
[Dev] Pod CPU Limit과 FFmpeg Thread 최적 조정 - 4.4. 튜닝 실험: FFmpeg Thread 수 관찰
이전 글에서 CPU limit만 변화시켰을 때의 추이를 확인했다. 특히 5000m~7000m 구간의 Dead Zone은 -threads auto가 비효율적인 스레드 수를 선택하기 때문이라고 추정했다.
이번에는 두 번째 변수인 ffmpeg -threads 수를 직접 제어한다. CPU limit이 고정된 상황에서, 스레드 수를 조절하면 throttling 오버헤드를 줄일 수 있지 않을까?
아이디어
CPU limit으로 인해 throttling이 발생한다면, 스레드 수를 CPU limit 이내로 맞추면 불필요한 경쟁 없이 quota를 효율적으로 사용할 수 있지 않을까?
Scenario A: CPU 1 core + 20 threads (auto)
- 20 threads compete for 1 core quota
- Context switching overhead: high
- Throttling: severe
- Expected: inefficient
Scenario B: CPU 1 core + 2 threads
- 2 threads share 1 core quota
- Context switching overhead: low
- CPU cache efficiency: high
- Expected: potentially better than A
실험 방법
이전 글과 동일하게 모니터링 스크립트 + Grafana 대시보드를 병행했다. 차이점은 API 요청이 아니라 Pod 내부에서 직접 ffmpeg 명령을 실행하여 -threads 옵션을 제어한 것이다.
#!/bin/bash
# exec-ffmpeg-in-a-pod.sh
NAMESPACE="<namespace>"
APP_LABEL="<app-label>"
THREADS=${1:-4}
POD_NAME=$(kubectl get pod -n $NAMESPACE -l app=$APP_LABEL \
-o jsonpath='{.items[0].metadata.name}')
CPU_LIMIT=$(kubectl get pod $POD_NAME -n $NAMESPACE \
-o jsonpath='{.spec.containers[0].resources.limits.cpu}')
echo "Pod: $POD_NAME"
echo "Input Threads: $THREADS"
echo "CPU Limit: $CPU_LIMIT"
echo "Starting experiment..."
echo "================================"
kubectl exec -n $NAMESPACE $POD_NAME -- bash -c "
time ffmpeg \
-loglevel error \
-threads $THREADS \
-i /data/video.mp4 \
-filter_complex [0]scale=1280:720[s0] \
-map [s0] \
-q:v 2 \
-fps_mode vfr \
-pix_fmt yuv420p \
/data/frames/frame_%06d.jpg \
-y
"
CPU limit은 kubectl set resources로 변경하고, 스레드 수는 스크립트의 인자로 전달한다. API 요청 경로가 아닌 Pod 내부 직접 실행이라는 한계가 있지만, 목적은 절대 수치가 아니라 변화 양상 파악이므로 충분하다.
실험 1: CPU Limit = Thread 수 (선형 확장 검증)
목적
CPU limit과 ffmpeg -threads 수를 동일하게 맞춰서 1부터 16까지 증가시킨다. 이 조합에서 성능이 선형적으로 향상되는지 확인한다. 만약 그렇다면, 이전 실험의 Dead Zone이 -threads auto의 문제임이 확증된다.
부수적으로, 일부 구간에서 over-subscription(threads > limit)도 시도하여 효과를 확인했다.
