
[Kubernetes] Cluster: RKE2를 이용해 클러스터 구성하기 - 0. RKE2: Overview
서종호(가시다)님의 On-Premise K8s Hands-on Study 7주차 학습 내용을 기반으로 합니다.
TL;DR
이번 글의 목표는 RKE2의 핵심 개념과 아키텍처 이해다.
- 정의: Rancher에서 개발한 보안 강화형 엔터프라이즈 Kubernetes 배포판
- 핵심: K3s 아키텍처(단일 바이너리 + supervisor + Helm Controller) + 보안 하드닝 + 런타임 이미지 부트스트랩
- K3s와의 관계: K3s의 편의성과 배포 모델을 그대로 계승하면서, CIS Benchmark 기본 통과, etcd 암호화, hardened 이미지 등 보안 계층을 추가
- 아키텍처: supervisor가 containerd/kubelet을 spawn하고, static pod로 컨트롤 플레인을, Helm Controller로 애드온을 관리하는 이중 구조
들어가며
Kubernetes The Hard Way에서는 클러스터의 모든 구성 요소를 손으로 설치했다. kubeadm은 핵심 부트스트래핑을 자동화했고, Kubespray는 Ansible 기반으로 OS 설정부터 클러스터 구성까지 전체 과정을 자동화했다.
이번에는 RKE2다. 또 다른 클러스터 프로비저닝 도구인데, 앞선 도구들과는 접근 방식이 다르다. kubeadm이나 Kubespray는 각 컴포넌트를 독립 프로세스로 설치하고 관리하는 구조였다면, RKE2는 단일 바이너리 하나로 모든 것을 관리하는 구조다. 회사에서 K3s를 사용하고 있어 이 구조가 익숙한데, RKE2는 K3s 아키텍처 위에 엔터프라이즈 보안을 올린 배포판이다.
이번 시리즈에서는 RKE2 클러스터를 직접 배포하고 확인해 본다.
RKE2란
공식 문서 살펴보기
RKE2 공식 문서를 보면, RKE2를 다음과 같이 소개한다.
RKE2, also known as RKE Government, is Rancher’s next-generation Kubernetes distribution.
RKE Government라고도 불린다. 이름에서 알 수 있듯이, 미국 연방 정부 부문의 보안 및 규정 준수를 만족하는 것을 목표로 설계된 배포판이다.
정의
RKE2는 Rancher에서 개발한 보안 강화형 엔터프라이즈 Kubernetes 배포판이다. 공식적으로는 “fully conformant Kubernetes distribution, focusing on security and compliance within the U.S. Federal Government sector”로 정의된다.
참고: fully conformant
여기서 fully conformant란, CNCF Kubernetes Conformance Program의 공식 Conformance Test Suite를 통과했다는 의미다. 이 테스트를 통과한 배포판은 “Certified Kubernetes” 마크를 받으며, 표준 Kubernetes API를 모두 지원한다는 것이 보장된다. 즉, K3s나 RKE2처럼 내부 구조가 다르더라도
kubectl, Helm chart, Operator 등 Kubernetes 생태계 도구가 동일하게 동작한다.
이 목표를 달성하기 위해 RKE2는 다음을 제공한다:
- CIS Kubernetes Benchmark 기본 통과: CIS(Center for Internet Security)에서 만든 Kubernetes 보안 설정 가이드라인이다.
--anonymous-auth=false설정, etcd 데이터 암호화, 파일 퍼미션 등 수백 개의 보안 항목을 점검하는 벤치마크로, RKE2는 운영자 개입 없이 v1.7 또는 v1.8을 통과하도록 설계되어 있다. - FIPS 140-2 규정 준수: 미국 연방 정부가 승인한 암호화 모듈 보안 표준이다. RKE2는 Go의 표준 crypto 라이브러리 대신 NIST가 검증한 BoringCrypto 모듈을 사용해서 컴파일하며, API Server, kubelet, etcd, containerd, runc 등 거의 모든 컴포넌트가 FIPS 호환 빌드로 제공된다.
- CVE 정기 검사: CVE(Common Vulnerabilities and Exposures)는 공개적으로 알려진 보안 취약점에 부여하는 고유 식별자다. RKE2는 빌드 파이프라인에서 Trivy를 사용하여 모든 구성 요소의 CVE를 정기적으로 스캔하고, 취약점이 발견되면 패치된 이미지를 배포한다.
설계 철학
RKE2는 RKE1과 K3s의 장점을 결합한 배포판이다.
- K3s로부터: 사용 편의성(usability), 운영 용이성(ease-of-operations), 배포 모델(deployment model)
- RKE1으로부터: 업스트림 Kubernetes와의 정합성(close alignment with upstream Kubernetes)
공식 문서의 아키텍처 설명에도 이 철학이 드러난다:
With RKE2 we take lessons learned from developing and maintaining our lightweight Kubernetes distribution, K3s, and apply them to build an enterprise-ready distribution with K3s ease-of-use.
K3s를 개발하고 유지해 온 경험을 바탕으로, K3s의 편의성을 유지하면서 엔터프라이즈 환경에 적합한 배포판을 만들고자 했다는 것이다.
K3s와 RKE2의 관계는 Fedora와 Red Hat의 관계에 비유할 수 있지 않을까 싶다. K3s에서 기능을 테스트하고, 검증된 장점을 RKE2에 녹여 내서 엔터프라이즈에 적합하게 만드는 구조다.
K3s와의 비교
K3s를 사용해 본 경험이 있다면, RKE2를 이해하는 데 K3s와의 비교가 도움이 된다. 결론부터 말하면, K3s = 경량 + 편의성이고 RKE2 = K3s 아키텍처 + 엔터프라이즈 보안 기본 적용이다.
공통점
K3s와 RKE2는 아키텍처의 핵심이 같다.
