
[Kubernetes] 쿠버네티스 스케줄링 - 2. 프로세스와 선점
TL;DR
- 스케줄러는 PreFilter → Filter → Score → Bind 순서로 파드를 노드에 배치한다. 모든 노드가 Filter에서 탈락하면 PostFilter 단계가 실행된다.
- Filter는 부적합 노드를 탈락시키고(리소스, 배치 규칙, 볼륨 등), Score는 통과 노드에 0~100 점수를 가중 합산하여 최적 노드를 선택한다. 하나의 플러그인이 Filter와 Score 양쪽에 등록될 수 있다.
- 선점(Preemption): 모든 노드가 부적합할 때, PostFilter 단계에서 낮은 우선순위 파드를 축출하여 공간을 확보한다. 선점이 동작하려면
PriorityClass가 정의되어 있어야 한다. nominatedNodeName은 선점 후 다른 파드가 해당 공간에 끼어드는 것을 방지하는 예약 마커이며, 해당 노드에 반드시 스케줄링된다는 보장은 없다.
들어가며
이전 글에서 스케줄링의 기본 개념, 스케줄링 대상, 스케줄러 큐 구조에 대해 알아보았다. 이번 글에서는 다음 두 가지를 다룬다.
- 스케줄링 프로세스: 스케줄러가 파드를 노드에 배치하는 전체 단계(PreFilter → Filter → Score → Bind)와 PostFilter 단계의 동작
- 선점 메커니즘: PriorityClass 기반의 선점이 동작하는 방식,
nominatedNodeName의 역할과 한계
스케줄러가 어떤 단계를 거쳐 노드를 선택하는지, 모든 노드가 부적합할 때 어떻게 선점이 동작하는지를 이해하면, 파드가 Pending 상태에 빠졌을 때 원인을 빠르게 좁혀 나갈 수 있다.
프로세스
쿠버네티스 스케줄러가 파드를 노드에 배치하는 프로세스를 메인 스케줄링 프로세스와 PostFilter 단계로 나누어 살펴본다.
메인 스케줄링 프로세스
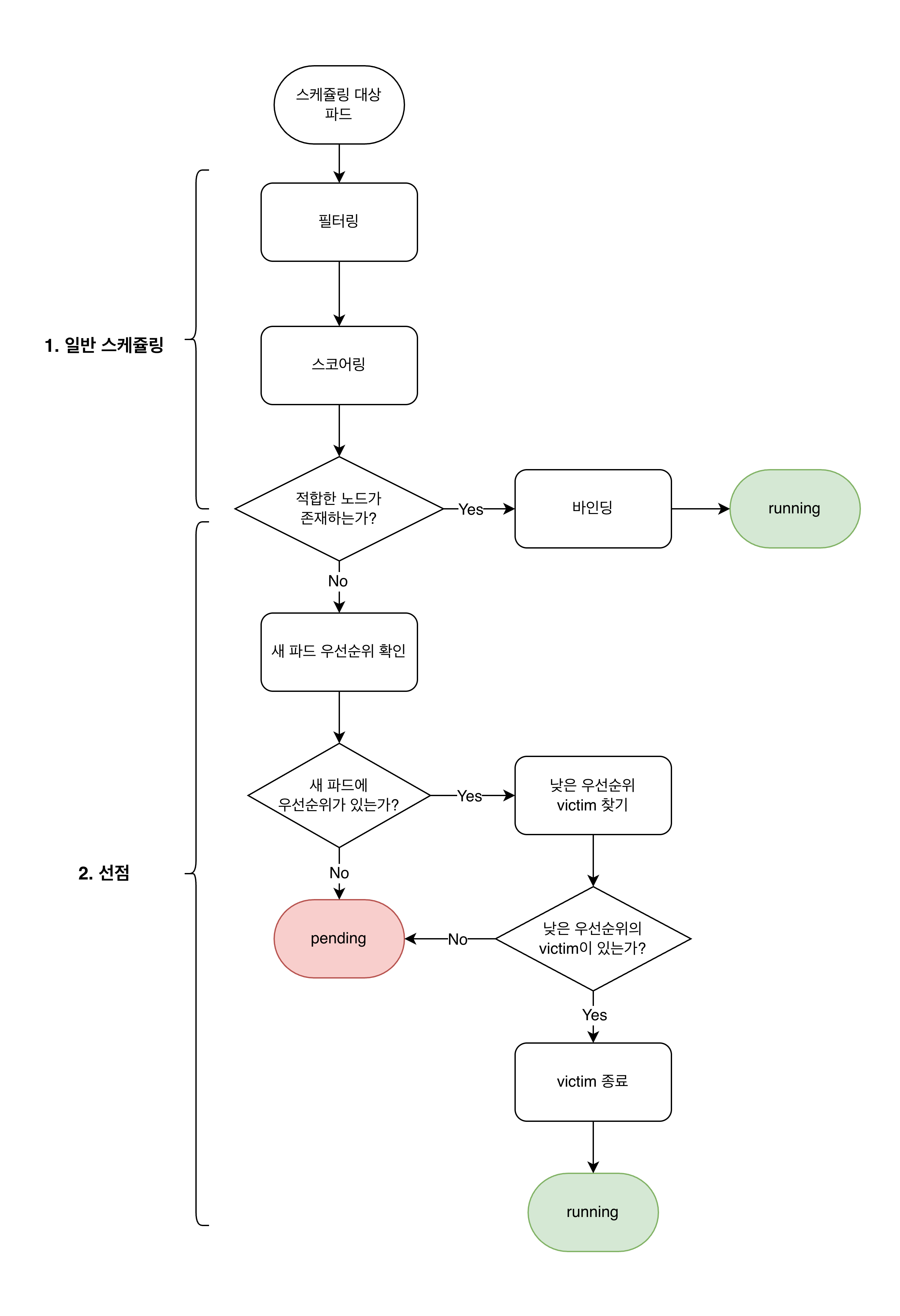
- 스케줄링 대상 파드: Active Queue에 있는 파드
- 전체 단계
- PreFilter: 스케줄링 전 사전 처리
- Filter: 모든 노드 동시 체크 (병렬)
- 성공 시, PreScore 단계로 감
- 실패 시, PostFilter 단계로 감
