
[Kubernetes] Kubernetes 환경에서 NVIDIA GPU 사용하기 - NVIDIA Device Plugin
K8s 환경에서 GPU가 있는 노드를 사용하기 위해서는 Kubernetes version이 1.10 이상이어야 하며, 클러스터 내에 NVIDIA Device Plugin을 배포해야 한다.
- GPU 노드 Prerequisites
- NVIDIA driver 설치
- NVIDIA Container Runtime 설정: NVIDIA Docker 혹은 NVIDIA Container Toolkit 설치 → NVIDIA Container Toolkit을 설치할 예정
- NVIDIA Docker는 현재 deprecated로, NVIDIA Container Toolkit을 사용할 것을 권장하고 있음
- 게다가, NVIDIA Docker는 윈도우 환경에서 활용할 수 없음
- NVIDIA Container Toolkit 설치를 위한 NVIDIA 공식 가이드
- NVIDIA Docker는 현재 deprecated로, NVIDIA Container Toolkit을 사용할 것을 권장하고 있음
- Docker runtime으로 NVIDIA Docker container runtime 설정
- 쿠버네티스 클러스터에 NVIDIA GPU Device Plugin 배포: Helm을 이용해 배포할 예정
- 공식 제공되는 YAML 파일 직접 배포
- Helm을 이용한 배포
- 수동 배포
NVIDIA Device Plugin
Kubernetes 클러스터 환경에서 GPU를 활용할 수 있도록 해 주는 플러그인이다. NVIDIA에서 공식적으로 제공하는 Kubernetes Device Plugin 구현체이다.
- 쿠버네티스 클러스터에 GPU 사용 노드 노출
- GPU 헬스 체크
Kubernetes Device Plugin
Kubernetes에서 시스템 하드웨어 리소스를 사용하기 위해서는 kubelet에 하드웨어 리소스를 등록하여 파드를 해당 리소스가 있는 노드에 스케줄할 수 있게 해야 한다. 이를 위해 Kubernetes는 클러스터의 kubelet에게 시스템 하드웨어 리소스를 알릴 수 있도록 Device Plugin framework를 제공한다. 각 하드웨어 리소스 공급 업체는 Kubernetes가 제공하는 Device Plugin framework를 구현하기만 하면 된다.
말하자면 인터페이스인 셈인데, 공식 문서를 잠깐 참고하면, gRPC 기반 서비스인 것으로 보인다.
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device Manager.
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// GetPreferredAllocation returns a preferred set of devices to allocate
// from a list of available ones. The resulting preferred allocation is not
// guaranteed to be the allocation ultimately performed by the
// devicemanager. It is only designed to help the devicemanager make a more
// informed allocation decision when possible.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// PreStartContainer is called, if indicated by Device Plugin during registration phase,
// before each container start. Device plugin can run device specific operations
// such as resetting the device before making devices available to the container.
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
실제 NVIDIA Device Plugin 코드를 보면, 해당 인터페이스를 구현하고 있는 것을 확인할 수 있다.