- 단일 바이너리 아키텍처: supervisor가 containerd, kubelet을 직접 spawn하고 관리
- Helm Controller 기반 애드온 부트스트랩:
helm.cattle.io/v1CRD를 사용한 경량 Helm 차트 배포 - Content Bootstrap: 부팅 시 필요한 바이너리와 차트를 추출하는 구조
차이점
RKE2가 K3s 위에 추가한 것은 거의 대부분 보안 하드닝 계층이다.
| 항목 | K3s | RKE2 |
|---|---|---|
| 기본 CNI | Flannel (network policy 없음) | Canal (Flannel + Calico network policy) |
| etcd encryption at rest | 기본 비활성 (수동 설정 필요) | 기본 활성 (encryption-provider-config 자동 적용) |
| anonymous-auth | 기본 허용 | --anonymous-auth=false 기본 |
| API server liveness probe | 일반 HTTP 체크 | mTLS 인증 적용 (client cert/key 사용) |
| TLS cipher suite | 지정 없음 (Go 기본값) | 명시적 강화 cipher suite 지정 |
| 컴포넌트 이미지 | 표준 upstream 이미지 | rancher/hardened-* 이미지 (Trivy CVE 스캔 + CIS Benchmark 통과) |
| CIS Benchmark | 수동으로 하드닝 필요 | 기본 설정으로 v1.7/v1.8 통과 |
| FIPS 140-2 | 미지원 | 지원 |
런타임 이미지 차이
K3s와 RKE2의 가장 눈에 띄는 구조적 차이는 런타임 이미지 처리 방식이다.
| K3s | RKE2 | |
|---|---|---|
| 핵심 바이너리 위치 | k3s 단일 바이너리에 내장(embedded) |
rke2-runtime 컨테이너 이미지에 별도 패키징 |
| 부팅 시 동작 | 바이너리에서 바로 프로세스 spawn | 런타임 이미지에서 bin/ + charts/ 추출 후 spawn |
| airgap 이미지 | k3s-airgap-images-*.tar (컨테이너 이미지만) |
rke2-runtime 이미지 자체가 바이너리 + 차트 포함 |
K3s는 핵심 바이너리(containerd, kubelet, runc 등)가 k3s 바이너리 안에 직접 컴파일되어 있어, k3s server를 실행하면 바이너리 내부에서 바로 프로세스를 spawn한다. 반면, RKE2는 rke2-runtime 컨테이너 이미지 안에 바이너리와 Helm chart를 패키징해 두고, 부팅 시 이를 추출하는 과정을 거친다.
이 차이가 K3s의 기동 속도가 RKE2보다 빠른 이유이기도 하다. K3s는 바이너리에 이미 다 들어있어서 바로 시작하지만, RKE2는 런타임 이미지에서 import/추출하는 과정이 필요하기 때문이다.
아키텍처
RKE2의 아키텍처를 살펴보자. 공식 문서에 아키텍처 다이어그램이 있다.
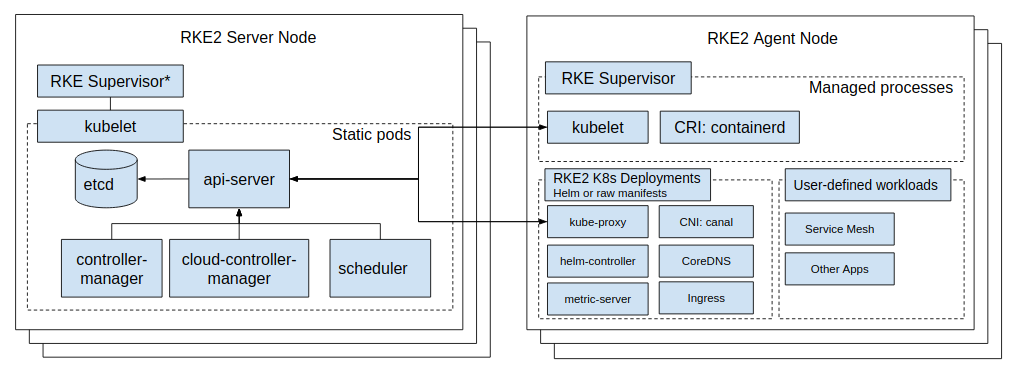
핵심 구조: 단일 바이너리 + Supervisor 패턴
RKE2는 rke2라는 단일 바이너리 하나로 동작한다. 이 바이너리가 supervisor 프로세스 역할을 하면서, containerd와 kubelet을 직접 spawn하고 관리한다.
rke2 (supervisor)
├── containerd ← 컨테이너 런타임
├── kubelet ← 노드 에이전트
└── containerd-shim-runc-v2 (각 컨테이너마다)
K3s에서 물려받은 구조로, kubeadm이나 Kubespray로 구성한 클러스터처럼 각 컴포넌트가 독립 프로세스로 도는 구조와는 완전히 다르다. 내장 컨테이너 런타임은 containerd이며, 컨트롤 플레인 구성 요소는 kubelet이 관리하는 static pod로 실행된다.
여기서 주목할 점은, 서버 노드도 내부적으로 에이전트를 임베딩하고 있다는 것이다. 서버 노드의 프로세스 트리를 보면 containerd와 kubelet이 떠 있는데, 이것은 에이전트 노드와 동일한 구성이다. 서버 노드에 에이전트가 필요한 이유는 컨트롤 플레인의 동작 방식 때문이다:
- static pod를 실행하려면 kubelet이 필요하다. etcd, kube-apiserver, kube-controller-manager, kube-scheduler는 모두 static pod로 실행되는데, static pod는 kubelet이
pod-manifests/디렉터리를 감시하면서 기동하는 구조다. kubelet 없이는 컨트롤 플레인 자체가 뜰 수 없다. - kubelet이 컨테이너를 실행하려면 containerd가 필요하다. kubelet은 CRI(Container Runtime Interface)를 통해 containerd에 컨테이너 생성을 요청한다. containerd가 없으면 kubelet이 pod를 실행할 수 없다.
