
[NLP] Hybrid_IMDB 감성분석
조성현 강사님의 강의 및 강의 자료를 기반으로 합니다. Github Repo
Tensorflow : 2.2.0
Hybrid 네트워크 구현-과제-IMDB 감성 분석
CNN과 LSTM 네트워크를 병렬로 결합한 Hybrid Network를 통해 IMDB 감성 분석 문제를 풀어 보자. 모델을 구성할 때 임베딩을 따로 구성했을 때와 같이 구성했을 때 예시 문장의 임베딩이 어떻게 달라지는지에 초점을 맞추어 결과를 확인하자.
1. 모델 아키텍쳐
구현할 모델의 아키텍쳐는 다음과 같다. Covid-19 예측 과제 에서와 비슷하다. 다만 직렬은 제외하고, LSTM, CNN 네트워크를 병렬로 연결한 모델을 구성하고, Embedding 레이어를 삽입하는 위치를 달리 한다.
한 모델의 경우 Embedding 레이어를 LSTM, CNN 네트워크에 맞게 따로 구성한다.
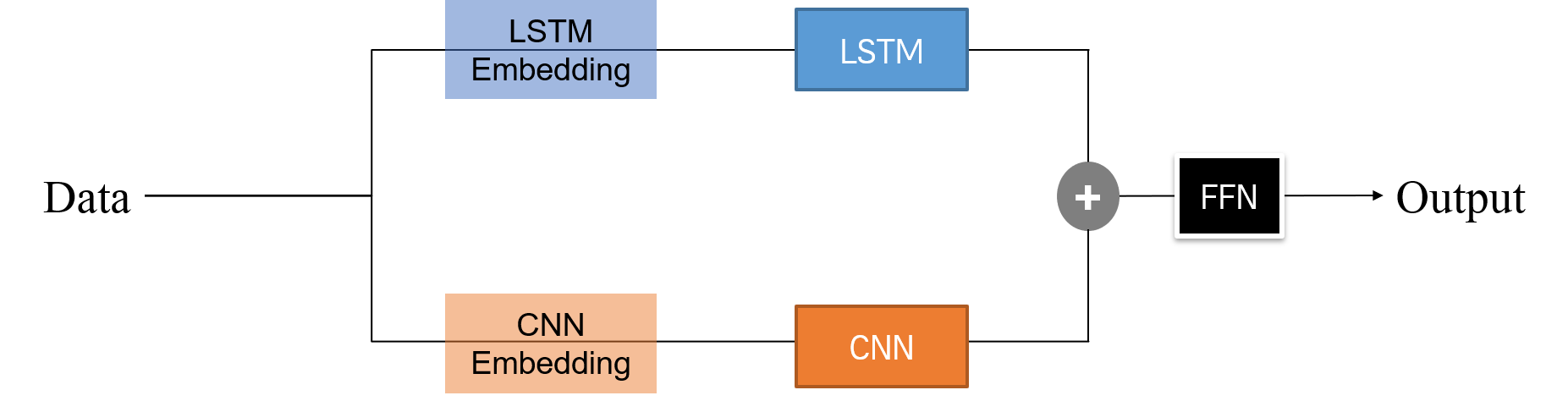
다음 모델 경우 Embedding 레이어를 하나로 구성하고, 이를 서로 다른 네트워크에 통과시킨다.