NVIDIA GPU Device Plugin을 통한 동작 구조
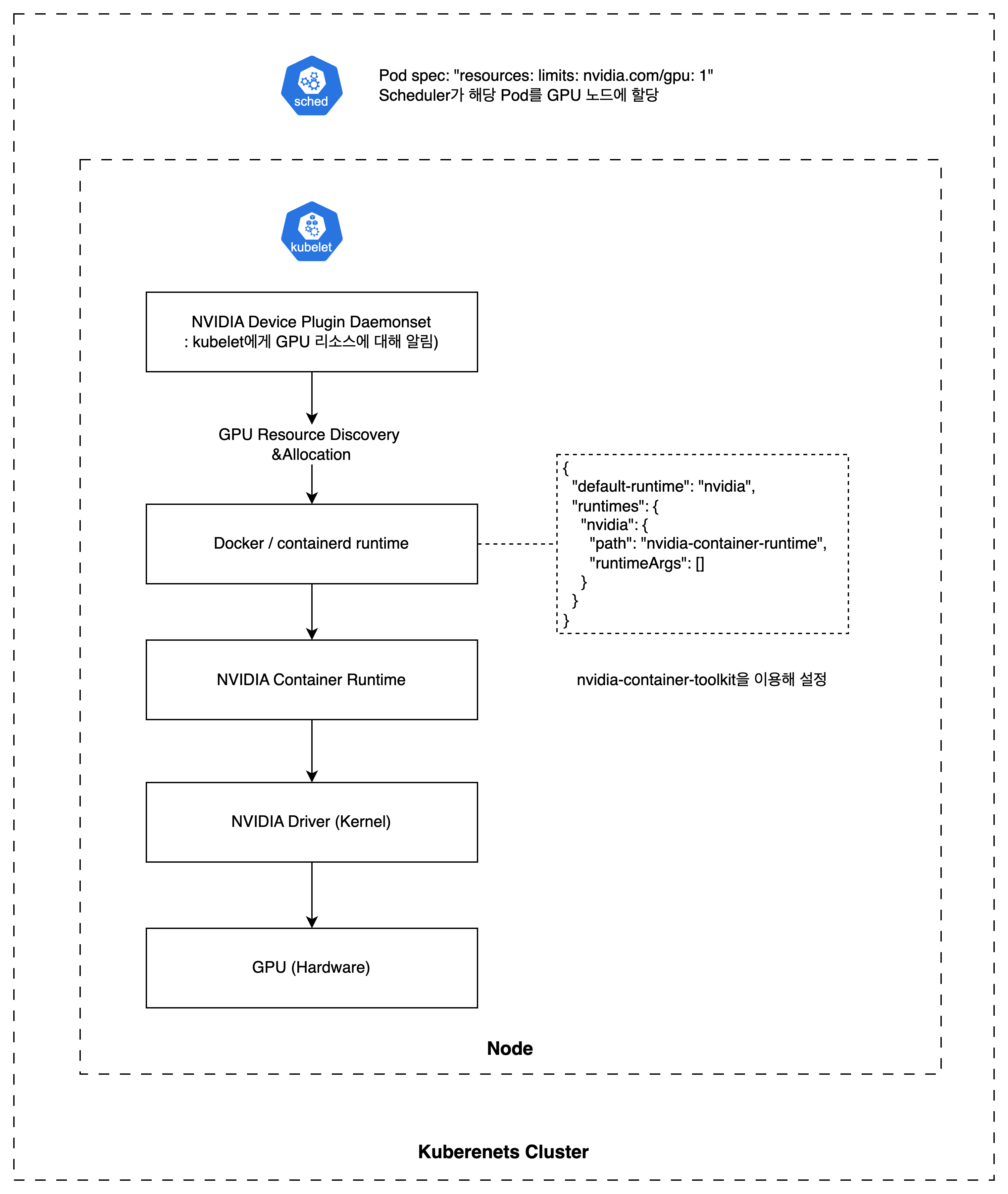
- GPU Hardware: 실제 물리 GPU 장치. GPU 물리 연산 수행
- NVIDIA Driver: 커널 레벨 드라이버 모듈. OS와 GPU 하드웨어 간 통신 담당. GPU 메모리 관리 및 명령 실행
- NVIDIA Container Runtime: 컨테이너 엔진(Docker, containerd 등) 런타임에 GPU 지원 연결
- 컨테이너 실행 시 GPU 환경 관련 정보 전달
- 컨테이너 실행 시 GPU 접근 권한 설정
- Dockerd/containerd: 컨테이너 런타임. CRI를 통해 Kubelet과 통신. NVIDIA Container Toolkit을 통해 NVIDIA Runtime 자동 연결
- Docker:
/etc/daemon.json에서 default runtime 지정 - containerd:
/etc/containerd/config.toml에서 nvidia runtime 설정
- Docker:
- Kubelet: NVIDIA Device Plugin과 통신. CRI를 통해 Container Runtime에 GPU 할당 정보 전달
- NVIDIA Device Plugin: Kubernetes GPU 리소스 등록
- ListAndWatch: 노드의 GPU 탐지 및
nvidia.com/gpu형태로 kubelet에 등록. kubelet에 실시간 상태 전달 - Allocate: Pod 스케줄링 시 특정 GPU 할당, 환경변수 설정 등등
- ListAndWatch: 노드의 GPU 탐지 및
GPU 노드 설정
Kubernetes에 배포하기 앞서, 컨테이너 환경에서 GPU를 인식할 수 있도록 해야 한다. 컨테이너 런타임이 GPU를 인식할 수 있도록 해야 한다.
