
[DL] AutoEncoder_2.구현_잡음 제거
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
오토 인코더 구현-잡음 제거-이미지
MNIST 데이터셋을 가지고 잡음 제거를 위한 오토 인코더를 구현해 본다. Convolutional Neural Network를 사용하며, 이전과 달리 노이즈가 포함된 데이터를 입력으로 받아 원본 데이터를 출력하도록 모델을 구성한다.
모델 학습 후, 노이즈가 포함된 테스트 데이터를 이용해 잡음을 잘 제거하는지 확인해 본다.
# 모듈 불러오기
import pickle
import numpy as np
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
# 1) 데이터 준비
data_path = "..."
with open(f"{data_path}/mnist.pickle", 'rb') as f:
mnist = pickle.load(f)
X_train = mnist.data[:3000, :] / 255.0
X_test = mnist.data[3000:3100, :] / 255.0
# 2) 노이즈 삽입
X_train_n = X_train + 0.3*np.random.normal(size=X_train.shape)
X_test_n = X_test + 0.3*np.random.normal(size=X_test.shape)
plt.imshow(X_train_n[102].reshape(28, 28), cmap=plt.cm.bone)
plt.show()
# 3) 값 범위 clip
X_train_n_clipped = np.clip(X_train_n, 0.0, 1.0)
X_test_n_clipped = np.clip(X_test_n, 0.0, 1.0)
# 4) 데이터 shape 변경 및 channel 축 추가
X_train = X_train.reshape(-1, 28, 28)
X_train = X_train[:, :, :, np.newaxis]
X_train_n = X_train_n.reshape(-1, 28, 28)
X_train_n = X_train_n[:, :, :, np.newaxis]
X_test = X_test.reshape(-1, 28, 28)
X_test = X_test[:, :, :, np.newaxis]
X_test_n = X_test_n.reshape(-1, 28, 28)
X_test_n = X_test[:, :, :, np.newaxis]
# 5) 파라미터 설정
n_height = X_train_n.shape[1] # 28
n_width = X_train_n.shape[2] # 28
n_channel = X_train_n.shape[3] # 흑백: 1
# 6) 모델 레이어 설정
x_Input = Input(batch_shape=(None, n_height, n_width, n_channel)) # 인코더 입력
# 인코더 부분
e_conv = Conv2D(filters=10, kernel_size=(3, 3), strides=1, padding='SAME', activation='relu')(x_Input)
e_pool = MaxPooling2D(pool_size=(2, 2), strides=1, padding='SAME')(e_conv)
# 디코더 부분
d_conv = Conv2DTranspose(filters=10, kernel_size=(3, 3), strides=1, padding='SAME', activation='relu')(e_pool)
x_Output = Conv2D(filters=1, kernel_size=(3, 3), strides=1, padding='SAME', activation='sigmoid')(d_conv)
# 7) 모델 구성
model = Model(x_Input, x_Output)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.005))
print("====== 모델 전체 구조 =====")
print(model.summary())
# 모델 학습
EPOCHS = 500
BATCH = 300
hist = model.fit(X_train_n, X_train, epochs=EPOCHS, batch_size=BATCH, shuffle=True)
# 8) 화면에 이미지 그림
def showImage(images):
n = 0
for k in range(2):
plt.figure(figsize=(8, 2))
for i in range(5):
ax = plt.subplot(1, 5, i+1)
plt.imshow(images[n])
plt.gray()
ax.get_axis().set_visible(False)
ax.get_yaxis().set_visible(False)
n += 1
plt.show()
# 9) 노이즈 포함된 테스트 데이터 잡음 제거
# 비교 위해 먼저 그림 그리기
print("잡음 제거 전 테스트 데이터 10개")
showImage(X_test_n)
# 학습된 모델 통과
X_test_detected = model.predict(X_test_n)
# 잡음 제거 후 그림 그리기
print("잡음 제거 후 테스트 데이터 10개")
showImage(X_test_n_detected)
1. 오토 인코더 구성
1) 데이터 준비
노이즈를 제거하는 모델을 구성한 후, 테스트 데이터를 활용해 잡음이 제대로 제거되는지 확인해야 하므로 train, test 데이터를 모두 준비한다. 255.0으로 나눠주어 표준화를 진행한다.
2) 노이즈 삽입
np.random.normal로 가우지안 분포를 따르는 잡음을 각 이미지에 삽입한다. 0.3을 곱해준 것은 너무 큰 노이즈 숫자가 더해지지 않기로 하기 위함이다.