결과적으로, 서버 노드의 부팅 과정은 “에이전트 초기화(containerd + kubelet spawn) → 컨트롤 플레인 초기화(static pod manifest 작성 → kubelet 감지 → pod 기동)”의 순서로 진행된다. 이 흐름은 프로세스 라이프사이클 섹션에서 자세히 다룬다.
구성 요소
RKE2는 다양한 오픈소스 구성 요소로 이루어져 있다. 공식 문서에서 제시하는 구성 요소 목록을 기반으로 정리한다.
K3s
RKE2가 K3s로부터 가져온 핵심 구성 요소다. 표준 Kubernetes에는 없는 RKE2/K3s 고유의 접근법이다.
- Helm Controller: 클러스터 부트스트랩 시 필수 애드온(CNI, CoreDNS, metrics-server 등)을 자동 설치하기 위한 경량 Helm 차트 배포 컨트롤러. K3s 프로젝트에서 만든 것을 그대로 가져다 쓰는 구조로, GitHub 리포도
k3s-io/helm-controller이고, CRD도helm.cattle.io/v1로 K3s 네이밍이 그대로 남아 있다.
Kubernetes
표준 Kubernetes의 컨트롤 플레인 및 노드 컴포넌트다. 업스트림과 동일한 컴포넌트를 사용하되, rancher/hardened-* 이미지로 빌드되어 보안이 강화된 상태로 제공된다.
- API Server, Controller Manager, Scheduler: 컨트롤 플레인 구성 요소. static pod로 실행된다.
- Kubelet, Proxy: 노드 에이전트. supervisor가 kubelet을 직접 spawn하고, kube-proxy는 static pod로 실행된다.
런타임 및 네트워크
클러스터 운영에 필요한 데이터 스토어, 컨테이너 런타임, 네트워크, 애드온 구성 요소다.
- etcd: 클러스터 상태를 저장하는 분산 키-값 스토어. static pod로 실행되며, RKE2에서는 encryption at rest가 기본 활성화되어 있다.
- containerd / CRI, runc: 컨테이너 런타임 스택. containerd가 CRI를 구현하고, runc가 실제 컨테이너를 생성한다. supervisor가 containerd를 직접 spawn한다.
- CNI: Canal(기본), Cilium, Calico, Flannel 선택 가능. Multus도 지원. Helm Controller를 통해 자동 부트스트랩된다. Canal에 대해서는 아래 참고 섹션에서 좀 더 다룬다.
- CoreDNS: 클러스터 내부 DNS. Metrics Server: 리소스 메트릭 수집. 둘 다 Helm Controller로 배포된다.
- Ingress NGINX Controller 및/또는 Traefik: 외부 트래픽을 클러스터 내부로 라우팅하는 인그레스 컨트롤러.
- Helm: Kubernetes 패키지 매니저. Helm Controller가 내부적으로 Helm을 사용하여 차트를 배포한다.
관리 구조: Static Pod + Helm Controller 이중 구조
RKE2는 컨트롤 플레인 컴포넌트와 애드온을 서로 다른 메커니즘으로 관리한다.
| 구분 | 경로 | 관리 주체 | 대상 |
|---|---|---|---|
| Static Pod | /var/lib/rancher/rke2/agent/pod-manifests/ |
kubelet | etcd, apiserver, scheduler, kcm |
| Helm Controller | /var/lib/rancher/rke2/server/manifests/ |
helm-controller | CNI, CoreDNS, metrics-server 등 |
Static Pod
RKE2의 컨트롤 플레인 컴포넌트(etcd, kube-apiserver, kube-scheduler, kube-controller-manager)는 static pod로 실행된다. kubelet이 /var/lib/rancher/rke2/agent/pod-manifests/ 디렉터리를 watch하고 있다가, 여기에 YAML 파일이 생기면 자동으로 해당 pod를 기동한다. kubeadm에서 /etc/kubernetes/manifests/를 사용하는 것과 동일한 메커니즘이다.
다만 RKE2에서는 이 manifest 파일들이 처음부터 존재하는 것이 아니다. 프로세스 라이프사이클에서 다루겠지만, Initialize Server 단계에서 각 컴포넌트별 goroutine이 의존 대상을 기다린 후에 manifest를 작성하는 구조다. 즉, kubelet이 먼저 기동되고 → goroutine이 manifest를 작성하면 → kubelet이 이를 감지해서 pod를 띄우는 순서다.
ls -ltr /var/lib/rancher/rke2/agent/pod-manifests/
total 32
-rw-r--r--. 1 root root 3279 Feb 16 17:32 etcd.yaml
-rw-r--r--. 1 root root 2325 Feb 16 17:32 kube-proxy.yaml
-rw-r--r--. 1 root root 9337 Feb 16 17:33 kube-apiserver.yaml
-rw-r--r--. 1 root root 3724 Feb 16 17:33 kube-scheduler.yaml
-rw-r--r--. 1 root root 6325 Feb 16 17:33 kube-controller-manager.yaml
위는 실제 RKE2 서버 노드에서 확인한 예시다. 파일 생성 시간을 보면 etcd와 kube-proxy가 먼저(17:32), 이후 apiserver, scheduler, controller-manager가 순서대로(17:33) 생성된 것을 확인할 수 있다. 이 시간 차이는 프로세스 라이프사이클에서 다루는 goroutine 의존성 체인이 반영된 결과다.
참고: kube-proxy도 static pod로 실행된다는 점이 kubeadm과 다르다. kubeadm에서는 kube-proxy가 DaemonSet으로 배포되지만, RKE2에서는 static pod manifest로 관리된다.
