
[NLP] Transformer_3.Multi-head Attention_2
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. 논문 출처
Transformer 이해하기_Multi-head Attention
트랜스포머 모델의 또 다른 핵심 중 하나는 Multi-head Attention을 네트워크를 사용한 것이었다. 전체적인 Multi-head Attention 네트워크 구조는 다음과 같다.
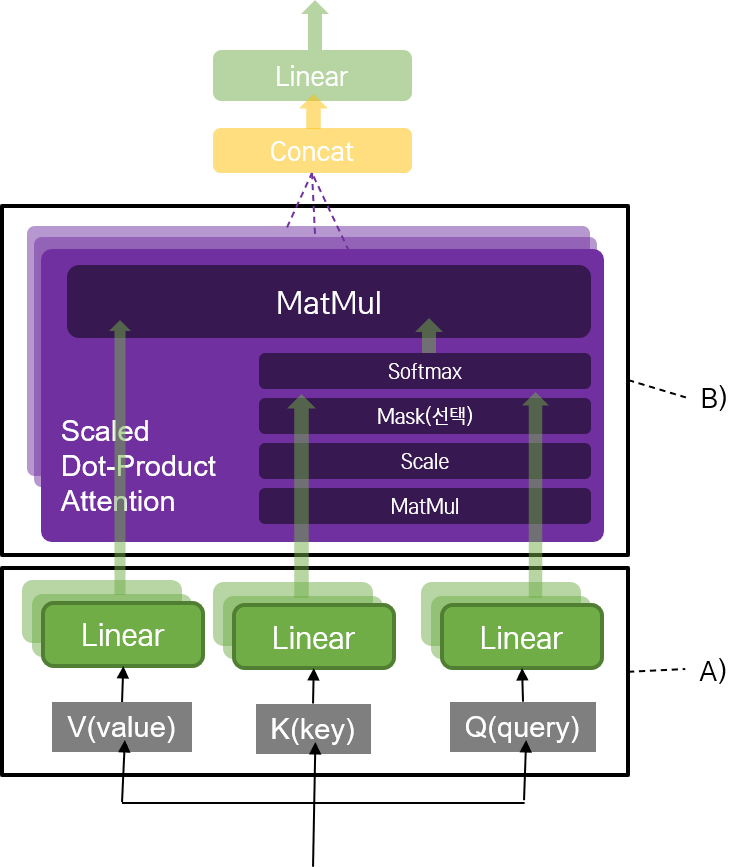
1) Attention 메커니즘으로서 2) Scaled Dot-Product를 수행하는데, 3) 이를 여러 개의 head로 나누어 수행한다. 특이한 것은 4) 입력 문장 자신에 대해 Scaled Dot-Product를 수행하는 Self-Attention 레이어가 있다는 것과, 5) 레이어에 따라 Masking을 진행할 수 있다는 것이다.
3. Self-Attention
Self 라는 단어에서도 알 수 있듯, 문장 자기 자신과 attention을 진행하는 것이다.
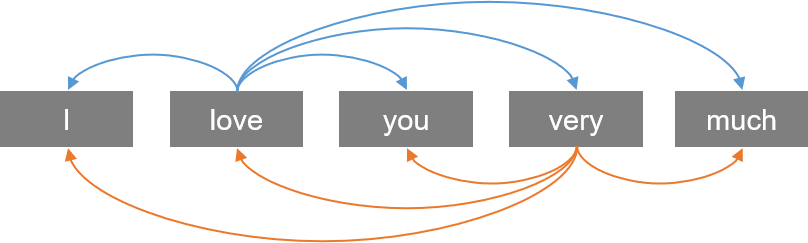
예컨대, Jungkook is very handsome. He is a perfect singer.이라는 문장이 있을 때, 자기 자신의 문장과 attention을 수행함으로써 He가 무엇인지 알아내고자 하는 아이디어이다.
Multi-head Attention을 수행할 때, Query, Key, Value가 모두 동일하다. 자기 자신인 것이다. 입력 문장의 단어들끼리 Attention 메커니즘을 통해 유사도를 구하면서, 문장 내의 각 단어가 어떤 단어와 가장 연관되어 있는지 구한다. 이제 구체적으로 그 과정을 살펴 보자.