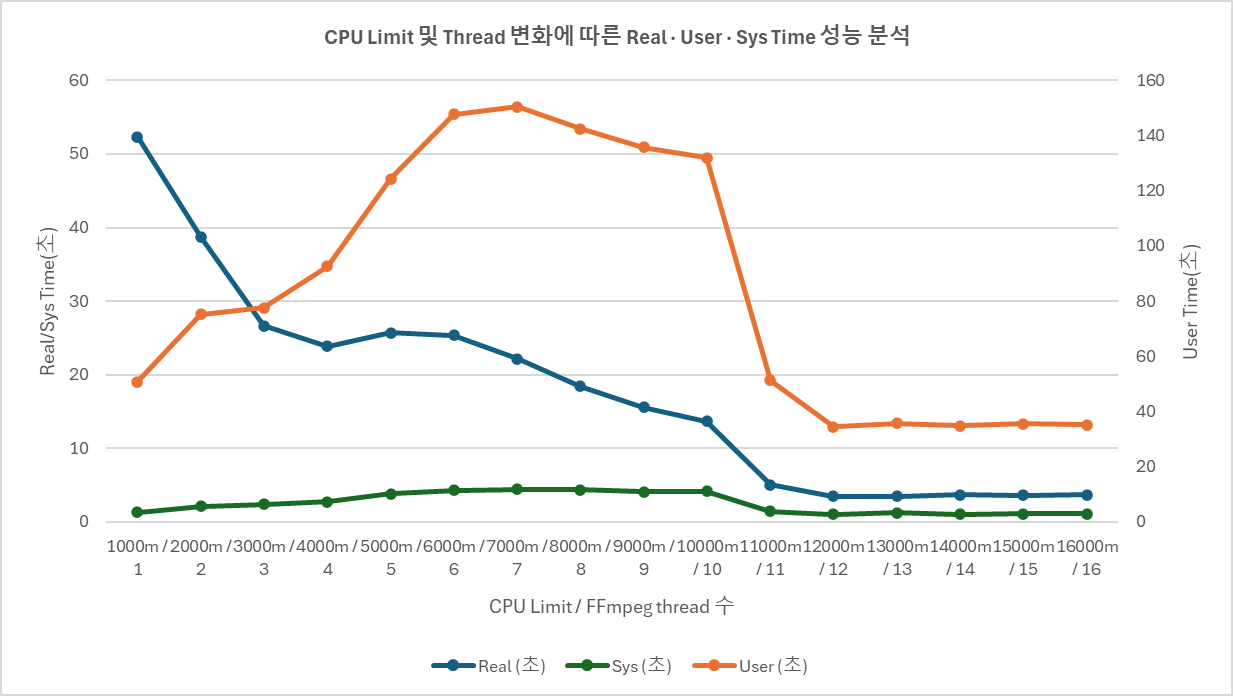
결과: limit = threads 일치 구간
| CPU Limit | Thread | Real (초) | User (초) | Sys (초) | CPU 효율 |
|---|---|---|---|---|---|
| 1000m | 1 | 52.32 | 50.87 | 1.33 | 1.00 |
| 2000m | 2 | 38.78 | 75.33 | 2.13 | 2.00 |
| 3000m | 3 | 26.68 | 77.59 | 2.38 | 3.00 |
| 4000m | 4 | 23.88 | 92.59 | 2.73 | 3.99 |
| 5000m | 5 | 25.73 | 124.33 | 3.85 | 4.98 |
| 6000m | 6 | 25.39 | 147.76 | 4.31 | 5.99 |
| 7000m | 7 | 22.20 | 150.47 | 4.44 | 6.98 |
| 8000m | 8 | 18.45 | 142.39 | 4.34 | 7.96 |
| 9000m | 9 | 15.61 | 135.68 | 4.07 | 8.95 |
| 10000m | 10 | 13.70 | 131.95 | 4.14 | 9.94 |
| 11000m | 11 | 5.08 | 51.25 | 1.44 | 10.37 |
| 12000m | 12 | 3.46 | 34.41 | 1.01 | 10.24 |
| 13000m | 13 | 3.50 | 35.81 | 1.21 | 10.58 |
| 14000m | 14 | 3.72 | 34.82 | 1.02 | 9.62 |
| 15000m | 15 | 3.63 | 35.57 | 1.09 | 10.10 |
| 16000m | 16 | 3.67 | 35.13 | 1.10 | 9.87 |
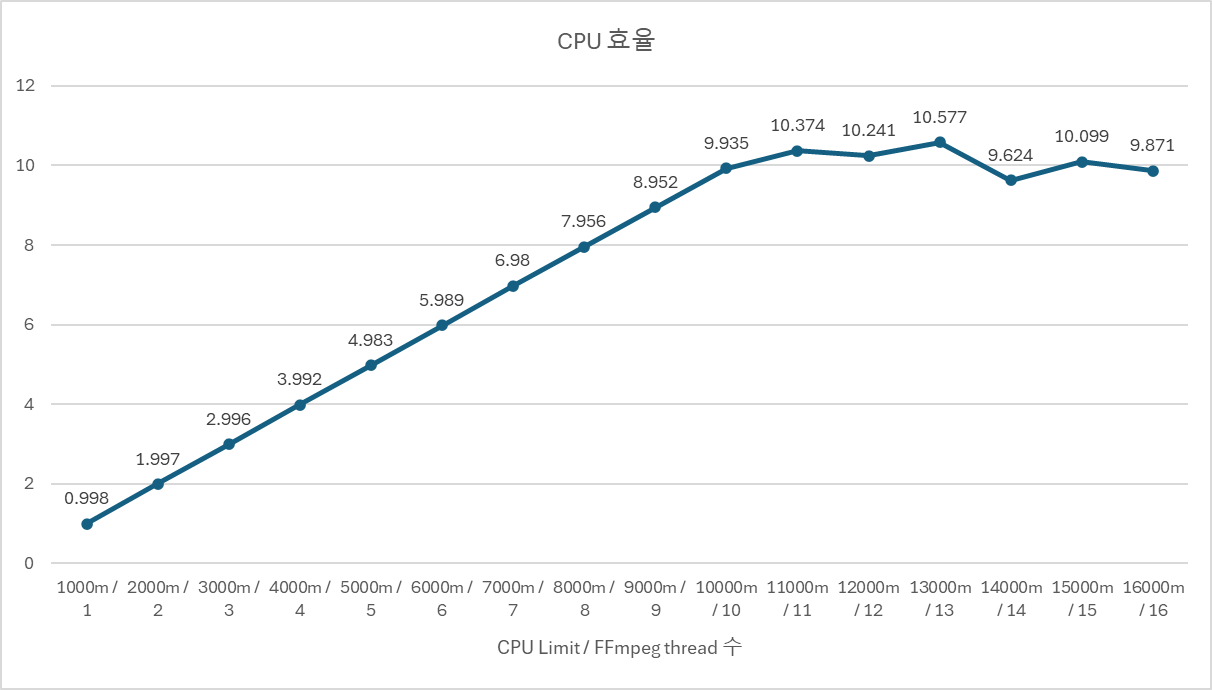
CPU 효율 = (User + Sys) / Real. 실제로 몇 코어 분량의 CPU 시간을 사용했는지를 나타낸다.