참고
잡음 데이터를 생성하면 다음과 같다.
array([[ 0.34911953, 0.42679871, -0.06234537, ..., 0.08395142, -0.14962927, -0.29976097], [-0.40273606, 0.03263321, 0.32538957, ..., 0.65707865, 0.22589704, 0.20959764], ..., [ 0.04168609, 0.29732153, 0.20265235, ..., 0.50813627, 0.15694841, -0.04167244], [-0.25658924, 0.13600611, -0.0697845 , ..., -0.27303452, 0.15497477, -0.07805152]])이 잡음 수치를 원래 데이터에 더하면 element-wise 연산이 이루어지면서 표준화된 픽셀 수치에 잡음 수치가 더해진 데이터가 만들어 진다.
노이즈가 포함된 데이터가 원래의 이미지와 조금씩 달라진 것을 확인할 수 있다. 특히 원래 이미지에서 강도가 0이던 부분이 회색으로 약간씩 변해 있다.
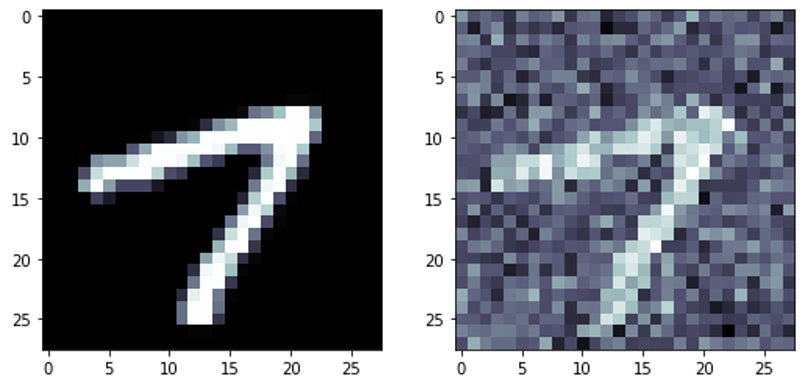
3) 클리핑
노이즈 삽입 전 원래 train, test 데이터를 0.0, 1.0 사이의 값으로 맞춰 놓았기 때문에, 클리핑을 진행한다.
4), 5) 데이터 shape 변경 및 파라미터 설정
기본적으로 CNN을 활용한 오토인코더를 구성하므로, 4차원 shape의 텐서로 바꿔 준다. 흑백 채널 축을 추가해 줘야 함을 잊지 말자.
이후 모델 레이어를 설정할 때 필요한 파라미터를 설정한다. 모델에는 노이즈가 포함된 train 데이터를 설정할 것이므로, 이를 기준으로 Height, Width, Channel의 수를 설정한다.
6), 7) 모델 구성
모델 아키텍쳐는 CNN 오토인코더 에서와 동일하다. 모델 구성 시, 입력 데이터로 노이즈가 포함된 X_train_n을, 출력 데이터로 X_train을 사용함에 주의하자. 이 모델은 노이즈가 포함된 데이터가 노이즈가 없는 원래 데이터와 비슷해지도록 학습할 것이다.
모델 출력층의 activation function을 sigmoid로, 컴파일 시 loss function을 binary crossentropy로 설정한 것에 주의하자. 0과 1 사이로 구성되어 있는 픽셀 값의 특성을 살리기 위해 두 조합을 사용했다.
2. 결과 확인
8) 이미지 그림 그리는 함수
이미지 데이터 셋에서 10개 그림을 그리는 코드이다. 처음 10개의 이미지를 가져와 두 줄로 나눠서 subplot으로 그린다. 나중에 랜덤으로 샘플링해서 가져오도록 코드를 수정해 보자.
9) 노이즈 제거 및 결과 확인
학습한 모델에 노이즈가 포함된 테스트 데이터를 예측하도록 한다. 결과를 확인하면 다음과 같다.
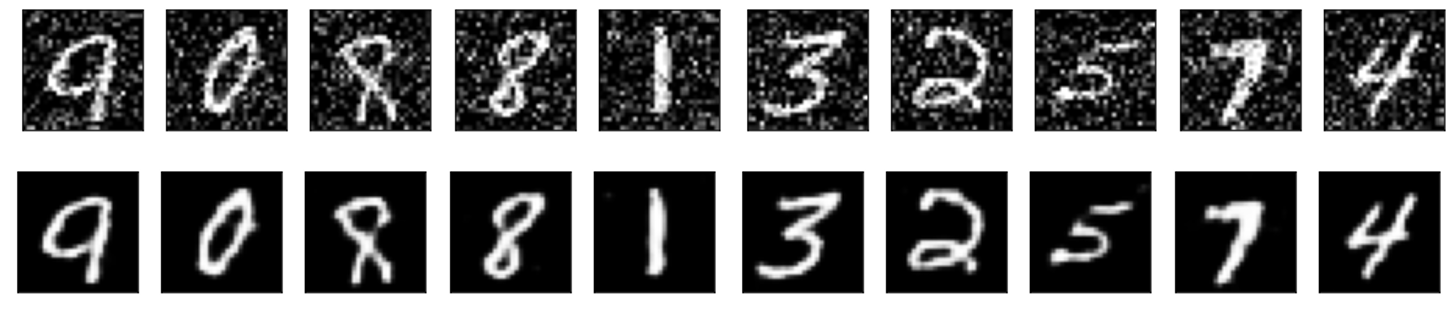
위와 아래를 비교하면, 잡음이 제거되고 원래 이미지가 나오는 것을 확인할 수 있다.
