
[DL] AutoEncoder_2.구현_이상치 탐지
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
오토 인코더 구현-과제-이상치 탐지
오토 인코더로 이상치를 검출할 수 있다. 기존 강의에서 이상치를 탐지하는 머신러닝 알고리즘으로 Isolation Forest를 사용했다. 당시의 이상치 탐지 원리를 응용하여 신용카드 데이터의 이상치를 탐지하는 Auto Encoder를 구현하고, 그 결과를 Isolation Forest와 비교해 보자.
힌트
입력 데이터와 출력 데이터가 같아지도록 학습하는 오토 인코더의 원리를 떠올려 보자. 제대로 학습이 되었다면 입력 데이터를 예측했을 때, 기존의 데이터와는 다른 데이터가 있을 것이다. 기존 데이터와 유사하지 않은 데이터일수록 이상치일 가능성이 높다.
1. 풀이
- 유사하지 않은 데이터를 찾아내기 위해 데이터 포인트 간의 유클리디안 거리를 계산했다. 거리가 클수록 기존 데이터와 다른 이상치 라 판단한다.
- Isolation Forest 알고리즘을 적용해
anomaly score를 바탕으로 이상치를 예측한다. - 오토 인코더로 예측한 유클리디안 거리가 큰 상위 몇 개의 데이터를 확인한다. 그 안에서 기존의 라벨에서 이상치인 데이터와 Isolation Forest로 예측한 이상치 데이터가 얼마나 존재하는지 확인한다.
# 모듈 불러오기
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.layers import Input, Dense, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# ====== 1) 데이터 준비 및 원본 데이터 보존 ======
# 데이터 로드
data_path = "..."
credit = pd.read_csv(f"{data_path}/creditcard_fraud.csv")
# 피쳐 선택
X_data = credit.iloc[:, 1:-1]
y_data = credit.iloc[:, -1]
# 표준화
scaler = StandardScaler()
scaler.fit(X_data)
X_train = scaler.transform(X_data)
# ====== 2) 오토 인코더 모델 학습 및 예측 ======
X_train_AE = X_train.copy()
# 파라미터 설정
n_input = X_train_AE.shape[1]
n_output = n_input
# 모델 레이어 설정
x_Input = Input(batch_shape=(None, n_input))
x_Encoder1 = Dense(256, activation='relu')(x_Input)
x_Encoder1 = Dropout(0.3)(x_Encoder1)
x_Encoder2 = Dense(512, activation='relu')(x_Encoder1)
x_Encoder2 = Dropout(0.2)(x_Encoder2)
y_Decoder1 = Dense(256, activation='relu')(x_Encoder2)
y_Decoder1 = Dropout(0.3)(y_Decoder1)
y_Decoder2 = Dense(n_output, activation='linear')(y_Decoder1)
# 모델 구조 설정
model = Model(x_Input, y_Decoder2)
model.compile(loss='mse', optimizer=Adam(lr=0.001))
print("====== 모델 전체 구조 ======")
print(model.summary())
# 모델 파라미터 및 조기 종료 조건
EPOCHS = int(input('학습 횟수 설정: '))
BATCH = int(input('배치 사이즈 설정: '))
es = EarlyStopping(monitor='loss', patience=5, verbose=1)
# 모델 훈련
hist = model.fit(X_train_AE, X_train_AE,
epochs=EPOCHS,
batch_size=BATCH,
callbacks=[es],
shuffle=True)
# loss 그래프
plt.plot(hist.history['loss'], label='Train Loss')
plt.title('Loss Trajectory_AutoEncoder')
plt.legend()
plt.show()
# 예측
y_pred_AE = model.predict(X_train_AE)
# 거리 계산
def calc_distance(origin, pred):
dist = []
for i in range(len(pred)):
