
[DL] AutoEncoder_2.구현_차원 축소 1
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
오토 인코더 구현-차원 축소-이미지
MNIST 데이터셋을 가지고 오토 인코더를 구현해 본다. 차원 축소가 어떻게 이루어지는지 확인하자. feed forward network와 convolutional neural network를 사용할 때 오토 인코더의 네트워크 구성 및 latent feature가 어떻게 달라지는지 확인한다.
1. Feed Forward Network
(28, 28)의 shape을 갖는 입력 데이터(MNIST 이미지)를 (10, 10)의 데이터로 변환한다. 차원을 축소한 뒤, latent feature를 KMeans 알고리즘을 이용해 군집화한다.
# 모듈 불러오기
import pickle
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 경로 설정
data_path = '...'
# 데이터 로드
with open(f"{data_path}/mnist.pickle", 'rb') as f:
mnist = pickle.load()
# 1) 데이터 준비
X_data = mnist.data[:3000]
X_image = X_data.copy()
scaler = StandardScaler()
X_data = scaler.fit_transform(X_data.T).T
# 2) 파라미터 설정
n_input = X_data.shape[1]
n_feature = 100
n_output = n_input
# 3) 모델 레이어 설정
x_Input = Input(batch_shape=(None, n_input))
x_Encoder = Dense(256, activation='relu')(x_Input) # 인코더 1층
x_Encoder = Dense(n_feature, activation='relu')(x_Encoder) # 인코더 2층
y_Decoder = Dense(256, activation='relu')(x_Encoder) # 디코더 1층
y_Decoder = Dense(n_output, activation='linear')(y_Decoder) # 디코더 2층
# 4) 모델 구성
model = Model(x_Input, y_Decoder) # 오토인코더 모델 전체
model.compile(loss='mse', optimizer=Adam(lr=0.01))
print("====== AutoEncoder 모델: 전체 구조 ======")
print(model.summary())
encoder = Model(x_Input, x_Encoder) # 인코더 모델
print("====== AutoEncoder 모델: 인코더 부분 ======")
print(encoder.summary())
# 5) 모델 학습
EPOCHS = 500
BATCH = 300
hist = model.fit(X_data, X_data, epochs=EPOCHS, batch_size=BATCH)
# 6) latent feature 확인
mnist_latent = encoder.predict(X_data)
sample_num = 100
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
ax1.imshow(X_image[sample_num].reshape(28, 28), cmap='Greys')
ax2.imshow(X_image[sample_num].reshape(10, 10), cmap='Greys')
plt.show()
# 7) latent feature 기준 KMeans 군집화
km = KMeans(n_clusters=10, init='k-means++', n_init=3, max_iter=300, tol=1e-04, random_state=42, verbose=1)
km.fit(mnist_latent)
clust = km.predict(mnist_latent)
# 8) 군집화된 latent feature 확인
for k in np.unique(clust):
idx = np.where(clust==k)[0][:10] # 클러스터 라벨이 k인 이미지 10개의 인덱스
f1 = plt.figure(figsize=(8, 2)) # 원래 이미지
f2 = plt.figure(figsize=(8, 2)) # latent feature
for i in range(10):
# 원본 이미지 그림
image = X_image[idx[i]].reshape(28, 28)
ax1 = f1.add_subplot(1, 10, i+1)
ax1.imshow(image, cmap=plt.cm.bone)
ax1.grid(False)
ax1.set_title(f"{k}-original")
ax1.xaxis.set_ticks([])
ax1.yaxis.set_ticks([])
# latent
image_latent = mnist_latent[idx[i]].reshape(10, 10)
ax2 = f2.add_subplot(1, 10, i+1)
ax2.imshow(image_latent, cmap='Greys')
ax2.grid(False)
ax2.set_title(f"{k}-latent")
ax2.xaxis.set_ticks([])
ax2.yaxis.set_ticks([])
plt.tight_layout()
1.1. 오토 인코더
1) 데이터 준비
학습하는 데 시간이 많이 걸리기 때문에 3000개의 데이터만 사용한다. 오토인코더에는 target이 필요하지 않다.
