
[Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 4.2. 튜닝 실험 설계
이전 글에서 CPU throttling이 성능 저하의 직접적 원인임을 정량적으로 확인했다. 이 글에서는 그 과정에서 얻은 인사이트를 정리하고, 이를 바탕으로 튜닝 실험의 방향과 환경을 설계한다.
인사이트
원인은 알고 있었지만, 측정이 필요했다
애초에 CPU limit을 걸어 놓고 느려진 것이니 CPU가 원인이겠거니 짐작은 했다. ffmpeg 프레임 추출이 CPU 집약적 작업이라는 것도 알고 있었다. 하지만 “아마 CPU 때문일 것이다”와 “85%의 period에서 throttling이 발생하고, 대기 시간이 작업 시간의 2배 이상이다”는 전혀 다른 수준의 이해다. 측정 없이는 해결책도 감에 의존하게 된다.
두 가지 튜닝 포인트
| 관찰 | 원인 | 인사이트 |
|---|---|---|
| K8s Pod에서만 37배 느림 | CPU limit 1000m으로 인한 throttling | CPU limit 조절 필요 |
| limit 해제 시 Docker와 동일 성능 | 코어 수가 처리 속도에 직접 영향 | 코어 수 ↔ 처리 속도 상관관계 확인 |
| ffmpeg 기본 스레드 수 = 호스트 코어 수 | 1코어 제한에서 20개 스레드는 경쟁만 증가 | ffmpeg 스레드 수 조절 가능성 |
여기서 두 가지 축이 보인다.
- CPU limit (코어 수): 할당 가능한 CPU 시간의 총량을 결정한다
- ffmpeg
-threads수: 그 시간을 몇 개의 스레드로 나눠 쓸지를 결정한다
ffmpeg 스레드 수 조절에 대한 기대
CPU limit이 있을 때, 스레드 수가 많으면 throttling 오버헤드가 증가한다. 스레드 수를 줄이면 이 오버헤드를 줄일 수 있지 않을까?
예를 들어, CPU 1 core 환경에서:
| 시나리오 | 스레드 수 | 예상 동작 |
|---|---|---|
| A | 20개 (기본값) | 20 스레드가 1코어 경쟁, context switching 오버헤드 높음, throttling 심각 |
| B | 2개 | 2 스레드가 1코어 공유, context switching 오버헤드 낮음, throttling 경쟁 감소 |
기대할 수 있는 개선:
- context switching 비용 감소
- CPU cache 효율성 증가 (캐시 미스 감소)
- 스케줄러 경쟁 감소
다만 이것은 가설이다. 스레드 수를 줄이면 ffmpeg 내부의 파이프라인 병렬성도 함께 줄어들기 때문에, 단순히 “적을수록 좋다”가 아닐 수 있다. 실제로 어떤 조합이 최적인지는 측정해 봐야 한다.
실험 목적
이번 실험의 목적은 최적값을 찾는 것이 아니다. CPU limit과 ffmpeg 스레드 수를 변화시켰을 때 처리 성능이 어떤 양상으로 변하는지, 상관관계와 변화 추이를 파악하는 것이다.
- CPU limit을 늘리면 처리 속도가 선형으로 개선되는가, 아니면 어느 지점에서 수렴하는가?
- 동일한 CPU limit에서 스레드 수를 줄이면 오히려 빨라지는 구간이 있는가?
- CPU limit과 스레드 수의 조합에 따라 throttling 양상이 어떻게 달라지는가?
이런 추이를 파악해야 운영 환경에서 리소스를 결정할 때 근거가 생긴다.
실험 환경
운영 환경에서 하지 않는 이유
운영 환경에서 직접 실험하면 가장 정확하겠지만, 실험 자체가 리소스를 점유하므로 다른 서비스에 영향을 줄 수 있다. CPU limit을 다양하게 변경하며 반복 실험해야 하기 때문에, 별도 서버에서 진행한다.