[GPU Hardware]
↓
[NVIDIA Driver] ← Host 커널 모듈
↓
[nvidia-container-runtime]
↓
[Docker/containerd]
↓
[Container (ex: CUDA image)]
참고: k3s와 Docker Runtime
k3s는 기본적으로 containerd를 사용하지만,
--docker플래그를 통해 Docker를 런타임으로 사용할 수 있다. 본 글의 환경은 Docker 런타임을 사용하도록 설정된 k3s 클러스터이다. 그래서 앞으로의 설정 역시 Docker 컨테이너 런타임 기반으로 진행된다.다만, 이 경우 몇 가지 주의할 점이 있다:
- GPU Operator 등 containerd 기반으로 동작하는 도구들이 예상대로 동작하지 않을 수 있음
- k3s의 경량화 이점을 충분히 살리지 못함 (Docker 데몬이 추가로 실행되므로)
실제로 레거시 환경이나 기존 인프라와의 호환성을 위해 이렇게 구성된 클러스터가 종종 있고, 내가 사용한 클러스터 환경도 그 중 하나였다.
만약 새로운 환경을 구축한다면, k3s 기본 런타임인 containerd를 사용하고, 그에 맞는 NVIDIA Container Runtime 설정을 적용하는 것을 권장한다.
NVIDIA Driver 설치
공식 홈페이지
정식 NVIDIA 드라이버에서 맞는 버전의 파일을 다운 받은 후 설치한다.
chmod +x ./NVIDIA-Linux-x86_64-XXX.XXX.XX.run
sudo sh ./NVIDIA-Linux-x86_64-XXX.XXX.XX.run
package repository에서 설치
Ubuntu apt repository를 이용해서 설치해도 된다.
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-driver-XXX
# Building kernel modules ......
# An alternate method of installing the NVIDIA driver was detected. -> Continue installation
# Warning: nvidia-installer was forced -> OK
# Install Nvidia`s 32-bit campatibility libraries? -> NO
# WARNING: Unable to determine the path to install the libglvnd EGL vendor library config files. Check that you have pkg-config and the libglvnd development libraries installed, or specify a path with --glvnd-egl-config-path. -> OK
# Warning: This NVIDIA driver package includes Vulkan components -> OK
# Installing ......
# Would you like to run the nvidia-xconfig utility -> NO
# Installation of the NVIDIA Accelerated Graphics Driver -> OK
참고: 권장 버전 설치
sudo ubuntu-drivers autoinstall
참고: gcc 관련 에러 날 때
# ERROR: Unable to find the development tool 'cc' in your path; please make sure that you have the package 'gcc' installed...sudo apt-get update sudo apt-get upgrade sudo apt-get install build-essential
확인
드라이버 설치 시, nvidia-smi 프로그램이 함께 설치된다. nvidia-smi 명령어를 치고 결과가 나오는 것을 확인하면 된다.
nvidia-smi
# 무언가 출력되면 성공
(Optional) Linux 기존 NVIDIA Driver 삭제
Ubuntu나 다른 Linux 배포판에 기본적으로 Nouveau라는 오픈소스 NVIDIA 드라이버가 포함되어 있는데, 이것이 설치되어 있고 활성화되어 있다면 아래와 같이 삭제해 주어야 한다. 목적은, 시스템에서 기존 NVIDIA 드라이버 및 커널 모듈을 완전히 제거하고, Nouveau 충돌을 방지하여 새 드라이버 설치를 위한 깨끗한 환경을 만드는 것이다.