결과: over-subscription 시도
일부 CPU limit에서 threads를 limit보다 크게 설정하여 효과를 확인했다.
4000m (4 core)에서 threads 변화:
| Thread | Real (초) | vs thread=4 | CPU 효율 |
|---|---|---|---|
| 4 | 23.88 | baseline | 3.99 |
| 5 | 21.02 | 11.9% ↓ | 3.98 |
| 6 | 20.13 | 15.7% ↓ | 4.00 |
| 7 | 19.86 | 16.8% ↓ | 4.00 |
| 8 | 21.53 | 9.8% ↓ | 4.00 |
thread 7에서 최적점. thread 8부터 다시 악화. CPU 효율은 모두 ~4.0으로 limit에 막혀 있다.
5000m (5 core)에서 threads 변화:
| Thread | Real (초) | vs thread=5 | CPU 효율 |
|---|---|---|---|
| 5 | 25.73 | baseline | 4.98 |
| 10 | 25.72 | 0.0% | 4.98 |
| 15 | 24.43 | 5.1% ↓ | 4.99 |
| 20 | 24.71 | 4.0% ↓ | 4.99 |
| 25 | 23.11 | 10.2% ↓ | 4.99 |
| 30 | 23.68 | 8.0% ↓ | 4.99 |
효과가 미미하다. thread를 5배(25)로 늘려도 10% 정도의 개선.
6000m (6 core)에서 threads 변화:
| Thread | Real (초) | vs thread=6 | CPU 효율 |
|---|---|---|---|
| 4 | 24.21 | 4.7% ↓ | 5.99 |
| 6 | 25.39 | baseline | 5.99 |
| 8 | 25.72 | 1.3% ↑ | 5.98 |
| 12 | 26.00 | 2.4% ↑ | 5.99 |
threads를 늘려도 개선 없음. 오히려 미세하게 악화.
분석
구간별 패턴
결과를 코어 수에 따라 5개 구간으로 나눌 수 있다.