- PostFilter: 필터링 실패 시 실행 (여기서 선점 로직 동작)
- PreScore: 스코어링 전 사전 처리
- Score: 필터링 통과한 노드에 대해 점수 부여 (병렬)
- NormalizeScore: 점수 정규화
- Reserve: 선택된 노드에 리소스 예약
- 실제 바인딩 전에 리소스를 예약하여 다른 스케줄러 인스턴스와의 경쟁 방지
- Reserve 실패 시 다른 노드로 재시도, Reserve 성공 후 Bind 실패 시 예약 해제(Unreserve)
- Permit: 스케줄링 승인 대기
- 웹훅 등 외부 승인을 기다리는 단계 (기본적으로는 즉시 승인)
- 승인 대기 중에는 다른 파드가 해당 노드의 리소스를 사용할 수 있음
- PreBind: 바인딩 전 작업 (예: 볼륨 프로비저닝)
- Bind: 실제 노드에 파드 바인딩
- API Server에 PATCH 요청을 보내
spec.nodeName을 설정하는 것이 핵심 작업 spec.nodeName이 설정되면 해당 노드의 Kubelet이 파드를 감지하고 실행을 시작- PodScheduled condition은 API Server가 자동으로 업데이트
- Bind 실패 가능성: 노드가 갑자기 NotReady 상태가 되거나, 노드의 리소스가 부족해지거나, 네트워크 문제로 API Server와 통신 실패
- 실패 시 파드가 Backoff Queue로 이동
PATCH /api/v1/namespaces/default/pods/my-pod { "spec": { "nodeName": "worker-node-1" # 바인딩: nodeName 설정 } }
- API Server에 PATCH 요청을 보내
- PostBind: 바인딩 후 작업
주요 단계 상세
위 파이프라인에서 핵심이 되는 세 단계(Filter, Score, PostFilter)를 상세히 살펴본다. 이 세 단계가 쿠버네티스의 Scheduling Framework에서 정의한 extension point로, 각 extension point에 플러그인을 등록하여 스케줄링 로직을 구성한다. 하나의 플러그인이 여러 extension point에 동시에 등록될 수 있다(예: TaintToleration은 Filter와 Score 양쪽에 등록).
