
[Dev] AI Agent: 개념과 구현
TL;DR
- AI Agent: LLM이 외부 도구(Tool)를 자율적으로 사용하여 목표를 달성하는 시스템
- Function Calling: LLM이 필요할 때 Tool을 호출할 수 있도록 하는 메커니즘
- Agentic Loop: Tool 호출 → 결과 관찰 → 재추론을 반복하는 핵심 패턴
- 구현: Upstage Solar API(OpenAI 호환)와 Function Calling을 이용한 SQL Agent 예시
이 글의 구현 예시는 OpenAI SDK 호환 형식(Upstage API)을 사용한다. 다른 LLM(Anthropic Claude, Google Gemini 등)을 사용할 경우 API 구조가 달라 코드 수정이 필요하다.
계기
실무에서 MLOps 대시보드를 운영하면서, 대시보드 API를 위한 SQL 호출이 점점 복잡해지고 있었다. 쿼리가 복잡해지는 것은 물론이고, 모델 간 부모-자식 관계가 있어 재귀 쿼리까지 필요한 상황이었다.
MLflow 같은 오픈소스를 도입하는 방법도 있지만, 이미 구축되어 있는 RDB 스키마를 활용하는 편이 현실적이었다. 그러다 요즘 화제인 AI Agent를 활용하면 자연어로 복잡한 SQL 조회를 대체할 수 있지 않을까 싶어, 도입 가능성을 테스트해 보기 위해 Upstage API로 간단한 SQL Agent를 구현해 보았다.
이 글에서는 그 과정에서 정리한 AI Agent의 개념과 구현 패턴을 다룬다.
들어가며
LLM은 자연어를 이해하고 생성하는 데 뛰어난 능력을 보여주지만, 단독으로 사용하기에는 근본적인 한계가 있다.
| 강점 | 한계 | 분류 |
|---|---|---|
| 자연어를 이해하고 생성 | 학습 시점 이후의 정보를 알지 못함 | 지식의 한계 |
| 학습된 지식을 기반으로 응답 | 외부 시스템(DB, API, 파일 등)에 접근 불가 | 행동의 한계 |
| 맥락을 유지하며 대화 | 실제 작업을 수행할 수 없음 | 행동의 한계 |
| 추론과 판단 | 정확한 계산이나 데이터 조회에 오류 가능 | 행동의 한계 |
예를 들어, “오늘 날씨가 어때?”라는 질문에는 실시간 날씨 API가 필요하고, “데이터베이스에서 프로젝트 목록을 보여줘”라는 요청에는 DB 접근이 필요하다. LLM 혼자서는 이런 작업을 수행할 수 없다.
LLM이 대중화된 이후, 이러한 한계를 극복하기 위한 확장이 크게 두 가지 방향으로 이루어졌다.
LLM의 한계
├── 지식의 한계 (모르는 것) ──→ RAG로 해결: 검색으로 지식 보강
│ "학습 이후 정보를 모른다"
│ "사내 문서를 모른다"
│
└── 행동의 한계 (못 하는 것) ──→ AI Agent로 해결: Tool로 행동 능력 부여
"DB를 조회할 수 없다"
"API를 호출할 수 없다"
RAG(Retrieval-Augmented Generation)는 LLM이 응답을 생성하기 전에 외부 지식 소스에서 관련 정보를 검색하여 컨텍스트로 제공하는 패턴이다. LLM이 학습하지 않은 최신 정보나 사내 문서 등을 “검색 → 주입 → 생성”이라는 고정된 파이프라인으로 보강한다.
AI Agent는 LLM이 외부 도구(Tool)를 자율적으로 사용하여 목표를 달성하는 시스템이다. LLM은 “두뇌”로서 판단과 계획을 담당하고, Tool은 “손과 발”로서 실제 작업(DB 조회, API 호출, 파일 읽기 등)을 수행한다.
두 패턴은 서로 다른 한계를 해결하지만, 최근에는 RAG의 검색 기능을 Agent의 Tool 중 하나로 통합하는 등 상호 보완적으로 함께 사용되는 경우가 많다. 이 글에서는 AI Agent의 개념과 구현 패턴을 다룬다.
AI Agent
정의
AI Agent란 LLM이 외부 도구(Tool)를 자율적으로 사용하여 목표를 달성하는 시스템이다.
여기서 핵심은 “자율적으로”다. 개발자는 “어떤 도구를 쓸 수 있는지”만 알려주고, “언제, 어떻게 쓸지”는 LLM이 판단한다.
핵심 구성 요소
AI Agent는 네 가지 구성 요소로 이루어진다.
LLM
Agent의 두뇌 역할이다. 사용자의 의도를 이해하고, 필요한 작업을 판단하며, Tool 호출 시점과 방법을 결정한다. Tool 실행 결과를 해석하여 최종 응답을 생성하는 것도 LLM의 역할이다.
Tool
외부 시스템과 상호작용하는 함수다. 데이터베이스 조회, API 호출, 파일 읽기/쓰기, 계산 등 LLM이 직접 수행할 수 없는 작업을 담당한다. 개발자가 정의하여 LLM에게 제공한다.
