
[GPU] Phantom GPU Utilization 사례 분석: CUDA Context 잔류 가설과 그 한계
TL;DR
- 관찰된 사실: NCCL backend 학습 검증 실험 종료 후, 4개 GPU 노드 32개 GPU 중 14개가 “Util 100%, Memory 0 MiB, Process 없음, Xid 없음” 상태에 빠졌다. 이른바 phantom GPU utilization — GPU가 바쁜 척하지만 실제로는 아무것도 하지 않는 상태 — 이다
- 결과: 이후 새 워크로드가 phantom GPU 위에 배치되자 정상 동작하면서 현상은 해소되었다. 의도한 해결이 아니라 결과론적으로 알게 된 사실이다
- 유력 가설: Pod가 비정상 종료된 실험 회차 이후 phantom 상태가 관측되었고, 새 CUDA context가 생성되자 해소된 점을 종합하면 “orphaned CUDA context로 인해 driver가 compute engine을 busy로 유지했다”는 가설이 가장 그럴듯하다. 다만 leaked context를 직접 가리키는 driver 측 증거(Xid, NVML context list, kernel trace)는 확보하지 못했다. Blackwell/580 드라이버 버그, 펌웨어 이슈, NCCL 종료 시점의 GPU 상태 등 다른 원인은 배제되지 않는다
- 제약:
nvidia-smi -r(GPU reset)은 nvidia-persistenced가 모든 device handle을 보유하고 있어 K8s GPU 노드에서 실행 불가 - 미해결: 가설이 맞다 하더라도, “왜 driver가 orphaned context를 자동 회수하지 못했는가”는 답이 없다. 본 글은 이 사건을 사례 보고와 가설 정리로 다루며, 단정적 결론이 아님을 명시한다
배경
이 글에서 다루는 사례는 실험 환경(전용 GPU 노드, 다른 팀 워크로드 없음)에서 발생한 것이다. 원인 분석에 시간을 들일 수 있었던 것도 이 때문이며, 운영 환경에서는 대응 우선순위가 달라진다는 점을 먼저 밝혀 둔다.
NCCL 트러블슈팅 과정에서 베이스 이미지를 리빌드(NCCL 2.29.7, sm_120 포함)한 뒤, NCCL backend로 분산학습 검증 실험을 진행했다. 실험 자체는 통과했지만, validation 단계에서 에러가 발생하면서 RayJob이 FAILED로 종료되는 일이 반복되었다.
실험이 끝난 뒤 Grafana 대시보드를 확인하니, 일부 GPU가 utilization 100%를 찍고 있었다. 처음에는 아직 뭔가 돌고 있는 줄 알았지만, 학습 namespace에 Pod도 RayJob도 없었다. nvidia-smi를 직접 확인한 결과, GPU-Util 100%인데 프로세스는 없고 메모리도 0인 기이한 상태를 확인했다.
| 항목 | 값 |
|---|---|
| GPU | NVIDIA GeForce RTX 5090 (Blackwell, sm_120) |
| Driver | 580.126.09 (NVIDIA Open Kernel Module) |
| CUDA | 13.0 |
| 노드 | gpu-node-1 ~ gpu-node-4 (각 8 GPU) |
| 실험 | RayJob, 8 GPU worker, NCCL backend, 4회 반복 실행 |
본 환경의 580 + Open Kernel Module + Blackwell(sm_120) + CUDA 13.0 조합은 비교적 최근에 일반 사용자가 운영하기 시작한 조합이다. NVIDIA Open GPU Kernel Modules GitHub 이슈에는 580-open / Blackwell 계열의 GSP timeout 및 안정성 관련 보고가 다수 있어, 본 사건의 driver-side root cause가 이 조합에 특수한 이슈일 가능성을 배제하기 어렵다. 원인 분석에서 SIGKILL/orphaned context를 1순위 가설로 두되 단정하지 않는 이유 중 하나다.
현상: Phantom GPU Utilization
nvidia-smi 출력 패턴
실험 종료 후 각 노드에서 GPU 상태를 확인했다. gpu-node-1의 출력을 보면 패턴이 명확하다.
# gpu-node-1 GPU 상태
$ nvidia-smi --query-gpu=index,pstate,utilization.gpu,memory.used,power.draw --format=csv,noheader
0, P8, 0 %, 0 MiB, 22.69 W
1, P0, 100 %, 0 MiB, 117.40 W # ← phantom
2, P8, 0 %, 0 MiB, 15.94 W
3, P0, 100 %, 0 MiB, 123.02 W # ← phantom
4, P0, 100 %, 0 MiB, 111.55 W # ← phantom
5, P0, 100 %, 0 MiB, 114.22 W # ← phantom
6, P8, 0 %, 0 MiB, 15.90 W
7, P0, 100 %, 0 MiB, 114.13 W # ← phantom
정상 GPU(0, 2, 6번)는 P8(idle) 상태에서 0%, 15~23W를 소비한다. Phantom GPU(1, 3, 4, 5, 7번)는 P0(최고 성능) 상태에 고정되어 100%, 111~123W를 소비하면서도, 메모리 사용량은 0 MiB이고 실행 중인 프로세스도 없다.
나머지 3개 노드 출력
# gpu-node-2
$ nvidia-smi --query-gpu=index,pstate,utilization.gpu,memory.used,power.draw --format=csv,noheader
0, P8, 0 %, 0 MiB, 13.10 W
1, P8, 0 %, 0 MiB, 3.23 W
2, P8, 0 %, 0 MiB, 10.08 W
3, P8, 0 %, 0 MiB, 14.09 W
4, P8, 0 %, 0 MiB, 10.07 W
5, P0, 100 %, 0 MiB, 120.01 W # ← phantom
6, P0, 100 %, 0 MiB, 123.06 W # ← phantom
7, P8, 0 %, 0 MiB, 8.24 W
# gpu-node-3
$ nvidia-smi --query-gpu=index,pstate,utilization.gpu,memory.used,power.draw --format=csv,noheader
0, P8, 0 %, 0 MiB, 3.41 W
1, P8, 0 %, 0 MiB, 3.64 W
2, P8, 0 %, 0 MiB, 9.38 W
3, P0, 100 %, 0 MiB, 123.11 W # ← phantom
4, P8, 0 %, 0 MiB, 14.94 W
5, P0, 100 %, 0 MiB, 108.37 W # ← phantom
6, P0, 100 %, 0 MiB, 127.46 W # ← phantom
7, P0, 100 %, 0 MiB, 115.17 W # ← phantom
# gpu-node-4
$ nvidia-smi --query-gpu=index,pstate,utilization.gpu,memory.used,power.draw --format=csv,noheader
0, P8, 0 %, 0 MiB, 4.72 W
1, P0, 100 %, 0 MiB, 114.34 W # ← phantom
2, P0, 100 %, 0 MiB, 114.44 W # ← phantom
3, P8, 0 %, 0 MiB, 8.90 W
4, P0, 100 %, 0 MiB, 124.43 W # ← phantom
5, P8, 0 %, 0 MiB, 3.28 W
6, P8, 0 %, 0 MiB, 7.75 W
7, P8, 0 %, 0 MiB, 13.41 W
현황 요약
4개 노드 전체를 점검하여 phantom GPU의 분포를 정리했다. 하드웨어 손상 여부를 확인하기 위해 온도와 전력도 함께 살펴봤는데, 온도는 27~48°C로 정상 범위였고, 하드웨어 손상은 없었다. 다만 phantom GPU가 idle 대비 훨씬 높은 전력을 소비하고 있어서 전력 낭비 규모도 추정해 보았다.
| 노드 | Phantom GPU (100%, 0 MiB, P0) | Phantom 수 | 추정 전력 낭비 |
|---|---|---|---|
| gpu-node-1 | 1, 3, 4, 5, 7 | 5 | ~580W |
| gpu-node-2 | 5, 6 | 2 | ~243W |
| gpu-node-3 | 3, 5, 6, 7 | 4 | ~474W |
| gpu-node-4 | 1, 2, 4 | 3 | ~353W |
| 합계 | 14/32 | ~1,650W |
32개 GPU 중 14개가 phantom 상태였다. nvidia-smi 출력에서 볼 수 있듯이 phantom GPU는 idle GPU(~15W) 대비 약 7배(~114W)의 전력을 소비하고 있었는데, 이유는 배경 지식 섹션에서 다룬다.
워크로드 종료 확인
# 학습 namespace에 리소스 없음
$ kubectl get pods -n ml-training
No resources found in ml-training namespace.
$ kubectl get rayjob -n ml-training
No resources found in ml-training namespace.
실험에 사용한 RayJob과 Pod가 전부 정리된 상태다. GPU를 점유하는 워크로드가 없는데 utilization만 100%인 상태가 확인되었다.