- Nouveau
- 커널에 내장된 오픈소스 드라이버
- 별도로 설치하지 않아도 배포 기본 설치파일에 깔려서 동작함
- 성능이 낮고, CUDA, TensorRT, GPU 연산을 지원하지 않음
- NVIDIA GPU Driver를 사용해야 AI 모델 학습 및 추론에 필요한 GPU 기능 사용 가능
- 만약 Nouveau가 설치되어 있다면, 커널에서 해당 드라이버가 GPU를 이미 점유하고 있기 때문에, 공식 NVIDIA 드라이버가 커널 모듈을 제대로 로드하지 못함
- 즉, 동시에 커널에 로드됨으로써 GPU 충돌이 발생할 수 있음
-
위의 과정을 거쳐 NVIDIA Driver를 설치했는데 아래와 같이
nvidia-smi가 실패한다면, GPU 드라이버 충돌 의심$ nvidia-smi NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver.
- 이와 같은 상황에서는 아래와 같이 기본 driver를 삭제하고, 다시 재설치해주면 됨
Nouveau 비활성화
Nouveau 블랙리스트 설정을 위해, /etc/modprob.d/blacklist.conf 파일을 수정한다.
# 1. Nouveau 블랙리스트 설정
sudo vi /etc/modprobe.d/blacklist.conf
# Disable open-source nouveau driver (conflicts with official NVIDIA driver)
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
부팅 이미지를 갱신한 후, 시스템을 재부팅한다.
# 2. 부팅 이미지 갱신
sudo update-initramfs -u
# 3. 시스템 재부팅
sudo reboot
재부팅 후, Nouveau 드라이버가 로드되지 않는지 확인한다. 아무 것도 출력되지 않아야 정상이다.
lsmod | grep nouveau
# 아무 것도 출력되지 않음
기존 NVIDIA 커널 모듈 언로드 및 프로세스 종료
NVIDIA 드라이버가 꼬여 있거나, 여러 버전이 섞여 있을 때 깔끔히 지우기 위해 아래 절차를 수행한다. 마지막에 NVIDIA 모듈 확인 시, 아무 것도 출력되지 않아야 정상이다.
# 1. 현재 NVIDIA 모듈 확인
lsmod | grep nvidia
# 2. GPU를 사용하는 프로세스 종료
sudo lsof /dev/nvidia*
# 위에서 표시된 PID를 kill
sudo kill -9 <pid>
# 3. NVIDIA 모듈 언로드
sudo rmmod nvidia_drm
sudo rmmod nvidia_modeset
sudo rmmod nvidia_uvm
sudo rmmod nvidia
# 4. NVIDIA 모듈 확인
lsmod | grep nvidia
# 아무 것도 출력되지 않음
NVIDIA 드라이버 및 관련 패키지 완전 제거
# 1. 모든 nvidia 관련 패키지 제거
sudo apt --purge remove '*nvidia*'
sudo apt --purge remove 'libnvidia*'
sudo apt autoremove -y
sudo apt autoclean -y
# 2. 패키지 잔재 확인
dpkg -l | grep nvidia
# 3. 남은 게 있다면 개별 제거
sudo apt-get remove --purge <남은패키지명>
# 4. 재부팅
sudo reboot
NVIDIA Container Runtime 설정
컨테이너에서 GPU를 사용할 수 있도록 NVIDIA Container Toolkit을 설치하고, 컨테이너 런타임의 설정을 변경한다.