Helm Controller
Helm Controller는 /var/lib/rancher/rke2/server/manifests/ 디렉터리를 감시한다. 여기에 HelmChart CRD YAML이 있으면 자동으로 Helm 차트를 설치/업데이트한다.
tree /var/lib/rancher/rke2/server/manifests
├── rke2-canal-config.yaml
├── rke2-canal.yaml
├── rke2-coredns-config.yaml
├── rke2-coredns.yaml
├── rke2-metrics-server.yaml
└── rke2-runtimeclasses.yaml
CRD는 helmcharts.helm.cattle.io와 helmchartconfigs.helm.cattle.io 두 가지다. cattle.io는 Rancher Labs 시절부터 사용하던 도메인으로, K3s의 Helm Controller(k3s-io/helm-controller)에서 정의한 CRD를 RKE2가 그대로 가져다 쓰는 것이다.
참고: Helm Controller는 부트스트랩 용도다. Canal, CoreDNS, metrics-server 같은 클러스터 필수 애드온을 부팅 시 자동 설치하는 것이 핵심 역할이다. HelmChart CR을 직접 작성해서 다른 워크로드를 배포할 수도 있지만, MinIO, PostgreSQL 같은 인프라 컴포넌트나 실제 애플리케이션(개발자가 만드는 백엔드/프론트엔드 서비스 등) 배포는 별도의 도구(
helm install직접 실행, ArgoCD/FluxCD 같은 GitOps 도구, Rancher UI 등)를 사용하는 것이 일반적이다.
참고: Canal
RKE2는 기본 CNI로 Canal을 사용한다. Canal이 독특한 이유는 Flannel과 Calico, 두 CNI의 장점만 조합한 하이브리드이기 때문이다.
Flannel은 간단하고 가볍지만, 단독으로 사용하면 네트워크 정책을 적용할 수 없다. Calico는 네트워크 연결 및 네트워크 정책을 모두 지원하는 풀스택 CNI지만, 네트워크 연결까지 Calico가 담당해야 해서 구성이 복잡해진다. 단독으로 쓰기에는 Flannel보다 설정이 복잡하고 무겁다. Canal은 네트워크 연결은 Flannel의 단순함을 그대로 쓰면서, Calico의 네트워크 정책 엔진만 얹는 구조다.
| 역할 | 담당 | 특징 |
|---|---|---|
| 네트워크 연결 (Pod-to-Pod 통신) | Flannel | 간단하고 가벼운 VXLAN overlay |
| 네트워크 정책 (트래픽 제어) | Calico | Kubernetes NetworkPolicy 구현 |
RKE2가 Canal을 기본 CNI로 선택한 이유는 보안 때문이다. CIS Kubernetes Benchmark에서 네트워크 정책 적용을 요구하는데, Flannel만으로는 이 항목을 통과할 수 없다. Canal이 Flannel의 단순함과 Calico의 네트워크 정책을 결합하여, 보안 요건을 충족하면서도 설정 부담을 낮추는 균형점이 된다.
K3s는 기본 CNI가 Flannel이다. 네트워크 정책이 없어도 되는 경량 환경을 상정하기 때문이다. RKE2는 엔터프라이즈/보안 중심이라 네트워크 정책이 필수이고, 따라서 Canal이 기본이 된다. 이 차이가 K3s와 RKE2의 보안 철학 차이를 잘 보여준다.
실제로 Canal DaemonSet 파드 내부에는 각 역할을 담당하는 두 개의 컨테이너가 있다:
kubectl describe pod -n kube-system -l k8s-app=canal | grep Image: | uniq
Image: rancher/hardened-calico:v3.31.3-build20260119
Image: rancher/hardened-flannel:v0.28.0-build20260119
hardened-calico: network policy (iptables 규칙) 담당hardened-flannel: VXLAN overlay 네트워크 담당
이미지 이름에 hardened-가 붙어 있는 것에 주목하자. Trivy로 CVE 스캔을 거치고, CIS Benchmark를 통과하도록 설정된 보안 강화 이미지다.
프로세스 라이프사이클
서버 노드
RKE2 서버 노드가 부팅될 때 어떤 일이 일어나는지 살펴보자.

