
[Kubernetes] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 4.3. 튜닝 실험: CPU Limit 관찰
이전 글에서 튜닝 실험의 방향과 환경을 설계했다. 이 글에서는 첫 번째 변수인 CPU limit을 변화시키며 처리 성능과 throttling 양상이 어떻게 달라지는지 관찰한다.
실험 방법
매 실험마다 세 가지를 동시에 실행한다.
터미널 1: 모니터링 스크립트 (kubectl top + cpu.stat 실시간 기록)
터미널 2: 요청 실행 (time curl)
브라우저: Grafana 대시보드 실시간 관찰 + 스크린샷
모니터링 스크립트
1초 간격으로 kubectl top, cpu.stat, cpu.max를 수집하여 로그 파일에 기록한다.
#!/bin/bash
# monitor_cpu.sh
LABEL="${1:-app=<app-label>}"
NAMESPACE="${2:-<namespace>}"
INTERVAL="${3:-1}"
OUTPUT_DIR="${4:-.}"
POD_NAME=$(kubectl get pod -n "$NAMESPACE" -l "$LABEL" \
-o jsonpath='{.items[0].metadata.name}' 2>/dev/null)
if [ -z "$POD_NAME" ]; then
echo "Error: No pod found with label '$LABEL' in namespace '$NAMESPACE'"
exit 1
fi
mkdir -p "$OUTPUT_DIR"
LOG_FILE="${OUTPUT_DIR}/cpu_monitor_$(date +%Y%m%d_%H%M%S).log"
echo "=== CPU Monitoring Started ===" | tee "$LOG_FILE"
echo "Pod: $POD_NAME" | tee -a "$LOG_FILE"
echo "Namespace: $NAMESPACE" | tee -a "$LOG_FILE"
echo "Interval: ${INTERVAL}s" | tee -a "$LOG_FILE"
echo "Log file: $LOG_FILE" | tee -a "$LOG_FILE"
echo "===============================" | tee -a "$LOG_FILE"
while true; do
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S.%3N')
echo "--- $TIMESTAMP ---" | tee -a "$LOG_FILE"
echo "[kubectl top]" | tee -a "$LOG_FILE"
kubectl top pod "$POD_NAME" -n "$NAMESPACE" --containers 2>/dev/null \
| tee -a "$LOG_FILE"
echo "[cgroup cpu.stat]" | tee -a "$LOG_FILE"
kubectl exec "$POD_NAME" -n "$NAMESPACE" \
-- cat /sys/fs/cgroup/cpu.stat 2>/dev/null | tee -a "$LOG_FILE"
echo "[cgroup cpu.max]" | tee -a "$LOG_FILE"
kubectl exec "$POD_NAME" -n "$NAMESPACE" \
-- cat /sys/fs/cgroup/cpu.max 2>/dev/null | tee -a "$LOG_FILE"
echo "" | tee -a "$LOG_FILE"
sleep "$INTERVAL"
done
매 초마다 다음 세 가지를 기록한다.
| 항목 | 수단 | 확인하려는 것 |
|---|---|---|
| CPU 사용량 | kubectl top pod --containers |
메트릭 서버 기준 사용량 |
| throttling 상태 | cpu.stat (usage_usec, nr_throttled, throttled_usec) |
실시간 throttling 누적값 |
| limit 설정 | cpu.max |
현재 적용된 quota/period 확인 |
요청
다른 터미널에서 동일한 영상으로 API 요청을 보낸다.
time curl -X 'POST' \
'http://<node-ip>:<port>/api/train/manual/init' \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-F 'model_name=test' \
-F 'video=@video.mp4;type=video/mp4'
time으로 감싸서 벽시계 시간(real), CPU 시간(user, sys)을 함께 측정한다.
실험 1: CPU limit 전체 구간 탐색
목적
CPU limit을 단계적으로 상향하면서, 처리 시간과 throttling이 어떤 추이로 변하는지 전체 구간을 탐색한다. 선형적으로 개선되는지, 어느 지점에서 수렴하는지, 예상과 다른 구간은 없는지를 확인한다.