정상 GPU vs Phantom GPU
후에 새 학습 워크로드가 phantom 상태이던 GPU 위에 배치되어 정상 동작하는 것을 관측했다. 이를 통해 세 가지 상태를 비교할 수 있었다.
| 정상 idle | 정상 사용 중 | Phantom | |
|---|---|---|---|
| GPU-Util | 0% | 부하에 비례 | 100% (stuck) |
| Memory | 0~1 MiB | 수천~수만 MiB | 0~1 MiB |
| Process | 없음 | CUDA 프로세스 표시 | 없음 |
| Perf State | P8 | P0~P2 | P0 (stuck) |
| Power | ~15W | ~170W | ~114W |
Phantom GPU는 utilization과 perf state만 보면 “풀 로드”처럼 보이지만, 메모리와 프로세스는 “idle”이다. 일종의 유령 상태 — GPU가 바쁜 척하지만 실제로는 아무것도 하지 않는다 — 이다.
배경 지식
Phantom GPU utilization을 이해하려면 두 가지를 알아야 한다. nvidia-smi가 보고하는 “GPU-Util”이 실제로 무엇을 측정하는지, 그리고 CUDA context가 어떻게 생성되고 해제되는지.
GPU Utilization의 정의: nvidia-smi와 NVML
nvidia-smi는 내부적으로 NVML(NVIDIA Management Library) API를 호출하는 CLI wrapper다. GPU-Util 값은 nvmlDeviceGetUtilizationRates() 함수에서 가져오는데, NVIDIA 공식 문서의 정의는 다음과 같다.
Percent of time over the past sample period during which one or more kernels was executing on the GPU.
핵심은 이것이 시간 기반 측정이라는 점이다. “샘플 구간 중 커널이 하나라도 실행 중이던 시간의 비율”이지, GPU의 SM(Streaming Multiprocessor)이 몇 개나 활용되었는지는 반영하지 않는다. 1개 SM만 쓰는 가벼운 커널이라도 샘플 구간 내내 돌고 있었으면 GPU-Util은 100%가 된다. Modal GPU Glossary가 이를 명확하게 짚는다.
If a kernel uses only one SM, e.g. because it only has one thread block, then it will achieve 100% GPU utilization while it is active, but the SM utilization will be at most one over the number of SMs — under 1% in an H100 GPU.
이 정의가 phantom GPU utilization과 어떻게 연결되는가. NVML이 공식 문서로 보장하는 것은 어디까지나 “샘플 구간 중 커널이 실행 중이던 시간의 비율”이지, driver 내부 엔진 상태와의 직접 대응이 아니다. 별도로 DCGM은 graphics/compute 엔진 활동을 DCGM_FI_PROF_GR_ENGINE_ACTIVE로, SM 활동을 DCGM_FI_PROF_SM_ACTIVE로 따로 정의한다 — 즉 NVIDIA의 metric taxonomy에서 “kernel 실행 시간”과 “엔진/SM이 active인지”는 별개 metric이다.
본 글에서 phantom 상태를 풀 때 등장하는 “driver가 compute engine을 active로 유지한다”는 표현은, 두 metric을 잇는 documented relation이 아니라 본 사건을 설명하기 위해 잠정적으로 채택한 가설이다. 증명된 결론이 아니라, “이 모델로 보면 관찰된 현상이 잘 설명된다”는 수준의 설명 틀이며 본 글은 이 가설을 전제로 현상을 풀어간다. 구체적으로는, “프로세스가 사라졌는데도 회수되지 않은 orphaned context가 남아, NVML이 보고하는 ‘kernel 실행 시간 비율’이 100%로 고정된 것처럼 보이는” 상태를 가정한다. 다른 메커니즘(예: 엔진/펌웨어 측 stuck, telemetry/accounting 자체의 stuck, 전력 상태 전이 실패 등)으로 동일 현상이 발생할 가능성은 배제하지 않는다.
nvidia-smi dmon으로 더 정밀하게 보기
nvidia-smi dmon은 nvidia-smi의 device monitoring 모드다. 기본 nvidia-smi가 스냅샷(한 시점의 상태)을 보여주는 반면, dmon은 매 초(기본값) GPU별 메트릭을 연속으로 출력한다. GPU당 전력, 온도, SM activity, memory activity, 인코더/디코더 활동, 클럭 주파수를 한 줄로 보여주므로 시계열 변화를 관찰하기 좋다. 비슷한 모드로 nvidia-smi pmon(process monitoring — 프로세스별 GPU/메모리 사용량 추적)이 있다.
참고: GR 엔진과 dmon 컬럼
GPU에는 여러 하드웨어 엔진이 있다. GR(Graphics) 엔진은 이름과 달리 그래픽 전용이 아니라, CUDA compute 커널도 실행하는 GPU의 핵심 연산 엔진이다. 이 밖에 Copy Engine(CE, 메모리 전송), NVENC/NVDEC(영상 인코딩/디코딩) 등 별도 엔진이 있다.
nvidia-smi dmon의 각 컬럼은 이 엔진들의 활동률에 대응한다.sm컬럼은 SM(Streaming Multiprocessor) activity — SM 코어가 active한 시간 비율 — 이고,enc,dec,jpg,ofa가 인코더/디코더 등 나머지 엔진의 활동률이다.NVIDIA DCGM의 metric taxonomy에서는 GR 엔진 활동(
DCGM_FI_PROF_GR_ENGINE_ACTIVE)과 SM 활동(DCGM_FI_PROF_SM_ACTIVE)을 별개 metric으로 정의한다.dmon의sm컬럼은 SM 활동을 보여주는 것이지 GR 엔진 활동 자체와 동일하지는 않다. 본 사건에서 phantom GPU의sm이 100%로 고정된 것은 “SM이 active로 보고된 상태”이며, 이를 “GR 엔진 stuck”으로 단정하려면 별도 GR 엔진 metric(dcgmi dmon -e 1001) 수집이 필요하다(본 사건에선 수집하지 않았다).
Phantom GPU가 남아 있던 노드에서 dmon을 실행한 결과다.
# gpu-node-1 nvidia-smi dmon: GPU 5번만 phantom 상태로 남아 있는 시점
$ nvidia-smi dmon
# gpu pwr gtemp mtemp sm mem enc dec jpg ofa mclk pclk
# Idx W C C % % % % % % MHz MHz
0 24 29 - 0 0 0 0 0 0 405 210
1 11 29 - 0 0 0 0 0 0 405 210
2 15 29 - 0 0 0 0 0 0 405 210
3 16 29 - 0 0 0 0 0 0 405 210
4 13 27 - 0 0 0 0 0 0 405 210
5 113 37 - 100 0 0 0 0 0 14001 2940
6 19 31 - 0 0 0 0 0 0 405 210
7 14 27 - 0 0 0 0 0 0 405 210
GPU 5번(phantom)의 상태가 두드러진다.
| 정상 idle GPU | Phantom GPU (5번) | |
|---|---|---|
SM activity (sm) |
0% | 100% |
Memory activity (mem) |
0% | 0% |
Memory clock (mclk) |
405 MHz | 14,001 MHz (최대) |
Core clock (pclk) |
210 MHz | 2,940 MHz (최대) |
| Power | 10~24W | 113W |
SM activity 100%인데 memory activity 0% — GPU 코어는 “바쁘다”고 보고하지만 메모리 I/O는 전혀 없다. 클럭도 최대치에 고정되어 있다. 이것이 phantom GPU의 하드웨어 레벨 시그니처다.
참고: GPU 클럭과 전력의 관계
GPU에는 두 종류의 클럭이 있다. 코어 클럭(pclk)은 연산을 수행하는 SM(Streaming Multiprocessor)의 동작 속도, 메모리 클럭(mclk)은 VRAM의 데이터 전송 속도를 결정한다. 클럭이 높을수록 처리 성능이 올라가지만, 전력 소비도 함께 증가한다.
GPU의 전력 소비는 두 가지로 나뉜다. 동적 전력(dynamic power)은 실제 연산(SM 활동, 메모리 R/W)에 의해 소비되고, 정적 전력(static power)은 연산 없이도 소비된다. Phantom GPU는 실제 연산이 없으므로 동적 전력은 거의 0이지만, P0 상태에서 클럭이 최대치(pclk 2,940MHz, mclk 14,001MHz)로 고정되면 이를 안정적으로 구동하기 위한 코어 voltage도 함께 최대로 유지된다(DVFS — Dynamic Voltage and Frequency Scaling). 높아진 voltage는 트랜지스터의 누설 전류(leakage current)를 증가시키고, 이 정적 전력만으로 ~114W를 소비한다. Idle GPU(클럭 최저: pclk 210MHz, mclk 405MHz)가 ~15W인 것과 비교하면 7배에 달한다.
참고: GPU Performance State (P-state)
NVIDIA GPU의 Performance State(P-state)는 P0(최고 성능)부터 P12(최저 전력)까지 있다. P-state는 클럭 주파수를 결정한다 — P8(idle)에서는 클럭이 최저로 내려가고, P0에서는 최대로 올라간다. Phantom GPU는 P0에 고정되어 클럭과 voltage가 최대치를 유지하고, 앞서 본 것처럼 높은 voltage가 정적 전력 소비를 유발한다.