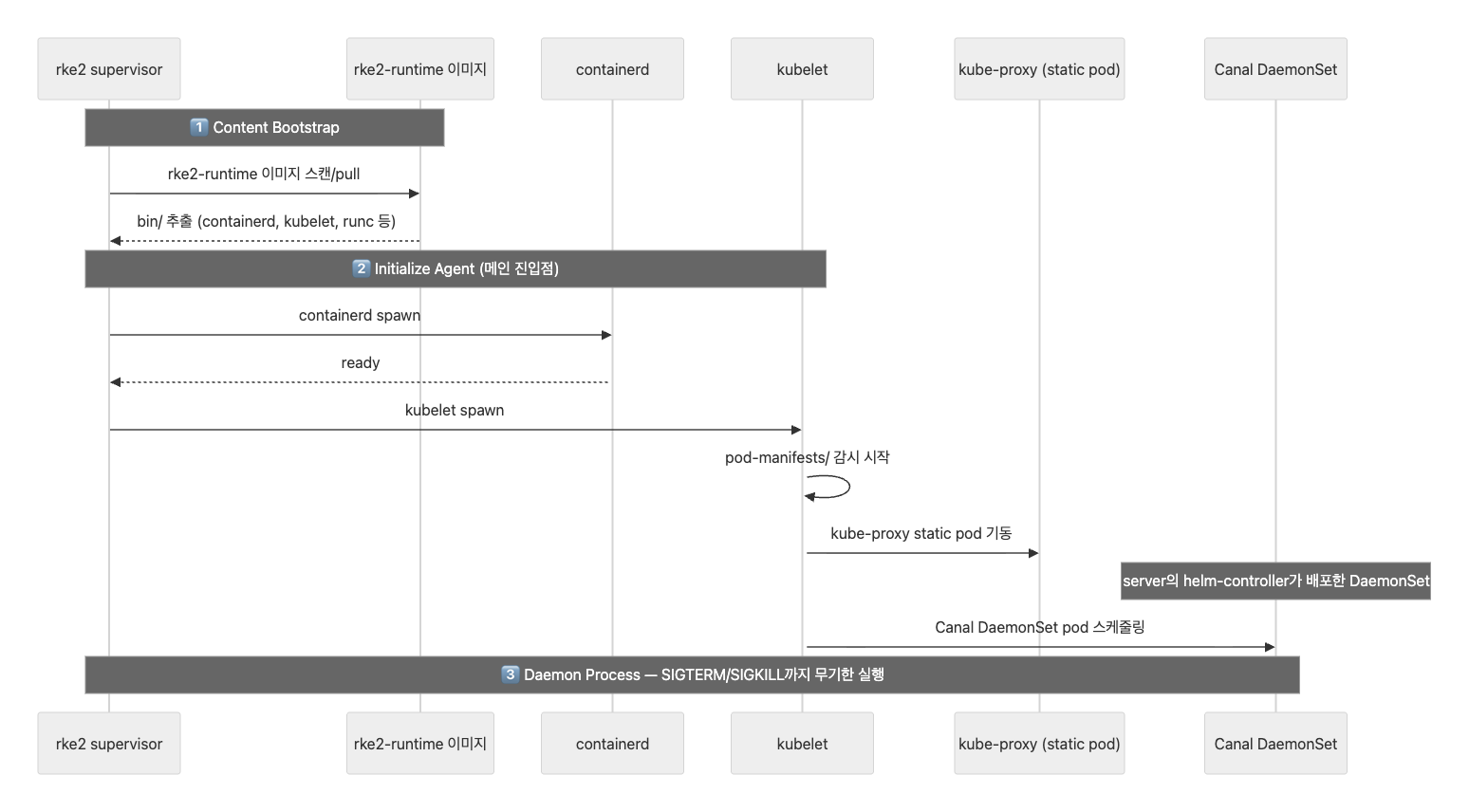
1단계: Content Bootstrap
rke2-runtime 컨테이너 이미지에서 바이너리와 Helm chart를 추출하는 단계다.
공식 문서에 따르면, 런타임 이미지가 제공하는 것은 다음과 같다:
- 필수 바이너리:
- containerd: 컨테이너 런타임 (CRI)
- containerd-shim-runc-v2: containerd가 종료되어도 컨테이너를 유지하는 shim
- kubelet: 노드 에이전트
- runc: OCI 런타임
- 운영 도구:
ctr: containerd 점검crictl: CRI 점검kubectl: 클러스터 관리socat:kubectl port-forward등에서 내부적으로 사용
RKE2는 /var/lib/rancher/rke2/agent/images/*.tar에서 rancher/rke2-runtime 이미지를 스캔한다. 태그는 rke2 --version 출력과 대응된다. 로컬에서 이미지를 찾을 수 없으면 Docker Hub에서 가져온다.
# 런타임 이미지 참조 확인
cat /var/lib/rancher/rke2/agent/images/runtime-image.txt
index.docker.io/rancher/rke2-runtime:v1.34.3-rke2r3
이미지로부터 바이너리와 차트를 아래 타겟 경로로 추출한다:
- 바이너리:
/var/lib/rancher/rke2/data/${RKE2_DATA_KEY}/bin - 차트:
/var/lib/rancher/rke2/server/manifests/
여기서 바이너리 추출 경로에 포함된 ${RKE2_DATA_KEY}는 이미지를 식별하는 고유 문자열이다. {버전태그}-{이미지 참조의 SHA256 해시 앞 12자리} 형식이다. 예를 들어, 아래 트리에서 v1.34.3-rke2r3-5b8349de68df는 버전 v1.34.3-rke2r3에 이미지 참조 문자열의 해시 5b8349de68df를 붙인 것이다.
해시를 붙이는 이유는 업그레이드 시 버전별 바이너리를 격리하기 위해서다. 새 버전의 바이너리가 추출되어도 기존 버전의 디렉터리는 그대로 남아 있고, /var/lib/rancher/rke2/bin 심링크만 새 버전을 가리키도록 전환된다. 동일한 RKE2_DATA_KEY 디렉터리가 이미 존재하면 추출을 건너뛴다.
tree /var/lib/rancher/rke2/data/
└── v1.34.3-rke2r3-5b8349de68df
├── bin
│ ├── containerd
│ ├── containerd-shim-runc-v2
│ ├── crictl
│ ├── ctr
│ ├── kubectl
│ ├── kubelet
│ └── runc
└── charts
├── rke2-canal.yaml
├── rke2-cilium.yaml
├── rke2-coredns.yaml
├── rke2-ingress-nginx.yaml
├── rke2-metrics-server.yaml
└── ... (기타 차트)
2단계: Initialize Server
추출된 바이너리로 컨트롤 플레인을 초기화하는 단계다. 이 단계에서 각 컨트롤 플레인 컴포넌트마다 goroutine을 하나씩 띄워서 자기가 의존하는 컴포넌트를 비동기로 기다리는 구조다.
supervisor
├── goroutine: etcd용 → kubelet 대기 → manifest 작성
├── goroutine: apiserver용 → etcd 대기 → manifest 작성
├── goroutine: kcm용 → apiserver 대기 → manifest 작성
├── goroutine: scheduler용 → apiserver 대기 → manifest 작성
└── goroutine: helm-controller용 → apiserver 대기 → 시작
goroutine을 사용하는 이유는, 메인 supervisor 프로세스가 etcd를 기다리면서 블로킹되면 안 되기 때문이다. Go의 동시성 모델을 활용하여, supervisor는 모든 goroutine을 동시에 띄워놓고, 각 goroutine이 자기 의존 대상이 준비되면 static pod manifest를 작성하는 구조다.
