
[Crawling] 파이썬 웹 크롤링
신윤수 강사님의 강의 및 강의 자료를 기반으로 합니다.
Crawling Tips
1. GET vs. POST
참고 : HTTP 메소드
- GET : 가져오기
- POST : 붙이기(등록하기)
- PUT : 수정하기
- DELETE : 삭제하기
GET : 읽거나 검색. 눈에 보임.
- URL에 변수(데이터) 포함해 요청. URL 형식에 맞지 않는 경우 인코딩.
- 데이터를 Header에 포함해 요청.
- Body는 보통 빈 상태로 전송.
POST : 데이터 제출 후 데이터 등록 혹은 생성. 눈에 안 보임.
- URL에 데이터 노출하지 않고 요청.
- 데이터는 Body에 포함해 요청. 전송 시 필요한 추가 데이터 포함.
- Header 필드 중 Body의 데이터를 포함하는 Content-Type 필드가 들어가고, 어떠한 데이터 타입인지 명시.
- 쿼리 스트링 뿐만 아니라, 라디오 버튼, 텍스트 박스 등 객체 값도 전송 가능.
2. 태그 선택
- find(), find_all()
- find_all()에서
recursive=False옵션을 적절하게 활용하자. - find_all()로 가져 온 태그 묶어서 가져올 때 zip 함수 써서 unpack하면 편하다!
- find_all()에서
# 언패킹 예시
for news_li, enter_li in zip(*ols):
news_kwd = news_li.find('span', class_='tit').text.strip()
enter_kwd = enter_li.find('span', class_='tit').text.strip()
- selector로 반환하면 굳이
find,find_all로 타고 타고 들어가지 않아도 된다.- 원래 위의 방법으로 태그 타고 타고 들어가는 방법을 썼는데, 이제 보니 selector로 선택하는 게 더 편해 보인다.
- `
(공백)은 하위 태그 전체,>`는 하위 태그 중 직계 자식만을 의미한다.
3. URL 설정
문자열 formatting도 좋지만, dictionary 사용해서 header 정보 및 쿼리까지 같이 넘기자.
base_url = "https://news.naver.com/main/list.nhn"
# 뒷부분 : ?mode=LS2D&mid=shm&sid1=101&sid2=259
params = {
'mode' : 'LS2D',
'mid' : 'shm',
'sid1' : 101, # category1 : 경제
'sid2' : 259, # category2 : 금융
'date' : '20200602' # date
}
# 요청 전송
req = requests.get(base_url, params=params)
4. iframe
- 효과적으로 다른 HTML 페이지를 현재 페이지에 포함시키는 중첩된 브라우저로, 특수한 태그의 일종이다.
- 개발자 도구에서 네트워크 흐름을 분석하면, 브라우저가 iframe 태그를 만나는 순간 또 다른 요청을 보낸다는 것을 알 수 있다. 우리도 브라우저처럼 요청을 똑같이 2번 보내줘야 한다. 어디로? iframe의 소스 url로!
- 요청 가는 url을 개발자 도구 말고, 그냥
프레임 소스 보기로 검사하면 빠르다.
5. DOM 크롤링 (w/o Selenium)
지금 강사님은 Selenium을 좋아하지는 않는 편
Selenium 말고, 순수하게 네트워크 분석을 통해 request와 header 정보 활용해서 한 번에 JSON 데이터를 받아오자.
예전 프로젝트할 때 뉴스 댓글 크롤링 셀레늄으로 안 하고 이렇게 했다면 오히려 댓글 한 번에 받아와서 더 편했을 수도 있었을 듯?
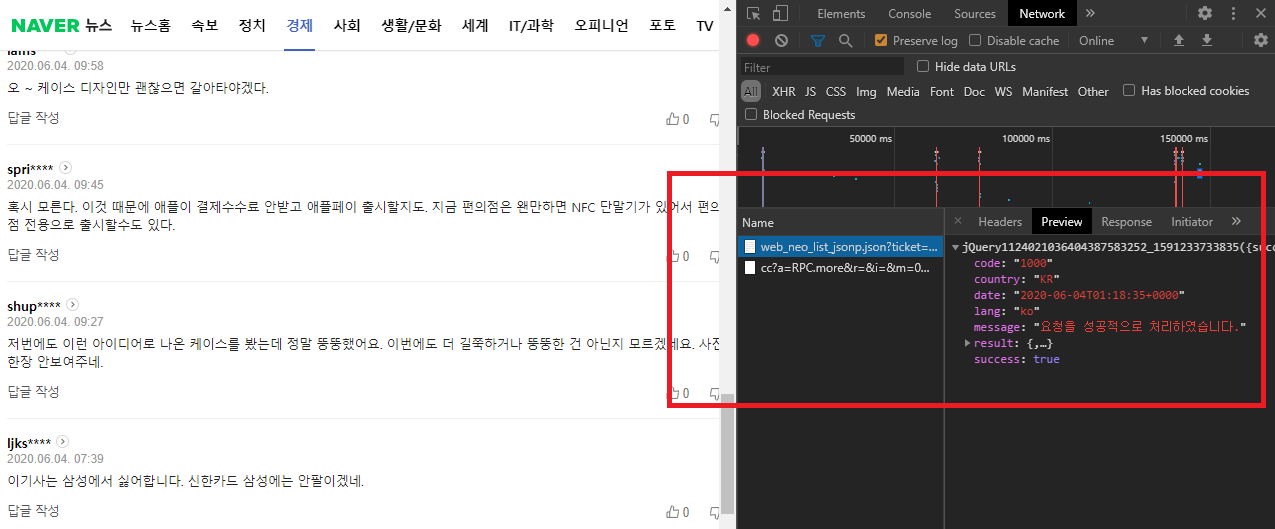
request_comment_list: 뉴스 url을 바탕으로 해당 뉴스 댓글 데이터에 request를 보내는 함수.- 네트워크 분석에서 알아낸 request url을 분석한다. 쓸데 없는 파라미터는 다 날려 버리고, 동적으로 컨트롤할 수 있는 파라미터를 구분해내야 한다.
