
[ELK] ELK stack
최근 회사에서 어플리케이션 로그 모니터링 시스템을 구축하며 ELK stack을 활용한 경험이 있다. 이 과정에서 ELK stack에 대해 공부한 내용을 정리해 보고자 한다.
개요
ELK stack이란, Elastic의 오픈소스 프로젝트 Elasticsearch, Logstash, Kibana를 연동하여 구성된 스택으로, 각 프로젝트의 앞 글자를 따서 만든 약어이다. 한 마디로 정의하기는 어렵지만, 여러 곳에서 발생하는 데이터를 한 곳으로 수집해 변환하고, 분석할 수 있는 데이터 분석 스택이라고 볼 수 있다.
데이터 분석 스택이 제공해야 할 기능으로는 여러 데이터 소스로부터의 데이터 수집 및 변환, 수집한 데이터의 적재, 데이터의 분석 및 시각화 등이 있다. ELK stack은 각각을 구성하는 프로젝트를 통해 이 기능들을 제공한다.
- Elasticsearch: 데이터 적재, 검색 및 집계
- Logstash: 데이터 수집, 변환
- Kibana: 데이터 시각화
최근에는 데이터 수집을 위한 데이터 수집기 제품군인 Beats를 ELK stack에 추가해 사용하는데, 이를 Elastic stack이라고 부른다. 이 경우, Logstash가 담당하던 데이터 수집 역할을 Beats가 담당하게 된다.
ELK stack
ELK stack을 이루는 각각에 대해 간단하게 살펴 보자.
Elasticsearch
‘Elasticsearch is a distributed, RESTful search and analytics engine capable of addressing a growing number of use cases.’ - Elasticsearch
Elasticsearch는 자바 Apache Lucene 기반의 검색 엔진이다. 검색 엔진은 가진 데이터 중 특정 데이터를 검색할 수 있는 기능을 제공하는 프로그램이다.
문서를 수집하고, 수집된 문서를 검색이 쉽도록 색인하고, 저장된 색인으로부터 질의에 해당하는 문서를 검색하여 결과로 제공한다. 색인된 데이터 기반의 각종 집계도 지원한다.
참고: 검색 엔진
Elasticsearch가 검색 엔진이라고 하는데, 검색 엔진이라는 기술에 대한 이해가 얕아 이해하는 데에 어려움이 있었다.
- 검색 엔진이 저장하고 있는 데이터는 기존에 익숙하던 RDBMS의 데이터와는 달리, 문서이다. 검색 엔진은 저장되어 있는 문서를 검색하는 엔진이다.
- 색인이란, 검색 엔진이 특정 데이터를 검색하기 편하도록 자료 구조로 만들어서 저장하는 것을 의미한다.
- 검색 엔진을 데이터베이스로 볼 수 있는지에 대해서 의문이 있었는데, 실제로 문서를 저장할 수 있는 스토리지로서의 역할을 하기 때문에, 데이터베이스 개념으로 이해해도 될 듯하다. 실제로 여러 문서에서 검색 엔진을 NoSQL 데이터베이스의 일종으로 분류하기도 한다.
역 인덱싱
Elasticsearch는 문서 색인에 역 인덱싱(Inverted Indexing) 기법을 이용하여 빠른 검색 성능을 보인다. 역 인덱싱이란, 키워드가 어떤 문서에 있는지를 해시 테이블로 저장해 놓는 색인 방식을 의미한다.