Phase 1: 고효율 구간 (1~4 core)
가장 효율적인 투자 구간이다. 매 코어 추가 시 10~16%/core의 개선을 얻는다.
| Core | 처리 시간 | 누적 개선 | 코어당 개선율 |
|---|---|---|---|
| 2 | 38.78초 | -25.9% | 12.9%/core |
| 3 | 26.68초 | -49.0% | 16.3%/core |
| 4 | 23.88초 | -54.4% | 13.6%/core |
Dead Zone 없이 안정적이고 예측 가능하다. 리소스가 제한적이라면 이 구간에서 투자 대비 효과가 가장 크다.
Phase 2: Dead Zone (5~6 core)
이전 실험에서 -threads auto가 만들었던 Dead Zone이 threads를 명시 지정해도 여전히 비효율적인 구간이다. 4 core 대비 오히려 악화된다.
| Core | 처리 시간 | vs 4 core |
|---|---|---|
| 5 | 25.73초 | 7.7% 악화 |
| 6 | 25.39초 | 6.3% 악화 |
다만, auto 때의 극심한 악화(6000m: 27.33초, 7000m: 29.22초)보다는 완화되었다. threads 명시 지정이 Dead Zone을 완전히 해소하지는 못하지만 상당히 줄여 준다.
Phase 3: 회복 구간 (7~10 core)
Dead Zone을 벗어나 점진적이고 안정적인 개선이 나타난다.
| Core | 처리 시간 | 이전 대비 |
|---|---|---|
| 7 | 22.20초 | 12.6% ↓ |
| 8 | 18.45초 | 16.9% ↓ |
| 9 | 15.61초 | 15.4% ↓ |
| 10 | 13.70초 | 12.2% ↓ |
코어당 약 8%/core 수준의 효율. 선형 확장의 끝 구간이다.
Phase 4: Breakthrough (11~12 core)
10 → 11 core에서 처리 시간이 63% 급감하는 극적인 변화가 나타난다.
| Core | 처리 시간 | 이전 대비 | 누적 개선 |
|---|---|---|---|
| 11 | 5.08초 | 62.9% ↓ | 90.3% |
| 12 | 3.46초 | 31.9% ↓ | 93.4% |
이전 실험(auto)에서도 비슷한 구간(8000m → 12000m)에서 급변이 있었다. threads를 명시적으로 지정해도 같은 패턴이므로, ffmpeg의 frame-level parallelism이 본격적으로 활성화되는 임계점이 여기에 있는 것으로 보인다.
Phase 5: Plateau (13~16 core)
12 core 이후로는 코어를 추가해도 유의미한 개선이 없다. 3.5~3.7초 범위에서 변동만 있을 뿐이다.
CPU 효율 그래프를 보면, 11 core 이후 효율이 ~10에서 수렴한다. 12~16 core를 할당해도 실제로는 10 core 분량만 사용하고 있다. ffmpeg의 이 영상에 대한 병렬 처리 한계가 약 10~11 core인 것이다.
Dead Zone 비교: auto vs 명시 지정
| CPU Limit | Thread Auto (이전 실험) | Thread = Limit (이번 실험) | 변화 |
|---|---|---|---|
| 4000m | 20.43초 | 23.88초 | 16.9% 악화 |
| 5000m | 22.96초 | 25.73초 | 12.1% 악화 |
| 6000m | 27.33초 | 25.39초 | 7.1% 개선 |
| 7000m | 29.22초 | 22.20초 | 24.0% 개선 |
| 8000m | 20.42초 | 18.45초 | 9.6% 개선 |
흥미로운 패턴이다.
- 4000m~5000m: auto가 오히려 더 빠르다. auto가 limit보다 더 공격적으로 스레드를 만들어서, 결과적으로 over-subscription 효과를 얻은 것으로 추정된다. (실제로 4000m에서 thread 7이 최적이었다.)