- 요청을 보내고 한 뉴스 기사에 달려 있는 모든 댓글의 json 데이터를 받아 온다.
- 한 번에 더 많은 뉴스 댓글을 가져오고 싶다면
pageSize와page를 조정한다. 일단 지금은 예시로 1000개의 댓글만 가져오도록 설정했다.
import requests
def request_comment_list(oid, aid):
"""
뉴스 url을 기반으로 해당 뉴스 댓글 데이터 페이지에 request를 보내는 함수.
* parameter
- oid: 본문 url의 oid 쿼리.
- aid: 본문 url의 aid 쿼리.
* return
- 요청을 보낸 후 파싱한 html.
"""
# 댓글 API url
comment_base_url = "https://apis.naver.com/commentBox/cbox/web_neo_list_jsonp.json"
# 댓글 API url 필수 파라미터
params = {
'ticket': 'news',
'pool': 'cbox5',
'lang': 'ko',
'country': 'KR',
'objectID': 'news{0},{1}'.format(oid, aid), # 각각의 뉴스 url
'pageSize': 1000,
'indexSize': 10,
'page': 1,
'includeAllSTatus': 'true',
'cleanbotGrade': 2
}
# request headers 설정
headers = {
'referer': "https://news.naver.com/main/read.nhn?m_view=1&includeAllCount=true&mode=LS2D&mid=shm&sid1=101&sid2=259&oid={0}&aid={1}".format(oid, aid)
}
# request 전송
req = requests.get(comment_base_url, params=params, headers=headers)
# html 문서 반환
html = req.text
return html
이 방식을 사용하면 댓글의 JSON 데이터를 저장하게 된다. 이를 위해 JSON 데이터를 파이썬 객체로 바꿔주는 과정이 필요하다. 나중에는 바꾼 파이썬 객체에서 필요한 데이터만 뽑아 쓰면 된다.
resp_to_json: 댓글 리스트에 요청을 보내 받아온 결과 html을 파싱하여 json 객체로 바꾼다.
import json
def resp_to_json(html):
"""
응답으로 온 html 텍스트를 분석하여 파이썬의 객체로 만드는 함수.
* parameter
- html : <Response.text>
* return
- 응답 데이터가 저장되어 있는 파이썬 dict.
"""
comment_resp = html[10:-2] # 필요 없는 데이터 날리기
comment_resp_dict = json.loads(comment_resp) # json을 파이썬의 dict형태로 변환
return comment_resp_dict
6. 이미지 크롤링
- url의 개념적 저장보다는 이미지 실제 파일의 물리적 저장이 추천된다.
- 대용량 파일의 경우
stream=True옵션으로 진행한다.req.iter_content()이터레이터 객체 안에 chunk 단위로 분할하여 저장하자.
import os
from urllib.parse import urlparse, parse_qs
# 저장 경로 설정
base_file_dir = 'images'
if not os.path.exists(base_file_dir):
os.makedirs(base_file_dir)
# 로컬 파일 저장 경로에 바이너리 데이터 저장
for result in news_results:
image_url = result['image']
# 개별 이미지 파일 이름
if image_url:
parsed_image_url = urlparse(image_url)
parsed_image_qs = parse_qs(parsed_image_url.query)
image_src = parsed_image_qs['src'][0]
image_path = os.path.join(base_file_dir, image_src.split('/')[-1])
# 대용량 이미지 저장 옵션
image_content = requests.get(image_url, stream=True).content
# 이미지 chunk 바이너리 모드 저장
with open(image_path, 'wb') as f:
for chunk in req.iter_content():
f.write(chunk)
# 이미지 경로 저장
result['image_path'] = image_path


댓글남기기