비유하면 자동차 공회전에 가깝다. 기어는 최고단(P0)에, 엔진 RPM은 최대(클럭 최대)인데, 바퀴는 굴러가지 않는(연산 없음) 상태다.
CUDA Context Lifecycle
NVIDIA GPU에서 CUDA 연산을 수행하려면 먼저 CUDA context를 생성해야 한다. CUDA context는 GPU의 메모리 할당, 모듈(커널 코드), 스트림 등을 캡슐화하는 객체다. 프로세스가 context를 생성하면 driver가 해당 GPU 자원을 점유하기 시작하고, context가 해제(destroy)되어야 자원이 풀린다.
NVML이 보고하는 utilization과 context 수명을 직접 묶는 공식 문서는 찾지 못했다 — 인용한 NVML 문서는 client attachment와 kernel 실행 시간 비율만 정의한다. 다만 “context 점유 상태가 풀리지 않으면 driver/엔진 측 active 상태가 유지되어 NVML이 100% utilization을 보고할 수 있다”는 가설은, GPU Utilization의 정의에서 잠정 채택한 가설을 같은 맥락에서 확장한 것이다.
Context의 생성과 해제는 두 가지 API 수준에서 관리된다.
- CUDA Runtime API: 대부분의 사용자(PyTorch, TensorFlow 등)가 사용하는 고수준 API다. 프로세스가 처음 GPU를 사용할 때 내부적으로 context를 생성하고, 정상 종료 시 Python의
atexithook이나 C++ destructor를 통해 context를 해제한다 - CUDA Driver API: 저수준 API로,
cuCtxCreate()/cuCtxDestroy()를 명시적으로 호출한다
어떤 수준을 쓰든, 정상 종료 시에는 cleanup이 보장된다. 문제는 비정상 종료일 때다.
| 종료 방식 | cleanup 실행 여부 | 결과 |
|---|---|---|
정상 종료 (exit(0)) |
atexit, destructor 실행 |
context 정상 해제 |
| 예외/segfault | stack unwinding 시도 | 대부분 해제, 일부 실패 가능 |
| SIGKILL | 일체 미실행 | context 잔류 (orphaned) |
SIGKILL을 받으면 프로세스는 즉시 종료된다. atexit도, try/finally도, torch.cuda.empty_cache()도 실행되지 않는다. GPU driver 입장에서는 “방금까지 context를 가지고 있던 프로세스가 갑자기 사라진” 상태다.
정상적이라면 driver가 프로세스 종료를 감지하고 orphaned context를 자동 회수해야 한다. 회수되면 점유가 풀리고 utilization은 0%로 내려간다. CUDA 커뮤니티 가이드(NVIDIA 공식 문서는 아니다)도 이 기대를 전제한다.
When an application exits, regardless of how, the context (and any associated allocations that are encapsulated within) should be destroyed.
— Stack Overflow, CUDA context destruction at host process termination (community discussion, not official documentation)
그러나 “should”가 항상 “does”는 아니다. 본 사건에서 잠정 채택한 가설은 “특정 드라이버 버전이나 GPU 아키텍처 조합에서 driver가 orphaned context를 회수하지 못하면, NVML이 보고하는 utilization 100%가 고정될 수 있다”이다. 다른 가능 가설 — 엔진/펌웨어 측 stuck, telemetry/accounting 버그, 전력 상태 전이 실패 — 도 동일 시그니처를 만들 수 있으며, 이번 사건만으로 그중 하나로 좁히기는 어렵다.
원인 분석
이 섹션은 글 도입부에서 밝힌 유력 가설의 메커니즘을 풀어쓴다. 직접 증거(Xid, NVML context list, kernel trace) 없이 정황 증거만으로 구성한 모델이며, 다른 원인이 배제된 것은 아니다.
발생 메커니즘
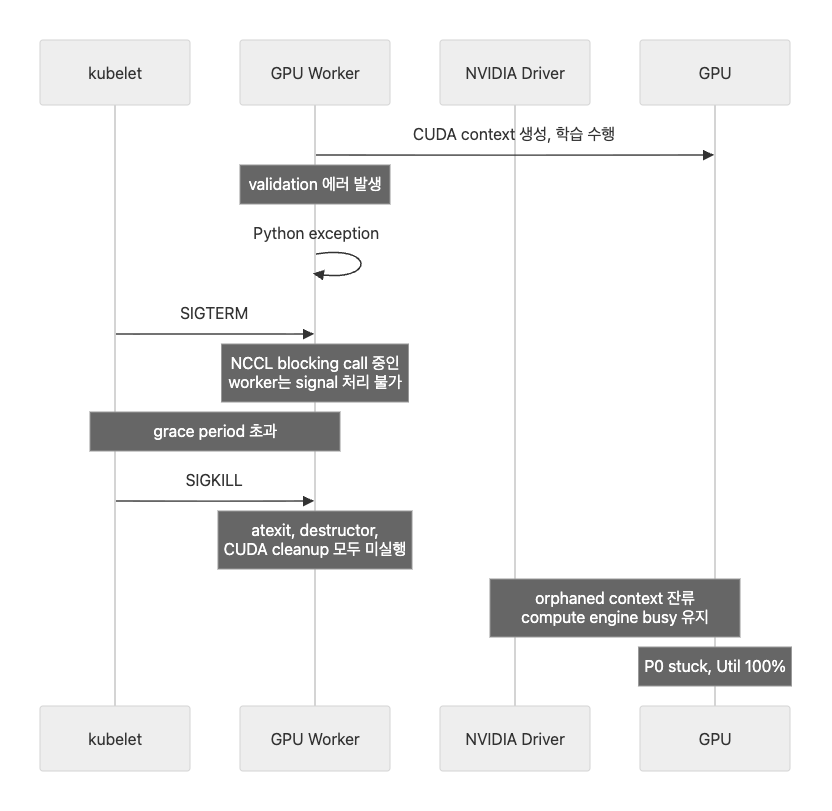
RayJob이 FAILED로 종료되면 kubelet이 Pod를 terminate한다. 이때 Pod 안의 GPU worker 프로세스에 일어나는 일은 두 가지 경로로 나뉘는 것으로 추정된다.
- 경로 1 — 예외가 발생한 worker: Python 예외로 stack unwinding(호출 스택을 역순으로 되감으며 각 프레임의 리소스를 정리하는 과정)이 시작되지만, CUDA cleanup 로직이 없어 context가 정리되지 않는다. SIGTERM을 받아도 정리할 코드가 없으므로 grace period 초과 후 SIGKILL이 들어왔을 것으로 추정
- 경로 2 — NCCL blocking 중인 나머지 worker: C++ 레벨의 collective op 안에서 대기 중이라 SIGTERM 자체를 처리하지 못한다. grace period 초과 후 SIGKILL이 들어왔을 것으로 추정
두 경로 모두 grace period 초과 → SIGKILL 경로로 들어갔을 것으로 추정되고, 결과도 동일한 것으로 보인다 — CUDA context cleanup이 실행되지 않고 orphaned context가 GPU에 남는다. cleanup이 안 되는 이유만 다르다(cleanup 코드 부재 vs signal 처리 불가).
다만 본 사건에서는 SIGKILL의 직접 증거 — kubelet event, container exit code 137, Pod termination timeline 등 — 를 별도로 수집해 두지 않았다. 따라서 위 경로는 NCCL blocking과 grace period 도달 가능성에서 추정한 정황 시나리오이며, “SIGKILL 경로가 가장 유력하다”는 수준의 가설로 읽어야 한다.
예외가 발생한 worker
Python 예외가 발생하면 stack unwinding이 시작되지만, 학습 코드에 CUDA cleanup 로직이 없었다. runner.train() 호출 후 아무 cleanup 없이 함수가 종료되는 구조였다. SIGTERM을 받더라도 CUDA context를 정리할 로직 자체가 구현되어 있지 않았다.
NCCL blocking 상태의 나머지 worker
분산학습에서 한 worker가 실패하면, 나머지 worker들은 collective op(예: all_reduce) 안에서 blocking 상태로 대기 중이다. Collective op은 “모든 rank가 참여해야 완료되는” 연산이므로, 한 rank가 빠지면 나머지는 그 rank를 무한히 기다린다.
이때 NCCL collective op은 Python이 아니라 C++ 네이티브 코드 레벨에서 실행된다. 이것이 왜 문제가 되는지는 CPython의 signal 처리 구조를 보면 드러난다.
CPython은 Python 소스를 바이트코드(bytecode)로 컴파일하고, 바이트코드 명령어를 하나씩 실행한다. OS가 signal을 전달하면 즉시 handler가 실행되는 게 아니라, 인터프리터가 “pending signal이 있는가?”를 체크하는 시점까지 대기한다. 이 체크는 바이트코드 명령어 실행 사이사이에 일어난다(CPython의 eval_breaker 메커니즘).
문제는 PyTorch가 NCCL collective을 호출하면 실행 흐름이 C++ 확장 모듈(libtorch → libnccl) 안으로 넘어간다는 점이다. C++ 코드가 실행 중인 동안에는 Python 바이트코드 실행 루프가 정지해 있으므로, 바이트코드 간 체크 포인트에 영원히 도달하지 못한다. 결과적으로 signal handler가 호출될 기회 자체가 없다.