- 6000m~8000m: 명시 지정이 확실히 빠르다. Dead Zone이 사라진다. auto가 이 구간에서 비효율적인 스레드 수를 선택했음이 확인된다.
over-subscription 효과
| CPU Limit | 효과 |
|---|---|
| 4000m (4 core) | thread 7까지 유의미한 개선 (+17%). 파이프라인 중첩 효과 |
| 5000m (5 core) | 미미한 개선 (최대 +10%). 실용적 의미 제한적 |
| 6000m (6 core) | 효과 없음. 오히려 악화 |
코어 수가 적을 때는 limit보다 약간 많은 스레드가 파이프라인 중첩(한 스레드가 I/O 대기하는 동안 다른 스레드가 CPU 사용)에 도움이 될 수 있다. 하지만 코어가 충분해지면 이 효과가 사라지고 오버헤드만 남는다.
정리
핵심 발견
- limit = threads일 때, 1~10 core 구간에서 선형 확장 확인. CPU 효율 99% 이상.
- Dead Zone(5~7 core)은
-threads auto의 문제. threads를 명시 지정하면 해소된다. - ffmpeg 병렬 처리 한계는 ~10~11 core. 이후 코어를 추가해도 실제 활용은 ~10 core에서 수렴.
- over-subscription은 제한적 효과. 4 core에서 thread 7 정도는 의미 있지만, 5 core 이상에서는 미미.
실무적 가이드라인
이번 실험에서 얻은 추이를 바탕으로 정리하면:
| 시나리오 | 권장 설정 | 근거 |
|---|---|---|
| 리소스가 제한적 (4 core 이하) | limit = threads, 또는 threads를 limit의 1.5~2배 | over-subscription 효과 활용 |
| 중간 리소스 (5~10 core) | limit = threads | 선형 확장 구간, auto 대신 명시 지정 |
| 충분한 리소스 (11+ core) | threads = 10~11 | 이 이상은 효과 없음 |
다만, 이 가이드라인은 이 영상과 이 서버 환경에서의 추이다. 영상 해상도, 코덱, 서버 아키텍처에 따라 수치는 달라질 수 있다. 중요한 것은 “측정 → 추이 파악 → 근거 기반 결정”이라는 접근 방식이다.
-threads auto라는 편리한 기본값이 모든 환경에서 최적은 아니라는 것을 확인했다. 특히 CPU limit이 있는 컨테이너 환경에서는, auto가 호스트 코어 수를 기준으로 스레드를 결정하면서 오히려 비효율을 만들 수 있다. limit에 맞게 threads를 명시적으로 지정하는 것이 더 안정적인 선택이다.
참고: CPU Limit 고정 시 Thread 수 변화 상세
본문에서는 limit = threads 일치 구간과 일부 over-subscription을 다뤘다. 여기서는 각 CPU limit에서 threads를 1부터 20까지 변화시킨 전체 데이터를 정리한다.
일부 이상치가 포함되어 있다. thread 1~2에서 비정상적으로 빠른 결과가 나오는 경우가 있는데, ffmpeg이
-threads옵션과 별개로 내부 필터(swscaler 등)에서 추가 스레드를 생성하기 때문으로 추정된다. 이상치는 (*) 표시했다.
CPU Limit 4000m
| Thread | Real (초) | User (초) | Sys (초) | 비고 |
|---|---|---|---|---|
| 1 | 7.48 | 28.58 | 0.83 | (*) 이상치. user/real ≈ 3.9, limit 전체 활용 |
| 2 | 30.36 | 117.63 | 3.57 | under-subscription |
| 3 | 28.20 | 109.35 | 3.38 | under-subscription |
| 4 | 23.49 | 90.99 | 2.69 | limit = threads |
| 5 | 21.28 | 82.59 | 2.44 | over-subscription, 개선 |
| 6 | 20.72 | 80.27 | 2.52 | over-subscription, 개선 |
| 7 | 20.71 | 80.12 | 2.51 | over-subscription, 최적 근방 |
| 8 | 21.10 | 81.84 | 2.54 | 악화 시작 |
| 9 | 20.92 | 80.87 | 2.63 | |
| 10 | 20.82 | 80.46 | 2.54 | |
| 11 | 21.66 | 84.31 | 2.44 | |
| 12 | 21.68 | 83.77 | 2.69 | |
| 13 | 20.15 | 77.88 | 2.37 | |
| 14 | 19.77 | 76.59 | 2.35 | |
| 15 | 20.47 | 79.19 | 2.60 | |
| 16 | 20.81 | 80.39 | 2.62 | |
| 17 | 20.70 | 79.83 | 2.86 | |
| 18 | 19.92 | 76.89 | 2.43 | |
| 19 | 20.40 | 78.95 | 2.50 | |
| 20 | 19.71 | 76.42 | 2.33 | |
| 21 | 21.26 | 82.40 | 2.46 | 호스트 코어 수 초과 |
4000m에서는 thread 5~7 구간에서 over-subscription 효과가 있고, 이후로는 20~21초 범위에서 평탄하다. CPU 효율은 모두 ~4.0으로 limit에 막혀 있다.