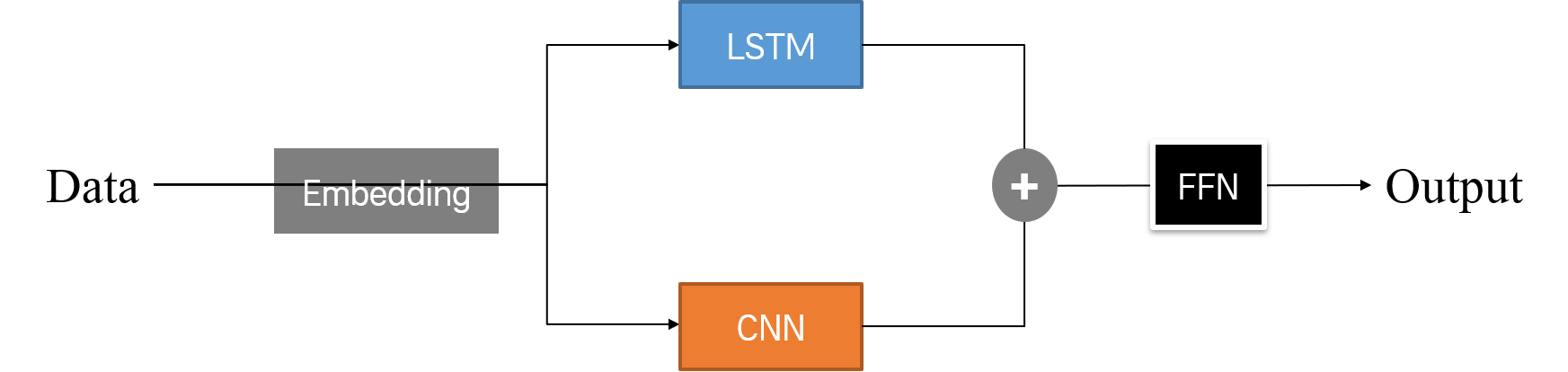
두 모델 모두 병렬 네트워크이기 때문에, Dense 레이어 및 FFN을 통과시키는 부분은 예전과 동일하다.
2. 풀이
참고 : LSTM 활성화 함수
처음에 네트워크 구성하다가 LSTM 레이어에 activation 함수로 ‘relu’를 줬다. 왜 그렇게 썼는지 모르겠는데, 그 결과
약 1시간 넘게, 그것도 내 문제를 함께해결해 주려던 동기들과 함께loss가 갑자기nan이 되어 버리는 문제로 고통 받았다. loss가 잘 나오다가 갑자기nan이 되어 버린다. 말로만 듣던Vanishing Gradients문제를 실감하게 되는 순간이었다.LSTM 모델을 그렇게 공부하고 아키텍쳐를 생각했어도, 함수 쓸 때 정신을 제대로 차리고 쓰지 않으면 이렇게 된다. LSTM 모델에는 절대로, 실수로라도 activation 함수로
ReLU를 사용하지 말자.질문을 해결해 주신 강사님께 감사를..
사용한 모듈은 다음과 같다.
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Embedding, Dropout, Flatten
from tensorflow.keras.layers import Conv1D, GlobalMaxPooling1D # CNN
from tensorflow.keras.layers import Bidirectional, LSTM # LSTM
from tensorflow.keras.layers import Concatenate
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
import sys
np.set_printoptions(threshold=sys.maxsize) # numpy array 출력 길이
이후 임베딩된 문장 벡터를 끝까지 보기 위해, Numpy의 print 옵션을 조정하여 출력 길이를 늘려 주었다. (다만 이렇게 했더니 마지막에 출력 스트리밍의 길이가 길어서 콘솔이 멈추기도 했다.)
2.1. 사전 작업
최대 단어 빈도를 설정해 IMDB 데이터셋을 로드한다. 강사님과 동일하게 6000으로 설정했다.
# 데이터 불러 오기
max_features = int(input('최대 단어 빈도 설정: '))
(X_train_raw, y_train), (X_test_raw, y_test) = imdb.load_data(num_words=max_features)
데이터를 불러 오고, 패딩하는 과정에서 사전 작업이 필요하다. 문장 길이를 맞춰 주는 패딩 작업을 진행하기 위해, IMDB 데이터셋을 구성하는 문장들의 길이가 어떻게 되는지 확인하는 함수를 추가했다.