Function Calling
LLM이 Tool을 호출할 수 있도록 하는 메커니즘이다. Tool의 이름, 설명, 파라미터를 LLM에게 알려주면, LLM이 필요하다고 판단할 때 Tool 호출 정보를 생성한다.
Tool Execution Handler
LLM이 생성한 Tool 호출 정보를 받아 실제 함수를 실행하는 부분이다. 실행 결과를 다시 LLM에게 반환하여 추론을 이어가게 한다.
동작 흐름: Agentic Loop
AI Agent의 동작 흐름은 다음과 같다.
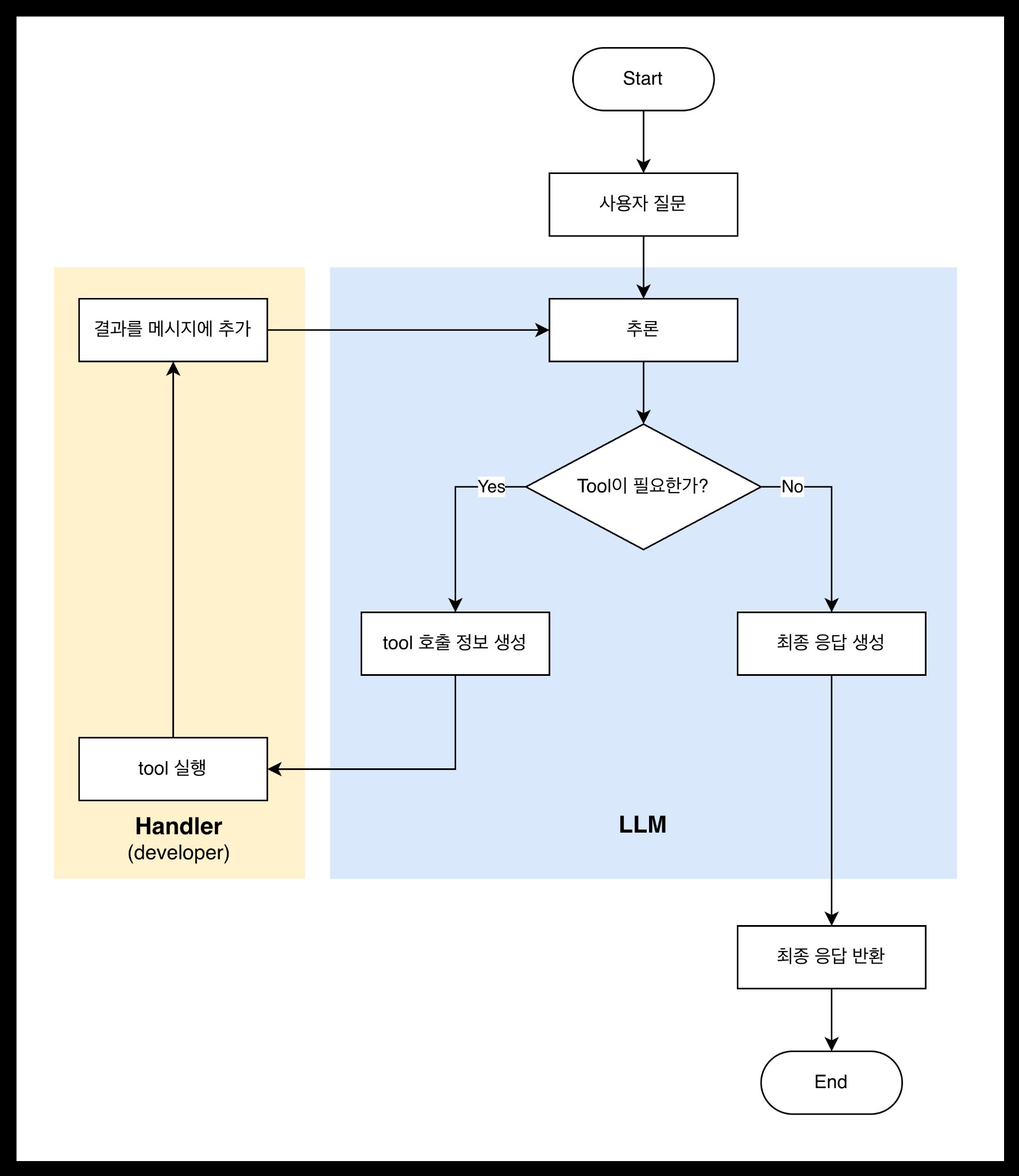
컴포넌트 간 상호작용을 시퀀스 다이어그램으로 나타내면 다음과 같다.