Filter 단계
부적합한 노드를 탈락시키는 단계다. 각 노드에 대해 등록된 Filter 플러그인을 순차 실행하며, 하나라도 실패하면 해당 노드는 즉시 탈락한다.
주요 특성은 아래와 같다.
- 노드 간 병렬 처리: 여러 노드에 대한 필터링을 동시에 수행한다.
- 대규모 클러스터 최적화: 클러스터 노드가 많을 경우, 모든 노드를 평가하지 않는다. 스케줄러는
percentageOfNodesToScore파라미터(기본값: 클러스터 규모에 따라 자동 조정)에 따라 충분한 수의 적합 노드를 찾으면 나머지 노드 평가를 중단한다. 예를 들어 5,000노드 클러스터에서 모든 노드를 평가하면 스케줄링 지연이 커지므로, 적합 노드를 일정 수 확보하면 바로 Score 단계로 넘어간다. 이것은 스케줄링 품질과 성능 사이의 트레이드오프이다.
대표적인 Filter 플러그인은 다음과 같다.
| 분류 | 플러그인 | 체크 항목 |
|---|---|---|
| 노드 상태 | NodeUnschedulable | 노드가 Unschedulable로 마킹되어 있는지 (kubectl cordon 적용 여부) |
| 리소스 | NodeResourcesFit | CPU, Memory 등 리소스 충분 여부. requests 기준으로 판단하며, limits는 스케줄링 시 고려하지 않는다. GPU 등 extended resource는 limits만 설정하면 requests도 동일하게 자동 설정되므로 결과적으로는 같지만, 원리적으로는 항상 requests 기준 |
| 배치 규칙 | NodeSelector | nodeSelector 라벨 일치 여부 |
| 배치 규칙 | NodeAffinity | requiredDuringSchedulingIgnoredDuringExecution 조건 만족 여부 |
| 배치 규칙 | TaintToleration | 노드의 taint를 파드가 tolerate하는지 |
| 배치 규칙 | PodTopologySpread | 토폴로지 분산 규칙의 maxSkew 위반 여부 |
| 배치 규칙 | InterPodAffinity | 파드 간 anti-affinity의 requiredDuringScheduling 조건 충족 여부 |
| 실용성 | VolumeBinding | 요청한 PVC/PV가 해당 노드에서 마운트 가능한지 |
| 실용성 | NodePorts | 요청한 hostPort가 해당 노드에서 이미 사용 중인지 |
참고: NodeAffinity와 InterPodAffinity의
preferredDuringScheduling조건은 Filter가 아닌 Score 단계에서 처리된다. Filter에서는required조건만 체크한다.
Score 단계
Filter를 통과한 노드들 중 최적의 노드를 선택하는 단계다. 각 노드에 점수를 부여하고, 최종적으로 가장 높은 점수를 받은 노드에 파드를 배치한다.
스코어링 과정은 다음과 같다.
- Score: 각 Score 플러그인이 노드에 0~100 범위의 점수를 부여한다.
- NormalizeScore: 플러그인별로 점수를 0~100 범위로 정규화한다.
- 가중치 적용: 각 플러그인에 설정된 가중치(weight)를 곱한다. 가중치는
KubeSchedulerConfiguration에서 플러그인별로 설정할 수 있으며, 기본값은 1이다. - 합산 및 선택: 모든 플러그인의 가중 점수를 합산하여 최고 점수 노드를 선택한다. 동점인 경우 라운드 로빈으로 선택한다.