참고: baseline 변화
실험 환경이 운영 환경과 다른 서버이기 때문에, baseline 자체가 달라졌다. 운영 환경에서 1000m일 때 148초였던 처리 시간이, 실험 서버에서는 70초로 측정되었다.
- 다른 워크로드의 간섭이 없음 (전용 실험 서버)
- CPU 아키텍처, 캐시, 메모리 대역폭 등의 차이 (i9-7900X vs i7-12700F)
이전 글에서 환경을 선정할 때부터 감안했던 부분이다. 중요한 것은 절대값이 아니라 CPU limit 변화에 따른 상대적 개선율과 추이이므로, 이 차이는 실험 목적에는 영향을 주지 않는다.
결과
CPU limit을 1000m부터 unlimited까지 단계적으로 상향하며 측정했다. ffmpeg -threads는 모두 auto(미지정)다.
| CPU Limit | 실제 소요 시간 | 이전 대비 | 누적 개선율 (vs 1000m) |
|---|---|---|---|
| 1000m (1 core) | 70.49초 | - | baseline |
| 1500m (1.5 core) | 40.03초 | 43.2% ↓ | 43.2% ↓ |
| 2000m (2 core) | 28.50초 | 28.8% ↓ | 59.6% ↓ |
| 3000m (3 core) | 22.14초 | 22.3% ↓ | 68.6% ↓ |
| 4000m (4 core) | 22.07초 | 0.3% ↓ | 68.7% ↓ |
| 5000m (5 core) | 23.82초 | 7.9% ↑ | 66.2% ↓ |
| 6000m (6 core) | 27.45초 | 15.2% ↑ | 61.1% ↓ |
| 8000m (8 core) | 20.37초 | 25.8% ↓ | 71.1% ↓ |
| 12000m (12 core) | 3.85초 | 81.1% ↓ | 94.5% ↓ |
| 16000m (16 core) | 3.92초 | 1.8% ↑ | 94.4% ↓ |
| unlimited | 3.63초 | 7.4% ↓ | 94.8% ↓ |
Grafana 대시보드
전체 실험 구간의 대시보드 스크린샷이다. CPU limit을 단계적으로 상향할 때마다 Pod을 재배포했으며, 각 실험마다 동일한 요청을 보냈다.
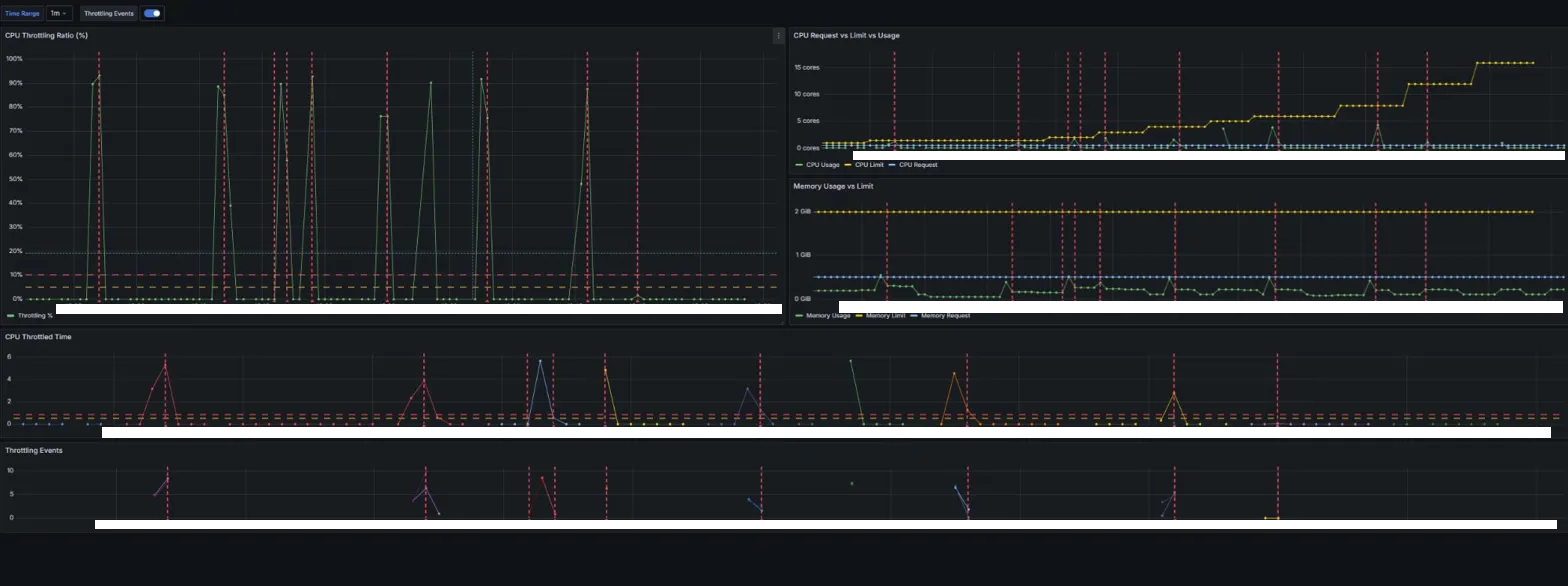