SIGTERM은 프로세스가 자기 코드(signal handler)를 실행해야 처리할 수 있는 signal이다. C++ blocking 상태에서는 Python signal handler가 실행되지 않으므로, SIGTERM을 받아도 아무 일이 일어나지 않는다. Grace period가 지나면 kubelet이 SIGKILL을 보낸다. SIGKILL은 프로세스가 “처리”하는 것이 아니라 커널이 직접 프로세스를 제거하므로, 프로세스의 blocking 상태와 무관하게 즉시 효력이 발생한다. 그리고 앞서 본 것처럼, SIGKILL 경로에서는 atexit도, try/finally도, destructor도 — 어떤 cleanup 코드도 실행되지 않는다.
14개 GPU의 누적
실험을 4회 반복 실행했고, 매회 8개 GPU worker가 4개 노드에 분산 배치되었다. 각 run에서 비정상 종료가 발생할 때마다 phantom GPU 수가 누적되면서, 결과적으로 14개 GPU가 phantom 상태에 빠졌다.
14는 어디까지나 현상 규모(phantom 시그니처를 보이는 GPU 개수)이며, NVML/driver 측에서 회수되지 않은 context를 하나하나 세어 확인한 수치가 아니다. 본 사건에서는 context 측 직접 측정이 없었기에, “14 phantom GPU = 14 leaked context”로 곧장 치환할 수는 없다. 개별 run의 GPU 배치 분포(어느 run에서 어떤 GPU가 phantom 됐는지)도 별도로 정리하지 않았다.
Xid와의 관계: 이번에는 Xid가 없다
NCCL Communicator Lazy Init 디버깅 포스트에서 다뤘듯이, NCCL 통신 실패 시 드라이버 레벨에서는 Xid 에러가 남는다. Xid 13(SM Warp Exception)과 Xid 43(channel reset)이 대표적이다. Xid 43 리셋 후 GR(Graphics) 엔진 카운터가 100%에 고정되면서 phantom utilization이 발생하는 것이, 기존에 알려진 경로다.
그런데 이번에는 Xid가 없었다.
# gpu-node-1: 실험 이후 Xid 기록 없음
$ journalctl -k --no-pager --since '2026-04-21' | grep -iE 'NVRM|Xid'
# (출력 없음)
과거 Xid 기록은 3월에 존재했지만(이전 NCCL 버전 시절의 잔재), 이번 실험 시점에서는 새로운 Xid가 발생하지 않았다.
# gpu-node-1: 과거 Xid는 3월에 존재 (이전 NCCL 버전 시절)
$ journalctl -k --no-pager | grep -iE 'NVRM|Xid' | tail -3
Mar 29 12:05:05 gpu-node-1 kernel: NVRM: Xid (PCI:0000:2a:00): 13, Graphics SM Warp Exception ...
Mar 29 12:05:05 gpu-node-1 kernel: NVRM: Xid (PCI:0000:2a:00): 13, Graphics SM Global Exception ...
Mar 29 12:05:05 gpu-node-1 kernel: NVRM: Xid (PCI:0000:2a:00): 43, pid=XXXXXX, name=ray::<train-worker> ...
본 사건의 journalctl 범위에서는 Xid가 관측되지 않았다. 이는 Xid 없이도 phantom GPU utilization이 발생할 수 있다는 가능성을 시사하지만, Xid가 다른 채널(ring buffer 오버플로, 캡처 윈도우 밖 등)로 기록되었을 가능성을 완전히 배제하지는 못한다.
기존에 팀 내에서 알려진 phantom 경로는 “Xid 43(channel reset) → GR 엔진 복귀 실패”로, hardware fault가 선행 조건이었다. 그러나 이번 현상을 통해 확인한 결과, hardware fault 증거(Xid) 없이 software 경로(SIGKILL에 의한 orphaned context)만으로도 driver가 compute engine을 busy로 유지할 수 있는 것으로 보인다.
즉 “phantom = hardware 에러의 후유증”이라는 기존 전제가 항상 성립하지는 않을 수 있다는 것이다.
팀원 선례와의 비교
이전에 팀원이 동일한 증상을 겪고 내부 문서로 정리해 둔 사례가 두 건 있었다.
Xid 13/43에 의한 유령 util
첫 번째는 NCCL 빌드 시 sm_120(Blackwell) 커널이 포함되지 않은 상태에서 해당 GPU를 사용하면서 발생한 illegal memory access가 트리거한 사례다(NCCL cuda12.2 빌드에 sm_120 미포함 → Blackwell GPU에서 커널 미스매치). 이 문제의 원인과 해결 과정은 NCCL Communicator Lazy Init 디버깅과 GPU 호환성 게이트에서 다뤘다. dmesg에 Xid 13/43이 기록되었고, GR(Graphics) 엔진이 Xid 43 리셋 이후 idle 상태로 복귀하지 못하면서 GPU-Util이 100%에 고정되었다. 노드 재부팅으로 해결했다.
| 항목 | 팀원 Xid 사례 | 이번 사례 |
|---|---|---|
| 트리거 | NCCL 버전 불일치 → illegal memory access | validation 에러 → Pod 비정상 종료 |
| dmesg Xid | Xid 13 + Xid 43 있음 | Xid 없음 |
| 추정 원인 | GR 엔진 stuck (Xid 43 리셋 후 복귀 실패) — dmesg Xid로 뒷받침 | orphaned CUDA context (SIGKILL) — 유력 가설, driver 측 직접 증거 없음 |
| 증상 | 100%, 0 MiB, P0, ~104W | 100%, 0 MiB, P0, ~114W — 동일 |
| 규모 | 1개 GPU | 14개 GPU |
| 해결 | 노드 재부팅 | 새 워크로드 배치로 현상적 해소 |
증상은 완전히 동일하지만, 원인 경로가 다르다. 팀원 사례는 “Xid → GR 엔진 stuck”이 명확한 반면, 이번에는 Xid 없이 orphaned context만으로 동일 현상이 발생한 변종 시나리오다.
완료된 RayJob에 의한 GPU 점유 누수
두 번째는 별개의 이슈다. RayJob CR에 shutdownAfterJobFinishes: true가 설정되지 않아, Job이 끝났는데도 RayCluster가 GPU를 계속 점유하고 있던 경우다. 이것은 K8s 스케줄러 레벨의 GPU 할당 누수로, 드라이버 레벨의 phantom utilization과는 다른 문제다. 다만, 이 사건에서 파드를 삭제한 직후 phantom utilization이 함께 관측되면서 두 이슈가 같은 시점에 동시 발생했다. 원인은 각각 독립적(K8s 스케줄러 레벨 할당 누수 vs driver 레벨 stuck)이지만 타이밍이 겹쳐 하나의 문제처럼 보였다.
배제되지 않는 다른 가설들
본 사건은 “SIGKILL + orphaned CUDA context”를 유력 가설로 두고 풀었지만, 동일 시그니처(100%, 0 MiB, P0 stuck, process 없음)를 만들 수 있는 다른 메커니즘이 더 있다. 본 사건에서 이들을 직접 검증·배제한 것은 아니므로, 가설 후보로만 정리해 둔다.
| 가설 | 핵심 메커니즘 | phantom을 만드는 경로 | 본 사건에서의 상태 |
|---|---|---|---|
| GSP firmware stuck | GPU 내부 마이크로프로세서(GSP)가 hang | GSP가 멈추면 호스트가 GPU 상태를 바꿀 수 없어 P0/active 상태에 고정 | 미검증 — GSP 측 진단 미수행 |
| PCIe power-state 전이 실패 | GPU의 전력 상태 변경이 실패 | 워크로드 종료 후 P0→P8 전이가 실패해 고클럭/고전력에 stuck | 미검증 — PCIe 이벤트 미수집 |
| Telemetry/accounting stuck | 실제로는 idle인데 보고만 잘못됨 | 드라이버/펌웨어의 카운터 버그로 NVML이 100%를 반환 | 미검증 — 실제 SM 활동 교차검증 불가 |
| SIGKILL 없이도 발생 (외부 사례) | 부팅 직후 idle에서도 관측 | 원인 불명 — job termination과 무관한 경로 존재 | 본 사건 가정의 반례 |
각 가설 상세 설명
GSP(GPU System Processor) firmware stuck
GSP는 NVIDIA GPU 내부에 탑재된 별도의 마이크로프로세서(RISC-V 기반)다. Open Kernel Module 아키텍처에서는 드라이버 로직의 상당 부분 — GPU 초기화, 전력 관리, 에러 처리, 보안 등 — 이 호스트 CPU의 커널 모듈이 아니라 이 GSP firmware 위에서 실행된다. 호스트 드라이버와 GSP 사이는 메시지 기반으로 통신하는데, GSP가 hang/timeout되면 호스트가 GPU 상태를 변경하는 명령 자체가 처리되지 않는다. 본 환경은 580.126.09 + NVIDIA Open Kernel Module + Blackwell(sm_120) 조합이고, NVIDIA Open GPU Kernel Modules GitHub 이슈에는 이 조합에서 GSP timeout이 보고된 사례가 있다. 본 사건에서는 nvidia-smi -q -d FIRMWARE, dmesg | grep -i gsp 같은 GSP 측 진단을 수행하지 못했다.