환경 선정 기준
운영 환경과 완전히 동일한 조건(동일 서버, 동일 파드 배치, 동일 노드 부하)을 재현하기는 현실적으로 어렵다. 다만, 이번 실험의 목적은 절대적인 최적값을 찾는 것이 아니라 CPU limit과 ffmpeg 스레드 수에 따른 변화 추이를 파악하는 것이므로, CPU 코어 수만 동일한 서버에서 진행해도 추이 자체는 크게 달라지지 않을 것으로 판단했다.
실험 서버 사양
| 항목 | 실험 서버 | 운영 환경 노드 (참고) |
|---|---|---|
| CPU | Intel Core i7-12700F | Intel Core i9-7900X @ 3.30GHz |
| 코어 | 12코어 20스레드 | 10코어 20스레드 |
| CPU(s) | 20 | 20 |
| L1d / L1i | 512 KiB / 512 KiB | 320 KiB / 320 KiB |
| L2 | 12 MiB | 10 MiB |
| L3 | 25 MiB | 13.8 MiB |
| NUMA | 1 node | 1 node |
두 서버 모두 CPU(s) = 20으로 동일하다. ffmpeg이 스레드 수를 결정할 때 참조하는 값이 이것이므로, 기본 동작은 동일한 조건이다. CPU 세대와 캐시 크기가 다르기 때문에 절대 수치(초)는 차이가 있겠지만, CPU limit / 스레드 수에 따른 변화 추이를 관찰하기에는 충분하다.
실험 설계
변수
| 변수 | 설명 |
|---|---|
| CPU limit | cgroup으로 제한하는 코어 수. 다양한 값을 시도하며 추이 확인 |
ffmpeg -threads |
ffmpeg이 사용하는 스레드 수. CPU limit과의 조합으로 변화 관찰 |
구체적인 범위와 조합은 실험을 진행하면서, 앞선 결과를 보고 의미 있는 구간을 좁혀 나가는 방식으로 결정했다.
측정 항목
| 측정 항목 | 수단 | 확인하려는 것 |
|---|---|---|
| 처리 시간 (real) | time 명령 |
벽시계 기준 전체 소요 시간 |
| ffmpeg speed, fps | ffmpeg stat 출력 | 처리 효율 |
| CPU 시간 분포 | time (user, sys) |
워크로드 특성 변화 |
| throttling | cpu.stat |
nr_throttled, throttled_usec 변화 |
실험 방법
각 CPU limit / threads 조합에 대해 동일한 영상으로 ffmpeg 프레임 추출을 수행하고 위 항목들을 측정한다. 조합 수가 많으므로, 먼저 CPU limit만 변화시키며 전체 추이를 확인한 후, 의미 있는 구간에서 threads를 조절하는 순서로 진행한다.
모니터링 대시보드
셸 스크립트를 넘어서
이전 글에서는 watch -n 1 cat /sys/fs/cgroup/cpu.stat으로 before/after 스냅샷을 찍어 throttling을 확인했다. 문제를 진단하는 데는 충분했지만, 튜닝 실험에서는 변화의 추이를 시계열로 봐야 한다. CPU limit이나 스레드 수를 바꿨을 때 throttling이 어떻게 변하는지, 요청 처리 구간에서 어떤 패턴이 나타나는지를 연속적으로 관찰하려면 스냅샷만으로는 한계가 있다.
그래서 Prometheus 메트릭 기반의 Grafana 대시보드를 구성하기로 했다. 먼저 Grafana 커뮤니티 대시보드에서 사용할 수 있는 것이 있는지 찾아봤는데, CPU throttling 전용 대시보드(Container CPU Throttling Dashboard 등)가 있긴 했지만, 지금 필요한 것과는 맞지 않았다. 다른 것들도 마땅히 적절한 것을 찾지 못했다.
실험 특성 상, 특정 Pod의 throttling 비율, CPU usage vs limit의 역설, 메모리 배제까지 한 화면에서 봐야 했기 때문에 직접 구성하기로 했다. 한편으로는 실험 도구이기도 하지만, 이후 운영 환경에서도 CPU throttling을 상시 모니터링할 수 있는 기반이 되기를 기대했다.
