
[NLP] Seq2Seq_2.구현
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
Seq2Seq 기반 챗봇 구현
Seq2Seq 모델을 이용해 챗봇을 만들어 보자. 송영숙 님이 공개한 챗봇 학습용 한국어 데이터를 이용한다. 질문에 대해 대답하는 기계번역 모델이다.
1. 모델 아키텍쳐
본격적으로 모델 아키텍쳐를 살펴 보기에 앞서, 핵심을 잡고 가자. 먼저, 입출력 데이터이다. 데이터 구성 상, Q 컬럼이 입력 데이터로, A 컬럼이 출력 데이터로 활용된다. 인코더에 Q를 입력하고, 디코더에 A가 입력되었을 때 <START> 등의 특수 토큰을 제외한 A가 나온다. 이 때, (당연하지만) 인코더와 디코더는 공통의 임베딩 레이어를 사용한다.
다음으로, 학습 및 예측 방식을 알아야 한다. 챗봇 특성 상, 학습 시에는 Q와 A를 모두 활용하지만, 예측 시에는 A를 활용할 수 없다. 즉, 예측(채팅)을 할 때에는 한 단어가 들어갔을 때 다음 단어가 나와야 한다. 이를 구현하기 위해서는 이론적으로 한 단어가 들어갔을 때, 다음 단어가 나오도록 학습 및 예측을 진행해야 한다. 그러나 시간 상의 문제가 있기 때문에, 학습 시에는 모든 데이터를 한 번에 넣어서 문장 단위로 학습하고, 예측 시에만 한 단어를 넣었을 때 다음 단어가 나오도록 네트워크를 구성한다. 이러한 학습 방식을 Teacher Forcing이라 한다.
모델 아키텍쳐는 다음과 같다.
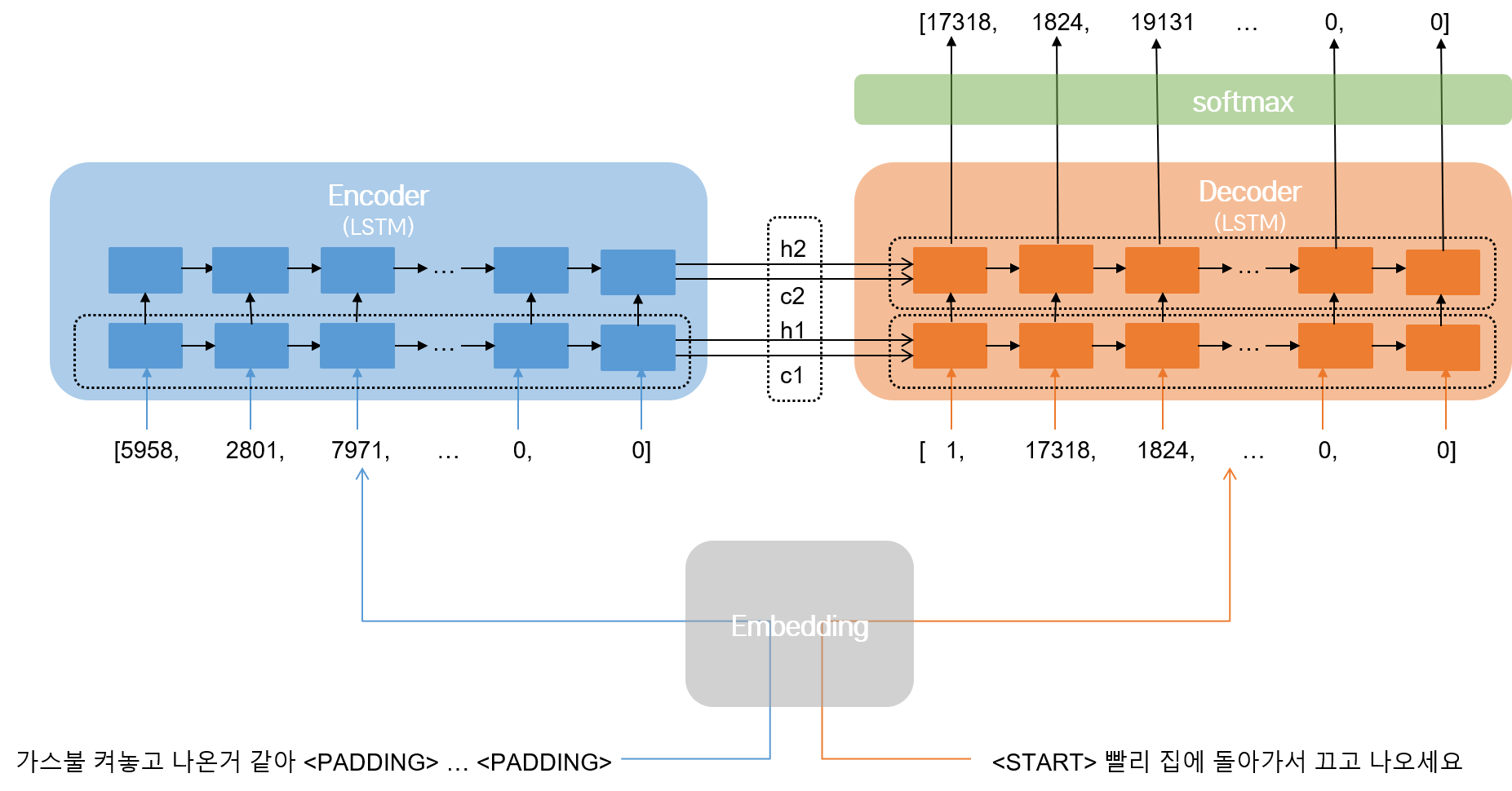
인코더와 디코더 각각을 2층 LSTM으로 구성한다. 인코더는 임베딩된 question을 받아 context vector와 hidden state를 decoder에 넘긴다. 디코더는 context vector, 각각의 단어와 이전 단계에서의 hidden state를 받아 다음에 나올 단어를 출력한다. 다음에 나올 단어를 출력하기 위해 softmax 활성화 함수를 사용한다.
인코더에서 디코더로 context vector와 hidden state를 넘기기 위해 return_state 옵션을 사용한다. 한편, 인코더와 디코더를 구성하는 각각의 층, 즉, 인코더는 1층과 2층 LSTM, 디코더는 1층 LSTM과 2층 LSTM, softmax층 사이에 다음 층으로 값을 넘겨주기 위해서는 return_sequences 옵션을 사용한다. <END> 토큰에 해당하는 인덱스가 나오거나, 문장 최대 길이를 넘어 가면, 디코더의 출력이 종료된다.
2. 구현
코드로 구현하는 부분은 크게 전처리, 학습(인코더), 채팅(디코더) 단계로 나뉜다. 사용한 모듈은 다음과 같다.
2.1. 전처리
전처리에 필요한 모듈은 다음과 같다.
# 모듈 불러오기
from konlpy.tag import Okt
import pandas as pd
import re
from sklearn.model_selection import train_test_split
import numpy as np
인코더, 디코더용 데이터를 만든다. <START>, <END> 등의 특별 토큰을 추가해 주어야 함을 잊지 말자. 당연히, 구둣점 제거, 문장 단어 수 제한 및 패딩 등 기본적인 자연어 전처리에 대한 부분을 진행해주어야 한다. 단, 형태소 분석의 경우, 챗봇 구현에서는 진행하지 않는다. 챗봇이 형태소 단위로 대답하면 안 되기 때문이다. (Github 소스 코드에는 형태소 분석 함수가 포함되어 있지만, 실제로는 사용하지 않으므로, 기록하지 않는다.)