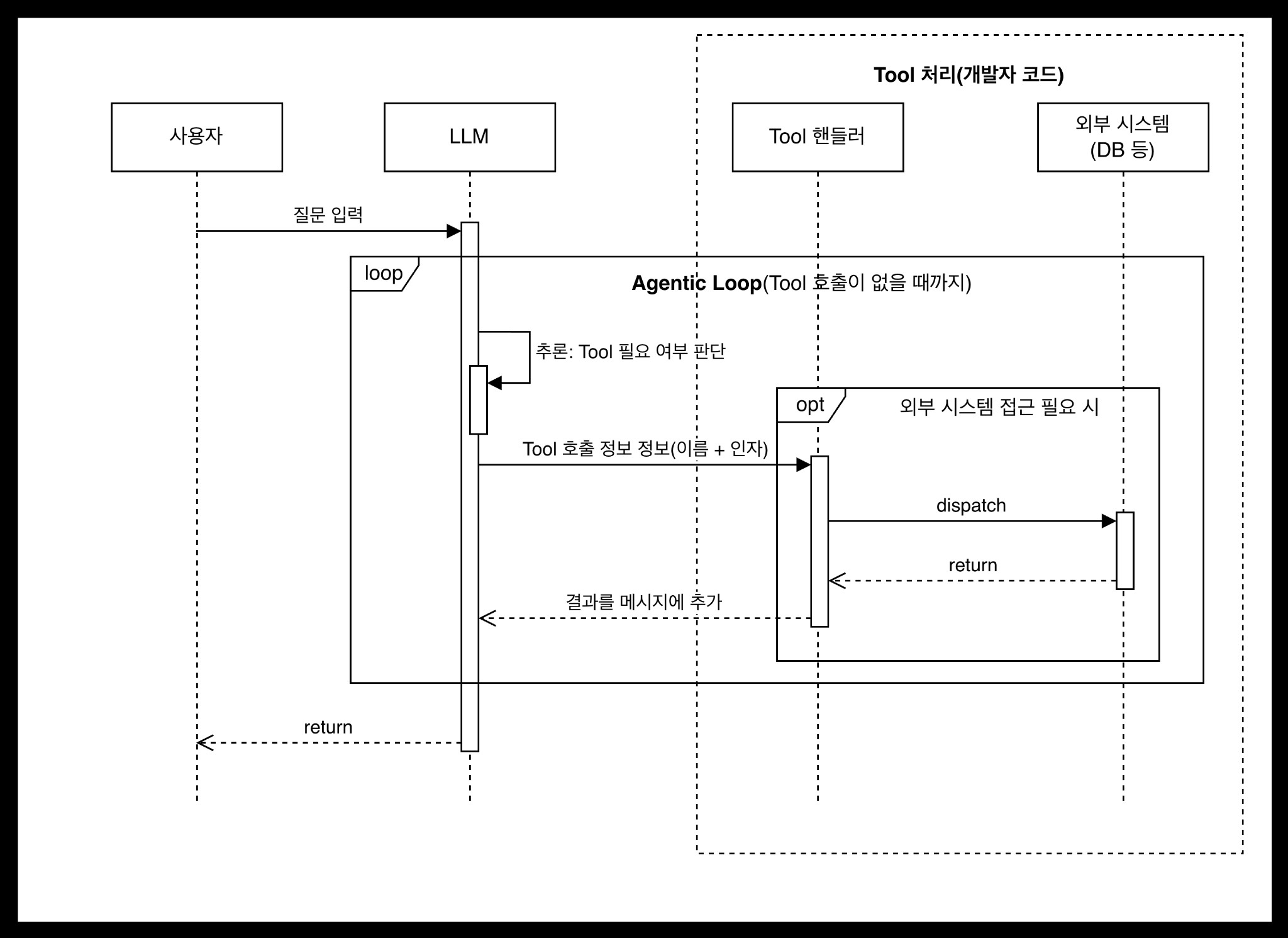
이 흐름을 단계별로 풀어보면 다음과 같다.
- Tool 정의 (개발자): 사용 가능한 Tool의 이름, 설명, 파라미터를 정의하여 LLM에 전달한다.
- 사용자 질문 입력: 자연어 질문이 대화 히스토리에 추가된다.
- LLM 추론 (자율 판단): LLM이 질문과 컨텍스트를 분석하여 Tool 호출이 필요한지 스스로 판단한다. “프로젝트 목록 보여줘”는 SQL이 필요하다고 판단하고, “안녕하세요”는 Tool 없이 바로 응답한다.
- Tool 실행: LLM이 생성한 Tool 호출 정보를 핸들러가 받아 실제 함수를 실행한다.
- 관찰 및 반복 (Agentic Loop): LLM이 Tool 실행 결과를 관찰하고, 추가 조회가 필요하면 다시 Tool을 호출한다. 예를 들어 SQL 오류가 발생하면, 수정된 쿼리로 재시도하는 것도 이 루프에서 자율적으로 일어난다.
- 최종 응답 생성: 더 이상 Tool 호출이 필요 없다고 판단하면 루프를 종료하고, 수집된 결과를 종합하여 최종 답변을 생성한다.
이 반복 구조를 Agentic Loop라고 한다. AI Agent의 핵심이 되는 패턴이다.
이 동작 흐름은 LLM 제공자마다 용어는 다르지만 동일한 패턴을 따른다. 각 공식 문서에서도 같은 흐름을 확인할 수 있다.
Function Calling
개념
Function Calling은 LLM이 외부 함수(Tool)를 호출할 수 있도록 하는 메커니즘이다. OpenAI가 2023년 6월에 처음 도입한 이후 사실상 업계 표준이 되었으며, 많은 LLM 제공자들이 유사한 형태로 지원하고 있다.
Function Calling의 동작 원리를 pseudo code로 나타내면 다음과 같다.