수집 메트릭
Prometheus가 cAdvisor를 통해 수집하는 컨테이너 CPU 메트릭 중, throttling 분석에 필요한 것들이다.
| 메트릭 | 설명 |
|---|---|
container_cpu_cfs_periods_total |
전체 CFS period 수 (누적) |
container_cpu_cfs_throttled_periods_total |
throttling이 발생한 period 수 (누적) |
container_cpu_cfs_throttled_seconds_total |
throttling된 총 시간, 초 단위 (누적) |
container_cpu_usage_seconds_total |
CPU 사용량, 초 단위 (누적) |
kube_pod_container_resource_limits |
Pod에 설정된 resource limit |
kube_pod_container_resource_requests |
Pod에 설정된 resource request |
이 메트릭들은 모두 누적 카운터다. rate() 함수로 시간당 변화율을 구해야 의미 있는 시계열이 된다.
대시보드 구성
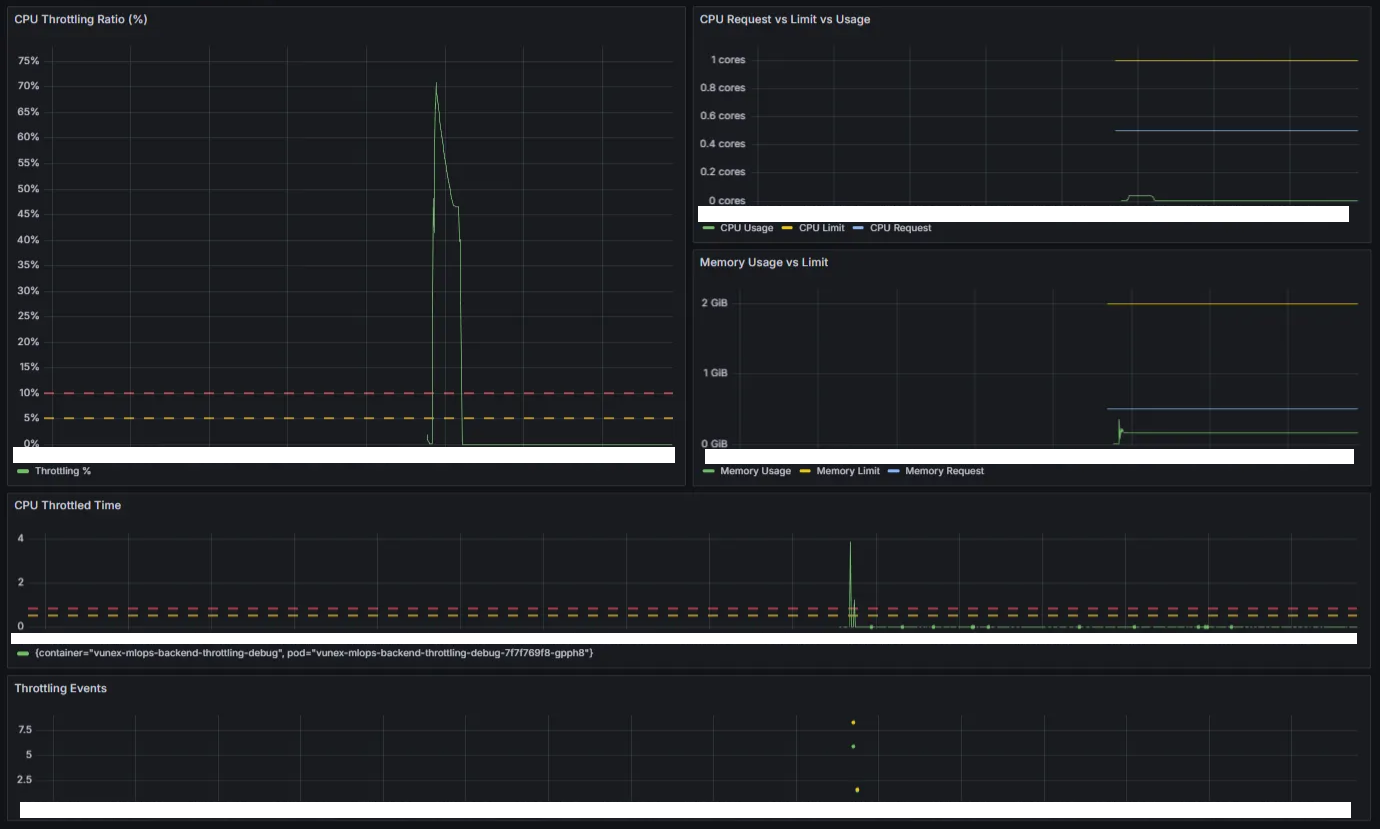
대략 아래와 같은 구성으로 만들었다.