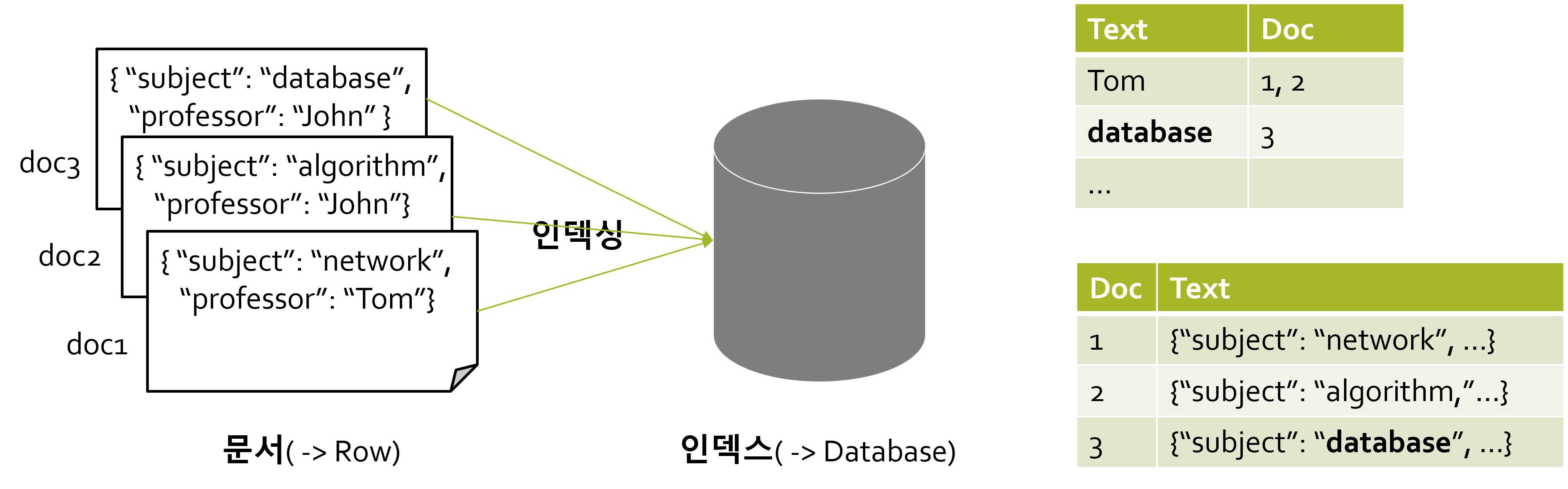
개념적으로, 위 그림에서 오른쪽 위의 표처럼 데이터를 저장해 놓는 방식이다. 오른쪽 아래의 표에서와 같이 기존 RDBMS에서처럼 데이터를 저장했다면, 사용자가 database를 질의했을 때 (최악의 경우) 모든 문서를 훑어야 하지만, 역 인덱싱 방식을 사용하면 O(1)의 시간 복잡도로 문서를 검색할 수 있다.
Elasticsearch는 문자, 숫자 외에도 메트릭, 위경도 등의 위치 정보에 이르기까지 다양한 정형 및 비정형 데이터에 대한 mapping을 통해 내부적으로 역 인덱싱이 가능하도록 지원한다. 따라서 다양한 형태의 데이터를 빠르게 검색할 수 있다는 특징을 보인다.
특징
역 인덱싱 기법을 사용하는 검색 엔진이라는 것 외에도, Elasticsearch는 다음과 같은 특징을 갖는다.
우선, 분산형 검색 엔진으로, 데이터 분산 처리를 지원한다. 클러스터를 구성할 수 있으며, 클러스터를 여러 대의 노드로 구성할 수 있다. 또한, 동일한 인덱스를 각기 다른 노드에 위치한 여러 개의 샤드로 분산해 저장함으로써, 대용량 데이터의 분산 저장 및 처리가 가능하다.
다음으로, REST API를 지원한다. HTTP 메서드 PUT, POST, GET, DELETE 등을 통해 사용자가 질의할 수 있다. 따라서 문서에 대한 쿼리, 집계 모두 HTTP 요청, 응답으로 가능하다. Elasticsearch 내부적으로 저장되어 있는 문서 데이터의 형태도 HTTP 요청 및 응답에 적합한 json 형태이다.