# 1. 개발자가 Tool을 정의한다
tools = [
Tool(
name = "execute_sql",
description = "데이터베이스에 SELECT 쿼리를 실행한다",
parameters = { "sql": String }
)
]
# 2. LLM에게 Tool 목록과 함께 질문을 전달한다
response = LLM.generate(messages, tools)
# 3. LLM이 Tool 호출이 필요하다고 판단하면, 호출 정보를 생성한다
# 필요 없다고 판단하면 텍스트 응답만 반환한다
if response.has_tool_calls:
for tool_call in response.tool_calls:
# tool_call.name = "execute_sql"
# tool_call.arguments = { "sql": "SELECT * FROM projects" }
result = execute_tool(tool_call.name, tool_call.arguments)
messages.add(tool_result(tool_call.id, result))
핵심은 다음과 같다.
- Tool 정의: 개발자가 사용 가능한 Tool 목록을 정의하여 LLM에 전달한다.
- 자율적 판단: LLM이 Tool 호출 여부를 스스로 결정한다. Tool이 필요하면 호출 정보를 생성하고, 필요 없으면 텍스트 응답만 반환한다.
- 구조화된 호출 정보: LLM은 Tool 이름과 인자를 구조화된 형태로 생성한다. 이를 받아 개발자가 정의한 핸들러에서 실제 함수를 실행한다.
- 결과 반환: Tool 실행 결과를 대화 히스토리에 추가하여 LLM에게 다시 전달한다.
여기서 중요한 점은 LLM이 실제로 함수를 실행하는 것이 아니라, “이 함수를 이 인자로 호출해 달라”는 정보를 생성하는 것이라는 점이다. 실제 실행은 개발자가 구현한 핸들러에서 이루어진다.
LLM별 Function Calling 패턴
Function Calling의 핵심 개념(Tool 정의 → LLM의 자율적 호출 결정 → 결과 피드백)은 LLM 제공자마다 동일하지만, API 구조는 제공자마다 다르다.
| LLM | Function Calling 패턴 | 비고 |
|---|---|---|
| OpenAI | tools 파라미터 + message.tool_calls |
원조, 사실상 표준 |
| Upstage | OpenAI SDK 호환 | base_url만 변경하여 OpenAI SDK 그대로 사용 |
| Anthropic (Claude) | tools 파라미터 + tool_use 콘텐츠 블록 |
OpenAI와 유사하나 API 구조가 다름 |
| Google (Gemini) | tools 파라미터 + function_call 파트 |
자체 SDK, 구조 유사하나 세부 형식이 다름 |
| 기타 (Meta Llama 등) | OpenAI 호환 API 제공 또는 자체 패턴 | 호스팅 플랫폼에 따라 다름 |
OpenAI 형식이 사실상 표준이 되면서, 많은 LLM 제공자들이 OpenAI SDK 호환 API를 제공한다. Upstage도 이 중 하나로, OpenAI의 Python SDK(openai 패키지)를 그대로 사용하면서 base_url만 변경하면 된다.
반면, Anthropic(Claude)이나 Google(Gemini)은 자체 SDK와 API 구조를 사용한다. Tool 정의 방식이나 호출 결과를 처리하는 메시지 구조가 다르기 때문에, 이들 LLM으로 Agent를 구현할 때는 코드 수정이 필요하다.
이 글의 구현 예시는 OpenAI SDK 호환 형식을 사용한다. Upstage API가 OpenAI 호환이므로,
openai패키지를 그대로 사용하되base_url만 Upstage 엔드포인트로 변경한다.
핵심 구현 패턴
AI Agent의 구현은 크게 Tool 정의, Agentic Loop, Tool 실행 핸들러 세 가지 패턴으로 구성된다. 이 절에서는 LLM 제공자에 의존하지 않는 일반적인 패턴을 먼저 정리하고, 이후 구현 예시에서 OpenAI 호환 형식의 실제 코드를 살펴본다.
Tool 정의
Tool을 정의할 때는 다음 정보를 포함해야 한다.
Tool(
name = "도구 이름",
description = "LLM이 이 도구의 용도를 파악할 수 있는 설명",
parameters = {
"param1": { type: String, description: "파라미터 설명" },
"param2": { type: Integer, description: "파라미터 설명", required: false }
}
)
LLM은 description을 보고 “이 Tool을 지금 써야 하는가?”를 판단한다. 따라서 description이 명확하고 구체적이어야 한다.
Agentic Loop
AI Agent의 핵심 구현 패턴이다. LLM의 응답에 Tool 호출이 포함되어 있는 한 반복을 계속하고, Tool 호출이 없으면 루프를 종료한다.
# LLM 호출 (Tool 목록 제공)
response = LLM.generate(messages, tools)
# Tool 호출이 있는 한 반복
WHILE response.has_tool_calls:
FOR EACH tool_call IN response.tool_calls:
result = execute_tool(tool_call.name, tool_call.arguments)
messages.add(tool_result(tool_call.id, result))
# Tool 결과를 포함하여 LLM 재호출
response = LLM.generate(messages, tools)
# 루프 종료 → 최종 응답
RETURN response.text
이 패턴을 통해 아래와 같은 효과를 얻을 수 있다.
- LLM이 여러 Tool을 순차적으로 호출할 수 있다.