┌───────────────────────┬───────────────────────┐
│ 1. CPU Throttling │ 2. CPU Request │
│ Ratio (%) │ vs Limit vs Usage │
│ ├───────────────────────┤
│ │ 3. Memory Usage │
│ │ vs Limit │
├───────────────────────┴───────────────────────┤
│ 4. CPU Throttled Time │
├───────────────────────────────────────────────┤
│ 5. Throttling Events │
└───────────────────────────────────────────────┘
각 패널이 담당하는 역할이 다르다.
1. CPU Throttling Ratio (%): 문제의 심각도
전체 CFS period 중 throttling이 발생한 비율이다.
# A: throttled periods rate
sum(rate(container_cpu_cfs_throttled_periods_total{
pod=~"<pod>.*", namespace="<ns>",
container!="POD", container=~".+"
}[$interval]))
# B: total periods rate
sum(rate(container_cpu_cfs_periods_total{
pod=~"<pod>.*", namespace="<ns>",
container!="POD", container=~".+"
}[$interval]))
# C: 비율 계산 (Grafana Expression)
$A / $B * 100
임계값을 두 단계로 설정했다.
| 구간 | 의미 |
|---|---|
| 0~5% | 정상. 간헐적 burst에 의한 것으로 무시 가능 |
| 5~10% (노란 점선) | 주의. 지속되면 성능 영향 가능 |
| 10%+ (빨간 점선) | 문제. CPU limit 재검토 필요 |
대시보드에서 영상 처리 요청 시 ~70%까지 치솟는 것이 보인다. period 10번 중 7번이 throttling되고 있다는 뜻이다.
2. CPU Request vs Limit vs Usage: 역설적 상황
# CPU Usage (cores)
sum(rate(container_cpu_usage_seconds_total{
pod=~"<pod>.*", namespace="<ns>",
container!="POD", container=~".+"
}[$interval]))
# CPU Limit
max(kube_pod_container_resource_limits{
pod=~"<pod>.*", namespace="<ns>", resource="cpu"
})
# CPU Request
max(kube_pod_container_resource_requests{
pod=~"<pod>.*", namespace="<ns>", resource="cpu"
})
CPU 사용량(Usage), limit, request를 한 그래프에 겹쳐 표시한다.
여기서 역설적인 상황이 드러난다. limit은 1코어인데 Usage는 ~0.5코어 수준이다. 일반적인 CPU 사용률 관점에서 보면 “여유가 있다”고 오해할 수 있다. 하지만 이것은 여유가 있는 게 아니라, throttling으로 막혀서 더 쓰지 못하는 것이다. 배경지식에서 다룬 것처럼, cpu.stat의 usage_usec은 실제로 CPU를 사용한 시간만 집계하고 throttling 대기 시간은 포함하지 않기 때문이다.
이 패널을 보면서, 전통적인 CPU 사용률 모니터링만으로는 throttling 문제를 놓칠 수 있다는 것을 실감했다. “CPU 50%밖에 안 쓰는데 왜 느리지?”라는 질문에 대한 답이 여기에 있다.
3. Memory Usage vs Limit: 다른 원인 배제
# Memory Usage (GiB)
sum(container_memory_working_set_bytes{
pod=~"<pod>.*", namespace="<ns>",
container!="POD", container=~".+"
}) / 1024 / 1024 / 1024
# Memory Limit (GiB)
max(kube_pod_container_resource_limits{
pod=~"<pod>.*", namespace="<ns>", resource="memory"
}) / 1024 / 1024 / 1024
# Memory Request (GiB)
max(kube_pod_container_resource_requests{
pod=~"<pod>.*", namespace="<ns>", resource="memory"
}) / 1024 / 1024 / 1024
메모리 사용량, limit, request를 표시한다. 이 패널의 목적은 메모리가 문제가 아님을 확인하는 것이다. 메모리 사용량이 limit에 근접하지 않고 안정적이라면, OOMKill이나 메모리 압박은 원인에서 배제할 수 있다.