표준화를 위해서는 모든 픽셀의 수치를 255로 나눠주어도 되지만, 연습을 위해 StandardScaler를 사용해 Z-Score Normalization을 진행한다. StandardScaler는 feature별로 표준화를 진행하므로, transpose하여 각각의 이미지에 대해 표준화를 진행한다. 그 결과를 다시 transpose함으로써, 원래의 (3000, 784)의 shape을 가지도록 한다.
2) 파라미터 설정
인코더 층을 거친 후 축소하고 싶은 차원의 수를 n_feature에 설정한다. 오토인코더는 입력과 출력 데이터가 같기 때문에, 입력 노드의 수 n_input과 출력 노드의 수 n_output이 같다.
3) 오토 인코더 모델 구성
Input, Dense 레이어를 활용해 Stacked 오토인코더 모델을 구성한다. 모델 아키텍쳐를 간단히 나타내면 다음과 같다.
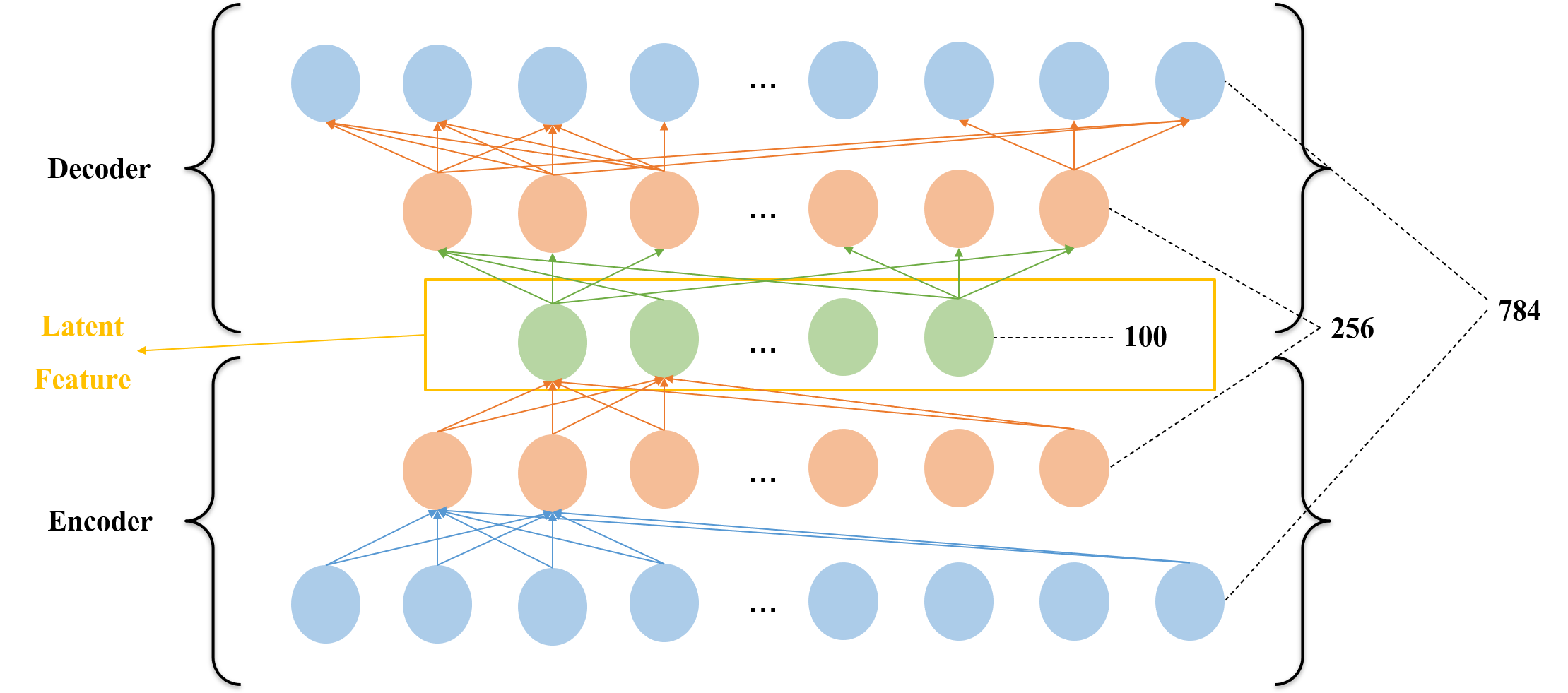
가운데 층이 차원이 축소된 결과를 나타낸다.