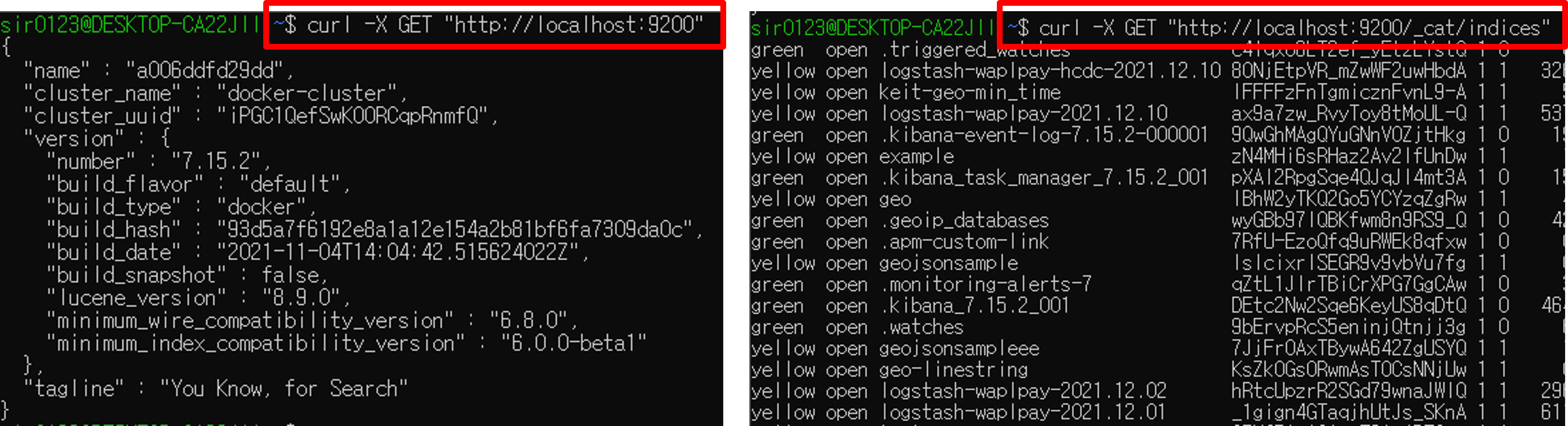
동작 원리
Elasticsearch에 데이터를 적재하고, 색인된 데이터를 검색하는 원리는 다음과 같다.
- 데이터 수집기가 REST API를 통해 데이터를 JSON 형태로 Elasticsearch에 전송한다.
- Elasticsearch가 데이터의
_source에 해당하는 모든 필드를 돌면서 역인덱싱을 통해 색인 후 데이터를 저장한다. - 사용자가 REST API를 통해 데이터를 검색(조회), 분석(집계)할 수 있는 질의를 보내고, 응답을 받는다.
Logstash
‘Logstash is a free and open server-side data processing pipeline that ingests data from a multitude of sources, transforms it, and then sends it to your favorite “stash.”‘ - Logstash
Logstash는 서버 데이터를 수집, 변환, 전송하는 데이터 처리 파이프라인으로, Jruby(JVM 기반 Ruby)로 개발되었다.

Logstash의 데이터 처리 과정은 위의 그림에서와 같이 input, filter, output의 세 단계로 구성된다. 각각의 단계는 다음과 같다.
- Input: 데이터가 유입되는 소스
- Filter: 유입된 데이터를 어떻게 변형할 것인지의 과정
- Output: 데이터를 전송할 목적지
Logstash 파이프라인을 작성하면, Input, Filter, Output 각 단계에 정의된 플러그인들이 순차적으로 실행되는 구조이다.
데이터 유입, 변형, 전송까지 다양한 기능을 지원하는데, 이 기능들은 모두 Logstash 플러그인 문서를 보며 확인해야 한다(링크는 input plugin). 또한, 사용할 플러그인을 설치해야 한다. 아래는 간단한 플러그인을 통해 파이프라인을 구성한 예시이다.
- Logstash가 tcp 5000 포트를 통해 전송되는 데이터를 수집한다.
- 수집한 데이터를 json 형태로 변형하고, 필드를 추가한다.
- 표준 출력으로 데이터를 출력하고, elasticsearch에 데이터를 전송한다.
input {
tcp { port => 5000 }
}
filter {
json { source => "message"} # tcp 통신을 통해 전송되는 데이터는 'message' 필드에 있음
mutate {
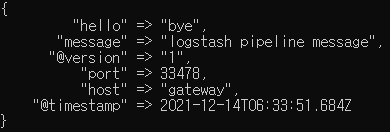
add_field => { "hello" => "bye" }
}
}
output {
stdout {}
elasticsearch {
hosts => "http://localhost:9200"
index => "hello-logstash" # 데이터가 저장될 인덱스
}
}
# tcp 통신을 통해 logstash에 메시지 전송
$ echo "logstash pipeline message" | nc localhost 5000 -w0
참고: Logstash와 ELK stack
원래 Logstash는 Elasticsearch와 같이 개발된 것은 아니고, 서버 쪽에서 데이터 수집 및 저장을 위해 개발된 프로젝트였다고 한다. Logstash에서 output 플러그인으로 Elasticsearch를 지원하면서, Elasticsearch가 인덱싱하기 좋도록 데이터를 수집하고 변환하여 Elasticsearch로 전송할 수 있게 되었다. 결과적으로 Logstash와 Elasticsearch와의 합이 잘 맞게 되며, Elasticsearch를 개발한 Elastic 사의 프로젝트로 통합된 것이다.