CPU Limit 8000m
| Thread | Real (초) | User (초) | Sys (초) | 비고 |
|---|---|---|---|---|
| 1 | 5.78 | 27.13 | 0.90 | (*) 이상치 |
| 2 | 4.99 | 37.24 | 0.98 | (*) 이상치 |
| 3 | 14.37 | 111.11 | 3.19 | under-subscription |
| 4 | 17.48 | 135.46 | 3.80 | under-subscription |
| 5 | 17.82 | 137.68 | 4.11 | under-subscription |
| 6 | 18.31 | 141.95 | 3.97 | under-subscription |
| 7 | 18.95 | 146.90 | 4.16 | under-subscription |
| 8 | 18.80 | 145.77 | 4.22 | limit = threads |
| 9 | 19.37 | 149.90 | 4.54 | over-subscription |
| 10 | 19.48 | 150.66 | 4.48 | over-subscription |
| 11 | 19.51 | 150.85 | 4.45 | |
| 12 | 19.69 | 152.68 | 4.46 | |
| 13 | 19.10 | 148.10 | 4.25 | |
| 14 | 18.08 | 139.27 | 4.37 | |
| 15 | 19.14 | 148.24 | 4.34 | |
| 16 | 19.67 | 151.77 | 4.59 | |
| 17 | 19.97 | 154.73 | 4.50 | |
| 18 | 19.69 | 152.53 | 4.41 | |
| 19 | 19.97 | 154.79 | 4.50 | |
| 20 | 20.05 | 155.22 | 4.51 |
8000m에서는 thread 1~2의 이상치를 제외하면, thread 3~8 구간에서 under-subscription일수록 빠른 경향이 있다. thread 8(limit = threads) 이후로는 over-subscription 효과가 거의 없고, 18~20초 범위에서 평탄하다.
CPU Limit 11000m
| Thread | Real (초) | User (초) | Sys (초) | 비고 |
|---|---|---|---|---|
| 1 | 5.67 | 27.27 | 0.69 | |
| 2 | 4.14 | 31.90 | 0.96 | |
| 3 | 3.68 | 33.64 | 0.98 | |
| 4 | 3.53 | 34.29 | 1.05 | |
| 5 | 3.54 | 34.90 | 1.19 | |
| 6 | 3.76 | 38.58 | 1.14 | |
| 7 | 3.86 | 36.59 | 1.18 | |
| 8 | 3.30 | 34.01 | 1.09 | |
| 9 | 3.57 | 35.14 | 1.04 | |
| 10 | 3.32 | 34.09 | 0.95 | |
| 11 | 3.72 | 37.04 | 1.03 | limit = threads |
| 12 | 3.55 | 35.47 | 1.03 | |
| 13 | 3.33 | 33.88 | 0.97 | |
| 14 | 10.65 | 111.34 | 3.49 | (*) 이상치. 원인 불명 |
| 15 | 3.95 | 39.39 | 1.21 | |
| 16 | 5.17 | 52.49 | 1.50 | |
| 17 | 3.39 | 34.76 | 1.10 | |
| 18 | 11.87 | 125.36 | 3.70 | (*) 이상치. 원인 불명 |
| 19 | 3.67 | 35.80 | 1.10 | |
| 20 | 4.90 | 49.74 | 1.73 |
11000m에서는 이상치(thread 14, 18)를 제외하면 thread 수와 거의 무관하게 3~4초 범위에 수렴한다. 리소스가 충분한 환경에서는 threads 수 조절의 의미가 크지 않다는 것을 보여준다. thread 1에서도 5.67초로 충분히 빠르다.

댓글남기기