개인적으로 이 설계가 Go의 동시성 모델을 잘 활용한 사례라고 생각한다. goroutine + channel 조합으로 복잡한 의존성 체인을 선언적으로 표현하면서도, 실제 실행은 비동기로 처리된다. 만약 이걸 스레드나 콜백 기반으로 구현했다면 의존성 순서 관리가 훨씬 복잡해졌을 것이다. “goroutine은 등록만 해두고, channel이 닫히면 manifest를 쓴다”는 패턴이 깔끔하다.
이 시점에서는 goroutine들이 모두 대기 상태다. containerd도, kubelet도 아직 기동되지 않았다. 실제 프로세스 spawn은 다음 단계에서 일어난다.
3단계: Initialize Agent
서버 노드 내부에서 agent 초기화가 호출되는 단계다. 임베디드 K3s 엔진이 agent 프로세스를 직접 호출한다. 서버 노드도 내부적으로는 에이전트처럼 동작하는 것이다.
| Server 노드 | Agent 노드 | |
|---|---|---|
| 호출 방식 | 임베디드 K3s 엔진이 직접 호출 | rke2 agent의 메인 진입점 |
| Initialize Agent 전에 | Content Bootstrap + Initialize Server 완료 후 | Content Bootstrap 후 바로 |
| 결과 | containerd + kubelet + CP static pods | containerd + kubelet + kube-proxy만 |
이 단계에서 비로소 containerd → kubelet이 spawn되면서, 앞서 등록해 둔 goroutine들의 대기가 풀리기 시작한다:
Initialize Server (goroutine 등록 = 대기 시작)
│
▼
Initialize Agent (containerd → kubelet spawn)
│
▼
goroutine 대기 해제 → manifest 작성 → kubelet 감지 → static pod 기동
- kubelet이 뜨면 → etcd goroutine의 대기가 풀림 → etcd static pod manifest 작성
- etcd가 뜨면 → apiserver goroutine의 대기가 풀림 → apiserver manifest 작성
- apiserver가 뜨면 → kcm, scheduler, helm-controller goroutine들의 대기가 풀림
연쇄적으로 모든 컨트롤 플레인 컴포넌트가 기동되는 것이다. Initialize Server 단계만으로는 컨트롤 플레인이 완성되지 않고, Initialize Agent까지 와야 실제 프로세스가 spawn되고, 그제서야 goroutine → manifest 작성 → pod 기동이 연쇄적으로 일어난다.
Daemon Process
모든 초기화가 완료되면, RKE2 프로세스는 SIGTERM 또는 SIGKILL을 받거나 containerd 프로세스가 종료될 때까지 무기한으로 실행된다. containerd가 종료되면 rke2 프로세스도 종료된다.
pstree -al
├─rke2
│ ├─containerd -c /var/lib/rancher/rke2/agent/etc/containerd/config.toml
│ │ └─12*[{containerd}]
│ ├─kubelet --volume-plugin-dir=/var/lib/kubelet/volumeplugins ...
│ │ └─14*[{kubelet}]
│ └─12*[{rke2}]
systemd unit 파일을 보면 이 구조가 반영되어 있다:
# /usr/lib/systemd/system/rke2-server.service
[Service]
Type=notify
KillMode=process # rke2 프로세스만 종료하고, 자식(containerd, kubelet)은 건드리지 않음
Delegate=yes # rke2 하위 cgroup 서브트리를 systemd가 간섭하지 않도록 위임
Restart=always
RestartSec=5s
ExecStartPre=-/sbin/modprobe br_netfilter
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/bin/rke2 server
KillMode=process
rke2 프로세스만 종료하고, containerd/kubelet 같은 자식 프로세스는 systemd가 건드리지 않는다.
이 설정이 없으면(기본값 KillMode=control-group), systemd가 서비스를 중지할 때 해당 cgroup에 속한 모든 프로세스에 SIGTERM을 동시에 보낸다. rke2, containerd, kubelet, shim, 실제 컨테이너 프로세스까지 전부 한꺼번에 종료 시그널을 받는 것이다.
문제는 컨테이너 런타임의 종료 순서가 중요하다는 점이다:
- 정상 종료(
KillMode=process): rke2가 SIGTERM을 받으면 → containerd에 graceful shutdown 요청 → containerd가 각 컨테이너를 순차적으로 정리 → kubelet이 노드 상태를 업데이트 → 깔끔하게 종료 - 일괄 종료(
KillMode=control-group): systemd가 모든 프로세스에 동시에 SIGTERM → containerd가 컨테이너를 정리하기도 전에 shim이 죽음 → 컨테이너 상태 불일치, 데이터 손상, 좀비 프로세스 발생 가능
RKE2 업그레이드 시에도 이 설정이 중요하다. systemctl restart rke2-server를 실행하면 rke2 바이너리만 교체하고 재시작하면 되는데, containerd까지 죽으면 실행 중인 모든 워크로드가 중단된다.
Delegate=yes
rke2 프로세스 하위의 cgroup 서브트리를 systemd가 간섭하지 않도록 위임한다. rke2 안에서 containerd가 컨테이너별 cgroup을 자유롭게 만들어야 하는데, 이 설정이 없으면 systemd가 rke2 하위 cgroup을 정리하거나 재배치할 수 있다.
참고로, containerd의 cgroup driver 자체는 kubeadm 환경과 마찬가지로 systemd를 사용한다(SystemdCgroup = true). 다만 kubeadm에서는 사용자가 /etc/containerd/config.toml에 직접 설정해야 하지만, RKE2는 containerd 설정을 자동 생성하면서(/var/lib/rancher/rke2/agent/etc/containerd/config.toml) 알아서 적용한다.