- NVIDIA Container Toolkit: 컨테이너 내부에서 GPU를 쓸 수 있도록 설정하기 위한 도구 모음
- Container Runtime: 컨테이너 실행 환경
- Docker, containerd 등: Docker 사용
- Nvidia-ctk: Docker runtime 설정 자동화
결국 Kubernetes는 컨테이너 런타임에서 실행되는 컨테이너 관리를 위한 도구이기 때문에, 컨테이너 런타임이 GPU를 인식하는 것이 우선이다.
(Optional) Docker 설치 및 사용자 권한 설정
sudo apt install docker.io
sudo service docker restart
sudo usermod -aG docker $USER
NVIDIA Container Toolkit 설치
# 1. NVIDIA Container Toolkit 저장소 등록
sudo apt install curl
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && \
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && \
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 2. NVIDIA Container Toolkit 설치
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
Docker 런타임 설정 변경
nvidia-ctk를 이용하여 Docker 런타임을 변경한다.
sudo nvidia-ctk runtime configure --runtime=docker
-
nvidia-ctk: NVIDIA Container Toolkit 설정 CLI -
/etc/docker/daemon.json파일이 수정됨: NVIDIA 런타임 등록{ "runtimes": { "nvidia": { "path": "nvidia-container-runtime", "runtimeArgs": [] } }, "default-runtime": "runc" } -
이후 Docker에서
--runtime=nvidia혹은--gpus all플래그를 인식할 수 있게 됨. GPU 컨테이너 실행 시 해당 옵션을 주면 됨
확인
Docker가 설정 파일을 다시 읽을 수 있도록, Docker를 재시작한다.
sudo systemctl restart docker
재시작 후, GPU가 컨테이너 내부에서 보이는지 확인한다.
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
# 출력 결과가 보여야 함
nvidia-smi 출력 결과가 보이면 된다.
쿠버네티스 환경에 NVIDIA Device Plugin 배포
이제는 쿠버네티스 환경에서 파드가 GPU를 사용할 수 있게 한다.
[Pod Spec]
↓ (requests nvidia.com/gpu)
[Kubernetes Scheduler]
↓ (assigns to GPU node)
[kubelet]
↓
[NVIDIA Device Plugin]
↓
[Docker / containerd]
↓
[nvidia-container-runtime]
↓
[NVIDIA Driver]
↓
[GPU Hardware]
Kubernetes 버전 확인
1.10 이상인지 확인한다
kubectl version
Client Version: v.1.29.2
Kustomize Version: v5.0.4-0.2023061165947-6ce0bf390ce3
Server Version: v1.29.2
Helm Chart 배포
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
XXXXXXX-mam Ready control-plane,master 3d2h v1.27.9+k3s1
XXXXXXX02 Ready <none> 23h v1.27.9+k3s1
- k8s cluster 구성
- master: non GPU node
- worker: GPU node
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
$ helm repo update
$ helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace \
--version 0.16.0
- master node에 접속해 NVIDIA k8s Device Plugin daemonset 배포
$ kubectl get daemonset nvdp-nvidia-device-plugin -n nvidia-device-plugin
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
nvdp-nvidia-device-plugin 0 0 0 0 0 <none> 23s
- daemonset 확인: 현재 클러스터 내에서 GPU가 있는 node가 인식되지 않은 상태로, Device Plugin pod가 어디에도 배포되지 않은 것을 확인할 수 있음
GPU node 라벨링

-
NVIDIA Device Plugin helm chart의
values.yaml파일을 보면, daemonset 노드 중nvidia.com/gpu.present라벨이 붙어 있는 것을 인식한다는 것을 알 수 있음- values.yaml
- trouble shooting 참고 링크: https://github.com/NVIDIA/k8s-device-plugin/issues/708
참고: NFD(Node Feature Discovery)를 이용한 자동 라벨링
NFD(Node Feature Discovery)를 사용하면 GPU 노드에 자동으로 라벨을 부여할 수 있다. NFD는 노드의 하드웨어 특성을 감지하여
feature.node.kubernetes.io/pci-10de.present=true(NVIDIA GPU 벤더 ID) 등의 라벨을 자동으로 추가한다.GPU Operator를 사용하는 경우에도 NFD가 함께 배포되어 GPU 관련 라벨이 자동으로 설정된다. 본 글에서는 수동 라벨링 방식을 설명하지만, 대규모 클러스터 환경에서는 NFD를 활용한 자동화를 권장한다.