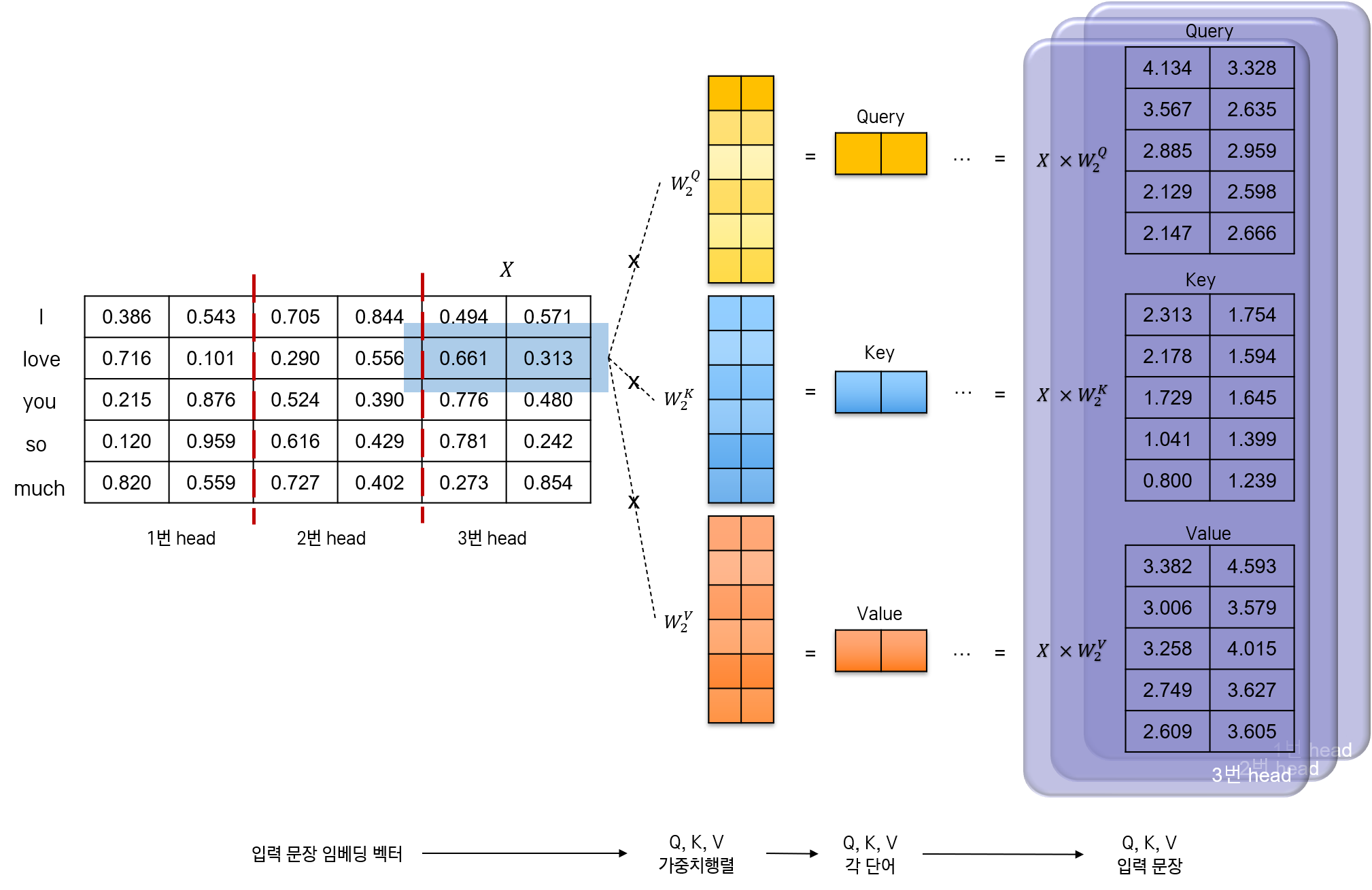
먼저 입력 문장으로부터 Query, Key, Value를 얻어야 한다.
-
단어 임베딩 행렬을 3개의 head로 나눈다. 각 head에 대해 서로 다른 가중치 행렬이 설정된다. 그 shape은 \((embed\_dim, d_k)\) 이다.
참고 : head와 input의 관계
결과적으로 입력 문장은 \(d_k\)차원의 Query와 Key, 그리고 \(d_v\)차원의 Value로 나뉘게 된다. 논문에서는 이를 “The input consists of queries and keys of dimension \(d_k\), and values of dimension \(d_v\).”와 과 같이 표현했다.