# 최대 문장 길이 확인
def check_len(m, sentences):
cnt = 0
for sent in sentences:
if len(sent) <= m:
cnt += 1
return f'전체 문장 중 길이가 {m} 이하인 샘플의 비율: {(cnt/len(sentences))*100}'
for length in range(100, 1000, 50):
print(check_len(length, X_train_raw))
print()
문장 길이를 확인한 결과는 다음과 같다.
전체 문장 중 길이가 100 이하인 샘플의 비율: 11.288
전체 문장 중 길이가 150 이하인 샘플의 비율: 37.732
전체 문장 중 길이가 200 이하인 샘플의 비율: 57.292
전체 문장 중 길이가 250 이하인 샘플의 비율: 68.688
전체 문장 중 길이가 300 이하인 샘플의 비율: 76.36800000000001
전체 문장 중 길이가 350 이하인 샘플의 비율: 81.93599999999999
전체 문장 중 길이가 400 이하인 샘플의 비율: 86.064
전체 문장 중 길이가 450 이하인 샘플의 비율: 89.184
전체 문장 중 길이가 500 이하인 샘플의 비율: 91.56800000000001
전체 문장 중 길이가 550 이하인 샘플의 비율: 93.308
전체 문장 중 길이가 600 이하인 샘플의 비율: 94.812
전체 문장 중 길이가 650 이하인 샘플의 비율: 95.92399999999999
전체 문장 중 길이가 700 이하인 샘플의 비율: 96.72800000000001
전체 문장 중 길이가 750 이하인 샘플의 비율: 97.432
전체 문장 중 길이가 800 이하인 샘플의 비율: 98.012
전체 문장 중 길이가 850 이하인 샘플의 비율: 98.5
전체 문장 중 길이가 900 이하인 샘플의 비율: 98.832
전체 문장 중 길이가 950 이하인 샘플의 비율: 99.136
이후 두 모델에 공통적으로 활용할 파라미터들을 한 번에 정의한다. 강사님께서는 최대 문장 길이를 400으로 설정하셨으나, 나는 500으로 설정해 봤다. 또한, 학습 과정에서 조기 종료 조건을 줄 것이기 때문에 학습 에폭 수만 1000으로 설정해 봤다. 나머지 파라미터는 모두 동일하게 적용한다.
# 공통 파라미터
max_length = int(input('문장 길이 설정: '))
n_embed = int(input('임베딩 차원 설정: '))
n_hidden = int(input('은닉 노드 수 설정: '))
BATCH = int(input('배치 사이즈 설정: '))
EPOCHS = int(input('학습 횟수 설정: '))
문장에 패딩을 진행한다.
# 패딩 진행
X_train = pad_sequences(X_train_raw, maxlen=max_length)
X_test = pad_sequences(X_test_raw, maxlen=max_length)
2.2. 임베딩 따로 한 모델
임베딩을 따로 했을 때 모델 구성은 다음과 같다. 이하에서는 이 모델을 A 모델이라고 부른다.
# 모델 네트워크 구성
X_Input = Input(batch_shape=(None, max_length))
X_Embed_CNN = Embedding(input_dim=max_features, output_dim=n_embed, input_length=max_length)(X_Input)
X_Embed_CNN_2 = Dropout(0.2)(X_Embed_CNN) # CNN 최종 임베딩
X_Conv = Conv1D(filters=n_filters, kernel_size=s_filters, strides=1, padding='same', activation='relu')(X_Embed_CNN_2)
X_Pool = GlobalMaxPooling1D()(X_Conv)
X_Dense = Dense(n_hidden, activation='relu')(X_Pool)
X_Dense_2 = Dropout(0.5)(X_Dense)
X_Flatten = Flatten()(X_Pool)
X_Embed_LSTM = Embedding(input_dim=max_features, output_dim=n_embed, input_length=max_length)(X_Input)
X_Embed_LSTM_2 = Dropout(0.2)(X_Embed_LSTM) # LSTM 최종 임베딩
X_LSTM = Bidirectional(LSTM(n_hidden, return_sequences=True))(X_Embed_LSTM_2) X_LSTM = Flatten()(X_LSTM)
X_merge = Concatenate()([X_Flatten, X_LSTM])
y_output = Dense(1, activation='sigmoid')(X_merge)
# 학습 모델
model = Model(X_Input, y_output) # 컴파일할 모델
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=0.001))
print("========== 전체 모델 구조 확인 ==========")
print(model.summary())
# 임베딩 모델
cnn_embed_model = Model(X_Input, X_Embed_CNN_2) # CNN 임베딩 모델
lstm_embed_model = Model(X_Input, X_Embed_LSTM_2) # LSTM 임베딩 모델
컴파일되어 감성분석을 수행할 모델의 전체 구조는 다음과 같다.