4) 모델 구조 확인
전체 오토인코더 모델의 이름은 model이라 한다. x_Input이 입력, y_Decoder가 출력이 된다. 인코딩 부분과 디코딩 부분이 대칭 으로 구성된다.
차원 축소가 목적이기 때문에 중간 층의 출력 벡터를 확인하면 된다. 중간 층의 출력 벡터를 확인하기 위해 encoder 모델을 구성한다. x_Input을 입력하고, x_Encoder가 출력되게 한다. 그 결과가 입력 데이터에서 차원이 축소되어 잠재된 특징을 가지고 있는 latent feature가 된다.
참고
인코더 모델인
encoder가 전체 오토 인코더 모델인model안에 포함되어 있기 때문에,model만 컴파일해도encoder를 사용할 수 있다.
차원을 축소해 latent feature를 뽑아낼 때 활성화 함수로 linear를 사용했다. 축소하고 싶은 차원을 설정해 주면 된다. PCA 처럼 선형 관계가 있다고 가정하고 linear 형태로 뽑아내는 건가?
5) 모델 학습
모델 훈련 시 출력으로 사용될 label 데이터가 따로 존재하지 않는다. 입력 데이터의 차원을 축소하여 최대한 입력 데이터와 비슷하게 만들어 주는 것이 목적이다. 따라서 원본 이미지를 모두 훈련용, 라벨용으로 사용하여 둘 간의 차이를 줄인다.
6) latent feature 확인
Encoder 모델에 입력 데이터를 넣고, 예측한다. 예측 결과 자체 가 바로 latent feature이다.
1.2. 군집화
7) KMeans 군집화
100차원으로 축소된 latent feature를 기준으로 군집화한다. 초기 중점 설정 횟수를 3, 최대 중점 변경 횟수를 100으로 설정한다. 군집화 결과로 나온 클러스터 라벨은 이미지 데이터가 나타내는 숫자와 무관하다.
8) 군집화 결과 이미지 확인
각 클러스터링 라벨 별로 10개의 이미지를 추출해 확인한다. 다만, 강사님 코드를 변형해 원본 이미지와 latent feature를 모두 이미지로 나타내도록 했다. 차원 축소가 어떻게 이루어지는지 직접 확인하기 위함이다. 가독성을 위해 cmap만 다르게 설정한다.

군집화 성능 자체는 예전 강의에서와 마찬가지로 좋은 것 같지 않다. 굳이 원본 데이터를 사용하지 않고 100차원으로 축소된 데이터를 사용하더라도 군집화 성능에 유의미한 향상이 일어나지는 않는다.
참고
물론 KMeans 알고리즘의 파라미터를 조정하지 않았다. 그러나 이 부분은 예전 강의에서 파라미터를 조정했을 때에도 큰 성능 향상이 있지는 않았다.
군집화된 모든 이미지를 확인한 것이 아니라는 점도 고려해야 한다.
다만, 0, 1, 6 등의 이미지는 이전과 마찬가지로 비교적 잘 군집화한다. 어떻게 본다면 차원 축소가 원본과 비슷하게 잘 되었기 때문에(?) 군집화 결과에서도 성능이 나는 이미지가 유사하다고 볼 수 있지 않을까?
1.3. 더 생각해 볼 점
애초에 차원 축소를 목적으로 진행한 작업이기 때문에, 100차원으로 축소된 데이터가 어떤 형태인지 살펴 보았다. 사람이 알아 보기에 적절하지는 않다.
이후 CNN 네트워크를 활용해 구성한 오토 인코더와 같은 조건에서 비교하기 위해 다음과 같이 강사님 코드를 수정했다. 원래의 Encoder 모델의 출력에 linear 활성화 함수를 사용해 Dense 레이어를 거치도록 했다.
