
[NLP] Word2Vec
출처가 명시되지 않은 모든 자료(이미지 등)는 조성현 강사님의 강의 및 강의 자료를 기반으로 합니다.
단어 임베딩_Word2Vec
단어 임베딩을 위한 방법으로 Keras Embedding 레이어를 사용하는 방법을 알아 보았다.
그러나 이와 같은 Word Embedding은 자연어 처리 태스크 중 classification 등 특정 목적을 달성하기 위해 그 때마다 학습하는 방식이었다. 따라서 다음과 같은 문제가 있다.
- Word Embedding 벡터가 사후적으로 결정된다.
-
임베딩된 단어 벡터들이 풀고자 하는 문제에만 맞게 학습되어 특정 용도에만 한정된다.
이와 같은 문제를 해결하고, 단어를 1) 사전에, 2) 범용적인 목적으로 사용할 수 있도록 임베딩하는 기법들이 개발되었다.
참고: 단어 임베딩의 역사
1에서 살펴볼 벡터 공간 모델 이전에는 잠재 의미 분석(LSA), 잠재 디리클레 할당(LDA) 등을 활용해 단어를 벡터 공간에 표현하고자 했다. 단어-문서 행렬, TF-IDF 행렬 등 빈도 기반의 수치화 기법이나, 확률 분포 이론을 기반으로 임베딩하는 방식이었다. 단어 임베딩(Word Embedding)이라는 명칭이 처음 등장한 것은 2003년 Bengio의 연구에서부터였다고 한다.
그 중에서도 아마 가장 유명한 모델은, 지금 살펴 볼 Word2Vec 모델일 것이다. 뉴럴 네트워크를 이용하면서도, 학습 속도가 비약적으로 빠른 비지도학습 기반의 임베딩 방법이다.
1. 개요
Word2Vec 임베딩은 방대한 양의 코퍼스를 학습하고, 단어들이 특정 관계를 갖도록 벡터화한다. 이러한 벡터화 과정의 밑바탕에는 분포 가설이 있다. 비슷한 문맥에 등장하는 단어들은 그 의미도 비슷할 것이라는 가설이다. 단어의 주변 단어를 참조하여 해당 단어를 벡터화하는 방식이기 때문에, distributed representation이라고도 한다. 임베딩 결과를 확인하면, 당연히 인접 단어 간 단어 벡터의 유사도가 높다.
각 단어는 원핫 벡터로 모델에 입력된다. 그리고 학습 방식에 따라 1) CBOW(Continuous Bag-Of-Words)와 2) Skip-Gram의 두 가지 종류로 나뉜다.
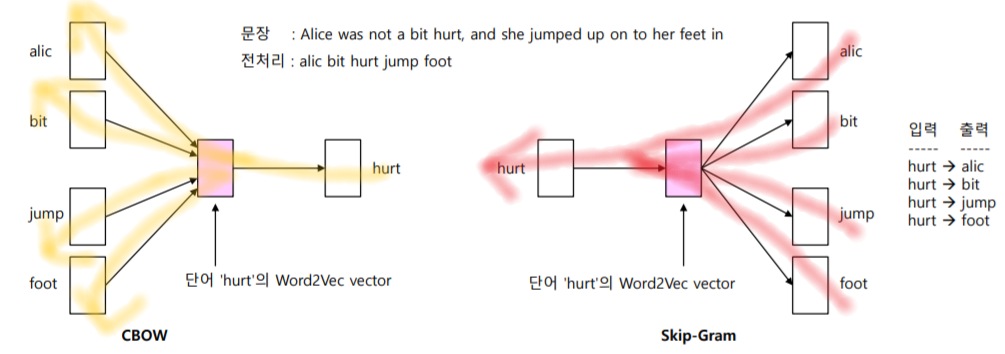
- CBOW : 얻고자 하는 단어를 중심으로 주변 단어(이전 n개, 이후 n개)가 주어졌을 때, 해당 단어를 예측하는 것을 목표로 한다. 주변 단어들을 모두 넣어야 하나의 단어에 대한 Word2Vec 벡터가 생성된다.