========== 전체 모델 구조 확인 ==========
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 650)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 650, 64) 384000 input_1[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 650, 64) 0 embedding[0][0]
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 650, 64) 384000 input_1[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 650, 300) 57900 dropout[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 650, 64) 0 embedding_1[0][0]
__________________________________________________________________________________________________
global_max_pooling1d (GlobalMax (None, 300) 0 conv1d[0][0]
__________________________________________________________________________________________________
bidirectional (Bidirectional) (None, 650, 600) 876000 dropout_2[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 300) 0 global_max_pooling1d[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 390000) 0 bidirectional[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 390300) 0 flatten[0][0]
flatten_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 390301 concatenate[0][0]
==================================================================================================
Total params: 2,092,201
Trainable params: 2,092,201
Non-trainable params: 0
__________________________________________________________________________________________________
None
CNN 네트워크와 LSTM 네트워크의 Embedding 레이어가 서로 다르기 때문에, 두 모델의 임베딩 결과를 확인하기 위한 임베딩 모델을 따로 구성했다.
2.3. 임베딩 같이 한 모델
임베딩을 같이 했을 때 모델 구성은 다음과 같다. 이하에서는 이 모델을 B 모델이라고 부른다.
# 모델 네트워크 구성
X_Input = Input(batch_shape=(None, max_length))
X_Embed = Embedding(input_dim=max_features, output_dim=n_embed, input_length=max_length)(X_Input)
X_Embed_2 = Dropout(0.2)(X_Embed) # 최종 임베딩
X_Conv = Conv1D(filters=n_filters, kernel_size=s_filters, strides=1, padding='valid', activation='relu')(X_Embed_2)
X_Pool = GlobalMaxPooling1D()(X_Conv)
X_Dense = Dense(n_hidden, activation='relu')(X_Pool)
X_Dense_2 = Dropout(0.5)(X_Dense)
X_Flatten = Flatten()(X_Dense_2)
X_LSTM = Bidirectional(LSTM(n_hidden, return_sequences=True))(X_Embed_2)
X_LSTM = Flatten()(X_LSTM)
X_merge = Concatenate()([X_Flatten, X_LSTM])
y_output = Dense(1, activation='sigmoid')(X_merge)
# 학습 모델
model = Model(X_Input, y_output) # 컴파일할 모델
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=0.001))
print("========== 전체 모델 구조 확인 ==========")
print(model.summary())
# 임베딩 모델
embed_model = Model(X_Input, X_Embed_2)
컴파일되어 감성분석을 수행할 모델의 전체 구조는 다음과 같다. 위의 모델보다 params 수가 적다.
========== 전체 모델 구조 확인 ==========
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 650)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 650, 64) 384000 input_1[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 650, 64) 0 embedding[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 648, 300) 57900 dropout[0][0]
__________________________________________________________________________________________________
global_max_pooling1d (GlobalMax (None, 300) 0 conv1d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 300) 90300 global_max_pooling1d[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 300) 0 dense[0][0]
__________________________________________________________________________________________________
bidirectional (Bidirectional) (None, 650, 600) 876000 dropout[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 300) 0 dropout_1[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 390000) 0 bidirectional[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 390300) 0 flatten[0][0]
flatten_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 390301 concatenate[0][0]
==================================================================================================
Total params: 1,798,501
Trainable params: 1,798,501
Non-trainable params: 0
__________________________________________________________________________________________________
None
3. 결과
각 모델의 loss 변화 추이 및 정확도를 나타내면 다음과 같다. 두 모델에서 정확도가 크게 차이가 나지는 않는다.