# 3) 모델 레이어 설정
x_Input = Input(batch_shzpe=(None, n_input))
x_Encoder = Dense(256, activation='relu')(x_Encoder)
x_Encoder = Dense(n_feature, activation='relu')(x_Encoder)
e_latent = Dense(10*10, activation='linear')(x_Encoder)
y_Decoder = Dense(256, activation='relu')(e_latent)
y_Output = Dense(n_output, activation='linear')(y_Decoder)
...
encoder = Model(X_Input, e_latent)
mnist_latent = encoder.predict(X_train)
샘플로 한 장의 이미지만 확인했다. 1.1에서의 결과와 비슷하게, 사람이 알아보기는 힘들어 보인다.
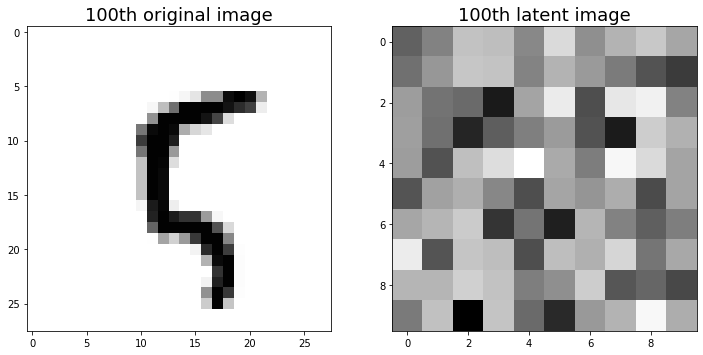
2. Convolutional Neural Network
(28, 28)의 입력 데이터(MNIST 이미지)를 (14, 14)의 데이터로 변환한다. 차원을 축소한 뒤 latent feature map을 이용해 KMeans 알고리즘으로 군집화한다.
# 모듈 불러오기
import pickle
from tensorflow.keras.layers import Input, Conv2D, Flatten, Conv2DTranspose, Dense, Reshape
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 데이터 로드 및 준비
with open(f"{data_path}/mnist.pickle", 'rb') as f:
mnist = pickle.load(f)
X_data = mnist.data[:3000]
X_image = X_data.copy() # 그림 확인용
# 1) 2차원 이미지 변환 및 표준화
X_data = X_data / 255.0
X_data = X_data.reshape(-1, 28, 28)
X_data = X_data[:, :, :, np.newaxis] # channel 축 추가
# 파라미터 설정
n_height = X_data.shape[1]
n_width = X_data.shape[2]
n_channel = X_data.shape[3] # 흑백 이미지
# 2) 모델 레이어 설정
x_Input = Input(batch_shape=(None, n_height, n_width, n_channel)) # 인코더 입력
# 인코더
e_conv = Conv2D(filters=10, kernel_size=(5, 5), strides=1, padding='SAME', activation='relu')(x_Input)
e_pool = MaxPooling2D(pool_size=(5, 5), strides=1, padding='VALID')(e_conv)
e_flat = Flatten()(e_pool)
e_latent = Dense(14*14, activation='linear')(e_flat) # latent feature map: 여기서 축소(최종)
e_latent = Reshape((14, 14, 1))(e_latent) # 디코더 입력
# 디코더
d_conv_t = Conv2DTranspose(filters=10, kernel_size=(4, 4), strides=2, padding='SAME', activation='relu')(e_latent)
x_Output = Conv2D(filters=1, kernel_size=(4, 4), padding='SAME')(d_conv_t)
# 3) 모델 구성
model = Model(x_Input, x_Output)
model.compile(loss='mse', optimizer=Adam(lr=0.005))
print("====== AutoEncoder 모델: 전체 구조 ======")
print(model.summary())
encoder = Model(x_Input, e_latent) # 인코더 모델
print("====== AutoEncoder 모델: 인코더 부분 ======")
print(encoder.summary())
# 모델 학습
EPOCHS = 500
BATCH = 300
hist = model.fit(X_data, X_data, epochs=EPOCHS, batch_size=BATCH)
# latent feature map 확인
mnist_latent = encoder.predict(X_data)
sample_num = 100
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