- 이전 Tool 결과를 바탕으로 다음 작업을 결정할 수 있다.
- 오류 발생 시 수정된 인자로 재시도할 수 있다.
- 복잡한 작업을 단계적으로 수행할 수 있다.
Tool 실행 핸들러
LLM이 생성한 Tool 호출 정보를 받아 실제 함수를 실행하는 부분이다. Tool 이름에 따라 적절한 함수를 매핑하여 호출한다.
FUNCTION execute_tool(name, arguments):
SWITCH name:
CASE "execute_sql":
RETURN run_sql_query(arguments.sql)
CASE "read_file":
RETURN read_file(arguments.path)
DEFAULT:
RETURN "알 수 없는 도구입니다"
구현: MLOps SQL Agent
위에서 정리한 AI Agent 패턴을 실제 코드로 구현한 예시를 살펴본다. 이 예시는 Upstage의 Solar API를 사용하며, 자연어 질문을 SQL로 변환하여 데이터베이스를 조회하는 SQL Agent다.
이 구현은 OpenAI SDK 호환 형식을 사용한다. Upstage API가 OpenAI 호환이므로,
openai패키지의OpenAI클라이언트에base_url만 변경하여 사용한다.
아키텍처
사용자 질문 (자연어)
↓
SQLAgent.ask()
↓
LLM (solar-pro3) 추론
├── Tool 불필요 → 텍스트 응답
└── Tool 필요 → execute_sql 호출 결정
↓
handle_tool_call()
↓
execute_query() ──→ SQLite 실행
↓
결과 반환 → LLM 재추론 → 추가 Tool 필요? → 반복
↓ No
최종 응답 (한국어)
전체 코드
common/client.py
```python import os from openai import OpenAI from dotenv import load_dotenv load_dotenv() client = OpenAI( api_key=os.environ["UPSTAGE_API_KEY"], base_url="https://api.upstage.ai/v1", ) ```mlops_dashboard/db_manager.py
```python import sqlite3 import os DB_PATH = os.path.join(os.path.dirname(__file__), "data", "sample.db") BLOCKED_KEYWORDS = {"DROP", "DELETE", "UPDATE", "INSERT", "ALTER", "CREATE", "TRUNCATE", "REPLACE"} def get_connection(): return sqlite3.connect(DB_PATH) def get_schema() -> str: conn = get_connection() cur = conn.cursor() cur.execute("SELECT name FROM sqlite_master WHERE type='table' ORDER BY name") tables = cur.fetchall() schema_parts = [] for (table_name,) in tables: cur.execute(f"PRAGMA table_info({table_name})") columns = cur.fetchall() col_defs = [f" {col[1]} {col[2]}" for col in columns] cur.execute(f"PRAGMA foreign_key_list({table_name})") fks = cur.fetchall() fk_defs = [f" FOREIGN KEY ({fk[3]}) REFERENCES {fk[2]}({fk[4]})" for fk in fks] parts = ",\n".join(col_defs + fk_defs) schema_parts.append(f"CREATE TABLE {table_name} (\n{parts}\n);") conn.close() return "\n\n".join(schema_parts) def execute_query(sql: str) -> str: sql_upper = sql.strip().upper() for keyword in BLOCKED_KEYWORDS: if keyword in sql_upper.split(): return f"[오류] {keyword} 쿼리는 허용되지 않습니다. SELECT만 사용 가능합니다." try: conn = get_connection() cur = conn.cursor() cur.execute(sql) columns = [desc[0] for desc in cur.description] if cur.description else [] rows = cur.fetchall() conn.close() if not rows: return "결과 없음" header = " | ".join(columns) separator = "-" * len(header) row_strs = [" | ".join(str(val) for val in row) for row in rows] return f"{header}\n{separator}\n" + "\n".join(row_strs) except Exception as e: return f"[SQL 오류] {e}" ```mlops_dashboard/sql_agent.py
```python import json import sys import os sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..")) from common.client import client from common.usage import UsageTracker, print_usage from mlops_dashboard.db_manager import get_schema, execute_query TOOLS = [ { "type": "function", "function": { "name": "execute_sql", "description": "SQLite 데이터베이스에 SELECT 쿼리를 실행합니다. SELECT 쿼리만 허용됩니다.", "parameters": { "type": "object", "properties": { "sql": { "type": "string", "description": "실행할 SQL SELECT 쿼리", } }, "required": ["sql"], }, }, } ] SYSTEM_PROMPT = """당신은 MLOps 플랫폼의 SQL 전문가입니다. 사용자의 자연어 질문을 SQL 쿼리로 변환하고 실행 결과를 설명합니다. 데이터베이스 스키마: {schema} 테이블 관계: - users 1:N projects (user_id) - projects 1:N datasets (project_id) - datasets 1:N pipelines (dataset_id) — 보통 dataset당 0~1개 파이프라인 - pipelines 1:N artifacts (pipeline_id) — checkpoint, log, config 등 - pipelines 1:0..1 models (pipeline_id, UNIQUE) — 학습 완료 시 모델 등록 - models 1:1 metrics (model_id, UNIQUE) — mAP50, F1 score 등 평가 지표 주요 컬럼 설명: - models.stage: development / staging / production / archived (모델 라이프사이클) - models.parameters_m: 모델 파라미터 수 (백만 단위) - metrics.map50: mAP@IoU=0.50 (object detection용, 분류 모델은 NULL) - metrics.f1_score: F1 Score (precision과 recall의 조화 평균) - metrics.precision_val: Precision (정밀도) - metrics.recall: Recall (재현율) - metrics.inference_ms: 추론 시간 (밀리초) - metrics.confidence_threshold: 모델 추론 시 사용한 confidence 기준값 - metrics.deploy_note: 배포 의사결정 메모 - pipelines.status: pending / running / completed / failed - artifacts.type: checkpoint / log / config 도메인 지식 (Precision vs Recall 트레이드오프): - 오탐 민감 현장: precision 높은 모델 선호 - 미탐 민감 현장: recall 높은 모델 선호 - 같은 모델도 confidence_threshold를 조절하면 precision/recall 밸런스가 바뀜 - deploy_note에 현장별 의사결정 근거가 기록되어 있음 규칙: - SELECT 쿼리만 사용하세요. - execute_sql 도구를 사용해서 쿼리를 실행하세요. - 쿼리 결과를 한국어로 친절하게 설명하세요. - 메트릭 값은 소수점으로 표시하되, 퍼센트로 변환해서 설명해도 됩니다. - precision/recall 관련 질문에는 오탐/미탐 관점에서 실무적으로 설명하세요. - 용량은 MB 단위입니다. """ def handle_tool_call(tool_call) -> str: if tool_call.function.name == "execute_sql": args = json.loads(tool_call.function.arguments) return execute_query(args["sql"]) return "[오류] 알 수 없는 도구입니다." class SQLAgent: def __init__(self, usage_enabled: bool = False): schema = get_schema() self.messages = [ {"role": "system", "content": SYSTEM_PROMPT.format(schema=schema)} ] self.tracker = UsageTracker(enabled=usage_enabled) def ask(self, question: str) -> str: self.messages.append({"role": "user", "content": question}) response = client.chat.completions.create( model="solar-pro3", messages=self.messages, tools=TOOLS, ) self.tracker.track_chat(response) message = response.choices[0].message self.messages.append(message) while message.tool_calls: for tool_call in message.tool_calls: sql = json.loads(tool_call.function.arguments).get("sql", "") print(f"\n[SQL] {sql}") result = handle_tool_call(tool_call) print(f"\n[결과]\n{result}") self.messages.append( { "role": "tool", "tool_call_id": tool_call.id, "content": result, } ) response = client.chat.completions.create( model="solar-pro3", messages=self.messages, tools=TOOLS, ) self.tracker.track_chat(response) message = response.choices[0].message self.messages.append(message) last_info = {"input": self.tracker.total_input_tokens, "output": self.tracker.total_output_tokens, "cost": self.tracker.total_cost} print_usage(self.tracker, last_info) return message.content ```mlops_dashboard/main.py
```python import os import sys sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..")) from mlops_dashboard.db_manager import DB_PATH from mlops_dashboard.setup_db import create_sample_db from mlops_dashboard.sql_agent import SQLAgent def main(): usage_enabled = "--usage" in sys.argv if not os.path.exists(DB_PATH): print("샘플 DB가 없습니다. 생성합니다...") create_sample_db() print(f"DB 연결 완료 ({DB_PATH})") print("질문을 입력하세요 (quit 또는 exit로 종료)\n") agent = SQLAgent(usage_enabled=usage_enabled) while True: try: question = input("> ").strip() except (EOFError, KeyboardInterrupt): print("\n종료합니다.") break if not question: continue if question.lower() in ("quit", "exit"): print("종료합니다.") break try: answer = agent.ask(question) print(f"\n[설명] {answer}\n") except Exception as e: print(f"\n[오류] {e}\n") if __name__ == "__main__": main() ```주요 코드 설명
API 클라이언트
Upstage API는 OpenAI SDK 호환이므로, openai 패키지의 OpenAI 클라이언트를 그대로 사용한다. base_url만 Upstage 엔드포인트로 변경하면 된다.
from openai import OpenAI
client = OpenAI(
api_key=os.environ["UPSTAGE_API_KEY"],
base_url="https://api.upstage.ai/v1", # Upstage 엔드포인트
)
OpenAI를 직접 사용하는 경우에는 base_url 없이 api_key만 설정하면 된다. OpenAI 호환 API를 제공하는 다른 제공자(Together AI, Fireworks 등)도 같은 방식으로 base_url만 변경하면 된다.
Tool 정의
OpenAI 호환 형식에서 Tool은 다음과 같은 JSON 스키마로 정의한다. type은 "function"으로 고정이고, function 안에 이름, 설명, 파라미터를 기술한다.
TOOLS = [
{
"type": "function",
"function": {
"name": "execute_sql",
"description": "SQLite 데이터베이스에 SELECT 쿼리를 실행합니다. SELECT 쿼리만 허용됩니다.",
"parameters": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "실행할 SQL SELECT 쿼리",
}
},
"required": ["sql"],
},
},
}
]
여기서 execute_sql은 실제 Python 함수 이름이 아니라 Tool 이름이다. LLM은 이 이름으로 Tool을 호출하겠다는 의사를 표현하고, 실제 어떤 함수가 실행되는지는 핸들러에서 매핑한다.
description이 중요하다. LLM은 이 설명을 읽고 “이 Tool을 지금 써야 하는가?”를 판단한다. “SELECT 쿼리만 허용됩니다”라는 제약 조건도 description에 포함하여 LLM이 적절한 쿼리를 생성하도록 유도한다.