대표적인 Score 플러그인은 다음과 같다.
| 플러그인 | 스코어링 기준 | 비고 |
|---|---|---|
| NodeResourcesFit | 리소스 여유가 많은 노드 선호 (MostAllocated / LeastAllocated 전략 선택 가능) |
기본값은 LeastAllocated (리소스를 고르게 분산) |
| NodeResourcesBalancedAllocation | CPU와 Memory의 사용 비율이 균형 잡힌 노드 선호 | CPU 80% / Memory 20%보다 CPU 50% / Memory 50%에 높은 점수 |
| ImageLocality | 파드에 필요한 컨테이너 이미지가 이미 존재하는 노드 선호 | 이미지 크기가 클수록 점수 가산 |
| TaintToleration | toleration이 필요 없는(taint가 적은) 노드 선호 | |
| NodeAffinity | preferredDuringScheduling 조건에 부합하는 노드에 높은 점수 |
|
| InterPodAffinity | 파드 간 preferredDuringScheduling 친화성 조건 반영 |
|
| PodTopologySpread | 토폴로지 분산이 균일한 배치에 높은 점수 |
참고:
NodeResourcesFit은 Filter와 Score 양쪽에 등록되는 대표적인 플러그인이다. Filter에서는 “리소스가 충분한가”를 판단하고, Score에서는 “충분한 노드들 중 어디가 더 적합한가”를 평가한다.
큐 복귀
이전 글에서 스케줄러가 큐 관리 역할을 담당한다고 했는데, 스케줄링 프로세스의 결과에 따른 큐 간 파드 이동도 모두 스케줄러가 담당한다.
- 스케줄링 실패 시 큐 이동: 실패 유형에 따라 다른 큐로 이동시킨다
- Score 단계 이후, 노드가 선택된 상태에서 바인딩까지 일시적 문제로 실패한 경우 → Backoff Queue
- 애초에 배치 가능한 노드를 찾지 못해 노드 선택 자체가 실패한 경우 → Unschedulable Queue
- Active Queue로의 복귀: 조건이 충족되면 다시 Active Queue로 이동시킨다
- Backoff Queue: 타이머 만료 시(스케줄러가 주기적으로 확인)
- Unschedulable Queue: 클러스터 이벤트 발생 시
- 선점 성공: PostFilter 단계에서 선점에 성공하여
nominatedNodeName이 설정된 경우 즉시 Active Queue로 이동
PostFilter 단계
필터링 단계에서 모든 노드에 대한 필터링이 실패했을 경우, PostFilter 단계를 진행한다. 아래 그림에서, 이전 그림에 비해 더 자세히 나타난 3 이후의 부분이다.