ax1.imshow(X_image[sample_num].reshape(28, 28), cmap='Greys')
ax2.imshow(mnist_latent[sample_num].reshape(14, 14), cmap='Greys')
plt.show()
# 5) latent feature 기준 KMeans 군집화
mnist_latent = mnist_latent[:, :, :, 0] # channel 축 제거
mnist_latent = mnist_latent.reshape(-1, 14*14)
km = KMeans(n_clusters=10, init='k-means++', n_init=3, max_iter=300, tol=1e-04, random_state=42, verbose=1)
km.fit(mnist_latent)
clust = km.predict(mnist_latent)
# 6) 군집화된 latent feature 확인
for k in np.unique(clust):
idx = np.where(clust==k)[0][:10]
f1 = plt.figure(figsize=(8, 2))
f2 = plt.figure(figsize=(8, 2))
for i in range(10):
# 원본 이미지 그림
image = X_image[idx[i]].reshape(28, 28)
ax1 = f1.add_subplot(1, 10, i+1)
ax1.imshow(image, cmap=plt.cm.bone)
ax1.grid(False)
ax1.set_title(f"{k}-original")
ax1.xaxis.set_ticks([])
ax1.yaxis.set_ticks([])
# latent feature map
image_latent = mnist_latent[idx[i]].reshape(14, 14)
ax2 = f2.add_subplot(1, 10, i+1)
ax2.imshow(image_latent, cmap='Greys')
ax2.grid(False)
ax2.set_title(f"{k}-latent")
ax2.xaxis.set_ticks([])
ax2.yaxis.set_ticks([])
plt.tight_layout()
2.1. 오토 인코더
Feed Forward Network로 구현할 때와는 모델의 구성 및 차원축소 결과가 달라진다.
1) 이미지 변환 및 표준화
FFN으로 구성할 때와는 달리 CNN에 입력해 주기 위한 형태로 이미지 데이터의 차원을 변환해주는 과정이 필요하다. 픽셀 표준화를 진행한 후, 이미지를 (3000, 28, 28) shape으로 변경하고, 채널 축을 추가한다.
2) 오토 인코더 모델 구성
Input, Conv2D, Conv2D, Dense 등의 레이어를 활용해 오토 인코더 모델을 구성한다. 모델 아키텍쳐는 다음과 같다.

shape 맞추다가 머리 깨지는 줄 알았다(^^;;)
흑백 이미지 3000장을 입력으로 받아야 하므로, 4차원 텐서를 x_Input 레이어에 입력 받는다. 이후 10개의 필터를 사용해 인코더의 Conv2D 레이어를 통과시켜 특징을 뽑아내고, MaxPooling을 진행한다. 이후 Flatten 레이어에 통과시켜 24 x 24 x 10 = 5760차원의 1차원 벡터로 평활화한 뒤, 이를 linear 활성화 함수를 갖는 Dense 레이어에 통과시켜 차원을 축소한다. 여기까지가 모델의 인코더 부분이 된다. e_flat을 입력으로 받아 linear 활성화 함수를 적용한 e_latent 출력 벡터가 latent feature map이다.
FFN에서와 마찬가지로 latent feature를 추출하는 과정에서 linear 활성화 함수를 적용한 Dense 레이어를 사용하는데, 이 때 줄이고 싶은 크기를 Height x Width 형태로 입력하면 된다.
이후 모델의 디코더 부분을 구성한다. Conv2D 레이어로 축소시킨 이미지를 다시 확장한다. shape을 변경해주어야 한다. 디코딩 레이어를 구성하기 앞서, 차원이 축소된 latent feature의 차원을는 점에 주의하자. Reshape 레이어를 활용해 3차원의 흑백 이미지 형태로 shape을 바꾼다. 그리고 데이터 크기를 확장하기 위해 Conv2DTranspose 레이어를 사용한다. padding 옵션을 ‘SAME’으로 설정하여, Height와 Width가 stride배만큼 확장되어 원래의 (28, 28) shape을 갖도록 한다. 이제 채널 축의 차원을 줄여 주기 위해 Conv2D 레이어를 다시 적용한다. 위에서 특징을 뽑아 내기 위해 여러 개의 필터를 사용한 것과 달리, 이제는 특징을 합쳐 주기 위해 (Conv2D 레이어가 이렇게 사용될 수도 있다..!) 필터 개수를 1로 설정한다.
