
[DL] CNN_2.모델 구현
문성훈 강사님의 강의를 기반으로 합니다. Github Repo
Tensorflow: 1.5
CNN 구현
1. CNN 개념의 코드 구현
다음과 같이 필요한 모듈을 불러 온다.
import tensorflow as tf
import numpy as np
학습 데이터를 생성한다. 픽셀의 색을 표현하는 스칼라 값들을 NumPy의 ndarray 배열로 표현한다. 3x3 크기의 gray scale 이미지 1장이므로, (1, 3, 3, 1) 형태의 4차원 배열을 생성해야 한다.
image = np.array([[[1],[2],[3]],
[[4],[5],[6]],
[[7],[8],[9]]], dtype=np.float32)
>>> print(image.shape) # (1, 3, 3, 1)
>>> print(image)
# [[[[1.]
# [2.]
# [3.]]
#
# [[4.]
# [5.]
# [6.]]
#
# [[7.]
# [8.]
# [9.]]]]
참고
.reshape()을 이용할 수도 있다.image = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=np.float32).reshape(1, 3, 3, 1)
width, height, color(=depth), filter 개수를 통해 filter를 정의한다. 이 때, filter가 예약어이므로 변수 명으로 사용할 수 없음에 주의하자.
2x2 사이즈의 gray scale 필터를 3개의 채널로 만들어 보자. 필터 스칼라 값은 아무렇게나 주어도 된다.
# (2, 2, 1, 3)
weight = np.array([[[[1,10,-1]],
[[1,10,-1]]],
[[[1,10,-1]],
[[1,10,-1]]]],
dtype=np.float32)
filter 순회를 통해 feature map을 만든다.
conv2d = tf.nn.conv2d(image,
weight,
strides=[1,1,1,1],
padding='VALID')
sess = tf.Session()
sess.run(conv2d)
tf.nn.conv2d 함수를 사용한다. Tensorflow 신경망의 convolution 함수 중 (이미지 형태와 무관하게) feature map을 2차원으로 추출해 준다.
parameter로는 1) 사용할 이미지, 2) 필터, 3) stride, 4) padding 옵션를 갖는다. 특히, stride를 지정할 때는 가운데 2칸이 중요하다. 가로, 세로 이동하는 칸 수를 다르게 잡아도 되지만, 연산에 문제가 생길 수도 있기 때문에, 미리 계산하지 않았다면 (웬만하면) 길이를 동일하게 지정하자. padding 옵션에서 VALID는 padding을 하지 않겠다 는 의미이고, SAME이 padding을 한다 는 의미이다.
conv2d층으로 이루어진 convolution 단계의 실행 결과는 다음과 같다.
결과 tensor shape :
(이미지 개수, feature map size, 필터 개수(=차원))
# conv2d층 실행한 결과로 tensor : (1, 2, 2, 3)
[[[[ 12. 120. -12.]
[ 16. 160. -16.]]
[[ 24. 240. -24.]
[ 28. 280. -28.]]]]
이제 pooling layer를 설계한다. pooling 연산의 종류에 따라 사용하는 함수가 달라진다. pooling 연산은 앞에서도 이야기했듯 3가지가 있지만, 주로 max pooling layer를 사용한다.
pool = tf.nn.max_pool(conv2d,
ksize=[1,2,2,1],
strides=[1,1,1,1],
padding='SAME')
tf.nn.max_pool함수를 이용한다.
parameter로는 1) pooling 적용할 층, 2) 커널 사이즈, 3) stride, 4) padding 옵션이 있다. kernel size에서 맨 앞과 뒤의 1은 더미 변수이다.
이번 단계에서는 패딩을 진행해 보자.
max_pool 층을 실행한 결과는 다음과 같다.
# pooling 결과 tensor
[[[[ 28. 280. -12.]
[ 28. 280. -16.]]
[[ 28. 280. -24.]
[ 28. 280. -28.]]]]