PCIe power-state 전이 실패
GPU는 PCIe 버스를 통해 호스트와 연결되며, 전력 절약을 위해 D0(active) ↔ D3cold(sleep) 등 전력 상태를 오간다. 워크로드가 끝나면 GPU가 D0에서 저전력 상태로 전이해야 하는데, 이 전이가 실패하면 P0(최고 성능)/고클럭에 stuck된다. Open-driver 이슈에 “프로세스 없음 + idle 전력 비정상 + clock stuck” 시그니처가 본 사건과 유사하게 보고되어 있다.
Telemetry/accounting 자체의 stuck
GPU 엔진은 실제로 idle인데, NVML이 읽어 오는 utilization 카운터 자체가 잘못된 값을 반환하는 경우다. 드라이버/펌웨어 측 telemetry 모듈의 버그로, 실제 SM 활동과 무관하게 카운터가 높은 값에 고정될 수 있다. dmon의 sm 100% / mem 0% 패턴은 실제 연산이 없는데 보고만 100%인 telemetry stuck으로도 나타날 수 있는 시그니처다.
외부 유사 사례 — SIGKILL 없이도 발생
본 글 참고 자료에 인용한 NVIDIA Developer Forum thread는 부팅 직후 idle 상태에서도 phantom util이 관측된 사례를 다룬다. “job termination이 트리거다”라는 본 사건의 가정 자체에 대한 반례이므로, “SIGKILL 경로만이 유일한 원인 경로”라는 단정은 피하는 편이 안전하다.
본 사건에서 “SIGKILL + orphaned context” 가설을 1순위로 둔 이유는 (1) Pod 비정상 종료 실험 회차와 phantom 발생의 시간적 근접, (2) 새 CUDA context 생성으로 해소된 정황이며, 위에서 나열한 다른 가설들이 직접 부정된 것이 아니라는 점을 다시 밝혀 둔다.
즉시 대응
nvidia-smi -r 시도 → 실패
가장 먼저 시도한 것은 GPU reset(nvidia-smi --gpu-reset)이다. 이것은 드라이버 재시작이 아니라, 커널 모듈은 유지한 채 개별 GPU 디바이스의 하드웨어 상태를 초기화하는 명령이다.
# gpu-node-1 GPU reset 시도 → 실패
$ sudo nvidia-smi -r
The following GPUs could not be reset:
GPU 00000000:17:00.0: In use by another client
GPU 00000000:2A:00.0: In use by another client
... # 8개 GPU 전부
8 devices are currently being used by one or more other processes
4개 노드 전부 동일한 결과. nvidia-smi에서 프로세스가 안 보이는데 “In use by another client”라고 한다.
lsof로 device 파일을 점유하고 있는 프로세스를 확인했다.
# nvidia-persistenced가 모든 GPU device를 점유
$ sudo lsof /dev/nvidia0 /dev/nvidia1 /dev/nvidiactl 2>/dev/null
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nvidia-pe 1639 nvidia-persistenced 4u CHR 195,255 0t0 749 /dev/nvidiactl
nvidia-pe 1639 nvidia-persistenced 5u CHR 195,0 0t0 750 /dev/nvidia0
nvidia-pe 1639 nvidia-persistenced 6u CHR 195,0 0t0 750 /dev/nvidia0
... # GPU 0~7 전부 nvidia-persistenced가 점유
nvidia-smi -r의 공식 조건은 “해당 GPU를 사용 중인 application이 없을 것”으로, 본 사건에서 관측된 blocker는 nvidia-persistenced였다. 본 데몬이 모든 device handle을 보유하고 있어 reset이 실패한다. NVLink topology 같은 다른 reset 제약도 존재할 수 있지만, 본 사건에서 직접 부딪힌 blocker는 이 데몬이다. K8s GPU Operator 환경에서는 이 데몬이 항상 실행되므로, 단순 GPU reset으로는 phantom utilization을 해소할 수 없다.
nvidia-persistenced가 GPU reset을 막는 이유
nvidia-persistenced는 GPU driver 커널 모듈을 항상 로드 상태로 유지하는 데몬이다.
Linux 커널 모듈은 reference count로 관리된다. /dev/nvidia* 디바이스 파일을 열고 있는 프로세스가 없으면 reference count가 0이 되고, 이 상태에서 rmmod 등으로 모듈을 제거할 수 있게 된다(자동으로 내려가지는 않지만, 제거 가능한 상태가 된다). 문제는 NVIDIA 드라이버 초기화가 비싸다는 것이다 — GPU 펌웨어 로드, 메모리 설정 등으로 수 초가 걸린다. 모듈이 내려갔다가 다시 올라가면 다음 CUDA 호출에서 이 초기화 비용을 다시 치러야 한다.
nvidia-persistenced는 /dev/nvidia*를 항상 열어 두어 reference count가 0이 되지 않게 막음으로써, 드라이버 모듈이 제거 가능한 상태에 빠지는 것 자체를 방지한다. K8s GPU 노드에서는 nvidia-device-plugin, dcgm-exporter와 함께 GPU Operator가 관리하는 필수 데몬이다.
문제는, 이 데몬이 항상 모든 GPU의 device handle을 보유하고 있다는 점이다. nvidia-smi -r은 해당 GPU의 device handle이 0개일 때만 실행 가능하므로, nvidia-persistenced가 살아 있는 한 GPU reset은 실패한다.
Persistence Mode 활성화 → 이미 stuck된 건 미해소
Persistence Mode를 켜면 cleanup이 개선될 가능성이 있다는 비공식 조언을 보고 시도했다. 다만 NVIDIA 공식 문서는 Persistence Mode를 “no clients일 때 GPU를 initialized 상태로 유지”로만 정의하며, context lifecycle 관리/orphan 자동 회수 개선을 공식 효과로 보장하지는 않는다 — 즉 이 시도는 메커니즘이 검증된 처방이라기보다 “켜 두면 손해는 없는 옵션”에 가깝다.
# Persistence Mode 활성화
$ sudo nvidia-smi -pm 1
Enabled persistence mode via daemon for GPU 00000000:17:00.0.
... # 8개 전부 Enabled
All done.
활성화 자체는 성공했지만, 본 사건에서 이미 stuck된 GPU의 phantom utilization은 해소되지 않았다. Persistence Mode가 “향후” 프로세스 종료 시 orphaned context를 더 잘 정리하는 역할인지는 본 사건만으로는 단언하기 어렵다(공식 문서에 그렇게 명시되어 있지 않다). 분명한 것은 이미 stuck된 상태를 풀어 주지는 못한다는 점이다.
참고: nvidia-persistenced 데몬 vs Persistence Mode
이 노드에는 이미
nvidia-persistenced데몬이 실행 중이다(앞서lsof에서 확인). 그런데 왜 별도로 Persistence Mode를 켜는가? 둘은 “persistence”라는 목표는 같지만 메커니즘이 다르다.
nvidia-persistenced데몬:/dev/nvidia*파일 디스크립터를 항상 열어 두어 커널 모듈의 reference count가 0이 되지 않게 막는다. 목적은 드라이버 모듈이 unload되는 것을 방지하는 것이다(모듈 레벨).- Persistence Mode (
nvidia-smi -pm 1): GPU 디바이스 자체를 항상 initialized 상태로 유지하는 per-GPU 설정이다. 클라이언트가 없어도 GPU가 uninitialized 상태로 내려가지 않는다(디바이스 레벨).데몬이 돌고 있어도 Persistence Mode를 명시적으로 켜는 것은 중복이 아니라, “모듈 유지” 위에 “디바이스 레벨 초기화 상태 유지”를 추가로 보장하는 조치다. 다만 두 방식 모두 context lifecycle/orphan 자동 회수에 대한 영향을 공식 문서에서 명확히 보장하지 않는다.
노드 재부팅 → 시도하지 않음
팀원의 Xid 13/43 선례에서는 노드 재부팅으로 해결했고, 이번에도 확실한 해소 방법이었다. 그러나 재부팅하면 원인을 파악할 증거가 사라지기 때문에 요청하지 않았다.
다시 한 번 강조하지만, 이 판단이 가능했던 것은 실험 환경이었기 때문이다. 해당 노드들이 실험 전용이었고, phantom GPU가 다른 팀의 학습을 blocking하고 있지 않았다. 운영 환경이라면 원인 분석보다 서비스 복구가 우선이므로, 비즈니스 임팩트를 최소화하는 방향 — drain 후 재부팅, 또는 nvidia-persistenced 재시작(본 사건에서 직접 검증하지는 않았다) — 을 먼저 선택해야 한다.
