
[Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 2. 배경지식: cgroup, 컨테이너, 쿠버네티스
이전 글에서 CFS bandwidth control이 quota/period 기반으로 CPU 시간을 제한하고, quota를 초과하면 throttling이 발생한다는 것을 알았다. 그런데 이 제한은 “프로세스 그룹” 단위로 적용된다고 했다. 이 그룹은 어떻게 정의되고, K8s의 CPU limit 설정이 실제로 어떤 경로를 거쳐 커널에 전달되는 걸까?
cgroup, 컨테이너 런타임, 쿠버네티스의 리소스 관리 각각이 그 자체로 깊은 주제다. 여기서는 CPU limit이 커널까지 전달되는 경로를 따라가는 데 필요한 수준으로만 정리한다.
TL;DR
- cgroup: 프로세스 그룹 단위로 리소스를 제한하는 리눅스 커널 기능
cpu.max파일에 quota/period를 설정하고,cpu.stat파일에서 사용량과 throttling 정보를 확인- 컨테이너 = namespace(격리) + cgroup(제한)이며, 별도 커널 없이 호스트 커널 하나가 모든 컨테이너를 스케줄링
- K8s CPU limit 설정은 kubelet → 컨테이너 런타임 → cgroup
cpu.max로 변환된다 - 정밀한 throttling 분석에는
kubectl top보다cpu.stat을 직접 읽는 것이 신뢰할 만하다
cgroup
개념
cgroup(control group)은 프로세스들을 그룹으로 묶어 리소스 사용량을 제한하고 추적하는 리눅스 커널 기능이다. CPU, 메모리, I/O 등 다양한 리소스를 제어할 수 있다.
이전 글에서 다룬 CFS bandwidth control의 quota/period 설정이 바로 이 cgroup 단위로 적용된다. cgroup이 없으면 개별 프로세스마다 제한을 걸어야 하지만, cgroup이 있으면 “이 그룹에 속한 모든 프로세스가 합산해서 CPU를 얼마까지만 쓸 수 있다”고 선언할 수 있다.
cgroup에는 v1과 v2 두 가지 버전이 있다. v1은 리소스 컨트롤러별로 별도의 계층 구조를 가지고, v2는 단일 통합 계층 구조를 사용한다. 이 시리즈의 실험 환경은 cgroup v2이며, 이후 등장하는 파일 경로와 인터페이스(cpu.max, cpu.weight, cpu.stat 등)는 모두 cgroup v2 기준이다. 기존 자료에서 자주 등장하는 cgroup v1 인터페이스와의 대응 관계는 다음과 같다.
| 기능 | cgroup v1 | cgroup v2 |
|---|---|---|
| quota/period 설정 | cpu.cfs_quota_us + cpu.cfs_period_us |
cpu.max |
| 상대적 가중치 | cpu.shares (범위: 2~262144) |
cpu.weight (범위: 1~10000) |
| 사용량/throttling 통계 | cpuacct.stat + cpu.stat (별도 파일) |
cpu.stat (통합) |
cpu.max: quota/period 설정
cgroup v2에서 CPU 제한은 cpu.max 파일로 설정한다.
cat /sys/fs/cgroup/<cgroup-path>/cpu.max
# 출력: 100000 100000
형식은 <quota> <period>이며, 단위는 마이크로초(us)다.
| 설정 | quota | period | 의미 |
|---|---|---|---|
100000 100000 |
100ms | 100ms | 1코어 분량 |
200000 100000 |
200ms | 100ms | 2코어 분량 |
400000 100000 |
400ms | 100ms | 4코어 분량 |
max 100000 |
제한 없음 | 100ms | 무제한 |
K8s에서 CPU limit 1000m을 설정하면, cpu.max가 100000 100000(1코어)으로 설정된다.
cpu.stat: 커널이 기록하는 카운터
cpu.stat은 커널이 cgroup 단위로 CPU 사용량과 throttling 정보를 누적 기록하는 파일이다.