패딩 옵션을 주어 풀링을 진행한 결과 tensor를 해석하면 다음의 그림과 같다. (질문을 해결해 주신 문쌤께 감사를!) 패딩이 붙은 픽셀의 스칼라 값은 0이고, 빨간 사각형이 커널이다.
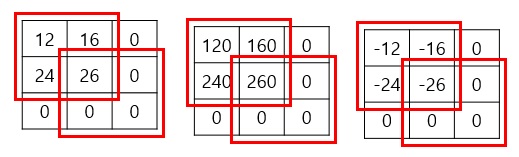
내부적으로 패딩이 붙는 규칙이 있을 텐데, 정형화할 수 있는 규칙을 찾아내지는 못했다. 0은 숫자로서 값을 가진다기보다는, 말 그대로 비어 있는 공간을 만드는 것이라고 이해해야 한다. 그렇기 때문에 pooling의 결과 음수가 나온다.
2. MNIST 실습
Tensorflow 내장 MNIST 데이터를 활용해 CNN 모델을 구현한다.
- 이미지 convolution 및 pooling 후 원본과 어떻게 달라지는지 확인하고,
- 이미지의 특징을 나타내는 픽셀만 학습시킬 때 성능이 좋음을 확인한다.
2.1. 모듈 및 데이터 준비
다음과 같이 필요한 모듈을 불러온다.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
불러 온 input_data로부터 학습 데이터를 확보한다. 데이터를 저장할 경로를 지정하고, one_hot 옵션을 주어 라벨에 대한 원핫 인코딩까지 진행한다.
mnist = input_data.read_data_sets("./data/mnist", one_hot=True)
2.2. 이미지 확인
train set에 55000개의 이미지가 존재한다. 그 중 하나를 가져와 그림을 그리고, 원본 이미지를 확인하자. 기존의 이미지 데이터를 28x28 사이즈로 바꿔 주어야 2차원의 그림 형태로 확인할 수 있다. 컬러맵 옵션을 Greys로 주어 흑백 이미지로 반환했다.
# check data
sample_img = mnist.train.images[0].reshape(28, 28)
# show image
plt.imshow(sample_img, cmap='Greys')

참고
tf.keras.datasets에서 다운로드하면 reshape의 과정이 필요 없다.data_train, data_test = tf.keras.datasets.mnist.load_data() (images_train, labels_train) = data_train (images_test, labels_test) = data_test >>> images_train[0].shape # (28, 28)
1) reshape
샘플 이미지를 4차원 ndarray 형태로 변환한다. 이미지 개수는 신경쓰지 말고 -1로 설정하면 된다.
img = sample_img.reshape(-1, 28, 28, 1)
2) filter
activation map을 만들기 위한 filter를 정의한다. 난수 텐서를 생성하기 위해 tf.random_normal을 사용한다.
# 3x3 크기의 필터, 5채널 구성.
W = tf.Variable(tf.random_normal([3,3,1,5]), name='filter1')
3) feature map
stride 옵션을 가로 세로 2칸씩 주었기 때문에, 결과로 도출될 채널들의 이미지 사이즈는 14x14로 줄어들게 된다.
conv2d = tf.nn.conv2d(img, W, strides=[1,2,2,1], padding='SAME')
4) activation map
convolution 후 feature map들을 모은다.
# session 설정
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 초기화
# convolution layer 실행
conv2d_result = sess.run(conv2d)
>>> print(conv2d_result)
# [[[[ 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
# 0.0000000e+00]
# [ 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
# 0.0000000e+00]
# [ 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
# 0.0000000e+00]
# [ 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
# 0.0000000e+00]
# ...
# [ 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
# 0.0000000e+00]]
# ...
>>> print(conv2d_result.shape)
# (1, 14, 14, 5)
5) convolution 결과 확인
convolution 결과 shape을 통해, 1장의 이미지가 5개의 채널로 겹쳐져 있음을 알 수 있다. 각각의 채널은 이미지에서 특징적인 부분을 잡아 내고 있는 부분이다.