dist.append(np.sqrt(np.sum(np.square(origin[i]-pred[i]))))
return pd.Series(dist)
distance_AE = calc_distance(X_train_AE, y_pred_AE)
credit['distance_AE'] = distance_AE # 원래 데이터에 넣기
# ====== 3) IsolationForest 모델 학습 및 예측 ======
X_train_IF = X_train.copy()
model2 = IsolationForest(n_estimators=200, verbose=1)
model2.fit(X_train_IF)
score = abs(model.score_samples(X_train_IF)) # 이상치 점수
plt.hist(score, bins=50) # 이상치 점수 시각화
plt.show()
y_pred_IF = (score > 0.7).astype(int) # 이상치 점수 기준: 0.7
credit['Class_iForest'] = pd.Series(y_pred_IF) # 원래 데이터에 넣기
# ====== 4) 결과 비교 ======
df = credit.sort_values(by='distance_AE', ascending=False) # 거리 순 정렬
print(df['Class'].value_counts()) # original label 이상치
print(df['Class_iForest'].value_counts()) # iForest label 이상치
# AE로 계산한 거리 상위 n개 중 이상치 몇 개 있는지 반환
def count_abnormal(data, threshold, num=30):
for i in range(threshold//num):
print(f"<< 상위 {(i+1)*num}개에서 이상치 체크 >> ")
print(" ====== AutoEncoder vs. Original Label ======")
print(data['Class'][:(i+1)*num].value_counts())
print(" ====== AutoEncoder vs. iForest Label ======")
print(data['Class_iForest'][:(i+1)*num].value_counts())
print(" ")
# 상위 600개 데이터에서 비교
count_abnormal(df, 600)
1.1. 데이터 준비
Time 피쳐만 빼고 모든 데이터를 다 사용했다. 강사님께서는 Amount도 빼라고 힌트를 주셨는데, 신용카드 부정 사용의 경우 사용 금액에도 차이가 있을 것이라 판단했다.
애초에 데이터가 표준화가 되어 있었는데 모르고 다시 한 번 진행했다. Amount에 대해서만 표준화를 진행했어도 될 듯하다. 어쨌든 모든 모델에서 같은 데이터로 학습할 수 있도록 원본 데이터를 보존했다.
1.2. 오토 인코더 모델 학습 및 예측
학습 횟수와 배치 사이즈는 일괄적으로 500으로 설정했다. 조기 종료 조건을 Train loss 값이 5회 이상 감소하지 않을 때로 설정했다.
기존에 사용했던 오토 인코더 모델과 달리, 중간으로 갈수록 차원이 확장되도록 구성했다. 처음에는 원래 모델과 동일하게 차원이 축소되는 모델을 구성해 보았다. 결과적으로 두 경우 간 이상치 탐지 결과 비율 등이 크게 달라지지는 않는다. 그러나 학습 과정에서 차원이 확장되도록 구성했을 때, loss 값이 작아지고, 수렴 속도 역시 빠른 것을 확인할 수 있었다.
그럼에도 불구하고 차원을 확장하고 노드 수를 늘린 만큼 파라미터 수가 늘어나고 네트워크가 깊어졌기 때문에, 과적합의 우려가 있어 Dropout을 적용했다. 실제로 위와 같은 Dropout을 적용하는 것만으로도 이전에 비해 예측한 유클리디안 거리 범위가 상대적으로 안정화되는 것을 확인할 수 있었다.
다만 loss 값의 변화 추이를 그래프로 확인하니, Dropout 적용 후 매끄럽지 않아졌다.
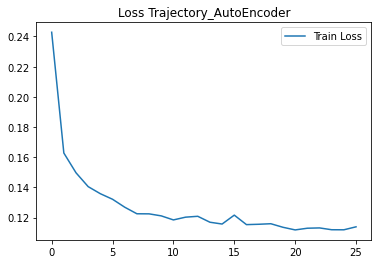
참고 : 강사님 조언
loss값 자체는 들쭉날쭉할 수 있다. 이전 강의에서 다루었듯 regularizer를 사용하거나 NAG 등의 optimizer를 사용하면 loss값의 변화 추이가 조금은 매끄러워질 수 있다. 그러나 그래프의 형태가 매끄럽지 못하다고 이상한 것은 아니다.
loss 형태보다도 과적합을 줄이는 게 더 중요하다. 일반적으로 deep한 네트워크를 구성해 과적합을 유발시킨 뒤, 규제를 적용하면 된다. 처음에는 지금처럼 가볍게 Dropout 적용해 보고, kernel regularizer, batch normalization 등을 적용해 가며 바꿔 보자. 그 과정에서도 역시나, loss 형태는 들쭉날쭉할 수 있다.