cat /sys/fs/cgroup/<cgroup-path>/cpu.stat
usage_usec 601310324000
user_usec 394662213000
system_usec 206648111000
nr_periods 0
nr_throttled 0
throttled_usec 0
nr_bursts 0
burst_usec 0
| 필드 | 의미 |
|---|---|
usage_usec |
cgroup 내 프로세스들이 사용한 총 CPU 시간 (us) |
user_usec |
사용자 모드에서 소비한 CPU 시간 |
system_usec |
커널 모드에서 소비한 CPU 시간 |
nr_periods |
bandwidth control이 활성화된 상태에서 경과한 총 period 수 |
nr_throttled |
quota를 초과해 throttle된 period 수 |
throttled_usec |
throttle 상태로 대기한 총 시간 (us) |
nr_bursts |
burst가 발생한 횟수 |
burst_usec |
burst로 추가 사용한 총 CPU 시간 (us) |
nr_bursts와 burst_usec은 cgroup v2의 cpu.max.burst 기능과 관련된다. cpu.max.burst는 이전 period에서 사용하지 않은 quota를 축적해 두었다가, 순간적으로 quota를 초과하여 사용할 수 있게 하는 burst capacity다. 기본값은 0(burst 비활성)이며, K8s에서 직접 설정하지는 않는다. burst가 설정되어 있으면, 일시적인 CPU 사용량 급증에 대해 throttling 없이 유연하게 대응할 수 있다.
모든 값이 누적 카운터라는 점에 주의해야 한다. 파일을 읽는 순간(cat 등으로) 그 시점까지의 누적값이 보인다. 따라서 특정 구간의 상태를 분석하려면 before/after 패턴으로 delta를 구해야 한다.
# before
cat cpu.stat > before.txt
# (작업 실행)
# after
cat cpu.stat > after.txt
# delta 계산
# nr_periods: after - before = 해당 구간의 period 수
# nr_throttled: after - before = throttle된 period 수
각 필드의 업데이트 시점도 다르다.
| 값 | 업데이트 시점 |
|---|---|
usage_usec / user_usec / system_usec |
컨텍스트 스위치마다 (수 us ~ 수 ms 단위) |
nr_periods / nr_throttled / throttled_usec |
CFS period마다 (기본 100ms 간격) |
throttling 관점에서 중요한 세 필드를 자세히 보자. nr_periods와 nr_throttled는 cpu.max에 quota가 설정되어 bandwidth control이 활성화된 경우에만 카운트된다. cpu.max가 max(제한 없음)이면 두 값 모두 0으로 남는다.
| 필드 | 카운트 단위 | 증가 조건 | 해석 예시 |
|---|---|---|---|
nr_periods |
period | bandwidth control 활성 + 해당 period에 실행 대기 태스크 존재 | 215 = 21.5초간 측정 |
nr_throttled |
period | 해당 period에서 quota 소진으로 throttling 발생 | 208 = 208개 period에서 throttle |
throttled_usec |
마이크로초(us) | throttle 상태에서 대기할 때마다 누적 | 154,500,000us = 154.5초 대기 |
nr_throttled / nr_periods는 “실행 대기 태스크가 있었던 period 중 몇 %에서 throttling이 발생했는가”를 의미한다. 이 비율이 높을수록 CPU 제한이 심한 것이다 (예: 208/215 = 96.7%).
cgroup 계층 구조
cgroup은 트리 구조로 구성된다. 호스트의 /sys/fs/cgroup/ 아래에 계층적으로 배치되며, 각 소프트웨어가 자신의 하위 계층을 만든다.
/sys/fs/cgroup/ ← 호스트 루트 cgroup
├── cpu.stat ← 시스템 전체 CPU 사용량
├── system.slice/ ← systemd 서비스들
│ ├── sshd.service/
│ └── containerd.service/
└── user.slice/ ← 사용자 프로세스들
.slice 네이밍은 systemd의 cgroup 관리 방식이다. systemd가 cgroup driver로 사용될 때, 프로세스 그룹을 slice 단위로 관리하고, 이름에서 -가 계층 구분자 역할을 한다 (예: A-B.slice는 A.slice 아래의 B).