새 워크로드 배치: 현상적 해소
재부팅 대신, phantom이 실제 운영에 어떤 악영향을 미치는지 — GPU utilization이 전부 100%가 되면 스케줄링에 영향을 주는지, 스케줄링은 되더라도 워크로드 실행에 문제가 생기는지 — 를 확인하기 위해 학습을 계속 돌렸다.
K8s 스케줄러는 phantom utilization을 인식하지 못했다 — GPU resource request/limit만 보고 배치하기 때문이다. Phantom 상태이던 GPU 위에도 새 워크로드가 정상적으로 배치되었고, 놀랍게도 정상 동작했다. 이전에 phantom이었던 GPU가 P0(stuck) → P1(정상 compute)으로 전환되고, 메모리도 정상 할당되었다.
그런데 엉뚱하게도, 학습을 돌리고 나니 phantom이 해소되어 있었다. 의도한 것이 아니라 결과론적으로 알게 된 사실이다.
왜 해소되었는지에 대해서는 추측만 가능하다. 두 가지 가설이 있다.
- 가설 A — 새 context 요청이 reset trigger 역할: 새 프로세스가 같은 GPU에 CUDA context를 요청하면 driver가 compute engine 상태를 재초기화해야 하는데, 이 과정에서 orphaned context의 stuck 상태가 덮어쓰여졌을 수 있다. 즉 driver에 cleanup 코드 자체는 있지만, 프로세스 종료 시점에 자발적으로(proactive) 실행하지 않고 새 context 요청이라는 외부 트리거가 있어야만 동작하는 구조일 가능성이다.
- 정상적인 경우라면 driver가 프로세스 종료를 감지하고 orphaned context를 자동 회수해야 한다(배경 지식 섹션에서 “should be destroyed”로 인용한 기대). 대부분의 CUDA 프로그램은 명시적으로
cuCtxDestroy()를 호출하지 않아도 되는데, 정상 종료 시에는 런타임의atexithook/destructor가 알아서 처리해 주기 때문이다. 문제는 SIGKILL처럼 아무 cleanup도 실행되지 않는 경로뿐이며, 이 경로에서 driver가 회수에 실패한 것이 본 사건이다. - 이것을 “driver bug”가 아니라 “설계 한계”로 표현한 이유: “cleanup 코드가 깨졌다”는 것이 아니라 “cleanup을 발동시키는 trigger 조건이 빠져 있다”는 뉘앙스다. 사용자 입장에서는 bug나 다름없지만, 원인 파악의 관점이 다르다 — bug라면 “코드를 고쳐 달라”이고, 설계 한계라면 “외부에서 trigger를 만들어 주는 workaround를 써야 한다”이다
- 정상적인 경우라면 driver가 프로세스 종료를 감지하고 orphaned context를 자동 회수해야 한다(배경 지식 섹션에서 “should be destroyed”로 인용한 기대). 대부분의 CUDA 프로그램은 명시적으로
- 가설 B — 시간 경과에 의한 자체 회수: phantom 관측 시점부터 새 워크로드 배치까지의 wall-clock gap이 길었다면, driver/firmware 측 timeout이 그 사이 발동해 이미 회수되었고 우연히 그 직후 워크로드를 배치한 것일 수 있다
아쉽게도 phantom 해소 시점의 wall-clock을 기록해 두지 않아, “새 context가 trigger였는지”(A)와 “이미 자체 회수된 뒤였는지”(B)를 구분할 수 없다.
어플리케이션 코드 단 재발 방지 시도와 재검토
1차 시도: try/finally CUDA cleanup — 한계
현상적 해소 이후, 재발 방지를 위해 가장 먼저 시도한 것은 학습 코드에 try/finally 블록을 추가해 CUDA cleanup을 보장하는 것이었다.
# 1차 시도 — SIGKILL 경로에서는 실행되지 않는다
def train_func(config):
try:
runner = build_runner(config)
runner.train()
finally:
if torch.cuda.is_available():
torch.cuda.empty_cache()
if dist.is_initialized():
dist.destroy_process_group()
이 변경 이후 단기적으로 새로운 phantom이 재현되지 않아 처음에는 효과가 있는 것처럼 보였다. 그러나 다시 따져 보면 이 접근은 본 사건의 발생 경로를 직접 막을 수 없다.
- 본문에서 분석한 트리거 경로는 “NCCL collective blocking → SIGTERM 무시 → grace period 초과 → SIGKILL”이다.
try/finally가 동작하려면 (a) try 블록 안에서 예외가 발생하거나, (b) try 블록이 정상 완료되거나, (c) signal handler가 예외를 raise하는 — 세 가지 중 하나가 일어나야 한다. 그래야 Python 인터프리터가 finally 블록으로 진입한다.- NCCL collective blocking 중에 SIGKILL이 오면: C++ 안에서 대기 중이므로 예외가 Python으로 올라오지 않고, SIGKILL은 커널이 프로세스를 즉시 제거하는 것이므로 어떤 Python 코드도 실행되지 않는다. 결과적으로 finally 블록 진입 자체가 불가능하다.
- 앞서 정리한 대로 SIGKILL 경로에서는
atexit도,try/finally도, destructor도 실행되지 않는다. - 따라서 cleanup 코드가 실행되려면 그 전에 프로세스가 정상 종료 경로(graceful exit)로 들어와야 하는데, NCCL blocking 상태에서는 그 진입 자체가 막힌다.
즉 try/finally는 정상 종료/일반 예외 경로의 기본 방어일 뿐, phantom 방지의 본선이 될 수 없다. 변경 이후 phantom이 재현되지 않은 것도 try/finally의 효과라기보다는, validation 에러가 사라져 SIGKILL 경로 자체를 타지 않았기 때문으로 보는 편이 정합적이다.
더 적합해 보이는 방향(미검증): NCCL collective를 abort 가능한 상태로 만들기
이 한계를 인지한 후 자료를 찾아본 결과, 진짜로 막아야 할 것은 cleanup 코드 부재가 아니라 NCCL collective가 무한 대기에 빠져 SIGTERM이 무시되는 상태라는 결론에 도달했다. 이를 해소하려면 cleanup 코드를 늘리는 게 아니라, collective 자체에 timeout과 async error handling을 걸어 Python 레이어로 예외가 올라오도록 만드는 방향이 더 그럴듯해 보였다. 다만 본 사건 이후 실제로 이 옵션을 적용해 검증한 것은 아니므로, 아래는 “조사 결과 제안 가능한 방향(미검증)” 정도로 두는 것이 적절하다.
대략의 코드 형태는 다음과 같다.
# 미검증안 — collective에 timeout/async error handling 부여
import os
from datetime import timedelta
import torch.distributed as dist
# NCCL collective가 hang에 빠지면 communicator를 abort. 동작은 PyTorch 버전에 따라
# "예외로 승격" 또는 "프로세스 teardown"으로 달라진다 (아래 주의 참고).
os.environ.setdefault("TORCH_NCCL_ASYNC_ERROR_HANDLING", "1")
# PyTorch 최신 권장 이름은 TORCH_NCCL_BLOCKING_WAIT, legacy는 NCCL_BLOCKING_WAIT.
# 사용 중인 버전 문서를 반드시 확인.
dist.init_process_group(
backend="nccl",
timeout=timedelta(hours=<TBD>), # 워크로드별로 산정 필요. 아래 주의사항 참고
)
init_process_group(timeout=...)이 NCCL collective의 wall-clock 상한을 정의한다. 이 시간을 넘기면 PyTorch가 NCCL communicator를 abort한다. 단, abort 이후의 동작은 PyTorch 버전에 따라 다르다 — 최신 공식 문서(PyTorch 2.x 계열)는 TORCH_NCCL_ASYNC_ERROR_HANDLING=1을 “abort communicator and tear down process”로, NCCL timeout을 “collectives aborted asynchronously and the process will crash”로 설명한다. 즉 Python 예외로 깔끔히 복귀해 try/finally를 실행시켜 주는 보장은 없으며, 버전/모드 조합에 따라 프로세스가 그대로 종료(crash)되는 경로가 더 자연스러울 수 있다.
따라서 이 방향이 의도하는 효과 — “collective abort → Python 예외 → cleanup 코드 실행 기회” — 가 사용 중인 PyTorch/NCCL 버전에서 실제로 보장되는지는 별도 검증이 필요한 영역이다. 본 글은 이 옵션을 적용/검증한 단계까지는 가지 못했으므로, 권장 가이드라기보다 후속 검토가 필요한 방향 정도로 두는 것이 적절하다. 검증 시에는 의도적으로 NCCL collective hang을 재현(예: 한 worker를 의도적으로 kill)한 뒤, (a) 나머지 worker에서 timeout 이후 Python 스택으로 예외/종료가 올라오는지, (b) 종료 후 nvidia-smi 상에 phantom utilization이 남는지 두 가지로 판단한다. (b)가 깨끗하면 검증된 fix로 승격하고, (a)가 일어났는데 (b)에서 phantom이 또 발생한다면 SIGKILL 경로 외의 다른 메커니즘이 있다는 신호다.