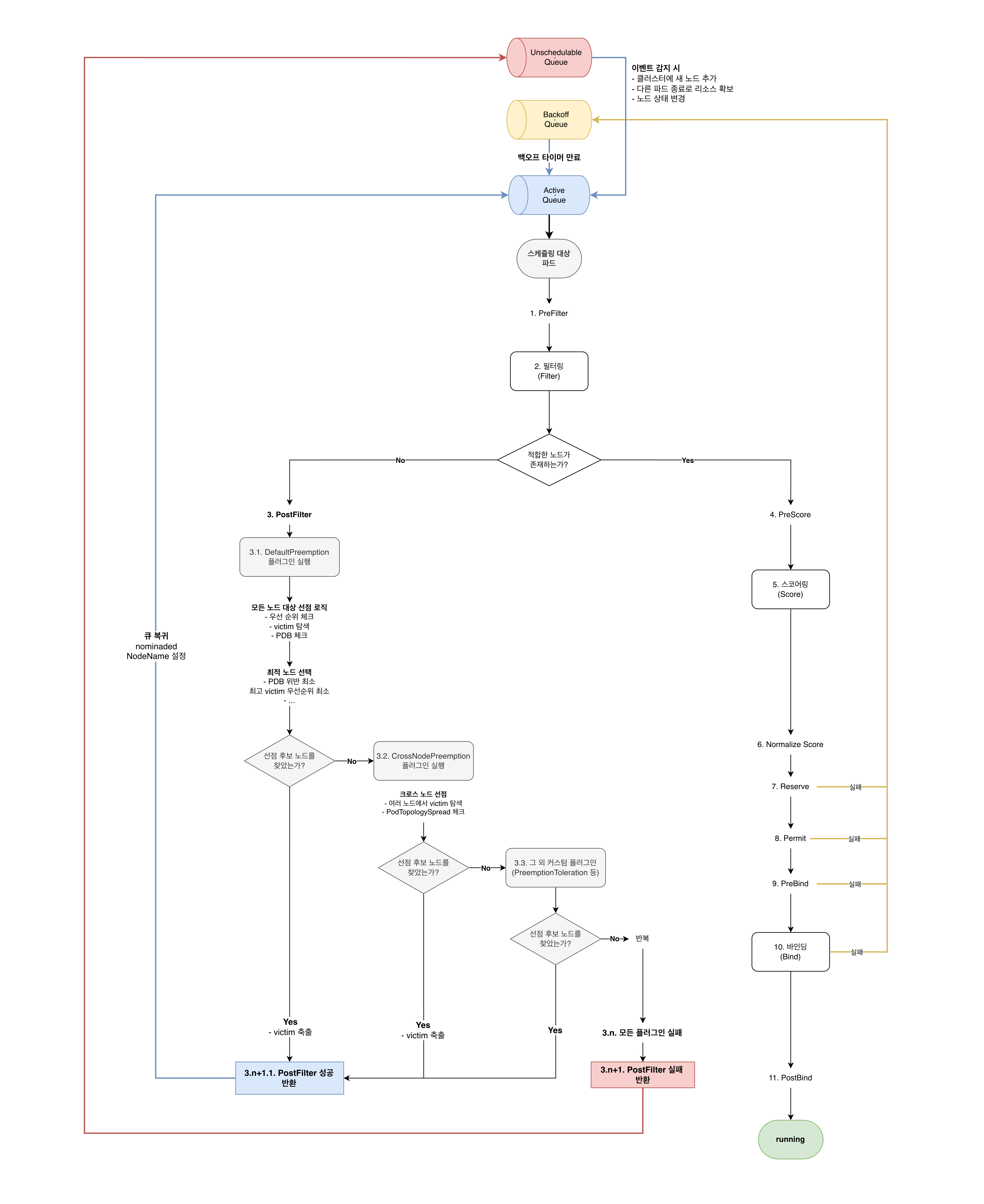
그림에서는 단일 큐로 표현했지만, 실제로는 Active Queue, Backoff Queue, Unschedulable Queue 3개로 구성된다.
Filter 단계가 실패하면 실행되는 확장점(extension point)이다. 공식 문서에 의하면, 다음과 같다.
PostFilter is called by the scheduling framework when the scheduling cycle failed at Prefilter or Filter
다양한 플러그인으로 구성되어, 각각의 플러그인이 실행되는 형태이다. DefaultPreemption(선점)이라는 기본 플러그인이 제공되며, 그 외에 다른 플러그인도 등록할 수 있다. 커스텀 플러그인을 만들어 등록하는 것 또한 가능하다.
설정된 순서대로 실행되며, 첫 번째로 성공한 플러그인에서 nominatedNodeName, 즉, 파드를 실행할 수 있는 노드명이 설정된다.