-
head와 가중치 행렬을 곱한다. 그림 상으로는 한 부분(정확히는,
love단어의 임베딩 벡터에서 3번 head에 해당하는 부분)에 대해 Query, Key, Value를 얻는 과정만 표현했다. head 전체 행렬에 대해 이 과정을 수행하면 된다.
사실은 위의 과정이 모든 head에 대해 다 수행되므로, head별로 Query, Key, Value가 나온다. Query, Key, Value가 head 개수만큼 있다는 말이다. (이를 어떻게든 나타내고 싶어 그림에서는 입체(?)적으로 표현하고자 했다.) 또한, 각 Query, Key, Value가 문장 자기 자신으로부터 나왔다는 것이 매우 중요하다. (그래서 Self-Attention이다.)
다음으로 Attention을 계산한다. 앞에서 살펴 보았던 Self Dot-Product 공식에 따라 진행하면 된다.
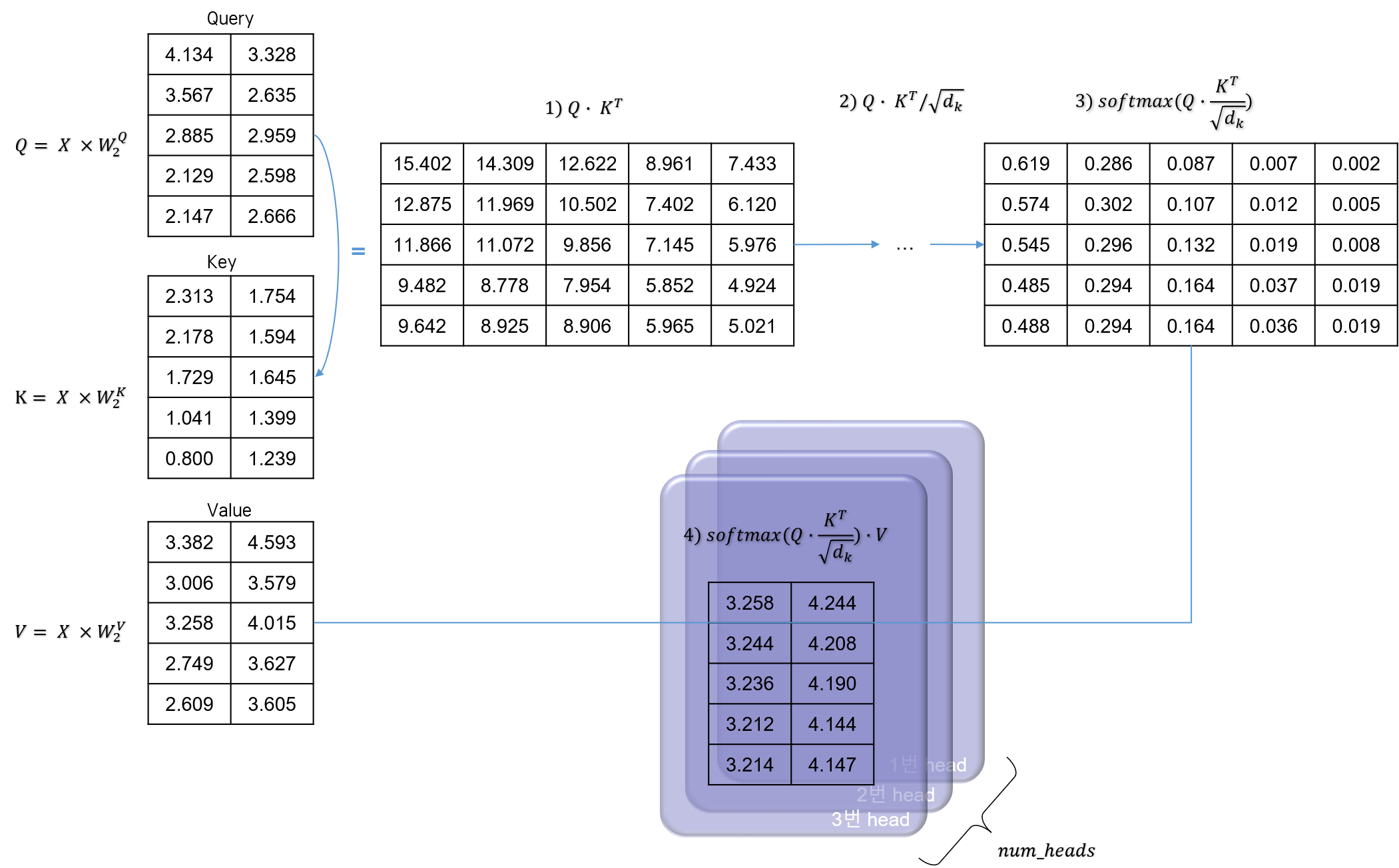
- Query와 Key 간에 dot product 연산을 한다.