왼쪽에서 오른쪽으로 갈수록 CPU limit이 증가한다. 대시보드에서 읽을 수 있는 것을 자세히 확인해 보자:
- CPU Throttling Ratio (좌상): 초반(1000m~2000m)에는 요청마다 거의 100%까지 치솟지만, limit을 올릴수록 스파이크가 줄어든다. 12000m 이후에는 throttling이 거의 관찰되지 않는다.
- CPU Request vs Limit vs Usage (우상): limit 선(노란색)이 계단식으로 올라가는 것이 보인다. 초반에는 Usage가 limit에 막혀 있다가, limit이 충분해지면 Usage가 자유롭게 올라간다. unlimited 설정 시에는 limit 선 자체가 사라진다. 한 가지 의아할 수 있는 점은, limit을 올려도 Usage가 limit보다 한참 낮게 보인다는 것이다. 예를 들어 limit이 4 core인데 Usage가 2 core 수준에 머문다. 이전 글에서 다룬 1 core일 때의 역설과 같은 현상인데, 원인은 두 가지다.
- 첫째,
container_cpu_usage_seconds_total은 실제로 CPU를 사용한 시간만 집계하고 throttling 대기 시간은 포함하지 않는다. - 둘째, 이 실험에서 ffmpeg
-threads auto는 호스트 코어 수(20)를 기준으로 스레드를 생성하기 때문에, limit을 올려도 20개 스레드가 늘어난 quota를 순식간에 소진하고 나머지 시간을 대기하는 burst-then-idle 패턴이 반복된다. 이 패턴이 Prometheusrate()윈도우 안에서 평균화되면서 Usage가 낮게 뭉개져 보이는 것이다. - 따라서 Usage만 보고 “여유가 있다”고 판단하면 안 되고, 실제 throttling 심각도는 좌상단의 Throttling Ratio 패널로 확인해야 한다.
- 첫째,
- Memory Usage vs Limit (우중): 전체 구간에 걸쳐 안정적이다. 메모리는 이 실험의 변수가 아님을 확인할 수 있다.
- CPU Throttled Time (하단 1): Throttling Ratio와 유사한 패턴이지만, 값의 절대 크기가 limit 구간에 따라 달라진다. 앞서 언급한 것처럼 상대 비교 용도로 참고한다.
- Throttling Events (하단 2): 빨간 Annotation 마커가 초반 실험에 집중되어 있고, 후반으로 갈수록 사라진다.