이 특징들이 어떤 것인지 보기 위해서는, 5개의 이미지들을 펼쳐야 한다. 축을 전환하면 된다. (3차원 축, 즉 겹쳐져 있던 채널들이 x축으로 오면서 각각의 채널들이 0차원 축으로 들어가게 된다.)
conv2d_img = np.swapaxes(conv2d_result, 0, 3)
각각의 이미지 형태를 확인하면 다음과 같다.
plt.imshow(conv2d_img[0].reshape(14,14), cmap="Greys")
plt.imshow(conv2d_img[1].reshape(14,14), cmap="Greys")
plt.imshow(conv2d_img[2].reshape(14,14), cmap="Greys")
plt.imshow(conv2d_img[3].reshape(14,14), cmap="Greys")
plt.imshow(conv2d_img[4].reshape(14,14), cmap="Greys")

기존 이미지에서 어떻게 특징이 뽑혀 나왔는지 확인할 수 있다. 각각의 이미지가 강조하고 있는 부분이 (미세하..지만) 다르게 나타난다.
6) pooling 결과 확인
convolution한 결과에서 pooling을 진행해 보자. 커널 사이즈를 2x2, stride 옵션을 가로 세로 2칸씩, padding을 진행하지 않는 것으로 하여 max_pool 레이어를 구성했다.
14x14 사이즈의 각 이미지를 역시 가로, 세로 2칸씩 이동하며 pooling했으므로, 결과적으로 각 5장의 이미지가 7x7 사이즈의 이미지로 변환된다.
# pooling layer 구성
pool = tf.nn.max_pool(conv2d_result,
ksize=[1,2,2,1],
strides=[1,2,2,1],
padding='VALID')
>>> print(pool.shape) # (7,7)
# pooling 진행
pool = sess.run(pool)
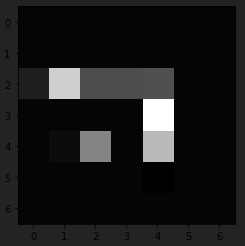
위와 동일하게 축을 전환하고 이미지를 확인한다. 전반적으로 pooling 후 이미지가 더 흐릿해짐을 확인할 수 있다. 첫 번째 이미지는 매우 어둡기 때문에 결과 사진을 첨부하지는 않는다.
# 이미지 확인을 위한 축 전환
pool_img = np.swapaxes(pool, 0, 3)
#plt.imshow(pool_img[0].reshape(7,7), cmap="Greys")
plt.imshow(pool_img[1].reshape(7,7), cmap="Greys")
2.3. 모델 구현
convolution 및 pooling 과정을 거쳐 이미지가 어떻게 변환되는지 감을 잡았다. 이제 모델을 구성하고 학습하자.
참고
- 틈틈이 shape을 확인하자.
invalid arguments error가 난다.- 현재 가상환경에서는
Tensorflow ver==1.5.0이므로 dropout 시keep_prob를 설정해야 한다.
1) graph 초기화
tf.reset_default_graph()
2) placeholder 설정
X = tf.placeholder(shape=[None, 784], dtype=tf.float32) # input data
Y = tf.placeholder(shape=[None, 10], dtype=tf.float32) # labels
prob_rate = tf.placeholder(dtype=tf.float32) # dropout 시 남길 비율
3) Convolution Layer
두 개의 convolution층을 구성한다. 첫 번째 층에서 14x14로 이미지 사이즈가 줄어들고, 두 번째 층에서 7x7로 이미지 사이즈가 줄어든다. 각 층에서 convolution을 진행한 후 max pool까지 진행한다.
각각의 층에서 커널 크기, 채널 개수 등은 모두 임의로 지정한다. convolution 적용 후 feature map에 relu activation 함수를 적용했다.
# reshape images
X_img = tf.reshape(X, [-1,28,28,1]) # 이미지 개수 모름, color = 흑백.