# 파라미터 설정
TOKENIZE_AS_MORPH = FALSE # 형태소 분석 여부
ENC_INPUT = 0 # 인코더 입력
DEC_INPUT = 1 # 디코더 입력
DEC_LABEL = 2 # 디코더 출력
MAX_LENGTH = 10 # 문장 최대 길이
PAD = "<PADDING>" # 특수 토큰: 패딩
STD = "<START>" # 특수 토큰: 문장 시작
END = "<END>" # 특수 토큰: 문장 끝
UNK = "<UNKNOWN>" # 특수 토큰: OOV
MARKER = [PAD, STD, END, UNK]
FILTERS = "([~.,!?\"':;)(])" # 제거할 구둣점
CHANGE_FILTER = re.compile(FILTERS)
# 데이터 로드
def load_data(path):
data = pd.read_csv(path, header=0)
question, answer = list(data['Q']), list(data['A'])
train_input, test_input, train_label, test_label = \
train_test_split(question, answer, test_size=0.1, random_state=42)
return train_input, train_label, test_input, test_label
# 토크나이징
def tokenize_data(data):
words = []
for sentence in data:
sentence = re.sub(CHANGE_FILTER, '', sentence)
for word in sentence.split():
words.append(word)
return [word for word in words if word]
# 어휘집 생성
def make_vocabulary(path, tokenize_as_morph=TOKENIZE_AS_MORPH):
data = pd.read_csv(path, encoding='utf-8')
question, answer = list(data['Q']), list(data['A'])
sentences = []
sentences.extend(question)
sentences.extend(answer)
words = tokenize_data[sentences]
words = list(set(words)) # 중복 제거
words[:0] = MARKER # 특수 토큰 추가
word2idx = {word:idx for idx, word in enumerate(words)}
idx2word = {idx:word for idx, word in enumerate(words)}
return word2idx, idx2word
# 최종 전처리
def preprocess_data(data, dictionary, data_type, \
tokenize_as_morph=TOKENIZE_AS_MORPH, filt=CHANGE_FILTER, maxlen=MAX_LENGTH):
sequences_input_index = []
for sequence in data:
sequence = re.sub(filt, '', sequence) # 구둣점 제거
# 디코더 입력: <START>로 시작함.
if data_type == DEC_INPUT:
sequence_index = [dictionary[STD]]
else:
sequence_index = []
# 단어 인코딩
for word in sequence.split():
if dictionary.get(word) is not None:
sequence_index.append(dictionary[word])
else: # OOV
sequence_index.append(dictionary[UNK])
# 최대 문장 길이 제한
if len(sequence_index) >= maxlen:
break
# 디코더 출력: 문장 길이 제한에 걸리지 않았을 때, <END>로 끝남.
if data_type == DEC_LABEL:
if len(sequence_index) < maxlen:
sequence_index.append(dictionary[END])
else:
sequence_index[len(sequence_index)-1] = dictionary[END]
# 패딩
sequence_index += (maxlen-len(sequence_index)) * [DICTIONARY[PAD]]
sequences_input_index.append(sequence_index)
return np.asarray(sequences_input_index)
2.2. 학습
학습을 위해 필요한 모듈은 다음과 같다.
# 모듈 불러오기
from tensorflow.keras.layers import Input, Dense, Embedding
from tensorflow.keras.layers import LSTM, TimeDistributed
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import pickle
인코더, 디코더를 이용한 챗봇 학습은, 상술했듯 Teacher Forcing 방식으로 이루어진다. 전처리한 데이터를 불러오고, 인코더 네트워크와 디코더 네트워크를 구성하자. 아키텍쳐 설명에서도 보듯, 인코더와 디코더를 모두 2층으로 구성한다. 두 네트워크가 어떻게 연결되는지, 가중치와 중간 출력값이 어떻게 전달되는지를 위주로 아래의 코드를 살펴 보자.
# 데이터 로드
with open(f"{data_path}/6-1.vocabulary.pickle", 'rb') as f:
word2idx, idx2word = pickle.load(f) # 어휘집
with open(f"{data_path}/6-1.train_data.pickle", 'rb') as f:
X_train_E, X_train_D, y_train_D = pickle.load(f) # 학습 데이터 인코더 입력, 디코더 입력, 디코더 출력
with open(f"{data_path}/6-1.eval_data.pickle", 'rb') as f:
X_test_E, X_test_D, y_test_D = pickle.load(f) # 테스트 데이터 인코더 입력, 디코더 입력, 디코더 출력
# 모델 파라미터 설정
VOCAB_SIZE = len(idx2word)
EMB_SIZE = int(input('임베딩 사이즈 설정: '))
LSTM_HIDDEN = int(input('LSTM 은닉 노드 수 설정: '))
MODEL_PATH = f"{chatbot_path}/seq2seq.h5"
# 공통 임베딩 레이어
embed_layer = Embedding(input_dim=VOCAB_SIZE, output_dim=EMB_SIZE)
# 1) 인코더 네트워크 구성
X_input_E = Input(batch_shape=(None, X_train_E.shape[1]))
X_embed_E = embed_layer(X_Input_E)
X_lstm1_E = LSTM(LSTM_HIDDEN, return_sequences=True, return_state=True)
X_lstm2_E = LSTM(LSTM_HIDDEN, return_state=True)
ey1, eh1, ec1 = X_lstm1_E(X_embed_E)
_, eh2, ec2 = X_lstm2_E(ey1)
# 2) 디코더 네트워크 구성
X_input_D = Input(batch_shape=(None, X_train_D.shape[1]))
X_embed_D = embed_layer(X_input_D)
X_lstm1_D = LSTM(LSTM_HIDDEN, return_sequences=True, return_state=True)