4. CPU Throttled Time
# Throttled seconds per second
sum by(container, pod) (rate(container_cpu_cfs_throttled_seconds_total{
pod=~"<pod>.*", namespace="<ns>",
container!="POD", container=~".+"
}[1m]))
container_cpu_cfs_throttled_seconds_total의 변화율로, 초당 몇 초가 throttling되었는지를 나타낸다.
| 값 | 해석 |
|---|---|
| 0.5 s/s (노란 점선) | 초당 0.5초 대기. 50% throttling |
| 0.8 s/s (빨간 점선) | 초당 0.8초 대기. 80% throttling |
대시보드에서 요청 처리 시 3~4 s/s까지 치솟는 것이 관찰된다.
다만, 솔직히 이 지표는 직관적이지 않다. 여러 코어에서 동시에 throttling된 시간이 합산되기 때문에 값이 1을 넘을 수 있고, 스레드 수에 따라 같은 throttling 상황에서도 수치가 달라진다. throttling의 심각도를 판단하는 데는 패널 1(Throttling Ratio %)이 훨씬 직관적이다. 이 패널은 동일 조건에서 실험 간 상대 비교(CPU limit이나 threads를 바꾸기 전 vs 후)에 참고하는 정도로 활용했다.
5. Throttling Events: 발생 시점
# 패널 쿼리: throttled periods rate > 0
rate(container_cpu_cfs_throttled_periods_total{
pod=~"<pod>.*", namespace="<ns>"
}[1m]) > 0
# Annotation 쿼리: 1분 내 카운터 변화 감지
changes(container_cpu_cfs_throttled_periods_total{
pod=~"<pod>.*", namespace="<ns>"
}[1m]) > 0
container_cpu_cfs_throttled_periods_total 카운터의 변화를 감지하여, throttling이 발생한 시점을 표시한다. Annotation으로도 같은 쿼리를 설정하여, 다른 패널의 그래프 위에 throttling 발생 시점을 빨간 마커로 겹쳐 볼 수 있게 했다.
다만, throttling이 발생했다는 것과 그것이 문제가 되는 수준인지는 별개다. 간헐적인 burst에 의한 소량의 throttling은 대부분 무시해도 되므로, 실제 대응 판단은 패널 1의 비율을 기준으로 한다.
참고: 대응 판단
위에서 대응 판단은 패널 1의 비율을 기준으로 한다고 했는데, alert를 설정한다면 마찬가지다. Throttling Ratio(%)는
throttled_periods / total_periods이므로, 스레드 수나 코어 수가 달라져도 “period 몇 번 중 몇 번 throttling이 걸렸는가”라는 일관된 의미를 가진다. 반면 Throttled Time(s/s)은 여러 코어의 대기 시간을 합산한 값이기 때문에, 스레드 수가 바뀌면 같은 throttling 비율이어도 수치가 완전히 달라져 임계값을 고정하기 어렵다. 일반적으로 Throttling Ratio 25% 이상이면 CPU limit 재검토가 필요하다고 본다.
대시보드에서 읽을 수 있는 것
이 대시보드를 통해 셸 스크립트 측정만으로는 보기 어려운 것들을 확인할 수 있다.
- 시간축 위의 패턴: 요청이 들어오는 순간 throttling이 급증하고, 처리가 끝나면 0으로 돌아오는 패턴
- 지표 간 상관관계: throttling ratio가 치솟는 구간에서 CPU Usage가 오히려 낮게 보이는 역설
- 실험 간 비교: CPU limit이나 threads를 변경한 뒤 같은 대시보드로 변화를 비교
튜닝 실험에서는 조합을 변경할 때마다 이 대시보드를 통해 throttling 양상의 변화를 관찰한다.
다음 글에서
실제 튜닝 실험 결과를 정리한다.

댓글남기기