분석
구간별 패턴
결과를 보면 “코어를 늘리면 선형적으로 빨라진다”는 단순한 기대와는 다른, 계단식 패턴이 나타난다.
Time
70s |# 1000m
|
40s | # 1500m
|
28s | # 2000m
22s | ## 3000m, 4000m
24s | # 5000m <-- worse
27s | # 6000m <-- worse
20s | # 8000m
|
4s | ### 12000m, 16000m, unlimited
+---------------------------------------> CPU Limit
이 패턴을 5개 구간으로 나눌 수 있다.
Phase 1: 1000m → 2000m — 선형 개선
CPU가 명확한 병목인 구간이다. 코어를 2배로 늘리면 처리 시간이 59.6% 감소한다. 이 구간에서는 코어를 추가할수록 throttling이 직접적으로 줄어들며, 그만큼 처리 시간이 단축된다.
Phase 2: 2000m → 4000m — throttling 제거, 미미한 개선
3000m부터 throttling이 급격히 감소하고, 4000m에서 거의 사라진다. 하지만 처리 시간은 22초 근방에서 정체된다. throttling은 해소되었지만, 이제는 ffmpeg 내부의 병렬화 효율이 병목으로 넘어간 것으로 보인다.
Phase 3: 4000m → 8000m — 정체와 역전 (Dead Zone)
가장 흥미로운 구간이다. 코어를 늘렸는데 오히려 성능이 악화된다.
| CPU Limit | 처리 시간 | 변화 |
|---|---|---|
| 4000m | 22.07초 | - |
| 5000m | 23.82초 | +1.75초 (악화) |
| 6000m | 27.45초 | +5.38초 (더 악화) |
| 8000m | 20.37초 | -7.08초 (회복) |
가능한 원인:
- ffmpeg
-threads auto의 비효율적 스레드 수 선택: 이 구간에서 ffmpeg이 코어 수를 참조하여 스레드 수를 결정하는 과정에서 비효율적인 값을 선택했을 가능성 - context switching + 동기화 오버헤드: 스레드 수가 증가하면서 이득보다 손해가 커지는 구간
- 실험 노이즈: 특정 실험 시점에 노드의 다른 부하가 있었을 가능성
이 구간은 재현 가능한 현상인지 확인이 필요하다. 실험 2에서 다룬다.
Phase 4: 8000m → 12000m — 극적 개선
20초에서 4초로, 81.1% 감소하는 극적인 개선이 나타난다. 12코어가 제공되면서 ffmpeg의 frame-level parallelism이 본격적으로 작동하고, 디코딩/스케일링/인코딩/I/O가 완전히 파이프라인화된 것으로 추정된다.
Phase 5: 12000m → unlimited — Plateau
12코어 이후로는 코어를 더 추가해도 유의미한 개선이 없다. 3.85초 → 3.63초로, ffmpeg 병렬 처리의 상한선에 도달한 것이다.
ffmpeg -threads auto 동작 추정
| CPU Limit | 추정 동작 | 병렬화 효율 |
|---|---|---|
| 1000m ~ 2000m | CPU 부족, 소수 스레드도 throttling | 낮음 (CPU 병목) |
| 3000m ~ 4000m | throttling 해소, 내부 병렬화가 병목 | 중간 |
| 5000m ~ 6000m | 스레드 수 증가로 오버헤드 > 이득? | 비효율적 |
| 8000m | 오버헤드와 이득의 균형 | 중간 |
| 12000m+ | 충분한 코어로 완전 병렬화 달성 | 최적 |
이 추정을 검증하려면 -threads 수를 직접 지정하는 실험이 필요하다. 이는 이후 글에서 다룬다.
실험 2: Dead Zone 재현
배경
실험 1에서 4000m → 8000m 구간에서 성능이 오히려 악화되는 현상이 관찰되었다. 코어를 늘렸는데 느려진다는 것은 직관에 어긋난다. 이것이 재현 가능한 현상인지, 실험 도중의 노이즈(이전 요청의 잔여 효과, 노드 부하 등)였는지를 확인한다.