Kibana
‘Kibana is a free and open user interface that lets you visualize your Elasticsearch data and navigate the Elastic Stack.’ - Kibana
Kibana는 Elasticsearch에 있는 데이터를 시각화할 수 있도록 하는 웹 브라우저 기반의 시각화 플랫폼이다. Elasticsearch에 있는 인덱스의 패턴을 찾아서, 데이터를 확인(Discover)하거나, 시각화할 수 있도록 한다.
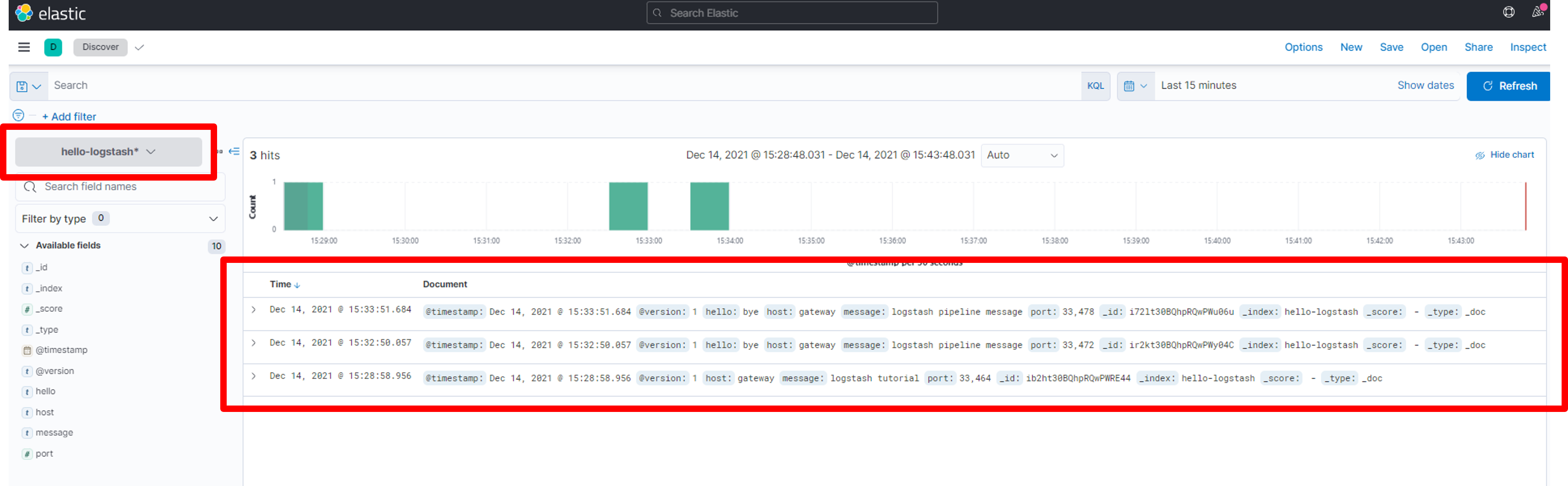
Elasticsearch와 REST API를 통해 통신하므로, HTTP 요청을 통해 시각화에 필요한 데이터를 요청하고, 응답으로 온 데이터를 시각화한다.
활용
ELK stack을 활용할 수 있는 분야는 다음과 같다.
로그 모니터링
로그란, 프로그램에서 발생하는 모든 이벤트에 대한 기록으로, 서비스 동작 상태 및 장애 원인을 파악하기 위해 필요하다.
대개 로그는 실시간, 대용량으로 발생하기 때문에, 로그를 관리하기 위해서는 로그 수집 – 저장 – 검색/분석/시각화 단계를 모두 관리할 수 있는 중앙 집중식 로그 관리 시스템이 필요하다.