이 트리의 핵심은 읽는 위치에 따라 보이는 범위가 달라진다는 점이다. 루트에서 읽으면 시스템 전체, 특정 slice에서 읽으면 해당 그룹만 보인다. 컨테이너 런타임이나 K8s도 이 트리 아래에 자신만의 하위 계층을 만들어 프로세스를 관리한다.
컨테이너와 cgroup
컨테이너 = namespace + cgroup
컨테이너는 VM과 다르다. 별도의 커널을 가지지 않는다. 컨테이너는 두 가지 리눅스 커널 기능의 조합이다.
| 기능 | 역할 |
|---|---|
| namespace | 격리 (프로세스, 네트워크, 파일시스템 등을 분리) |
| cgroup | 제한 (CPU, 메모리 등 리소스 사용량 상한 설정) |
namespace가 “무엇이 보이는지”를 제어하고, cgroup이 “얼마나 쓸 수 있는지”를 제어한다.
컨테이너 런타임(containerd, Docker 등)이 컨테이너를 생성할 때, 앞서 본 cgroup 트리 아래에 컨테이너 전용 cgroup을 만든다. 예를 들어 containerd가 단독으로 컨테이너를 실행하면 system.slice/ 아래에 scope가 생긴다. K8s 환경에서는 kubelet이 런타임에게 별도의 계층 구조를 지시하는데, 이 부분은 쿠버네티스 리소스 관리 섹션에서 자세히 다룬다.
호스트 커널이 모든 것을 스케줄링한다
이것이 핵심이다. 컨테이너에는 별도의 커널이 없다. 호스트의 리눅스 커널 하나가 모든 컨테이너의 프로세스를 스케줄링한다. 컨테이너를 쓰다 보면 마치 독립된 머신인 것처럼 느끼기 쉬운데, 실제로는 하나의 커널 위에서 돌아가고 있다는 점을 잊지 말아야 한다.
Container A (ffmpeg 스레드들) Container B Container C
\ | /
\ | /
+--------------------------------------------+
호스트 Linux 커널 (단일)
CFS 스케줄러 + cgroup bandwidth ctrl
+--------------------------------------------+
물리 CPU (멀티코어)
+--------------------------------------------+
컨테이너 내부에서 fork()를 하든, 스레드를 만들든, 전부 호스트 커널의 CFS 스케줄러가 관리한다. cgroup의 cpu.max에 설정된 quota/period에 따라 throttling을 적용하는 것도 호스트 커널이다.
mount namespace와 cgroup 가시성
컨테이너 내부에서 /sys/fs/cgroup/cpu.stat을 읽으면 자기 컨테이너의 값만 보인다. 이는 mount namespace에 의해 cgroup 파일시스템의 마운트 포인트가 자기 cgroup 디렉토리로 바인드 마운트되어 있기 때문이다.
실제 데이터는 호스트 커널이 관리하는 단일 cgroup 트리에 있고, 컨테이너는 그 중 자기 노드만 볼 수 있는 구조다.
호스트에서 컨테이너의 cgroup 경로를 찾아 직접 확인할 수도 있다. 구체적인 경로 확인 방법은 K8s 환경의 cgroup 계층 구조와 함께 아래에서 다룬다.
쿠버네티스 리소스 관리
request, limit, QoS
K8s에서 컨테이너의 CPU 리소스는 request와 limit으로 설정한다.
| 설정 | 의미 | cgroup 매핑 |
|---|---|---|
| request | 최소 보장량. 스케줄링 기준 | cpu.weight (상대적 가중치) |
| limit | 최대 사용량. 초과 시 throttling | cpu.max (quota/period) |
CPU 단위는 밀리코어(m)다. 1000m = 1코어, 500m = 0.5코어.
request와 limit 설정에 따라 Pod의 QoS(Quality of Service) 클래스가 결정된다.