모든 레이어를 통과한 뒤 나온 x_Output이 CNN 네트워크를 활용한 오토인코더의 출력이 된다.
4) 모델 구조 확인
전체 오토인코더 모델의 이름을 model, 인코더의 이름을 Encoder라 한다. 1.FFN에서와 다르게, 인코딩 부분과 디코딩 부분이 대칭으로 구성되지 않는다는 점에 주의하자.
2.2. 군집화
5) KMeans 군집화
모델을 학습하고, 입력 데이터를 활용해 예측한 latent feature map을 추출한다.
시행착오
FFN에서와 마찬가지로 learning rate 0.01로 설정했는데, 끔찍한(?) 결과가 나왔다.
공포영화인 줄…output 레이어에 activation function으로
ReLU줘 봤는데, 500번의 에폭 모두 loss가 1.000에서 안 떨어졌다. 추측하는 이유는 있어서 중헌쓰에게 가르침을 구했는데, 무언가 인사이트를 얻기는 했지만 정확히 말로 풀어내지는 못하겠다. Activation Function에 대해 정확히 이해하지 못해서 그런 듯한데, 나중에 다시 따로 정리하기로 하고, 지금 단계에서는 ‘마지막 단계에 적용하면 안 된다’ 정도로만 이해하고 넘어 간다.
이후 똑같이 군집화를 진행하면 된다. 다만, latent feature가 4차원 텐서 형태이기 때문에 channel 축을 제거하고, 2차원 형태로 reshape해주어야 한다.
8) 군집화 결과 이미지 확인
마찬가지로 강사님의 코드를 수정해 위와 같은 방식으로 원본 이미지와 군집화된 latent feature map을 확인한다.

군집화 성능 자체가 크게 향상되었다고 단언하기는 어렵다. 결과 단에서 확연히 눈에 띄는 것은, CNN 네트워크를 사용해 오토인코더를 구성했을 때, latent feature가 알아보기 쉽다는 것이다. 이미지의 정보가 소실되는 건 어쩔 수 없지만, 원본 이미지와 비슷한 특징을 갖도록 최대한 유용하도록 보존하는 듯하다.
2.3. 더 생각해 볼 점
CNN 네트워크를 사용할 때 활성화 함수로 sigmoid를 사용하면 어떤 결과가 나올 지 궁금했다. 결과를 확인해 봤는데, CNN 네트워크라도 sigmoid 함수를 사용했을 때는 latent feature가 잘 포착되지 않았다. 표준화 방법, learning rate 모두 바꿔 봤는데도 아래와 같은 모습이었다.
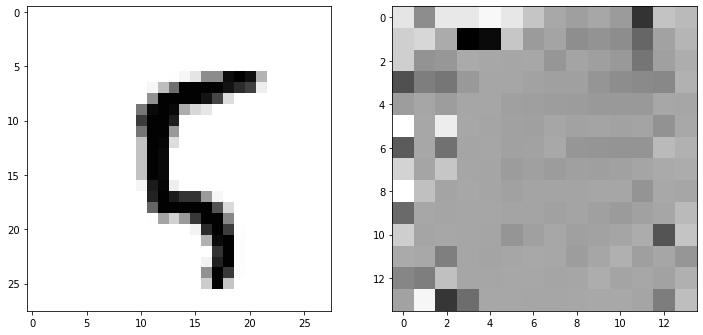
3. 해석
그렇다면 FFN으로 오토인코더를 구성했을 때의 latent feature를 어떻게 해석해야 할지 궁금해 진다. FFN은 그 나름대로 자신의 네트워크에 맞추어 차원을 축소하고 이해한다고 보아야 할 듯하다. 그렇다고 FFN으로 구성한 오토 인코더가 원본을 복원하지 못하는 것이 아니다.
다만, 본래 이미지라는 것이 사람이 인식하는 형태가 있다 보니, FFN보다는 CNN이 사람이 이해하기에 좋은 형태로 이미지를 학습하고, 차원을 축소하는 데에 강점이 있다고 결론을 내리고 싶다.
공유하기
Twitter Facebook LinkedIn

댓글남기기