| A | B | |
|---|---|---|
| Accuracy | Train Accuracy: 0.99728 Test Accuracy: 0.8656 |
Train Accuracy: 0.99292 Test Accuracy: 0.8602 |
| Loss | 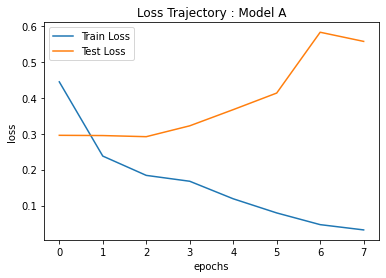 |
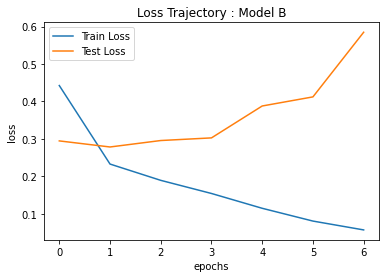 |
같은 문장에 대한 임베딩을 확인하면 다음과 같다. A모델의 경우에는 CNN 네트워크 임베딩, LSTM 네트워크 임베딩의 2개의 결과가 존재한다. B모델의 경우는 임베딩 결과가 1개이다. 똑같은 문장, 똑같은 조건임에도 모두 임베딩 결과가 다름을 알 수 있다.
# A 모델
========== CNN 모델 임베딩 결과 ============
[[-0.01276525 0.00116454 -0.01112397 ... 0.0602836 0.00600436
-0.04445797]
[-0.01276525 0.00116454 -0.01112397 ... 0.0602836 0.00600436
-0.04445797]
[-0.01276525 0.00116454 -0.01112397 ... 0.0602836 0.00600436
-0.04445797]
...
[-0.0182672 0.08226017 -0.00914974 ... 0.0713894 -0.0359947
0.00411192]
[ 0.00433552 -0.02160217 -0.03094409 ... 0.0904799 0.01571204
-0.0239571 ]
[-0.01285743 0.07846005 -0.05796566 ... 0.03992537 0.0537003
-0.01400306]]
========== LSTM 모델 임베딩 결과 ============
[[-0.00271338 0.02094274 0.00371999 ... -0.00023136 -0.02612202
-0.01543511]
[-0.00271338 0.02094274 0.00371999 ... -0.00023136 -0.02612202
-0.01543511]
[-0.00271338 0.02094274 0.00371999 ... -0.00023136 -0.02612202
-0.01543511]
...
[-0.01716644 -0.02204421 -0.02440149 ... 0.02342658 -0.00588947
-0.00600715]
[ 0.00709489 0.01465347 -0.02767408 ... -0.04112244 -0.08582544
-0.06375209]
[-0.0480172 -0.00326056 0.02997746 ... -0.0047763 -0.00199021
0.03296294]]
# B모델
========== 모델 임베딩 결과 ============
[[-0.01970719 0.03226156 -0.01150685 ... -0.01324784 0.0146792
-0.0247236 ]
[-0.01970719 0.03226156 -0.01150685 ... -0.01324784 0.0146792
-0.0247236 ]
[-0.01970719 0.03226156 -0.01150685 ... -0.01324784 0.0146792
-0.0247236 ]
...
[-0.03874208 0.03714151 -0.03370604 ... 0.03531352 0.03331351
-0.01129962]
[-0.07488174 -0.08750328 -0.02646397 ... -0.06887636 0.01457421
0.02120831]
[-0.02932738 -0.00823586 -0.0016395 ... -0.00436181 0.03938067
0.02489971]]
공유하기
Twitter Facebook LinkedIn

댓글남기기