X_lstm2_D = LSTM(LSTM_HIDDEN, return_sequences=True, return_state=True)
dy1, _, _ = X_lstm1_D(X_embed_D, initial_state=[eh1, ec1])
dy2, _, _ = X_lstm2_D(dy1, initial_state=[eh2, ec2])
# 3) 출력 네트워크
y_output = TimeDistributed(Dense(VOCAB_SIZE, activation='softmax'))
y_output = y_output(dy2)
# 4) 모델 구성 및 컴파일
model = Model([X_input_E, X_input_D], y_output)
model.compile(optimizer=Adam(lr=0.001),
loss='sparse_categorical_crossentropy')
# 학습
hist = model.fit([X_train_E, X_train_D], y_train_D,
batch_size=300,
epochs=500,
shuffle=True,
validation_data=[X_test_E, x_test_D], y_test_D)
1) 인코더 네트워크
many-to-one 방식으로 구성한다. 인코더를 거쳐 나온 최종 출력 가중치 h와 cell state C가 디코더로 전달되어야 한다. return_sequences와 return_state 옵션의 사용에 주의하자. 전자의 경우, 2층 LSTM 구조에서 1층 네트워크의 hidden state를 2층 네트워크로 전달하기 위한 목적이므로, 1층 네트워크에만 True를 설정한다. 반면, 인코더에서 디코더로 context vector를 넘기기 위함이므로, 두 네트워크 모두에 True를 설정한다.
참고 : contect vector
LSTM 인코더를 통과해서 나오는 hidden state와 cell state가 바로 인코더를 통과한
Q문장의 context vector이다.Q의 latent feature를 담고 있다.return_state=True옵션으로 인해 원래 출력인y에 더해h,c값을 얻을 수 있게 된다.
2) 디코더 네트워크
Teacher Forcing 방식으로 학습한 인코더 네트워크와 달리, many-to-many 방식으로 구성한다. 따라서 두 층 모두에 return_sequences와 return_state 옵션을 True로 설정한다. 유의할 점은, 각 층의 LSTM 네트워크 초기 가중치가 인코더에서 넘어 온 hidden state와 cell state로 설정된다는 점이다. Q의 context vector를 활용하여야 하므로, 당연한 이야기다. 인코더 네트워크에서는 2층 네트워크의 출력을 활용하지 않았으나, 디코더에서는 2층 네트워크의 출력 dy2가 실제 문장의 라벨을 예측할 용도로 사용된다는 점도 기억해 두자.
3), 4) 출력 네트워크 및 모델 구성
디코더 네트워크가 many-to-many 방식으로 구성되었기 때문에, 각각의 타임스텝마다 오류를 분배하여 역전파한다. 따라서 TimeDistributed 함수를 사용한다. 모델을 컴파일 시, 디코더 출력을 원핫 벡터로 바꾸지 않았기 때문에 sparse_categorical_crossentropy를 loss로 설정한다. 굳이 원핫 벡터를 사용하지 않는 까닭은, 실용성 측면에서 챗봇 대답에 활용되기에 시간이 오래 걸리기 때문이다.
구성한 모델의 전체 구조를 확인하면 다음과 같다.

2.3. 채팅(예측)
학습을 위해 필요한 모듈은 다음과 같다.
# 모듈 불러오기
from tensorflow.keras.layers import Input, Dense, Embedding
from tensorflow.keras.layers import LSTM, TimeDistributed
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import pickle
import numpy as np
학습된 모델을 바탕으로 채팅이 이루어져야 한다. 따라서 다음과 같은 방식으로 각 스텝마다 예측을 하게 된다.
- 학습된 모델에서 사용한 인코더 입력 질문을 예측 모델의 인코더 입력 질문에 넣는다.
- 예측 모델의 인코더를 통과한 뒤 나온
Q의 hidden state(h), cell state(C) 값을 디코더의 첫 타임 스텝 가중치로 설정한다. - 디코더의 첫 입력으로
<START>토큰을 넣는다. - 두 번째 스텝부터는 디코더의 이전 타임 스텝 출력값과 hidden state, cell state 값을 모두 넣어 모델을 가동시킨다.
우선 학습된 모델을 바탕으로 해야 하므로, 모델 네트워크 구성을 인코더와 동일하게 만들고, 학습된 가중치를 불러 와 사용한다. 다만 주의해야 할 것은, 디코더에서는 타임 스텝이 1이라는 점이다!