| QoS 클래스 | 조건 | cgroup 계층 |
|---|---|---|
| Guaranteed | 모든 컨테이너에 request = limit | kubepods-guaranteed.slice |
| Burstable | request와 limit이 다름 | kubepods-burstable.slice |
| BestEffort | request, limit 모두 미설정 | kubepods-besteffort.slice |
이전 글의 매니페스트는 request: 500m, limit: 1000m이었으므로 Burstable QoS다.
cgroup 계층 구조
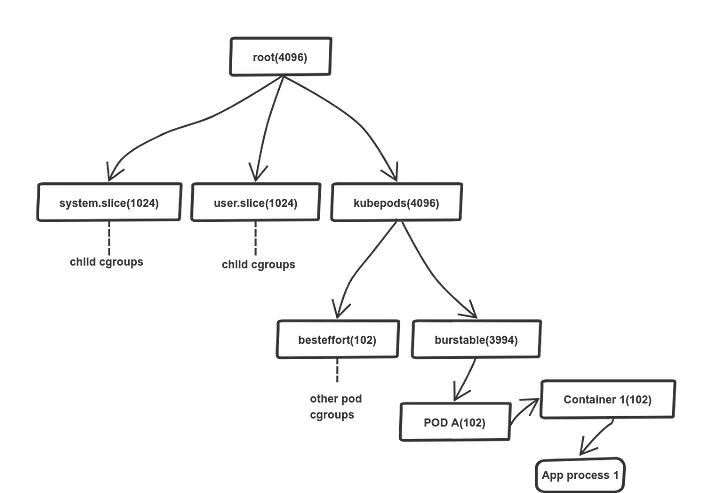
kubelet은 QoS 클래스별로 cgroup 하위 계층을 만들어 Pod를 배치한다. K8s가 없으면 이 계층은 존재하지 않는다. 앞서 본 일반적인 cgroup 트리에 K8s가 추가하는 부분을 포함하면 다음과 같다.
/sys/fs/cgroup/ ← 호스트 루트 cgroup
├── cpu.stat ← 시스템 전체 CPU 사용량
├── system.slice/ ← systemd 서비스들
│ ├── sshd.service/
│ └── containerd.service/
├── user.slice/ ← 사용자 프로세스들
└── kubepods.slice/ ← K8s가 관리하는 모든 Pod
├── cpu.stat ← 모든 Pod의 CPU 합산
├── kubepods-guaranteed.slice/ ← Guaranteed QoS Pod들
├── kubepods-burstable.slice/ ← Burstable QoS Pod들
│ └── kubepods-burstable-pod<UID>.slice/ ← 특정 Pod
│ ├── cpu.stat ← Pod 레벨 합산
│ └── cri-containerd-<CID>.scope/ ← 특정 컨테이너
│ ├── cpu.max ← CPU limit 설정
│ └── cpu.stat ← 컨테이너의 CPU 사용량
└── kubepods-besteffort.slice/ ← BestEffort QoS Pod들
kubepods.slice → kubepods-burstable.slice 같은 네이밍은 systemd의 slice 규칙을 따른 것이다 (이름의 -가 계층 구분자). kubelet의 cgroup driver가 systemd로 설정되어 있기 때문에 이 네이밍이 적용된다.
참고: cgroup 드라이버 설정
cgroup 드라이버를
systemd로 맞춰야 하는 이유는, systemd가 이미 호스트의 cgroup 트리를 관리하고 있어서 kubelet이 직접 cgroup을 조작(cgroupfs)하면 관리 주체가 둘이 되어 충돌이 발생할 수 있기 때문이다. containerd의SystemdCgroup = true와 kubelet의cgroupDriver: systemd를 일치시켜야 하며, 이에 대한 상세한 설명은 kubeadm 시리즈에서 다룬 바 있다.
QoS별로 계층이 분리되는 이유는 축출(eviction) 우선순위 때문이다. 노드 리소스가 부족하면 BestEffort → Burstable → Guaranteed 순으로 축출하는데, cgroup이 분리되어 있어야 QoS 클래스 단위로 리소스 사용량을 추적하고 제어할 수 있다.