- PostFilter 플러그인 실행 규칙
- 순차 실행: 설정된 순서대로 하나씩 실행
- Early Exit: 첫 번째 성공한 플러그인에서 종료, 나머지는 실행 안 함
- 단일 nominatedNodeName: 파드당 하나의 후보 노드만 설정 가능
- 플러그인별 동작 방식
- DefaultPreemption:
- 모든 노드를 평가하여 각 노드에서 선점 가능 여부 확인
- 선점 알고리즘으로 최적의 단일 노드 선택
- 선택 기준: PDB 위반 최소 → 최고 victim 우선순위 최소 → victim 개수 최소
- 선택된 하나의 노드에서만 victim 축출
- CrossNodePreemption:
- 여러 노드 조합을 평가
- cross-node 제약(PodTopologySpread, AntiAffinity) 고려
- 여러 노드에 걸쳐 victim 축출 가능
- PreemptionToleration: victim 측면의 선점 정책 커스터마이징
- DefaultPreemption:
nominatedNodeName이 설정된 파드는 다시 스케줄링 큐로 돌아가며, 추후 다시 스케줄링 프로세스를 거친다.
프로세스 결과와 큐 이동 요약
위 프로세스를 종합하면, PostFilter에서 선점에 성공하여 nominatedNodeName이 설정된 파드는 큐로 돌아가 재스케줄링을 시도하고, PostFilter에서도 후보 노드를 찾지 못하면 Unschedulable Queue로 이동한다. 이 모든 과정에서 파드는 Pending 상태를 유지하며, 스케줄링에 성공해 바인딩되고 컨테이너가 시작되어야 비로소 Running 상태가 된다. 큐 구조와 큐 간 이동 조건에 대한 자세한 내용은 이전 글의 스케줄러 큐 섹션을 참고한다.
| 프로세스 결과 | 이동 대상 큐 |
|---|---|
| Filter 통과 → Score → Bind 성공 | 스케줄링 완료 (큐에서 제거) |
| Filter 통과 → Bind 실패 (일시적 문제) | Backoff Queue |
| Filter 전체 실패 → PostFilter 선점 성공 | Active Queue (재스케줄링) |
| Filter 전체 실패 → PostFilter 실패 | Unschedulable Queue |
선점
공식 문서에서는 이렇게 설명한다.
Pods can have priority. Priority indicates the importance of a Pod relative to other Pods. If a Pod cannot be scheduled, the scheduler tries to preempt (evict) lower priority Pods to make scheduling of the pending Pod possible.
즉, 우선순위가 더 높은 파드를 위해 더 낮은 우선순위 파드를 종료하는 것이다. “선점”이라는 표현이 해당 파드가 직접 리소스를 빼앗는 것처럼 들리지만, 실제 동작은 낮은 우선순위 파드를 종료시켜 공간을 확보한 후, 높은 우선순위 파드가 그 공간에 스케줄링되는 방식이다. 선점한 파드에는 nominatedNodeName이 설정된다.
우선순위에 따라 결정한다는 것이 중요하다. 즉, 선점이 이루어지기 위해서는 우선순위가 있어야 한다.
-
priorityClass 리소스를 정의해야 함
--- apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false # true로 설정하면 priorityClassName 미지정 파드의 기본값으로 사용됨 (클러스터당 1개만 가능) preemptionPolicy: PreemptLowerPriority # PreemptLowerPriority: 낮은 우선순위 파드 선점 가능 / Never: 선점하지 않음 description: "High priority pods" --- apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: low-priority value: 1000 globalDefault: false description: "Low priority pods" -
기존 파드와 우선순위 대상 파드에 해당 priorityClass가 적용되어 있어야 함
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent priorityClassName: high-priority
대부분 파드를 그 자체로 띄우지 않으므로, Deployment와 같은 리소스 컨트롤러에 우선순위를 적용한다. 같은 리소스 컨트롤러에서 생성된 파드는 같은 우선순위를 갖는다. 실제 프로덕션 환경에서는 서로 다른 워크로드 간 우선순위 차이를 적용해 선점을 활용한다.