다만 timeout 값은 환경/워크로드마다 다르며, 단순히 짧게 잡을수록 좋은 것이 아니다. 본 사건 워크로드의 학습 로그를 보면 step당 약 8초, 50 step에 약 7분, 한 에폭이 대략 3.6시간 수준이고, 그 사이에 validation/checkpoint upload(S3) 같은 구간이 끼면 일부 rank가 collective 안에서 수 분~수십 분 머무는 것은 정상 동작이다.
참고: 본 워크로드 학습 로그 발췌
(RayTrainWorker pid=XXX, ip=10.x.x.x) [S3] Uploaded /app/work_dirs/<model>/epoch_16.pth -> s3://<bucket>/ray-checkpoints/<run-id>/<model>/epoch_16.pth
(RayTrainWorker pid=XXX, ip=10.x.x.x) [S3] Deleted old checkpoint: s3://<bucket>/ray-checkpoints/<run-id>/<model>/epoch_13.pth
(RayTrainWorker pid=XXX, ip=10.x.x.x) 05/10 19:51:31 - mmengine - INFO - Epoch(train) [17][ 50/1563] ... time: 8.5176 data_time: 0.2987 ...
(RayTrainWorker pid=XXX, ip=10.x.x.x) 05/10 19:58:21 - mmengine - INFO - Epoch(train) [17][ 100/1563] ... time: 8.2140 data_time: 0.0635 ...
(RayTrainWorker pid=XXX, ip=10.x.x.x) 05/10 20:05:15 - mmengine - INFO - Epoch(train) [17][ 150/1563] ... time: 8.2670 data_time: 0.0578 ...
(RayTrainWorker pid=XXX, ip=10.x.x.x) 05/10 20:12:07 - mmengine - INFO - Epoch(train) [17][ 200/1563] ... time: 8.2546 data_time: 0.0614 ...
(RayTrainWorker pid=XXX, ip=10.x.x.x) 05/10 20:19:05 - mmengine - INFO - Epoch(train) [17][ 250/1563] ... time: 8.3535 data_time: 0.0644 ...
50 step 간격이 약 6분 50초~7분, step당 평균 약 8.3초 → 1 epoch(1,563 step) ≈ 3.6시간. 에폭 경계에서는 checkpoint S3 업로드와 validation이 끼므로 rank별 collective 대기가 추가로 길어질 수 있다. 즉 “10분”은 본 워크로드 기준으로는 너무 짧다.
이런 환경에서 timeout을 무턱대고 짧게 잡으면 정상 collective까지 abort되어 학습이 죽는다. 따라서 다음 조건을 모두 만족하도록 운영 SLO에 맞춰 산정해야 한다.
- 정상 collective의 최대 지속 시간보다 충분히 길 것 — validation/checkpoint write/eval rollout 등 GPU가 잠시 멈춰 보일 수 있는 구간을 모두 포함
- 단, 무한대로 두지는 말 것 — hang을 abort로 끊을 수 없으면 결국 SIGTERM 무시 → SIGKILL 경로로 회귀
- rank 간 데이터 편차가 큰 워크로드(예: variable batch, dynamic shape)에서는 더 보수적으로 산정
또한 TORCH_NCCL_ASYNC_ERROR_HANDLING / NCCL_BLOCKING_WAIT 류 환경변수는 PyTorch/NCCL 버전에 따라 이름과 동작이 모두 달라지는 영역이다. 최신 PyTorch 문서는 TORCH_NCCL_BLOCKING_WAIT를 권장 이름으로 두고 NCCL_BLOCKING_WAIT은 legacy alias로 받는 경향이 있으며, TORCH_NCCL_ASYNC_ERROR_HANDLING의 mode 값별 의미도 마이너 버전 단위로 바뀐 사례가 있다. 사용 중인 버전의 공식 문서를 직접 확인하는 것이 안전한 영역이다 — 이 역시 본 사건에서 검증한 범위 밖이다.
정리하면, 1차 시도와 이 방향은 서로 대안이 아니라 선행 조건(collective abort 가능 상태) → 후행 기본 방어(cleanup) 의 관계로 묶어야 한다. 1차 시도만 단독으로 적용하면 실제 phantom을 일으키는 SIGKILL 경로에는 손이 닿지 않는다는 점이, 이 사건에서 얻은 가장 분명한 교훈이다.
정리
근본 원인은 미해결: 더 파야 한다
이 사례의 핵심 질문은 “왜 driver가 orphaned CUDA context를 자동 회수하지 못했는가?“이다. 앞서 본 것처럼 새 워크로드를 돌리면서 현상은 해소되었지만, 현상 해소가 곧 원인 해소는 아니다.
본문에서 도출한 유력 가설은 “SIGKILL에 의해 CUDA context cleanup이 실행되지 않았고, orphaned context가 driver의 compute engine을 busy로 유지했다”이다. 원인 분석에서 정리한 정황 증거(시간적 근접, Xid 부재, 새 context에 의한 해소)가 이 가설을 뒷받침하지만, leaked context를 직접 가리키는 driver 측 증거는 확보하지 못했다. 본 관찰은 580.126.09 + sm_120 + CUDA 13.0 조합에 한정되며, 동일 조건에서의 재현 시도도 아직 수행하지 않았다.
이 질문은 열어 둔다. 드라이버 업데이트 시 동일 시나리오를 재현해 볼 것이고, NVIDIA Open Kernel Module 소스에서 context 회수 경로를 추적하는 것도 검토하고 있다.
그럼에도 이번 사례를 통해 얻은 진단 휴리스틱과 방어선은 정리할 가치가 있다.
재발 방지 계층
Phantom GPU utilization의 발생 자체를 줄이기 위한 방어선을 세 계층으로 정리한다.
| 계층 | 조치 | 효과 |
|---|---|---|
| 애플리케이션 | 비정상 종료 원인 제거 (학습 코드 에러 핸들링 보강) | 비정상 종료 자체를 방지 → orphaned context 미발생 |
| 워크로드 (1) — 기본 방어 | train_func try/finally CUDA cleanup, Pod terminationGracePeriodSeconds 확보, RayJob shutdownAfterJobFinishes: true |
정상 종료/예외 경로 한정 cleanup 기회. SIGKILL 경로는 막지 못함 |
| 워크로드 (2) — collective abort (미검증) | NCCL timeout + async error handling으로 collective blocking 해소 → SIGTERM 처리 가능 상태 확보 | SIGKILL 경로 진입 자체를 줄임. 워크로드 (1)과 결합해야 cleanup까지 완결 |
| 플랫폼 | Persistence Mode 상시 활성화 | orphaned context 발생 빈도 감소 (공식 보장은 아님) |
워크로드 (1)의 try/finally는 NCCL timeout(워크로드 (2))과 결합되어야 SIGKILL 경로의 phantom 방지에 닿을 수 있다. 단독 적용 시 한계는 1차 시도 절에서 상세히 다룬다.
애플리케이션 계층 해결이 가장 효과적이다. 비정상 종료가 일어나지 않으면 orphaned context도 발생하지 않는다. 워크로드와 플랫폼 계층은 “비정상 종료가 일어나더라도 피해를 줄이는” 방어선이다.
모니터링: Phantom 탐지 규칙 (미검증 초안)
재발 방지와 별개로, phantom이 발생했을 때 빠르게 감지하기 위한 모니터링 규칙을 검토할 수 있다. 다만 이 글 시점에서는 실제 알람으로 검증한 것이 아니라 초안 수준임을 먼저 밝혀 둔다.
가장 단순한 형태는 다음과 같다.
# 단순안 — false positive가 많아 그대로 쓰면 안 된다
alert: PhantomGPUUtilization
expr: DCGM_FI_DEV_GPU_UTIL > 95 and DCGM_FI_DEV_FB_USED < 100
for: 5m
문제는 GPU Utilization의 정의 섹션에서 짚었듯 GPU-Util은 시간 기반 측정이라 메모리 사용량과 직접적인 상관이 없다는 점이다. 다음과 같은 정상 워크로드도 이 조건을 그대로 만족한다.