이 계층 구조 역시 읽는 위치에 따라 보이는 범위가 달라진다.
| 읽는 위치 | 보이는 범위 |
|---|---|
컨테이너 내부 /sys/fs/cgroup/cpu.stat |
자기 컨테이너만 |
호스트 kubepods-burstable-pod<UID>.slice/cpu.stat |
해당 Pod의 모든 컨테이너 합산 |
호스트 kubepods.slice/cpu.stat |
모든 K8s Pod 합산 |
호스트 루트 /sys/fs/cgroup/cpu.stat |
시스템 전체 |
호스트에서 특정 컨테이너의 cgroup 경로를 찾아 직접 확인할 수 있다.
# 컨테이너 ID 확인
crictl ps | grep <container-name>
# 해당 컨테이너의 cgroup 경로 확인
crictl inspect <container-id> | grep cgroupsPath
# 호스트에서 직접 cpu.stat 읽기
cat /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/\
kubepods-burstable-pod<pod-uid>.slice/\
cri-containerd-<container-id>.scope/cpu.stat
실제로 Burstable QoS Pod의 컨테이너 cgroup에 들어가 보면 다음과 같은 파일들을 확인할 수 있다.
$ cd /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/ \
kubepods-burstable-pod<UID>.slice/ \
cri-containerd-<CID>.scope
$ ls
cgroup.controllers cpu.max cpu.stat cpuset.cpus ...
cgroup.events cpu.max.burst cpu.stat.local cpuset.mems ...
cgroup.procs cpu.pressure cpu.weight memory.current ...
...
cpu.max, cpu.weight, cpu.stat 등 앞서 다룬 파일들이 모두 이 디렉토리에 존재한다. cpu.stat을 읽으면 현재까지의 누적 카운터를 확인할 수 있다.
$ cat cpu.stat
usage_usec 20581
user_usec 11581
system_usec 8999
core_sched.force_idle_usec 0
nr_periods 0
nr_throttled 0
throttled_usec 0
nr_bursts 0
burst_usec 0
이 Pod는 nr_periods와 nr_throttled가 모두 0이다. nr_periods = 0은 bandwidth control이 비활성 상태(cpu.max가 max로 설정)이거나 해당 cgroup에 실행 중인 프로세스가 없었다는 뜻이다. nr_periods는 bandwidth control이 활성화된 상태에서 경과한 총 period 수를 기록하므로, throttling 발생 여부와는 별개다. throttling이 한 번도 발생하지 않았음을 나타내는 것은 nr_throttled = 0이다.
YAML에서 cgroup까지의 경로
K8s에서 CPU request와 limit을 선언하면, kubelet이 Pod spec을 읽어 컨테이너 런타임을 통해 cgroup 파일에 값을 쓰는 방식으로 커널에 전달된다.
Deployment YAML (cpu request/limit)
↓
kubelet (Pod spec 수신)
↓
컨테이너 런타임 (containerd)
↓
cgroup v2 파일에 값 설정
├── request → cpu.weight (상대적 가중치)
└── limit → cpu.max (quota/period)
↓
호스트 커널 CFS bandwidth control 적용
↓
quota 초과 시 throttling 발생
request와 limit은 각각 다른 cgroup 메커니즘으로 매핑된다.
request → cpu.weight: 상대적 가중치
request는 cgroup v2의 cpu.weight로 변환된다. 핵심은 이 값이 CPU 경합이 있을 때만 의미를 가지는 상대적 가중치라는 점이다.
cgroup v2에서 cpu.weight의 범위는 1~10000(기본값 100)이다. kubelet은 내부적으로 request 밀리코어 값을 먼저 cgroup v1의 shares 값으로 변환한 뒤, 이를 다시 v2 weight로 매핑한다.