실험 1과 달리, 자원 설정 변경과 요청 사이에 충분한 시간을 두고 진행했다. 7000m도 추가하여 더 세밀하게 관찰했다.
결과
| CPU Limit | 실제 소요 시간 | 이전 대비 | 누적 (vs 4000m) |
|---|---|---|---|
| 4000m | 18.78초 | - | baseline |
| 5000m | 22.09초 | 17.6% ↑ (악화) | 17.6% ↑ |
| 6000m | 27.21초 | 23.2% ↑ (악화) | 44.9% ↑ |
| 7000m | 29.22초 | 7.4% ↑ (악화) | 55.6% ↑ |
| 8000m | 20.46초 | 30.0% ↓ (개선) | 9.0% ↑ |
4000m에서 7000m까지 코어를 늘릴수록 일관되게 느려지고, 8000m에서 회복되는 U자형 곡선이 나타났다.
Time
30s | * 7000m (worst)
| * 6000m
25s | * 5000m
|
20s | * * 8000m
| 4000m
+-------------------------------> CPU Limit
4k 5k 6k 7k 8k
재현성 확인: 실험 1의 결과(4000m: 22.07초, 5000m: 23.82초, 6000m: 27.45초, 8000m: 20.37초)와 동일한 패턴이다. 실험 노이즈가 아님이 확인되었다.
Grafana 대시보드

왼쪽에서 오른쪽으로 4000m → 5000m → 6000m → 7000m → 8000m 순서다. 각 실험 사이에 충분한 간격을 두었다.
- CPU Throttling Ratio (좌상): 모든 구간에서 80~100%의 높은 throttling이 발생한다. CPU limit을 늘렸는데도 throttling이 줄지 않는다는 것은, ffmpeg이 더 많은 스레드를 생성하여 늘어난 quota를 즉시 소진하고 있다는 의미다.
- CPU Request vs Limit vs Usage (우상): limit 선(노란색)이 계단식으로 올라갈 때마다 Usage(초록색)도 따라 올라간다. 코어를 줘도 줘도 바로 채워 쓰고, 그래도 부족하여 throttling이 발생하는 상황이다.
- Memory Usage vs Limit (우중): 5000m~7000m 구간에서 메모리 사용량이 소폭 증가하는 것이 관찰된다. 스레드 수 증가에 따른 버퍼/캐시 증가로 추정된다.
- CPU Throttled Time (하단 1): 5000m(14:24 부근)에서 스파이크가 가장 높게 치솟는다. 이후 6000m, 7000m에서도 지속적으로 높다.
limit을 늘려도 throttling이 발생하는 이유
대시보드를 보면 흥미로운 점이 있다. 4000m이든 8000m이든, limit을 늘려도 throttling ratio가 80~100%로 여전히 높다. limit을 충분히 주면 throttling이 사라질 것 같지만, 그렇지 않다.
이유는 CFS bandwidth control의 period 단위 정산 방식 때문이다. 예를 들어 4000m(4 core)이면:
cpu.cfs_period_us = 100,000 (100ms)
cpu.cfs_quota_us = 400,000 (4 cores x 100ms)
매 100ms period마다 400ms의 CPU 시간을 사용할 수 있다. 평균적으로 4 core를 쓰는 것과 같다. 하지만 ffmpeg은 CPU를 균일하게 쓰지 않는다.
[Decode burst] → 순간적으로 4+ core 사용 시도 → quota 초과 → throttling
[Scale/Encode] → 다시 burst → throttling
[I/O write] → CPU 사용 감소 → quota 여유
실제로 cpu.stat을 확인하면, 4000m + 4 threads에서도 throttling ratio가 97%에 달한다.
# 4000m, threads=4 실행 구간의 cpu.stat delta
nr_periods: 239
nr_throttled: 232
ratio: 232 / 239 = 97.1%
period의 거의 매 번에서 quota를 초과한다. 이는 ffmpeg의 디코딩/인코딩 과정이 burst 패턴으로 CPU를 사용하기 때문이다. 100ms라는 period 안에서 순간적으로 limit 이상의 CPU를 사용하려 하면, 남은 시간은 강제 대기해야 한다.