Delegate=yes는 이 cgroup driver 설정과는 다른 레벨의 이야기다. Delegate=yes는 containerd에게 전달하는 설정이 아니라, systemd에게 “이 서비스 하위의 cgroup 서브트리를 건드리지 말라”고 알려주는 설정이다. containerd가 어디서 실행되느냐에 따라 어떤 unit 파일에 넣어야 하는지가 달라진다:
| containerd 실행 위치 | Delegate=yes 위치 |
|
|---|---|---|
| kubeadm | containerd.service (독립 서비스) |
containerd.service (containerd 패키지가 제공) |
| RKE2 | rke2 자식 프로세스 | rke2-server.service (RKE2 패키지가 제공) |
kubeadm 환경에서 Delegate=yes는 kubeadm이 설정하는 것이 아니라, containerd 패키지를 설치할 때 함께 제공되는 containerd.service unit 파일에 이미 포함되어 있다. RKE2에서는 containerd가 별도 systemd 서비스 없이 rke2의 자식 프로세스로 실행되므로, rke2 unit 파일에 이 설정이 필요하다.
에이전트 노드
에이전트(워커) 노드의 부팅 과정은 서버 노드보다 훨씬 단순하다. Initialize Server 단계가 없고, 컨트롤 플레인 static pod도 없다.
서버 노드와의 차이
| 서버 노드 | 에이전트 노드 | |
|---|---|---|
| 시작 명령 | rke2 server |
rke2 agent |
| Content Bootstrap | 바이너리 + 차트 추출 | 바이너리만 추출 (차트 불필요) |
| Initialize Server | goroutine 등록 (CP 초기화) | 없음 |
| Initialize Agent | 임베디드 K3s 엔진이 내부 호출 | rke2 agent의 진입점 자체 |
| static pod | etcd, apiserver, scheduler, kcm, kube-proxy | kube-proxy만 |
| Helm Controller | 실행 (애드온 배포) | 없음 |
1단계: Content Bootstrap
서버 노드와 동일하게 rke2-runtime 이미지에서 바이너리(containerd, kubelet, runc 등)를 추출한다. 단, 에이전트 노드에서는 Helm Controller가 동작하지 않으므로 차트 추출은 필요 없다.
2단계: Initialize Agent
에이전트 노드에서는 이 단계가 진입점 자체다. 서버 노드처럼 Initialize Server를 거치지 않고, Content Bootstrap 직후 바로 Initialize Agent로 진입한다.
rke2 agent (supervisor)
├── containerd 기동
├── kubelet 기동
│ └── kube-proxy static pod 기동
└── 서버의 kube-apiserver에 join
supervisor가 containerd를 spawn하고, 이어서 kubelet을 spawn한다. kubelet이 기동되면 pod-manifests/ 디렉터리를 감시하기 시작하고, kube-proxy static pod를 띄운다. 서버 노드와 달리 etcd, apiserver, scheduler, controller-manager 등의 static pod는 없다.
노드가 클러스터에 join되면, 서버 노드의 Helm Controller가 배포한 DaemonSet(Canal 등)이 에이전트 노드에도 스케줄링된다. 에이전트 노드 자체에 Helm Controller가 없지만, 서버에서 배포된 DaemonSet이 클러스터 전체 노드에 걸쳐 동작하는 구조다.
3단계: 서버에 Join
kubelet이 기동되면 서버 노드의 kube-apiserver에 등록된다. 에이전트 노드 설정 시 서버 URL과 토큰을 지정해야 한다.
# /etc/rancher/rke2/config.yaml (에이전트 노드)
server: https://<server-ip>:9345
token: <server-token>
server: 서버 노드의 supervisor API 주소. 서버 노드의 Initialize Server 단계에서 HTTP 서버가 goroutine으로 기동되어 에이전트의 join 요청을 수신한다.token: 서버 노드에서 생성된 토큰./var/lib/rancher/rke2/server/token에 저장되어 있으며, 노드 join 시 인증에 사용된다.
4단계: Daemon Process
서버 노드와 동일하다. RKE2 프로세스가 SIGTERM/SIGKILL을 받거나 containerd가 종료될 때까지 무기한 실행된다.
kubeadm, Kubespray와의 비교
지금까지 살펴본 프로비저닝 도구들과 RKE2를 비교해 보자.
| Kubernetes The Hard Way | kubeadm | Kubespray | RKE2 | |
|---|---|---|---|---|
| 자동화 수준 | 수동 | 부트스트래핑 자동화 | OS 설정부터 전체 자동화 | 단일 바이너리로 전체 자동화 |
| 컴포넌트 관리 | 독립 프로세스 직접 관리 | static pod (kubelet) | static pod (kubelet) | supervisor + static pod + Helm Controller |
| CNI 설치 | 수동 | 수동 | Ansible Role로 자동 | Helm Controller로 자동 부트스트랩 |
| 보안 하드닝 | 수동 | 수동 | 변수로 설정 가능 | 기본 적용 (CIS Benchmark 통과) |
| 접근 방식 | 학습 목적 | Kubernetes 공식 도구 | Ansible 기반 자동화 | 단일 바이너리 배포판 |
RKE2가 가장 큰 차이를 보이는 부분은 아키텍처다. kubeadm이나 Kubespray는 기본적으로 각 컴포넌트가 독립 프로세스(또는 kubelet이 관리하는 static pod)로 동작하는 표준 Kubernetes 구조를 따른다. 반면 RKE2는 단일 supervisor 프로세스가 모든 것을 관장하는 구조로, K3s에서 가져온 완전히 다른 배포 모델이다.
결과
RKE2는 K3s의 단일 바이너리 아키텍처와 편의성을 그대로 가져오면서, CIS Benchmark 기본 통과, etcd 암호화, hardened 이미지 등 엔터프라이즈 보안 계층을 추가한 배포판이다.