# 1단계: request → shares (v1 호환 중간값)
shares = request(millicores) × 1024 / 1000
# 2단계: shares → weight (v2)
weight = 1 + ((shares - 2) × 9999) / 262142
예를 들어 1000m request는 shares 1024를 거쳐 weight 약 39로, 500m request는 shares 512를 거쳐 weight 약 20으로 변환된다. 두 컨테이너가 CPU를 두고 경쟁할 때, weight가 높은 컨테이너가 비례적으로 더 많은 CPU 시간을 할당 받는다. 하지만 노드가 유휴 상태이고 CPU 경합이 없다면, 컨테이너는 weight 값과 무관하게 필요한 만큼 CPU를 사용할 수 있다.
참고: cgroup v1 환경에서는
cpu.shares(범위 2~262144)가 직접 사용되며,shares = request(millicores) × 1024 / 1000공식이 최종 값이 된다.
이 가중치 값은 cgroup 계층 구조를 따라 전파된다. 아래 그림은 cgroup v1 기준의 예시로, 괄호 안의 숫자가 각 레벨의 cpu.shares 값이다. cgroup v2에서도 cpu.weight로 동일한 비례 배분 원리가 적용된다.
limit → cpu.max: 절대적 시간 할당량
limit은 CFS bandwidth control의 quota/period로 변환된다.
quota = limit(코어) × period
period = 100,000us (100ms, 고정)
예를 들어, 1000m(1코어) limit은 cpu.max가 100000 100000으로 설정된다. 100ms period마다 100ms의 CPU 시간, 즉 1코어 분량이다. 500m limit이면 50000 100000, 매 100ms마다 50ms만 사용할 수 있다.
request와 달리, limit은 노드에 유휴 CPU가 있더라도 항상 강제된다. 다른 컨테이너가 CPU를 전혀 쓰지 않고 있어도, limit을 초과하면 throttling이 발생한다. 이것이 CPU limit을 안티패턴으로 보는 시각의 핵심 근거다.
정리
| K8s 설정 | 목적 | cgroup v2 매핑 | 동작 방식 |
|---|---|---|---|
requests.cpu |
스케줄링 + 경합 시 최소 보장 | cpu.weight |
상대적 가중치. 경합 시에만 활성화 |
limits.cpu |
최대 사용량 제한 | cpu.max (quota/period) |
절대적 시간 할당량. 항상 활성화, throttling 발생 |
“시끄러운 이웃” 문제와 limit의 역할
시끄러운 이웃(noisy neighbor) 문제란, 동일 노드에서 특정 Pod가 CPU를 과도하게 소비하여 같은 노드의 다른 Pod 성능을 저하시키는 현상이다.
CPU limit이 이 문제를 해결해 줄 것 같지만, 실제로 경합 상황에서 리소스를 공정하게 배분하는 것은 request에 의해 결정되는 cpu.weight다. 모든 Pod에 적절한 request가 설정되어 있다면, CFS 스케줄러는 shares 값에 비례하여 CPU 시간을 분배하고, 특정 Pod가 다른 Pod를 기아 상태에 빠뜨리는 것을 방지한다.
반면 limit은 다른 누구도 CPU를 필요로 하지 않는 상황에서조차 Pod의 사용량을 제한한다. 노드에 유휴 코어가 남아 있어도 quota를 초과하면 강제로 대기해야 한다. 이런 의미에서 limit은 경합 문제를 해결하는 정밀한 도구라기보다, 상한선을 강제하는 무딘 도구에 가깝다.
이전 글에서도 언급했지만, CPU limit을 안티패턴으로 보는 시각이 여기에서 출발한다. request만 적절히 설정하면 CFS가 경합을 해결해 주는데, limit은 오히려 유휴 리소스가 있는 상황에서도 불필요한 throttling을 유발할 수 있기 때문이다.
측정 도구
kubectl top
kubectl top pod은 메트릭 서버가 수집한 CPU 사용량을 보여준다.
kubectl top pod <pod-name>
내부적으로는 kubelet의 cAdvisor가 cgroup usage_usec 값을 읽어, 일정 윈도우(기본 약 15초) 동안의 delta를 계산해 평균 CPU 사용률을 구한다.