모델 학습이 완료된 후, 기존의 데이터를 입력해 예측한 후 유클리디안 거리를 계산했다. 반복문을 돌며 모든 데이터 포인트 간 거리를 manual하게 계산했다. 다시 보니 굳이 함수로 구현할 필요까지는 없어 보인다. 왜 그랬지?
1.3. Isolation Forest 모델 학습 및 예측
Isolation Forest 모델의 경우 학습 및 예측 과정이 간단하다. 다만 이상치로 판단할 기준 점수를 몇 점으로 설정할 것인가가 중요했다. 기존 데이터 284807개 중 이상치가 492개이므로 너무 많으면 안 된다.
히스토그램을 그려 빈도를 확인한 뒤, 임의로 이상치로 간주할 기준 점수를 0.7로 설정해 주었다.
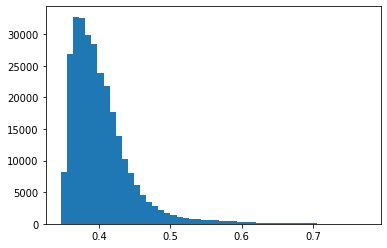
1.4. 결과 해석
오토 인코더 모델이 계산한 유클리디안 거리를 기준으로 데이터를 내림차순 정렬했다. 위에 있을수록 이상치일 가능성이 높다고 가정한다.
그리고 상위 600개까지의 데이터 중 30개씩 범위를 늘려 가면서,
- 1) 원래 라벨과,
- 2) Isolation Forest가 예측한 라벨에서,
이상치가 몇 개 있는지를 value_counts()를 통해 확인했다.
참고
상위 600개 까지만 확인한 이유는, 원래 데이터에 이상치가 492개밖에 없기 때문이다. 오차를 감안하더라도 끝까지 다 확인하는 것은 의미가 없다.
만약 내가 구현한 오토 인코더와 Isolation Forest 알고리즘이 이상치를 완벽하게 탐지해 낸다면, 거리 순으로 내림차순 정렬했을 때 적어도 600개 안에는 이상치 라벨(
1)이 대부분 들어 있어야 한다고 판단했다.
전체 결과를 확인하면 다음과 같다.
(사실 만족스럽게 나온 결과는 아니지만, 한계점에 대해서는 후술한다. 내 풀이의 한계 및 이상치 탐지의 어려움을 감안하고, 상대적으로 가장 만족스럽게 나온 결과를 첨부한다)
아래 경우에서 Isolation Forest가 예측한 이상치 라벨의 개수는 207개였다.
<< 상위 30개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 26
1 4
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
1 28
0 2
Name: Class_iForest, dtype: int64
<< 상위 60개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 49
1 11
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
1 53
0 7
Name: Class_iForest, dtype: int64
<< 상위 90개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 79
1 11
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
1 71
0 19
Name: Class_iForest, dtype: int64
<< 상위 120개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 102
1 18
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
1 93
0 27
Name: Class_iForest, dtype: int64
<< 상위 150개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 126
1 24
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
1 108
0 42
Name: Class_iForest, dtype: int64
...
(중략)
...
<< 상위 570개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 458
1 112
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
0 392
1 178
Name: Class_iForest, dtype: int64
<< 상위 600개에서 이상치 체크 >>
====== AutoEncoder vs. Original Label ======
0 477
1 123
Name: Class, dtype: int64
====== AutoEncoder vs. iForest Label ======
0 417
1 183
Name: Class_iForest, dtype: int64
모델을 돌려볼 때마다 결과가 다르긴 했으나, 전반적으로 다음과 같은 공통점을 파악할 수 있었다.
- 오토 인코더 모델으로 판단한 이상치와 원래 데이터의 라벨이 일치하지는 않는 듯하다.
- 다만, 오토 인코더 모델로 이상치를 판단했을 때, 상위 600개까지 확인하면 Isolation Forest의 이상치 수가 거진 들어 있기는 하다.