- \(\sqrt{d_k}\)로 scale한다.
- softmax를 취한다. 그림에서 각 행끼리 더하면 1의 값이 나온다.
- Value와 dot product 연산을 한다.
결과적으로 나오는 행렬은 Attention Value로, 각각의 Query가 각 Value에 얼마나 집중해야 할지 그 가중치를 나타내게 된다. 의미적으로 해석하자면, 문장의 각 부분 부분을 Query로 볼 때, 그 각 단어가 문장 내 다른 단어들에 얼마나 주목해야 할지, 그 주목도를 수치로 표현한 값이다.
다시 한 번 잊지 말아야 한다. 위와 같은 연산을 각각의 head에서 모두 수행한다. 따라서 Attention Value가 헤드의 개수만큼 있다. 이를 linear 네트워크를 거쳐서 최종적인 Multi-head Attention Value를 얻어 내자.

이렇게 각 문장이 임베딩 + Positional Encoding + Self-Attention을 과정을 거치고 난 후에는, 결과로 나오는 Multi-head Attention Value에 각 단어별로 어느 단어와 관련이 높은지가 수치로 표현된다. 논문에서는 예시 문장을 가지고 Multi-head Attention Value를 구한 뒤, 각 문장의 단어가 어떤 부분과 가장 연관성이 높은지를 다음과 같이 시각화했다. its라는 지칭어가 Law와 application라는 단어에 주목하고 있음을 알 수 있다.

4. Masking
이전까지의 과정을 요약해 Seq2Seq 모델과 트랜스포머 모델의 차이점을 생각해 보자. 트랜스포머 모델은 순환신경망 네트워크를 제거하고, Self-Attention 과정을 거쳐 문장의 정보를 효과적으로 추출해 낸다. 그런데 이 과정에서 문장 전체를 한번에 행렬 형태로 입력했다. 이 때문에 예측 과정에 문제가 발생할 수 있다. 학습 시에는 자기 자신보다 뒤에 있는 모든 위치의 단어들을 참고할 수 있었지만, 예측 시에는 입력되는 단어보다 뒤에 있는 단어를 사용할 수 없기 때문이다.
따라서 순차적으로 결과를 만들어내야 하는 디코더의 경우에는 Masking 기법을 사용해 학습 및 예측하도록 한다. 특정 포지션 \(i\)에 단어가 들어 온다면, 그 뒤에 있는 위치의 단어들에 Attention을 주지 못하게 하는 것이다. 이미 알고 있는 결과를 활용하기만 해서 Attention을 주고 다음 단어를 예측하는 데에 활용하는 것이다. 특히 디코더에서 이렇게 학습한다.
참고
논문에서는 디코더에서는 Self-Attention 기법을 변형하여 적용한다고 표현되어 있다.
We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
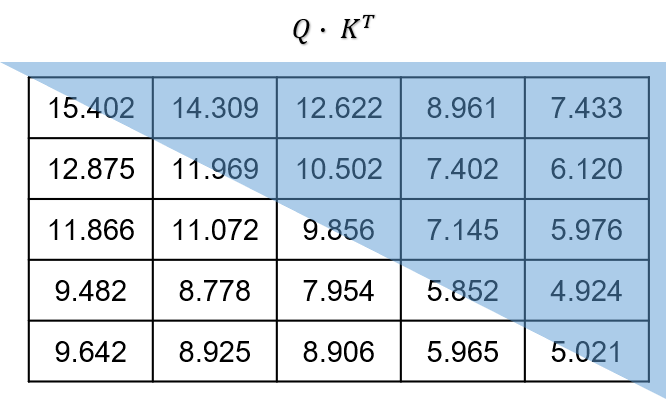
아래 그림에서와 같이 상삼각행렬 부분에 마스킹을 씌우면 된다.


댓글남기기