- 로그 스트림: 다수 서비스, 다수 서버 환경에서 계속해서 생성되는 로그
- 로그 적재기: 실시간, 대용량으로 발생하는 로그를 수집해 저장소로 전송
- 로그 저장소: 로그 메시지를 적재하고, 질의 시 빠르게 검색
- 로그 분석기(보통 대시보드 형태): 저장소에 적재된 로그를 조회하고, 분석 결과를 시각화
이러한 관점에서 ELK stack을 로그 모니터링 스택으로 활용할 수 있다. 특히 Elasticsearch의 다양한 데이터 형태에 대한 빠른 검색 성능은 로그 모니터링 스택에 요구되는 것이기도 하다. 로그 데이터는 문자열로 비정형 데이터이고, CRUD 중 조회가 빈번하게 요구되는 데이터이기 때문이다.
ELK stack을 로그 모니터링 스택으로 활용할 경우, 각 스택은 다음과 같은 역할을 한다.
- Logstash: 로그 데이터 수집 및 처리
- Elasticsearch: 로그 데이터 저장
- Kibana: Elasticsearch에 저장된 데이터 시각화
예컨대, ELK stack을 활용해 다음과 같은 로그 모니터링 시스템을 구축할 수 있을 것이다.

머신러닝 데이터 시각화
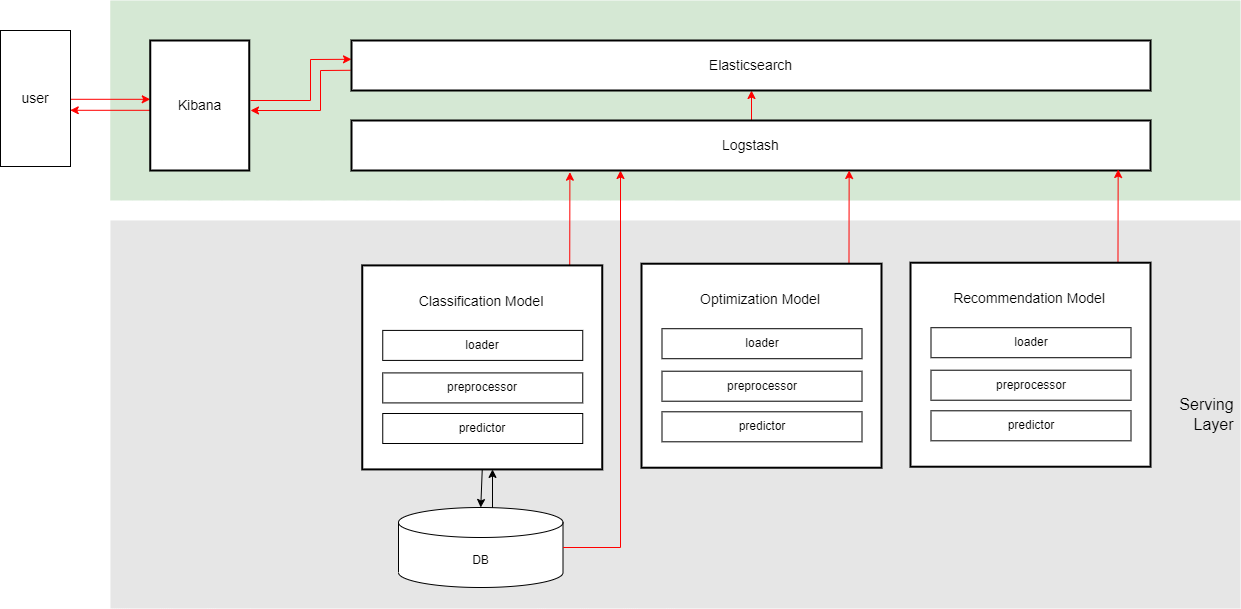
머신러닝에 활용된 데이터를 분석하고 시각화할 수 있는 용도로도 사용할 수 있다. 데이터 소스로부터 데이터를 추출하고, 머신러닝 inference data를 시각화하는 것이다.
예컨대, (개념적으로) 다음 그림과 같이 구성할 수 있다.
공유하기
Twitter Facebook LinkedIn

댓글남기기