# 1st Convolution Layer
W1 = tf.Variable(tf.random_normal([3,3,1,32]), name='filter1')
L1 = tf.nn.conv2d(X_img, W1, strides=[1,1,1,1], padding='SAME')
L1 = tf.nn.relu(L1)
L1 = tf.nn.max_pool(L1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# 2nd Convolution Layer
W2 = tf.Variable(tf.random_normal([3,3,32,64]), name='filter2') # 채널 개수 주의
L2 = tf.nn.conv2d(L1, W2, strides=[1,1,1,1], padding='SAME')
L2 = tf.nn.relu(L2)
L1 = tf.nn.max_pool(L2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
4) 평면화
L2 = tf.reshape(L2, [-1, 7*7*64]) # 채널 개수 = 필터의 수
5) FC Layer
3개의 전결합 층을 구성한다. 각각의 층에서 은닉 층의 수는 임의로 적용한다. Xavier 초기화, ReLU 활성화 함수, dropout을 적용한다.
# 1st FC Layer
W3 = tf.get_variable('weight3', shape=[7*7*64, 256], initializer = tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([256]), name='bias3')
_L3 = tf.nn.relu(tf.matmul(L2, W3)+b3) # 활성화: ReLU
L3 = tf.nn.dropout(_L3, keep_prob=prob_rate) # dropout
# 2nd FC Layer
W4 = tf.get_variable('weight4', shape=[256, 256], initializer = tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([256]), name='bias4')
_L4 = tf.nn.relu(tf.matmul(L3, W4)+b4)
L4 = tf.nn.dropout(_L4, keep_prob=prob_rate)
# 3rd FC Layer
W5 = tf.get_variable('weight5', shape=[256,10], initializer = tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([10]), name='bias5')
6) Hypothesis
logit = tf.matmul(L4, W5) + b5
H = tf.nn.relu(logit)
7) Cost
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logit, labels=Y))
8) optimizer, session
AdamOptimizer를 사용해 학습을 진행한다.
# optimizer 설정
train = tf.train.AdamOptimizer(learning_rate=0.01).minimize(cost)
# session 설정
sess = tf.Session()
9) 학습
학습 횟수와 한 학습 당 배치 사이즈를 결정한 후, 학습을 진행한다.
# 변수 초기화
sess.run(tf.global_variables_initializer())
# 학습
num_of_epoch = 50
batch_size = 100
for step in range(num_of_epoch):
num_of_iter = int(mnist.train.num_examples/batch_size) # 한 학습 주기 동안의 반복 횟수
cost_val = 0
for i in range(num_of_iter):
batch_X, batch_y = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([train, cost], feed_dict = {X:batch_X, Y:batch_Y, prob_rate:0.75})
if step % 5 == 0:
print(f"cost : {cost_val}")
# 학습 종료
print("학습이 끝났습니다.")
학습을 진행하면서 cost 값의 변화 추이를 보면 다음과 같다.
Cost : 0.3225434124469757
Cost : 0.17546415328979492
Cost : 0.017594777047634125
Cost : 0.1369365155696869
Cost : 0.012903297320008278
Cost : 0.02968418411910534
Cost : 0.04002965986728668
Cost : 0.02480500377714634
Cost : 0.1298915296792984
Cost : 0.029111383482813835
10) 정확도 측정
테스트 셋 이미지를 대상으로 정확도를 측정한다. 테스트 시에는 dropout을 적용하지 않아야 함에 유의한다.
# calculate accuracy
predict = tf.argmax(H, 1)
is_correct = tf.equal(predict, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, dtype=tf.float32))
result = sess.run(accuracy, feed_dict = {X:mnist.test.images, Y:mnist.test.labels, drop_rate:1}) # dropout 적용하지 않음.
>>> print(f"정확도는 {result}입니다.")
test accuracy가 0.9850999712944031로 나온다. 기존에 기본 딥러닝 층을 활용해 모델을 구성했을 때보다 성능이 향상 되었음을 알 수 있다.
공유하기
Twitter Facebook LinkedIn

댓글남기기