- Skip-Gram : 얻고자 하는 단어가 주어졌을 때 주변 단어(이전 n개, 이후 n개)를 예측한다. 단어를 하나만 넣어도 Word2Vec 벡터를 생성할 수 있다. 사용하기 편하고, CBOW보다 더 넓은 범위의 문맥을 단어 학습에 활용할 수 있다.
일반적으로 Skip-Gram 모델을 학습했을 때 품질이 더 좋은 경향이 있다. 그 이유를 다음의 두 가지 관점에서 살펴볼 수 있다.
Skip-Gram, CBOW 모두 n=2라고 가정해 보자.
첫째, 학습 데이터를 더 많이 확보할 수 있다. 이 경우 Skip-Gram 모델이 입력과 출력에 활용할 수 있는 데이터 쌍은 (타깃 단어, 타깃 이전 2번째 단어), (타깃 단어, 타깃 이전 1번째 단어), (타깃 단어, 타깃 이후 1번째 단어), (타깃 단어, 타깃 이후 2번째 단어)의 4가지 쌍이 된다. 반면 CBOW의 경우, ((타깃 이전 2번째 단어, 타깃 이전 1번째 단어, 타깃 이후 1번째 단어, 타깃 이후 2번째 단어), 타깃 단어)의 1가지 쌍만 활용할 수 있다. 따라서 Skip-Gram이 같은 코퍼스를 가지고도 더 많은 문맥을 활용할 수 있어 임베딩 품질이 더 좋은 경향이 있다.
참고 : Skip-Gram의 학습 방식
사실 방법론만 보자면 CBOW처럼 하나의 중심 단어를 놓고 주변 단어 4개를 모두 학습시키는 게 맞다. 그러나 실제 구현 상으로는 위와 같이 중심 단어 하나에 대해 이전 2개 단어, 이후 2개 단어 각각이 나오도록 학습시킨다.
둘째, gradient update 과정에서 더 많은 정보를 활용할 수 있다. CBOW 방식의 경우에는 위의 그림에서 보듯 오류 역전파가 이전 4개 단어 쌍으로 모두 전파되는 반면, Skip-Gram의 경우는 4개의 출력 결과에서 오류가 하나의 입력 단어로 모두 전파된다.
2. 모델 아키텍쳐
논문에 등장하는 목적 함수를 보면 다음과 같다.
\[J(\theta) = \frac {1} {T} \Sigma_{t=1}^T \Sigma_{-m\leq j \leq m, j \neq 0}logp(w_{t+j}|w_t)\]간단하게 이해하자면, \(t\) 번째 단어를 예측해야 한다고 할 때, \(t\) 번째 단어를 기준으로 왼쪽으로 \(m\)개, 오른쪽으로 \(m\)개의 단어가 생성될 확률을 최대화하고자 한다. \(t\) 를 1부터 \(T\)까지, 즉 가지고 있는 코퍼스 내의 모든 단어에 대해 위의 확률을 최대화하고자 하는 것이다.
은닉층이 하나, 출력층이 하나인 2개 계층의 신경망 구조를 통하여 학습한다. 활성화 함수도 없다. 전부 다 linear 네트워크 구조이다.
타겟 단어가 주어졌을 때, 그 주변에 나오는 문맥 단어들의 생성 확률을 높이고자 한다.
모델 구조 자체가 간단하기 때문에 계산량이 적고, 더 많은 데이터를 활용할 수 있다. 학습을 완료한 후 은닉층의 벡터가 해당 단어의 Word2Vec 벡터가 된다. 단어의 의미를 반영한 latent vector라고 보면 된다.
ㄹ
더 자주 사용되는 Skip-Gram 방식을 기준으로 모델 아키텍쳐를 알아 보자.
공유하기
Twitter Facebook LinkedIn

댓글남기기