System Prompt
System Prompt는 Agent의 행동 방식을 정의한다. 이 SQL Agent에서는 데이터베이스 스키마를 동적으로 주입하여 LLM이 테이블 구조를 파악할 수 있도록 한다.
SYSTEM_PROMPT = """당신은 MLOps 플랫폼의 SQL 전문가입니다. ...
데이터베이스 스키마:
{schema}
테이블 관계:
- users 1:N projects (user_id)
- projects 1:N datasets (project_id)
...
규칙:
- SELECT 쿼리만 사용하세요.
- execute_sql 도구를 사용해서 쿼리를 실행하세요.
- 쿼리 결과를 한국어로 친절하게 설명하세요.
..."""
Agent 초기화 시 get_schema()로 실제 DB 스키마를 가져와 주입한다.
class SQLAgent:
def __init__(self, usage_enabled: bool = False):
schema = get_schema()
self.messages = [
{"role": "system", "content": SYSTEM_PROMPT.format(schema=schema)}
]
이렇게 하면 테이블이 추가되거나 변경되어도 코드 수정 없이 자동으로 반영된다.
Agent 메인 로직 (Agentic Loop)
앞서 정리한 Agentic Loop 패턴의 실제 구현이다.
def ask(self, question: str) -> str:
self.messages.append({"role": "user", "content": question})
# LLM 호출 (Tool 목록 제공)
response = client.chat.completions.create(
model="solar-pro3",
messages=self.messages,
tools=TOOLS, # ← 사용 가능한 Tool 목록 제공
)
message = response.choices[0].message
self.messages.append(message)
# Tool 호출이 있으면 반복 실행 (Agentic Loop)
while message.tool_calls:
for tool_call in message.tool_calls:
result = handle_tool_call(tool_call)
# Tool 실행 결과를 대화 히스토리에 추가
self.messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result,
})
# Tool 결과를 포함하여 LLM 재호출
response = client.chat.completions.create(
model="solar-pro3",
messages=self.messages,
tools=TOOLS,
)
message = response.choices[0].message
self.messages.append(message)
return message.content
주목할 점:
tools=TOOLS: 매 호출마다 Tool 목록을 전달한다. LLM이 매번 “이 Tool들을 사용할 수 있다”는 것을 인지한다.message.tool_calls: LLM이 Tool 호출이 필요하다고 판단하면 이 필드에 호출 정보가 담긴다. 필요 없으면None이다.role: "tool": Tool 실행 결과를 대화 히스토리에 추가할 때 사용하는 역할이다.tool_call_id로 어떤 호출의 결과인지 매핑한다.while message.tool_calls: Tool 호출이 없을 때까지 반복한다. LLM이 “충분한 정보를 얻었다”고 판단하면 Tool 호출 없이 텍스트 응답만 반환하고, 루프가 종료된다.
Tool 실행 핸들러
LLM이 생성한 Tool 호출 정보를 받아 실제 함수를 실행하는 부분이다.
def handle_tool_call(tool_call) -> str:
if tool_call.function.name == "execute_sql":
args = json.loads(tool_call.function.arguments)
return execute_query(args["sql"]) # 실제 SQL 실행 함수 호출
return "[오류] 알 수 없는 도구입니다."
tool_call.function.arguments는 JSON 문자열이므로 파싱이 필요하다. 파싱된 인자를 실제 SQL 실행 함수인 execute_query()에 전달한다.
DB 보안: 읽기 전용 제한
Agent가 DB에 접근할 수 있으므로, 보안을 위해 쓰기 작업을 차단한다.
BLOCKED_KEYWORDS = {"DROP", "DELETE", "UPDATE", "INSERT", "ALTER", "CREATE", "TRUNCATE", "REPLACE"}
def execute_query(sql: str) -> str:
sql_upper = sql.strip().upper()
for keyword in BLOCKED_KEYWORDS:
if keyword in sql_upper.split():
return f"[오류] {keyword} 쿼리는 허용되지 않습니다. SELECT만 사용 가능합니다."
# ... SELECT 쿼리 실행
System Prompt에서 “SELECT만 사용하세요”라고 안내하지만, LLM이 이를 무시할 가능성이 있다. 따라서 핸들러 수준에서도 차단하는 이중 방어를 적용한다. AI Agent를 구현할 때는 이처럼 LLM의 판단에만 의존하지 않고, 실행 레이어에서도 보안 제약을 설정하는 것이 중요하다.
실행 흐름 예시
Tool 호출이 필요한 경우
사용자가 “프로젝트 목록을 보여줘”라고 질문하면:
- LLM이 데이터베이스 조회가 필요하다고 판단한다.
execute_sqlTool 호출을 결정하고, 인자로SELECT * FROM projects를 생성한다.- 핸들러가
execute_query("SELECT * FROM projects")를 실행한다. - 결과(포맷팅된 테이블 데이터)가 대화 히스토리에 추가된다.