CPU 사용률 = (usage_usec_after - usage_usec_before) / (wall_time_after - wall_time_before)
편리하지만 한계가 있다. 샘플링 윈도우와 실제 작업 구간이 정확히 일치하지 않으면, idle 시간이 섞여 부정확한 값이 나올 수 있다. throttling 여부도 알 수 없다.
cpu.stat 직접 읽기
정밀한 분석에는 cpu.stat을 직접 읽는 것이 낫다. 커널이 기록한 정확한 누적값을 볼 수 있고, throttling 정보도 확인할 수 있다.
# 작업 전
cat /sys/fs/cgroup/cpu.stat
# nr_periods 4495
# nr_throttled 3859
# throttled_usec 2189358984
# (작업 실행)
# 작업 후
cat /sys/fs/cgroup/cpu.stat
# nr_periods 4710
# nr_throttled 4067
# throttled_usec 2343860882
# delta 계산
# nr_periods: 4710 - 4495 = 215 (21.5초간 측정)
# nr_throttled: 4067 - 3859 = 208 (208/215 period에서 throttle 발생)
# throttled_usec: 2343860882 - 2189358984 = 154501898us (≈154.5초 대기)
위 예시에서 215개 period 중 208개(96.7%)에서 throttle이 발생했다. 거의 매 period마다 CPU quota를 소진하고 대기했다는 뜻이다.
Prometheus 메트릭
Prometheus를 사용하는 환경이라면 cAdvisor가 노출하는 메트릭으로도 확인할 수 있다.
| 메트릭 | 의미 |
|---|---|
container_cpu_cfs_throttled_periods_total |
throttling이 발생한 period 수 |
container_cpu_cfs_periods_total |
전체 CFS period 수 |
container_cpu_cfs_throttled_seconds_total |
throttling된 총 시간 (초) |
container_cpu_usage_seconds_total |
CPU 사용량 |
이 메트릭들의 원본 데이터가 바로 cpu.stat이다.
정리
지금까지의 내용을 다시 이 문제에 연결하면 다음과 같다.
| 개념 | 이 문제에서의 의미 |
|---|---|
| cgroup | Pod 컨테이너의 CPU 제한이 실제로 적용되는 메커니즘 |
| cpu.max | K8s CPU limit 1000m → 100000 100000 (1코어) |
| cpu.stat | throttling 발생 여부와 정도를 확인하는 수단 |
| 호스트 커널 단일 스케줄링 | ffmpeg 스레드도 호스트 커널이 스케줄링, cgroup quota에 종속 |
| kubectl top의 한계 | 정밀 분석에는 cpu.stat 직접 읽기 필요 |
CPU limit이 cgroup을 통해 어떻게 적용되고, throttling이 어떻게 발생하는지는 알았다. 다음으로 알아야 할 것은 ffmpeg이 내부적으로 CPU를 어떻게 사용하는지다. ffmpeg이 몇 개의 스레드를 만들고, 어떤 방식으로 병렬 처리하는지에 따라 throttling의 양상이 달라지기 때문이다.
YAML에서
cpu: "1000m"이라는 한 줄은, kubelet → 컨테이너 런타임 → cgroupcpu.max→ CFS bandwidth control → throttling이라는 긴 경로를 거쳐 커널 수준의 동작으로 이어진다. 이 경로를 이해하면 리소스 설정을 단순한 숫자가 아닌, 커널 메커니즘에 대한 선언으로 바라볼 수 있다.
참고
이 글을 참조하는 글
- [Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 0. 목격한 상황
- [Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 1. 배경지식: CPU와 스케줄링
- [Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 3. 배경지식: 영상 처리와 FFmpeg
- [Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 4.1. 문제 원인 파악: 현상 관찰
- [Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 4.2. 튜닝 실험 설계
- [Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 5. 결론: CPU Limit을 설정하지 않기로 한 이유

댓글남기기