이번 글에서는 RKE2가 무엇이고 어떤 아키텍처로 동작하는지 살펴보았다. 다음 글에서는 실제로 RKE2 클러스터를 배포해 본다.
부록: RKE2 보안 하드닝 상세
RKE2가 “보안 강화형”이라고 주장하는 근거를 좀 더 구체적으로 정리한다. RKE2 공식 문서 Security 섹션의 하위 문서들을 기반으로 한다.
Hardened Images
RKE2의 모든 컴포넌트 이미지는 upstream 미러가 아니라 소스에서 직접 빌드된다.
| 항목 | 설명 |
|---|---|
| 베이스 이미지 | SUSE BCI(Base Container Image) - 최소한의 패키지만 포함하는 경량 이미지 |
| 빌드 시 스캔 | Trivy로 CVE 취약점 스캔 |
| Go 바이너리 | FIPS 140-2 호환 BoringCrypto 모듈로 컴파일 (Linux AMD64만) |
| 이미지 네이밍 | rancher/hardened-* 접두사로 구분 |
CIS Hardening 기본 적용
RKE2는 “hardened by default”를 표방한다. 별도 설정 없이 기본으로 적용되는 보안 설정들이 있다.
- Pod Security Admission: restricted 모드를 네임스페이스에 강제 적용 (시스템 네임스페이스 예외)
- Network Policies:
kube-system,kube-public,default네임스페이스에 네트워크 정책 자동 적용 - etcd 보안: 전용
etcd사용자로 실행, 디렉터리 퍼미션 관리, encryption at rest 기본 활성화
profile: "cis" 설정을 추가하면 더 강화된 보안이 적용된다:
- 호스트 커널 파라미터 검증
- 파일 퍼미션 강화 (644 →600)
protect-kernel-defaults=true적용
참고: 두 가지 CIS 항목은 운영자가 수동으로 설정해야 한다.
- Control 1.1.12:
etcd사용자/그룹 생성 및 디렉터리 퍼미션 설정- Control 5.1.5: 커스텀 네임스페이스의 default ServiceAccount에
automountServiceAccountToken: false설정
FIPS 140-2 호환 빌드 대상
| 계층 | 대상 컴포넌트 |
|---|---|
| Kubernetes 핵심 | API Server, Controller Manager, Scheduler, kubelet, kube-proxy, kubectl |
| 런타임 | etcd, containerd, runc |
| 네트워크 | Canal (기본 CNI만 FIPS 호환 빌드) |
| Ingress | NGINX Ingress Controller (Go 컴파일러 + FIPS 검증 OpenSSL) |
제한: FIPS 140-2는 현재 Linux AMD64에서만 호환된다. Windows, s390x 아키텍처는 미지원이다.
Pod Security Standards
RKE2는 Kubernetes의 Pod Security Admission을 활용하여 Pod 수준의 보안을 제어한다. 배포 모드에 따라 기본 동작이 달라진다.
- CIS 모드 (
profile: "cis"): 클러스터 전체에 restricted 정책을 강제 적용한다. 시스템 네임스페이스(kube-system,cis-operator-system등)는 예외 처리된다. - 기본 모드: privileged 정책이 적용되어 Pod에 대한 제한이 없다.
커스텀 설정이 필요하면 /etc/rancher/rke2/rke2-pss.yaml로 정책을 조정할 수 있다.
Secrets Encryption
RKE2는 etcd에 저장되는 Kubernetes Secret을 기본적으로 암호화한다. 별도 설정 없이 시작 시 자동으로 AES-CBC 암호화 키와 설정을 생성한다.
- 기본 암호화 제공자: AES-CBC (FIPS 140-2 호환)
- 대안: Secretbox (비 FIPS 환경용)
- 키 로테이션: 싱글 서버 및 HA 클러스터 모두에서 키 로테이션 및 재암호화 절차를 지원한다.
kubeadm에서는 encryption-provider-config를 수동으로 설정해야 하지만, RKE2는 이것이 기본 활성화되어 있다.
인증서 관리
RKE2는 클러스터 컴포넌트 간 mTLS 통신에 사용되는 인증서를 자동으로 관리한다.
- 클라이언트/서버 인증서: 유효기간 1년. 만료 120일 전에 자동 갱신된다.
- 자체 서명 CA: 최초 시작 시 생성되며 유효기간 10년. 자동 갱신되지 않으므로, 필요 시 수동으로 로테이션해야 한다.
- 커스텀 CA:
/var/lib/rancher/rke2/server/tls에 미리 배치하면 최초 시작 시 해당 CA를 사용한다. - 만료 경고: 인증서 만료가 가까워지면 Kubernetes Warning 이벤트가 발생한다.
토큰 관리
RKE2는 토큰 기반 인증으로 노드 join과 클러스터 통신을 보호한다.
- 서버 토큰: 기본적으로 자동 생성되며
/var/lib/rancher/rke2/server/token에 저장된다. - Secure format: CA 해시를 포함하여 MITM(중간자 공격)을 방지하는 토큰 형식을 지원한다.
- 부트스트랩 토큰: 노드 join 시 일시적으로 사용되는 토큰. CLI를 통해 생성, 삭제 등 라이프사이클을 관리할 수 있다.
- 토큰 로테이션: 클러스터 전체 노드에 대한 서버 토큰 로테이션을 지원한다.
SELinux
RKE2는 SELinux를 지원하며, container-selinux 기반의 커스텀 SELinux 정책을 제공한다.
- RPM 설치: SELinux가 기본 활성화된다.
- tarball 설치: 수동으로
selinux: true설정이 필요하다. - 커스텀 컨텍스트:
rke2_service_t(서비스용)와rke2_service_db_t(데이터 스토어용) 레이블을 사용하여, containerd의 비표준 설치 경로에 대한 보안을 처리한다.

댓글남기기