- LLM이 결과를 해석하여 한국어로 설명한다.
- 추가 Tool 호출이 필요 없으므로 루프가 종료되고, 최종 응답이 반환된다.
Tool 호출이 불필요한 경우
사용자가 “안녕하세요”라고 말하면:
- LLM이 Tool이 필요하지 않다고 판단한다.
message.tool_calls가None이므로while루프에 진입하지 않는다.- 바로 텍스트 응답(“안녕하세요! 무엇을 도와드릴까요?”)이 반환된다.
오류 자동 수정
LLM이 잘못된 SQL을 생성한 경우:
execute_query()가[SQL 오류] ...메시지를 반환한다.- 이 오류 메시지가 대화 히스토리에 추가되어 LLM에 전달된다.
- LLM이 오류를 관찰하고, 수정된 쿼리로 다시
execute_sql을 호출한다. - Agentic Loop가 이 자동 수정을 가능하게 한다.
Tool 정의 전략
목적에 맞는 Tool만 정의한다
이론적으로 모든 Tool을 한꺼번에 정의해도 동작하지만, 목적에 맞는 Tool만 제공하는 것이 좋다.
| Agent 유형 | 필요한 Tool |
|---|---|
| SQL Agent | execute_sql |
| 파일 관리 Agent | read_file, write_file, list_files |
| 웹 검색 Agent | search_web, fetch_url |
Tool이 너무 많으면 LLM이 잘못된 Tool을 선택할 가능성이 높아지고, 관련 없는 Tool은 오히려 혼란을 유발한다.
Description을 명확하게 작성한다
LLM은 Tool의 description을 보고 사용 여부를 판단한다. 따라서 무엇을 하는 도구인지, 어떤 제약 조건이 있는지 구체적으로 작성해야 한다.
# 나쁜 예
description = "SQL을 실행합니다"
# 좋은 예
description = "SQLite 데이터베이스에 SELECT 쿼리를 실행합니다. SELECT 쿼리만 허용됩니다."
보안 제약을 반드시 설정한다
앞서 살펴본 SQL Agent의 읽기 전용 제한처럼, Tool이 수행할 수 있는 작업의 범위를 제한해야 한다. Agent가 자율적으로 동작하는 만큼, 의도치 않은 위험한 작업이 실행되지 않도록 실행 레이어에서 방어하는 것이 중요하다.
참고: response_format과 Function Calling
response_format은 LLM API의 파라미터로, LLM 응답을 특정 형식(예: JSON)으로 강제하는 기능이다. 이는 AI Agent 패턴의 일부가 아니라 LLM API 자체의 기능이다.
# response_format 사용 예: 응답을 JSON으로 강제
response = client.chat.completions.create(
model="solar-pro3",
messages=messages,
response_format={"type": "json_object"},
)
AI Agent에서는 일반적으로 response_format을 사용하지 않는다. Agent는 상황에 따라 “Tool을 호출할지, 텍스트로 응답할지”를 자유롭게 선택할 수 있어야 하는데, response_format은 응답 형식을 고정하여 이 자유를 제약하기 때문이다.
이 프로젝트의 SQL Agent에서도 response_format을 사용하지 않는다.
response = client.chat.completions.create(
model="solar-pro3",
messages=self.messages,
tools=TOOLS,
# response_format은 사용하지 않음
)
response_format은 Tool 호출이 필요 없는 상황, 예를 들어 구조화된 JSON 데이터만 필요한 단순 질의응답에서 유용하다.
API 제공자에 따라
response_format과tools를 동시에 사용할 수 있는 경우도 있지만, Agent의 자율성을 보장하기 위해 함께 사용하지 않는 것이 일반적이다.
정리
이 글에서 다룬 내용을 정리하면 다음과 같다.
| 개념 | 설명 |
|---|---|
| AI Agent | LLM + Tool + Function Calling으로 구성된 자율적 시스템 |
| Function Calling | LLM이 Tool을 호출할 수 있도록 하는 메커니즘 |
| Agentic Loop | Tool 호출 → 결과 관찰 → 재추론을 반복하는 핵심 패턴 |
| 개발자 역할 | Tool 정의 + 명확한 Description + 보안 제약 설정 |
| LLM 역할 | Tool 호출 시점과 방법 결정 + 결과 해석 + 최종 응답 생성 |
SQL Agent는 이 패턴의 구체적인 구현 예시다. 자연어 질문을 SQL로 변환하고, 데이터베이스를 조회하며, 결과를 한국어로 설명하는 일련의 과정이 Agentic Loop를 통해 자율적으로 이루어진다.
AI Agent의 가치는 LLM의 추론 능력과 외부 도구의 실행 능력을 결합하여, LLM 단독으로는 불가능했던 작업을 수행할 수 있게 한다는 점이다. 개발자는 적절한 Tool만 정의하면, LLM이 자율적으로 필요한 도구를 선택하고 실행하여 사용자의 목표를 달성한다.
참고 자료
- OpenAI Function Calling
- Upstage API - Function Calling
- Anthropic Tool Use
- Google Gemini Function Calling

댓글남기기