3. 더 생각해 볼 점
3.1. activation, loss 변경
activation function과 loss function의 조합을 linear와 mse로 변경해 보았다. 조금씩 흐릿한 부분이 있지만, 잡음 제거 측면에서만 보면 결과 자체는 좋다.

loss 값의 추이가 아주 조금 달랐다. 아래 그림에서 왼쪽이 기존에 sigmoid와 binary crossentropy를 사용했을 때, 오른쪽이 linear와 mse를 사용했을 때이다. 알려진 대로, binary crossentropy를 사용할 때 loss 값의 수렴이 더 일찍 이루어진다. activation function이 sigmoid이긴 하지만, 그건 출력층의 값을 뽑아 내는 것이지, 은닉층에서의 활성화 함수가 아니므로 loss function을 보고 판단하면 될 듯하다.
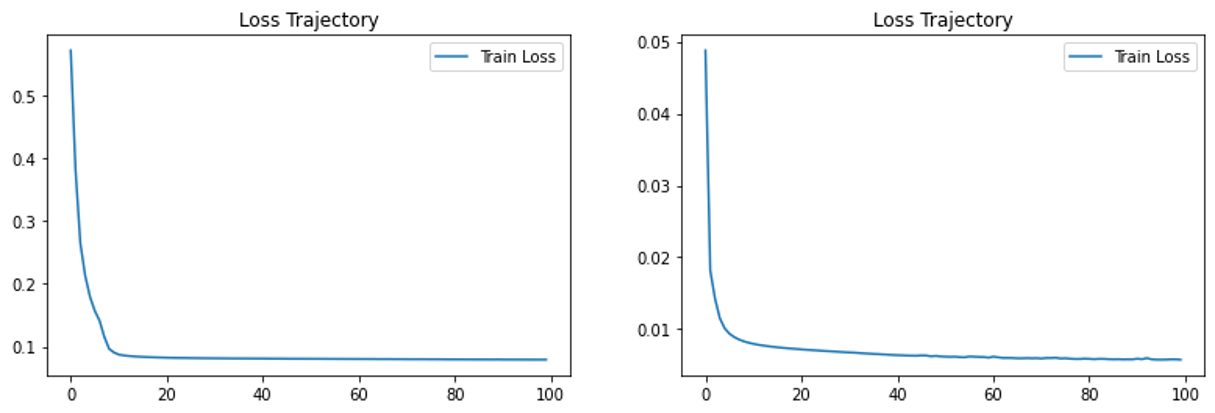
3.2. 잡음 제거 역할을 하는 층은 무엇인가
위에서 구성한 모델에서 레이어를 하나씩 줄여 보았다. 입력 후 Conv2D 레이어 하나만 통과시켰을 때만 제외하면, 모두 다 잡음이 제거된다. 어떻게 보면 당연한 결과이기도 하다. Conv2D 레이어만 통과시키면, 어떻게 보면 인코더 부분이며, 잡음이 포함된 데이터의 특징 만을 추출해낼 것이기 때문이다.
Conv2D 레이어 하나만으로 구성했을 때 결과는 다음과 같다.

다만 신기한 것은, Conv2D 레이어를 통과한 뒤, Conv2DTranspose 레이어를 통과 시키지 않고
- 1) Pooling 레이어만 통과시키더라도,
- 2) Pooling 없이 중간에 Conv2D 레이어만 통과시키더라도,
원래 데이터가 복원된다는 것이다.
각각의 경우, 그 결과는 아래와 같다. 조금씩 흐릿한 잡음 부분이 남아 있기는 하더라도, 어느 정도 괜찮게 잡음이 제거된다.

Pooling을 거치든 거치지 않든, 어쨌든 CNN 네트워크를 활용해 특징을 뽑아 내는 과정에서 잡음 정보만 소실시키는 것인가 싶다.
공유하기
Twitter Facebook LinkedIn

댓글남기기