 : 논문 9.2. 뒷부분
We are using the test data to build both the tf-idf vectors and to build the distributed document representation, as both approaches are unsupervised, and thus do not require labels (This is allowed in the competition rules, as long as they are used as unsupervised data, like we did).
요컨대, 저자도 전처리 및 임베딩 과정에서 Train 데이터와 Test 데이터를 모두 사용한 것이었다! 예전에는 절대 Test 데이터를 보면 안 된다는 생각에 사로잡혀 있었는데, 강사님께서도 Test 데이터의 라벨은 사용하면 안 되지만, 경우에 따라서 Test 데이터의 feature들은 활용해도 될 것이라는 조언을 해 주셨다.
+) 그리고 이후에 전체 데이터에 대해 코퍼스를 동일하게 구성해서 TF-IDF 400차원, doc2vec 400차원 임베딩을 한 결과물을 딥러닝 네트워크로 구현해서 제출해 봤는데, 0.8563 정도가 최고 점수였다. 사이킷런의 roc_auc_score로 검증셋에 대해 측정할 때는 최고 점수가 0.93 정도였지만, 조금은 향상되었다.

댓글남기기