$ kubectl label nodes XXXXXXX02 nvidia.com/gpu.present=true
-
클러스터에 추가하고자 하는 GPU node에 해당 라벨 추가
-
노드 정보 확인
$ kubectl describe node XXXXXXX02 Name: XXXXXXX02 Roles: <none> Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/instance-type=k3s beta.kubernetes.io/os=linux kubernetes.io/arch=amd64 kubernetes.io/hostname=XXXXXXX02 kubernetes.io/os=linux node.kubernetes.io/instance-type=k3s nvidia.com/gpu.present=true # 라벨 추가됨 Annotations: alpha.kubernetes.io/provided-node-ip: 172.40.10.22 flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"3e:3d:a4:26:52:a6"} flannel.alpha.coreos.com/backend-type: vxlan flannel.alpha.coreos.com/kube-subnet-manager: true flannel.alpha.coreos.com/public-ip: 172.40.10.22 k3s.io/hostname: XXXXXXX02 k3s.io/internal-ip: 172.40.10.22 k3s.io/node-args: ["agent","--Docker"] k3s.io/node-config-hash: AITGS3UENG3OLFRETTJ3T6FVBFULREX5XXK5TORDBNAAOFCPL2DQ==== k3s.io/node-env: {"K3S_DATA_DIR":"/var/lib/rancher/k3s/data/dd87b6b4674aaf5776fcb1cec91f293bca5b6bbdb02dac95e866c2cf6a86ab4e","K3S_NODE_NAME":"XXXXXXX02","... management.cattle.io/pod-limits: {"cpu":"150m","ephemeral-storage":"1Gi","memory":"192Mi"} management.cattle.io/pod-requests: {"cpu":"100m","ephemeral-storage":"50Mi","memory":"128Mi","pods":"8"} node.alpha.kubernetes.io/ttl: 0 volumes.kubernetes.io/controller-managed-attach-detach: true (...)
-
노드 라벨링 추가 시, 해당 노드의 라벨이 인식되며, daemonset에 의해 파드가 배포된다.
$ kubectl get daemonset nvdp-nvidia-device-plugin -n nvidia-device-plugin
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
nvdp-nvidia-device-plugin 1 1 1 1 1 <none> 1h
쿠버네티스 클러스터 GPU 사용 확인
GPU 리소스 등록 확인
NVIDIA Device Plugin이 정상적으로 배포되면, GPU 노드에 nvidia.com/gpu 리소스가 등록된다. 아래 명령어로 확인할 수 있다.
$ kubectl describe node <GPU_NODE> | grep -A 5 "Allocatable"
Allocatable:
cpu: 8
ephemeral-storage: 95551679124
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32780872Ki
nvidia.com/gpu: 1 # GPU 리소스 등록 확인
nvidia.com/gpu항목이 표시되면 정상적으로 GPU 리소스가 등록된 것
테스트 파드 배포
아래는 GPU 동작을 확인하기 위한 테스트용 파드 예시이다.
참고: 아래 예시에서 사용하는
vectoradd-cuda10.2이미지는 테스트 목적의 샘플 이미지이다. 실제 워크로드에서는 필요한 CUDA 버전에 맞는 이미지를 사용해야 한다.
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
$ kubectl apply -f gpu-test.yaml
- GPU 사용하는 테스트 파드 배포: 정상적으로 실행된다면, toleration에 의해 GPU가 있는 노드에 스케줄링됨
$ kubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
- pod 실행 로그 확인: 정상적으로 실행되었음을 확인할 수 있음

댓글남기기