| 높은 우선순위 | 낮은 우선순위 | 비고 |
|---|---|---|
| 프로덕션 환경 파드 | 개발/테스트 환경 파드 | |
| 핵심 서비스 | 배치 작업 | |
| 상시 서비스 | ML 학습 작업 | preemptionPolicy: Never 활용 |
| 시스템 컴포넌트 | 사용자 워크로드 | system-cluster-critical |
리소스가 제한적인 클러스터에서는 이러한 우선순위 설정이 서비스 안정성 확보를 위해 필수적이다. 예를 들어, ML 서비스에서 긴급한 추론 요청이 들어왔을 때 학습 워크로드보다 높은 우선순위를 부여하거나, 권한이 다른 사용자 간 학습 작업의 우선순위를 차등 적용하는 등의 방식으로 활용할 수 있다.
nominatedNodeName이 하는 일
PostFilter 단계 이후, nominatedNodeName이 설정된 파드는 스케줄링 큐로 돌아가 다시 필터링, 스코어링 등 원래 스케줄링 프로세스를 거친다. 그렇다면 nominatedNodeName의 역할은 무엇인가?
nominatedNodeName은 선점 후 victim 파드가 종료되는 동안:
- 다른 낮은 우선순위 파드가 끼어들어 그 공간을 차지하는 것을 방지하고,
- 리소스 예약을 표시하는 역할을 하여,
- 스케줄러가 다른 파드를 평가할 때, nominated 파드도 실행 중인 것처럼 계산한다.
예컨대, 아래와 같은 문제 상황을 방지하는 것이다.
- 높은 우선순위 파드 P가 선점 성공
- victim 파드 축출 시작
- 파드 P는 큐로 돌아가 대기
- 그 사이 다른 파드가 끼어 들어서 victim이 비운 공간을 차지
- 파드 P는 영원히 기다림
nominatedNodeName이 설정되면, 스케줄러가 해당 파드도 실행 중인 것처럼 계산하므로, 다른 파드를 평가할 때 이미 예약된 리소스로 간주하여 끼어들기를 방지한다.
다만, nominatedNodeName이 설정된 파드더라도, nominated node에 항상 스케줄링된다는 보장은 없다. 높은 우선순위 파드가 나타나게 되면, 변경될 수 있다. 공식 문서의 표현에 따르면, 아래와 같다. 보장되지는 않는다는 것이다.
Please note that Pod P is not necessarily scheduled to the ‘nominated Node’.
정리
이 글에서 다룬 핵심 내용을 정리한다.
- 스케줄링 프로세스는 Filter → Score → Bind 순서로 진행된다. Filter에서 모든 노드가 탈락하면 PostFilter가 실행되고, 여기서 선점 등의 로직이 동작한다.
- Filter는 부적합 노드를 탈락시키고, Score는 최적 노드를 선택한다. Filter에서는
requests기준으로 리소스를 판단하며,required조건만 체크한다. Score에서는preferred조건과 리소스 분산 전략 등을 반영하여 0~100 점수를 가중 합산한다. 하나의 플러그인이 Filter와 Score 양쪽에 등록될 수 있다. - 선점은 PriorityClass 기반으로 동작한다. 우선순위가 정의되지 않으면 선점은 발생하지 않는다. 선점의 핵심 선택 기준은 PDB 위반 최소 → 최고 victim 우선순위 최소 → victim 개수 최소 순이다.
nominatedNodeName은 예약 마커일 뿐, 보장이 아니다. 선점 후 다른 파드의 끼어들기를 방지하는 역할을 하지만, 해당 노드에 반드시 스케줄링된다는 보장은 없다.
이전 글의 큐 구조와 함께 이해하면, 파드가 왜 Pending 상태에 빠지는지, 어떤 조건에서 빠져나올 수 있는지를 체계적으로 파악할 수 있다. 이 내용이 실제 문제 상황에서 어떻게 적용되는지는 Deployment 재배포 실패 원인과 해결 시리즈에서 다루고 있다.

댓글남기기