# 1) 모델 파라미터 설정
VOCAB_SIZE = len(idx2word)
EMB_SIZE = int(input('임베딩 사이즈 설정: '))
LSTM_HIDDEN = int(input('LSTM 은닉 노드 수 설정: '))
MAX_LENGTH = int(input('문장 최대 길이 설정(주의): '))
MODEL_PATH = f"{chatbot_path}/seq2seq.h5"
# 2) 모델 네트워크 구성
embed_layer = Embedding(input_dim=VOCAB_SIZE, output_dim=EMB_SIZE)
X_input_E = Input(batch_shape=(None, MAX_LENGTH)) # shape 대신 MAX_LENGTH 사용
X_embed_E = embed_layer(X_input_E)
X_lstm1_E = LSTM(LSTM_HIDDEN, return_sequences=True, return_state=True)
X_lstm2_E = LSTM(LSTM_HIDDEN, return_state=True)
ey1, eh1, ec1 = X_lstm1_E(X_embed_E)
_, eh2, ec2 = X_lstm2_E(ey1)
X_input_D = Input(batch_shape=(None, 1)) # 주의!
X_embed_D = embed_layer(X_input_D)
X_lstm1_D = LSTM(LSTM_HIDDEN, return_sequences=True, return_state=True)
X_lstm2_D = LSTM(LSTM_HIDDEN, return_sequences=True, return_state=True)
dy1, _, _ = X_lstm1_D(X_embed_D, initial_state=[eh1, ec1])
dy2, _, _ = X_lstm2_D(dy1, initial_state=[eh2, ec2])
y_output = TimeDistributed(Dense(VOCAB_SIZE, activation='softmax'))
y_output = y_output(dy2)
# 3) 모델 구성
model = Model([X_input_E, X_input_D], y_output)
model.load_weights(MODEL_PATH) # 주의!
# 4) 채팅용 네트워크 및 초기 가중치 설정
model_enc = Model(X_input_E, [eh1, ec1, eh2, ec2])
ih1 = Input(batch_shape = (None, LSTM_HIDDEN))
ic1 = Input(batch_shape = (None, LSTM_HIDDEN))
ih2 = Input(batch_shape = (None, LSTM_HIDDEN))
ic2 = Input(batch_shape = (None, LSTM_HIDDEN))
dec_y1, dh1, dc1 = X_lstm1_D(X_embed_D, initial_state=[ih1, ic1])
dec_y2, dh2, dc2 = X_lstm2_D(dec_y1, initial_state=[ih2, ic2])
dec_output = TimeDistributed(Dense(VOCAB_SIZE, activation='softmax'))
dec_output = dec_output(dec_y2)
# 5) 채팅용 디코더 모델 구성
model_dec = Model([X_inpt_D, ih1, ic1, ih2, ic2],
[y_output, dh1, dc1, dh2, dc2])
# 6) Q에 대한 A 생성
def generate_answer(question):
question = question[np.newaxis, :]
init_h1, init_c1, init_h2, init_c2 = model_enc.predict(question) # 최초 가중치
word = np.array(word2idx['<START>']).reshape(1, 1) # 최초 단어
answer = []
for i in range(MAX_LENGTH):
dY, next_h1, next_c1, next_h2, next_c2 = \
model_dec.predict([word, init_h1, init_c1, init_h2, init_c2])
next_word = np.argmax(dY[0, 0]) # 예측한 다음 단어 인덱스
if next_word == word2idx['<END>'] or next_word == word2idx['<PADDING>']:
# 예측이 무의미한 경우
break
answer.append(idx2word[next_word]) # 예측 단어 기록
# 다음 스텝에서의 입력 데이터, 가중치 준비
word = np.array(next_word).reshape(1, 1)
init_h1, init_c1, init_h2, init_c2 = next_h1, next_c1, next_h2, next_c2
return ' '.join(answer)
# 7) 챗봇과 대화
N = int(input('몇 번 동안 대화하시겠습니까? '))
for _ in range(N):
question = input('Q: ')
if question == 'quit':
break
q_idx = []
for x in question.split(' '):
if x in word2idx:
q_idx.append(word2idx[x])
else: # OOV
q_idx.append(word2idx['<UNKNOWN>'])
# 패딩 삽입해야 하는 경우
if len(q_idx) < MAX_LENGTH:
q_idx.extend([word2idx['<PADDING>']] * (MAX_LENGTH - len(q_idx)))
else:
q_idx = q_idx[0:MAX_LENGTH]
answer = generate_answer(np.array(q_idx))
print('A :', answer)
1), 2), 3) 각 네트워크 및 모델에서 달라지는 점
한 단어를 입력 받아 다음 단어를 예측하므로, time step이 1이 될 수 있게 batch shape만 수정해 주면 된다. time step만 달라졌을 뿐, 전체 네트워크의 파라미터는 학습 모델과 동일하다. 마지막에 모델 구성 시, 미리 학습시켜 놓은 가중치를 업데이트하는 것을 잊지 말자.