처음에는 “limit = threads로 맞추면 throttling이 사라지겠지”라고 기대했는데, 실제로는 그렇지 않았다. throttling 자체는 CFS의 period 기반 정산 방식에서 발생하는 것이고, 중요한 것은 throttling의 유무가 아니라 처리 시간이 개선되었는가였다.
분석
핵심: -threads auto가 만드는 비효율
이 구간의 핵심은 CPU limit을 늘릴수록 ffmpeg이 더 많은 스레드를 만들고, 그것이 오히려 역효과를 낸다는 것이다.
| CPU Limit | 추정 스레드 수 | 결과 |
|---|---|---|
| 4000m (4 core) | 적정 수준 | 18.78초 (최적) |
| 5000m (5 core) | 증가 | 22.09초 (악화 시작) |
| 6000m (6 core) | 더 증가 | 27.21초 (악화) |
| 7000m (7 core) | 더 증가 | 29.22초 (최악) |
| 8000m (8 core) | 임계치 돌파 | 20.46초 (회복) |
코어를 더 주면 ffmpeg -threads auto가 더 많은 스레드를 만든다. 스레드가 늘어나면:
- context switching 오버헤드 증가: 스레드 간 전환 비용이 커진다
- CPU cache 효율 저하: 스레드가 많아질수록 L1/L2 캐시 미스율이 증가한다
- 동기화 오버헤드 증가: ffmpeg 내부의 frame-level parallelism에서 스레드 간 동기화 포인트의 대기 시간이 늘어난다
5000m~7000m 구간에서는 이러한 오버헤드가 코어 추가로 얻는 이득을 초과한다. 8000m에서 회복되는 것은, 코어가 충분해져서 오버헤드를 상쇄하고도 남는 시점에 도달했기 때문으로 추정된다.
Dead Zone의 의미
이 결과는 실무적으로 중요한 시사점을 준다.
- “코어를 늘리면 빨라진다”는 가정은 틀릴 수 있다. 특히
-threads auto처럼 런타임이 스레드 수를 자동으로 결정하는 경우, 코어 증가가 오히려 독이 되는 구간이 존재한다. - 리소스 비용 관점에서도 손해다. 4000m(4코어)이 7000m(7코어)보다 빠르다면, 7코어를 할당하는 것은 비용만 늘리고 성능은 악화시키는 셈이다.
-threads수를 직접 지정하면 이 Dead Zone을 회피할 수 있을 가능성이 있다. 이는 다음 실험에서 검증한다.
정리
두 실험을 통해 확인한 것:
- CPU limit 증가는 비선형적 개선을 보인다. 선형 개선(1~2코어), 정체(3~4코어), 역전(5~7코어), 극적 개선(12코어), 수렴(12코어+)의 계단식 패턴이 나타난다.
- 5000m~7000m 구간에 Dead Zone이 존재한다. 코어를 늘렸는데 오히려 느려지는 현상이 재현 가능하다. 원인은
-threads auto의 비효율적 스레드 수 선택으로 추정된다. - 12코어 이상에서 ffmpeg 병렬 처리의 상한선에 도달한다. 이후 코어를 추가해도 유의미한 개선이 없다.
여기서 자연스러운 질문이 나온다. Dead Zone이 -threads auto 때문이라면, 스레드 수를 직접 지정하면 어떻게 될까? 다음 글에서는 CPU limit과 -threads 수를 조합하여 실험한다.
CPU limit만 조절하면 될 줄 알았는데, 오히려 “코어를 줄수록 느려지는” 구간이 있다는 건 예상 밖이었다.
-threads auto라는 편리한 기본값 뒤에 이런 함정이 숨어 있을 줄은 몰랐다.

댓글남기기