- 메모리 풋프린트가 작은 compute-bound 커널(작은 batch, 작은 모델, kernel-only 마이크로벤치마크, small CNN inference 등): SM을 지속적으로 점유하면서도 framebuffer는 거의 쓰지 않아 두 조건 모두 만족
- quantized/sparse 모델이나 sparse matrix operation 등 연산 밀도는 높지만 working set이 작은 워크로드
즉 단순안은 phantom과 “메모리 적게 쓰는 정상 워크로드”를 구분하지 못한다. 알람으로 운영하면 false positive가 잦아져 룰 자체가 신뢰를 잃기 쉽다. 본 사건의 dmon 시그니처를 룰로 옮긴다면, 다음 특징을 조합하는 편이 더 적은 false positive를 낼 것으로 보이지만, 실제 알람 운영으로 검증한 것은 아니다.
| 시그널 | 정상 워크로드 | Phantom |
|---|---|---|
GR 엔진 activity (DCGM_FI_PROF_GR_ENGINE_ACTIVE) |
부하에 비례 | 100% 고정(가설상) — 수집 시 1차 식별자 |
SM activity (DCGM_FI_PROF_SM_ACTIVE) |
부하에 비례 | 100% 고정 |
DRAM/메모리 activity (DCGM_FI_PROF_DRAM_ACTIVE) |
0보다 큼 | 0% 고정 |
코어/메모리 클럭 (DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_MEM_CLOCK) |
부하에 따라 변동 | 최대값 stuck |
Performance state (DCGM_FI_DEV_PSTATE) |
P0~P8 변동 | P0 stuck |
| GPU device 위의 실행 프로세스/Pod | 존재 | 부재 (지속적) |
참고: 이 시그니처를 그대로 룰로 쓰기 전에
위 표에서 가장 직접적인 phantom 식별자는 사실 따로 있다. DCGM에는
DCGM_FI_PROF_GR_ENGINE_ACTIVE라는 별도 metric이 있고, “GR(graphics/compute) 엔진이 active로 보고된 시간 비율”을 의미한다. 본 글에서 잠정 채택한 가설인 “엔진이 active 상태로 stuck”을 가장 가깝게 보여주는 값이다. 본 사건에서는 이 metric을 따로 수집하지 못해SM_ACTIVE를 대신 썼다. 룰을 옮길 때 GR engine metric을 함께 보는 편이 가설과 더 정합적이다.또한
SM_ACTIVE = 100%가 항상 “GPU가 실제 연산을 풀로 한다”는 뜻은 아니다. DCGM 정의상 SM에 active warp이 하나라도 있으면 active로 카운트되며, 메모리 응답을 기다리며 대기 중인 warp까지 포함된다. 마찬가지로DRAM_ACTIVE가 0에 가까운 상태도, 작은 working set으로 도는 정상 compute-bound 커널에서 나타날 수 있다. 즉SM_ACTIVE높음 +DRAM_ACTIVE낮음 조합만 보고 phantom으로 단정하기는 어렵다.따라서 아래 시그니처는 본 사건 dmon 패턴을 잡으려는 heuristic으로 두는 편이 안전하다. “이 조건이면 phantom이다”는 일반 정의로 쓰면 정상 워크로드에서도 알람이 울리는 false positive가 잦아질 수 있다.
본 사건의 시그니처를 기준으로 이 시그널들을 함께 보면, phantom은 “SM은 100%인데 DRAM은 0%이고, P0/최대 클럭에 고정되어 있으며, 해당 GPU 위에 어떤 Pod도 스케줄되어 있지 않은 상태가 충분히 오래 지속“되는 경우로 좁힐 수 있을 것으로 보인다. 예시 룰은 아래와 같다 (역시 미검증 초안).
# 보강안 (미검증 초안)
alert: PhantomGPUUtilization
expr: |
DCGM_FI_PROF_SM_ACTIVE > 0.95
and DCGM_FI_PROF_DRAM_ACTIVE < 0.02
and DCGM_FI_DEV_FB_USED < 100
and DCGM_FI_DEV_PSTATE == 0
# 해당 GPU(uuid/pci)에 매핑된 Pod가 없는 상태와 join 필요
for: 15m
핵심 디자인은 다음과 같다.
- SM은 높지만 DRAM은 0: 본 사건 dmon에서 관측된 phantom 시그니처. 정상 compute-bound 커널 중에도 동일 패턴을 보이는 경우가 있으므로(앞 박스 참고) 이 조합만으로 단정하지 말고, 아래 조건들과 함께 본다
- FB 메모리(framebuffer memory — GPU의 VRAM,
nvidia-smi의Memory-Used에 해당) 거의 0 + P0 stuck: orphaned context의 부수 시그널. 임계값(FB_USED < 100)은 본 사건의 phantom GPU가 모두Memory: 0~1 MiB였던 관측치를 기준으로 잡은 예시이며, 클러스터마다 정상 워크로드의 framebuffer 분포가 달라 baseline 측정 후 조정 필요 - 해당 GPU 위에 Pod 없음: 가장 강한 식별자. 정상 워크로드와 phantom을 결정적으로 가르는 신호이며, K8s 사이드의 GPU 할당 정보와 join해서 확인해야 한다
for: 15m또는 그 이상: 짧은 spike(짧게 메모리를 비우는 정상 케이스)와 구분하기 위해 지속 시간 윈도우를 충분히 길게 잡음. 본 사건의 phantom은 수 시간 단위로 stuck되어 있었으므로 15분도 보수적인 값이지만, alert latency 목표와 정상 워크로드의 일시적 idle 구간(예: validation/checkpoint upload)에 맞춰 조정하는 것이 안전하다
운영 환경마다 사용 가능한 DCGM 메트릭과 PromQL join 방식이 다르므로, 본 사건의 시그니처를 룰로 옮길 때는 자신의 클러스터에서 정상/phantom 두 케이스의 메트릭을 수집해 임계값을 조정하는 단계가 반드시 필요하다. 그 과정 없이 위 식을 그대로 붙이면 룰이 silent하거나 노이즈가 될 위험이 있다.
진단 휴리스틱
다음에 비슷한 증상을 만났을 때 무엇을 확인할 것인가 — 이번 사건에서 배운 진단 기준을 정리한다. 이 글이 실험 환경에서 작성되었다는 점을 다시 밝혀 둔다. 운영 환경에서 phantom GPU가 발견되면 먼저 해당 노드가 서비스에 미치는 영향을 파악하고, drain → 재부팅(또는 nvidia-persistenced 재시작(미검증))으로 복구한 뒤 원인 분석은 사후에 진행해야 한다.
- nvidia-smi GPU-Util만으로 GPU 상태를 판단하지 말 것. Phantom utilization처럼 util 100%가 항상 실제 사용을 의미하지는 않는다.
nvidia-smi dmon으로 SM activity, memory activity, clock frequency를 함께 확인해야 한다 - K8s GPU 노드에서는
nvidia-smi -r이 안 된다. nvidia-persistenced가 device handle을 잡고 있으므로, phantom utilization 해소에는 서비스 재시작이나 노드 재부팅이 필요하다 - 본 사건에서는 Xid 없이 phantom utilization이 관측되었다. 기존 문서가 Xid 13/43을 전제로 했지만, SIGKILL에 의한 orphaned context만으로도 동일 현상이 나타날 수 있는 것으로 보인다. 진단 시 Xid 부재만으로 “문제 없음”을 결론짓지 않는 편이 안전하다
재현 시 수집 계획
본 사건에서 직접 증거를 확보하지 못한 반성을 바탕으로, 다음에 같은 증상이 발생하면 아래 증거를 우선 수집한다.
| 수집 대상 | 명령어 | 확인할 수 있는 것 |
|---|---|---|
| Container exit code | kubectl get pod -o jsonpath='{.status.containerStatuses[*].lastState.terminated.exitCode}' |
137이면 SIGKILL 경로 직접 증거 |
| Kubelet termination timeline | kubectl get events --field-selector involvedObject.name=<pod> |
SIGTERM → grace period → SIGKILL 타임라인 |
| Compute app accounting | nvidia-smi -q -d ACCOUNTING |
종료된 프로세스의 잔여 record 유무 |
| GPU별 client process list | nvidia-smi -q -d PIDS |
NVML이 보고하는 client attachment 상태 |
| GSP firmware 상태 | nvidia-smi -q -d FIRMWARE 및 dmesg \| grep -iE 'gsp\|nvrm' |
GSP path stuck 가설 검증 |
| GR engine 활동 | dcgmi dmon -e 1001 (DCGM_FI_PROF_GR_ENGINE_ACTIVE) |
“엔진 stuck” 가설의 1차 식별자 |
추가 관찰: 새 워크로드에 의한 해소
본 사건에서는 phantom GPU 위에 새 워크로드를 배치하자 현상이 해소되었다. 새 CUDA context 생성이 orphaned context의 stuck 상태를 덮어쓴 것으로 추측되지만, 이것은 몇 차례 관찰에 기반한 우연한 발견이며 메커니즘이 규명된 것이 아니다. 다른 환경/드라이버 조합에서 동일하게 동작할 보장이 없으므로, 운영 환경에서 일반적 처방으로 적용하는 것은 권장하지 않는다.
참고 자료
- NVIDIA Developer Forum — nvidia-smi reports phantom utilization reported on one GPU — 유사 증상이 보고되어 있으나, 드라이버/아키텍처 조건이 본 사건과 달라 직접 비교는 보류
- NVML API Reference — nvmlDeviceGetUtilizationRates
- NVML API Reference — nvmlUtilization_t
- Lei Mao — NVIDIA NVML GPU Statistics
- Modal GPU Glossary — Streaming Multiprocessor Utilization
- Stack Overflow — CUDA context destruction at host process termination
- NCCL 트러블슈팅 회고
- NCCL Communicator Lazy Init 디버깅
- GPU 호환성 게이트: 빌드 타임과 배포 타임에서 NCCL 커널 미스매치 차단하기

댓글남기기