4), 5) 채팅용 모델
한 단어씩 입력 받아 채팅을 하기 위한 모델이다. 기본적으로 채팅을 위해서는 디코더가 필요하다. 디코더 모델을 다시 구성한다. 인코더 모델은 가중치 설정을 위한 것이다.
번거롭지만, 각각의 입력과 초기 h, C를 넣었을 때 출력과 함께 다음 타임 스텝에서의 h, C가 나오도록 모델을 구성한다. 즉, 각 LSTM 인코더 층에 입력이 들어 가면 출력으로 hidden state 2개, cell state 2개가 나오게 모델을 구성한다. 그리고 time step을 1로 한 입력이 들어 갔을 때 나온 hidden state, cell state를 다음 타임 스텝에서의 초기 가중치 ih, ic로 설정하여 채팅용 모델의 디코더 LSTM 1층, 2층에 각각 initial state로 넘긴다.
이렇게 구성한 모델의 구조는 다음과 같다.

6) Q로부터 A 생성
최초 word(<START>)와 인코더 모델로부터 넘어 온 최초 가중치를 디코더 모델에 넘겨 예측한다. 어휘집에서 예측 결과에 해당하는 단어를 찾아 기록한 후, word와 가중치를 업데이트한다. 예측을 더 이상 하지 않아도 되는 경우, 즉, 다음 단어를 예측했는데 문장의 끝(<END>)이거나 패딩(<PADDING>)인 경우라면, 더 이상 작업을 진행하지 않는다. 이 과정을 반복할 뿐이다.
7) 챗봇과 대화
이제 챗봇과 이야기를 나눌 수 있다! 질문을 토큰 단위로 분리하고, OOV 및 패딩 처리를 한 뒤 generate_answer 함수를 이용하여 질문에 대한 답을 얻으면 된다.
3. 결과
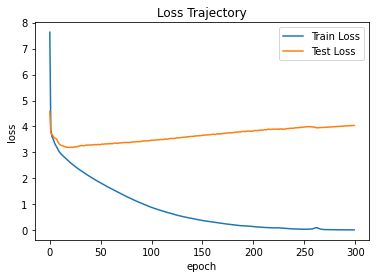
학습 과정 도중의 loss 변화 추이를 나타내면 다음 그림과 같다.
대화 내용을 예시로 보면 다음과 같다. 학습한 문장을 질문하면, 그럭저럭 잘 대답한다. 혹시 사람인가 싶기도? 다음 달에는 더 절약해 보라니…
가끔 궁금해 : 그 사람도 그럴 거예요.,0
가끔 뭐하는지 궁금해 : 그 사람도 그럴 거예요.,0
가끔은 혼자인게 좋다 : 혼자를 즐기세요.,0
가난한 자의 설움 : 돈은 다시 들어올 거예요.,0
가만 있어도 땀난다 : 땀을 식혀주세요.,0
가상화폐 쫄딱 망함 : 어서 잊고 새출발 하세요.,0
가스불 켜고 나갔어 : 빨리 집에 돌아가서 끄고 나오세요.,0
가스불 켜놓고 나온거 같아 : 빨리 집에 돌아가서 끄고 나오세요.,0
가스비 너무 많이 나왔다. : 다음 달에는 더 절약해봐요.,0
가스비 비싼데 감기 걸리겠어 : 따뜻하게 사세요!,0
참고 : 이상한 대답을 한다면?
학습한 문장을 질문하면, 그럭저럭 잘 대답한다는 말은, 학습하지 않은 문장을 질문하면, 이상한 대답을 한다는 의미이기도 하다. 이 문제에 대해서는 트랜스포머 이론 기반의 챗봇을 만들 때 해결의 실마리를 얻을 수 있을 것이다.한편, 어휘집 생성 및 가중치 저장이 제대로 되지 않으면 이상한 대답을 하기도 한다. 결과가 너무 이상하니까, 여기서는 굳이 기록하지 않는 것이 좋겠다.

댓글남기기