완벽하지는 않지만, 일단 Isolation Forest의 라벨 예측 결과와 어느 정도 유사한 흐름을 보이는 데에서 만족해야 할 듯하다. 강사님께서 조언해 주시기를, 이상치 탐지가 이렇게나 어렵다고…
2. 더 생각해 볼 점
2.1. 한계 및 보완점
가장 큰 문제점은 모델이 안정화되지 않는다는 것이다. 오토 인코더나 Isolation Forest나 모델을 돌릴 때마다 결과가 다르게 나온다. 전자의 경우, Dropout을 적용해 좀 나아지긴 했으나, 그럼에도 불구하고 유클리디안 거리를 계산했을 때 범위가 들쭉날쭉하다. 더 다양한 규제를 적용할 필요가 있다. 후자의 경우는, 이상치로 예측한 라벨의 개수만 셌을 때 최소 130개에서 최대 227개까지, 범위가 무척 다양하다.
위 문제점의 연장선상에서 본다면, Isolation Forest 알고리즘 역시 이상치를 완벽하게 탐지하는 것은 아닐 수도 있다. 물론 파라미터를 충분히 조정하지 않았고, random state를 고정하지도 않았으며, anomaly score 기준치를 조정하지도 않았다. 그럼에도 불구하고 라벨 예측 범위가 너무나도 다양하다.
또한, 유클리디안 거리보다 코사인 유사도 등 유사도를 나타낼 수 있는 척도로 각 데이터 포인트 간 유사도를 측정하는 것이 유사도의 개념에 더 적합했을 수도 있다.
마지막으로, 이상치 탐지의 성과를 라벨이 포함된 단순 개수로만 측정했을 뿐, 재현율 등 엄밀한 통계적 척도로 측정하지 않았다.
2.2. 시행착오
- Adam 옵티마이저 학습률을 0.01로 주지 말자.
sigmoid,binary_crossentropy조합을 주는 사용하는 순간 끔찍한 loss의 변화 추이를 경험하게 된다.
왜인지 어렴풋이 잡히는 이유는 있으나, 명확하게 왜인지는 모르겠다. 이 역시 activation function 공부 후 다시 고민해 볼 것!
3. 다른 풀이
태엽 님께서 코사인 유사도와 재현율을 사용해 문제를 푸셨다. 허락을 얻어 풀이를 게재한다.
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 10 17:29:47 2020
@author: student
"""
import pandas as pd
import numpy as np
from tensorflow.keras.layers import Input, Dense, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.metrics.pairwise import cosine_similarity
df = pd.read_csv('dataset/creditcard(fraud).csv')
df.shape
dataX=df.iloc[:,1:-1]
dataX = (dataX- dataX.mean()) / dataX.std()
dt=np.array(dataX).astype(np.float32)
nFeature=dt.shape[1]
inputX = Input(batch_shape=(None,nFeature))
Xencode = Dense(12, activation='relu')(inputX)
Xdecode = Dense(nFeature, activation='linear')(Xencode)
model = Model(inputX, Xdecode)
model.compile(loss='mse', optimizer=Adam(lr=0.001))
h = model.fit(dt,dt,epochs=300, batch_size=1000, shuffle=True)
yhat=model.predict(dt)
dist_list=[]
for i in range(len(yhat)):
dist = cosine_similarity([dt[i]],[yhat[i]])
dist_list.append(dist)
dist_list2 = dist_list.copy()
maxN=492
max_dict={}
for i in range(maxN):
max_index = dist_list2.index(max(dist_list2))
max_value = dist_list2.pop(max_index)
dist_list2.insert(max_index,0)
max_dict[max_index]=max_value
actual =set(df[df['Class']==1].index)
predicted = set(max_dict.keys())
print('실제로 비정상인 데이터 수:',len(actual))
print('실제 비정상인데 비정상으로 예측한 데이터 수:',len(actual.intersection(predicted)))
print('precision={}'.format(len(actual.intersection(predicted))/len(actual)))
"""
Isolation forest의 confusion matrix
confusion matrix :
pred_normal pred_abnormal
actual_normal 283969 346
actual_abnormal 359 133
실제 정상 데이터를 비정상으로 잘못 판정한 비율 = 0.0012
실제 비정상 데이터를 정상으로 잘못 판정한 비율 = 0.7297
accuracy = 0.9975
[[283969 346]
[ 359 133]]
precision recall f1-score support
0.0 1.00 1.00 1.00 284315
1.0 0.28 0.27 0.27 492
accuracy 1.00 284807
macro avg 0.64 0.63 0.64 284807
weighted avg 1.00 1.00 1.00 284807
"""
공유하기
Twitter Facebook LinkedIn

댓글남기기